SLM 설문 조사
소규모 언어 모델에 대한 포괄적 인 설문 조사 : 기술, 사후 응용 프로그램, 효율성, LLM 향상 및 신뢰성
이 repo에는 작은 언어 모델에 대한 최신 설문 조사 논문에서 논의 된 논문이 포함됩니다.
여기에서 전체 용지를 읽으십시오 : 종이 링크
소식
- 2024/11/04 : 설문 조사의 첫 번째 버전은 ARXIV에 있습니다!
참조
설문 조사가 귀하의 연구에 유용한 경우, 신문을 친절하게 인용하십시오.
@article{wang2024comprehensive,
title={A Comprehensive Survey of Small Language Models in the Era of Large Language Models: Techniques, Enhancements, Applications, Collaboration with LLMs, and Trustworthiness},
author={Wang, Fali and Zhang, Zhiwei and Zhang, Xianren and Wu, Zongyu and Mo, Tzuhao and Lu, Qiuhao and Wang, Wanjing and Li, Rui and Xu, Junjie and Tang, Xianfeng and others},
journal={arXiv preprint arXiv:2411.03350},
year={2024}
}
SLM의 개요
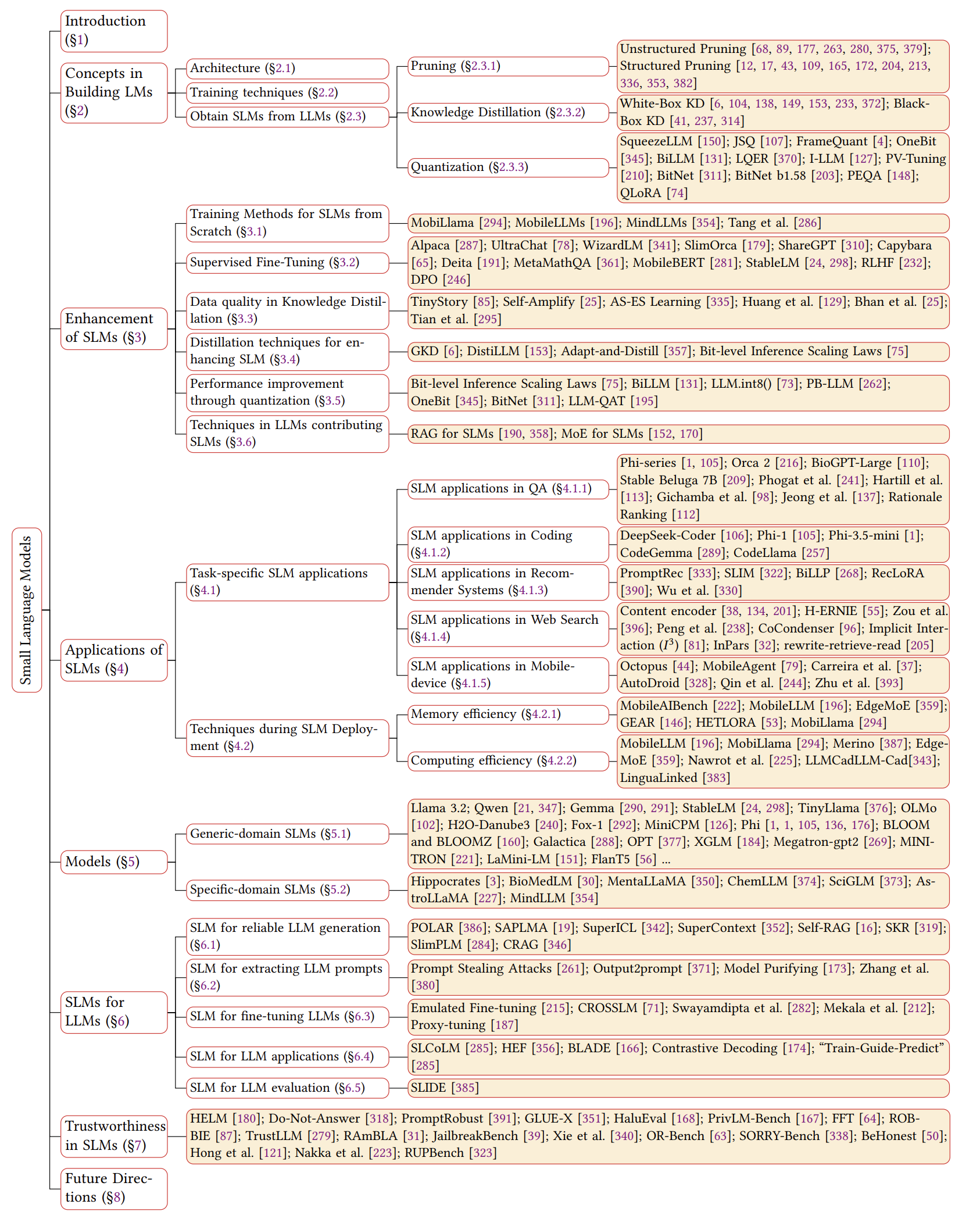
SLM의 타임 라인
SLMS 종이 목록
기존 SLM
| 모델 | #Params | 날짜 | 어형 변화표 | 도메인 | 암호 | HF 모델 | 종이/블로그 |
|---|
| 라마 3.2 | 1B; 3B | 2024.9 | 사전 훈련 | 일반적인 | github | hf | 블로그 |
| Qwen 1 | 1.8b; 7b; 14b; 72b | 2023.12 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Qwen 1.5 | 0.5b; 1.8b; 4b; 7b; 14b; 32b; 72b | 2024.2 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Qwen 2 | 0.5b; 1.5b; 7b; 57b; 72b | 2024.6 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Qwen 2.5 | 0.5b; 1.5b; 3b; 7b; 14b; 32b; 72b | 2024.9 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 아체 | 2b; 7b | 2024.2 | 사전 훈련 | 일반적인 | | hf | 종이 |
| 젬마 2 | 2b; 9b; 27b | 2024.7 | 사전 훈련 | 일반적인 | | hf | 종이 |
| H2O-Danube3 | 500m; 4B | 2024.7 | 사전 훈련 | 일반적인 | | hf | 종이 |
| llm-neo | 1B | 2024.11 | 지속적인 훈련 | 일반적인 | | hf | 종이 |
| 폭스 -1 | 1.6b | 2024.6 | 사전 훈련 | 일반적인 | | hf | 블로그 |
| rene | 1.3b | 2024.5 | 사전 훈련 | 일반적인 | | hf | 종이 |
| minicpm | 1.2B; 2.4b | 2024.4 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 올모 | 1B; 7b | 2024.2 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 작은 일마마 | 1B | 2024.1 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| PHI-1 | 1.3b | 2023.6 | 사전 훈련 | 코딩 | | hf | 종이 |
| PHI-1.5 | 1.3b | 2023.9 | 사전 훈련 | 일반적인 | | hf | 종이 |
| PHI-2 | 2.7b | 2023.12 | 사전 훈련 | 일반적인 | | hf | 종이 |
| PHI-3 | 3.8b; 7b; 14b | 2024.4 | 사전 훈련 | 일반적인 | | hf | 종이 |
| PHI-3.5 | 3.8b; 4.2b; 6.6b | 2024.4 | 사전 훈련 | 일반적인 | | hf | 종이 |
| OpenElm | 270m; 450m; 1.1b; 3B | 2024.4 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Mobillama | 0.5b; 0.8b | 2024.2 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Mobilellm | 125m; 350m | 2024.2 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 안정 | 3b; 7b | 2023.4 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| Stablelm 2 | 1.6b | 2024.2 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 뇌 GPT | 111M-13B | 2023.4 | 사전 훈련 | 일반적인 | | hf | 종이 |
| 블룸, 블룸츠 | 560m; 1.1b; 1.7b; 3b; 7.1b; 176b | 2022.11 | 사전 훈련 | 일반적인 | | hf | 종이 |
| 고르다 | 125m; 350m; 1.3b; 2.7b; 5.7b | 2022.5 | 사전 훈련 | 일반적인 | | hf | 종이 |
| XGLM | 1.7b; 2.9b; 7.5b | 2021.12 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| gpt-neo | 125m; 350m; 1.3b; 2.7b | 2021.5 | 사전 훈련 | 일반적인 | github | | 종이 |
| Megatron-GPT2 | 355m; 2.5b; 8.3b | 2019.9 | 사전 훈련 | 일반적인 | github | | 종이, 블로그 |
| 미니 트론 | 4b; 8b; 15b | 2024.7 | 가지 치기 및 증류 | 일반적인 | github | hf | 종이 |
| 미니 믹스 | 7b | 2024.7 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 최소 -2 | 1B; 3B | 2023.12 | 사전 훈련 | 일반적인 | github | hf | 종이 |
| 미니마 | 3B | 2023.11 | 가지 치기 및 증류 | 일반적인 | github | hf | 종이 |
| 오카 2 | 7b | 2023.11 | 증류 | 일반적인 | | hf | 종이 |
| 돌리 -V2 | 3b; 7b; 12b | 2023.4 | 지시 조정 | 일반적인 | github | hf | 블로그 |
| 라미니 -LM | 61m-7b | 2023.4 | 증류 | 일반적인 | github | hf | 블로그 |
| 특수 플랜트 5 | 250m; 760m; 3B | 2023.1 | 지시 조정 | 제네릭 (수학) | github | - | 종이 |
| flant5 | 80m; 250m; 780m; 3B | 2022.10 | 지시 조정 | 일반적인 | gihub | hf | 종이 |
| T5 | 60m; 220m; 770m; 3b; 11b | 2019.9 | 사전 훈련 | 일반적인 | github | hf | 종이 |
SLM 아키텍처
- 변압기 : 주의가 필요한 전부입니다. Ashish Vaswani . Neurips 2017.
- Mamba 1 : Mamba : 선택적 상태 공간을 가진 선형 시간 시퀀스 모델링. Albert Gu와 Tri Dao . Colm 2024. [종이].
- MAMBA 2 : 변압기는 SSM입니다 : 구조화 된 상태 공간 이중성을 통한 일반화 된 모델 및 효율적인 알고리즘. Tri Dao와 Albert Gu . ICML 2024. [종이] [코드]
SLM의 향상
처음부터 훈련
- Mobillama : "Mobillama : 정확하고 가벼운 완전히 투명한 GPT를 향해" . Omkar Thawakar, Ashmal Vayani, Salman Khan, Hisham Cholakal, Rao M. Anwer, Michael Felsberg, Tim Baldwin, Eric P. Xing, Fahad Shahbaz Khan. arxiv 2024. [종이] [github] [huggingface]
- Mobilellm : "Mobilellm : 기기 사용 사례에 대한 수십억 이하 매개 변수 언어 모델 최적화" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra Icml 2024.
- 작은 언어 모델에 대한 최적화 및 아키텍처를 다시 생각합니다. Yehui Tang, Fangcheng Liu, Yunsheng Ni, Yuchuan Tian, Zheyuan Bai, Yi-Qi Hu, Sichao Liu, Shangling Jui, Kai Han 및 Yunhe Wang. ICML 2024. [종이] [코드]
- Mindllm : "Mindllm : 사전 훈련 경량 대형 언어 모델, 처음부터 평가 및 도메인 응용 프로그램" . Yizhe Yang, Huashan Sun, Jiawei Li, Runheng Liu, Yinghao Li, Yuhang Liu, Heyan Huang, Yang Gao . Arxiv 2023. [종이] [Huggingface]
감독 된 미세 조정
- 직접 선호도 최적화 : 언어 모델은 비밀리에 보상 모델입니다. Rafael Rafailov, Archite Sharma, Eric Mitchell, Christopher D Manning, Stefano Ermon 및 Chelsea Finn. Neurips, 2024. [종이] [코드]
- 고품질 교육 대화를 확장하여 채팅 언어 모델 향상. Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan Liu, Maosong Sun 및 Bowen Zhou. EMNLP 2023. [종이] [코드]
- SLIMORCA : 검증 된 GPT-4 증강 플랜 추론 흔적의 열린 데이터 세트. Wing Lian, Guan Wang, Bleys Goodson, Eugene Pentland, Austin Cook, Chanvichet Vong 및 "Teknium". Huggingface, 2023. [데이터]
- Stanford Alpaca : 교육을 따르는 라마 모델. Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang 및 Tatsunori B. Hashimoto. Github, 2023. [블로그] [Github] [Huggingface]
- OpenChat : 혼합 품질의 데이터로 오픈 소스 언어 모델 발전. Guan Wang, Sijie Cheng, Xianyuan Zhan, Xiangang Li, Sen Song 및 Yang Liu. ICLR, 2024. [종이] [코드] [Huggingface]
- 인간의 피드백으로 지침을 따르는 언어 모델. Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Amanda Askell 라이언 로우. Neurips, 2022. [종이]
- RLHF : "인간의 피드백으로 지침을 따르는 언어 모델 교육" . Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Amanda Askell 로우. 2022. [종이]
- MobileBert : "MobileBert : 리소스 제한 장치를위한 소형 작업 공급 버트" . Zhiqing Sun, Hongkun Yu, Xiaodan Song, Renjie Liu, Yiming Yang, Denny Zhou. ACL 2020. [종이] [Github] [Huggingface]
- 언어 모델은 감독되지 않은 멀티 태스킹 학습자입니다. Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever. Openai Blog, 2019. [종이]
KD의 데이터 품질
- Tinystory : "Tinystories : 언어 모델이 얼마나 작고 여전히 일관된 영어를 말할 수 있습니까?" . Ronen Eldan, Yuanzhi Li. 2023. [종이] [Huggingface]
- AS-ES : "AS-ES 학습 : 소규모 모델에서 효율적인 침대 학습을 향해" . Nuwa XI, Yuhan Chen, Sendong Zhao, Haochun Wang, Bing Qin, Ting Liu. 2024. [종이]
- 자기 증폭 : "자기 증폭 : 자체 사후 설명으로 작은 언어 모델 향상" . Milan Bhan, Jean-Noel Vittaut, Nicolas Chesneau, Marie-Jeanne Lesot. 2024. [종이]
- 대형 언어 모델은 자체 개선 할 수 있습니다. Jiaxin Huang, Shixiang Shane Gu, Le Hou, Yuexin Wu, Xuezhi Wang, Hongkun Yu 및 Jiawei Han. EMNLP 2023. [종이]
- 상상력, 검색 및 비판을 통해 LLM의 자기 개선을 향해. Ye Tian, Baolin Peng, Linfeng Song, Lifeng Jin, Dian Yu, Haitao MI 및 Dong Yu. Neurips 2024. [종이] [코드]
SLM의 증류
- GKD : "언어 모델의 정책 증류 : 자체 생성 실수로부터 배우기" . Rishabh Agarwal et al. ICLR 2024. [종이]
- DESTILLLM : "Distillm : 큰 언어 모델의 간소화 증류를 향해" . Jongwoo Ko et al. ICML 2024. [종이] [Github]
- 적응 및 방향 : "적응 및 방향 : 도메인에 대한 작고 빠르고 효과적인 사전에 걸린 언어 모델 개발" . Yunzhi Yao et al. ACL2021. [종이] [Github]
- AKL : "대형 언어 모델에 대한 지식 증류에서 Kullback-Leibler Divergence를 다시 생각합니다" . Taiqiang Wu, Chaofan Tao, Jiahao Wang, Runming Yang, Zhe Zhao, Ngai Wong. Arxiv 2024. [종이] [Github]
- 태스크-비수성 Bert 압축 Taiqiang Wu, Cheng Hou, Shanshan Lao, Jiayi Li, Ngai Wong, Zhe Zhao, Yujiu Yang Naacl, 2024, [종이] [코드]
양자화
- SmoothQuant : "SmoothQuant : 대형 언어 모델에 대한 정확하고 효율적인 사후 훈련 양자화" . Guangxuan Xiao, Ji Lin, Mickael Seznec, Hao Wu, Julien Demouth, Song Han. ICML 2023. [종이] [GitHub] [슬라이드] [비디오]
- Billm : "Billm : LLMS에 대한 훈련 후 양자화의 한계를 추진" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [종이] [Github]
- LLM-QAT : "LLM-QAT : 대형 언어 모델에 대한 데이터가없는 양자화 인식 교육" . Zechun Liu, Barlas Oguz, Changsheng Zhao, Ernie Chang, Pierre Stock, Yashar Mehdad, Yangyang Shi, Raghuraman Krishnamoorthi, Vikas Chandra. 2023. [종이]
- PB-LLM : "PB-LLM : 부분적으로 이정화 된 대형 언어 모델" . Zhihang Yuan, Yuzhang Shang, Zhen Dong. ICLR 2024. [종이] [Github]
- Onebit : "Onebit : 매우 낮은 비트 대형 언어 모델을 향해" . Yuzhuang Xu, Xu Han, Zonghan Yang, Shuo Wang, Qingfu Zhu, Zhiyuan Liu, Weidong Liu, Wanxiang Che. Neurips 2024. [종이]
- 비트넷 : "비트 넷 : 대형 언어 모델의 1 비트 변압기 스케일링" . Hongyu Wang, Shuming Ma, Li Dong, Shaohan Huang, Huaijie Wang, Lingxiao MA, Fan Yang, Ruiping Wang, Yi Wu, Furu Wei. 2023. [종이]
- Bitnet B1.58 : "1 비트 LLM의 시대 : 모든 대형 언어 모델은 1.58 비트입니다." MA, Hongyu Wang, Lingxiao MA, Lei Wang, Wenhui Wang, Shaohan Huang, Li Dong, Ruiping Wang, Jilong Xue, Furu Wei. 2024. [종이]
- Squeezellm : "Squeezellm : 조밀하고 스피트 양자화" . Sehoon Kim, Coleman Hooper, Amir Gholami, Zhen Dong, Xiuyu Li, Sheng Shen, Michael W. Mahoney, Kurt Keutzer. ICML 2024. [종이] [Github]
- JSQ : "공동 strarsification 및 Quantization에 의해 대형 언어 모델 압축" . Jinyang Guo, Jianyu Wu, Zining Wang, Jiaheng Liu, Ge Yang, Yifu Ding, Ruihao Gong, Haotong Qin, Xianglong Liu. ICML 2024. [종이] [Github]
- Framequant : "Framequant : 변압기를위한 유연한 저 비트 양자화" . Harshavardhan adepu, Zhanpeng Zeng, Li Zhang, Vikas Singh. 2024. [종이] [Github]
- Billm : "Billm : LLMS에 대한 훈련 후 양자화의 한계를 추진" . Wei Huang, Yangdong Liu, Haotong Qin, Ying Li, Shiming Zhang, Xianglong Liu, Michele Magno, Xiaojuan Qi. 2024. [종이] [Github]
- LQER : "LQER : LLM에 대한 저급 정량화 오류 재구성" . Cheng Zhang, Jianyi Cheng, George A. Constantinides, Yiren Zhao. ICML 2024. [종이] [Github]
- I-LLM : "I-LLM : 완전히 정량화 된 저급 대형 언어 모델에 대한 효율적인 정수 전용 추론" . Xing Hu, Yuan Cheng, Dawei Yang, Zhihang Yuan, Jiangyong Yu, Chen Xu, Sifan Zhou. 2024. [종이] [Github]
- PV 튜닝 : "PV 튜닝 : 극단적 인 LLM 압축에 대한 직선 추정 이상" . Vladimir Malinovskii, Denis Mazur, Ivan Ilin, Denis Kuznedelev, Konstantin Burlachenko, Kai Yi, Dan Alistarh, Peter Richtarik. 2024. [종이]
- PEQA : "4 비트 이하의 정수 양자화를 통해 압축 된 대형 언어 모델의 메모리 효율적인 미세 조정" . 전구 김, 정 NIPS 2023. [종이]
- Qlora : "Qlora : 양자화 된 LLM의 효율적인 양조 튜닝" . Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, Luke Zettlemoyerauthors 정보 및 클레임. NIPS 2023. [종이] [Github]
SLM에 대한 LLM 기술
- Ma et al. : "대형 언어 모델은 좋은 소수의 정보 추출기가 아니라 단단한 샘플을위한 좋은 재신자입니다!" . Yubo MA, Yixin Cao, Yongching Hong, Aixin Sun. Emnlp 2023. [종이] [Github]
- MOQE : "양자화 된 전문가 (MOQE)의 혼합물 : 저 비트 양자화 및 견고성의 보완 효과" . 젊은 진 킴, 래피 파힘,하니 하산 아아달라. 2023. [종이]
- SLM-RAG : "컴퓨터 과학을 학습 할 때 검색 된 세대가있는 소규모 언어 모델을 대체 할 수 있습니까?" . Suqing Liu, Zezhu Yu, Feiran Huang, Yousef Bulbulia, Andreas Bergen, Michael Liut. ITICSE 2024. [종이]
작업 별 SLM 응용 프로그램
QA의 SLM
- Alpaca : "알파카 : 강력하고 복제 가능한 명령을 따르는 모델" . Rohan Taori, Ishaan Gulrajani, Tianyi Zhang, Yann Dubois, Xuechen Li, Carlos Guestrin, Percy Liang, Tatsunori B. Hashimoto. 2023. [종이] [Github] [Huggingface] [웹 사이트]
- 안정적인 벨루가 7b : "안정적인 벨루가 2" . Mahan, Dakota와 Carlow, Ryan and Castricato, Louis and Cooper, Nathan과 Laforte, Christian. 2023. [Huggingface]
- 미세 조정 된 Biogpt Guo et al. : "생성 데이터 확대를 통해 PubMedqa에서 소규모 언어 모델 개선" . Zhen Guo, Peiqi Wang, Yanwei Wang, Shangdi Yu. 2023. [종이]
- 재무 SLM : "재무 문서에 대한 질문에 대한 질문에 대한 작은 언어 모델을 미세 조정" . Karmvir Singh Phogat Karmvir Singh Phogat, Sai Akhil Puranam, Sridhar Dasaratha, Chetan Harsha, Shashishekar Ramakrishna. 2024. [종이]
- Colbert : "언어 모델 질문 응답을위한 Colbert 검색 및 앙상블 대응 점수" . Alex Gichamba, Tewodros Kederalah Idris, Brian Ebiyau, Eric Nyberg, Teruko Mitamura. IEEE 2024. [종이]
- T-SAS : "질문 응답을위한 테스트 시간 자체 조정 소형 언어 모델" . Soyeong Jeong, Jinheon Baek, Sukmin Cho, Sung Hwang, Jong Park. ACL 2023. [종이] [Github]
- 이론적 순위 : "이론적 생성 및 조밀 한 검색을 사용하여 소규모 언어 모델로 보이지 않는 질문에 답하는 것" . Tim Hartill, Diana Benavides-Prado, Michael Witbrock, Patricia J. Riddle. 2023. [종이]
코딩의 SLM
- PHI-3.5-MINI : "PHI-3 기술 보고서 : 휴대 전화에서 로컬로 유능한 언어 모델" . Marah Abdin, Jyoti Aneja, Hany Awadalla, Ahmed Awadallah, Ammar Ahmad Awan, Nguyen Bach, Amit Bahree, Arash Bakhtiari, Jianmin Bao, Harkirat Behl, ..., Chunyu Wang, Guanhua Wang, Lijuan Wang et al. 2024. [종이] [Huggingface] [웹 사이트]
- Tinyllama : "Tinyllama : 오픈 소스 소규모 언어 모델" . Peiyuan Zhang, Guangtao Zeng, Tianduo Wang, Wei Lu. 2024. [종이] [Huggingface] [채팅 데모] [Discord]
- Codellama : "Code Llama : 코드를위한 기초 모델 오픈" . Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Romain Sauvestre, Tal Remez, ..., Nicolas Usunier, Thomas Scialom, Gabriel Synneeve. 2024. [종이] [Huggingface]
- CodeGemma : "CodeGemma : Gemma를 기반으로 한 오픈 코드 모델" . Codegemma 팀 : Heri Zhao, Jeffrey Hui, Joshua Howland, Nam Nguyen, Siqi Zuo, Andrea Hu, Christopher A. Choquette-Choo, Jingyue Shen, Joe Kelley, Kshitij Bansal, ..., Kathy Korevec, Kelly Schaefer, Scott Huffman. 2024. [종이] [Huggingface]
권장되는 SLM
- PROMPTREC : "소규모 언어 모델이 추천자 역할을 할 수 있습니까? 데이터 중심 콜드 스타트 권장 사항에 대한 권장 사항" . Xuansheng Wu, Huachi Zhou, Yucheng Shi, Wenlin Yao, Xiao Huang, Ninghao Liu. 2024. [종이] [Github]
- Slim : "소규모 언어 모델이 순차적 인 추천을 위해 좋은 추론자가 될 수 있습니까?" . Yuling Wang, Changxin Tian, Binbin Hu, Yanhua Yu, Ziqi Liu, Zhiqiang Zhang, Jun Zhou, Liang Pang, Xiao Wang. 2024. [종이]
- Billp : "대형 언어 모델은 장기 권장 사항을위한 학습 가능한 플래너입니다" . Wentao Shi, Xiangnan HE, Yang Zhang, Chongming Gao, Xinyue Li, Jizhi Zhang, Qifan Wang, Fuli Feng. 2024. [종이]
- 한 번 : "한 번 : 오픈 소스 및 폐쇄 소스 대형 언어 모델로 컨텐츠 기반 권장 사항을 높이기" . Qijiong Liu, Nuo Chen, Tetsuya Sakai, Xiao-Ming Wu. WSDM 2024. [종이] [Github]
- Reclora : "권장하기 위해 대형 언어 모델의 평생 개인화 된 저급 적응" . Jiachen Zhu, Jianghao Lin, Xinyi Dai, Bo Chen, Rong Shan, Jieming Zhu, Ruiming Tang, Yong Yu, Weinan Zhang. 2024. [종이]
웹 검색에서 SLM
- 컨텐츠 인코더 : "기반 대규모 검색을 포함시키기위한 사전 훈련 작업" . Wei-Cheng Chang, Felix X. Yu, Yin-Wen Chang, Yiming Yang, Sanjiv Kumar. ICLR 2020. [종이]
- Poly-Encoders : "Poly-Encoders : 빠르고 정확한 다중 서식 스코어링을위한 변압기 아키텍처 및 사전 훈련 전략" . Samuel Humeau, Kurt Shuster, Marie-Anne Lachaux, Jason Weston. ICLR 2020. [종이]
- Twin-Bert : "트윈버트 : 효율적인 검색을 위해 트윈 구조화 된 버트 모델에 대한 지식을 증류합니다" . Wenhao Lu, Jian Jiao, Ruofei Zhang. 2020. [종이]
- H-ernie : "H-ernie : 웹 검색을위한 다중 부문 미리 훈련 된 언어 모델" . Xiaokai Chu, Jiashu Zhao, Lixin Zou, Dawei Yin. Sigir 2022. [종이]
- 랭커 : "Bert와의 통과 재고" . 로드리고 노지 리라, 칸색 조교. 2019. [종이] [Github]
- Rewriter : "검색 된 대형 언어 모델을위한 쿼리 다시 작성" . Xinbei MA, Yeyun Gong, Pengcheng HE, Hai Zhao, Nan Duan. EMNLP2023. [종이] [Github]
모바일 디바이스의 SLM
- 문어 : "문어 : 소프트웨어 API의 기능 호출을위한 기기 언어 모델" . Wei Chen, Zhiyuan Li, Mingyuan MA. 2024. [종이] [Huggingface]
- MobileAgent : "Mobile-Agent-V2 : 다중 에이전트 협업을 통한 효과적인 내비게이션을 통한 모바일 장치 운영 어시스턴트" . Junyang Wang, Haiyang Xu, Haitao Jia, Xi Zhang, Ming Yan, Weizhou Shen, Ji Zhang, Fei Huang, Jitao Sang. 2024. [종이] [Github] [Huggingface]
- 모바일 상호 작용 혁명 : "모바일 상호 작용 혁신 : 모바일에서 30 억 파라미터 GPT LLM을 활성화" . Samuel Carreira, Tomás Marques, José Ribeiro, Carlos Grilo. 2023. [종이]
- AutoDroid : "AutoDroid : Android의 LLM 구동 작업 자동화" . Hao Wen, Yuanchun Li, Guohong Liu, Shanhui Zhao, Tao Yu, Toby Jia-Jun Li, Shiqi Jiang, Yunhao Liu, Yaqin Zhang, Yunxin Liu. 2023. [종이]
- 텍스트 재 작성을위한 기기 에이전트 : "텍스트 재 작성의 기기 에이전트를 향한" . Yun Zhu, Yinxiao Liu, Felix Stahlberg, Shankar Kumar, Yu-Hui Chen, Liangchen Luo, Lei Shu, Renjie Liu, Jindong Chen, Lei Meng. 2023. [종이]
기기 배포 최적화 기술
메모리 효율 최적화
- Edge-LLM : "Edge-LLM : 레이어 링 통합 압축 및 적응 형 레이어 튜닝 및 투표를 통해 Edge 장치에서 효율적인 대형 언어 모델 적응 가능성" . Zhongzhi Yu, Zheng Wang, Yuhan Li, Haoran You, Ruijie Gao, Xiaoya Zhou, Sreenidhi Reedy Bommu, Yang Katie Zhao, Yingyan Celine Lin. 2024. [종이] [Github]
- LLM-PQ : "LLM-PQ : 상 인식 파티션 및 적응 형 양자화를 갖춘 이종 클러스터에서 LLM 서빙" . Juntao Zhao, Borui Wan, Yanghua Peng, Haibin Lin, Chuan Wu. 2024. [종이] [Github]
- AWQ : "AWQ : LLM 압축 및 가속을위한 활성화 인식 중량 양자화" . Ji Lin, Jiagming Tang, Haotian Tang, Shang Yang, Wei-Ming Chen, Wei-Chen Wang, Guangxuan Xiao, Xingyu Dang, Chuang Gan, Song Han. MLSYS 2024. [종이] [Github]
- Mobileaibench : "Mobileaibench : 기기 사용 사례를위한 LLM 및 LMM 벤치마킹" . Ritesh Murthy, Liangwei Yang, Juntao Tan, Tulika Manoj Awalgaonkar, Yilun Zhou, Shelby Heinecke, Sachin Desai, Jason Wu, Ran Xu, Sarah Tan, Jianguo Zhang, Zhiwei Liu, Shirley Kokane, Zuxin Liu, Ming Zhu, Ming Zhu, Ming Xiong, Silvio Savaresel. 2024. [종이] [Github]
- Mobilellm : "Mobilellm : 기기 사용 사례에 대한 수십억 이하 매개 변수 언어 모델 최적화" . Zechun Liu, Changsheng Zhao, Forrest Iandola, Chen Lai, Yuandong Tian, Igor Fedorov, Yunyang Xiong, Ernie Chang, Yangyang Shi, Raghuraman Krishnamoorthi, Liangzhen Lai, Vikas Chandra. ICML 2024. [종이] [Github] [Huggingface]
- Edgemoe : "Edgemoe : MOE 기반 대형 언어 모델의 빠른 기기 추론" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [종이] [Github]
- 기어 : "기어 : LLM의 거의 손이없는 생성 추론을위한 효율적인 KV 캐시 압축 레시피" . Hao Kang, Qingru Zhang, Souvik Kundu, Geonhwa Jeong, Zaoxing Liu, Tushar Krishna, Tuo Zhao. 2024. [종이] [Github]
- DMC : "동적 메모리 압축 : 가속화 된 추론을위한 LLM을 개조" . Piotr Nawrot, Adrian łańcucki, Marcin Choochowski, David Tarjan, Edoardo M. Ponti. 2024. [종이]
- Transformer-Lite : "변압기 라이트 : 휴대폰 GPU에 대형 언어 모델의 고효율 배포" . Luchang Li, Sheng Qian, Jie Lu, Lunxi Yuan, Rui Wang, Qin Xie. 2024. [종이]
- LLMAAS : "모바일 장치의 시스템 서비스로서 LLM" . Wangsong Yin, Mengwei Xu, Yuanchun Li, Xuanzhe Liu. 2024. [종이]
런타임 효율 최적화
- Edgemoe : "Edgemoe : MOE 기반 대형 언어 모델의 빠른 기기 추론" . Rongjie Yi, Liwei Guo, Shiyun Wei, Ao Zhou, Shangguang Wang, Mengwei Xu. 2023. [종이] [Github]
- LLMCAD : "LLMCAD : 빠르고 확장 가능한 대형 언어 모델 추론" . Daliang Xu, Wangsong Yin, Xin Jin, Ying Zhang, Shiyun Wei, Mengwei Xu, Xuanzhe Liu. 2023. [종이]
- Lingualinked : "Lingualinked : 모바일 장치를위한 분산 된 대형 언어 모델 추론 시스템" . Junchen Zhao, Yurun Song, Simeng Liu, Ian G. Harris, Sangeetha Abdu Jyothi. 2023 [종이]
SLM은 LLM을 향상시킵니다
LLM 교정 및 환각 감지 용 SLM
- 세대 만 사용하여 큰 언어 모델을 교정합니다. Dennis Ulmer, Martin Gubri, Hwaran Lee, Sangdoo Yun, Seong Joon Oh . ACL 2024 Long, [PDF] [코드]
- 큰 언어 모델 오류를 추정하기위한 최적의 학습. Theodore Zhao, Mu Wei, J. Samuel Preston, Hoifung Poon . ACL 2024 Long, [PDF]
- LLM의 내부 상태는 언제 거짓말을하고 있는지 알고 있습니다. Amos Azaria, Tom Mitchell . EMNLP 2023 결과. [PDF]
- 소규모 요원도 흔들릴 수 있습니다! 환각 탐지기로서 작은 언어 모델에 권한을 부여합니다. Xiaoxue Cheng, Junyi Li, Wayne Xin Zhao, Hongzhi Zhang, Fuzheng Zhang, Di Zhang, Kun Gai, Ji-Rong Wen. EMNLP 2024 길이. [PDF]
- 그룹화 손실 관점에서 LLM을 재 융자합니다. Lihu Chen, Alexandre Perez-Lebel, Fabian M. Suchanek, Gaël Varoquaux. EMNLP 2024 결과. [PDF]
LLM RAG 용 SLM
- 작은 모델, 큰 통찰력 : Slim 프록시 모델을 활용하여 LLM에 대해 언제 어떻게 검색 해야하는지 결정합니다. Jiejun Tan, Zhicheng Dou, Yutao Zhu, Peidong Guo, Kun Fang, Ji-Rong Wen. ACL 2024 길이. [pdf] [코드] [Huggingface]
- 자체 경영 : 자기 반성을 통해 검색, 생성 및 비판을 배우는 학습. Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, Hannaneh Hajishirzi. ICLR 2024 구강. [pdf] [huggingface] [코드] [웹 사이트] [모델] [데이터]
- longllmlingua : 프롬프트 압축을 통해 긴 컨텍스트 시나리오에서 LLM을 가속화하고 향상시킵니다. Huiqiang Jiang, Qianhui Wu, Xufang Luo, Dongsheng Li, Chin-Yew Lin, Yuqing Yang, Lili Qiu. ICLR 2024 워크숍 ME-FOMO 포스터. [PDF]
- 시정 검색 강화 세대. Shi-Qi Yan, Jia-Chen Gu, Yun Zhu, Zhen-Hua Ling. Arxiv 2024.1. [PDF] [코드]
- 대형 언어 모델에 대한 자기 지식 안내 검색. Yile Wang, Peng Li, Maosong Sun, Yang Liu. EMNLP 2023 결과. [PDF] [코드]
- 텍스트 내 검색-구분 언어 모델. Ori Ram, Yoav Levine, Itay Dalmedigos, Dor Muhlgay, Amnon Shashua, Kevin Leyton-Brown, Yoav Shoham. TACL 2023. [PDF] [코드]
- RA-ISF : 반복적 인 셀프 피드백을 통한 검색 확대로부터 이해하는 법을 배우는 것. Liu, Yanming and Peng, Xinyue and Zhang, Xuhong and Liu, Weihao and Yin, Jianwei and Cao, Jiannan and du, Tianyu. ACL 2024 결과. [PDF]
- 더 적은 것은 더 많습니다 : 소규모 언어 모델을 유능한 서브 그래프 리트리버로 만들기 {kgqa}. Wenyu Huang, Guancheng Zhou, Hongru Wang, Pavlos Vougiouklis, Mirella Lapata, Jeff Z. Pan. EMNLP 2024 결과. [PDF]
LLM 추론을위한 SLM
- Canwen Xu, Yichong Xu, Shuohang Wang, Yang Liu, Chenguang Zhu 및 Julian McAuley. 소형 모델은 큰 언어 모델을위한 귀중한 플러그인입니다. ACL 2024 결과. [PDF]
- Linyi Yang, Shuibai Zhang, Zhuohao Yu, Guangsheng Bao, Yidong Wang, Jindong Wang, Ruochen Xu, Wei Ye, Xing Xie, Weizhu Chen 및 Yue Zhang. 감독 된 지식은 대형 언어 모델을 텍스트 내 학습자에게 더 잘 만듭니다. ICLR 2024 포스터. [PDF]
- Zhuofeng Wu, 그는 Bai, Aonan Zhang, Jiatao Gu, Vg Vydiswaran, Navdeep Jaitly 및 Yizhe Zhang. 분할 또는 대응? LLM을 증류 해야하는 부분은 무엇입니까? EMNLP 2024 결과. [PDF]
LLM의 저작권 및 프라이버시 완화를위한 SLM
- Tianlin Li, Qian Liu, Tianyu Pang, Chao du, Qing Guo, Yang Liu 및 Min Lin. 작은 언어 모델을 뒷받침하여 큰 언어 모델을 정화합니다. ARXIV 2024. [PDF]
LLM 프롬프트 추출을위한 SLM
- Yiming Zhang, Nicholas Carlini 및 Daphne Ippolito. 언어 모델에서 효과적인 프롬프트 추출. Colm 2024 [PDF]
- Zeyang Sha와 Yang Zhang. 큰 언어 모델에 대한 훔치기를 신속하게합니다. Arxiv (2024). [PDF]
- Collin Zhang, John X Morris 및 Vitaly Shmatikov. LLM 출력을 역전하여 프롬프트 추출. [PDF]
미세 조정 LLM을위한 SLM
- Eric Mitchell, Rafael Rafailov, Archite Sharma, Chelsea Finn 및 Christopher D Manning. 2024. 작은 언어 모델을 사용하여 대형 언어 모델을 미세 조정하기위한 에뮬레이터. ICLR 2024. [PDF]
- Alisa Liu, Xiaochuang Han, Yizhong Wang, Yulia Tsvetkov, Yejin Choi 및 Noah A Smith. 2024. 프록시에 의한 언어 모델 조정. Colm 2024. [PDF]
- Dheeraj Mekala, Alex Nguyen 및 Jingbo Shang. 2024. 소규모 언어 모델은 더 큰 언어 모델에 대한 교육 조정 교육 데이터를 선택할 수 있습니다. ACL 2024 결과. [PDF]
- Yongheng Deng, Ziqing Qiao, Ju Ren, Yang Liu 및 Yaoxue Zhang. 2023. 크로스 실로 지식 전달을 가진 크고 작은 언어 모델의 상호 향상. ARXIV 2023. [PDF]
- SmallTolarge (S2L) : 소규모 모델의 교육 궤적을 요약하여 대형 언어 모델을 미세 조정하기위한 확장 가능한 데이터 선택. Yu Yang · Siddhartha Mishra · Jeffrey Chiang · Baharan Mirzasoleiman. NIPS 2024 포스터. [PDF]
- 약한 검색 : 작은 언어 모델을 검색하여 대형 언어 모델을 정렬합니다. Zhanhui Zhou · Zhixuan Liu · jie liu · Zhichen Dong · Chao Yang · Yu Qiao. NIPS 2024 포스터. [PDF]
LLM 안전을위한 SLM
- LLAMA 가드 : 휴먼 -AI 대화를위한 LLM 기반 입력 출력 보호. 메타 arxiv 2024 [PDF]
- 가디언으로서의 SLM : 작은 언어 모델로 AI 안전을 개척합니다. Ohjoon Kwon, Donghyeon Jeon, Nayoung Choi, Gyu-Hwung Cho, Hwiyeol Jo, Changbong Kim, Hyunwoo Lee, Inho Kang, Sun Kim, Taiwoo Park. EMNLP 2024. [PDF]
LLM 평가를위한 SLM
- Kun Zhao, Bohao Yang, Chen Tang, Chenghua Lin 및 Liang Zhan . 2024. 슬라이드 : 오픈 도메인 대화를위한 소형 및 대형 언어 모델을 통합하는 프레임 워크 . ACL 2024 결과. [PDF]
- 시맨틱 불확실성 : 자연어 생성에서 불확실성 추정을위한 언어 적 불변. Lorenz Kuhn, Yarin Gal, Sebastian Farquhar. ICLR 2023. [PDF]
- SelfCheckgpt : 생성 대형 언어 모델에 대한 Zero Resource Black-Box 환각 감지. Potsawee Manakul, Adian Liusie, Mark Gales. EMNLP 2023 메인. [PDF]
- Proxylm : 프록시 모델을 통한 다국어 작업에서 언어 모델 성능 예측. David Anugraha, Genta Indra Winata, Chenyue Li, Patrick Amadeus Irawan, En-Shiun Annie Lee. ARXIV 2024. [PDF]
- FactScore : 장식 텍스트 생성에서 사실 정밀도의 세밀한 원자 평가. Sewon Min, Kalpesh Krishna, Xinxi Lyu, Mike Lewis, Wen-Tau Yih, Pang Koh, Mohit Iyyer, Luke Zettlemoyer, Hannaneh Hajishirzi. EMNLP 2023 메인. [PDF]
- 도약하기 전에 살펴보십시오 : 대형 언어 모델에 대한 불확실성 측정에 대한 탐색 적 연구. Yuheng Huang, Jiyang Song, Zhijie Wang, Shengming Zhao, Huaming Chen, Felix Juefei-Xu, Lei ma arxiv 2023. [PDF]
스타 역사


