Alpaca CoT
1.0.0
中文| Inglés

Este es el repositorio del proyecto Alpaca-CoT , cuyo objetivo es construir una plataforma de Finetuning (IFT) de instrucciones con una amplia recopilación de instrucciones (especialmente los conjuntos de datos COT) y una interfaz unificada para varios modelos de lenguaje grande y métodos de eficiencia de parámetros. Estamos constantemente expandiendo nuestra recopilación de datos de ajuste de instrucciones e integrando más LLM y métodos más eficientes en los parámetros. Además, creamos una nueva rama tabular_llm para construir un LLM tabular para resolver tareas de inteligencia de tabla.
Puede brindarnos cálidamente los conjuntos de datos de instrucciones no recolectados (o sus fuentes). Los formatearemos de manera uniforme, entrenaremos el modelo de Alpaca (y otros LLM en el futuro temprano) con estos conjuntos de datos, los puntos de control de código abierto y realizamos estudios empíricos extensos. Esperamos que nuestro proyecto pueda hacer una contribución modesta al proceso de código abierto de modelos de idiomas grandes y reducir su umbral para que los investigadores de PNL comiencen.

Si desea utilizar otros métodos además de Lora, instale la versión editada en nuestro proyecto pip install -e ./peft .
12.8: LLM InternLM se fusionó.
8.16: 4bit quantization está disponible para lora , qlora y adalora .
8.16: Se fusionó los métodos de los parámetros y el consumo de Qlora , Sequential adapter y Parallel adapter .
7.24: LLM ChatGLM v2 se fusionó.
7.20: LLM Baichuan se fusionó.
6.25: Agregue el código de evaluación del modelo, incluidos Belle y MMCU.
GPT4Tools , Auto CoT , pCLUE .tabular_llm para construir un LLM tabular. Recopilamos los datos de ajuste de instrucción para tareas relacionadas con la tabla como la respuesta de las preguntas de la tabla y los usamos para ajustar los LLM en este repositorio.MOSS se fusionó.GAOKAO , camel , FLAN-Muffin , COIG .webGPT , dolly , baize , hh-rlhf , OIG(part) .multi-turn conversation por @Paulcx.firefly , instruct , Code Alpaca se recopilan y formatean, que se pueden encontrar aquí.Parameter merging , Local chatting , Batch predicting y Web service building por @Weberr.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 y natural-instructions se recopilan y formatean.CoT_CN_data.json se puede encontrar aquí. 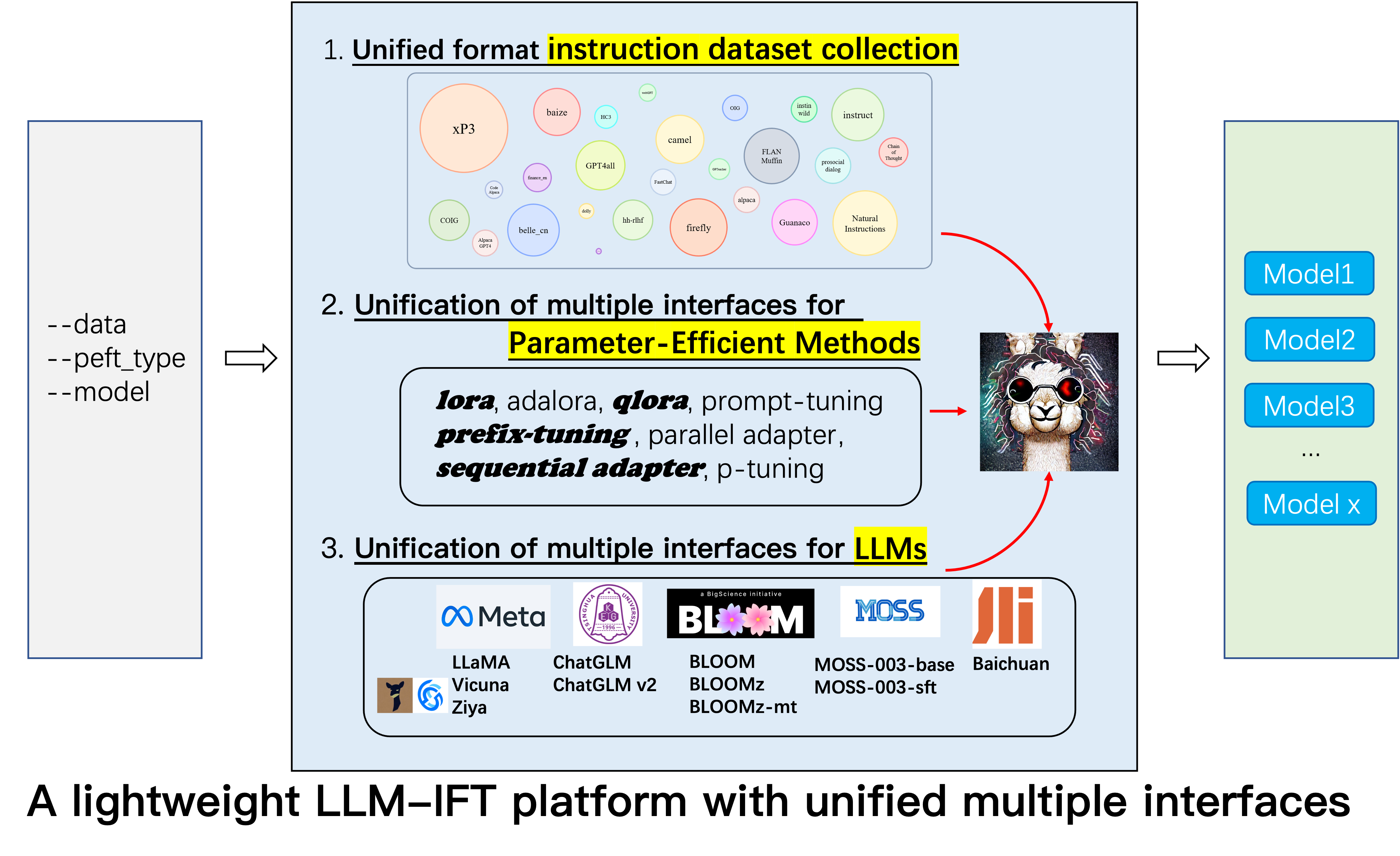
Llama [1] es un gran trabajo que demuestra la increíble habilidad de disparo cero y pocos disparos. Reduce significativamente el costo de la capacitación, la delicadeza y el uso de modelos competitivos de idiomas grandes, es decir, LLAMA-13B supera a GPT-3 (175B) y LLAMA-65B es competitivo con Palm-540B. Recientemente, para aumentar la capacidad de seguimiento de instrucciones de LLAMA, Stanford Alpaca [2] Finetuned Llama-7B en 52k Datos de seguimiento de instrucciones generados por las técnicas de autoinstructo [3]. Sin embargo, en la actualidad, la comunidad de investigación de LLM todavía enfrenta tres desafíos: 1. Incluso LLAMA-7B todavía tiene altos requisitos para calcular los recursos; 2. Hay pocos conjuntos de datos de código abierto para instrucción Finetuning; y 3. Hay una falta de estudio empírico sobre el impacto de varios tipos de instrucción sobre habilidades del modelo, como la capacidad de responder a la instrucción china y al razonamiento de la cuna.
Con este fin, proponemos este proyecto, que aprovecha varias mejoras que se propusieron posteriormente, con las siguientes ventajas:
7b , 13b y 30b de los modelos LLAMA se pueden entrenar fácilmente en un solo 80G A100. Hasta donde sabemos, este trabajo es el primero en estudiar el razonamiento de COT basado en Llama y Alpaca. Por lo tanto, abreviamos nuestro trabajo a Alpaca-CoT .
El tamaño relativo de los conjuntos de datos recopilados se puede mostrar con este gráfico:
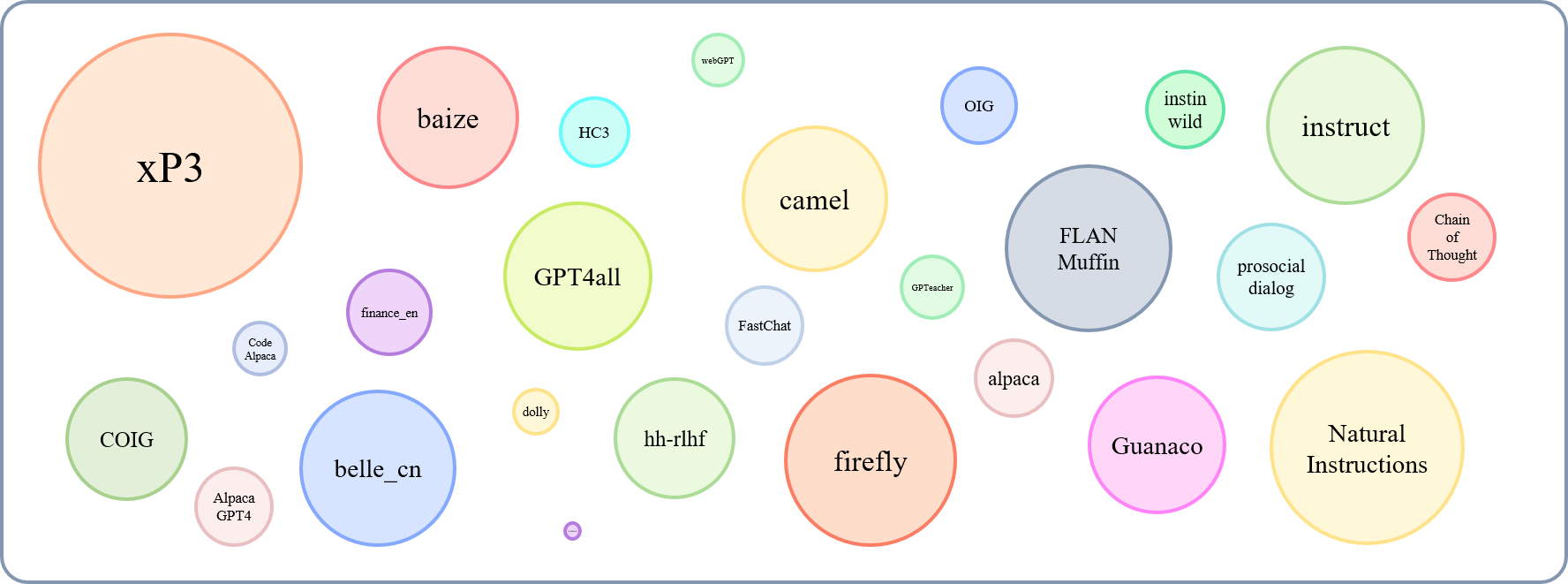
Refiriéndose a esto (@yaodongc), etiquetamos cada conjunto de datos recopilado de acuerdo con las siguientes reglas:
(Lang) Tags linguales:
(Tarea) Task-Tags:
(Gen) Método de generación:
| Conjunto de datos | Numeros | Lang | Tarea | Género | Tipo | SRC | Url |
|---|---|---|---|---|---|---|---|
| Cadena de pensamiento | 74771 | EN/CN | MONTE | Hg | instruir con el razonamiento de la cuna | anotando cuna en los datos existentes | descargar |
| GPT4All | 806199 | Interno | MONTE | COLUMNA | código, historias y diálogo | destilación de GPT-3.5-TURBO | descargar |
| GpTeacher | 29013 | Interno | MONTE | SI | General, Roleplay, Formador de herramientas | GPT-4 y formador de herramientas | descargar |
| Guanaco | 534610 | Ml | MONTE | SI | Varias tareas lingüísticas | texto-Davinci-003 | descargar |
| HC3 | 37175 | EN/CN | TS | MEZCLA | evaluación del diálogo | humano o chatgpt | descargar |
| alpaca | 52002 | Interno | MONTE | SI | instrucción general | texto-Davinci-003 | descargar |
| Instrucciones naturales | 5040134 | Ml | MONTE | COLUMNA | diversas tareas de PNL | Colección de conjuntos de datos anotados por humanos | descargar |
| belle_cn | 1079517 | CN | TS/MT | SI | Razonamiento general, matemático, diálogo | texto-Davinci-003 | descargar |
| instinwild | 52191 | EN/CN | MONTE | SI | Generación, Open-Qa, tormenta mental | texto-Davinci-003 | descargar |
| diálogo prosocial | 165681 | Interno | TS | MEZCLA | diálogo | GPT-3 reescribe preguntas + comentarios humanos manualmente | descargar |
| finanzas_en | 68912 | Interno | TS | COLUMNA | QA relacionado con la financiación | GPT3.5 | descargar |
| xp3 | 78883588 | Ml | MONTE | COLUMNA | Una colección de indicaciones y conjuntos de datos en 46 de idiomas y 16 tareas de PNL | Colección de conjuntos de datos anotados por humanos | descargar |
| luciérnaga | 1649398 | CN | MONTE | COLUMNA | 23 tareas de PNL | Colección de conjuntos de datos anotados por humanos | descargar |
| instruir | 888969 | Interno | MONTE | COLUMNA | Aumentado de GPT4All, Alpaca, conjuntos de datos de código abierto | Aumento realizado utilizando las herramientas NLP avanzadas proporcionadas por Allenai | descargar |
| Código alpaca | 20022 | Interno | TS | SI | Generación de código, edición, optimización | texto-Davinci-003 | descargar |
| Alpaca_gpt4 | 52002 | EN/CN | MONTE | SI | instrucción general | Generado por GPT-4 usando Alpaca | descargar |
| webgpt | 18994 | Interno | TS | MEZCLA | Recuperación de información (IR) QA | GPT-3 sintonizado, cada instrucción tiene dos salidas, seleccione mejor una | descargar |
| Dolly 2.0 | 15015 | Interno | TS | Hg | QA cerrado, resumen y etc., Wikipedia como referencias | anotado por humanos | descargar |
| bayeta | 653699 | Interno | MONTE | COLUMNA | Una colección de preguntas de Alpaca, Quora, Stackoverflow y Medquad | Colección de conjuntos de datos anotados por humanos | descargar |
| HH-RLHF | 284517 | Interno | TS | MEZCLA | diálogo | diálogo entre modelos humanos y rlhf | descargar |
| Oig (parte) | 49237 | Interno | MONTE | COLUMNA | creado a partir de varias tareas, como preguntas y respuesta | Usando el aumento de datos, la recopilación de conjuntos de datos anotados por humanos | descargar |
| Gaokao | 2785 | CN | MONTE | COLUMNA | Preguntas de opción múltiple, relleno en blanco y abierta del examen | anotado por humanos | descargar |
| camello | 760620 | Interno | MONTE | SI | Conversaciones de juego en AI Society, Code, Math, Physics, Chemistry, Biolog | GPT-3.5-TURBO | descargar |
| Flan-muffin | 1764800 | Interno | MONTE | COLUMNA | 60 tareas de PNL | Colección de conjuntos de datos anotados por humanos | descargar |
| Coig (Flaginstructo) | 298428 | CN | MONTE | COLUMNA | Examen de recolección de fron, traducido, instrucciones de alineación de valor humano y chat de múltiples ronda de corrección de corrección contrafactiva | Uso de herramientas automáticas y verificación manual | descargar |
| Gpt4tools | 71446 | Interno | MONTE | SI | una colección de instrucciones relacionadas con la herramienta | GPT-3.5-TURBO | descargar |
| Sharechat | 1663241 | Interno | MONTE | MEZCLA | instrucción general | Crowdsourcing para recopilar conversaciones entre personas y chatgpt (sharegpt) | descargar |
| Cuna automática | 5816 | Interno | MONTE | COLUMNA | aritmética, común, simbólica y otras tareas de razonamiento lógico | Colección de conjuntos de datos anotados por humanos | descargar |
| MUSGO | 1583595 | EN/CN | TS | SI | instrucción general | texto-Davinci-003 | descargar |
| ultrachat | 28247446 | Interno | Preguntas sobre el mundo, la escritura y la creación, la asistencia sobre los materiales existentes | Dos GPT-3.5-Turbo separados | descargar | ||
| Medicina-medicina | 792099 | CN | TS | COLUMNA | Preguntas sobre asesoramiento médico | gatear | descargar |
| CSL | 396206 | CN | MONTE | COLUMNA | Generación de texto en papel, extracción de palabras clave, resumen de texto y clasificación de texto | gatear | descargar |
| pcLue | 1200705 | CN | MONTE | COLUMNA | instrucción general | descargar | |
| News_commentary | 252776 | CN | TS | COLUMNA | traducir | descargar | |
| Stackllama | hacer | Interno |
Puede descargar todos los datos formateados aquí. Entonces debe ponerlos en la carpeta de datos.
Puede descargar todos los puntos de control capacitados en varios tipos de datos de instrucciones desde aquí. Luego, después de configurar LoRA_WEIGHTS (en generate.py ) en la ruta local, puede ejecutar directamente la inferencia del modelo.
Todos los datos en nuestra colección están formateados en las mismas plantillas, donde cada muestra es la siguiente:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Tenga en cuenta que, para conjuntos de datos COT, primero usamos la plantilla proporcionada por FLAN para cambiar el conjunto de datos original en varios formularios de cadena de pensamientos, y luego la convertimos al formato anterior. El script de formato se puede encontrar aquí.
pip install -r requirements.txt
Tenga en cuenta que, asegúrese de Python> = 3.9 al Finetuning ChatGlm.
Peft
pip install -e ./peft
Para que los investigadores realicen una investigación sistemática de IFT sobre LLM, hemos recopilado diferentes tipos de datos de instrucciones, LLM múltiples integradas e interfaces unificadas, lo que facilita la personalización de la colocación deseada:
--model_type : Establezca el LLM que desea usar. Actualmente, [Llama, Chatglm, Bloom, Moss] son compatibles. Los dos últimos tienen capacidades chinas fuertes, y más LLM se integrarán en el futuro.--peft_type : configure el PEFT que desea usar. Actualmente, se admiten [Lora, Adalora, Tuning de prefijo, Tuning P, Avecute].--data : Establezca el tipo de datos utilizado para IFT para adaptar flexiblemente la capacidad de cumplimiento del comando deseada. Por ejemplo, para una fuerte capacidad de razonamiento, establezca "Alpaca-Cot", para una fuerte capacidad china, establecer "Belle1.5m", para la capacidad de codificación y generación de historias, establecer "GPT4All", y para la capacidad de respuesta relacionada con el financiamiento, establecer "Finanzas".--model_name_or_path : esto está configurado para cargar diferentes versiones de los pesos del modelo para el objetivo LLM --model_type . Por ejemplo, para cargar la versión 13B de pesos 13b de Llama, puede establecer Decapoda-Research/LLAMA-13B-HF.GPU único
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
Nota: Para múltiples conjuntos de datos, puede usar --data como --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Tenga en cuenta que load_in_8bit aún no es adecuado para chatglm, por lo que batch_size debe ser más pequeño que otros.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Tenga en cuenta que también puede pasar la ruta local (donde se guardan los pesos LLM) a --model_name_or_path . Y el tipo de datos --data se puede establecer libremente de acuerdo con sus intereses.
GPU múltiples
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Tenga en cuenta que load_in_8bit aún no es adecuado para chatglm, por lo que batch_size debe ser más pequeño que otros.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Se pueden encontrar más detalles de instrucciones que se pueden encontrar aquí de la finidad y la inferencia donde nos modificamos. Tenga en cuenta que las carpetas saved-xxx7b son la ruta de guardado para los pesos de Lora, y los pesos de los llamas se descargan automáticamente de la cara abrazada.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Este documento selecciona dos puntos de referencia de evaluación, Belle-Eval y MMCU, para evaluar de manera integral las competencias de LLM en chino.
Belle-Eval está construida por autoestructura con ChatGPT, que tiene 1,000 instrucciones diversas que involucran 10 categorías que cubren tareas comunes de la PNL (por ejemplo, QA) y tareas desafiantes (por ejemplo, código y matemáticas). Utilizamos ChatGPT para calificar las respuestas del modelo en función de las respuestas doradas. Este punto de referencia se considera como la evaluación de la capacidad AGI (seguimiento de instrucciones).
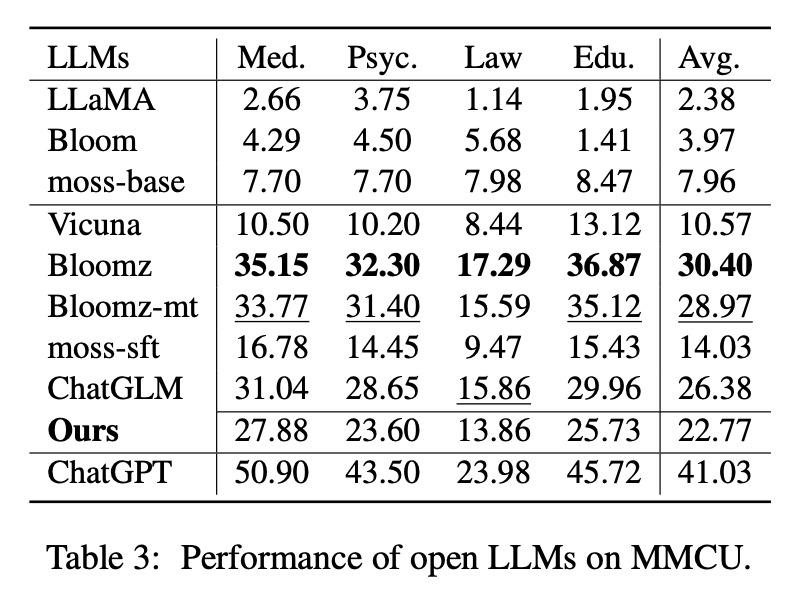
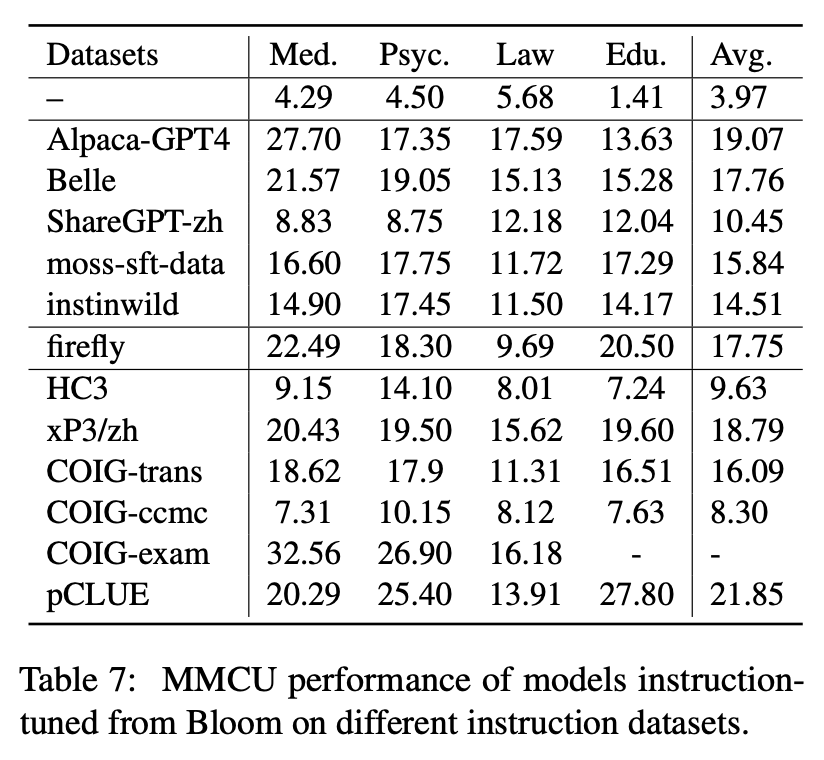
MMCU es una colección de preguntas chinas de opción múltiple en cuatro disciplinas profesionales de medicina, derecho, psicología y educación (por ejemplo, examen de Gaokao). Permite a los LLM tomar exámenes en la sociedad humana de una manera de prueba de opción múltiple, lo que lo hace adecuado para evaluar la amplitud y profundidad de conocimiento de los LLM en múltiples disciplinas.
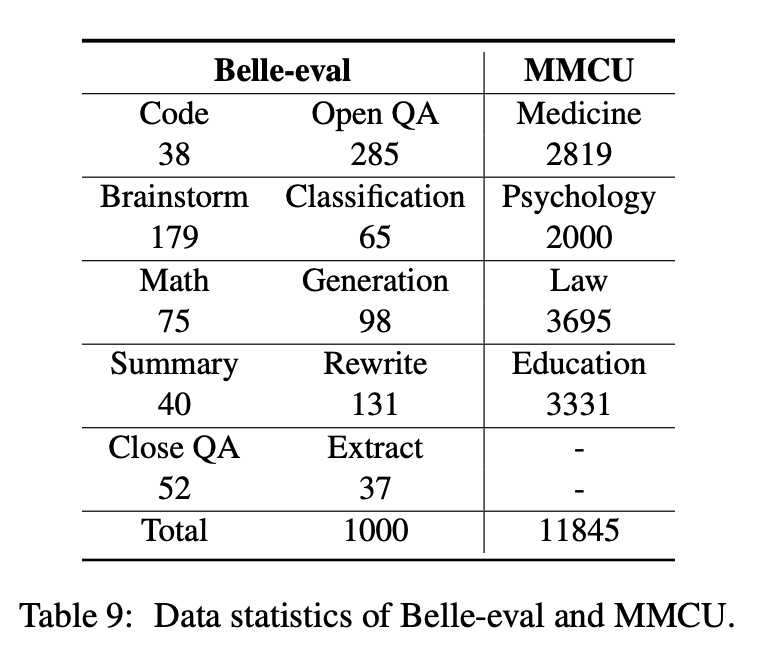
Las estadísticas de datos de Belle-EVal y MMCU se muestran en la tabla de arriba.
Realizamos experimentos para estudiar los tres factores principales en las LLM de ajuste de instrucciones: bases LLM, métodos de eficiencia de parámetros, conjuntos de datos de instrucciones chinas.
Para LLMS abiertos, probamos LLMS y LLM existentes ajustados con Lora en Alpaca-GPT4 en Belle-Eval y MMCU, respectivamente.
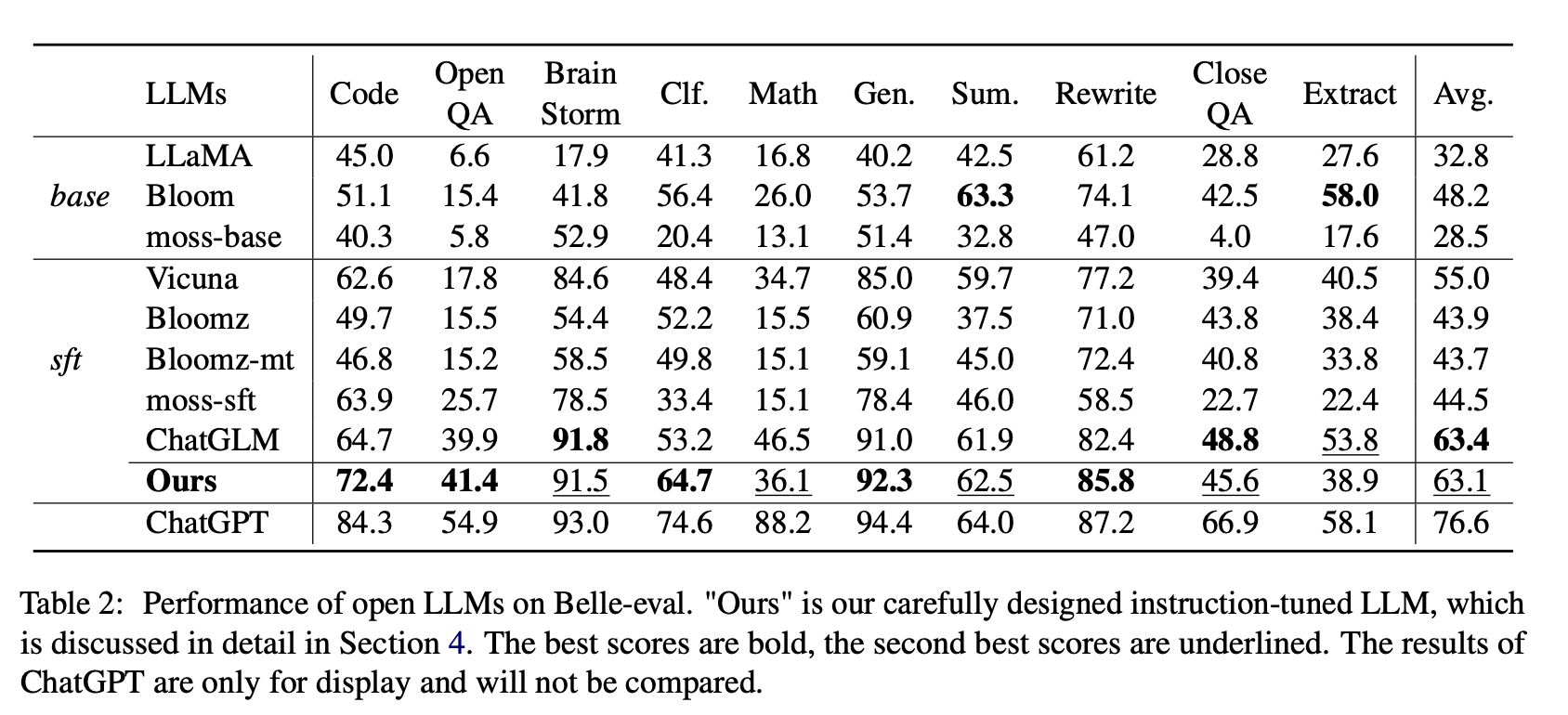
La Tabla 2 muestra los puntajes de LLM en Belle-Eval. La Tabla 3 muestra la precisión de LLM en MMCU. Atinan todos los LLM abiertos con el mismo método de eficiencia de parámetros Lora y el mismo conjunto de datos de instrucciones Alpaca-GPT4.
Resultados experimentales:
Evaluación de los LLM existentes
Actuación en Belle-Eval
(1) Para LLMS base, Bloom realiza lo mejor.
(2) Para SFT LLMS, ChatGlm supera a otros por grandes márgenes, gracias al hecho de que está entrenado con la mayoría de los tokens chinos y HFRL.
(3) Las categorías abiertas QA, Math, Closeqa y Extract siguen siendo muy desafiantes para las LLM abiertas existentes.
(4) Vicuna y Moss-SFT tienen mejoras claras en comparación con sus bases, llama y base de musgo, respectivamente.
(5) En contraste, el rendimiento de los modelos SFT, Bloicz y Bloicz-MT, se reduce en comparación con la floración del modelo base, porque tienden a generar una respuesta más corta.
Rendimiento en MMCU
(1) Todas las LLM de base funcionan mal porque es casi difícil generar contenido en el formato especificado antes de ajustar los números de opción de salida, por ejemplo.
(2) Todos los SFT LLM superan a sus LLM de base correspondientes, respectivamente. En particular, Bloicz realiza lo mejor (incluso Beats Chatglm) porque puede generar el número de opción directamente según lo requerido sin generar otro contenido irrelevante, lo que también se debe a las características de datos de su conjunto de datos de ajuste fino supervisado XP3.
(3) Entre las cuatro disciplinas, la ley es la más desafiante para los LLM.
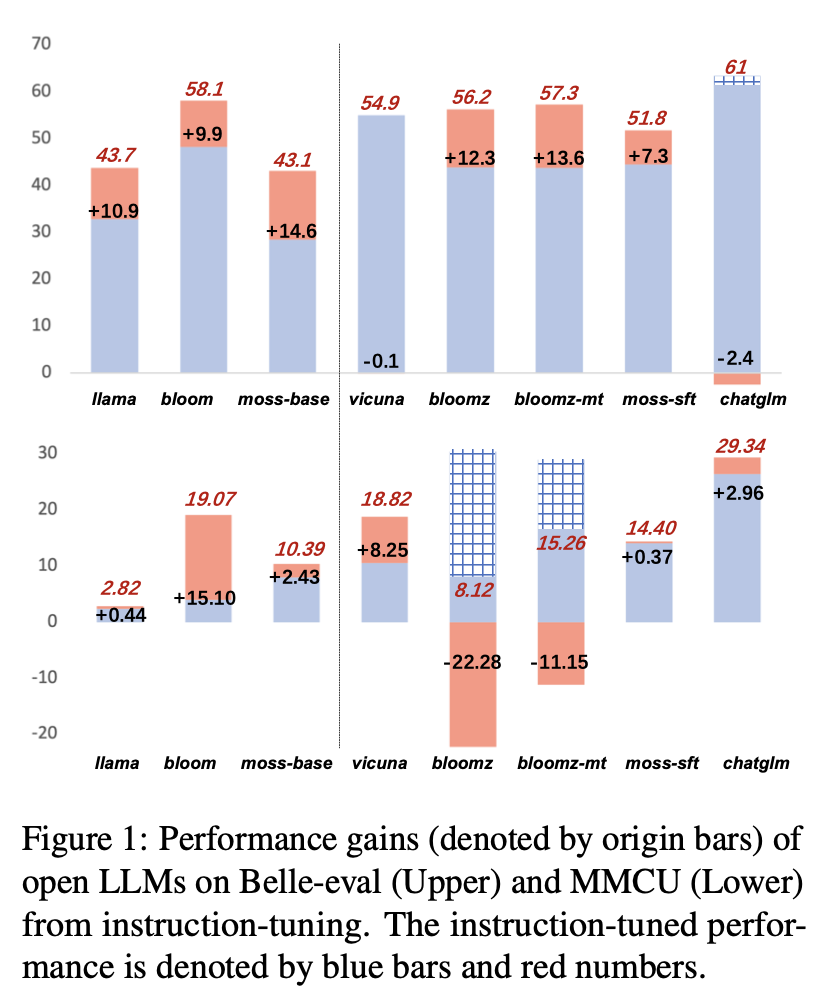
Los resultados de rendimiento de LLM después del ajuste de instrucciones en Alpaca-GPT4-ZH se muestran en la Figura 1.
Instruccionando diferentes LLMS
(1) En Belle-Eval, la mejora del rendimiento de los SFT LLM traídos por el ajuste de instrucciones no es tan significativa como la de los LLM de base, excepto SFT Bloomz y Bloombz-MT.
(2) El rendimiento del encuentro de Vicuna y Chatglm cae después del ajuste de instrucciones, porque Vicuna está entrenado a partir de conversaciones reales de Human-ChatGPT, con mejor calidad que Alpaca-GPT4. ChatGlm adopta HFRL, que ya no puede ser adecuado para un ajuste de instrucciones adicional.
(3) En MMCU, la mayoría de los LLM logran aumentos de rendimiento después del ajuste de instrucciones, con la excepción de Bloicz y Bloicz-MT, que inesperadamente han disminuido significativamente el rendimiento.
(4) Después del ajuste de instrucciones, Bloom tiene mejoras significativas y funciona bien en ambos puntos de referencia. Aunque el chatglm ritmos la floración de manera consistente, sufre una caída de rendimiento durante el ajuste de las instrucciones. Por lo tanto, entre todos los LLM abiertos, Bloom es más adecuado como modelo de base en los experimentos posteriores para la exploración de instrucciones chinas.
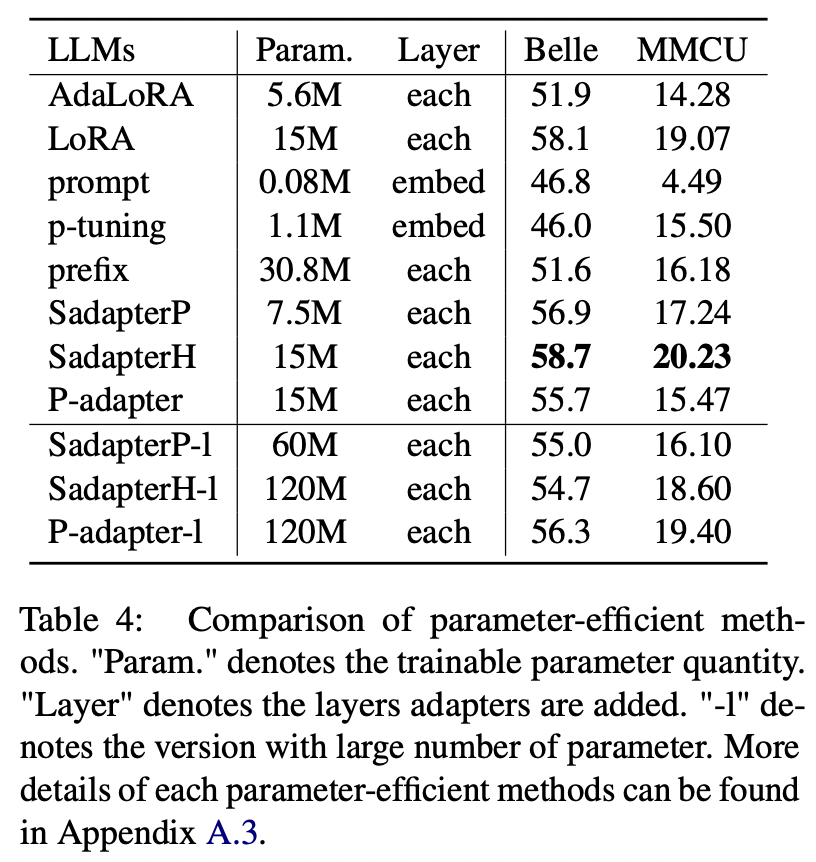
Para los métodos de los parámetros que no sean Lora, el documento recopila una gama de métodos eficientes de parámetros para ajustar la floración de instrucciones en el conjunto de datos Alpaca-GPT4.
Resultados experimentales:
Comparación de métodos eficientes de parámetros
(1) Sadapterh realiza lo mejor entre todos los métodos de eficiencia de parámetros, que pueden usarse como una alternativa a Lora.
(2) El ajuste de P y el ajuste anticuado de los otros por grandes márgenes, lo que indica que solo agregar capas capacitables en la capa de incrustación no es suficiente para admitir LLM para tareas de generación.
(3) Aunque Adalora es una mejora de Lora, su rendimiento tiene una caída clara, posiblemente porque los parámetros capacitables de Lora para LLM no son adecuados para una mayor reducción.
(4) Comparando las partes superiores e inferiores, se puede ver que aumentar el número de parámetros entrenables para adaptadores secuenciales (es decir, sadapterp y sadapterh) no provoca ganancia, mientras que el fenómeno opuesto se observa para adaptadores paralelos (es decir, adaptador P)
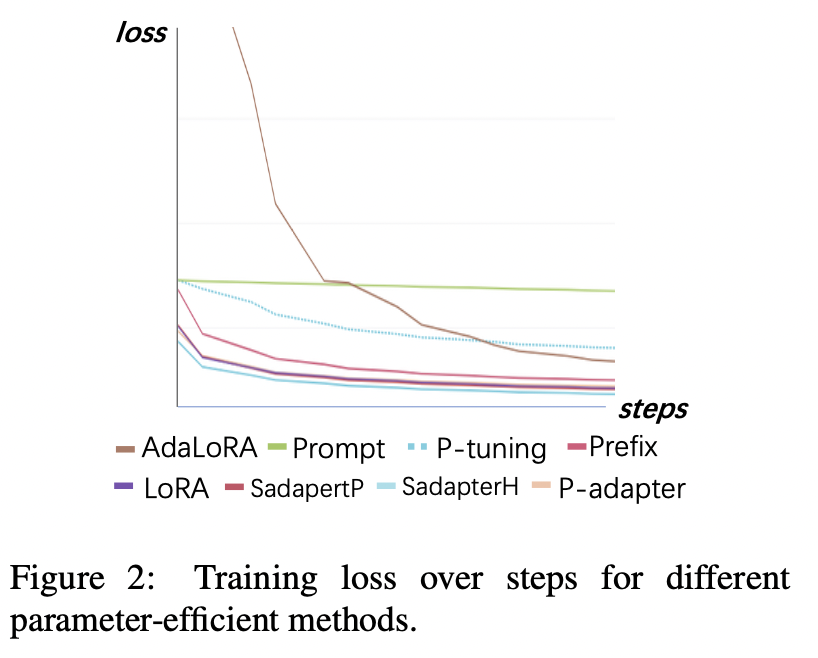
Pérdida de entrenamiento
(1) El ajuste rápido y el ajuste P convergen el más lento y tiene las pérdidas más altas después de la convergencia. Esto muestra que los adaptadores de incrustación no son adecuados para el ajuste de instrucciones LLM.
(2) La pérdida inicial de Adalora es muy alta porque requiere el aprendizaje simultáneo de la asignación de presupuesto de parámetros, lo que hace que el modelo no pueda adaptarse bien a los datos de capacitación.
(3) Los otros métodos pueden converger rápidamente en los datos de entrenamiento y ajustarlos bien.
Para el impacto de varios tipos de conjuntos de datos de instrucciones chinos, los autores recopilan instrucciones populares chinas abiertas (como se muestra en la Tabla 5) para ajustar la floración con Lora.
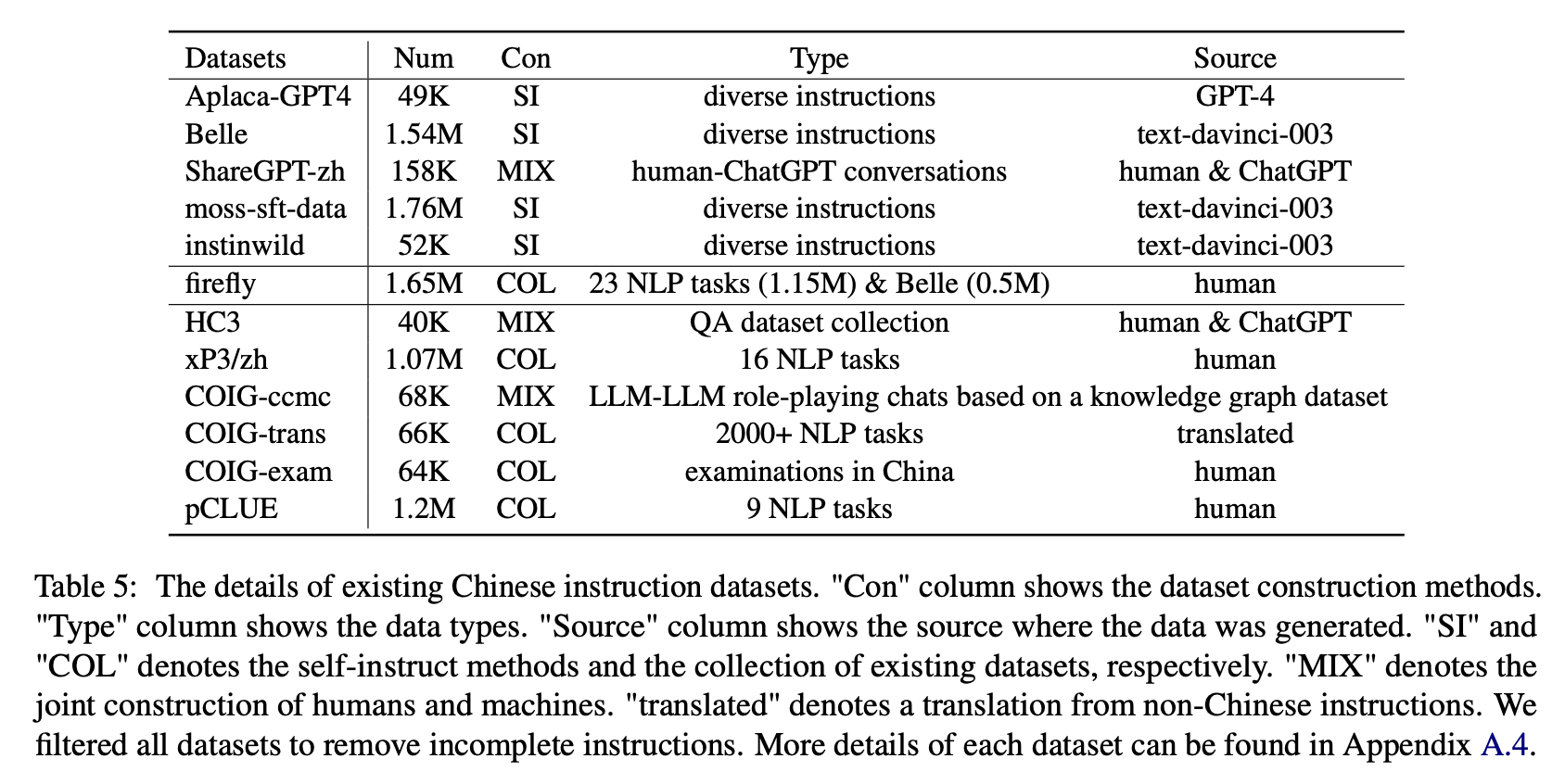
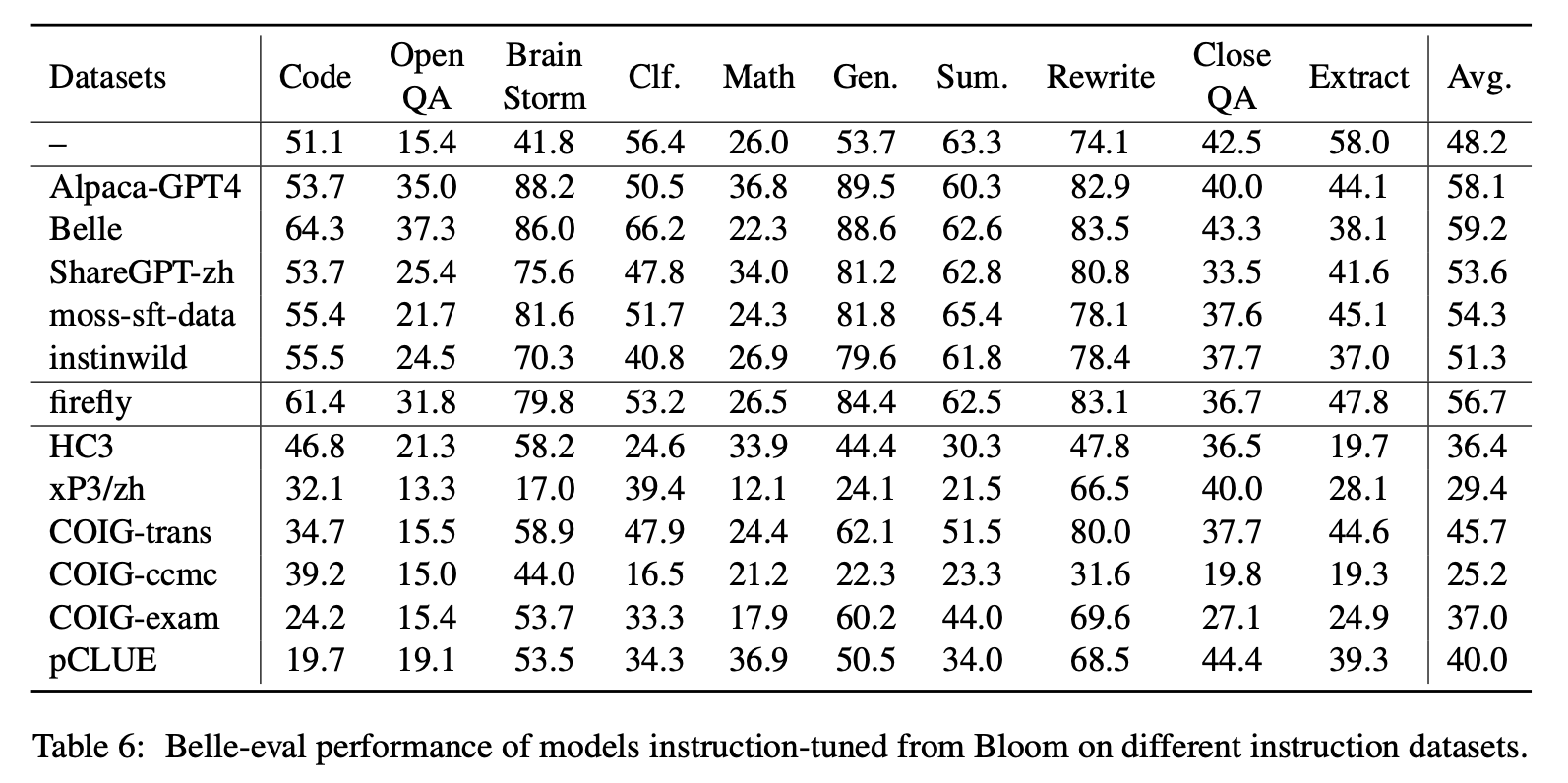
La Tabla 6 y la Tabla 7 muestran el ajuste de Bloom en diferentes conjuntos de datos de instrucciones.
Resultados experimentales:
Actuación en Belle-Eval
(1) Los datos de instrucción construidos por ChatGPT (por ejemplo, utilizando métodos de autoinstrucción o recopilar conversaciones reales de CHATGPT humano) mejoran constantemente la capacidad de seguimiento de la instrucción con aumentos de puntaje de 3.1 ∼ 11 puntos.
(2) Entre estos conjuntos de datos, Belle tiene el mejor rendimiento debido a la mayor cantidad de datos de instrucciones. Sin embargo, el rendimiento de los modelos capacitados en datos MOSS-SFT, que contienen más datos creados de manera similar, es insatisfactorio.
(3) El rendimiento traído por las instrucciones de Alpaca-GPT4 es el segundo mejor, con solo 49K siendo comparable a la belleza de 1.54m.
(4) Instinwild trae las menores ganancias de rendimiento entre ellas porque las instrucciones de semillas que se arrastran del tweet ("en la naturaleza") no son tan completas como las (como la alpaca) cuidadosamente diseñadas por los humanos.
(5) Estos datos basados en ChatGPT tienen principalmente un efecto de mejora significativo en las tareas de generación abierta, como la tormenta cerebral y la generación, mientras que hay una disminución significativa en las tareas que requieren altas habilidades de comprensión de lectura, como QA y extracto cercanos.
(6) Estos conjuntos de datos de instrucciones causan daños a la capacidad de seguimiento de instrucciones del modelo, porque la forma y la intención de cada NLP o conjunto de datos de examen son unitarios, que pueden ser sobrecargados fácilmente.
(7) Entre ellos, Coig-Trans funciona mejor porque involucra más de 2000 tareas diferentes con una amplia variedad de instrucciones de tareas. En contraste, XP3 y CoIG-CCMC tienen el peor impacto negativo en el rendimiento del modelo. Ambos solo cubren unos pocos tipos de tareas (traducción y control de calidad para las primeras conversaciones de corrección contrafactual para la segunda), que apenas cubren las instrucciones y tareas populares para los humanos.
Rendimiento en MMCU
(1) El ajuste de instrucciones en cada conjunto de datos siempre puede dar como resultado una mejora del rendimiento.
(2) Entre los datos basados en ChatGPT que se muestran en la parte superior, ShareGPT-ZH tiene un rendimiento inferior a otros por grandes márgenes. Esto puede deberse al hecho de que los usuarios reales rara vez hacen preguntas de opción múltiple sobre temas académicos.
(3) Entre los datos de colección del conjunto de datos que se muestran en la parte inferior, HC3 y CoIG-CCMC dan como resultado la precisión más baja porque las preguntas únicas de HC3 son solo 13K, y el formato de tarea de COIG-CCMC es significativamente diferente de MMCU.
(4) Coig-Exam trae la mayor mejora de la precisión, beneficiándose del formato de tarea similar al de MMCU.
Otros cuatro factores: cuna, expansión del vocabulario chino, lenguaje de indicaciones y alineación del valor humano
Para COT, los autores comparan el rendimiento antes y después de agregar datos de cuna durante el ajuste de instrucciones.
Configuración del experimento:
Recopilamos 9 conjuntos de datos COT y sus indicaciones de FLAN, y luego los traducimos al chino usando el traductor de Google. Comparan el rendimiento antes y después de agregar datos de cuna durante el ajuste de instrucciones.
Primero tenga en cuenta la forma de agregar datos de cuna como "Alpaca-GPT4+COT". Además, agregue una oración "先思考 再决定 再决定" ("Piense en paso a paso" en chino) al final de cada instrucción, para inducir el modelo a responder a las instrucciones basadas en la cuna y etiquetar de esta manera como "alpaca-gpt4+cot*".
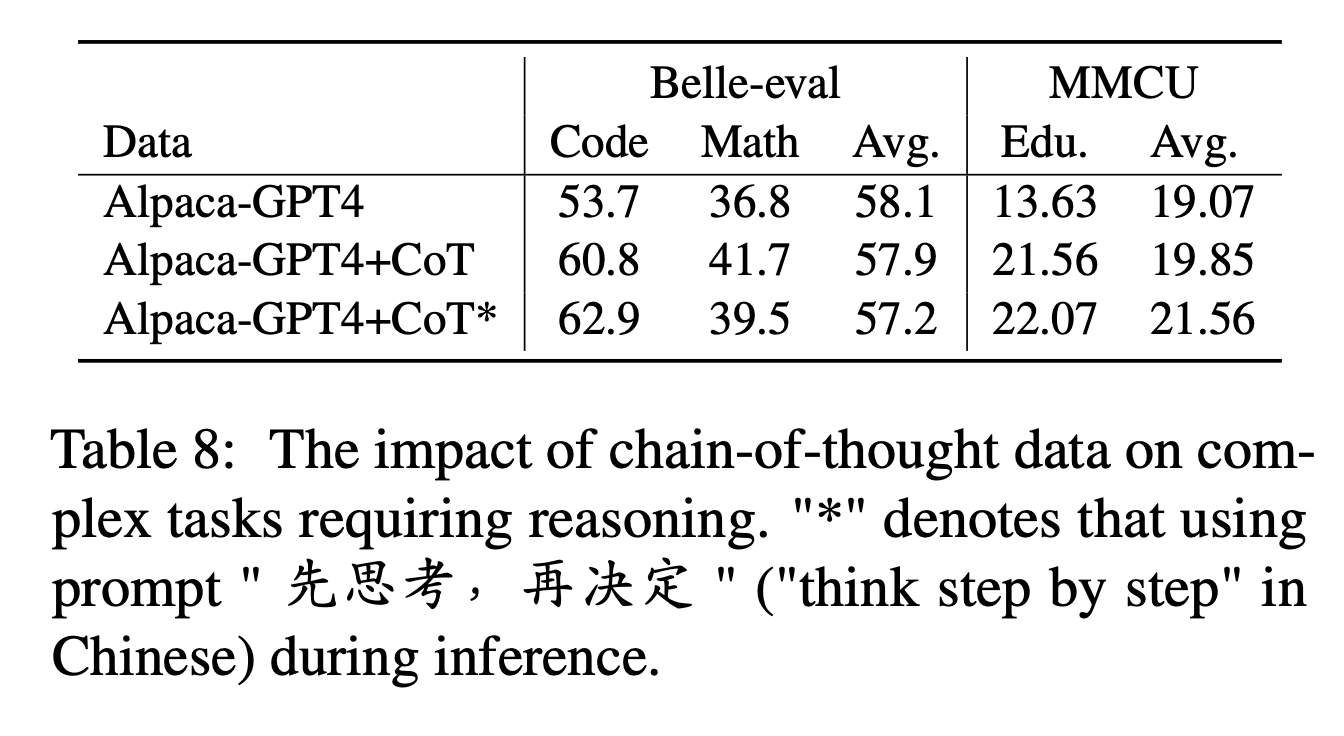
Resultados experimentales:
"Alpaca-GPT4+cot" supera "Alpaca-GPT4" en tareas de código y matemáticas que requieren una fuerte capacidad de razonamiento. Además, también hay una mejora significativa en la tarea de educación MMCU.
Como se muestra en la línea de "Alpaca-GPT4+COT*", la oración simple puede mejorar aún más el rendimiento del código y la educación de las tareas de razonamiento, mientras que el rendimiento matemático es ligeramente inferior al "Alpaca-GPT4+COT". Esto puede requerir una mayor exploración de indicaciones más robustas.
Para la expansión del vocabulario chino, los autores prueban la influencia del número de tokens chinos en el vocabulario del tokenizador sobre la capacidad de LLMS para expresar chino. Por ejemplo, si un personaje chino está en el vocabulario, puede ser representado por un solo token, de lo contrario puede requerir múltiples tokens para representarlo.
Configuración del experimento: los autores realizan principalmente experimentos en LLAMA, que utiliza la pieza de oración (tamaño de vocabulario de 32k de los caracteres chinos) que cubren menos caracteres chinos que Bloom (250k).
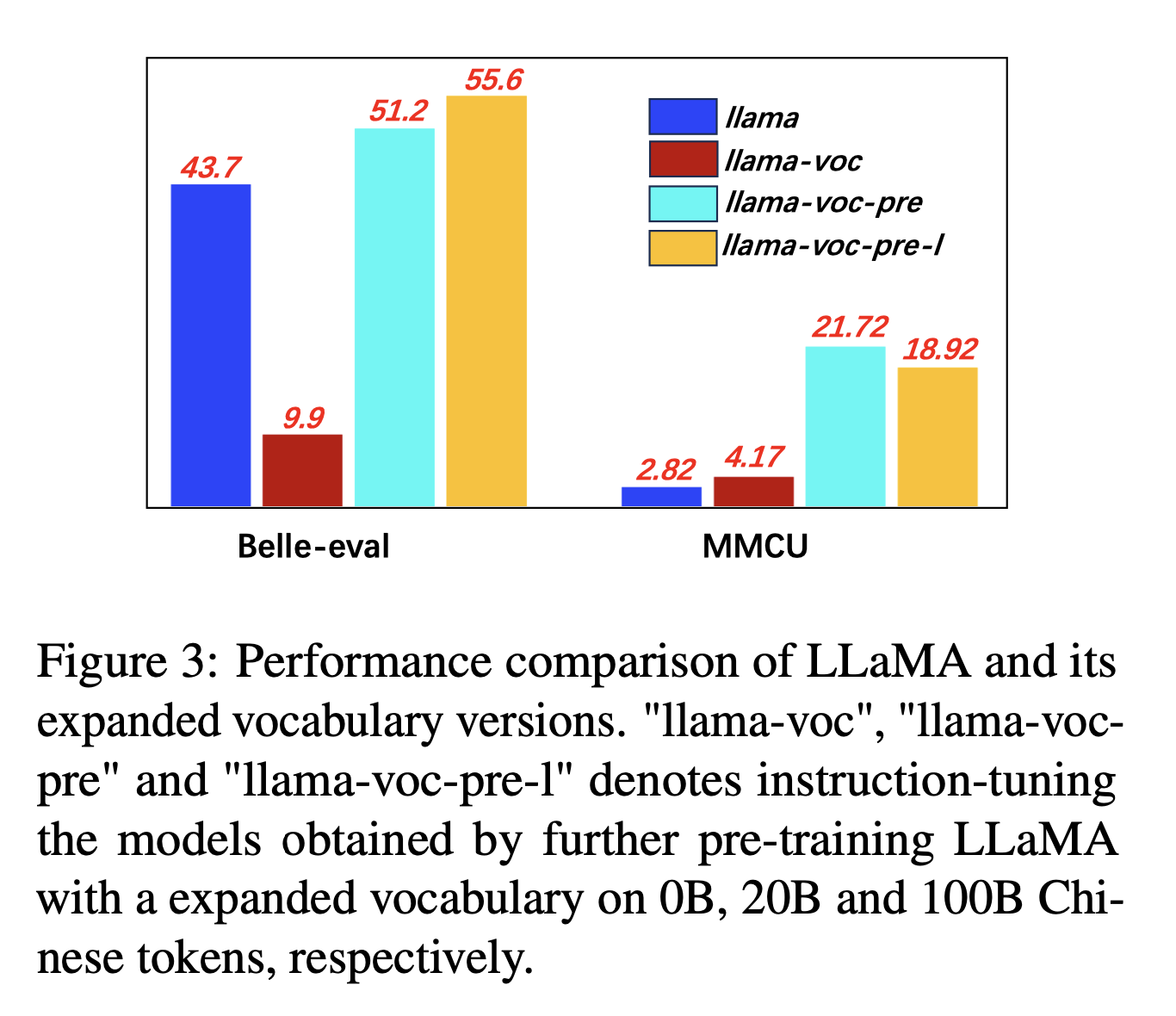
Resultados experimentales:
La capacitación previa en más corpus chino con expansión del vocabulario chino es consistentemente útil para la capacidad de seguimiento de instrucciones.
Y contraintuitivamente, "Llama-Voc-Pre-L" (100B) es inferior a "Llama-Voc-pre" (20B) en MMCU, que muestra que la capacitación previa en más datos puede no conducir necesariamente a un mayor rendimiento para los exámenes académicos.
Para el lenguaje de las indicaciones, los autores prueban la idoneidad de la instrucción ajustada para usar las indicaciones chinas.
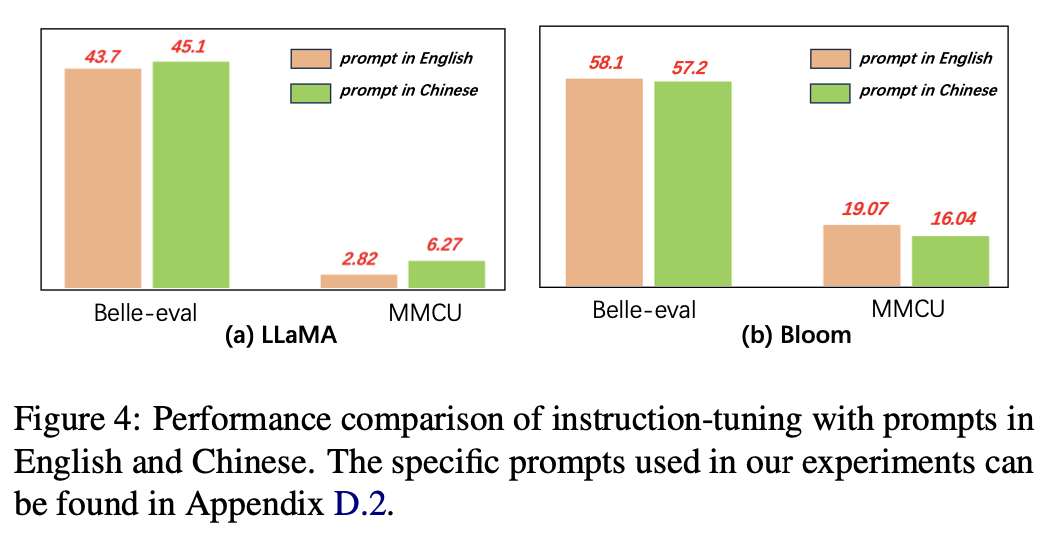
La Figura 4 muestra los resultados del uso de indicaciones chinas e inglesas basadas en Llama y Bloom. Cuando el ajuste de instrucciones, el uso de indicaciones chinas puede mejorar el rendimiento en ambos puntos de referencia en comparación con las indicaciones en inglés, mientras que el fenómeno opuesto se puede observar en la floración.
Resultados experimentales:
Para los modelos con habilidades chinas más débiles (por ejemplo, LLAMA), el uso de indicaciones chinas puede ayudar efectivamente a responder en chino.
Para los modelos con buenas habilidades chinas (p. Ej., Bloom), el uso de indicaciones en inglés (el idioma en el que son mejor) puede guiar mejor el modelo para comprender el proceso de ajuste con instrucciones.
Para evitar las LLM que generan contenido tóxico, alinearlos con los valores humanos es un problema crucial. Agregamos datos de alineación de valor humano creados por CoIG en el ajuste de instrucciones para explorar su impacto.
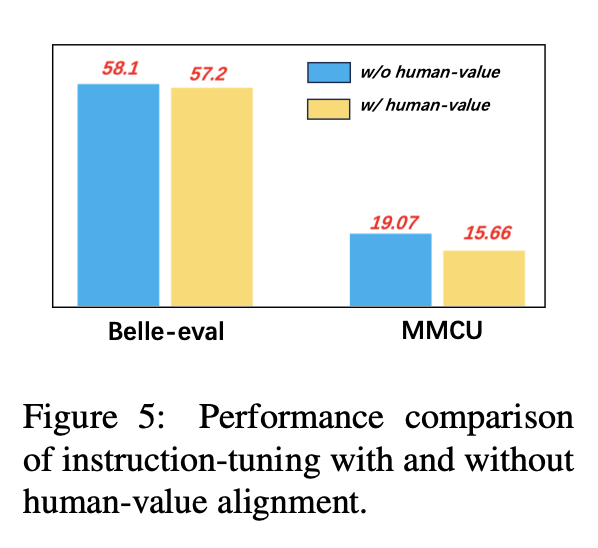
La Figura 5 compara los resultados del ajuste de instrucciones con y sin alineación del valor humano.
Resultados experimentales: la alineación del valor humano da como resultado una ligera caída de rendimiento. Cómo equilibrar la inofensiva y el rendimiento de los LLM es una dirección de investigación que vale la pena explorar en el futuro.
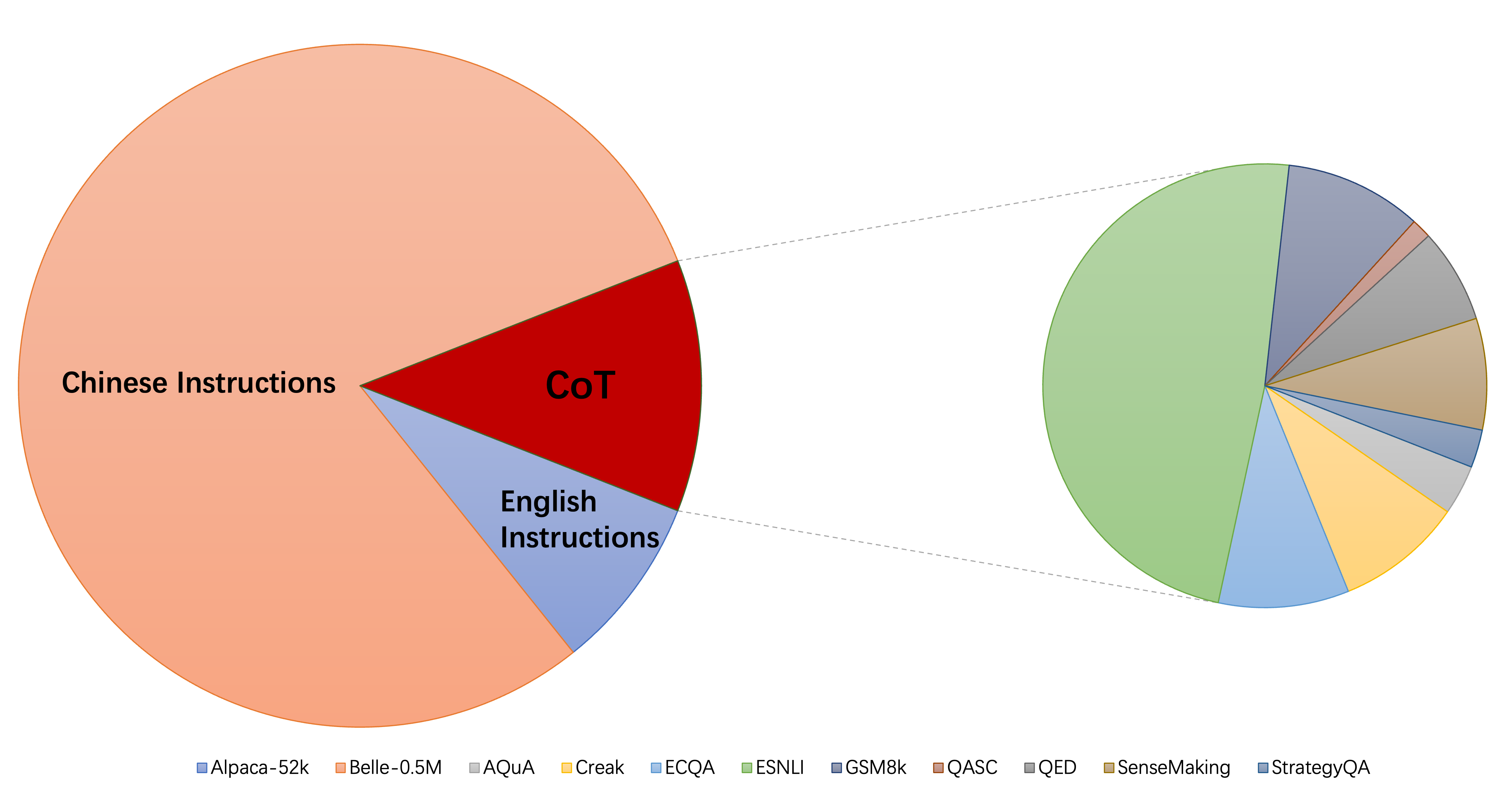 La colección actual de conjuntos de datos de finalización de instrucciones consiste principalmente en tres partes:
La colección actual de conjuntos de datos de finalización de instrucciones consiste principalmente en tres partes:
alpaca_data_cleaned.json : aproximadamente 52k muestras de entrenamiento de instrucción en inglés.CoT_data.json : 9 conjuntos de datos de cot que involucran aproximadamente 75k muestras. (Publicado por Flan [7])belle_data_cn.json : aproximadamente 0.5m chino | muestras de entrenamiento de seguimiento de instrucciones. (Publicado por Belle [8]) "W/o Cot" y "W/O CN" denotan modelos que excluyen los datos de COT y las instrucciones chinas de sus datos de Finetuning Fineting, respectivamente.
"W/o Cot" y "W/O CN" denotan modelos que excluyen los datos de COT y las instrucciones chinas de sus datos de Finetuning Fineting, respectivamente.
La tabla anterior muestra dos ejemplos (que involucran con cálculos numéricos) que requieren una cierta cantidad de capacidad de razonamiento para responder correctamente. Como se muestra en la columna media, Ours w/o CoT no puede generar la respuesta correcta, lo que muestra que una vez que los datos de Finetuning no contienen datos de cuna, la capacidad de razonamiento del modelo disminuye significativamente. Esto demuestra además que los datos de COT son esenciales para los modelos LLM.

La tabla anterior muestra dos ejemplos que requieren la capacidad de responder a las instrucciones chinas. Como se muestra en la columna correcta, el contenido generado Ours w/o CN no es razonable, o las instrucciones chinas son respondidas en inglés por Ours w/o CN . Esto muestra que eliminar los datos chinos durante la sintonización de finos hará que el modelo no pueda manejar las instrucciones chinas, y demuestra aún más la necesidad de recopilar datos de finetos de instrucción china.

La tabla anterior muestra un ejemplo relativamente difícil, que requiere una cierta acumulación de conocimiento de la historia china y una capacidad lógica y completa para establecer eventos históricos. Como se muestra en esta tabla, Ours w/o CN solo puede generar una respuesta corta y errónea, debido a la falta de datos de finising chinos, el conocimiento correspondiente de la historia china es naturalmente faltante. Aunque Ours w/o CoT enumera algunos eventos históricos chinos relevantes, su lógica de expresión es autocontradictoria, que es causada por la falta de datos de cuna. ``
En resumen, los modelos Finetuned de nuestro conjunto de datos completo (datos de instrucciones en inglés, chino y cot) pueden mejorar significativamente el razonamiento del modelo y la instrucción china siguiendo las habilidades.
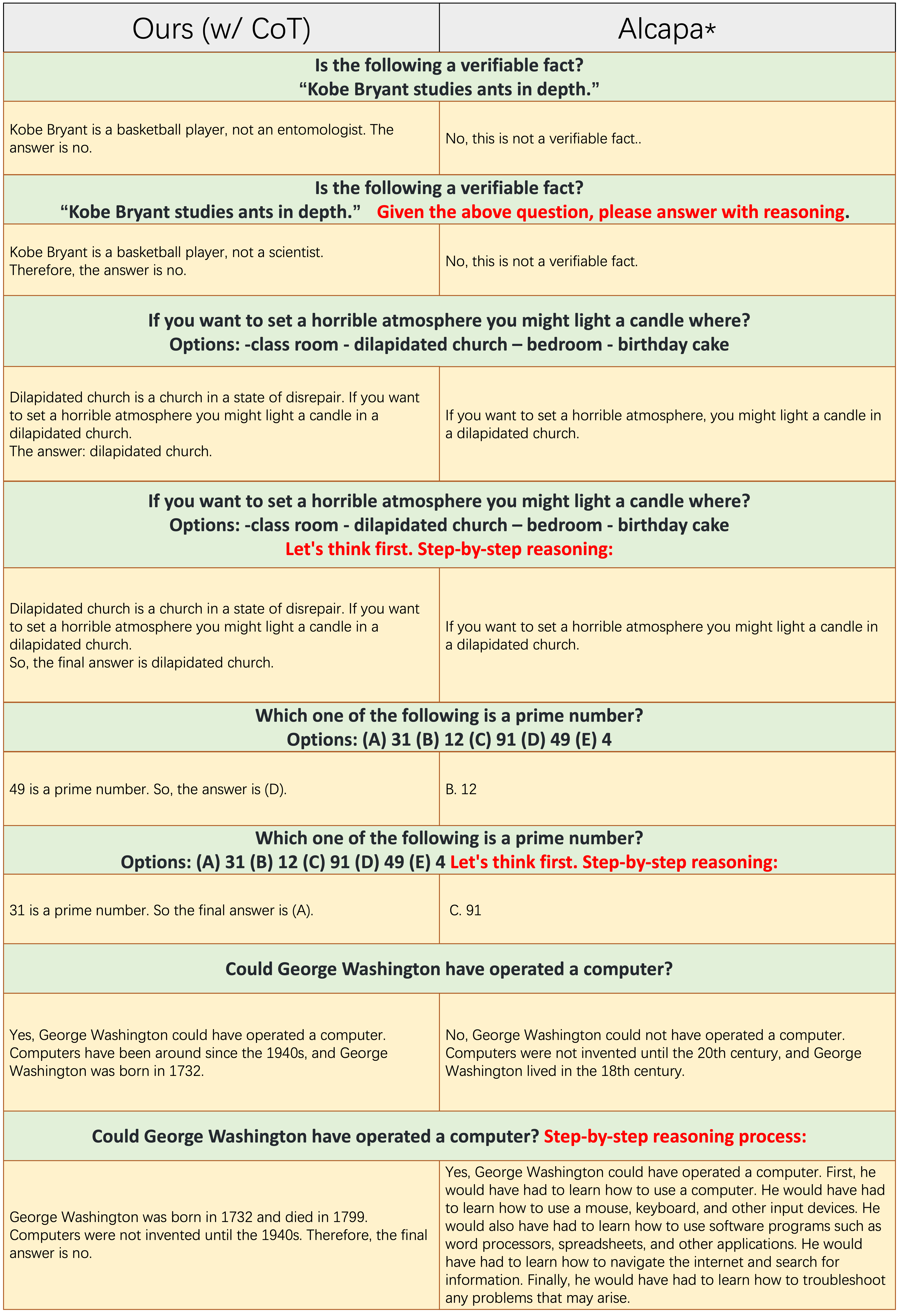 Las muestras de cada número impar de filas no aplican el indicador de la cuna, como "razonamiento paso a paso". Tanto
Las muestras de cada número impar de filas no aplican el indicador de la cuna, como "razonamiento paso a paso". Tanto Ours(w/CoT) como la alpaca se basan en LLAMA-7B, y la única diferencia entre ellos dos es que los datos de finalización de instrucciones Ours(w/CoT) tienen datos de cuna adicionales que los de la alpaca.
De la tabla anterior, encontramos que:
Ours(w/CoT) siempre genera la justificación correcta antes de la respuesta, mientras que la alpaca no genera ninguna justificación razonable, como se muestra en los primeros 4 ejemplos (preguntas de sentido común). Esto muestra que el uso de datos de COT para Finetuning puede mejorar significativamente la capacidad de razonamiento.Ours(w/CoT) , el aviso de cot (por ejemplo, concatenate 'paso a paso' con la pregunta de entrada) tiene poco efecto en ejemplos fáciles (por ejemplo, preguntas de sentido común) y tiene un efecto importante en las preguntas desafiantes (por ejemplo, preguntas que requieren razonamiento, como los últimos cuatro ejemplos). Comparación cuantitativa de respuestas a las instrucciones chinas. 
Nuestro modelo está fino de una llama de 7B en 52k Instrucciones en inglés e 0.5 millones de instrucciones chinas. Stanford Alpaca (Nuestra reimplementación) está fina de una llama de 7B en 52k Instrucciones en inglés. Belle está fina de una floración 7b en 2B de instrucciones chinas.
De la tabla anterior, se pueden encontrar varias observaciones:
ours (w/ CN) tiene una capacidad más fuerte para comprender las instrucciones chinas. Para el primer ejemplo, la alpaca no distingue entre la parte instruction y la parte input , mientras que lo hacemos.ours (w/ CN) no solo proporciona el código correcto, sino que también proporciona la anotación china correspondiente, mientras que la alpaca no. Además, como se muestra en los 3-5 ejemplos, la alpaca solo puede responder a la instrucción china con una respuesta en inglés.ours (w/ CN) en las instrucciones que requieren una respuesta abierta (como se muestra en los últimos dos ejemplos) todavía debe mejorarse. El rendimiento sobresaliente de Belle contra tales instrucciones se debe a: 1. Su modelo Bloom Backbone encuentra mucho más datos multilingües durante la capacitación previa; 2. Sus datos de Finetuning de instrucción china son más que los nuestros, es decir, 2 m frente a 0.5m. Comparación cuantitativa de las respuestas a las instrucciones en inglés. El propósito de esta subsección es explorar si la ficción de las instrucciones chinas tiene un impacto negativo en la alpaca. 
De la tabla anterior, encontramos que:
ours (w/ CN) muestra más detalles que la de Alpaca, por ejemplo, para el tercer ejemplo, ours (w/ CN) enumera tres provincias más que Alpaca. Cite el repositorio si usa la recopilación de datos, el código y los hallazgos experimentales en este repositorio.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Para los datos y los modelos, cite los datos originales, los métodos de eficiencia de parámetros y la fuente LLMS también.
Nos gustaría expresar nuestra gratitud especial al laboratorio APUS Ailme por patrocinar las 8 GPU A100 para los experimentos.
(De vuelta a la cima)


