Survei SLM
Survei Komprehensif Model Bahasa Kecil: Teknologi, Aplikasi Di Perangkat, Efisiensi, Peningkatan untuk LLM, dan Kepercayaan
Repo ini termasuk makalah yang dibahas dalam makalah survei terbaru kami tentang model bahasa kecil.
Baca makalah lengkapnya di sini: tautan kertas
Berita
- 2024/11/04: Versi pertama dari survei kami ada di ARXIV!
Referensi
Jika survei kami berguna untuk penelitian Anda, silakan kutip makalah kami:
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
Tinjauan SLMS
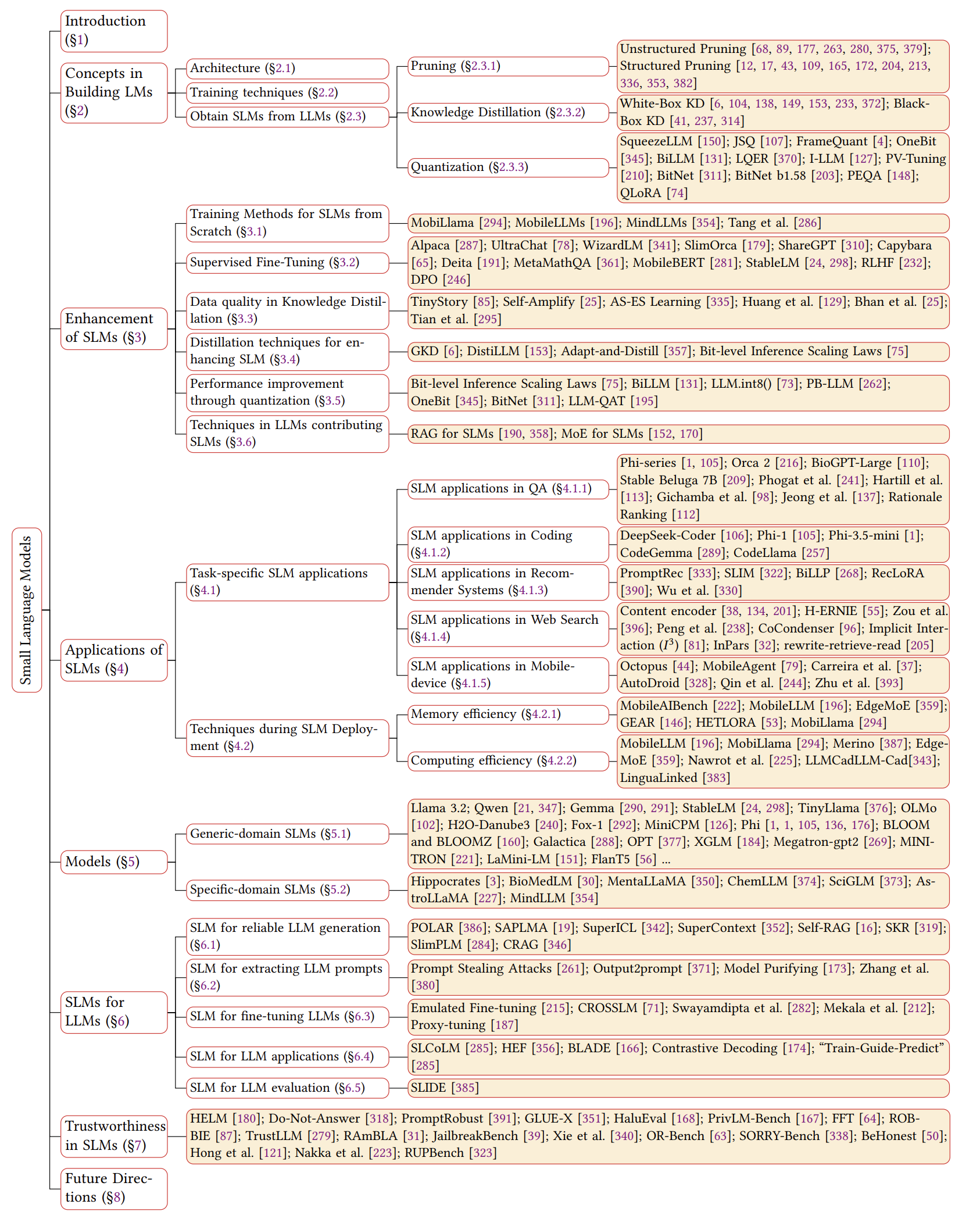
Garis waktu SLMS
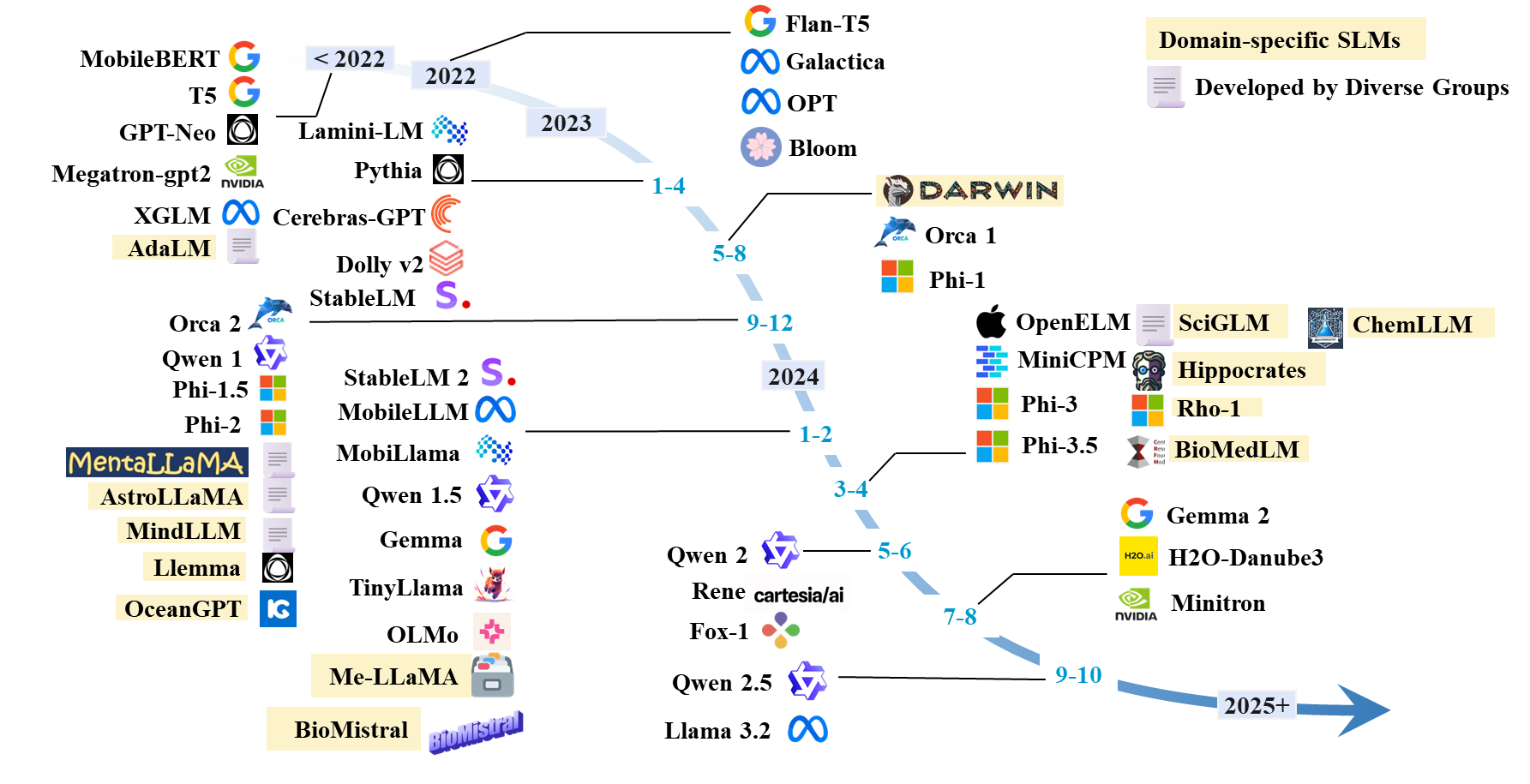
Daftar kertas SLMS
SLM yang ada
| Model | #Params | Tanggal | Paradigma | Domain | Kode | Model HF | Kertas/blog |
|---|
| Llama 3.2 | 1b; 3b | 2024.9 | Pra-pelatihan | Umum | GitHub | Hf | Blog |
| Qwen 1 | 1.8b; 7b; 14b; 72b | 2023.12 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Qwen 1.5 | 0,5b; 1.8b; 4b; 7b; 14b; 32b; 72b | 2024.2 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Qwen 2 | 0,5b; 1.5b; 7b; 57b; 72b | 2024.6 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Qwen 2.5 | 0,5b; 1.5b; 3b; 7b; 14b; 32b; 72b | 2024.9 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Gemma | 2b; 7b | 2024.2 | Pra-pelatihan | Umum | | Hf | Kertas |
| Gemma 2 | 2b; 9b; 27b | 2024.7 | Pra-pelatihan | Umum | | Hf | Kertas |
| H2O-Danube3 | 500m; 4b | 2024.7 | Pra-pelatihan | Umum | | Hf | Kertas |
| Llm-neo | 1b | 2024.11 | Pelatihan berkelanjutan | Umum | | Hf | Kertas |
| Fox-1 | 1.6b | 2024.6 | Pra-pelatihan | Umum | | Hf | Blog |
| Rene | 1.3b | 2024.5 | Pra-pelatihan | Umum | | Hf | Kertas |
| Minicpm | 1.2b; 2.4b | 2024.4 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Olmo | 1b; 7b | 2024.2 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Tinyllama | 1b | 2024.1 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Phi-1 | 1.3b | 2023.6 | Pra-pelatihan | Pengkodean | | Hf | Kertas |
| Phi-1..5 | 1.3b | 2023.9 | Pra-pelatihan | Umum | | Hf | Kertas |
| Phi-2 | 2.7b | 2023.12 | Pra-pelatihan | Umum | | Hf | Kertas |
| Phi-3 | 3.8b; 7b; 14b | 2024.4 | Pra-pelatihan | Umum | | Hf | Kertas |
| Phi-3.5 | 3.8b; 4.2b; 6.6b | 2024.4 | Pra-pelatihan | Umum | | Hf | Kertas |
| Openelm | 270m; 450m; 1.1b; 3b | 2024.4 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Mobillama | 0,5b; 0.8b | 2024.2 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Mobilellm | 125m; 350m | 2024.2 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Stablelm | 3b; 7b | 2023.4 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Stablelm 2 | 1.6b | 2024.2 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Cerebras-gpt | 111m-13b | 2023.4 | Pra-pelatihan | Umum | | Hf | Kertas |
| Bloom, Bloomz | 560m; 1.1b; 1.7b; 3b; 7.1b; 176b | 2022.11 | Pra-pelatihan | Umum | | Hf | Kertas |
| MEMILIH | 125m; 350m; 1.3b; 2.7b; 5.7b | 2022.5 | Pra-pelatihan | Umum | | Hf | Kertas |
| Xglm | 1.7b; 2.9b; 7.5b | 2021.12 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| GPT-NEO | 125m; 350m; 1.3b; 2.7b | 2021.5 | Pra-pelatihan | Umum | GitHub | | Kertas |
| Megatron-Gpt2 | 355m; 2.5b; 8.3b | 2019.9 | Pra-pelatihan | Umum | GitHub | | Kertas, blog |
| Minitron | 4b; 8b; 15b | 2024.7 | Pemangkasan dan distilasi | Umum | GitHub | Hf | Kertas |
| Minimix | 7b | 2024.7 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Minima-2 | 1b; 3b | 2023.12 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
| Minimum | 3b | 2023.11 | Pemangkasan dan distilasi | Umum | GitHub | Hf | Kertas |
| Orca 2 | 7b | 2023.11 | Distilasi | Umum | | Hf | Kertas |
| Dolly-V2 | 3b; 7b; 12b | 2023.4 | Penyetelan instruksi | Umum | GitHub | Hf | Blog |
| Lamini-lm | 61m-7b | 2023.4 | Distilasi | Umum | GitHub | Hf | Blog |
| FLANT5 KHUSUS | 250m; 760m; 3b | 2023.1 | Penyetelan instruksi | Generik (matematika) | GitHub | - | Kertas |
| FLANT5 | 80m; 250m; 780m; 3b | 2022.10 | Penyetelan instruksi | Umum | Gihub | Hf | Kertas |
| T5 | 60m; 220m; 770m; 3b; 11b | 2019.9 | Pra-pelatihan | Umum | GitHub | Hf | Kertas |
Arsitektur SLM
- Transformer: Perhatian adalah yang Anda butuhkan. Ashish Vaswani . Neurips 2017.
- Mamba 1: Mamba: Pemodelan urutan linear-waktu dengan ruang keadaan selektif. Albert Gu dan Tri Dao . Colm 2024. [Kertas].
- Mamba 2: Transformers adalah SSMS: Model umum dan algoritma yang efisien melalui dualitas ruang keadaan terstruktur. Tri Dao dan Albert Gu . ICML 2024. [Kertas] [Kode]
Peningkatan untuk SLM
Pelatihan dari awal
- Mobillama: "Mobillama: Menuju GPT yang akurat dan ringan sepenuhnya transparan" . Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan. Arxiv 2024. [Kertas] [GitHub] [Huggingface]
- Mobilellm: "Mobilellm: Mengoptimalkan model bahasa parameter sub-miliar untuk kasus penggunaan di perangkat" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra Icml 2024. [Liangzhen] [Vikas Chandra ICML 2024. [
- Memikirkan kembali optimasi dan arsitektur untuk model bahasa kecil. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Jui Berpaget, Kai Han, dan Yunhe Wang. ICML 2024. [Kertas] [Kode]
- Mindllm: "Mindllm: Pra-pelatihan model bahasa besar ringan dari awal, evaluasi dan aplikasi domain" . Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao . Arxiv 2023. [Kertas] [Huggingface]
Fine-tuning yang diawasi
- Optimalisasi Preferensi Langsung: Model bahasa Anda diam -diam merupakan model hadiah. Rafael Rafailov, Archit Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon, dan Chelsea Finn. Neurips, 2024. [Kertas] [Kode]
- Meningkatkan model bahasa obrolan dengan meningkatkan percakapan instruksional berkualitas tinggi. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun, dan Bowen Zhou. EMNLP 2023. [Kertas] [Kode]
- Slimorca: Dataset terbuka GPT-4 Augmented Flan Reasoning Traces, dengan verifikasi. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong, dan "Teknium". Huggingface, 2023. [Data]
- Stanford Alpaca: Model Llama yang mengikuti instruksi. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen LI, Carlos Guestrin, Percy Liang, dan Tatsunori B. Hashimoto. GitHub, 2023. [Blog] [GitHub] [HuggingFace]
- OpenChat: Memajukan model bahasa open-source dengan data berkualitas campuran. Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Song Sen, dan Yang Liu. Iclr, 2024. [Kertas] [kode] [HuggingFace]
- Melatih model bahasa untuk mengikuti instruksi dengan umpan balik manusia. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Madder, Maddan, Jacob Hilton, Fraser Kelton, Luke Miller, Madder, Maddon, Maddan, Jacob Hilton, Fraser Kelton, Luke Miller, Miller, Maddan, Maddan, Maddell Leike, Ryan Lowe. Neurips, 2022. [Kertas]
- RLHF: "Model bahasa pelatihan untuk mengikuti instruksi dengan umpan balik manusia" . Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, Ryan Lowe. 2022. [Kertas]
- MobileBert: "MobileBert: BERT agnostik tugas yang kompak untuk perangkat terbatas sumber daya" . Zhiqing Sun, Hongkun Yu, Lagu Xiaodan, Renjie Liu, Yiming Yang, Denny Zhou. ACL 2020. [Kertas] [GitHub] [Huggingface]
- Model bahasa adalah pelajar multitask yang tidak diawasi. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Blog Openai, 2019. [Makalah]
Kualitas Data dalam KD
- TinyStory: "TinyStories: Seberapa kecil model bahasa bisa dan masih berbicara bahasa Inggris yang koheren?" . Ronen Eldan, Yuanzhi Li. 2023. [Kertas] [Huggingface]
- As-es: "Pembelajaran As-ES: Menuju Pembelajaran Cot yang Efisien dalam Model Kecil" . Nuwa XI, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu. 2024. [Kertas]
- Amberifi diri: "Ambil-Diri: Meningkatkan Model Bahasa Kecil dengan Penjelasan Post Hoc Diri" . Milan Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot. 2024. [Kertas]
- Model bahasa besar dapat meningkatkan diri. Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu, dan Jiawei Han. EMNLP 2023. [Kertas]
- Menuju peningkatan diri LLM melalui imajinasi, pencarian, dan mengkritik. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao Mi, dan Dong Yu. Neurips 2024. [Kertas] [Kode]
Distilasi untuk SLM
- GKD: "Distilasi On-Policy Model Bahasa: Belajar dari Kesalahan yang Dihasilkan Diri" . Rishabh Agarwal et al. ICLR 2024. [Kertas]
- Distilllm: "Distillm: Menuju distilasi yang ramping untuk model bahasa besar" . Jongwoo Ko et al. ICML 2024. [Kertas] [GitHub]
- Adapt-and-Distill: "Adapt-and-Distill: Mengembangkan Model Bahasa Pretrained Kecil, Cepat dan Efektif untuk Domain" . Yunzhi Yao et al. ACL2021. [Kertas] [GitHub]
- AKL: "Memikirkan Kembali Kullback-Leibler Divergence dalam Distilasi Pengetahuan untuk Model Bahasa Besar" . Taiqiang Wu, Chaofan Tao, JiaHao Wang, Runming Yang, Zhe Zhao, Ngai Wong. Arxiv 2024. [Kertas] [GitHub]
- Distilasi Berat Weight untuk Kompresi Bert Tugas-Aggnostik Taiqiang Wu, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [Kertas] [Kode]
Kuantisasi
- Smoothquant: "Smoothquan: Kuantisasi pasca-pelatihan yang akurat dan efisien untuk model bahasa besar" . Xiao Guangxuan, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han. ICML 2023. [Kertas] [GitHub] [Slide] [Video]
- Billm: "Billm: Mendorong batas kuantisasi pasca-pelatihan untuk LLMS" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, XiaoJuan Qi. 2024. [Kertas] [GitHub]
- LLM-QAT: "LLM-QAT: Pelatihan sadar kuantisasi bebas data untuk model bahasa besar" . Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Stock Pierre, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra. 2023. [Kertas]
- PB-LLM: "PB-LLM: Sebagian model bahasa besar binarisasi" . Zhihang Yuan, Yuzhang Shang, Zhen Dong. ICLR 2024. [Kertas] [GitHub]
- OneBit: "OneBit: Menuju model bahasa besar yang sangat rendah" . Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che. Neurips 2024. [Kertas]
- Bitnet: "Bitnet: Menskalakan transformator 1-bit untuk model bahasa besar" . Hongyu Wang, Ma Shuming, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei. 2023. [Kertas]
- Bitnet B1.58: "Era 1-bit LLMS: Semua model bahasa besar berada dalam 1,58 bit" . Shuming Ma, Hongyu Wang, Lingxiao MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei. 2024. [Kertas]
- Squeezellm: "Squeezellm: kuantisasi padat-dan-spparse" . Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu LI, Sheng Shen, Michael W. Mahoney, Kurt Keutzer. ICML 2024. [Kertas] [GitHub]
- JSQ: "Mengompres model bahasa besar dengan sparsifikasi dan kuantisasi bersama" . Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu. ICML 2024. [Kertas] [GitHub]
- Framequant: "Framequant: Kuantisasi rendah-bit fleksibel untuk transformator" . Harshavardhan Adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh. 2024. [Kertas] [GitHub]
- Billm: "Billm: Mendorong batas kuantisasi pasca-pelatihan untuk LLMS" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, XiaoJuan Qi. 2024. [Kertas] [GitHub]
- LQER: "LQER: Rekonstruksi Kesalahan Kuantisasi Rendah untuk LLMS" . Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao. ICML 2024. [Kertas] [GitHub]
- I-LLM: "I-LLM: Inferensi hanya integer yang efisien untuk model bahasa besar-bit-bit yang sepenuhnya kuantisasi" . Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou. 2024. [Kertas] [GitHub]
- PV-Tuning: "PV-Tuning: Di luar estimasi lurus untuk kompresi LLM ekstrem" . Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik. 2024. [Kertas]
- PEQA: "Fine-tuning yang efisien memori dari model bahasa besar terkompresi melalui kuantisasi integer sub-4-bit" . Jeonghoon Kim, Jung Hyun Lee, Sungdong Kim, Joonsuk Park, Kang Min Yoo, Se Jung Kwon, Dongsoo Lee. Nips 2023. [Kertas]
- Qlora: "Qlora: Finetuning efisien LLMS kuantisasi" . Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Info & Klaim Luke Zettlemoyerauthors. NIPS 2023. [Kertas] [GitHub]
Teknik LLM untuk SLM
- Ma et al.: "Model bahasa besar bukanlah ekstraktor informasi beberapa-shot yang baik, tetapi penampilan yang bagus untuk sampel keras!" . Yubo MA, Yixin Cao, Yongching Hong, Aixin Sun. EMNLP 2023. [Kertas] [GitHub]
- MOQE: "Campuran ahli terkuantisasi (MOQE): Efek komplementer dari kuantisasi dan ketahanan rendah-bit" . Jin Kim muda, Raffy Fahim, Hany Hassan Awadalla. 2023. [Kertas]
- SLM-RAG: "Dapatkah model bahasa kecil dengan generasi pengambilan-pengambilan menggantikan model bahasa besar saat mempelajari ilmu komputer?" . Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut. Iticse 2024. [Kertas]
Aplikasi SLM khusus tugas
SLM di QA
- Alpaca: "Alpaca: Model pengikut instruksi yang kuat dan dapat ditiru" . Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen LI, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. [Kertas] [GitHub] [HuggingFace] [Situs Web]
- Stabil Beluga 7B: "Stabil Beluga 2" . Mahan, Dakota dan Carlow, Ryan dan Castricato, Louis dan Cooper, Nathan dan Laforte, Christian. 2023. [Huggingface]
- Biogpt Guo et al.: "Meningkatkan model bahasa kecil di PubMedqa melalui augmentasi data generatif" . Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu. 2023. [Kertas]
- Financial SLMS: "Menyempurnakan model bahasa yang lebih kecil untuk pertanyaan menjawab atas dokumen keuangan" . Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna. 2024. [Kertas]
- Colbert: "Colbert Retrieval dan Ensemble Response Scoring untuk menjawab pertanyaan model bahasa" . Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura. IEEE 2024. [Kertas]
- T-SAS: "Model Bahasa Kecil Self-Adaptive Test-Time untuk menjawab pertanyaan" . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [Kertas] [GitHub]
- Peringkat Dasar Pemikiran: "Menjawab pertanyaan yang tidak terlihat dengan model bahasa yang lebih kecil menggunakan generasi pemikiran dan pengambilan padat" . Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle. 2023. [Kertas]
SLM dalam pengkodean
- PHI-3.5-Mini: "Laporan Teknis PHI-3: Model Bahasa yang sangat cakap secara lokal di ponsel Anda" . Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ..., Chunyu Wang, Guanhua Wang, Libuuan. 2024. [Kertas] [HuggingFace] [Situs Web]
- Tinyllama: "Tinyllama: Model Bahasa Kecil Sumber Terbuka" . Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu. 2024. [Kertas] [Huggingface] [Demo Obrolan] [Perselisihan]
- Codellama: "Kode Llama: Model Yayasan Terbuka untuk Kode" . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ..., Nicolas Usunier, Thomas scialom, Gabriel Synnaeve. 2024. [Kertas] [Huggingface]
- Codegemma: "Codegemma: Model Kode Terbuka Berdasarkan Gemma" . Tim Codegemma: Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-Choo, Jingyue Shen, Joe Kelley, Kshitij Bansal, ..., Kathy Korevec, Kelly Schaefer, SCHOTT. 2024. [Kertas] [Huggingface]
SLM dalam rekomendasi
- Promptrec: "Bisakah model bahasa kecil berfungsi sebagai rekomendasi? Menuju rekomendasi start dingin-sentris data" . Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [Kertas] [GitHub]
- Slim: "Bisakah model bahasa kecil menjadi penalaran yang baik untuk rekomendasi berurutan?" . Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang. 2024. [Kertas]
- Billp: "Model bahasa besar adalah perencana yang dapat dipelajari untuk rekomendasi jangka panjang" . WOAO SHI, Xiangnan He, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng. 2024. [Kertas]
- Sekali: "Sekali: Meningkatkan rekomendasi berbasis konten dengan model bahasa besar yang terbuka dan tertutup" . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [Kertas] [GitHub]
- Reclora: "Adaptasi peringkat rendah yang dipersonalisasi seumur hidup dari model bahasa besar untuk rekomendasi" . Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang. 2024. [Kertas]
SLM dalam pencarian web
- Encoder konten: "Tugas pra-pelatihan untuk pengambilan skala besar berbasis embedding" . Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar. ICLR 2020. [Kertas]
- Poly-encoders: "Poly-encoders: Arsitektur Transformer dan Strategi Pra-Pelatihan untuk Penilaian Multi-kalimat yang Cepat dan Akurat" . Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston. ICLR 2020. [Kertas]
- Twin-Bert: "Twinbert: Pengetahuan Menyaring untuk Model Bert terstruktur kembar untuk pengambilan yang efisien" . Wenhao Lu, Jian Jiao, Ruofei Zhang. 2020. [Kertas]
- H-ernie: "H-ernie: Model bahasa pra-terlatih multi-granularitas untuk pencarian web" . Xiaokai Chu, Jiashu Zhao, Lixin Zou, Dawei Yin. Sigir 2022. [Kertas]
- Ranker: "Passage-ranking dengan Bert" . Rodrigo Nogueira, Kyunghyun Cho. 2019. [Kertas] [GitHub]
- REWITER: "Tulisan ulang permintaan untuk pengambilan model bahasa besar-agung" . Xinbei Ma, Yeyun Gong, Pengcheng He, Hai Zhao, Nan Duan. EMNLP2023. [Kertas] [GitHub]
SLM dalam perangkat seluler
- Octopus: "Octopus: Model Bahasa di Perangkat Untuk Fungsi Panggilan API Perangkat Lunak" . Wei Chen, Zhiyuan LI, Mingyuan MA. 2024. [Kertas] [Huggingface]
- MobileAgent: "Mobile-Agent-V2: Asisten Operasi Perangkat Seluler dengan Navigasi yang Efektif melalui Kolaborasi Multi-Agen" . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [Kertas] [GitHub] [Huggingface]
- Merevolusi Interaksi Seluler: "Merevolusi Interaksi Seluler: Mengaktifkan 3 miliar parameter GPT LLM di ponsel" . Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo. 2023. [Kertas]
- Autodroid: "Autodroid: Otomatisasi tugas bertenaga LLM di Android" . Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu. 2023. [Kertas]
- Agen On-Device untuk penulisan ulang teks: "Menuju agen di perangkat untuk penulisan ulang teks" . Yun Zhu, Yinxiao Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng. 2023. [Kertas]
Teknik Optimasi Penerapan On-Device
Optimalisasi Efisiensi Memori
- EDGE-LLM: "EDGE-LLM: Mengaktifkan adaptasi model bahasa besar yang efisien pada perangkat tepi melalui kompresi terpadu berlapis dan penyetelan dan pemungutan suara lapisan adaptif" . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaooya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin. 2024. [Kertas] [GitHub]
- LLM-PQ: "LLM-PQ: Melayani LLM pada kelompok heterogen dengan partisi fase-sadar dan kuantisasi adaptif" . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [Kertas] [GitHub]
- AWQ: "AWQ: Kuantisasi berat badan aktivasi untuk kompresi dan akselerasi LLM" . Ji Lin, Jiaming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han. MLSYS 2024. [Kertas] [GitHub]
- MobileAbench: "MobileAbench: Benchmarking LLMS dan LMM untuk kasus penggunaan di perangkat" . Rithesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Huan Wang, Caiming Xiong, Silvio Savaresel. 2024. [Kertas] [GitHub]
- Mobilellm: "Mobilellm: Mengoptimalkan model bahasa parameter sub-miliar untuk kasus penggunaan di perangkat" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra. ICML 2024. [Kertas] [GitHub] [Huggingface]
- Edgemoe: "Edgemoe: Inferensi cepat pada model bahasa besar berbasis MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shanggangan Wang, Mengwei Xu. 2023. [Kertas] [GitHub]
- Gear: "Gear: Resep kompresi cache KV yang efisien untuk inferensi generatif LLM yang hampir tanpa kehilangan" . Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao. 2024. [Kertas] [GitHub]
- DMC: "Kompresi Memori Dinamis: Retrofitting LLMS untuk inferensi yang dipercepat" . Piotr Nawrot, Adrian łańcucki, Marcin Chochowski, David Tarjan, Edoardo M. Ponti. 2024. [Kertas]
- Transformer-lite: "Transformer-Lite: Penyebaran Efisiensi Tinggi dari Model Bahasa Besar pada GPU Ponsel" . Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. 2024. [Kertas]
- LLMAAS: "LLM sebagai layanan sistem di perangkat seluler" . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [Kertas]
Optimalisasi efisiensi runtime
- Edgemoe: "Edgemoe: Inferensi cepat pada model bahasa besar berbasis MOE" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shanggangan Wang, Mengwei Xu. 2023. [Kertas] [GitHub]
- LLMCAD: "LLMCAD: Inferensi model bahasa besar yang cepat dan terukur" . Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu. 2023. [Kertas]
- Lingualinked: "Lingualinked: Sistem inferensi model bahasa besar yang didistribusikan untuk perangkat seluler" . Junchen Zhao, Lagu Yurun, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi. 2023 [kertas]
SLM meningkatkan LLMS
SLM untuk deteksi kalibrasi dan halusinasi LLM
- Mengkalibrasi model bahasa besar hanya menggunakan generasi mereka. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, Seong Joon Oh . ACL 2024 Long, [PDF] [Kode]
- Pembelajaran optimal Pareto untuk memperkirakan kesalahan model bahasa besar. Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon . ACL 2024 Long, [PDF]
- Keadaan internal LLM tahu kapan itu berbohong. Amos Azaria, Tom Mitchell . Temuan EMNLP 2023. [PDF]
- Agen kecil juga bisa bergoyang! Memberdayakan model bahasa kecil sebagai detektor halusinasi. Xiaoxue Cheng, Junyi LI, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 Long. [PDF]
- Konfidensi ulang LLM dari perspektif kerugian pengelompokan. Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gaël Varoquax. Temuan EMNLP 2024. [PDF]
Slms for llm rag
- Model kecil, wawasan besar: Memanfaatkan model proxy ramping untuk memutuskan kapan dan apa yang harus diambil untuk LLMS. Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen. ACL 2024 Panjang. [PDF] [kode] [HuggingFace]
- Self-Rag: Belajar mengambil, menghasilkan, dan mengkritik melalui refleksi diri. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hananeh Hajishirzi. ICLR 2024 Oral. [PDF] [HuggingFace] [kode] [Situs web] [Model] [Data]
- Longllmlingua: Mempercepat dan meningkatkan LLM dalam skenario konteks panjang melalui kompresi cepat. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. ICLR 2024 Workshop Me-Fomo Poster. [PDF]
- Pengambilan korektif generasi augmented. Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling. ARXIV 2024.1. [pdf] [kode]
- Pengetahuan diri yang dipandu pengambilan augmentasi untuk model bahasa besar. Yile Wang, Peng Li, Maosong Sun, Yang Liu. Temuan EMNLP 2023. [pdf] [kode]
- Model bahasa pengambilan dalam konteks. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. TACL 2023. [PDF] [Kode]
- Ra-ISF: Belajar menjawab dan memahami dari augmentasi pengambilan melalui feedback mandiri berulang. Liu, Yanming dan Peng, Xinyue dan Zhang, Xuhong dan Liu, Weihao dan Yin, Jianwei dan Cao, Jiannan dan Du, Tianyu. Temuan ACL 2024. [PDF]
- Less is More: Membuat model bahasa yang lebih kecil retriever subgraph yang kompeten untuk multi-hop {kgqa}. Wenyu Huang, Guancheng Zhou, Hongru Wang, Pavlos Vogiouklis, Mirella Lapata, Jeff Z. Pan. Temuan EMNLP 2024. [PDF]
SLM untuk penalaran LLM
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu, dan Julian McAuley. Model kecil adalah plug-in yang berharga untuk model bahasa besar. Temuan ACL 2024. [PDF]
- Linyi Yang, Shuibai Zhang, Zhuohao Yu, GuMangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen, dan Yue Zhang. Pengetahuan yang diawasi membuat model bahasa besar lebih baik dalam konteks pelajar. Poster ICLR 2024. [PDF]
- Zhuofeng Wu, He Bai, Aonan Zhang, Jiatao Gu, VG Vydiswaran, Navdeep Jaitly, dan Yizhe Zhang. Divide-or-conquer? Bagian mana yang harus Anda suling LLM Anda? Temuan EMNLP 2024. [PDF]
SLM untuk mengurangi hak cipta dan privasi LLMS
- Tianlin Li, Qian Liu, Tianyu Pang, Chao du, Qing Guo, Yang Liu, dan Min Lin. Memurnikan model bahasa besar dengan membuat model bahasa kecil. ARXIV 2024. [PDF]
SLM untuk mengekstraksi permintaan LLM
- Yiming Zhang, Nicholas carlini, dan Daphne Ippolito. Ekstraksi cepat yang efektif dari model bahasa. Colm 2024 [PDF]
- Zeyang Sha dan Yang Zhang. Segera mencuri serangan terhadap model bahasa besar. Arxiv (2024). [PDF]
- Collin Zhang, John X Morris, dan Vitaly Shmatikov. Mengekstrak petunjuk dengan membalikkan output LLM. [PDF]
SLM untuk fine-tuning llms
- Eric Mitchell, Rafael Rafailov, Archit Sharma, Chelsea Finn, dan Christopher D Manning. 2024. Emulator untuk menyempurnakan model bahasa besar menggunakan model bahasa kecil. ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi, dan Nuh A Smith. 2024. Model bahasa tuning dengan proxy. Colm 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen, dan Jingbo Shang. 2024. Model bahasa yang lebih kecil mampu memilih data pelatihan pengumpulan instruksi untuk model bahasa yang lebih besar. Temuan ACL 2024. [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu, dan Yaoxue Zhang. 2023. Peningkatan timbal balik dari model bahasa besar dan kecil dengan transfer pengetahuan lintas silo. Arxiv 2023. [PDF]
- SmallTolarge (S2L): Pemilihan data yang dapat diskalakan untuk menyempurnakan model bahasa besar dengan merangkum lintasan pelatihan model kecil. Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan Mirzasoleiman. Poster NIPS 2024. [PDF]
- Pencarian lemah ke kuat: Sejajarkan model bahasa besar melalui pencarian model bahasa kecil. Zhanhui zhou · zhixuan liu · jie liu · zhichen dong · chao Yang · yu qiao. Poster NIPS 2024. [PDF]
SLM untuk keamanan LLM
- Llama Guard: Perlindungan input-output berbasis LLM untuk percakapan manusia-AI. Meta Arxiv 2024 [PDF]
- SLM sebagai Guardian: Keamanan AI perintis dengan model bahasa kecil. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
SLM untuk evaluasi LLM
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin, dan Liang Zhan . 2024. Slide: Kerangka kerja yang mengintegrasikan model bahasa kecil dan besar untuk evaluasi dialog domain terbuka . Temuan ACL 2024. [PDF]
- Ketidakpastian semantik: invarian linguistik untuk estimasi ketidakpastian dalam generasi bahasa alami. Lorenz Kuhn, Yarin Gal, Sebastian Farquhar. ICLR 2023. [PDF]
- SelfCheckGPT: Deteksi halusinasi Zero-Resource Black-Box untuk model bahasa besar generatif. Potsawee Manakul, Adian Liusie, Mark Gales. EMNLP 2023 Main. [PDF]
- Proxylm: Memprediksi kinerja model bahasa pada tugas multibahasa melalui model proxy. David Anugraha, Genta Indra Winata, Chenyue LI, Patrick Amadeus Irawan, En-Shiun Annie Lee. ARXIV 2024. [PDF]
- FactScore: Evaluasi atom berbutir halus dari presisi faktual dalam pembuatan teks bentuk panjang. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hananeh Hajishirzi. EMNLP 2023 Main. [PDF]
- Lihat sebelum Anda melompat: Sebuah studi eksplorasi tentang pengukuran ketidakpastian untuk model bahasa besar. Yuheng Huang, Lagu Jiayang, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei Ma Arxiv 2023. [PDF]
Sejarah Bintang


