Alpaca CoT
1.0.0
中文| ภาษาอังกฤษ

นี่คือพื้นที่เก็บข้อมูลสำหรับโครงการ Alpaca-CoT ซึ่งมีจุดมุ่งหมายเพื่อสร้างแพลตฟอร์มการเรียนการสอน Finetuning (IFT) พร้อมการรวบรวมคำสั่งที่กว้างขวาง (โดยเฉพาะชุดข้อมูล COT) และอินเทอร์เฟซแบบครบวงจรสำหรับแบบจำลองภาษาขนาดใหญ่และวิธีการที่มีประสิทธิภาพพารามิเตอร์ เรากำลังขยายการรวบรวมข้อมูลการปรับแต่งคำสั่งของเราอย่างต่อเนื่องและการรวม LLMs มากขึ้นและวิธีการที่มีประสิทธิภาพมากขึ้น นอกจากนี้เรายังได้สร้างสาขาใหม่ tabular_llm เพื่อสร้าง LLM แบบตารางสำหรับการแก้ปัญหางาน Intelligence Table
คุณยินดีต้อนรับอย่างอบอุ่นเพื่อให้เรามีชุดข้อมูลการปรับแต่งคำสั่งที่ไม่ได้รวบรวม (หรือแหล่งที่มาของพวกเขา) เราจะจัดรูปแบบอย่างสม่ำเสมอฝึกอบรมโมเดล ALPACA (และ LLM อื่น ๆ ในอนาคตต้น) ด้วยชุดข้อมูลเหล่านี้โอเพ่นซอร์สจุดตรวจของแบบจำลองและดำเนินการศึกษาเชิงประจักษ์อย่างกว้างขวาง เราหวังว่าโครงการของเราสามารถมีส่วนร่วมเล็กน้อยในกระบวนการโอเพนซอร์ซของแบบจำลองภาษาขนาดใหญ่และลดเกณฑ์สำหรับนักวิจัย NLP เพื่อเริ่มต้น

หากคุณต้องการใช้วิธีการอื่นนอกเหนือจาก LORA โปรดติดตั้งเวอร์ชันที่แก้ไขในโครงการ pip install -e ./peft
12.8: LLM InternLM ถูกรวมเข้าด้วยกัน
8.16: 4bit quantization มีให้สำหรับ lora , qlora และ adalora
8.16: วิธีการที่มีประสิทธิภาพพารามิเตอร์ Qlora , Sequential adapter และ Parallel adapter ถูกรวมเข้าด้วยกัน
7.24: LLM ChatGLM v2 ถูกรวมเข้าด้วยกัน
7.20: LLM Baichuan ถูกรวมเข้าด้วยกัน
6.25: เพิ่มรหัสการประเมินแบบจำลองรวมถึง Belle และ MMCU
GPT4Tools , Auto CoT , pCLUE เพิ่มขึ้นtabular_llm ถูกสร้างขึ้นเพื่อสร้าง LLM แบบตาราง เรารวบรวมข้อมูลการปรับแต่งการเรียนการสอนสำหรับงานที่เกี่ยวข้องกับตารางเช่นการตอบคำถามตารางและใช้เพื่อปรับ LLMs ใน repo นี้MOSS LLM ถูกรวมเข้าด้วยกันGAOKAO , camel , FLAN-Muffin , COIG ถูกรวบรวมและจัดรูปแบบwebGPT , dolly , baize , hh-rlhf , OIG(part) ถูกรวบรวมและจัดรูปแบบmulti-turn conversation โดย @paulcxfirefly , instruct , Code Alpaca ถูกรวบรวมและจัดรูปแบบซึ่งสามารถพบได้ที่นี่Parameter merging Local chatting Batch predicting และ Web service building โดย @weberrGPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 และ natural-instructions จะถูกรวบรวมและจัดรูปแบบCoT_CN_data.json สามารถพบได้ที่นี่ 
Llama [1] เป็นงานที่ยอดเยี่ยมที่แสดงให้เห็นถึงความสามารถที่น่าทึ่งและความสามารถในการถ่ายภาพไม่กี่ครั้ง มันช่วยลดค่าใช้จ่ายในการฝึกอบรม finetuning และการใช้แบบจำลองภาษาขนาดใหญ่ที่แข่งขันได้เช่น LLAMA-13B มีประสิทธิภาพสูงกว่า GPT-3 (175B) และ LLAMA-65B แข่งขันกับ PALM-540B เมื่อเร็ว ๆ นี้เพื่อเพิ่มความสามารถในการติดตามการเรียนการสอนของ Llama, Stanford Alpaca [2] Finetuned Llama-7b บนข้อมูลการสอน 52K ที่สร้างขึ้นโดยเทคนิคการควบคุมตนเอง [3] อย่างไรก็ตามในปัจจุบันชุมชนการวิจัย LLM ยังคงเผชิญกับความท้าทายสามประการ: 1. แม้แต่ Llama-7b ก็ยังมีข้อกำหนดสูงสำหรับทรัพยากรการคำนวณ 2. มีชุดข้อมูลโอเพนซอร์สไม่กี่ชุดสำหรับการเรียนการสอน finetuning; และ 3. มีการขาดการศึกษาเชิงประจักษ์เกี่ยวกับผลกระทบของการเรียนการสอนประเภทต่าง ๆ เกี่ยวกับความสามารถของแบบจำลองเช่นความสามารถในการตอบสนองต่อการสอนภาษาจีนและการใช้เหตุผล COT
ด้วยเหตุนี้เราจึงเสนอโครงการนี้ซึ่งใช้ประโยชน์จากการปรับปรุงต่าง ๆ ที่ได้รับการเสนอในภายหลังโดยมีข้อดีดังต่อไปนี้:
7b , 13b และ 30b สามารถผ่านการฝึกอบรมได้อย่างง่ายดายใน 80G A100 เดียว เพื่อความรู้ที่ดีที่สุดของเรางานนี้เป็นคนแรกที่ศึกษา การใช้เหตุผลของ COT ตาม Llama และ Alpaca ดังนั้นเราจะย่องานของเราไปที่ Alpaca-CoT
ขนาดสัมพัทธ์ของชุดข้อมูลที่รวบรวมได้สามารถแสดงได้ด้วยกราฟนี้:
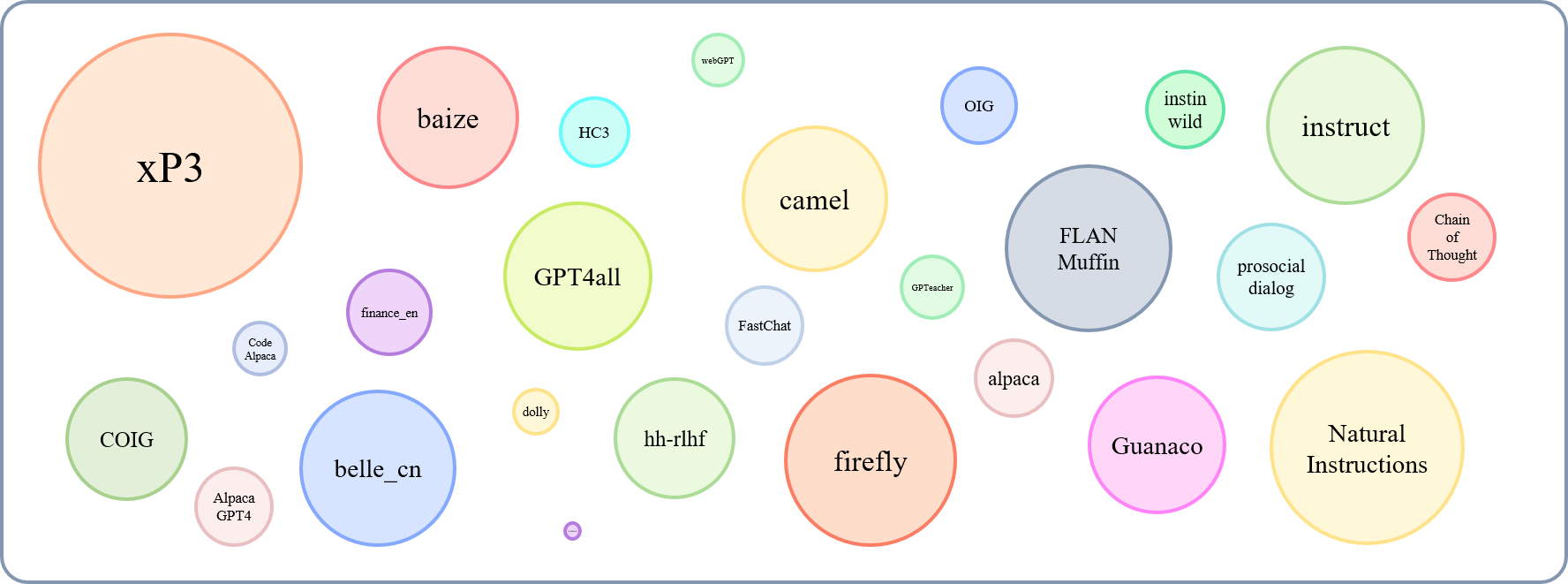
อ้างอิงถึงสิ่งนี้ (@yaodongc) เราติดป้ายชุดข้อมูลที่รวบรวมแต่ละชุดตามกฎต่อไปนี้:
(lang) ภาษาลิ้น:
(งาน) TASK-Tags:
(gen) วิธีการสร้าง:
| ชุดข้อมูล | คนโง่ | หรั่ง | งาน | คน | พิมพ์ | SRC | url |
|---|---|---|---|---|---|---|---|
| ห่วงโซ่แห่งความคิด | 74771 | en/cn | MT | HG | สอนด้วยการให้เหตุผล COT | คำอธิบายประกอบ COT บนข้อมูลที่มีอยู่ | การดาวน์โหลด |
| GPT4ALL | 806199 | en | MT | โคล | รหัสเรื่องราวและบทสนทนา | การกลั่นจาก GPT-3.5-turbo | การดาวน์โหลด |
| ผู้เข้าร่วม | 29013 | en | MT | ศรี | ทั่วไป, Roleplay, Toolformer | GPT-4 & Toolformer | การดาวน์โหลด |
| ชาวกวานาโค | 534610 | มล. | MT | ศรี | งานทางภาษาต่างๆ | Text-Davinci-003 | การดาวน์โหลด |
| HC3 | 37175 | en/cn | TS | ผสม | การประเมินผลการสนทนา | มนุษย์หรือ chatgpt | การดาวน์โหลด |
| อัลปากา | 52002 | en | MT | ศรี | คำสั่งทั่วไป | Text-Davinci-003 | การดาวน์โหลด |
| คำแนะนำธรรมชาติ | 5040134 | มล. | MT | โคล | งาน NLP ที่หลากหลาย | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| belle_cn | 1079517 | ซีเอ็นเอ็น | TS/MT | ศรี | ทั่วไปการใช้เหตุผลทางคณิตศาสตร์การสนทนา | Text-Davinci-003 | การดาวน์โหลด |
| ติดเชื้อ | 52191 | en/cn | MT | ศรี | รุ่น, Open-Qa, Mind-Storm | Text-Davinci-003 | การดาวน์โหลด |
| บทสนทนาต่อสังคม | 165681 | en | TS | ผสม | บทสนทนา | GPT-3 เขียนคำถาม + ข้อเสนอแนะของมนุษย์ด้วยตนเอง | การดาวน์โหลด |
| การเงิน _en | 68912 | en | TS | โคล | QA ที่เกี่ยวข้องกับการเงิน | GPT3.5 | การดาวน์โหลด |
| xp3 | 78883588 | มล. | MT | โคล | คอลเลกชันของชุดข้อมูลและชุดข้อมูลใน 46 ภาษา & 16 งาน NLP | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| หิ่งห้อย | 1649398 | ซีเอ็นเอ็น | MT | โคล | 23 งาน NLP | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| สั่งสอน | 888969 | en | MT | โคล | เพิ่ม GPT4ALL, Alpaca, ชุดข้อมูลเมตาโอเพนซอร์ซ | การเสริมดำเนินการโดยใช้เครื่องมือ NLP ขั้นสูงที่จัดทำโดย Allenai | การดาวน์โหลด |
| รหัส Alpaca | 2545 | en | TS | ศรี | การสร้างรหัสการแก้ไขการเพิ่มประสิทธิภาพ | Text-Davinci-003 | การดาวน์โหลด |
| alpaca_gpt4 | 52002 | en/cn | MT | ศรี | คำสั่งทั่วไป | สร้างโดย GPT-4 โดยใช้ alpaca | การดาวน์โหลด |
| WebGPT | พ.ศ. 2447 | en | TS | ผสม | การดึงข้อมูล (IR) QA | GPT-3 ที่ปรับแต่งอย่างละเอียดแต่ละคำสั่งมีเอาต์พุตสองรายการเลือกดีกว่า | การดาวน์โหลด |
| Dolly 2.0 | 15015 | en | TS | HG | QA ปิดการสรุปและ ETC, Wikipedia เป็นข้อมูลอ้างอิง | คำอธิบายประกอบของมนุษย์ | การดาวน์โหลด |
| บ่น | 653699 | en | MT | โคล | คอลเลกชันจาก Alpaca, Quora, Stackoverflow และคำถาม Medquad | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| HH-RLHF | 284517 | en | TS | ผสม | บทสนทนา | บทสนทนาระหว่างโมเดลมนุษย์และ RLHF | การดาวน์โหลด |
| OIG (ส่วน) | 49237 | en | MT | โคล | สร้างขึ้นจากงานต่าง ๆ เช่นคำถามและการตอบ | การใช้การเพิ่มข้อมูลการรวบรวมชุดข้อมูลคำอธิบายประกอบของมนุษย์ | การดาวน์โหลด |
| Gaokao | 2785 | ซีเอ็นเอ็น | MT | โคล | คำถามแบบปรนัยเติมเต็มและคำถามปลายเปิดจากการสอบ | คำอธิบายประกอบของมนุษย์ | การดาวน์โหลด |
| อูฐ | 760620 | en | MT | ศรี | บทสนทนาในการสวมบทบาทในสังคม AI, รหัส, คณิตศาสตร์, ฟิสิกส์, เคมี, ชีววิทยา | GPT-3.5-turbo | การดาวน์โหลด |
| คราม | พ.ศ. 1764800 | en | MT | โคล | 60 NLP งาน | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| coig (flaginstruct) | 298428 | ซีเอ็นเอ็น | MT | โคล | รวบรวมการสอบ fron, แปล, คำแนะนำการจัดแนวของมนุษย์และการสนทนาหลายรอบการแก้ไข | การใช้เครื่องมืออัตโนมัติและการตรวจสอบด้วยตนเอง | การดาวน์โหลด |
| gpt4tools | 71446 | en | MT | ศรี | ชุดคำแนะนำที่เกี่ยวข้องกับเครื่องมือ | GPT-3.5-turbo | การดาวน์โหลด |
| Sharechat | 1663241 | en | MT | ผสม | คำสั่งทั่วไป | crowdsourcing เพื่อรวบรวมการสนทนาระหว่างผู้คนและ CHATGPT (ShareGPT) | การดาวน์โหลด |
| เปลอัตโนมัติ | 5816 | en | MT | โคล | เลขคณิต, ทั่วไป, สัญลักษณ์และงานการใช้เหตุผลเชิงตรรกะอื่น ๆ | คอลเลกชันชุดข้อมูลบันทึกย่อของมนุษย์ | การดาวน์โหลด |
| มอส | 1583595 | en/cn | TS | ศรี | คำสั่งทั่วไป | Text-Davinci-003 | การดาวน์โหลด |
| มากที่สุด | 28247446 | en | คำถามเกี่ยวกับโลกการเขียนและการสร้างความช่วยเหลือเกี่ยวกับวัสดุที่มีอยู่ | GPT-3.5-turbo สองตัวแยกกัน | การดาวน์โหลด | ||
| แพทย์จีน | 792099 | ซีเอ็นเอ็น | TS | โคล | คำถามเกี่ยวกับคำแนะนำทางการแพทย์ | คลาน | การดาวน์โหลด |
| CSL | 396206 | ซีเอ็นเอ็น | MT | โคล | การสร้างข้อความกระดาษการสกัดคำหลักการสรุปข้อความและการจำแนกประเภทข้อความ | คลาน | การดาวน์โหลด |
| PCLUE | 1200705 | ซีเอ็นเอ็น | MT | โคล | คำสั่งทั่วไป | การดาวน์โหลด | |
| news_commentary | 252776 | ซีเอ็นเอ็น | TS | โคล | แปล | การดาวน์โหลด | |
| stackllama | สิ่งที่ต้องทำ | en |
คุณสามารถดาวน์โหลดข้อมูลที่จัดรูปแบบทั้งหมดได้ที่นี่ จากนั้นคุณควรใส่ไว้ในโฟลเดอร์ข้อมูล
คุณสามารถดาวน์โหลดจุดตรวจสอบทั้งหมดที่ผ่านการฝึกอบรมเกี่ยวกับข้อมูลคำสั่งประเภทต่าง ๆ จากที่นี่ จากนั้นหลังจากตั้งค่า LoRA_WEIGHTS (ใน generate.py ) ไปยังเส้นทางท้องถิ่นคุณสามารถเรียกใช้การอนุมานแบบจำลองได้โดยตรง
ข้อมูลทั้งหมดในคอลเลกชันของเราถูกจัดรูปแบบลงในเทมเพลตเดียวกันซึ่งแต่ละตัวอย่างมีดังนี้:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
โปรดทราบว่าสำหรับชุดข้อมูล COT ก่อนอื่นเราจะใช้เทมเพลตที่จัดทำโดย Flan เพื่อเปลี่ยนชุดข้อมูลต้นฉบับเป็นรูปแบบโซ่ของความคิดต่าง ๆ จากนั้นแปลงเป็นรูปแบบข้างต้น สคริปต์การจัดรูปแบบสามารถพบได้ที่นี่
pip install -r requirements.txt
โปรดทราบว่าตรวจสอบให้แน่ใจว่า Python> = 3.9 เมื่อ finetuning chatglm
คนอื่น ๆ
pip install -e ./peft
เพื่อให้นักวิจัยทำการวิจัย IFT อย่างเป็นระบบเกี่ยวกับ LLMS เราได้รวบรวมข้อมูลการเรียนการสอนประเภทต่าง ๆ รวม LLM หลายตัวและอินเทอร์เฟซแบบครบวงจรทำให้ง่ายต่อการปรับแต่งการจัดระเบียบที่ต้องการ:
--model_type : ตั้งค่า LLM ที่คุณต้องการใช้ ปัจจุบัน [Llama, Chatglm, Bloom, Moss] ได้รับการสนับสนุน สองหลังมีความสามารถของจีนที่แข็งแกร่งและ LLMS จะรวมเข้าด้วยกันในอนาคต--peft_type : ตั้งค่า peft ที่คุณต้องการใช้ ปัจจุบัน [LORA, Adalora, การปรับแต่งคำนำหน้า, การปรับจูน, PROMPT] ได้รับการสนับสนุน--data : ตั้งค่าประเภทข้อมูลที่ใช้สำหรับ IFT เพื่อปรับความยืดหยุ่นตามความสามารถในการปฏิบัติตามคำสั่งที่ต้องการ ตัวอย่างเช่นสำหรับความสามารถในการใช้เหตุผลที่แข็งแกร่งตั้งค่า "Alpaca-COT" เพื่อความสามารถของจีนที่แข็งแกร่งตั้ง "Belle1.5m" สำหรับการเข้ารหัสและความสามารถในการสร้างเรื่องราวตั้ง "GPT4ALL" และความสามารถในการตอบสนองทางการเงิน--model_name_or_path : นี่คือการตั้งค่าให้โหลดน้ำหนักรุ่นที่แตกต่างกันสำหรับ LLM เป้าหมาย --model_type ตัวอย่างเช่นในการโหลดน้ำหนัก 13B ของ Llama คุณสามารถตั้งค่า Decapoda-Research/Llama-13b-HFGPU เดี่ยว
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
หมายเหตุ: สำหรับชุดข้อมูลหลายชุดคุณสามารถใช้ --data LIKE --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
โปรดทราบว่า load_in_8bit ยังไม่เหมาะสำหรับ chatglm ดังนั้น batch_size จะต้องเล็กกว่าคนอื่น ๆ
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
โปรดทราบว่าคุณสามารถผ่านเส้นทางท้องถิ่น (ที่บันทึกน้ำหนัก LLM) ไปยัง --model_name_or_path และประเภทข้อมูล --data ข้อมูลสามารถตั้งค่าได้อย่างอิสระตามความสนใจของคุณ
GPU หลายตัว
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
โปรดทราบว่า load_in_8bit ยังไม่เหมาะสำหรับ chatglm ดังนั้น batch_size จะต้องเล็กกว่าคนอื่น ๆ
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
รายละเอียดเพิ่มเติมเกี่ยวกับการเรียนการสอนและการอนุมานสามารถพบได้ที่นี่ที่เราแก้ไขจาก โปรดทราบว่าโฟลเดอร์ saved-xxx7b เป็นเส้นทางที่ประหยัดสำหรับน้ำหนัก Lora และน้ำหนัก Llama จะถูกดาวน์โหลดโดยอัตโนมัติจากการกอดใบหน้า
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
บทความนี้เลือกมาตรฐานการประเมินสองประการคือ Belle-Eval และ MMCU เพื่อประเมินความสามารถของ LLM ในภาษาจีนอย่างครอบคลุม
Belle-Eval ถูกสร้างขึ้นโดย Instruct ด้วยตัวเองกับ ChatGPT ซึ่งมี 1,000 คำแนะนำที่หลากหลายที่เกี่ยวข้องกับ 10 หมวดหมู่ที่ครอบคลุมงาน NLP ทั่วไป (เช่น QA) และงานที่ท้าทาย (เช่นรหัสและคณิตศาสตร์) เราใช้ CHATGPT เพื่อให้คะแนนการตอบสนองแบบจำลองตามคำตอบสีทอง เกณฑ์มาตรฐานนี้ถือเป็นการประเมินความสามารถของ AGI
MMCU เป็นชุดของคำถามแบบปรนัยของจีนในสี่สาขาวิชาแพทย์, กฎหมาย, กฎหมาย, จิตวิทยาและการศึกษา (เช่นการสอบ Gaokao) ช่วยให้ LLMS ทำการสอบในสังคมมนุษย์ในลักษณะการทดสอบแบบปรนัยทำให้เหมาะสำหรับการประเมินความกว้างและความลึกของความรู้ของ LLMs ในหลายสาขาวิชา
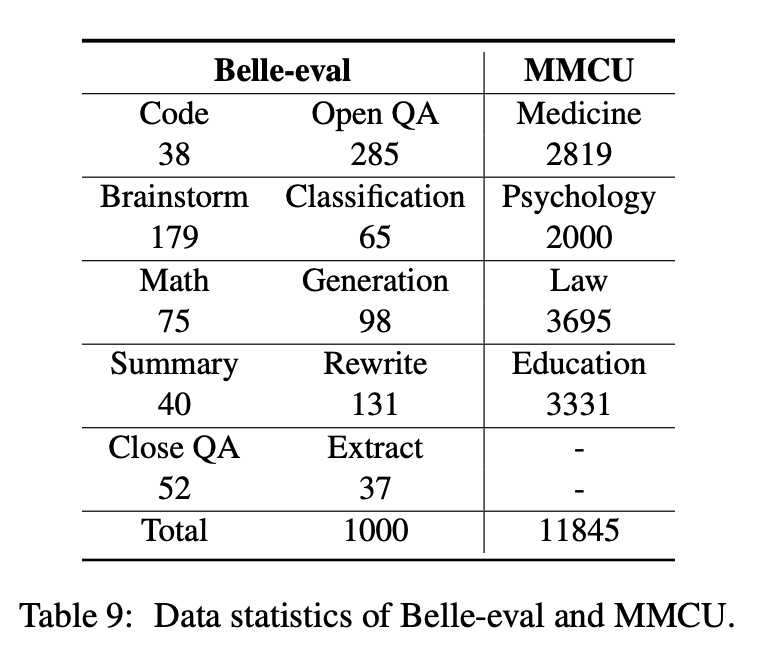
สถิติข้อมูลของ Belle-Eval และ MMCU แสดงในตารางด้านบน
เราทำการทดลองเพื่อศึกษาปัจจัยหลักสามประการในการปรับแต่ง LLMS: ฐาน LLM, วิธีการที่มีประสิทธิภาพพารามิเตอร์, ชุดข้อมูลการสอนภาษาจีน
สำหรับ Open LLMS เราทดสอบ LLMS ที่มีอยู่และ LLMs ปรับด้วย LORA บน AlpACA-GPT4 บน Belle-Eval และ MMCU ตามลำดับ
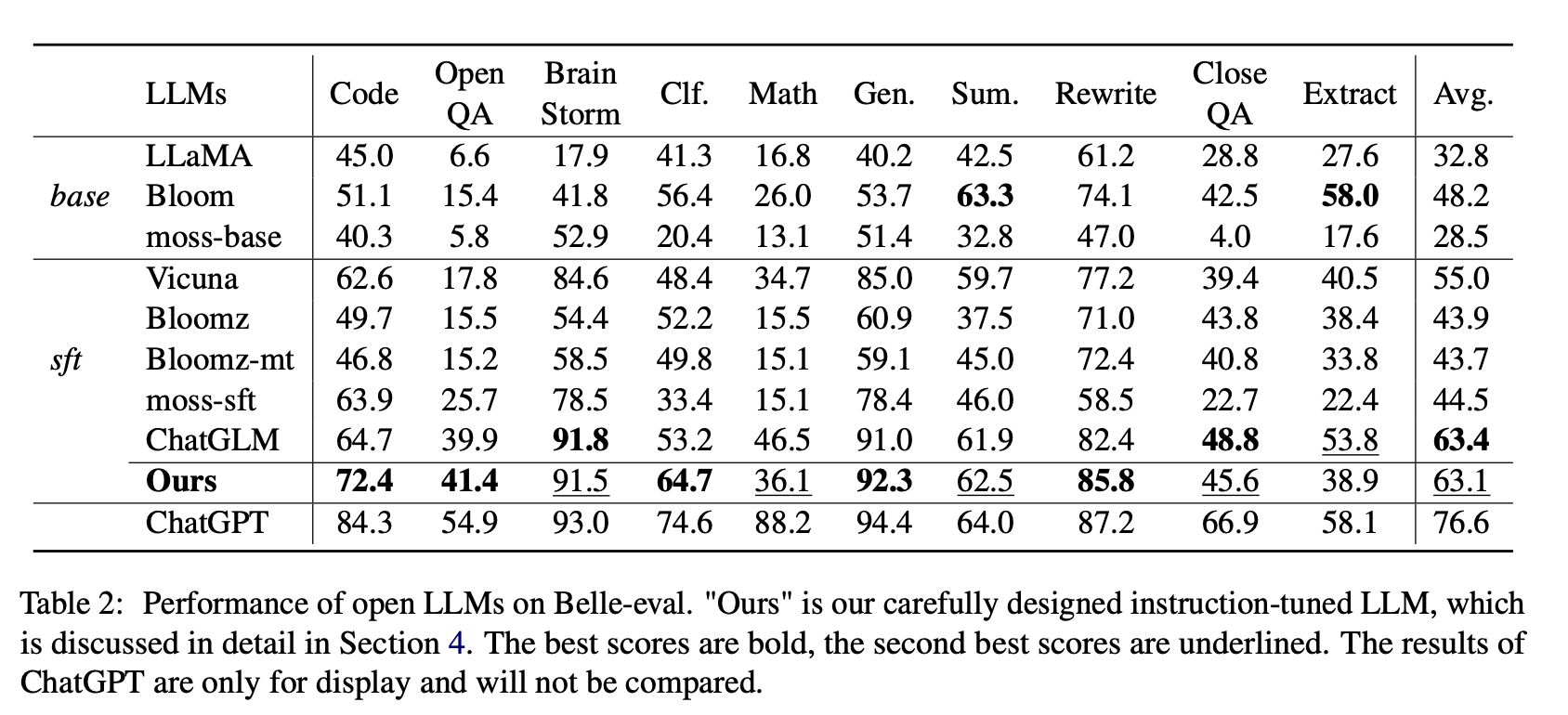
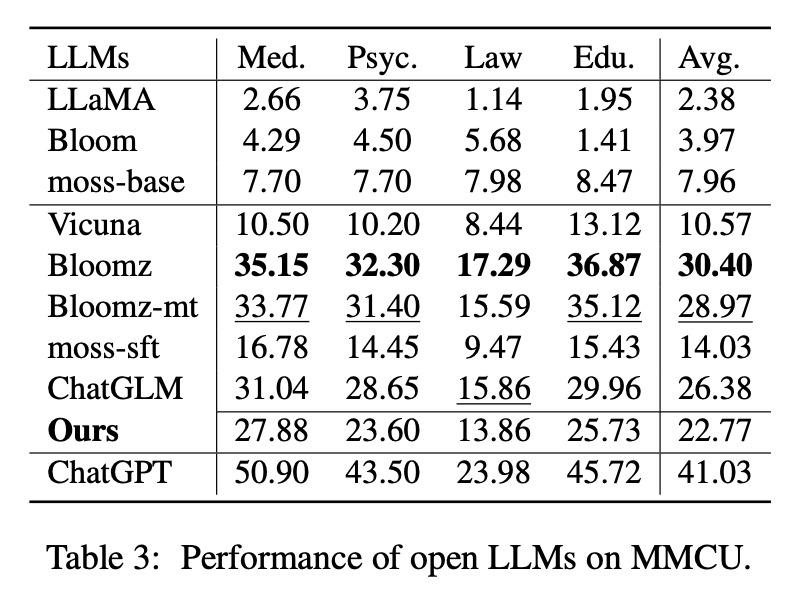
ตารางที่ 2 แสดงคะแนนของ LLM แบบเปิดบน Belle-Eval ตารางที่ 3 แสดงความถูกต้องของ LLMs บน MMCU พวกเขาปรับแต่ง LLM แบบเปิดทั้งหมดด้วยวิธีที่ประหยัดพารามิเตอร์ LORA และชุดข้อมูลคำสั่งเดียวกัน Alpaca-GPT4
ผลการทดลอง:
การประเมิน LLM ที่มีอยู่
ประสิทธิภาพของ Belle-Eval
(1) สำหรับฐาน LLMS Bloom ทำงานได้ดีที่สุด
(2) สำหรับ SFT LLMS chatglm มีประสิทธิภาพสูงกว่าคนอื่น ๆ ด้วยอัตรากำไรขั้นต้นขนาดใหญ่ด้วยความจริงที่ว่ามันได้รับการฝึกฝนด้วยโทเค็นภาษาจีนและ HFRL ส่วนใหญ่
(3) หมวดหมู่ QA, คณิตศาสตร์, closeqa และสารสกัดยังคงเป็นสิ่งที่ท้าทายมากสำหรับ LLM แบบเปิดที่มีอยู่
(4) Vicuna และ Moss-SFT มีการปรับปรุงที่ชัดเจนเมื่อเทียบกับฐานของพวกเขา Llama และ Moss-base ตามลำดับ
(5) ในทางตรงกันข้ามประสิทธิภาพของโมเดล SFT, Bloomz และ Bloomz-MT ลดลงเมื่อเทียบกับแบบจำลองพื้นฐานที่บานเพราะพวกเขามักจะสร้างการตอบสนองที่สั้นลง
ประสิทธิภาพของ MMCU
(1) ฐาน LLM ทั้งหมดทำงานได้ไม่ดีเพราะเกือบจะยากที่จะสร้างเนื้อหาในรูปแบบที่ระบุก่อนการปรับแต่งเช่นหมายเลขตัวเลือกการส่งออก
(2) SFT LLM ทั้งหมดมีประสิทธิภาพสูงกว่าฐาน LLMS ที่สอดคล้องกันตามลำดับ โดยเฉพาะอย่างยิ่ง Bloomz ดำเนินการที่ดีที่สุด (แม้กระทั่ง Beats Chatglm) เพราะสามารถสร้างหมายเลขตัวเลือกได้โดยตรงตามที่ต้องการโดยไม่ต้องสร้างเนื้อหาที่ไม่เกี่ยวข้องอื่น ๆ ซึ่งเป็นผลมาจากลักษณะข้อมูลของชุดข้อมูลการปรับแต่งการปรับแต่ง xp3
(3) ในสี่สาขาวิชากฎหมายเป็นสิ่งที่ท้าทายที่สุดสำหรับ LLMS
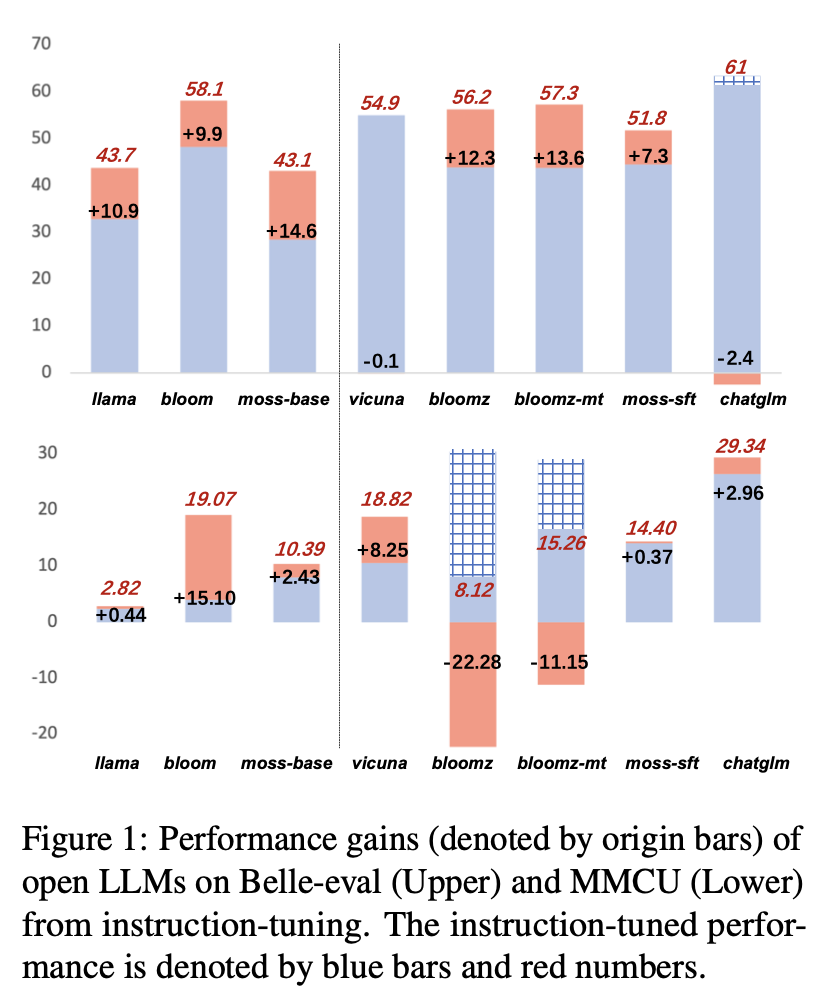
ผลการปฏิบัติงานของ LLMS หลังจากการปรับแต่งคำสั่งบน AlpACA-GPT4-ZH แสดงในรูปที่ 1
คำสั่งปรับ LLMS ที่แตกต่างกัน
(1) ใน Belle-Eval การปรับปรุงประสิทธิภาพของ SFT LLM ที่นำมาจากการปรับแต่งการเรียนการสอนนั้นไม่สำคัญเท่ากับฐาน LLMS ยกเว้น SFT Bloomz และ Bloomz-MT
(2) Vicuna และ Chatglm พบประสิทธิภาพลดลงหลังจากการปรับแต่งการเรียนการสอนเนื่องจาก Vicuna ได้รับการฝึกฝนจากการสนทนาที่แท้จริงของมนุษย์-Chatgpt ด้วยคุณภาพที่ดีกว่า Alpaca-GPT4 chatglm ใช้ HFRL ซึ่งอาจไม่เหมาะสำหรับการปรับแต่งคำสั่งเพิ่มเติมอีกต่อไป
(3) บน MMCU LLM ส่วนใหญ่จะได้รับประสิทธิภาพเพิ่มขึ้นหลังจากการปรับแต่งคำสั่งยกเว้น Bloomz และ Bloomz-MT ซึ่งลดประสิทธิภาพลงอย่างไม่คาดคิด
(4) หลังจากการปรับแต่งการเรียนการสอน Bloom มีการปรับปรุงที่สำคัญและทำงานได้ดีทั้งสองมาตรฐาน แม้ว่า chatglm จะบดบังอย่างต่อเนื่อง แต่มันก็ลดลงประสิทธิภาพการทำงานในระหว่างการปรับแต่ง ดังนั้นในบรรดา LLM แบบเปิดทั้งหมด Bloom จึงเหมาะสมที่สุดในฐานะแบบจำลองพื้นฐานในการทดลองครั้งต่อไปสำหรับการสำรวจการปรับแต่งการสอนภาษาจีน
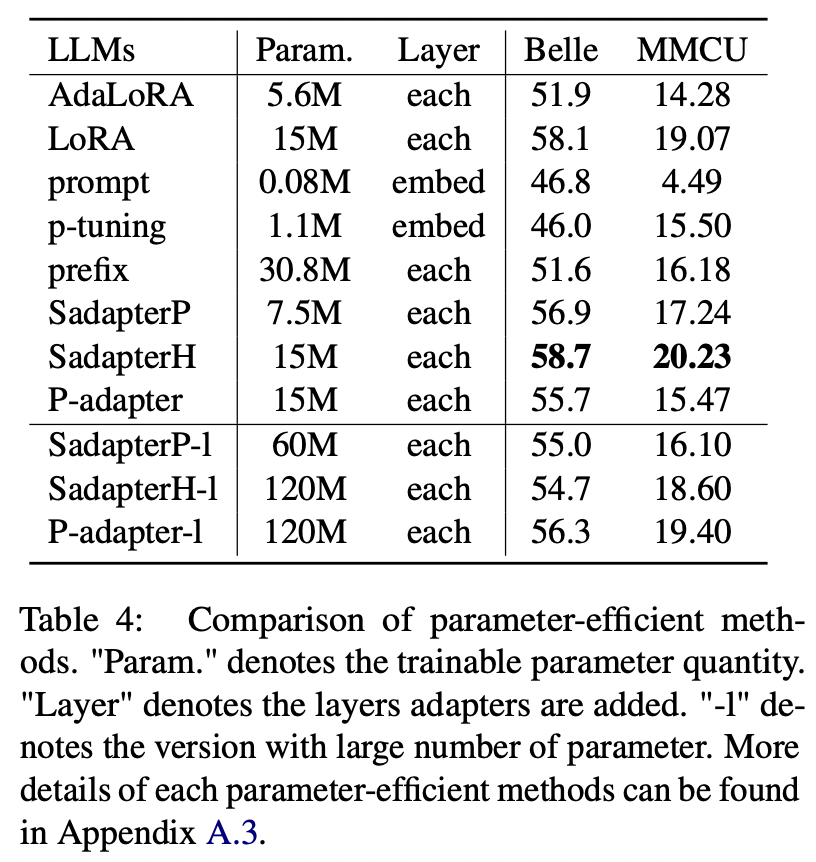
สำหรับวิธีการที่มีประสิทธิภาพพารามิเตอร์นอกเหนือจาก LORA กระดาษจะรวบรวมช่วงของวิธีการที่ประหยัดพารามิเตอร์ในการปรับแต่งคำสั่ง Bloom บนชุดข้อมูล AlpACA-GPT4
ผลการทดลอง:
การเปรียบเทียบวิธีการที่มีประสิทธิภาพพารามิเตอร์
(1) Sadapterh ทำงานได้ดีที่สุดในวิธีการที่มีประสิทธิภาพพารามิเตอร์ทั้งหมดซึ่งสามารถใช้เป็นทางเลือกแทน LORA
(2) การปรับจูนและการปรับจูนต่ำกว่าผู้อื่นด้วยระยะขอบขนาดใหญ่แสดงให้เห็นว่าการเพิ่มเลเยอร์ที่สามารถฝึกอบรมได้ในเลเยอร์การฝังนั้นไม่เพียงพอที่จะรองรับ LLMs สำหรับงานสร้าง
(3) แม้ว่า Adalora จะเป็นการปรับปรุง LORA แต่ประสิทธิภาพของมันก็มีการลดลงอย่างชัดเจนอาจเป็นเพราะพารามิเตอร์ที่สามารถฝึกอบรมได้ของ LORA สำหรับ LLMS ไม่เหมาะสำหรับการลดลงต่อไป
(4) การเปรียบเทียบส่วนบนและส่วนล่างจะเห็นได้ว่าการเพิ่มจำนวนพารามิเตอร์ที่สามารถฝึกอบรมได้สำหรับอะแดปเตอร์ต่อเนื่อง (เช่น SADAPTERP และ SADAPTERH) ไม่ได้นำมาซึ่งกำไรในขณะที่ปรากฏการณ์ตรงกันข้ามสำหรับอะแดปเตอร์คู่ขนาน
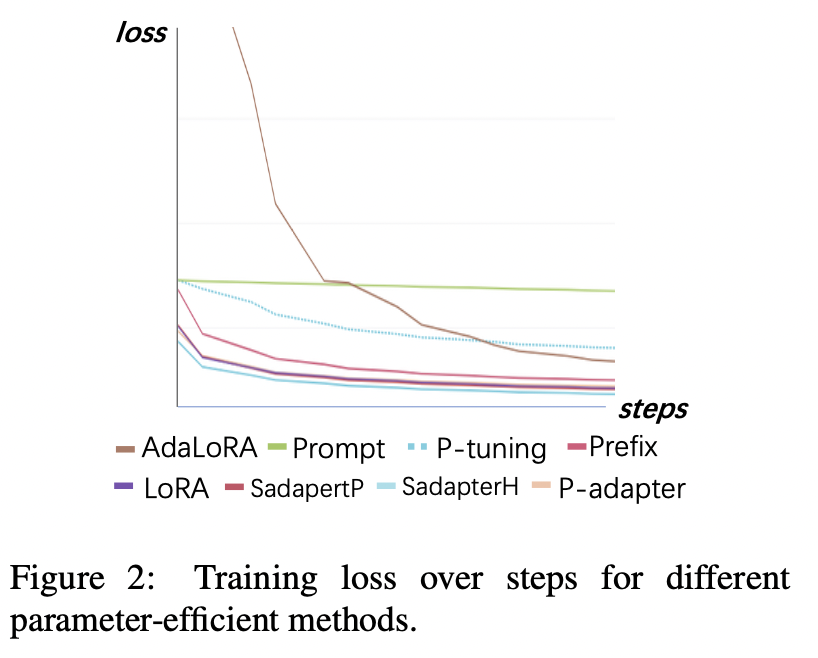
การสูญเสียการฝึกอบรม
(1) การปรับจูนและการปรับจูนมาบรรจบกันช้าที่สุดและมีการสูญเสียสูงสุดหลังจากการบรรจบกัน นี่แสดงให้เห็นว่าอะแดปเตอร์แบบฝังอย่างเดียวไม่เหมาะสำหรับการปรับแต่ง LLMS
(2) การสูญเสียครั้งแรกของ Adalora นั้นสูงมากเนื่องจากต้องใช้การเรียนรู้พร้อมกันของการจัดสรรงบประมาณพารามิเตอร์พร้อมกันซึ่งทำให้แบบจำลองไม่สามารถปรับข้อมูลการฝึกอบรมได้ดี
(3) วิธีอื่น ๆ สามารถมาบรรจบกันอย่างรวดเร็วในข้อมูลการฝึกอบรมและปรับให้เข้ากันได้ดี
สำหรับผลกระทบของชุดข้อมูลการเรียนการสอนภาษาจีนประเภทต่างๆผู้เขียนจะรวบรวมคำแนะนำภาษาจีนแบบเปิดที่ได้รับความนิยม (ดังแสดงในตารางที่ 5) เพื่อปรับแต่งการปรับแต่งด้วย LORA
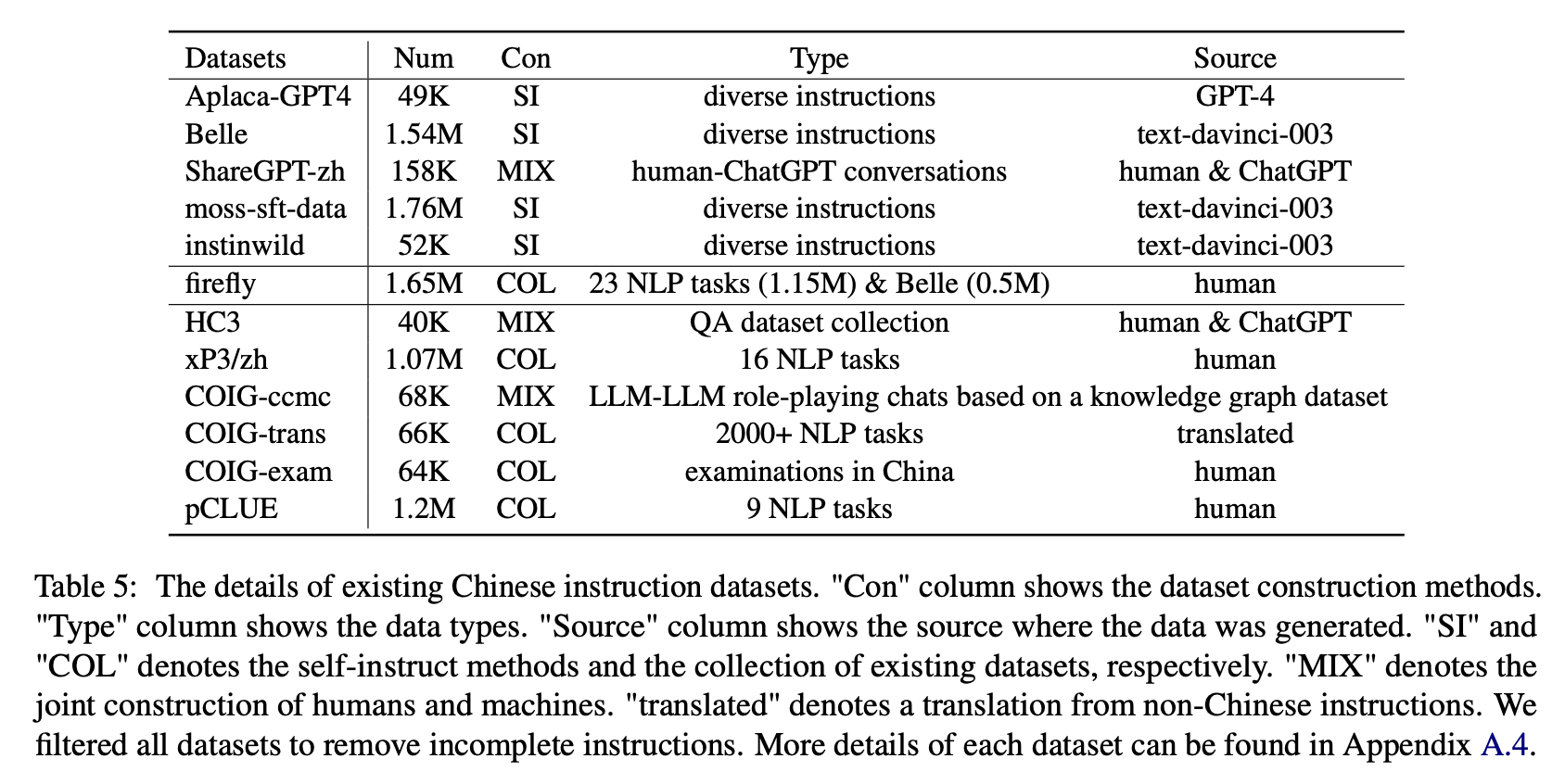
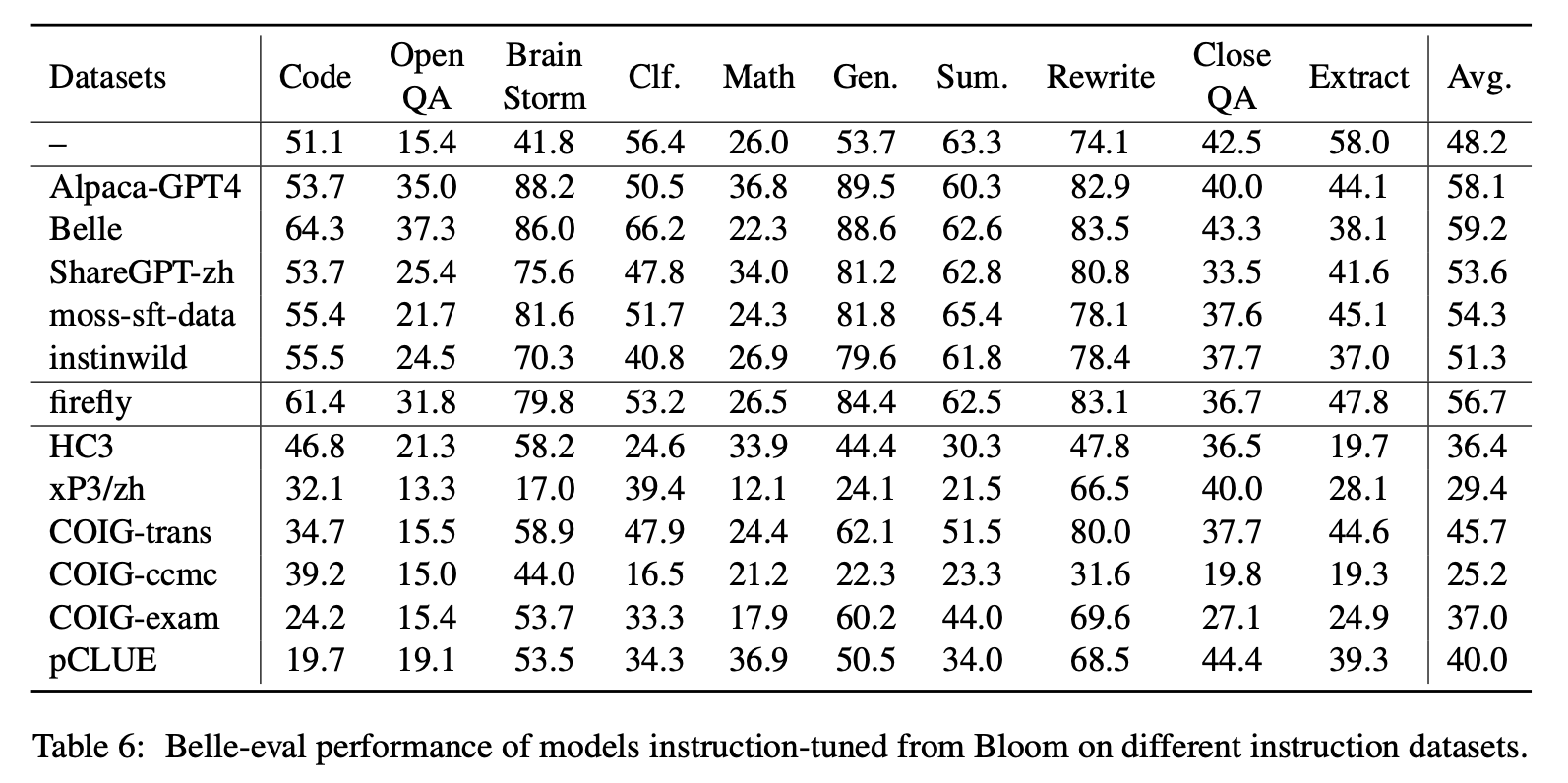
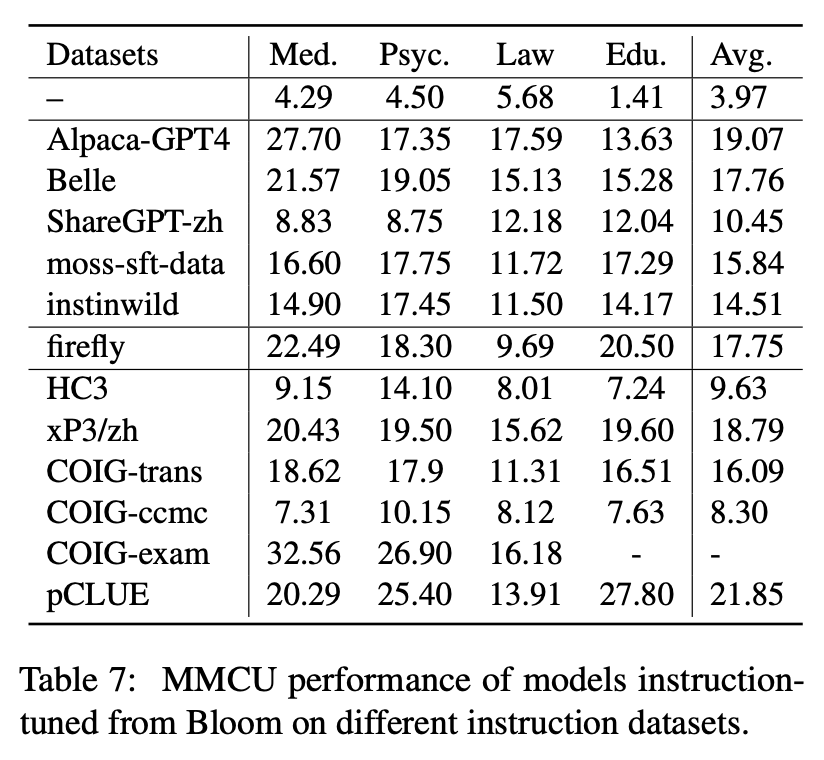
ตารางที่ 6 และตารางที่ 7 แสดงการปรับแต่งของ Bloom ในชุดข้อมูลคำสั่งที่แตกต่างกัน
ผลการทดลอง:
ประสิทธิภาพของ Belle-Eval
(1) ข้อมูลคำสั่งที่สร้างขึ้นโดย chatgpt (เช่นการใช้วิธีการสอนตนเองหรือรวบรวมการสนทนาของมนุษย์-แชทจีต์จริง) ช่วยเพิ่มความสามารถในการติดตามคำสั่งด้วยคะแนน 3.1 ∼ 11 จุด
(2) ในชุดข้อมูลเหล่านี้เบลล์มีประสิทธิภาพที่ดีที่สุดเนื่องจากข้อมูลการเรียนการสอนจำนวนมากที่สุด อย่างไรก็ตามประสิทธิภาพของโมเดลที่ได้รับการฝึกฝนเกี่ยวกับ Moss-SFT-Data ซึ่งมีข้อมูลเพิ่มเติมที่สร้างขึ้นในลักษณะเดียวกันนั้นไม่น่าพอใจ
(3) ประสิทธิภาพที่นำโดยคำแนะนำ Alpaca-GPT4 นั้นดีที่สุดเป็นอันดับสองโดยมีเพียง 49K เท่านั้นที่เทียบเคียงได้กับ 1.54M Belle
(4) Instinwild นำประสิทธิภาพการทำงานน้อยที่สุดมาให้พวกเขาเพราะคำแนะนำของเมล็ดมันรวบรวมข้อมูลจากทวีต ("in Wild") ไม่ครอบคลุมเท่าที่มนุษย์ออกแบบมาอย่างระมัดระวัง
(5) ข้อมูลที่ใช้ CHATGPT เหล่านี้ส่วนใหญ่มีผลการปรับปรุงอย่างมีนัยสำคัญต่องานรุ่นเปิดเช่นพายุสมองและรุ่นในขณะที่มีการลดลงอย่างมีนัยสำคัญในงานที่ต้องใช้ทักษะความเข้าใจในการอ่านสูงเช่น QA และสารสกัดอย่างใกล้ชิด
(6) ชุดข้อมูลคำสั่งเหล่านี้ทำให้เกิดความเสียหายต่อความสามารถในการติดตามคำสั่งของโมเดลเนื่องจากรูปแบบและความตั้งใจของชุดข้อมูล NLP หรือชุดตรวจสอบแต่ละชุดนั้นรวมกันซึ่งสามารถใช้งานได้ง่ายเกินไป
(7) ในหมู่พวกเขา Coig-Trans ทำงานได้ดีที่สุดเพราะเกี่ยวข้องกับงานที่แตกต่างกันมากกว่า 2,000 รายการพร้อมคำแนะนำงานที่หลากหลาย ในทางตรงกันข้าม XP3 และ COIG-CCMC มีผลกระทบด้านลบที่เลวร้ายที่สุดต่อประสิทธิภาพของโมเดล ทั้งคู่ครอบคลุมงานเพียงไม่กี่ประเภท (การแปลและ QA สำหรับการสนทนาการแก้ไขแบบต่อต้านในอดีต) ซึ่งแทบจะไม่ครอบคลุมคำแนะนำและงานที่ได้รับความนิยมสำหรับมนุษย์
ประสิทธิภาพของ MMCU
(1) การปรับแต่งคำสั่งในแต่ละชุดข้อมูลสามารถส่งผลให้ประสิทธิภาพการปรับปรุงประสิทธิภาพเสมอ
(2) ท่ามกลางข้อมูลที่ใช้ CHATGPT ที่แสดงในส่วนบน ShareGPT-ZH ต่ำกว่าผู้อื่นด้วยอัตรากำไรขั้นต้นขนาดใหญ่ นี่อาจเป็นเพราะความจริงที่ว่าผู้ใช้จริงไม่ค่อยถามคำถามแบบปรนัยเกี่ยวกับหัวข้อทางวิชาการ
(3) ในบรรดาข้อมูลการรวบรวมชุดข้อมูลที่แสดงในส่วนล่าง HC3 และ COIG-CCMC ส่งผลให้เกิดความแม่นยำต่ำสุดเนื่องจากคำถามที่ไม่ซ้ำกันของ HC3 นั้นมีเพียง 13K และรูปแบบงานของ COIG-CCMC นั้นแตกต่างจาก MMCU อย่างมาก
(4) Coig-Exam นำการปรับปรุงความแม่นยำมากที่สุดได้รับประโยชน์จากรูปแบบงานที่คล้ายกันกับ MMCU
อีกสี่ปัจจัย: COT, การขยายคำศัพท์ภาษาจีน, ภาษาของการแจ้งเตือนและการจัดแนวของมนุษย์
สำหรับ COT ผู้เขียนเปรียบเทียบประสิทธิภาพก่อนและหลังการเพิ่มข้อมูล COT ในระหว่างการปรับแต่งคำสั่ง
การตั้งค่าการทดลอง:
เรารวบรวมชุดข้อมูล COT 9 ชุดและพรอมต์จาก Flan จากนั้นแปลเป็นภาษาจีนโดยใช้ Google Translate พวกเขาเปรียบเทียบประสิทธิภาพก่อนและหลังการเพิ่มข้อมูล COT ในระหว่างการปรับแต่งคำสั่ง
ก่อนอื่นให้ทราบวิธีเพิ่มข้อมูล COT เป็น "Alpaca-GPT4+COT" นอกจากนี้เพิ่มประโยค "先思考, 再决定再决定" ("คิดทีละขั้นตอน" ในภาษาจีน) ในตอนท้ายของคำสั่งแต่ละคำสั่งเพื่อชักนำให้โมเดลตอบสนองต่อคำแนะนำตาม COT และติดฉลากด้วยวิธีนี้ว่า "Alpaca-GPT4+COT*"
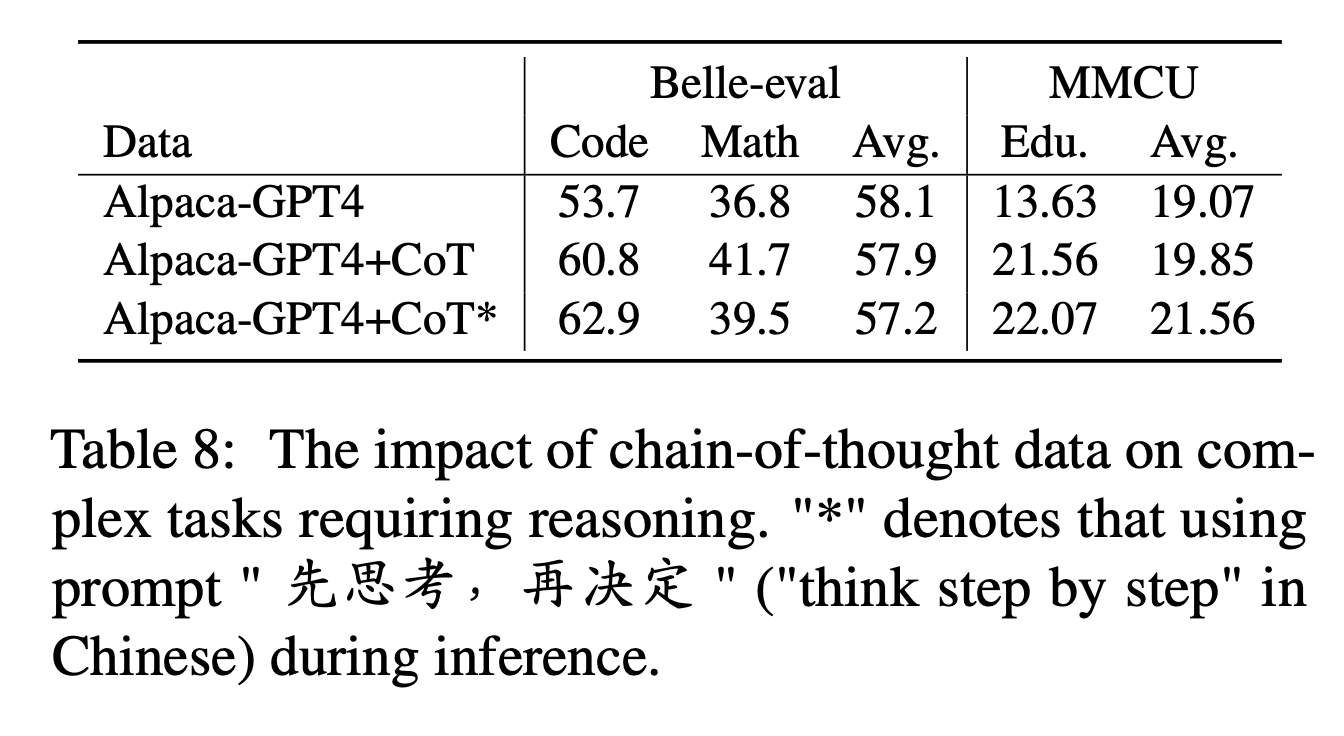
ผลการทดลอง:
"ALPACA-GPT4+COT" ดีกว่า "AlpACA-GPT4" ในรหัสและงานคณิตศาสตร์ที่ต้องใช้ความสามารถในการใช้เหตุผลที่แข็งแกร่ง นอกจากนี้ยังมีการปรับปรุงที่สำคัญในงานการศึกษา MMCU
ดังที่แสดงในบรรทัดของ "Alpaca-GPT4+COT*" ประโยคง่ายๆสามารถปรับปรุงประสิทธิภาพของรหัสการใช้เหตุผลและการศึกษาในขณะที่ประสิทธิภาพทางคณิตศาสตร์ต่ำกว่า "AlpACA-GPT4+COT" เล็กน้อย สิ่งนี้อาจต้องมีการสำรวจเพิ่มเติมเกี่ยวกับพรอมต์ที่แข็งแกร่งมากขึ้น
สำหรับการขยายคำศัพท์ภาษาจีนผู้เขียนทดสอบอิทธิพลของจำนวนโทเค็นจีนในคำศัพท์ของโทเคนิเซอร์ต่อความสามารถของ LLMS ในการแสดงภาษาจีน ตัวอย่างเช่นหากตัวละครภาษาจีนอยู่ในคำศัพท์ก็สามารถแสดงได้ด้วยโทเค็นเดียวมิฉะนั้นอาจต้องใช้โทเค็นหลายตัวเพื่อแสดง
การตั้งค่าการทดลอง: ผู้เขียนส่วนใหญ่ทำการทดลองเกี่ยวกับ Llama ซึ่งใช้ประโยคชิ้น (ขนาดคำศัพท์ 32K ของตัวละครจีน) ครอบคลุมตัวละครจีนน้อยกว่าบลูม (250K)
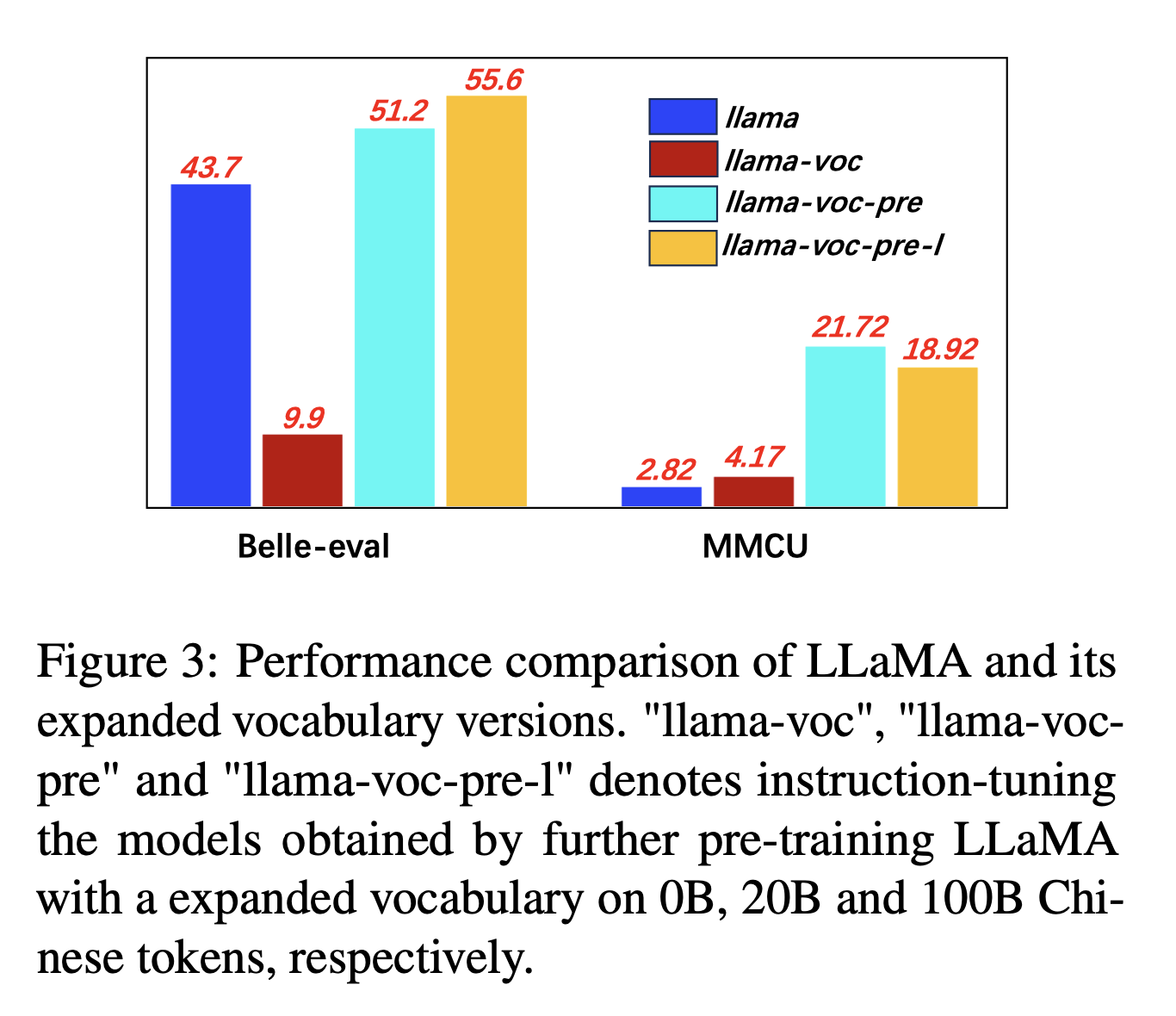
ผลการทดลอง:
การฝึกอบรมล่วงหน้าเกี่ยวกับคลังภาษาจีนที่มีการขยายตัวของคำศัพท์ภาษาจีนมีประโยชน์อย่างต่อเนื่องสำหรับความสามารถในการติดตามคำสั่ง
และ "LLAMA-VOC-PRE-L" (100B) นั้นด้อยกว่า "LLAMA-VOC-PRE" (20B) ใน MMCU ซึ่งแสดงให้เห็นว่าการฝึกอบรมก่อนการฝึกอบรมเพิ่มเติมอาจไม่จำเป็นต้องนำไปสู่ประสิทธิภาพที่สูงขึ้นสำหรับการสอบวิชาการ
สำหรับภาษาของพรอมต์ผู้เขียนทดสอบความเหมาะสมของการปรับแต่งการเรียนการสอนสำหรับการใช้พรอมต์ภาษาจีน
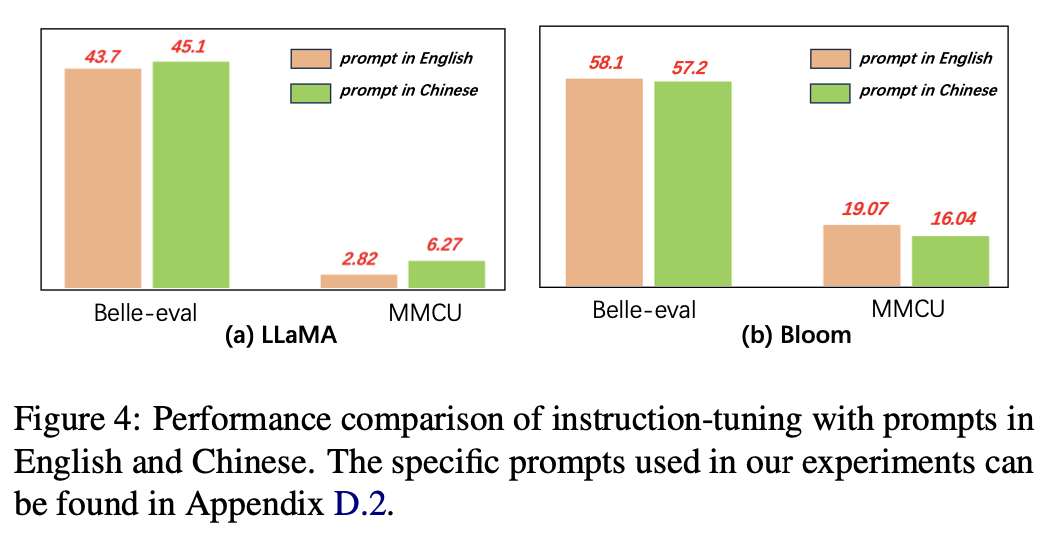
รูปที่ 4 แสดงผลลัพธ์ของการใช้พรอมต์ภาษาจีนและภาษาอังกฤษตาม Llama และ Bloom เมื่อ Llama การปรับแต่งการเรียนการสอนการใช้พรอมต์ภาษาจีนสามารถปรับปรุงประสิทธิภาพการทำงานของมาตรฐานทั้งสองเมื่อเทียบกับพรอมต์ภาษาอังกฤษในขณะที่ปรากฏการณ์ตรงกันข้ามสามารถสังเกตได้
ผลการทดลอง:
สำหรับแบบจำลองที่มีความสามารถของจีนที่อ่อนแอกว่า (เช่น Llama) การใช้พรอมต์จีนสามารถช่วยตอบสนองเป็นภาษาจีนได้อย่างมีประสิทธิภาพ
สำหรับนางแบบที่มีความสามารถของจีนที่ดี (เช่น Bloom) โดยใช้พรอมต์เป็นภาษาอังกฤษ (ภาษาที่ดีกว่า) สามารถแนะนำรูปแบบให้เข้าใจกระบวนการปรับแต่งด้วยคำแนะนำได้ดีขึ้น
เพื่อหลีกเลี่ยง LLMs ที่สร้างเนื้อหาที่เป็นพิษการจัดแนวพวกเขาให้สอดคล้องกับค่านิยมของมนุษย์เป็นปัญหาที่สำคัญ เราเพิ่มข้อมูลการจัดตำแหน่งของมนุษย์ที่สร้างโดย Coig ลงในการปรับแต่งเพื่อสำรวจผลกระทบ
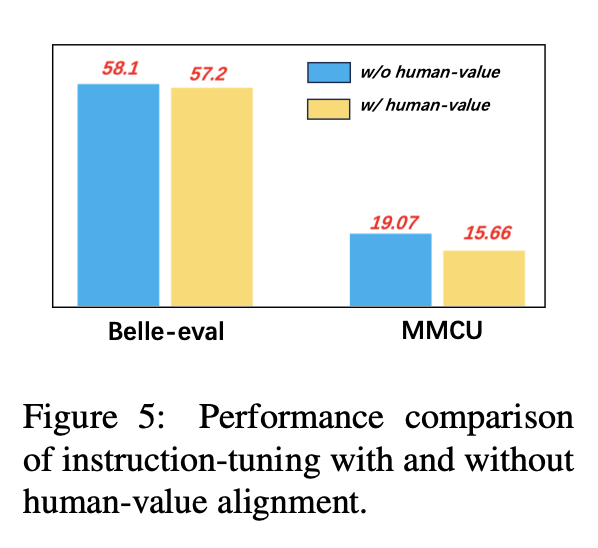
รูปที่ 5 เปรียบเทียบผลลัพธ์ของการปรับแต่งการเรียนการสอนที่มีและไม่มีการจัดแนวของมนุษย์
ผลการทดลอง: การจัดตำแหน่งของค่ามนุษย์ส่งผลให้ประสิทธิภาพลดลงเล็กน้อย วิธีการสร้างสมดุลระหว่างความไม่เป็นอันตรายและประสิทธิภาพของ LLMS เป็นทิศทางการวิจัยที่ควรค่าแก่การสำรวจในอนาคต
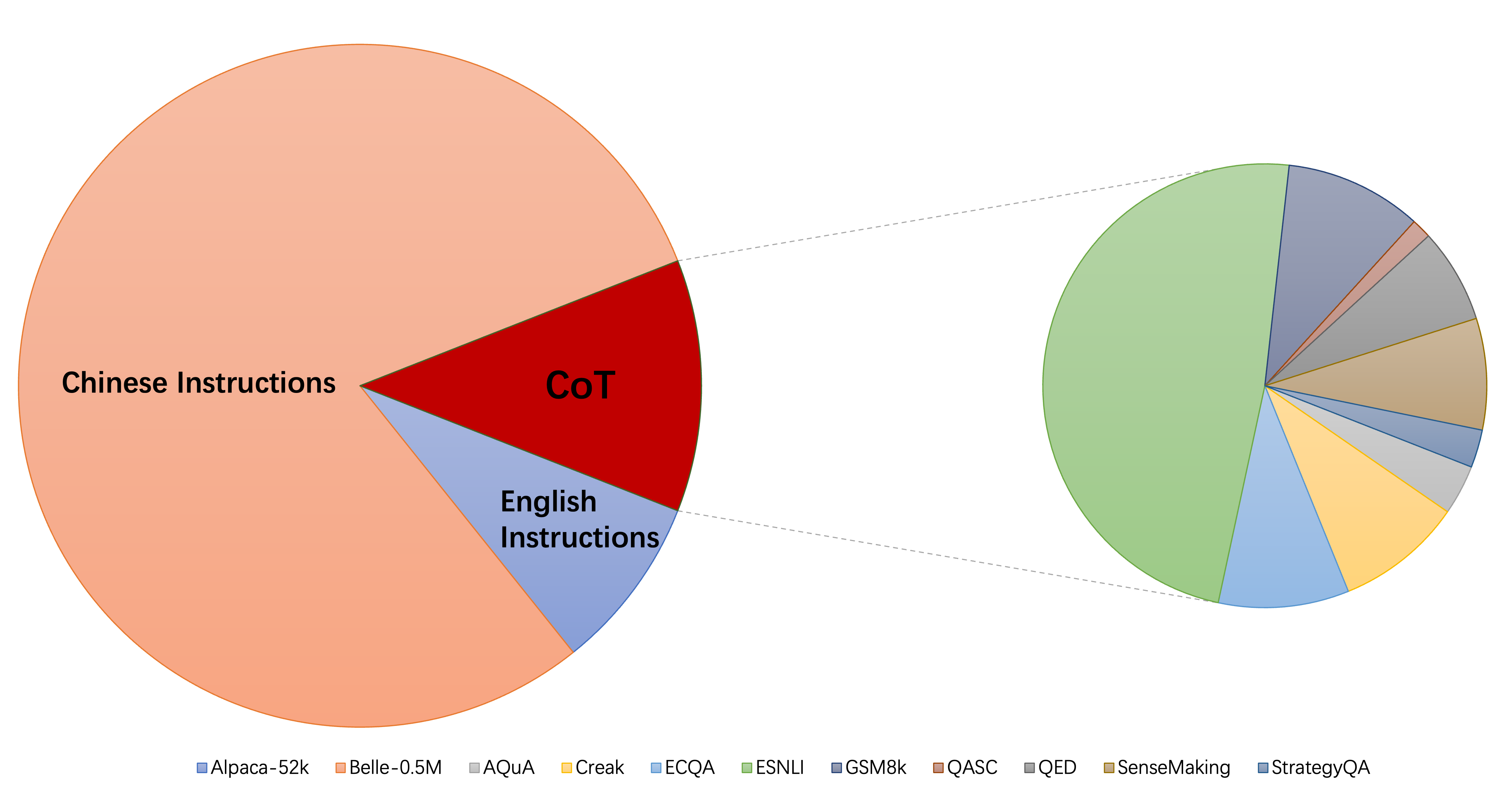 คอลเลกชันปัจจุบันของชุดข้อมูลการเรียนการสอนการเรียนการสอนประกอบด้วยส่วนใหญ่สามส่วน:
คอลเลกชันปัจจุบันของชุดข้อมูลการเรียนการสอนการเรียนการสอนประกอบด้วยส่วนใหญ่สามส่วน:
alpaca_data_cleaned.json : ตัวอย่างการฝึกอบรมการเรียนการสอนภาษาอังกฤษประมาณ 52KCoT_data.json : 9 ชุดข้อมูล COT ที่เกี่ยวข้องกับตัวอย่างประมาณ 75K (เผยแพร่โดย Flan [7])belle_data_cn.json : ประมาณ 0.5M ภาษาจีน | ตัวอย่างการฝึกอบรมตามคำแนะนำ (เผยแพร่โดย Belle [8]) "w/o cot" และ "w/o cn" แสดงถึงโมเดลที่ไม่รวมข้อมูล COT และคำแนะนำภาษาจีนจากข้อมูลคำสั่ง finetuning ตามลำดับ
"w/o cot" และ "w/o cn" แสดงถึงโมเดลที่ไม่รวมข้อมูล COT และคำแนะนำภาษาจีนจากข้อมูลคำสั่ง finetuning ตามลำดับ
ตารางข้างต้นแสดงตัวอย่างสองตัวอย่าง (เกี่ยวข้องกับการคำนวณเชิงตัวเลข) ที่ต้องใช้ความสามารถในการใช้เหตุผลในการตอบสนองอย่างถูกต้อง ดังที่แสดงในคอลัมน์กลาง Ours w/o CoT ล้มเหลวในการสร้างการตอบสนองที่ถูกต้องซึ่งแสดงให้เห็นว่าเมื่อข้อมูล finetuning ไม่มีข้อมูล COT ความสามารถในการให้เหตุผลของโมเดลจะลดลงอย่างมีนัยสำคัญ สิ่งนี้แสดงให้เห็นว่าข้อมูล COT เป็นสิ่งจำเป็นสำหรับรุ่น LLM

ตารางด้านบนแสดงสองตัวอย่างที่ต้องการความสามารถในการตอบสนองต่อคำแนะนำภาษาจีน ดังที่แสดงในคอลัมน์ด้านขวาไม่ว่าจะเป็นเนื้อหาที่สร้างขึ้นของ Ours w/o CN ไม่มีเหตุผลหรือคำแนะนำภาษาจีนจะได้รับคำตอบเป็นภาษาอังกฤษโดย Ours w/o CN สิ่งนี้แสดงให้เห็นว่าการลบข้อมูลภาษาจีนในระหว่างการ finetuning จะทำให้แบบจำลองไม่สามารถจัดการกับคำแนะนำของจีนและแสดงให้เห็นถึงความจำเป็นในการรวบรวมข้อมูลการสอนภาษาจีน

ตารางข้างต้นแสดงตัวอย่างที่ค่อนข้างยากซึ่งต้องการทั้งการสะสมความรู้เกี่ยวกับประวัติศาสตร์จีนและความสามารถเชิงตรรกะและสมบูรณ์ในการระบุเหตุการณ์ทางประวัติศาสตร์ ดังที่แสดงในตารางนี้ Ours w/o CN สามารถสร้างการตอบสนองสั้น ๆ และผิดพลาดได้เนื่องจากการขาดข้อมูลการจัดสรร Finetuning จีนความรู้ที่สอดคล้องกันของประวัติศาสตร์จีนจึงขาดหายไปตามธรรมชาติ แม้ว่า Ours w/o CoT ตรรกะของการแสดงออกของมันคือความขัดแย้งในตนเองซึ่งเกิดจากการขาดข้อมูล COT -
โดยสรุปโมเดลที่ได้รับการคัดค้านจากชุดข้อมูลที่สมบูรณ์ของเรา (ข้อมูลการเรียนการสอนภาษาอังกฤษจีนและ COT) สามารถปรับปรุงการใช้เหตุผลแบบจำลองและการเรียนการสอนภาษาจีนได้อย่างมีนัยสำคัญตามความสามารถ
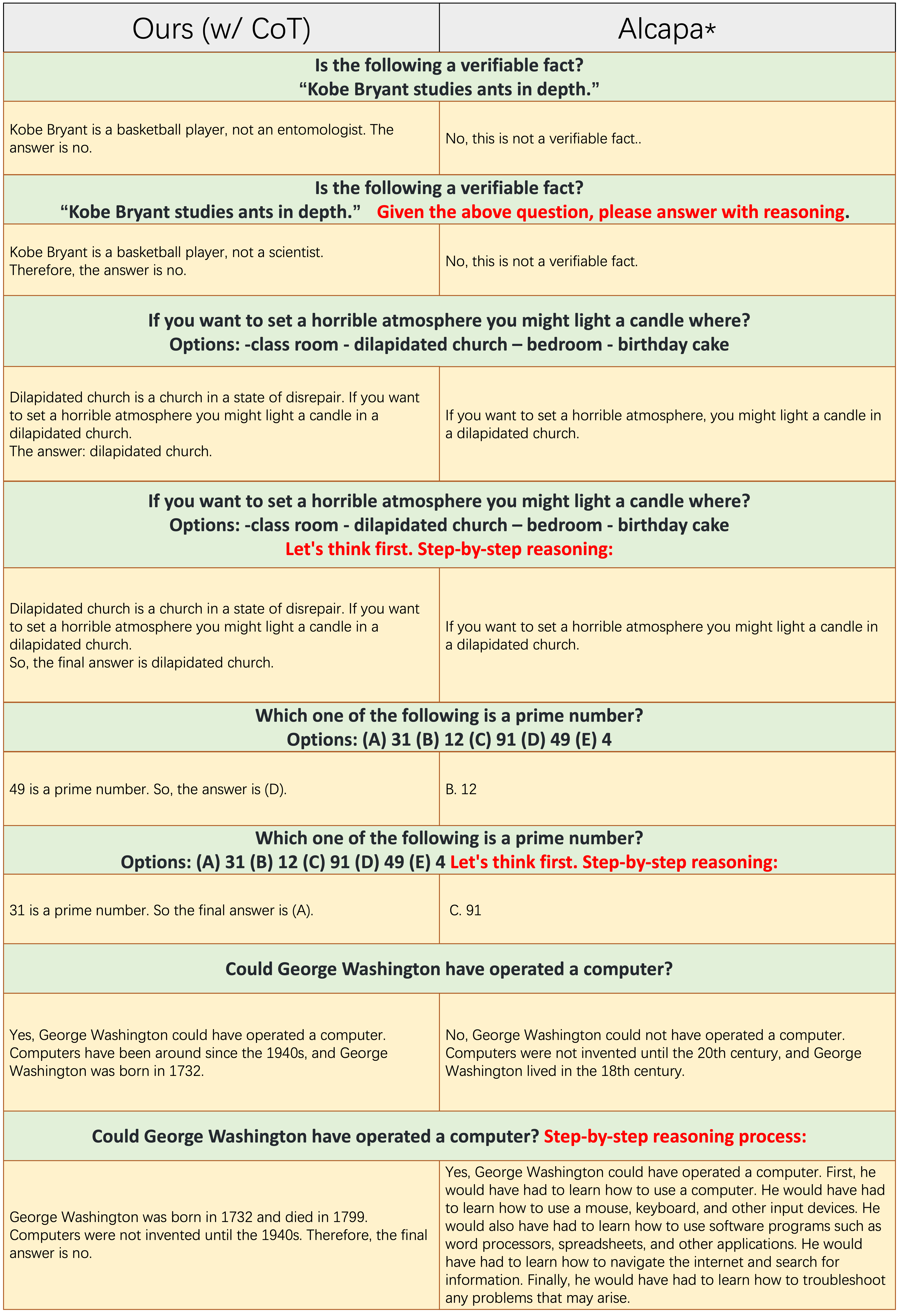 ตัวอย่างของแต่ละแถวคี่ไม่ได้ใช้พรอมต์ COT เช่น "การใช้เหตุผลทีละขั้นตอน" ทั้ง
ตัวอย่างของแต่ละแถวคี่ไม่ได้ใช้พรอมต์ COT เช่น "การใช้เหตุผลทีละขั้นตอน" ทั้ง Ours(w/CoT) และ Alpaca ขึ้นอยู่กับ LLAMA-7B และความแตกต่างเพียงอย่างเดียวระหว่างพวกเขาสองคือข้อมูลการเรียนการสอนของ Ours(w/CoT) มีข้อมูล COT พิเศษกว่า Alpaca
จากตารางด้านบนเราพบว่า:
Ours(w/CoT) มักจะสร้างเหตุผลที่ถูกต้องก่อนคำตอบในขณะที่ Alpaca ล้มเหลวในการสร้างเหตุผลที่สมเหตุสมผลใด ๆ ดังที่แสดงในตัวอย่าง 4 ตัวอย่างแรก (คำถามทั่วไป) สิ่งนี้แสดงให้เห็นว่าการใช้ข้อมูล COT สำหรับการ finetuning สามารถปรับปรุงความสามารถในการใช้เหตุผลอย่างมีนัยสำคัญOurs(w/CoT) , COT Prompt (เช่น concatenate 'ทีละขั้นตอน' พร้อมคำถามอินพุต) มีผลเพียงเล็กน้อยต่อตัวอย่างง่าย ๆ (เช่นคำถามทั่วไป) และมีผลกระทบที่สำคัญต่อคำถามที่ท้าทาย (เช่นคำถามที่ต้องใช้เหตุผลเช่นสี่ตัวอย่างสุดท้าย) การเปรียบเทียบเชิงปริมาณของการตอบสนองต่อคำแนะนำของจีน 
โมเดลของเราได้รับการแก้ไขจาก 7B LLAMA ตามคำแนะนำภาษาอังกฤษ 52K และคำแนะนำภาษาจีน 0.5M Stanford Alpaca (การปรับแต่งของเรา) ได้รับการแก้ไขจาก 7B Llama ตามคำแนะนำภาษาอังกฤษ 52K เบลล์ได้รับการคัดค้านจาก 7B บานในคำแนะนำภาษาจีน 2B
จากตารางด้านบนสามารถพบการสังเกตหลายครั้ง:
ours (w/ CN) มีความสามารถที่แข็งแกร่งในการเข้าใจคำแนะนำของจีน สำหรับตัวอย่างแรก Alpaca ไม่สามารถแยกแยะความแตกต่างระหว่างชิ้นส่วน instruction และส่วน input ในขณะที่เราทำours (w/ CN) ไม่เพียง แต่ให้รหัสที่ถูกต้อง แต่ยังให้คำอธิบายประกอบภาษาจีนที่สอดคล้องกันในขณะที่ Alpaca ไม่ได้ นอกจากนี้ดังที่แสดงในตัวอย่าง 3-5 ตัวอย่าง Alpaca สามารถตอบสนองต่อการเรียนการสอนภาษาจีนด้วยการตอบกลับภาษาอังกฤษเท่านั้นours (w/ CN) เกี่ยวกับคำแนะนำที่ต้องการการตอบสนองแบบเปิด (ดังแสดงในสองตัวอย่างสุดท้าย) ยังคงต้องปรับปรุง ประสิทธิภาพที่โดดเด่นของเบลล์กับคำแนะนำดังกล่าวเกิดจาก: 1. โมเดลกระดูกสันหลังบานสะพรั่งของมันพบข้อมูลหลายภาษามากขึ้นในระหว่างการฝึกอบรมก่อน 2. ข้อมูลการใช้งานของจีนการสอนภาษาจีนเป็นมากกว่าของเรานั่นคือ 2m เทียบกับ 0.5m การเปรียบเทียบเชิงปริมาณของการตอบสนองต่อคำแนะนำภาษาอังกฤษ วัตถุประสงค์ของส่วนย่อยนี้คือการสำรวจว่าการเพิ่มขึ้นของคำแนะนำภาษาจีนมีผลกระทบด้านลบต่อ Alpaca หรือไม่ 
จากตารางด้านบนเราพบว่า:
ours (w/ CN) แสดงรายละเอียดมากกว่าของ Alpaca เช่นสำหรับตัวอย่างที่สามรายการ ours (w/ CN) รายการสามจังหวัดมากกว่า Alpaca โปรดอ้างอิง repo หากคุณใช้การรวบรวมข้อมูลรหัสและการค้นพบการทดลองใน repo นี้
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
สำหรับข้อมูลและรุ่นโปรดอ้างอิงข้อมูลต้นฉบับวิธีการที่มีประสิทธิภาพพารามิเตอร์และแหล่งที่มาของ LLMS เช่นกัน
เราขอแสดงความขอบคุณเป็นพิเศษต่อ APUS AILME LAB สำหรับการสนับสนุน 8 A100 GPU สำหรับการทดลอง
(กลับไปด้านบน)


