Alpaca CoT
1.0.0
中文| Английский

Это репозиторий для проекта Alpaca-CoT , который направлен на создание платформы для создания инструкций (IFT) с обширным сбором инструкций (особенно наборов данных COT) и унифицированным интерфейсом для различных крупных языковых моделей и эффективных параметров. Мы постоянно расширяем наш сбор данных настройки инструкции и интегрируем больше LLMS и более эффективные методы. Кроме того, мы создали новую филиал tabular_llm для создания табличного LLM для решения задач интеллекта таблицы.
Вы тепло можете предоставить нам любые не созданные наборы данных настройки инструкций (или их источники). Мы будем равномерно отформатировать их, обучать модель Alpaca (и другие LLMS в начале будущего) с этими наборами данных, с открытым исходным кодом модели и проведем обширные эмпирические исследования. Мы надеемся, что наш проект может внести скромный вклад в процесс с открытым исходным кодом крупных языковых моделей и снизить его порог для исследователей НЛП, чтобы начать работу.

Если вы хотите использовать другие методы, помимо LORA, установите отредактированную версию в нашем проекте pip install -e ./peft .
12.8: LLM InternLM был объединен.
8.16: 4bit quantization доступно для lora , qlora и adalora .
8.16: Параметр-эффективные методы Qlora , Sequential adapter и Parallel adapter были объединены.
7.24: LLM ChatGLM v2 был объединен.
7.20: LLM Baichuan был объединен.
6.25: Добавьте код оценки модели, включая Belle и MMCU.
GPT4Tools , Auto CoT , pCLUE добавлены.tabular_llm создается для создания таблицы LLM. Мы собираем инструкции с тонкой настройкой для табличных задач, таких как ответы на таблицу, и используем их для LLMS в этом репо.MOSS был объединен.GAOKAO , camel , FLAN-Muffin , COIG собираются и отформатированы.webGPT , dolly , baize , hh-rlhf , OIG(part) собираются и отформатируются.multi-turn conversation @paulcx.firefly , instruct , Code Alpaca собираются и отформатированы, которые можно найти здесь.Parameter merging , Local chatting , Batch predicting и Web service building @Weberr.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 и natural-instructions собираются и отформатированы.CoT_CN_data.json можно найти здесь. 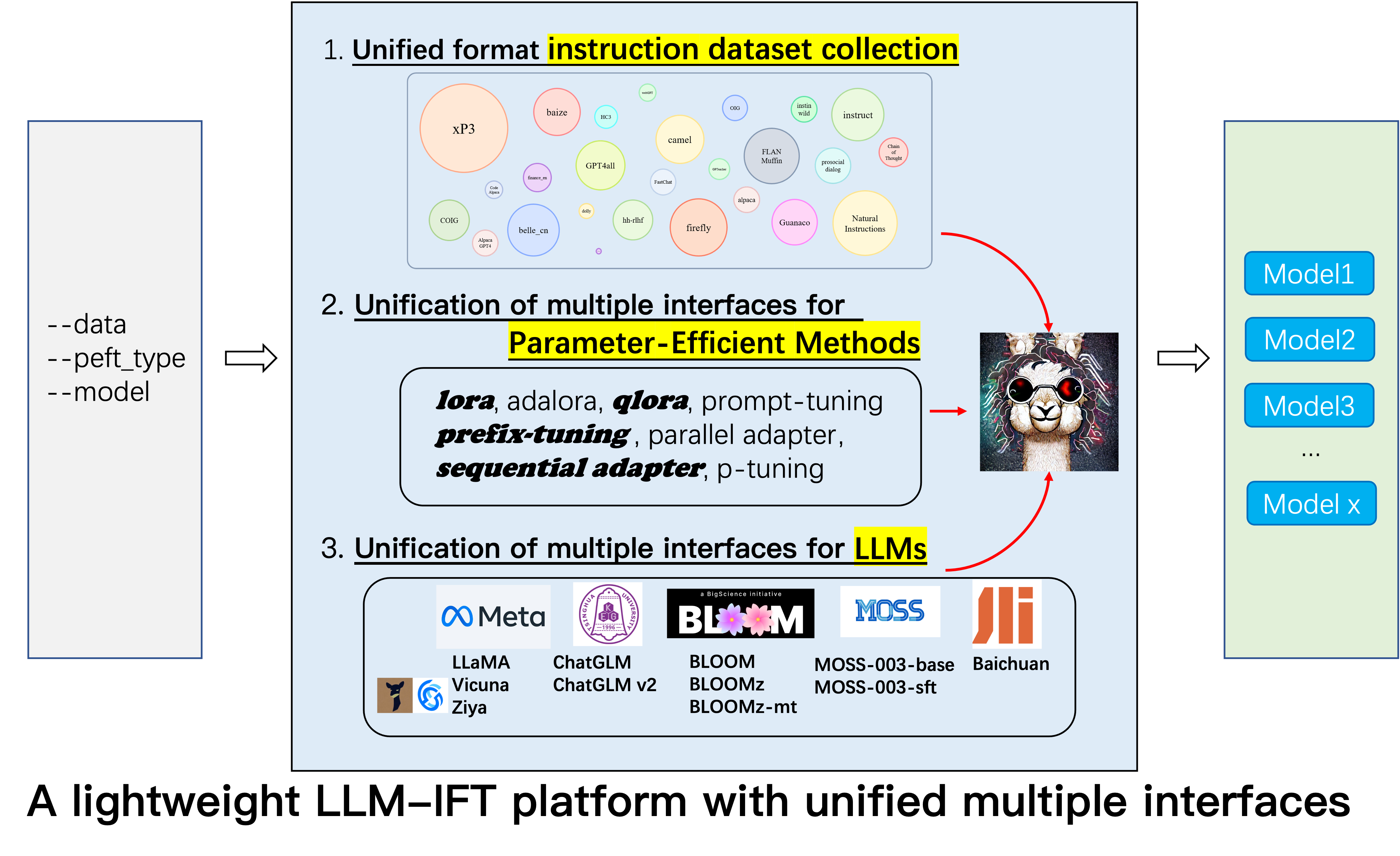
Llama [1]-отличная работа, которая демонстрирует удивительную нулевую и несколько выстрела. Это значительно снижает стоимость обучения, создания и использования конкурентных крупных языковых моделей, т.е. Llama-13b превосходит GPT-3 (175b), а Llama-65b конкуренции с PALM-540B. Недавно, чтобы повысить способность к обучению Llama, Стэнфордская Альпака [2] созданная Llama-7B на 52K, последовательные данные, полученные методами самостоятельного ввода [3]. Однако в настоящее время исследовательское сообщество LLM по-прежнему сталкивается с тремя проблемами: 1. Даже Llama-7b по-прежнему имеет высокие требования к вычислительным ресурсам; 2. Есть несколько наборов данных с открытым исходным кодом для создания инструкций; и 3. Не хватает эмпирического исследования влияния различных типов обучения на модельные способности, такие как способность реагировать на китайское обучение и рассуждения COT.
С этой целью мы предлагаем этот проект, который использует различные улучшения, которые впоследствии были предложены, со следующими преимуществами:
7b , 13b и 30b моделей Llama можно легко обучить на одном 80G A100. Насколько нам известно, эта работа является первой, кто изучает рассуждения в кот -кот -кровке , основанные на ламе и альпаке. Поэтому мы сокращаем нашу работу Alpaca-CoT .
Относительный размер собранных наборов данных может быть показан этим графиком:
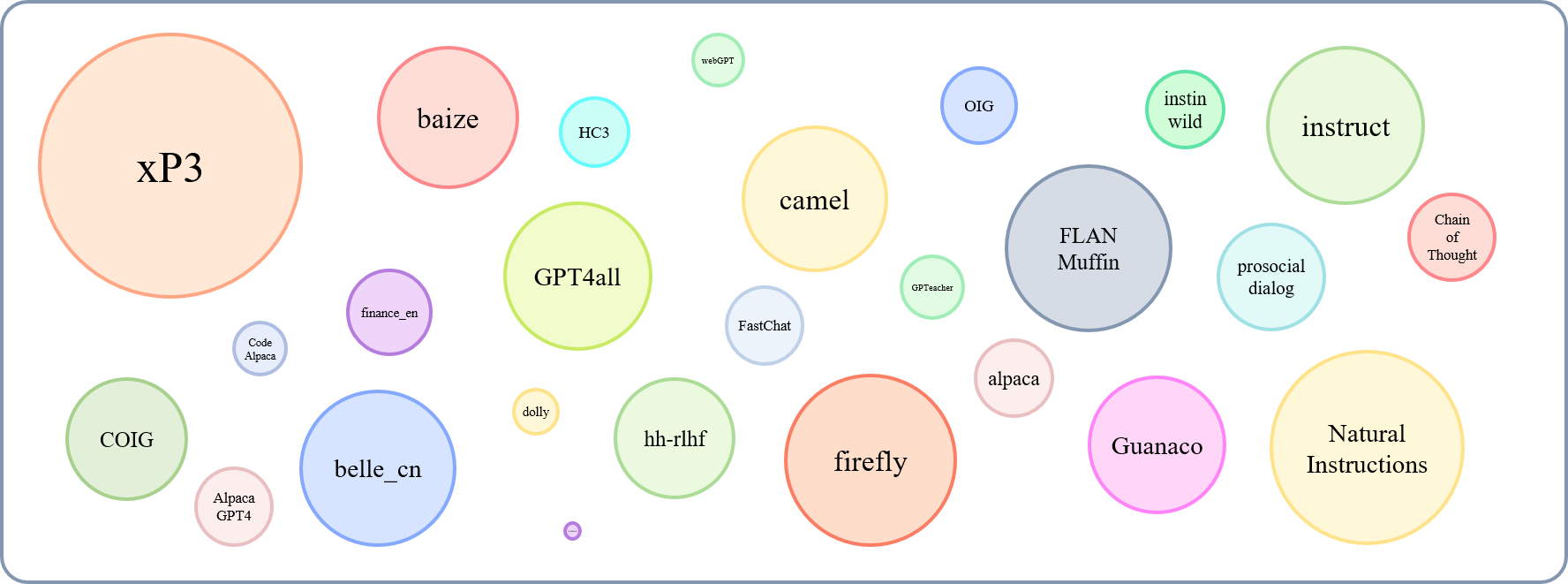
Ссылаясь на это (@yaodongc), мы пометили каждый собственный набор данных в соответствии со следующими правилами:
(Lang) Lingual-Tags:
(Задача) Задача:
(Gen) Method:
| Набор данных | Номеры | Ланг | Задача | Генерал | Тип | SRC | URL |
|---|---|---|---|---|---|---|---|
| Цепь мысли | 74771 | En/cn | Гору | Hg | инструктировать рассуждения | аннотирование кроватки на существующих данных | скачать |
| GPT4ALL | 806199 | Поступка | Гору | Полковник | Код, истории и диалоги | дистилляция от GPT-3,5-Turbo | скачать |
| Gpteacher | 29013 | Поступка | Гору | Сияние | Генерал, Ролепла, инструмент | GPT-4 и Toolformer | скачать |
| Гуанако | 534610 | Мл | Гору | Сияние | Различные лингвистические задачи | Текст-давинка-003 | скачать |
| HC3 | 37175 | En/cn | Т.С. | СМЕШИВАНИЕ | Оценка диалога | Человек или Чатгпт | скачать |
| альпака | 52002 | Поступка | Гору | Сияние | Общий инструкт | Текст-давинка-003 | скачать |
| Естественные инструкции | 5040134 | Мл | Гору | Полковник | Разнообразные задачи NLP | Человеческие аннотированные наборы данных | скачать |
| Belle_cn | 1079517 | CN | TS/MT | Сияние | Общие, математические рассуждения, диалог | Текст-давинка-003 | скачать |
| Instinwild | 52191 | En/cn | Гору | Сияние | Поколение, Open-qa, Mind Storm | Текст-давинка-003 | скачать |
| Просоциальный диалог | 165681 | Поступка | Т.С. | СМЕШИВАНИЕ | диалог | GPT-3 переписывает вопросы + люди обратную связь вручную | скачать |
| finance_en | 68912 | Поступка | Т.С. | Полковник | Финансовый QA | GPT3.5 | скачать |
| XP3 | 78883588 | Мл | Гору | Полковник | Сборник подсказок и наборов данных на 46 языках и 16 задач NLP | Человеческие аннотированные наборы данных | скачать |
| огненный | 1649398 | CN | Гору | Полковник | 23 задачи NLP | Человеческие аннотированные наборы данных | скачать |
| инструктировать | 888969 | Поступка | Гору | Полковник | Дополнен GPT4ALL, Alpaca, Meta Dataes с открытым исходным кодом | Увеличение, выполняемое с использованием расширенных инструментов NLP, предоставленных Allenai | скачать |
| Код альпака | 20022 | Поступка | Т.С. | Сияние | генерация кода, редактирование, оптимизация | Текст-давинка-003 | скачать |
| Alpaca_gpt4 | 52002 | En/cn | Гору | Сияние | Общий инструкт | генерируется GPT-4 с использованием альпаки | скачать |
| Webgpt | 18994 | Поступка | Т.С. | СМЕШИВАНИЕ | поиск информации (IR) QA | тонко настроенный GPT-3, каждая инструкция имеет два выхода, выберите лучший | скачать |
| Долли 2.0 | 15015 | Поступка | Т.С. | Hg | Закрытая QA, суммирование и т. Д., Википедия в качестве ссылок | человеческий аннотирован | скачать |
| Baize | 653699 | Поступка | Гору | Полковник | Коллекция из Alpaca, Quora, Stackoverflow и Mrequad Вопросы | Человеческие аннотированные наборы данных | скачать |
| HH-RLHF | 284517 | Поступка | Т.С. | СМЕШИВАНИЕ | диалог | Диалог между моделями человека и RLHF | скачать |
| Oig (часть) | 49237 | Поступка | Гору | Полковник | создан из различных задач, таких как вопрос и ответ | Использование увеличения данных, сборы наборов данных человека, аннотированные наборы данных | скачать |
| Гаокао | 2785 | CN | Гору | Полковник | Вопросы с несколькими вариантами выбора, заполнения и открытых вопросов с экзамена | человеческий аннотирован | скачать |
| верблюд | 760620 | Поступка | Гору | Сияние | Ролевые разговоры в обществе ИИ, код, математика, физика, химия, биолог | GPT-3.5-Turbo | скачать |
| Флан-муффин | 1764800 | Поступка | Гору | Полковник | 60 NLP -задач | Человеческие аннотированные наборы данных | скачать |
| Coig (flaginstruct) | 298428 | CN | Гору | Полковник | Соберите экзамен FRON, Перевод, Инструкции по выравниванию ценности человека и контрейтуальная коррекция многоуровневого чата | Использование автоматического инструмента и ручной проверки | скачать |
| GPT4Tools | 71446 | Поступка | Гору | Сияние | Коллекция инструкций, связанных с инструментами, | GPT-3.5-Turbo | скачать |
| Шаречат | 1663241 | Поступка | Гору | СМЕШИВАНИЕ | Общий инструкт | Краудсорсинг собирать разговоры между людьми и CHATGPT (SHAREGPT) | скачать |
| Авторушка | 5816 | Поступка | Гору | Полковник | Арифметические, здравомыслительные, символические и другие логические рассуждения | Человеческие аннотированные наборы данных | скачать |
| МОХ | 1583595 | En/cn | Т.С. | Сияние | Общий инструкт | Текст-давинка-003 | скачать |
| Ультрахат | 28247446 | Поступка | Вопросы о мире, письме и создании, помощи в существующих материалах | Два отдельных GPT-3.5-Turbo | скачать | ||
| Китайский медицинский | 792099 | CN | Т.С. | Полковник | Вопросы о медицинском совете | ползти | скачать |
| CSL | 396206 | CN | Гору | Полковник | Генерация текста бумаги, извлечение ключевых слов, суммирование текста и классификация текста | ползти | скачать |
| Pclue | 1200705 | CN | Гору | Полковник | Общий инструкт | скачать | |
| News_commentary | 252776 | CN | Т.С. | Полковник | переводить | скачать | |
| Стекллама | Тодо | Поступка |
Вы можете скачать все отформатированные данные здесь. Затем вы должны поместить их в папку данных.
Вы можете скачать все контрольно -пропускные пункты, обученные различным типам данных инструкций отсюда. Затем, после установки LoRA_WEIGHTS (в generate.py ) на локальный путь, вы можете напрямую выполнить вывод модели.
Все данные в нашей сборе отформатированы в одни и те же шаблоны, где каждый образец следующим образом:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Обратите внимание, что для наборов данных COT мы сначала используем шаблон, предоставленный FLAN, чтобы изменить исходный набор данных в различные формы цепочки частей, а затем преобразовать его в вышеуказанный формат. Форматирование сценария можно найти здесь.
pip install -r requirements.txt
Обратите внимание, что убедитесь, что Python> = 3.9 при создании чатглма.
Пефт
pip install -e ./peft
Чтобы исследователи могли проводить систематические исследования IFT по LLMS, мы собрали различные типы данных об инструкциях, интегрированные LLM и унифицированные интерфейсы, что облегчало настройку желаемой коллокации:
--model_type : установите LLM, который вы хотите использовать. В настоящее время поддерживаются [Llama, Chatglm, Bloom, Moss]. Последние два имеют сильные китайские возможности, и в будущем будет интегрировано больше LLMS.--peft_type : Установите PEFT, который вы хотите использовать. В настоящее время поддерживаются [Lora, Adalora, Prefix Tuning, P -Tuning, Prompt].--data : Установите тип данных, используемый для IFT, чтобы гибко адаптировать желаемую способность соответствовать команде. Например, для сильных способностей рассуждения установите «Alpaca-Cot», для сильной китайской способности, установите «Belle1.5m», для кодирования и способности генерации истории, установите «gpt4all» и для способности ответа, связанной с финансовой точки зрения, установить «финансы».--model_name_or_path : это установлено для загрузки разных версий веса модели для целевого LLM --model_type . Например, для загрузки версии веса Llama 13b вы можете установить Decapoda-Research/Llama-13b-HF.Одиночный графический процессор
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
Примечание. Для нескольких наборов данных вы можете использовать --data like --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Обратите внимание, что load_in_8bit еще не подходит для ChatGLM, поэтому BATCH_SIZE должен быть меньше других.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Обратите внимание, что вы также можете пройти локальный путь (где сохранены веса LLM) --model_name_or_path . И тип данных --data может быть свободно установить в соответствии с вашими интересами.
Несколько графических процессоров
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Обратите внимание, что load_in_8bit еще не подходит для ChatGLM, поэтому BATCH_SIZE должен быть меньше других.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Более подробную информацию о конфигурации и выводе инструкций можно найти здесь, откуда мы изменили. Обратите внимание, что saved-xxx7b -это путь сохранения весов Lora, а веса ламы автоматически загружаются с обнимающегося лица.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Эта статья выбирает два оценки оценки, Belle-Eval и MMCU, чтобы всесторонне оценить компетенции LLM на китайском языке.
Belle-eval построена в результате самостоятельной конструкции с CHATGPT, который имеет 1000 различных инструкций, в которых участвуют 10 категорий, охватывающих общие задачи NLP (например, QA) и сложные задачи (например, код и математика). Мы используем CHATGPT, чтобы оценить ответы модели на основе золотых ответов. Этот эталон считается оценкой возможностей AGI (следование инструкциям).
MMCU - это коллекция китайских вопросов с множественным выбором в четырех профессиональных дисциплинах медицины, права, психологии и образования (например, экзамен Gaokao). Это позволяет LLMS сдавать экзамены в человеческом обществе в тестовом манере с множественным выбором, что делает его подходящим для оценки широты и глубины знаний о LLMS по нескольким дисциплинам.
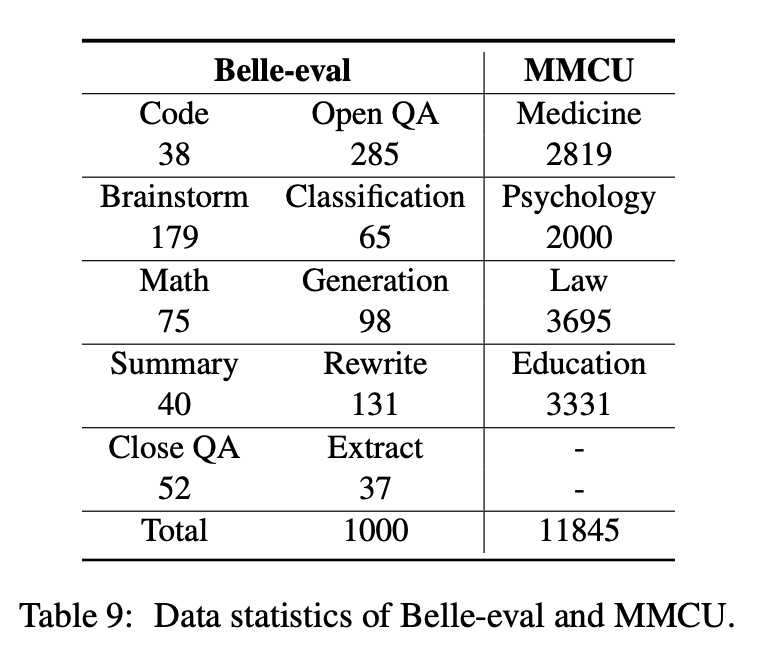
Статистика данных Belle-Eval и MMCU показана в таблице выше.
Мы проводим эксперименты по изучению трех основных факторов в LLMS настройки инструкций: основания LLM, методы, эффективные параметры, китайские наборы инструкций.
Для Open LLMS мы проверяем существующие LLMS и LLMS, настраиваемые с LORA на Alpaca-GPT4 на Belle-Eval и MMCU, соответственно.
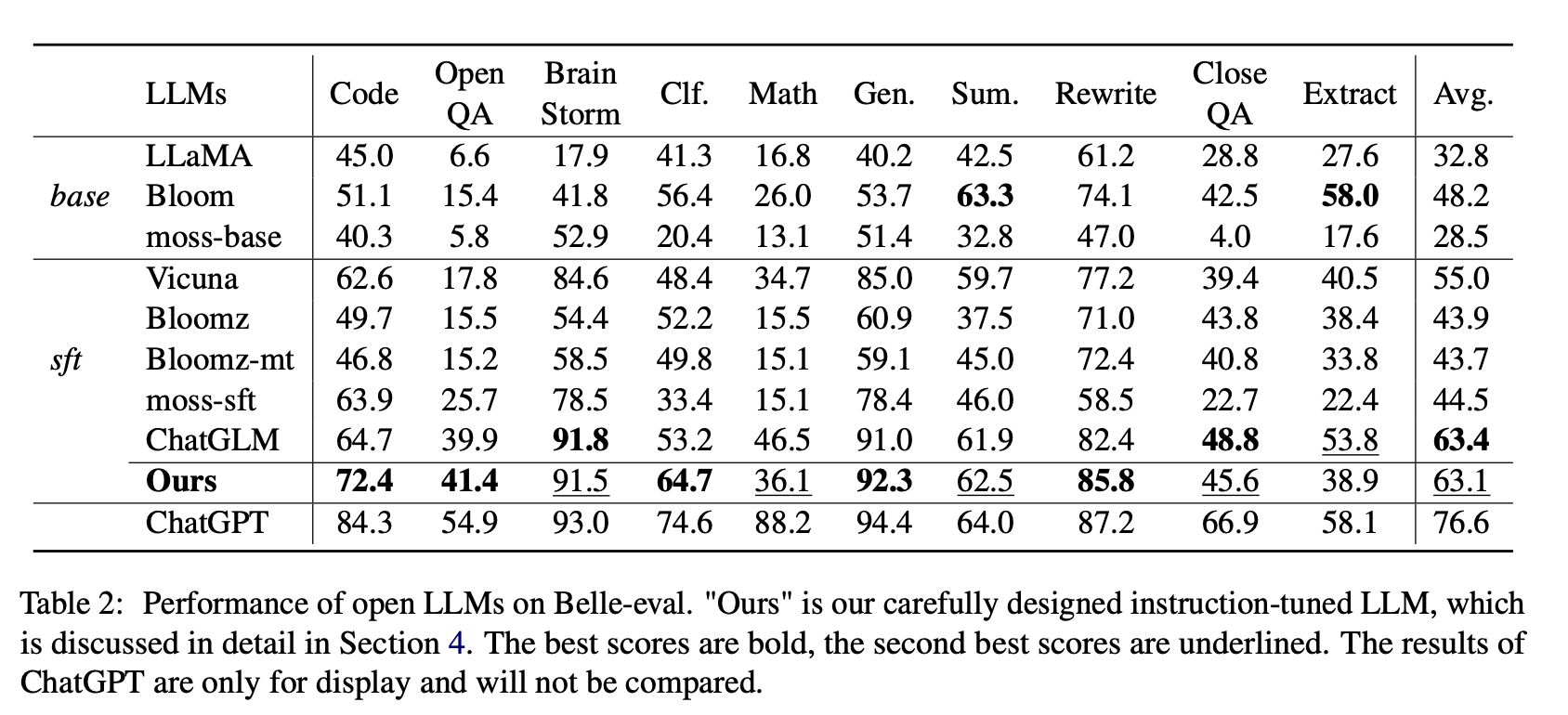
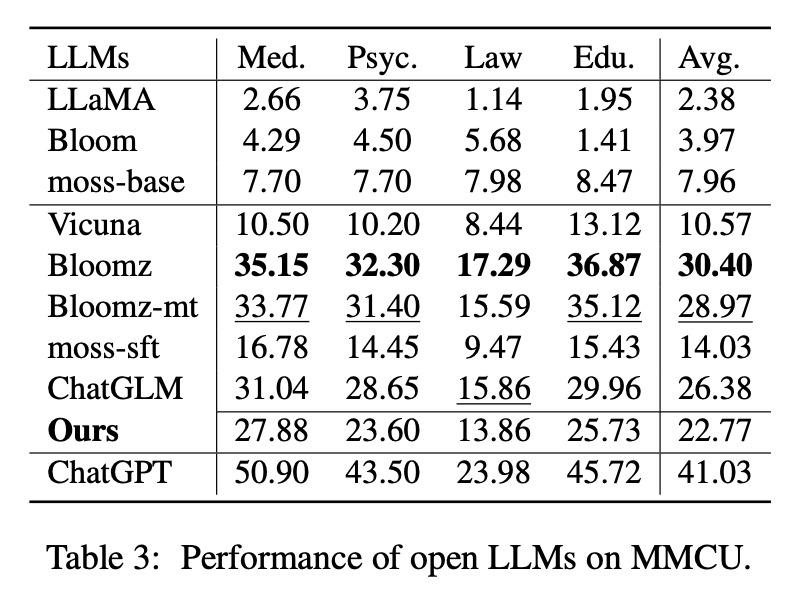
В таблице 2 показаны оценки Open LLM на Belle-Eval. Таблица 3 показывает точность LLM на MMCU. Они настраивают все открытые LLM с одним и тем же методом, эффективным для параметров LORA и одним и тем же набором данных Alpaca-GPT4.
Экспериментальные результаты:
Оценка существующих LLMS
Производительность на Belle-Eval
(1) Для Base LLMS Bloom работает лучше всего.
(2) Для SFT LLMS Chatglm превосходит других по большим полям, благодаря тому факту, что он обучен самым китайским токенам и HFRL.
(3) Категории открытого QA, математика, закрытия и извлечения по -прежнему очень сложны для существующих открытых LLMS.
(4) Vicuna и Moss-SFT имеют четкие улучшения по сравнению с их основаниями, ламой и моховой базой соответственно.
(5) Напротив, производительность моделей SFT, Bloomz и Bloomz-MT снижается по сравнению с Base Model Bloom, потому что они имеют тенденцию генерировать более короткий ответ.
Производительность на MMCU
(1) Все базовые LLM работают плохо, потому что почти сложно генерировать контент в указанном формате перед тонкой настройкой, например, вывода опций номеров.
(2) Все SFT LLMs превосходят свои соответствующие базовые LLM, соответственно. В частности, Bloomz выполняет лучшее (даже бьет чатггм), потому что он может генерировать номер опции непосредственно по мере необходимости, не генерируя другое нерелевантное содержание, что также связано с характеристиками данных его контролируемого набора данных с точной настройкой XP3.
(3) Среди четырех дисциплин, закон является наиболее сложным для LLMS.
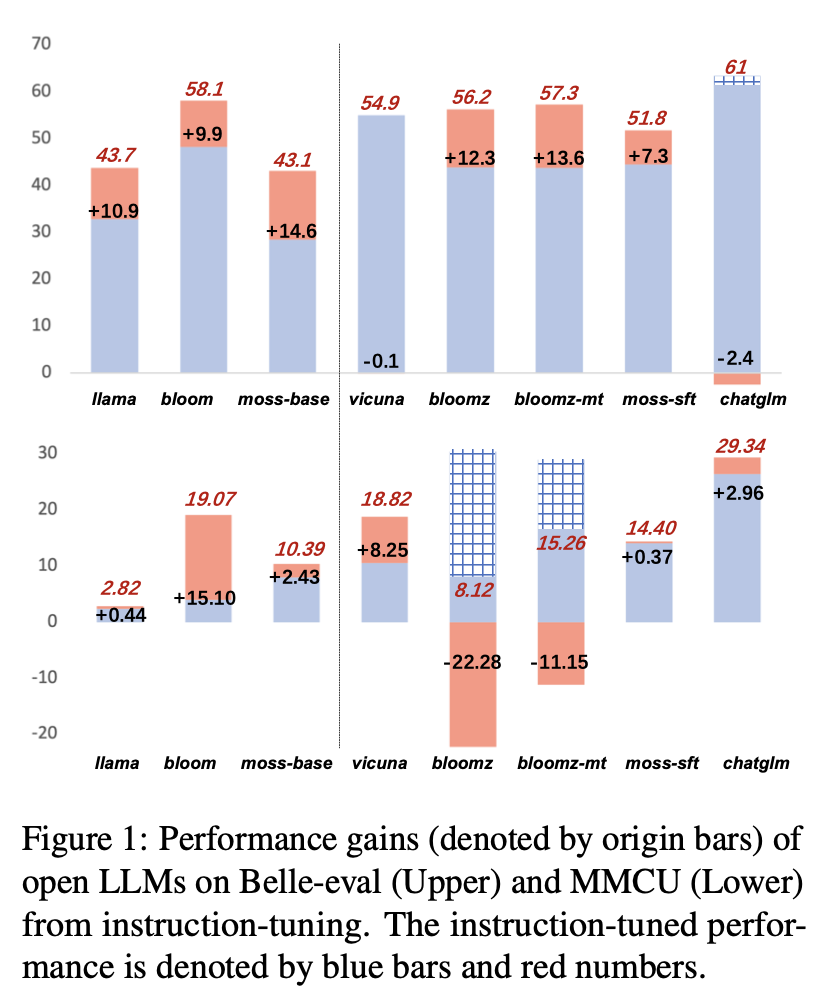
Результаты производительности LLMS после настройки инструкции на Alpaca-GPT4-ZH показаны на рисунке 1.
Настройка инструкции разных LLMS
(1) На Belle-eval улучшение производительности SFT LLM, принесенные настройкой инструкции, не так значительно, как у базовых LLM, за исключением SFT Bloomz и Bloomz-MT.
(2) Производительность Vicuna и Chatglm снимается после настройки инструкции, потому что Vicuna обучается из настоящих разговоров с человеком-чатгптом, с лучшим качеством, чем Alpaca-GPT4. Chatglm принимает HFRL, который больше не подходит для дальнейшей настройки обучения.
(3) На MMCU большинство LLMs достигают повышения производительности после настройки инструкции, за исключением Bloomz и Bloomz-MT, которые неожиданно значительно снижают производительность.
(4) После настройки инструкции Блум имеет значительные улучшения и хорошо работает на обоих тестах. Хотя чатггм бьет Bloom последовательно, он страдает от производительности во время настройки обучения. Следовательно, среди всех открытых LLMS, Bloom наиболее подходит в качестве модели фундамента в последующих экспериментах для китайского исследования настройки обучения.
Для эффективных параметров методов, отличных от LORA, статья собирает диапазон параметров-эффективных методов для расцвета инструкции на наборе данных Alpaca-GPT4.
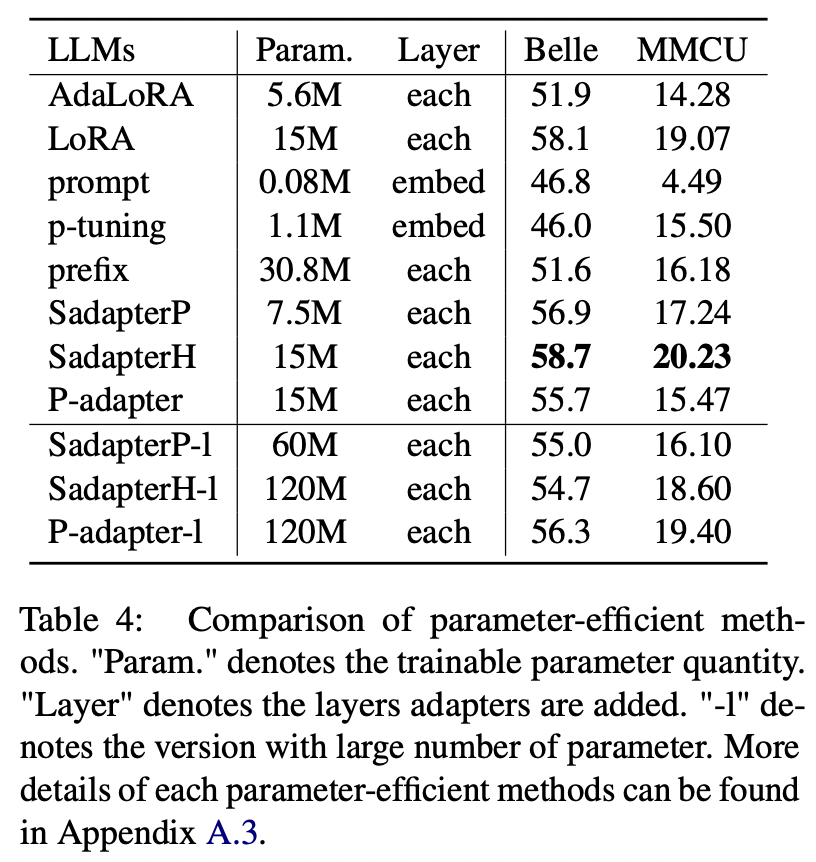
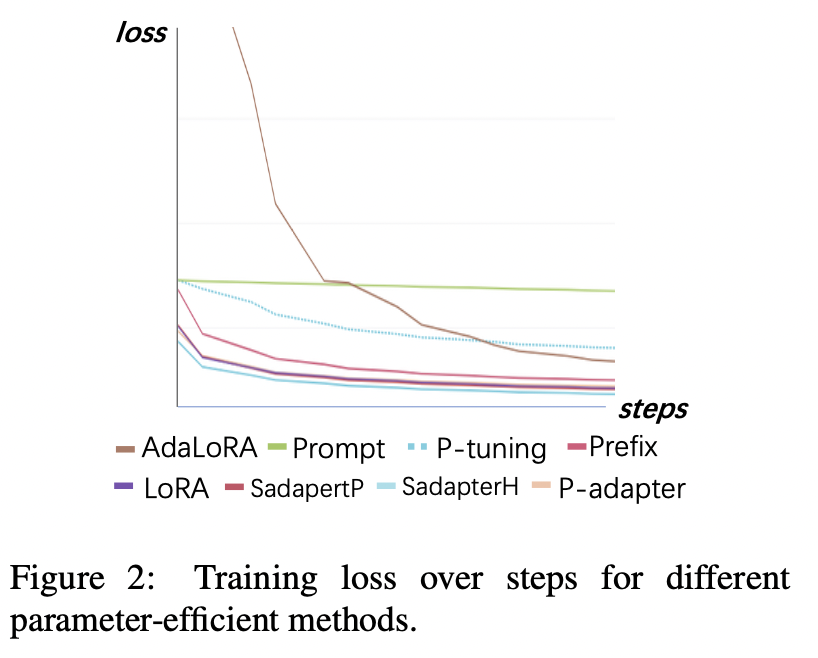
Экспериментальные результаты:
Сравнение методов эффективного параметров
(1) Sadapterh выполняет лучшее среди всех методов, эффективных для параметров, которые могут использоваться в качестве альтернативы Lora.
(2) P-подключение и подготовка быстрого настройки уступают большим полям, что указывает на то, что только добавление обучаемых слоев в слое встраивания недостаточно для поддержки LLM для задач генерации.
(3) Хотя Adalora является улучшением LORA, ее производительность имеет четкое падение, возможно, потому, что обучаемые параметры LORA для LLMS не подходят для дальнейшего сокращения.
(4) Сравнивая верхнюю и нижнюю часть, можно видеть, что увеличение числа обучаемых параметров для последовательных адаптеров (то есть Sadapterp и Sadapterh) не приносит усиление, в то время как противоположное явление наблюдается для параллельных адаптеров (то есть P-адаптер)
Потеря обучения
(1) Настройка быстрого подготовки и P-подключения сходятся самые медленные и имеют самые высокие потери после сходимости. Это показывает, что адаптеры только для встраивания не подходят для LLMS настройки обучения.
(2) Первоначальная потеря Adalora очень высока, потому что она требует одновременного изучения распределения бюджета параметров, что делает модель неспособностью хорошо соответствовать данным обучения.
(3) Другие методы могут быстро сходиться на учебных данных и хорошо их подходить.
Для воздействия различных типов китайских наборов данных инструкции авторы собирают популярные открытые китайские инструкции (как показано в таблице 5) для точного расцвета с Лорой.
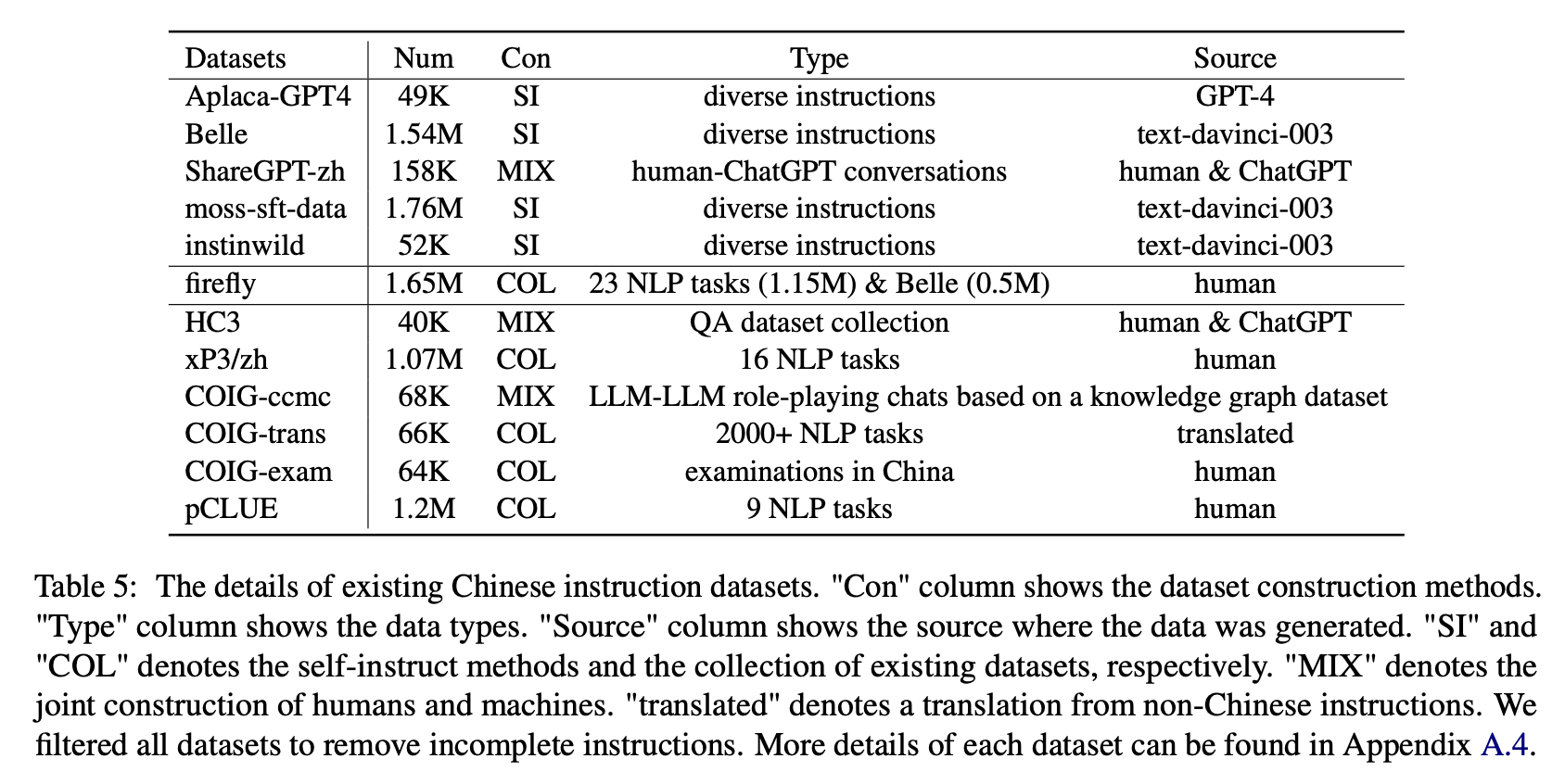
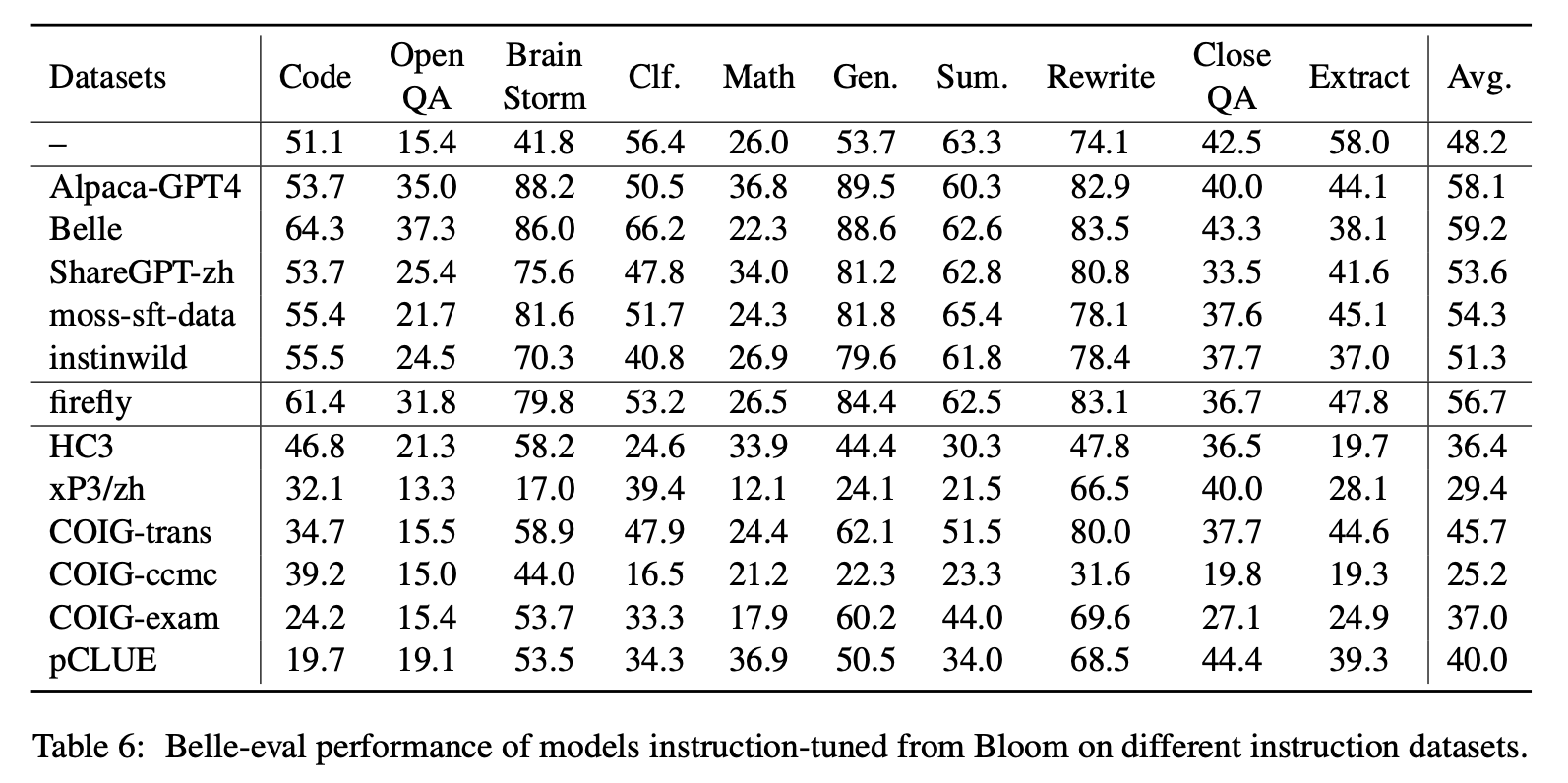
В таблице 6 и в таблице 7 показана точная настройка Блума на различных наборах данных.
Экспериментальные результаты:
Производительность на Belle-Eval
(1) Данные инструкции, построенные CHATGPT (например, с использованием методов самостоятельной произведения или сбора реальных разговоров с человеком-чатгптом), последовательно повышает способность к срабатыванию инструкций с 3,1 ∼ 11-балльное увеличение оценки.
(2) Среди этих наборов данных Belle обладает наилучшей производительностью из -за наибольшего объема данных инструкций. Тем не менее, производительность моделей, обученных мохам-SFT-DATA, содержащих больше данных, построенных аналогичным образом, является неудовлетворительным.
(3) Производительность, вызванная инструкциями Alpaca-GPT4, является вторым лучшим, а только 49 тыс. Сопоставимо с 1,54-метровой Belle.
(4) Instinwild приносит наименьший рост производительности среди них, потому что инструкции по семенам, которые он ползает из твита («в дикой природе»), не так полны, как (например, альпака), тщательно спроектированные людьми.
(5) Эти данные на основе CHATGPT в основном оказывают значительное улучшение на задачи открытой генерации, такие как мозговой шторм и генерация, в то время как существует значительное снижение задач, которые требуют высоких навыков понимания прочитанного, таких как близкий QA и экстракт.
(6) Эти наборы данных инструкций вызывают ущерб способности модели, посвященной инструкциям, потому что форма и намерение каждого набора данных NLP или экзамена являются унитарными, что может быть легко переполнено.
(7) Среди них Coig-Trans выполняет лучшее, потому что в нем участвуют более 2000 различных задач с широким спектром инструкций по заданиям. Напротив, XP3 и COIG-CCMC оказывают наихудшее негативное влияние на производительность модели. Оба они охватывают только несколько типов задач (перевод и QA для первых, контрфактивных коррекционных разговоров для последних), которые вряд ли охватывают популярные инструкции и задачи для людей.
Производительность на MMCU
(1) Настройка инструкции на каждом наборе данных всегда может привести к повышению производительности.
(2) Среди данных на основе CHATGPT, показанных в верхней части, ShareGPT-ZH поднигает других по большим полям. Это может быть связано с тем, что реальные пользователи редко задают вопросы с несколькими вариантами выбора по академическим темам.
(3) Среди данных сбора набора данных, показанных в нижней части, HC3 и COIG-CCMC приводят к самой низкой точности, поскольку уникальные вопросы HC3 составляют всего 13 тыс., И формат задачи COIG-CCMC значительно отличается от MMCU.
(4) COIG-EXAM приносит наибольшее повышение точности, извлекая выгоду из аналогичного формата задачи, что и MMCU.
Четыре других фактора: кроватка, расширение словарного запаса китайского языка, язык подсказок и выравнивание человеческой стоимости
Для COT авторы сравнивают производительность до и после добавления данных COT во время настройки инструкции.
Настройки эксперимента:
Мы собираем 9 наборов данных COT и их подсказки от Flan, а затем переводим их в китайский язык, используя Google Translate. Они сравнивают производительность до и после добавления данных COT во время настройки инструкции.
Сначала обратите внимание, как добавить данные COT в качестве «Alpaca-GPT4+Cot». Кроме того, добавьте предложение «先思考 , 再决定» («Подумайте о шаг за шагом» на китайском языке) в конце каждой инструкции, чтобы побудить модель реагировать на инструкции, основанные на кроватке, и пометить таким образом как «Alpaca-GPT4+Cot*».
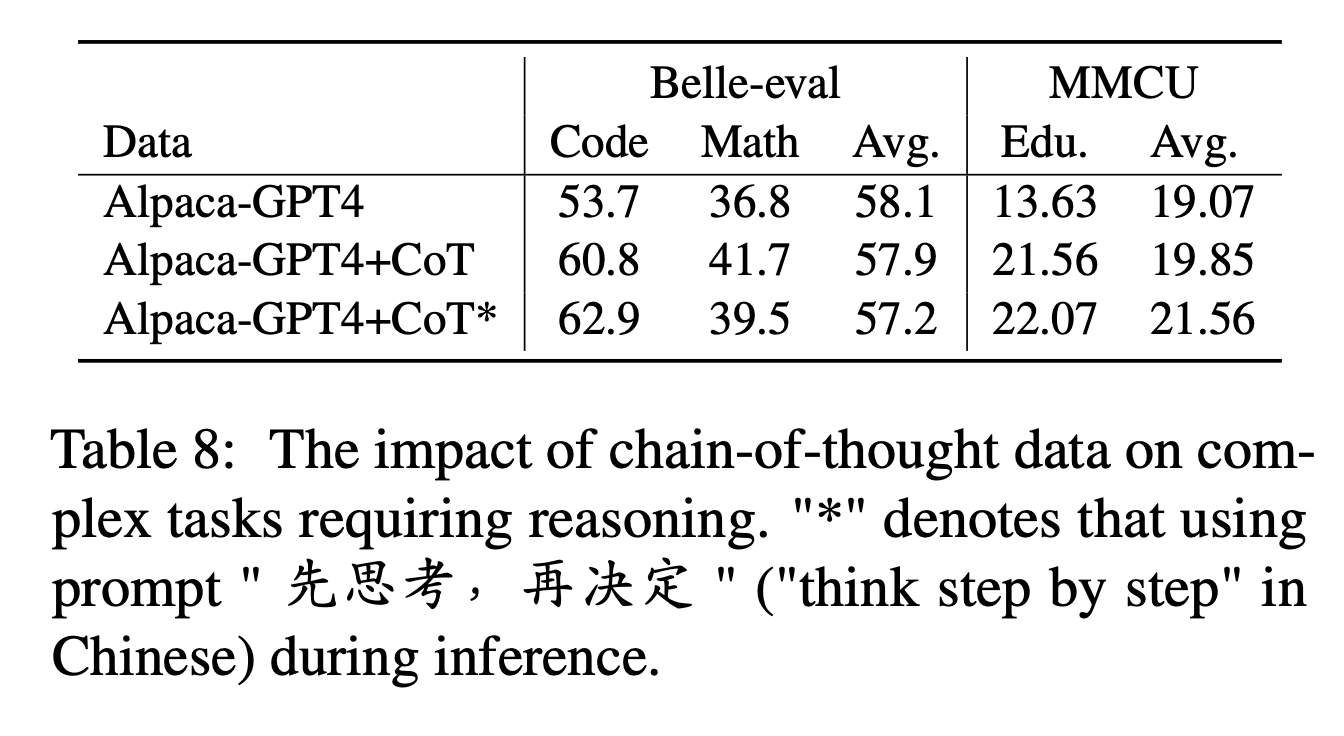
Экспериментальные результаты:
«Alpaca-Gpt4+Cot» превосходит «Alpaca-GPT4» в коде и математических задачах, которые требуют сильной способности рассуждения. Кроме того, существует также значительное улучшение в образовательной задаче MMCU.
Как показано в линии «Alpaca-GPT4+Cot*», простое предложение может еще больше улучшить выполнение кода и образования рассуждений, в то время как математическая производительность немного уступает «Alpaca-GPT4+Cot». Это может потребовать дальнейшего изучения более надежных подсказок.
Для расширения китайского словаря авторы проверяют влияние количества китайских токенов в словаре токенизатора на способность LLMS выражать китайцы. Например, если китайский символ находится в словарном запасе, он может быть представлен одним токеном, в противном случае это может потребовать нескольких токенов, чтобы представлять его.
Настройки эксперимента: авторы в основном проводят эксперименты на ламе, в которой используется предложение (размер словарного запаса 32 тыс. Китайских иероглифы), охватывающей меньше китайских иероглифы, чем Bloom (250K).
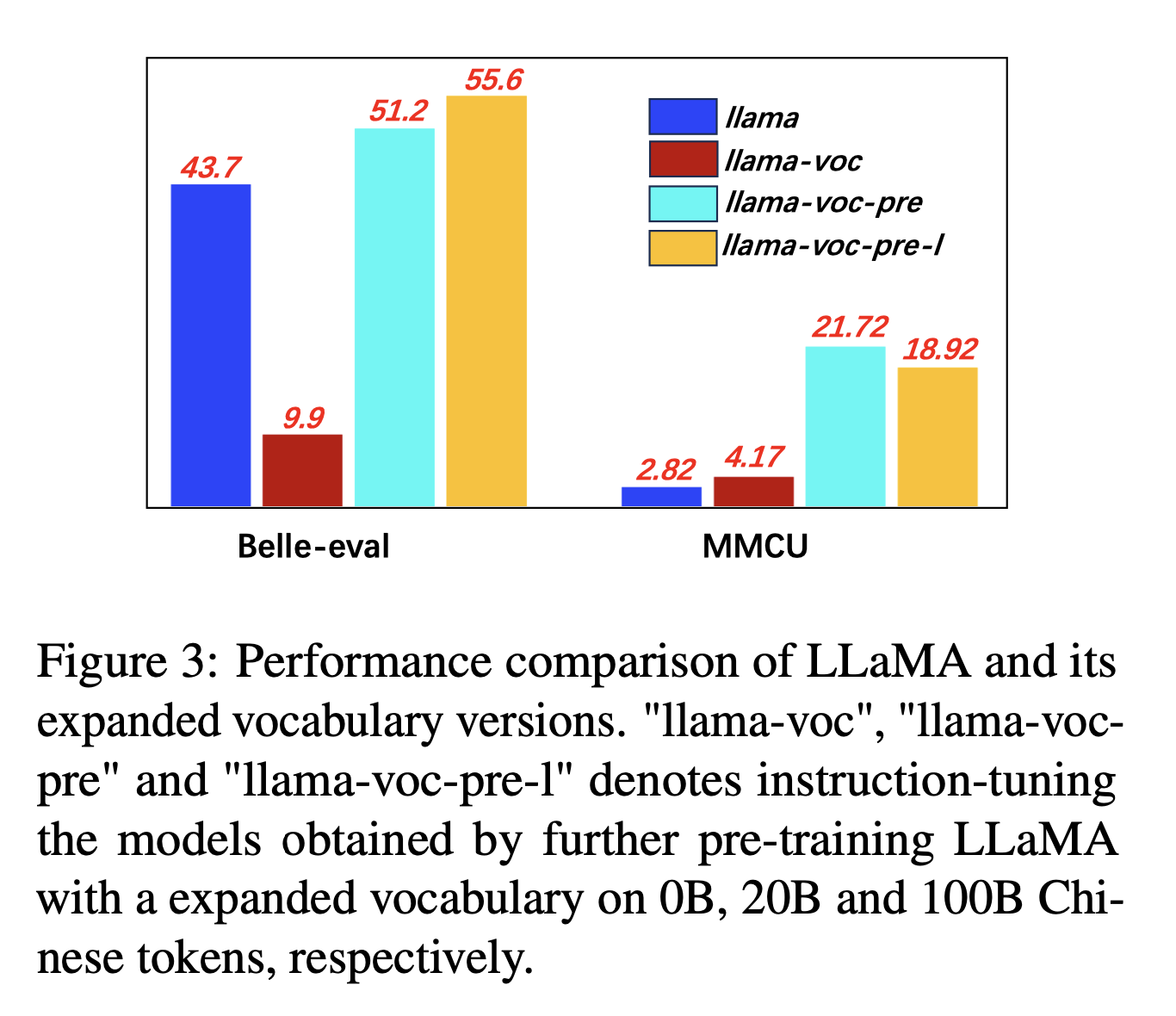
Экспериментальные результаты:
Предварительное обучение по большему количеству китайского корпуса с расширением китайского словарного запаса неизменно полезно для способности к обучению.
И противоречиво, «llama-voc-pre-l» (100b) уступает «llama-voc-pre» (20b) на MMCU, что показывает, что предварительное обучение по большему количеству данных не обязательно привести к более высокой производительности для академических экзаменов.
Для языка подсказок авторы проверяют пригодность инструкции для использования китайских подсказок.
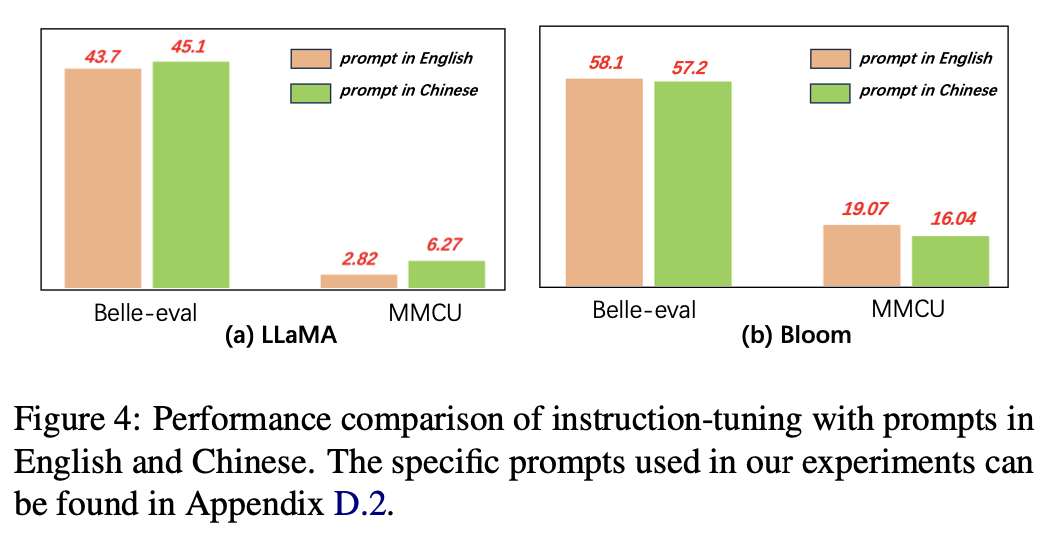
На рисунке 4 показаны результаты использования подсказок китайского и английского языка на основе ламы и цветов. При настройке инструкции Llama, использование китайских подсказок может улучшить производительность на обоих критериях по сравнению с английскими подсказками, в то время как противоположное явление можно наблюдать при цветении.
Экспериментальные результаты:
Для моделей с более слабыми китайскими способностями (например, Llama) использование китайских подсказок может эффективно помочь реагировать на китайском языке.
Для моделей с хорошими китайскими способностями (например, Bloom), используя подсказки на английском языке (язык, на котором они лучше), могут лучше направить модель, чтобы понять процесс точной настройки с помощью инструкций.
Чтобы избежать генерации LLMS, выравнивания токсического содержания, их выравнивание человеческими ценностями является важной проблемой. Мы добавляем данные о выравнивании человека, созданные COIG, в настройку инструкции, чтобы изучить его влияние.
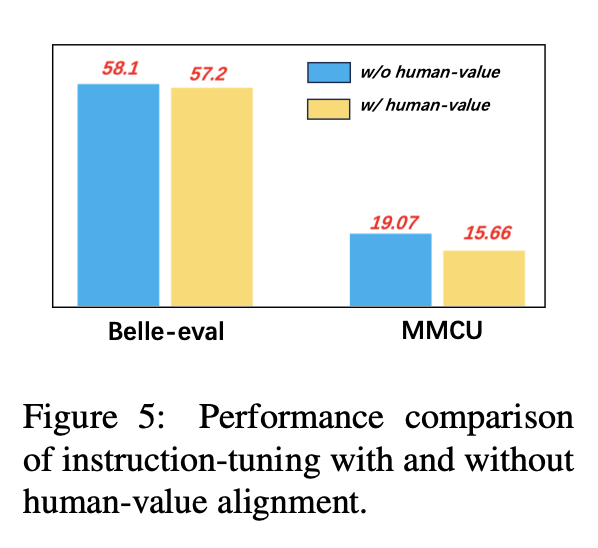
На рисунке 5 сравниваются результаты настройки инструкции с выравниванием по значению человека и без нее.
Экспериментальные результаты: выравнивание значений человека приводит к небольшому падению производительности. Как сбалансировать безобидность и производительность LLMS - это направление исследования, которое стоит изучить в будущем.
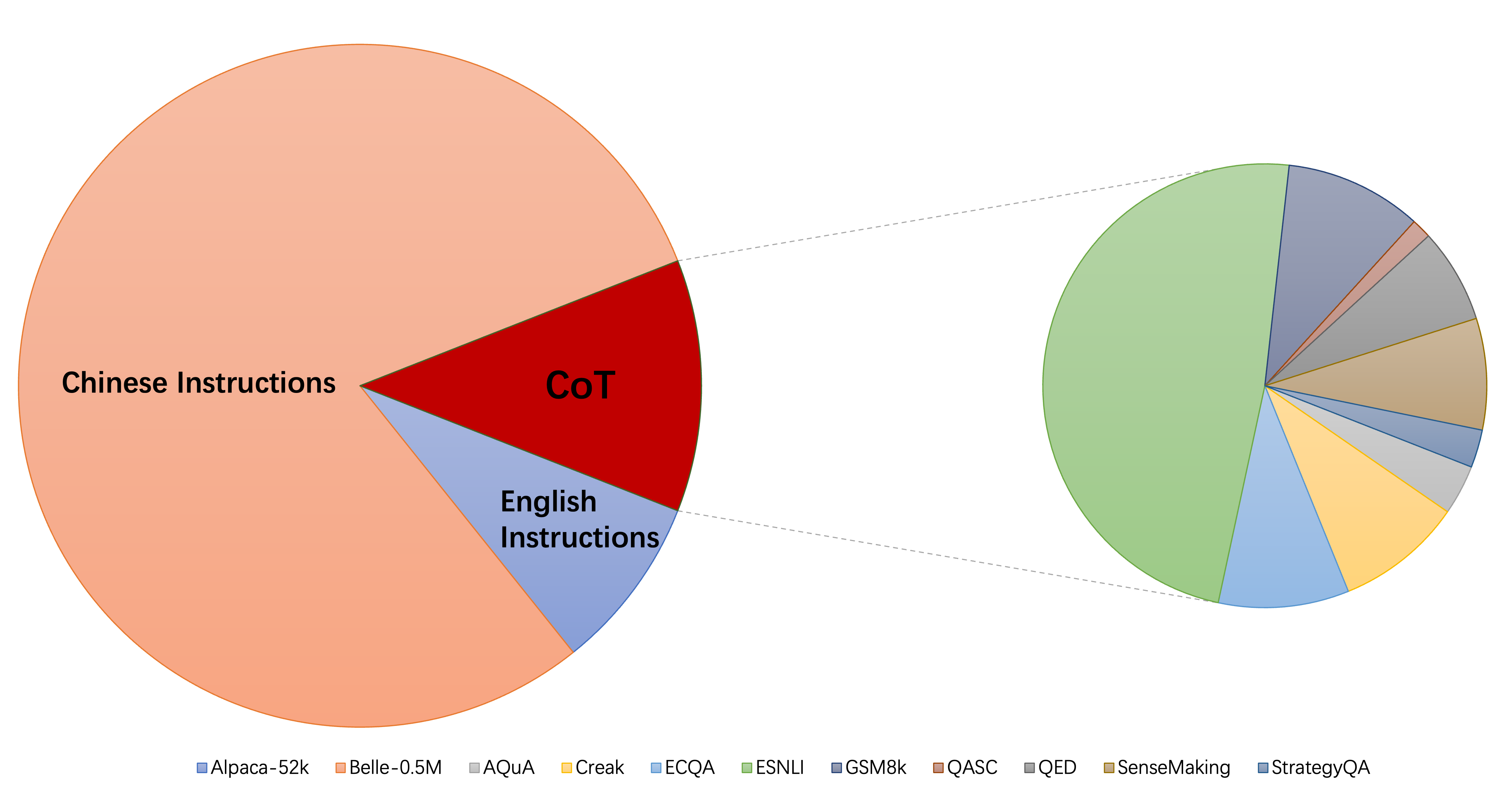 Текущая коллекция наборов данных по финиам инструкций состоит в основном из трех частей:
Текущая коллекция наборов данных по финиам инструкций состоит в основном из трех частей:
alpaca_data_cleaned.json : около 52 тыс. Английских инструкций с учетом.CoT_data.json : 9 наборов данных COT с участием около 75 тыс. Образцов. (Опубликовано Флан [7])belle_data_cn.json : около 0,5 м китайский | Образцы обучения с учетом. (Опубликовано Belle [8]) «без кот -кости» и «без CN» обозначают модели, которые исключают данные COT и китайские инструкции из их данных, соответственно.
«без кот -кости» и «без CN» обозначают модели, которые исключают данные COT и китайские инструкции из их данных, соответственно.
В приведенной выше таблице показаны два примера (с учетом численных расчетов), которые требуют определенного объема способности правильно реагировать. Как показано в среднем столбце, Ours w/o CoT не может генерировать правильный ответ, который показывает, что после того, как данные о создании не содержат данных COT, способность рассуждения модели значительно уменьшается. Это также демонстрирует, что данные COT необходимы для моделей LLM.

В приведенной выше таблице показаны два примера, которые требуют возможности отвечать на китайские инструкции. Как показано в правом столбце, либо сгенерированное содержание Ours w/o CN является необоснованным, либо китайские инструкции отвечают на английском языке Ours w/o CN . Это показывает, что удаление китайских данных во время создания, приведет к тому, что модель не сможет обрабатывать китайские инструкции, а также демонстрирует необходимость сбора данных о создании китайских инструкций.

В приведенной выше таблице показан относительно сложный пример, который требует как определенного накопления знаний о истории Китая, так и логической и полной способности государства исторических событий. Как показано в этой таблице, Ours w/o CN может генерировать лишь краткий и ошибочный ответ, потому что из -за отсутствия данных о создании китайского искусства, соответствующие знания китайской истории, естественно, отсутствуют. Хотя Ours w/o CoT перечислены некоторые соответствующие исторические события Китая, его логика выражения является самоупрекоемкой, что вызвано отсутствием данных COT. `
Таким образом, модели, основанные на нашем полном наборе данных (данные инструкций по английскому языку, китайскому и COT) могут значительно улучшить обоснование моделей и китайское обучение после способностей.
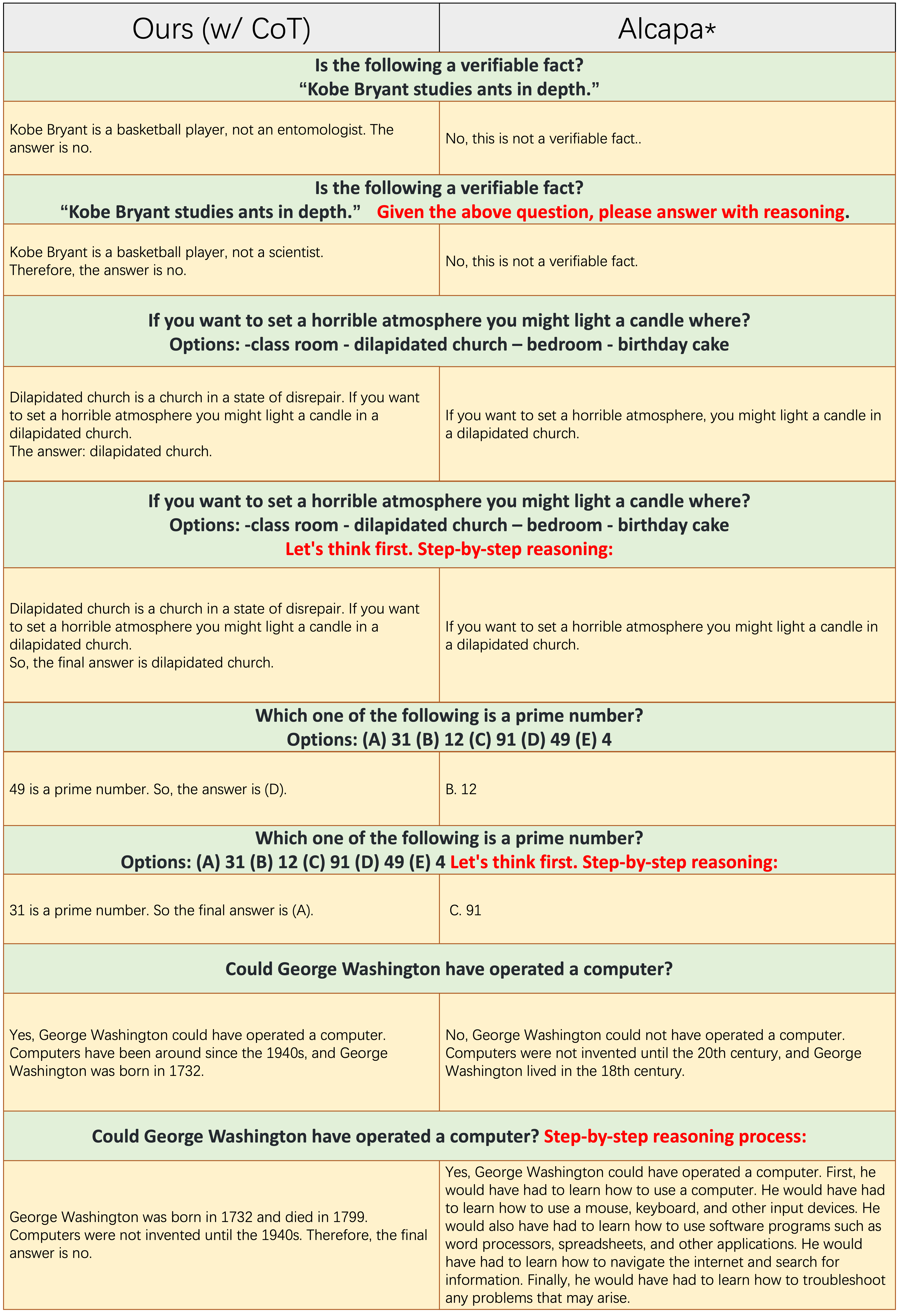 Образцы каждого нечетного количества строк не применяют подсказку кроватки, такие как «пошаговые рассуждения». Как
Образцы каждого нечетного количества строк не применяют подсказку кроватки, такие как «пошаговые рассуждения». Как Ours(w/CoT) так и Alpaca основаны на Llama-7B, и единственное различие между ними состоит в том, что данные о том, что Ours(w/CoT) имеют дополнительные данные COT, чем в Alpaca.
Из приведенной выше таблицы мы находим, что:
Ours(w/CoT) всегда генерирует правильное обоснование перед ответом, в то время как Alpaca не может генерировать какое -либо разумное обоснование, как показано в первых 4 примерах (вопросы сознания). Это показывает, что использование данных COT для создания может значительно улучшить способность рассуждения.Ours(w/CoT) , подсказка COT (например, CONCATENATE «пошаговый» с входным вопросом) мало влияет на простые примеры (например, вопросы здравого смысла) и оказывает важное влияние на сложные вопросы (например, вопросы, требующие рассуждения, такие как последние четыре примера). Количественное сравнение ответов на китайские инструкции. 
Наша модель создана из 7B Llama на 52K English Trancs и 0,5 -метровых китайских инструкциях. Стэнфордская Альпака (наша переосмысление) создана из 7B Llama на 52K English Trancs. Белль создана из цветущего 7B на 2B китайских инструкциях.
Из приведенной выше таблицы можно найти несколько наблюдений:
ours (w/ CN) обладает более сильной способностью понимать китайские инструкции. Для первого примера Alpaca не может различать часть instruction и input часть, пока мы это делаем.ours (w/ CN) не только предоставляет правильный код, но также предоставляет соответствующую китайскую аннотацию, а Alpaca - нет. Кроме того, как показано в 3-5 примерах, альпака может реагировать только на китайскую инструкцию с ответом на английском языке.ours (w/ CN) по инструкциям, требующим открытого ответа (как показано в последних двух примерах), все еще необходимо улучшить. Выдающаяся производительность Belle против таких инструкций обусловлена: 1. ее модель Bloom Backbone сталкивается с гораздо более многоязычными данными во время предварительного обучения; 2. Его китайские данные о создании обучения больше, чем наши, то есть 2M против 0,5 м. Количественное сравнение ответов на английские инструкции. Цель этого подраздела состоит в том, чтобы выяснить, оказывает ли создание китайских инструкций негативное влияние на альпаку. 
Из приведенной выше таблицы мы находим, что:
ours (w/ CN) показывает больше деталей, чем в Alpaca, например, для третьего примера ours (w/ CN) перечисляют три провинции больше, чем Alpaca. Пожалуйста, цитируйте репо, если вы используете сбор данных, код и экспериментальные результаты в этом репо.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Для данных и моделей, пожалуйста, цитируйте исходные данные, параметры, а также источник LLMS.
Мы хотели бы выразить свою особую благодарность Apus Ailme Lab за спонсирование 8 A100 графических процессоров для экспериментов.
(Вернуться к вершине)


