Alpaca CoT
1.0.0
中文| Anglais

Il s'agit du référentiel du projet Alpaca-CoT , qui vise à construire une plate-forme d'instructions Finetuning (IFT) avec une collection d'instructions étendue (en particulier les ensembles de données COT) et une interface unifiée pour divers modèles de langues grands et méthodes éconergétiques. Nous élargissons constamment notre collecte de données de réglage des instructions et intégrant plus de LLM et plus de méthodes économes par des paramètres. De plus, nous avons créé une nouvelle branche tabular_llm pour construire un LLM tabulaire pour résoudre les tâches d'intelligence de table.
Vous êtes chaleureusement invités à nous fournir tous les ensembles de données d'instructions non collectés (ou leurs sources). Nous les formaterons uniformément, entraînerons le modèle d'alpaga (et d'autres LLM dans le premier avenir) avec ces ensembles de données, les points de contrôle des modèles open source et effectueraient des études empiriques approfondies. Nous espérons que notre projet pourra apporter une contribution modeste au processus open source des modèles de grande langue et réduire son seuil pour que les chercheurs de la PNL commencent.

Si vous souhaitez utiliser d'autres méthodes en plus de LORA, veuillez installer la version éditée dans notre projet pip install -e ./peft .
12.8: LLM InternLM a été fusionné.
8.16: 4bit quantization est disponible pour lora , qlora et adalora .
8.16: Méthodes économes par les paramètres Qlora , Sequential adapter et Parallel adapter ont été fusionnés.
7.24: LLM ChatGLM v2 a été fusionné.
7.20: LLM Baichuan a été fusionné.
6.25: Ajouter un code d'évaluation du modèle, y compris Belle et MMCU.
GPT4Tools , Auto CoT , pCLUE sont ajoutés.tabular_llm est créée pour construire un LLM tabulaire. Nous collectons des données de réglage des instructions pour les tâches liées à la table comme la question de la question de la question du tableau et les utilisons pour affiner les LLM dans ce dépôt.MOSS a été fusionné.GAOKAO , camel , FLAN-Muffin , COIG sont collectés et formatés.webGPT , dolly , baize , hh-rlhf , OIG(part) sont collectés et formatés.multi-turn conversation par @paulcx.firefly , instruct , Code Alpaca est collecté et formaté, qui peut être trouvé ici.Parameter merging , Local chatting , Batch predicting et Web service building par @weberr.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 et natural-instructions sont collectés et formatés.CoT_CN_data.json peut être trouvé ici. 
Llama [1] est un excellent travail qui démontre l'incroyable capacité zéro-shot et à rares. Il réduit considérablement le coût de la formation, des finetuning et de l'utilisation de modèles compétitifs en grande langue, c'est-à-dire que LLAMA-13B surpasse GPT-3 (175B) et LLAMA-65B est compétitif avec PALM-540B. Récemment, pour augmenter la capacité de suivi des instructions de LLAMA, Stanford Alpaca [2] Finetuned Llama-7b sur des données de suivi de l'instruction 52k générées par les techniques d'auto-instructeur [3]. Cependant, à l'heure actuelle, la communauté de recherche LLM est toujours confrontée à trois défis: 1. Même Llama-7b a toujours des exigences élevées pour les ressources informatiques; 2. Il y a peu d'ensembles de données open source pour l'instruction Finetuning; et 3. Il y a un manque d'étude empirique sur l'impact de divers types d'instructions sur les capacités du modèle, telles que la capacité de répondre à l'enseignement chinois et le raisonnement du COT.
À cette fin, nous proposons ce projet, qui exploite diverses améliorations qui ont ensuite été proposées, avec les avantages suivants:
7b , 13b et 30b des modèles LLAMA peuvent être facilement formées sur un seul 80G A100. À notre connaissance, ce travail est le premier à étudier le raisonnement de COT basé sur Llama et Alpaca. Par conséquent, nous abrérons notre travail à Alpaca-CoT .
La taille relative des ensembles de données collectés peut être montré par ce graphique:
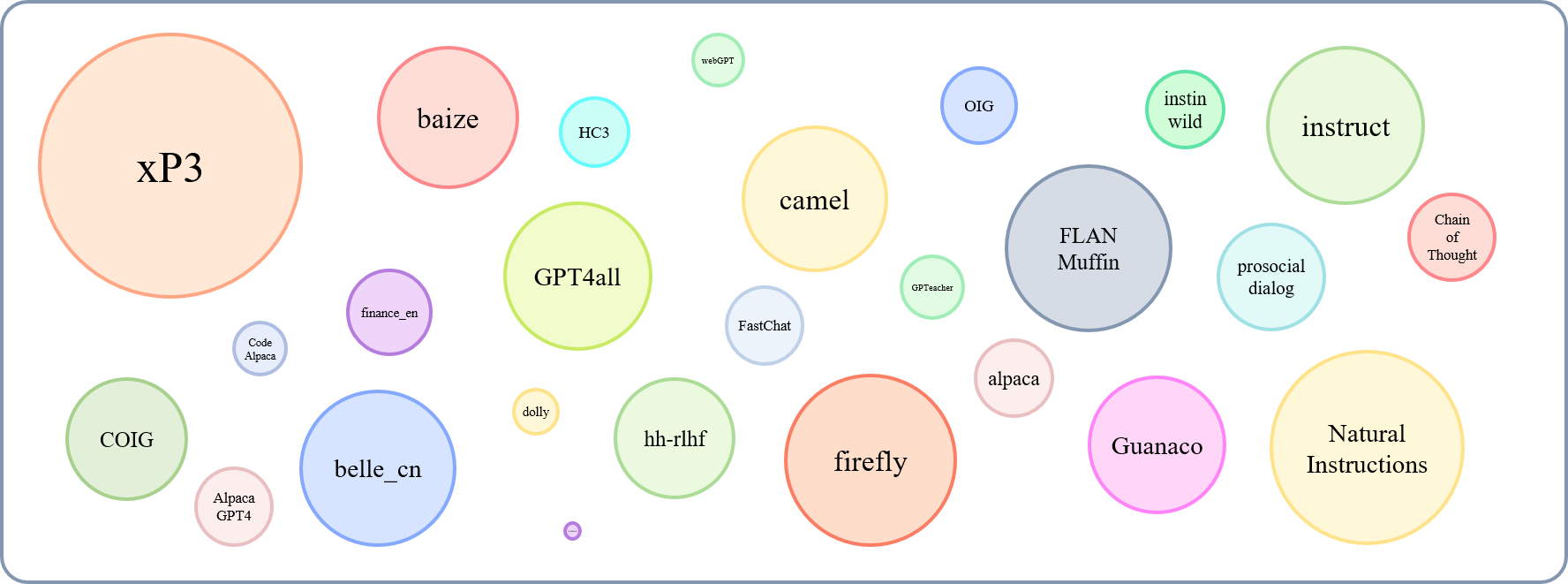
En faisant référence à cela (@yaodongc), nous avons étiqueté chaque ensemble de données collecté selon les règles suivantes:
(Lang) Tags linguaux:
(Tâche) Tank-Tags:
(Gen) Méthode de génération:
| Ensemble de données | Nombres | Égouter | Tâche | Génération | Taper | SRC | URL |
|---|---|---|---|---|---|---|---|
| Chaîne de pensée | 74771 | EN / CN | MT | HG | Instruire le raisonnement de COT | annoter le lit sur les données existantes | télécharger |
| Gpt4all | 806199 | En | MT | Col | Code, histoires et boîtes de dialogue | distillation de GPT-3,5-turbo | télécharger |
| Gptacher | 29013 | En | MT | SI | Général, jeu de rôle, formateur d'outils | GPT-4 & TOOLFORMER | télécharger |
| Guanaco | 534610 | Ml | MT | SI | diverses tâches linguistiques | text-davinci-003 | télécharger |
| Hc3 | 37175 | EN / CN | Ts | MÉLANGER | Évaluation du dialogue | humain ou chatppt | télécharger |
| alpaga | 52002 | En | MT | SI | instruction générale | text-davinci-003 | télécharger |
| Instructions naturelles | 5040134 | Ml | MT | Col | Tâches NLP diverses | Collection de jeux de données annotés humains | télécharger |
| Belle_cn | 1079517 | CN | TS / MT | SI | Général, raisonnement mathématique, dialogue | text-davinci-003 | télécharger |
| instinct | 52191 | EN / CN | MT | SI | Génération, Open-QA, Mind-Storm | text-davinci-003 | télécharger |
| dialogue prosocial | 165681 | En | Ts | MÉLANGER | dialogue | GPT-3 réécrit les questions + les commentaires des humains manuellement | télécharger |
| finance_en | 68912 | En | Ts | Col | QA lié financier | Gpt3.5 | télécharger |
| xp3 | 78883588 | Ml | MT | Col | Une collection d'invites et de jeux de données sur 46 de langues et 16 tâches NLP | Collection de jeux de données annotés humains | télécharger |
| luciole | 1649398 | CN | MT | Col | 23 tâches NLP | Collection de jeux de données annotés humains | télécharger |
| instruire | 888969 | En | MT | Col | Augmenté de GPT4all, alpaca, ensembles de données de méta open source | Augmentation effectuée à l'aide des outils PNL avancés fournis par Allenai | télécharger |
| Code alpaga | 20022 | En | Ts | SI | Génération de code, montage, optimisation | text-davinci-003 | télécharger |
| Alpaca_gpt4 | 52002 | EN / CN | MT | SI | instruction générale | Généré par GPT-4 à l'aide d'alpaga | télécharger |
| webgpt | 18994 | En | Ts | MÉLANGER | Renseignement de l'information (IR) QA | GPT-3 affiné, chaque instruction a deux sorties, sélectionnez-en mieux | télécharger |
| Dolly 2.0 | 15015 | En | Ts | HG | QA fermé, résumé et etc., wikipedia comme références | humain annoté | télécharger |
| tapis | 653699 | En | MT | Col | Une collection de questions Alpaca, Quora, Stackoverflow et Medquad | Collection de jeux de données annotés humains | télécharger |
| HH-RLHF | 284517 | En | Ts | MÉLANGER | dialogue | Dialogue entre les modèles humains et RLHF | télécharger |
| OIG (partie) | 49237 | En | MT | Col | créé à partir de diverses tâches, telles que la question et la réponse | En utilisant l'augmentation des données, la collecte des ensembles de données annotés humains | télécharger |
| Gaokao | 2785 | CN | MT | Col | Questions à choix multiples, remplies et ouvertes à l'examen | humain annoté | télécharger |
| chameau | 760620 | En | MT | SI | Conversations de jeu de rôle dans la société d'IA, le code, les mathématiques, la physique, la chimie, le biologiste | GPT-3,5-turbo | télécharger |
| Flan-muffin | 1764800 | En | MT | Col | 60 tâches NLP | Collection de jeux de données annotés humains | télécharger |
| Coig (FlaniNstruct) | 298428 | CN | MT | Col | Collectez l'examen Fron, traduit, instructions d'alignement de la valeur humaine et Correction contrefacturale Chat multi-ronde | Utilisation de l'outil automatique et de la vérification manuelle | télécharger |
| Gpt4tools | 71446 | En | MT | SI | Une collection d'instructions liées à l'outil | GPT-3,5-turbo | télécharger |
| Partage | 1663241 | En | MT | MÉLANGER | instruction générale | Crowdsourcing pour collecter des conversations entre les gens et le chatppt (Sharegpt) | télécharger |
| Lit de voiture | 5816 | En | MT | Col | arithmétique, bon sens, symbolique et autres tâches de raisonnement logiques | Collection de jeux de données annotés humains | télécharger |
| MOUSSE | 1583595 | EN / CN | Ts | SI | instruction générale | text-davinci-003 | télécharger |
| ultrachat | 28247446 | En | Questions sur le monde, l'écriture et la création, l'aide sur les matériaux existants | Deux GPT-3.5-turbo séparés | télécharger | ||
| Chinois-médical | 792099 | CN | Ts | Col | Questions sur les conseils médicaux | crawl | télécharger |
| CSL | 396206 | CN | MT | Col | Génération de texte en papier, extraction de mots clés, résumé de texte et classification du texte | crawl | télécharger |
| PCLUE | 1200705 | CN | MT | Col | instruction générale | télécharger | |
| news_commentary | 252776 | CN | Ts | Col | traduire | télécharger | |
| Pile | faire | En |
Vous pouvez télécharger toutes les données formatées ici. Ensuite, vous devez les mettre dans le dossier de données.
Vous pouvez télécharger tous les points de contrôle formés sur différents types de données d'instruction à partir d'ici. Ensuite, après avoir défini LoRA_WEIGHTS (dans generate.py ) sur le chemin local, vous pouvez exécuter directement l'inférence du modèle.
Toutes les données de notre collection sont formatées dans les mêmes modèles, où chaque échantillon est le suivant:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Notez que pour les ensembles de données COT, nous utilisons d'abord le modèle fourni par Flan pour changer l'ensemble de données d'origine en divers formulaires de chaîne de réflexion, puis le convertir au format ci-dessus. Le script de formatage peut être trouvé ici.
pip install -r requirements.txt
Notez que, assurez-vous que Python> = 3,9 lorsque Finetuning ChatGlm.
Pivot
pip install -e ./peft
Pour que les chercheurs mettent des recherches systématiques de l'IFT sur les LLM, nous avons collecté différents types de données d'instruction, multiples intégrés LLM et interfaces unifiées, ce qui facilite la personnalisation de la collocation souhaitée:
--model_type : définissez le LLM que vous souhaitez utiliser. Actuellement, [LLAMA, CHATGLM, BLOOM, MOSS] sont pris en charge. Les deux derniers ont de fortes capacités chinoises, et plus de LLM seront intégrés à l'avenir.--peft_type : définissez le PEFT que vous souhaitez utiliser. Actuellement, [LORA, ADALORA, PRÉFIX TUNING, P TUNING, INVERT] sont pris en charge.--data : définissez le type de données utilisé pour IFT pour adapter de manière flexible la capacité de conformité des commandes souhaitée. Par exemple, pour une forte capacité de raisonnement, définissez "Alpaga-Cot", pour une forte capacité chinoise, définissez "Belle1.5m", pour le codage et la capacité de génération d'histoires, définissez "GPT4ALL" et pour la capacité de réponse liée financière, définissez "Finance".--model_name_or_path : Ceci est défini pour charger différentes versions des poids du modèle pour la cible LLM --model_type . Par exemple, pour charger la version 13B des poids du lama, vous pouvez définir decapoda-research / llama-13b-hf.GPU unique
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
Remarque: Pour plusieurs ensembles de données, vous pouvez utiliser --data comme --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Notez que load_in_8bit ne convient pas encore pour le chatglm, donc Batch_Size doit être plus petit que les autres.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Notez que vous pouvez également passer le chemin local (où les poids LLM enregistrés) à --model_name_or_path . Et le type de données --data peuvent être librement définies en fonction de vos intérêts.
Plusieurs GPU
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Notez que load_in_8bit ne convient pas encore pour le chatglm, donc Batch_Size doit être plus petit que les autres.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Plus de détails sur l'instruction Fineting et l'inférence peuvent être trouvés ici d'où nous avons modifié. Notez que les dossiers saved-xxx7b sont le chemin de sauvegarde des poids LORA, et les poids LLAMA sont automatiquement téléchargés à partir de la face de câlins.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Cet article sélectionne deux repères d'évaluation, Belle-Eval et MMCU, pour évaluer de manière approfondie les compétences LLM en chinois.
Belle-Eval est construite par auto-instruction avec Chatgpt, qui a 1 000 instructions diverses qui impliquent 10 catégories couvrant les tâches PNL courantes (par exemple, QA) et les tâches difficiles (par exemple, code et mathématiques). Nous utilisons Chatgpt pour évaluer les réponses du modèle en fonction des réponses Golden. Cette référence est considérée comme l'évaluation de la capacité AGI (suivi des instructions).
MMCU est une collection de questions chinoises à choix multiples dans quatre disciplines professionnelles de la médecine, du droit, de la psychologie et de l'éducation (par exemple, examen Gaokao). Il permet aux LLMS de passer des examens dans la société humaine de manière test à choix multiples, ce qui le rend adapté à l'évaluation de l'étendue et de la profondeur de connaissance des LLM dans plusieurs disciplines.
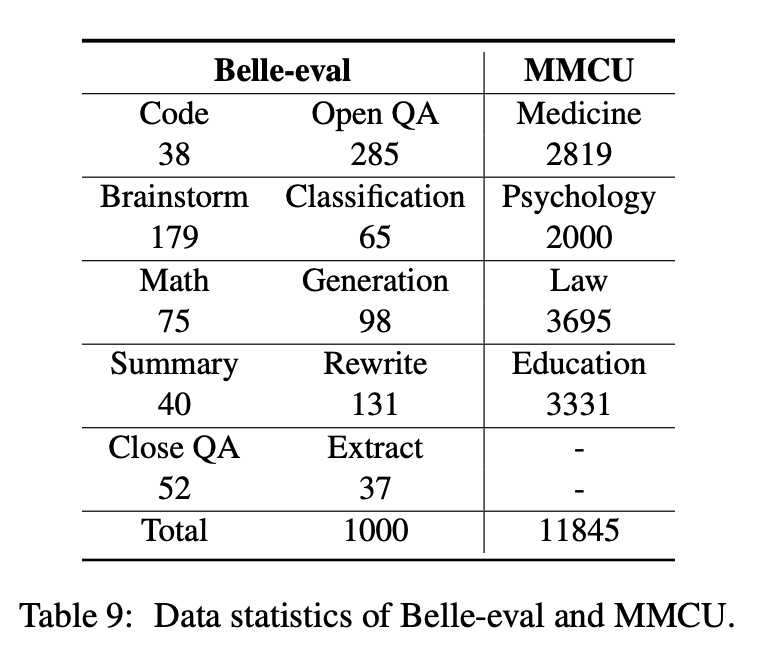
Les statistiques de données de Belle-Eval et MMCU sont présentées dans le tableau ci-dessus.
Nous effectuons des expériences pour étudier les trois principaux facteurs dans les bases LLMS de réglage de l'instruction: LLM, méthodes économes par les paramètres, ensembles de données d'instruction chinois.
Pour les LLM ouvertes, nous testons respectivement les LLMS et LLMS existants avec LORA sur Alpaca-GPT4 sur Belle-Eval et MMCU.
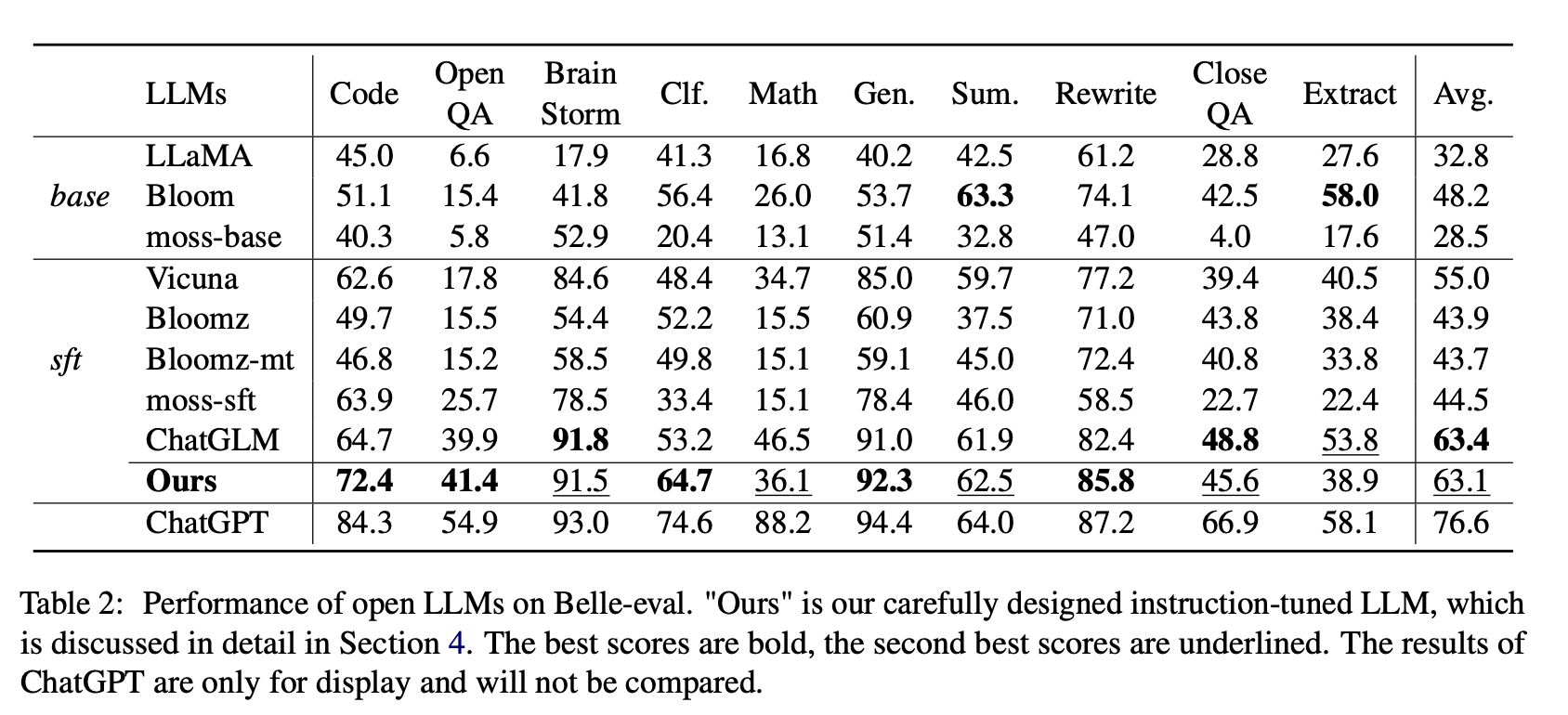
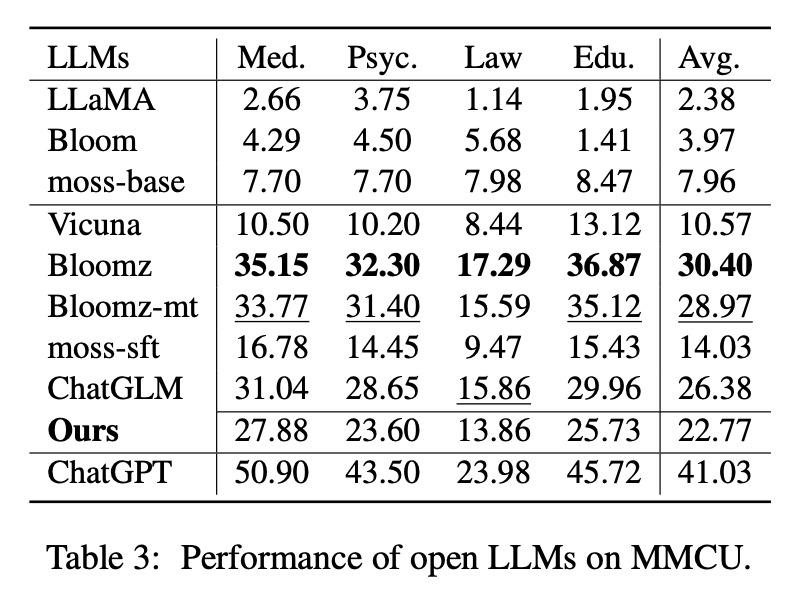
Le tableau 2 montre les scores des LLM ouverts sur Belle-Eval. Le tableau 3 montre la précision des LLM sur MMCU. Ils affinent tous les LLM ouverts avec la même méthode économe en paramètres LORA et le même ensemble de données d'instruction Alpaca-GPT4.
Résultats expérimentaux:
Évaluation des LLM existants
Performance sur Belle-Eval
(1) Pour les LLM de base, Bloom fonctionne le meilleur.
(2) Pour SFT LLMS, ChatGLM surpasse les autres par de grandes marges, grâce au fait qu'il est formé avec les jetons les plus chinois et le HFRL.
(3) Les catégories Open QA, mathématiques, clôtures et extraits sont toujours très difficiles pour les LLM ouvertes existantes.
(4) Vicuna et MOSS-SFT ont des améliorations claires par rapport à leurs bases, le lama et la base de la mousse, respectivement.
(5) En revanche, les performances des modèles SFT, Bloomz et Bloomz-MT, sont réduites par rapport à la floraison du modèle de base, car elles ont tendance à générer une réponse plus courte.
Performance sur MMCU
(1) Tous les LLM de base fonctionnent mal car il est presque difficile de générer du contenu dans le format spécifié avant le réglage fin, par exemple, les numéros d'option de sortie.
(2) Tous les SFT LLMS surpassent respectivement leurs LLM de base correspondants. En particulier, Bloomz fait le meilleur (même bat ChatGlm) car il peut générer un numéro d'option directement selon les besoins sans générer un autre contenu non pertinent, ce qui est également dû aux caractéristiques de données de son ensemble de données de réglage fin supervisé XP3.
(3) Parmi les quatre disciplines, le droit est le plus difficile pour les LLM.
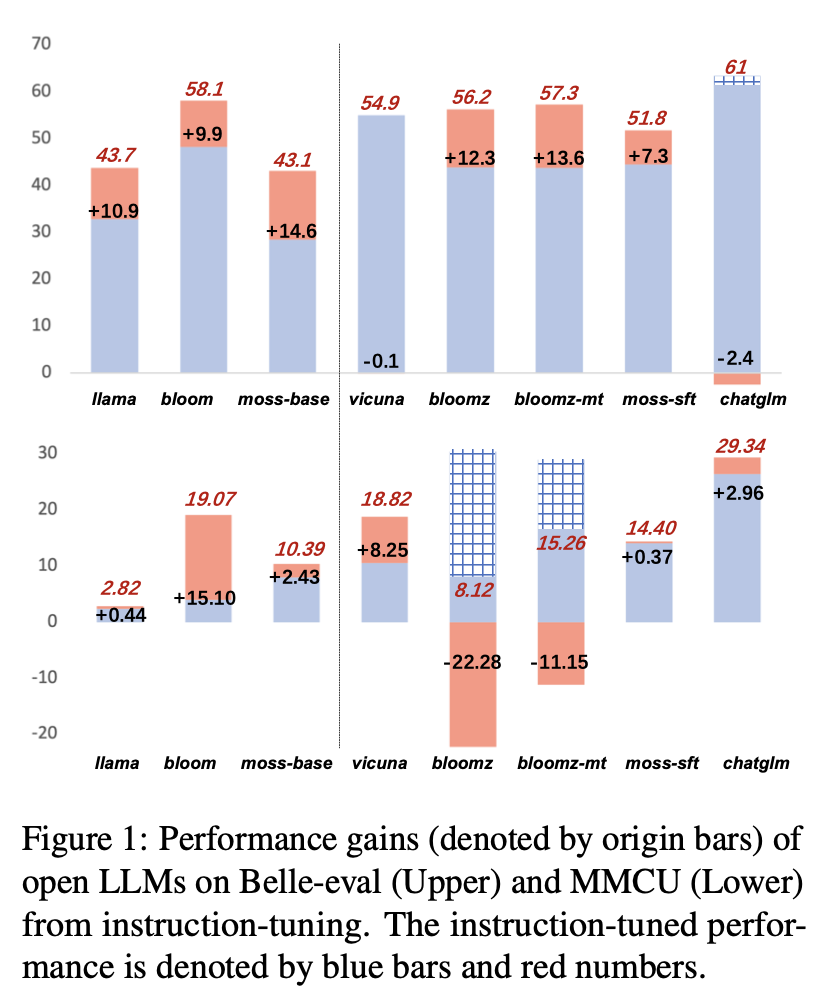
Les résultats des performances de LLMS après le réglage de l'instruction sur Alpaca-GPT4-ZH sont illustrés à la figure 1.
Régler des LLM différents
(1) Sur Belle-Eval, l'amélioration des performances des LLMS SFT apportées par un réglage de l'instruction n'est pas aussi significative que celle des LLM de base, à l'exception de SFT Bloomz et Bloomz-MT.
(2) Vicuna et ChatGlm rencontrent les performances des performances après le réglage de l'instruction, car vicuna est formée à partir de véritables conversations de chatGpt humain, avec une meilleure qualité qu'Alpaca-GPT4. ChatGLM adopte HFRL, qui peut ne plus convenir à un réglage de l'instruction.
(3) Sur MMCU, la plupart des LLMS atteignent des augmentations de performances après le réglage de l'instruction, à l'exception de Bloomz et Bloomz-MT, qui ont diminué de manière significative les performances.
(4) Après le réglage de l'instruction, Bloom a des améliorations significatives et fonctionne bien sur les deux repères. Bien que ChatGlm bat de façon cohérente Bloom, il subit une chute de performances pendant le réglage de l'instruction. Par conséquent, parmi tous les LLM ouverts, Bloom convient le plus comme modèle de fondation dans les expériences ultérieures pour l'exploration chinoise de l'instruction.
Pour les méthodes économes en paramètres autres que LORA, le papier collecte une gamme de méthodes économes par les paramètres pour la floraison de l'instruction sur l'ensemble de données Alpaca-GPT4.
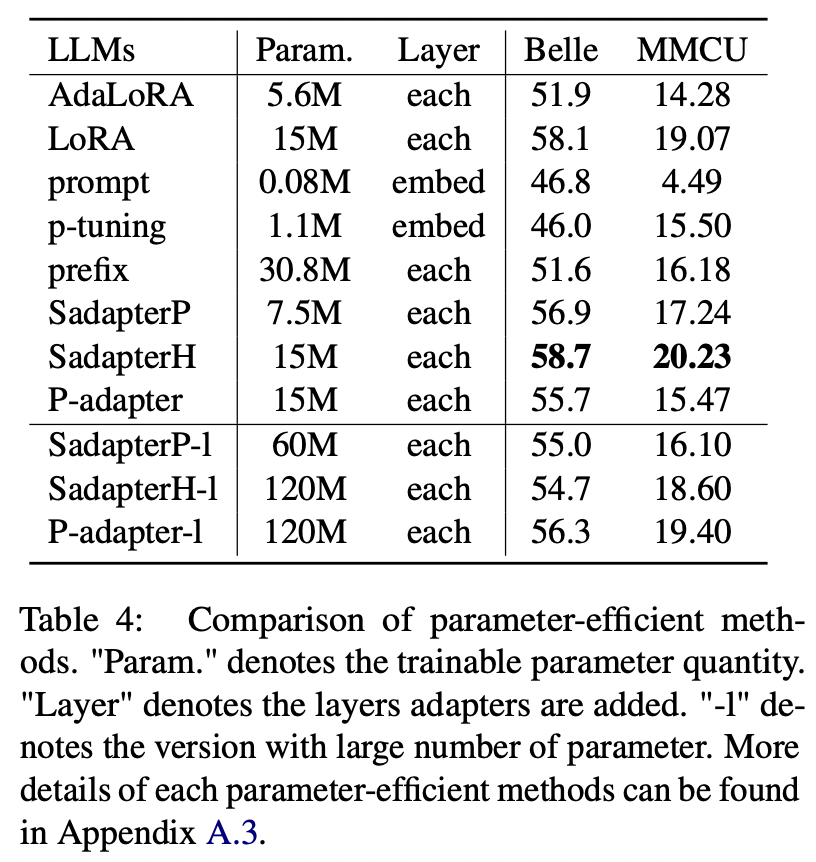
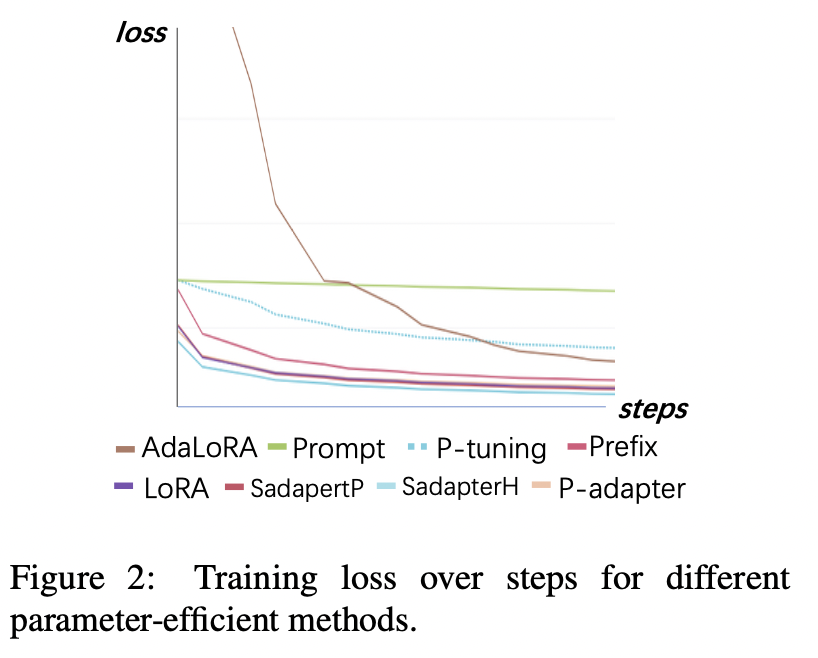
Résultats expérimentaux:
Comparaison des méthodes éconergétiques par les paramètres
(1) SADAPTERH effectue le meilleur parmi toutes les méthodes éconergétiques, qui peuvent être utilisées comme alternative à LORA.
(2) Pinage P et invite sous-performment les autres par de grandes marges, ce qui indique que l'ajout de couches d'entraînement dans la couche d'incorporation ne suffit pas pour prendre en charge les LLM pour les tâches de génération.
(3) Bien qu'Adalora soit une amélioration de la LORA, ses performances ont une baisse claire, peut-être parce que les paramètres d'entraînement de la LORA pour les LLM ne conviennent pas à une réduction supplémentaire.
(4) En comparant les parties supérieures et inférieures, on peut voir que l'augmentation du nombre de paramètres formables pour les adaptateurs séquentiels (c.-à-d. Sadapterp et Sadapterh) n'apporte pas de gain, tandis que le phénomène opposé est observé pour les adaptateurs parallèles (c'est-à-dire P-Adapter)
Perte de formation
(1) Le réglage rapide et le réglage du p convergent le plus lent et ont les pertes les plus élevées après convergence. Cela montre que les adaptateurs d'intégration uniquement ne conviennent pas aux LLM de réglage de l'instruction.
(2) La perte initiale d'Adalora est très élevée car elle nécessite l'apprentissage simultané de l'allocation du budget des paramètres, ce qui rend le modèle incapable de bien s'adapter aux données d'entraînement.
(3) Les autres méthodes peuvent rapidement converger sur les données d'entraînement et bien les adapter.
Pour l'impact de divers types d'ensembles de données d'instructions chinoises, les auteurs rassemblent des instructions chinoises ouvertes populaires (comme indiqué dans le tableau 5) pour affiner la floraison avec LORA.
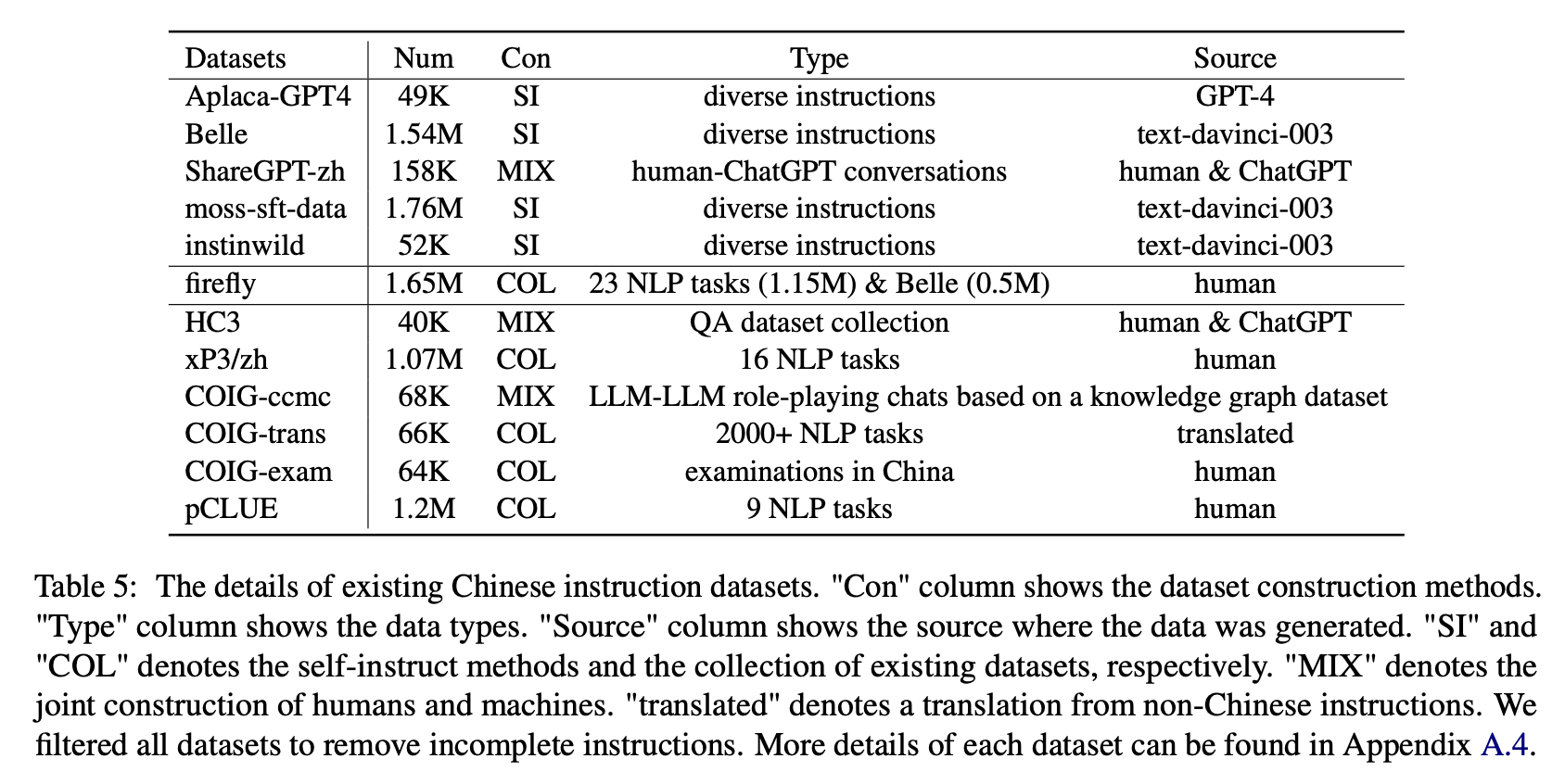
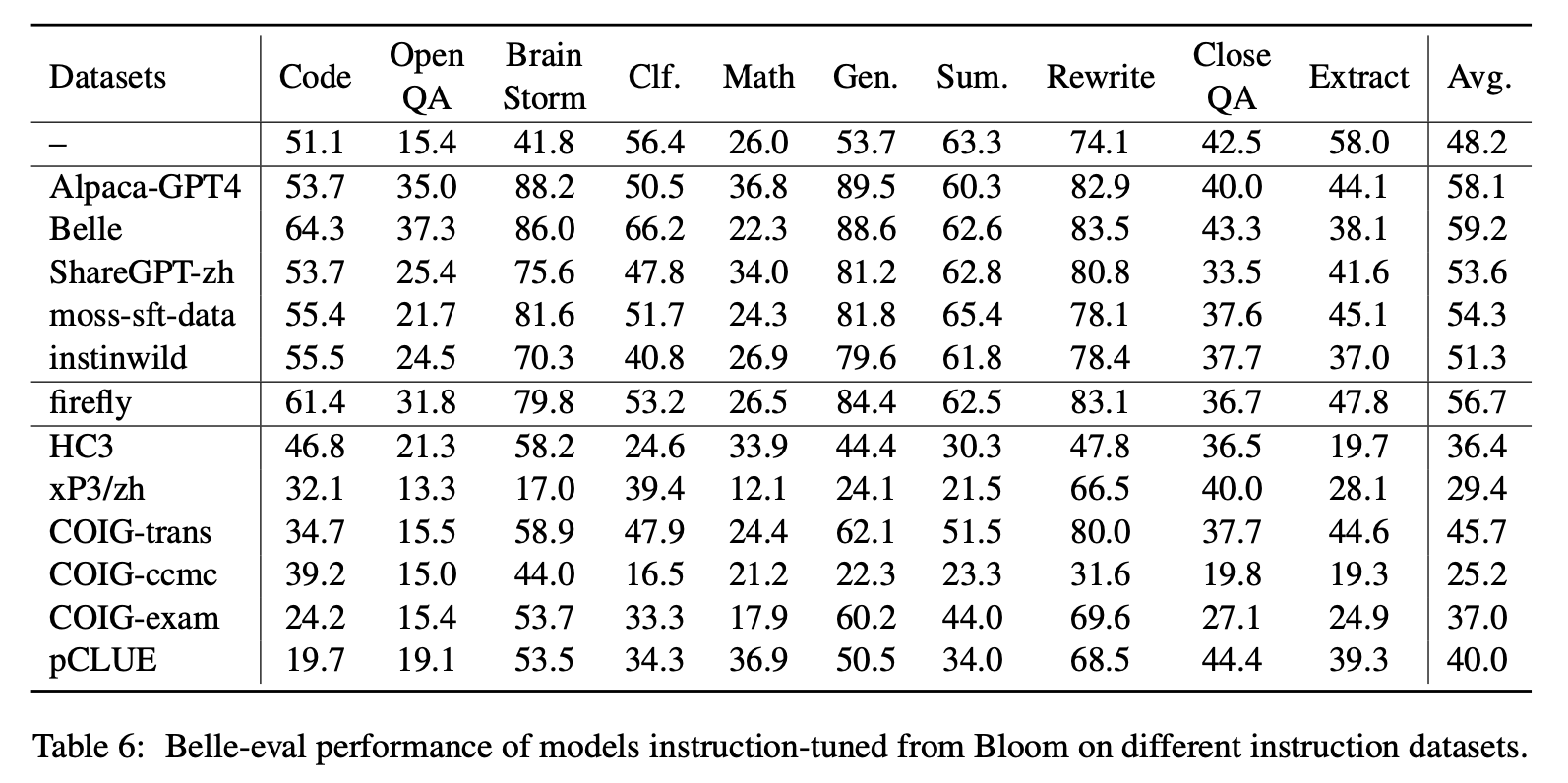
Le tableau 6 et le tableau 7 montrent le réglage fin de Bloom sur différents ensembles de données d'instructions.
Résultats expérimentaux:
Performance sur Belle-Eval
(1) Les données d'instructions construites par Chatgpt (par exemple, en utilisant des méthodes d'auto-instruction ou la collecte de conversations de chat-chat humain réelles) améliore systématiquement la capacité de suivi des instructions avec 3,1 ∼ ∼ Score à 11 points augmente.
(2) Parmi ces ensembles de données, Belle a les meilleures performances en raison de la plus grande quantité de données d'instruction. Cependant, les performances des modèles formées sur les données mousse-sft, contenant plus de données construites de manière similaire, n'est pas satisfaisante.
(3) La performance apportée par les instructions Alpaca-GPT4 est la deuxième meilleure, avec seulement 49k étant comparable à la Belle de 1,54 m.
(4) Instinwild apporte les moindres gains de performance parmi eux parce que les instructions de graines qu'il craigne du tweet ("en sauvage") ne sont pas aussi complètes que celles (comme l'alpaga) soigneusement conçues par les humains.
(5) Ces données basées sur le chatppt ont principalement un effet d'amélioration significatif sur les tâches de génération ouverte telles que la tempête cérébrale et la génération, tandis qu'il existe une diminution significative des tâches qui nécessitent des compétences de compréhension à la lecture élevées, telles que la QA et l'extrait proches.
(6) Ces ensembles de données d'instructions causent des dommages à la capacité de suivi des instructions du modèle, car la forme et l'intention de chaque NLP ou ensemble de données d'examen sont unitaires, ce qui peut facilement être trop élevé.
(7) Parmi eux, Coig-Trans obtient le meilleur car il implique plus de 2000 tâches différentes avec une grande variété d'instructions de tâches. En revanche, XP3 et COIG-CCMC ont le pire impact négatif sur les performances du modèle. Les deux ne couvrent que quelques types de tâches (traduction et QA pour les premières conversations de correction contrefactuelles pour les seconds), qui couvrent à peine les instructions et les tâches populaires pour les humains.
Performance sur MMCU
(1) Le réglage de l'instruction sur chaque ensemble de données peut toujours entraîner une amélioration des performances.
(2) Parmi les données basées sur le chatppt indiquées dans la partie supérieure, Sharegpt-Zh sous-performe les autres par de grandes marges. Cela peut être dû au fait que les vrais utilisateurs posent rarement des questions à choix multiples sur les sujets académiques.
(3) Parmi les données de collecte de données indiquées dans la partie inférieure, HC3 et COIG-CCMC entraînent la plus faible précision car les questions uniques de HC3 ne sont que 13K, et le format de tâche de COIG-CCMC est significativement différent de MMCU.
(4) Coig-Exam apporte la plus grande amélioration de la précision, bénéficiant du format de tâche similaire en tant que MMCU.
Quatre autres facteurs: Cot, extension du vocabulaire chinois, langue des invites et alignement de la valeur humaine
Pour le COT, les auteurs comparent les performances avant et après l'ajout de données de COT pendant le réglage de l'instruction.
Paramètres d'expérience:
Nous collectons 9 ensembles de données COT et leurs invites de Flan, puis les traduisons en chinois à l'aide de Google Translate. Ils comparent les performances avant et après l'ajout de données sur le COT pendant le réglage de l'instruction.
Notez d'abord le moyen d'ajouter des données de COT sous forme de "Cot alpaca-gpt4 +". De plus, ajoutez une phrase "先思考 , 再决定" ("pensez étape par étape" en chinois) à la fin de chaque instruction, pour inciter le modèle à répondre aux instructions basées sur le lit et étiqueter de cette façon "Alpaca-GPT4 + COT *".
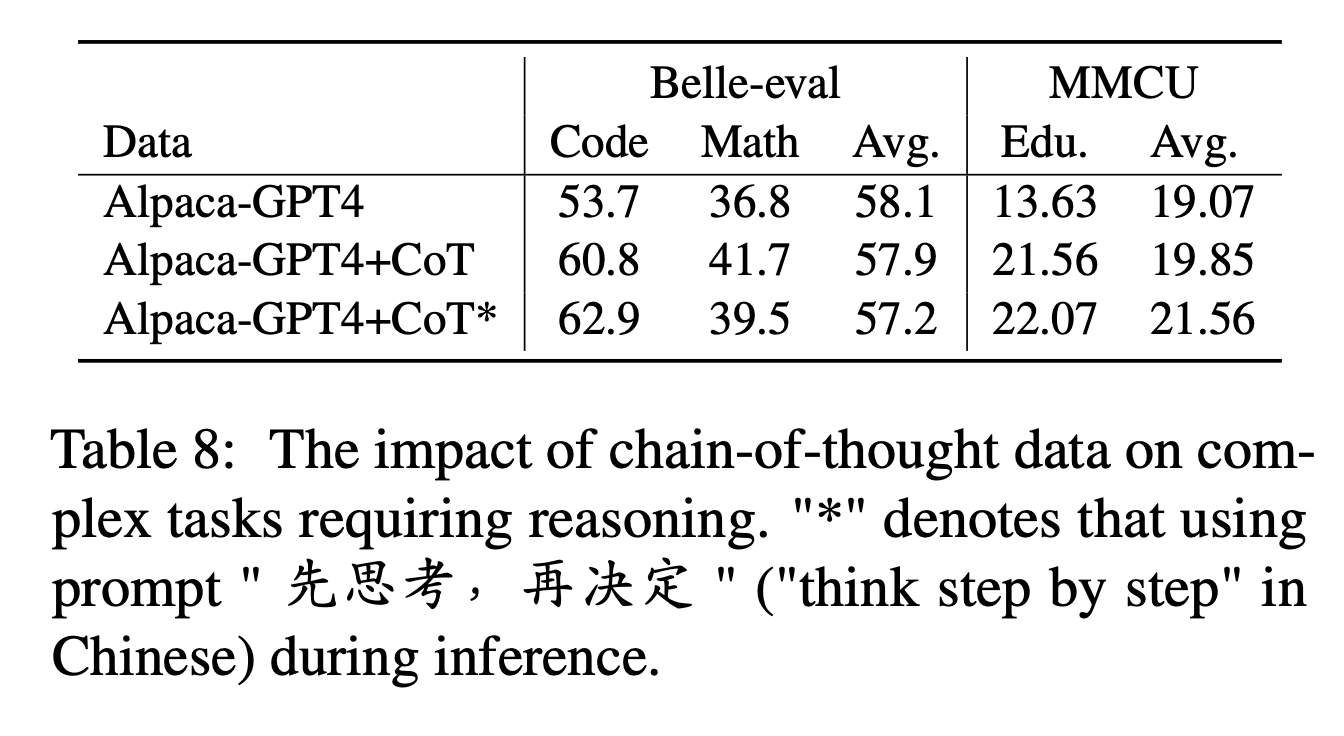
Résultats expérimentaux:
"ALPACA-GPT4 + COT" surpasse "Alpaca-GPT4" dans des tâches de code et de mathématiques qui nécessitent une forte capacité de raisonnement. En outre, il existe également une amélioration significative de la tâche d'éducation MMCU.
Comme le montre la ligne de "Alpaca-GPT4 + Cot *", la phrase simple peut améliorer davantage les performances des tâches de raisonnement code et éducation, tandis que les performances mathématiques sont légèrement inférieures à "alpaca-gpt4 + cot". Cela peut nécessiter une exploration plus approfondie d'invites plus robustes.
Pour l'expansion du vocabulaire chinois, les auteurs testent l'influence du nombre de jetons chinois dans le vocabulaire du tokenzer sur la capacité des LLMS à exprimer le chinois. Par exemple, si un caractère chinois est dans le vocabulaire, il peut être représenté par un seul jeton, sinon il peut nécessiter plusieurs jetons pour le représenter.
Paramètres d'expérience: les auteurs mènent principalement des expériences sur Llama, qui utilise la phrase (taille de vocabulaire 32k des caractères chinois) couvrant moins de caractères chinois que Bloom (250k).
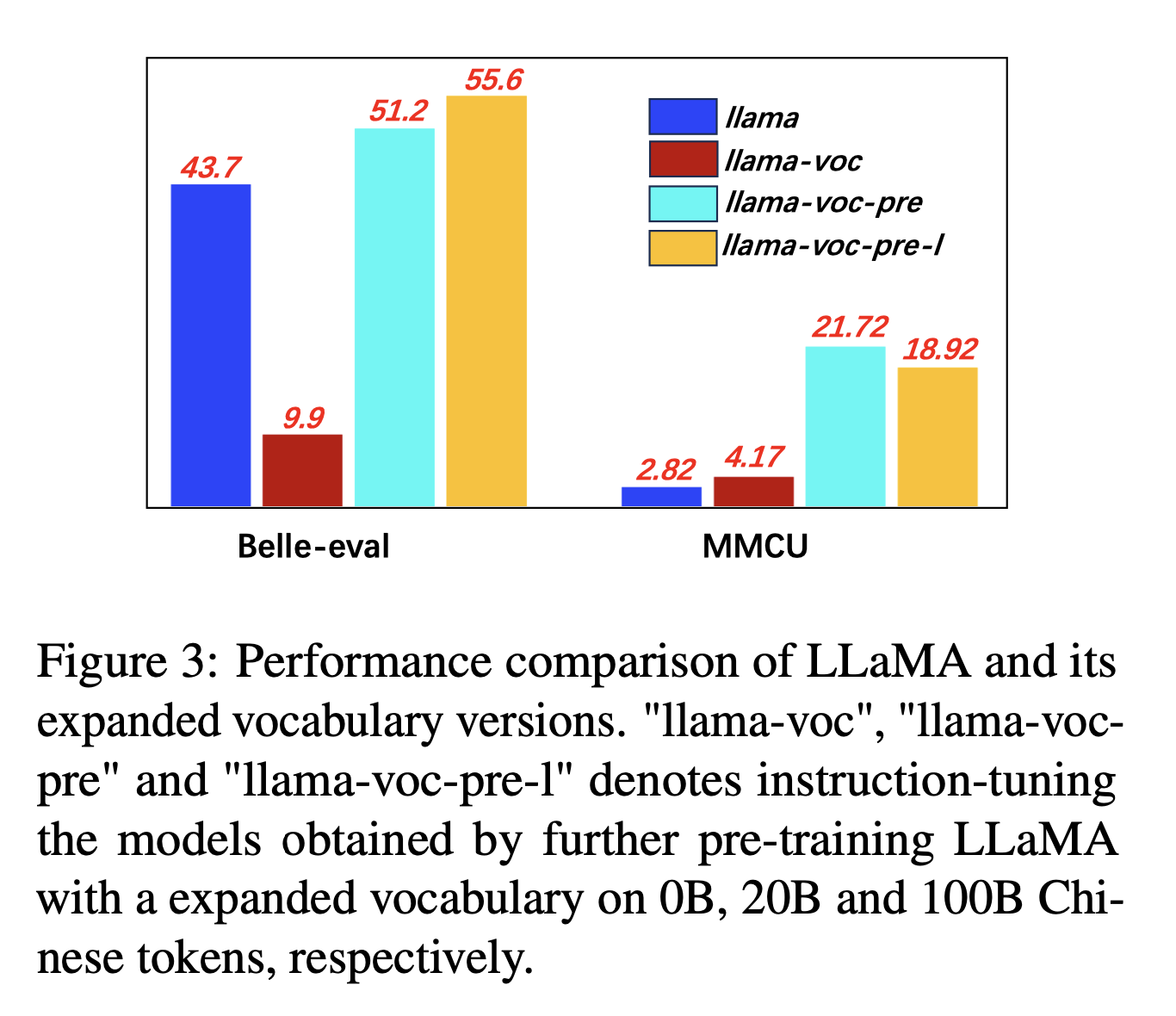
Résultats expérimentaux:
La pré-formation sur plus de corpus chinois avec l'expansion du vocabulaire chinois est toujours utile pour la capacité de suivi des instructions.
Et contre-intuitivement, "Llama-Voc-Pre-L" (100B) est inférieur à "LLAMA-VOC-PRE" (20B) sur MMCU, ce qui montre que la pré-formation sur plus de données ne peut pas nécessairement conduire à des performances plus élevées pour les examens académiques.
Pour le langage des invites, les auteurs testent la pertinence de l'instruction affinée pour utiliser les invites chinoises.
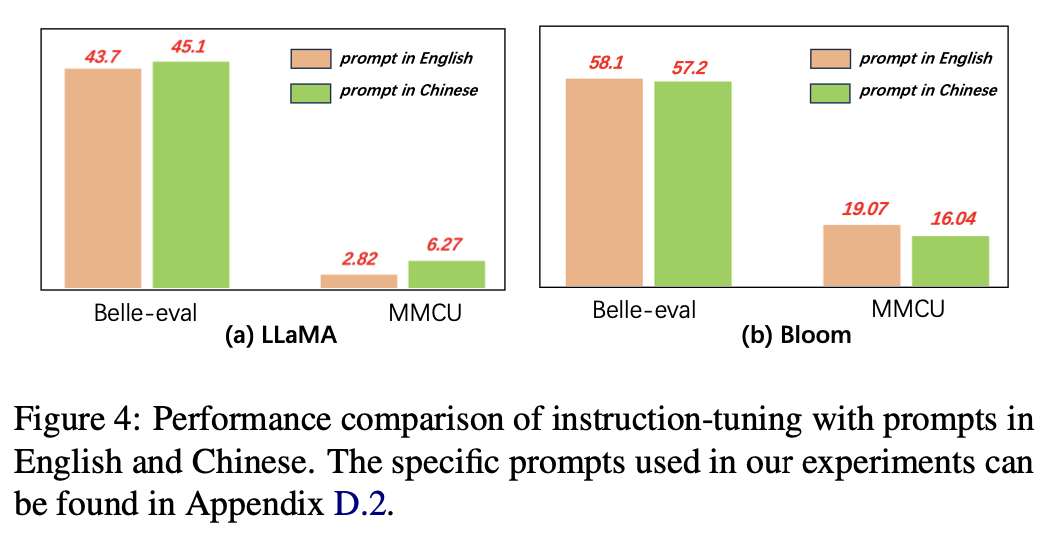
La figure 4 montre les résultats de l'utilisation des invites chinoises et anglaises basées sur Llama et Bloom. Lorsque vous avez réglé l'instruction, l'utilisation d'invites chinoises peut améliorer les performances des deux repères par rapport aux invites en anglais, tandis que le phénomène opposé peut être observé sur la floraison.
Résultats expérimentaux:
Pour les modèles avec des capacités chinoises plus faibles (par exemple, LLAMA), l'utilisation des invites chinoises peut efficacement aider à répondre en chinois.
Pour les modèles avec de bonnes capacités chinoises (par exemple, Bloom), l'utilisation d'invites en anglais (la langue dans laquelle ils sont meilleurs) peuvent mieux guider le modèle pour comprendre le processus de réglage fin avec des instructions.
Pour éviter la génération de contenu toxique du LLMS, les aligner sur les valeurs humaines est un problème crucial. Nous ajoutons des données d'alignement de valeur humaine construites par COIG dans le réglage de l'instruction pour explorer son impact.
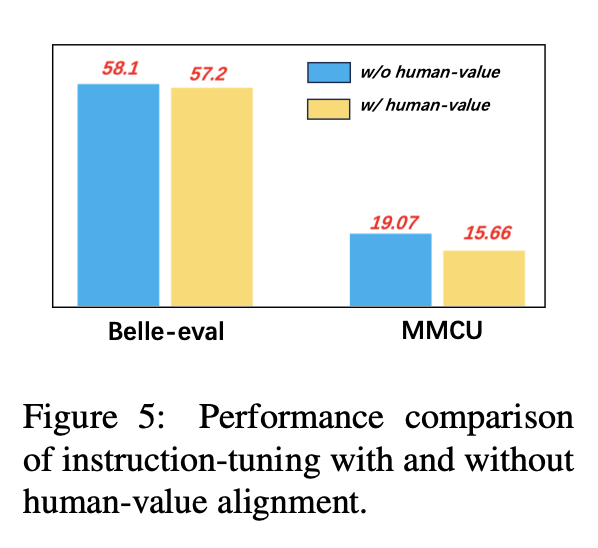
La figure 5 compare les résultats du réglage de l'instruction avec et sans alignement de la valeur humaine.
Résultats expérimentaux: l'alignement de la valeur humaine entraîne une légère baisse de performance. Comment équilibrer l'incapacité et les performances des LLM est une direction de recherche qui mérite d'être explorée à l'avenir.
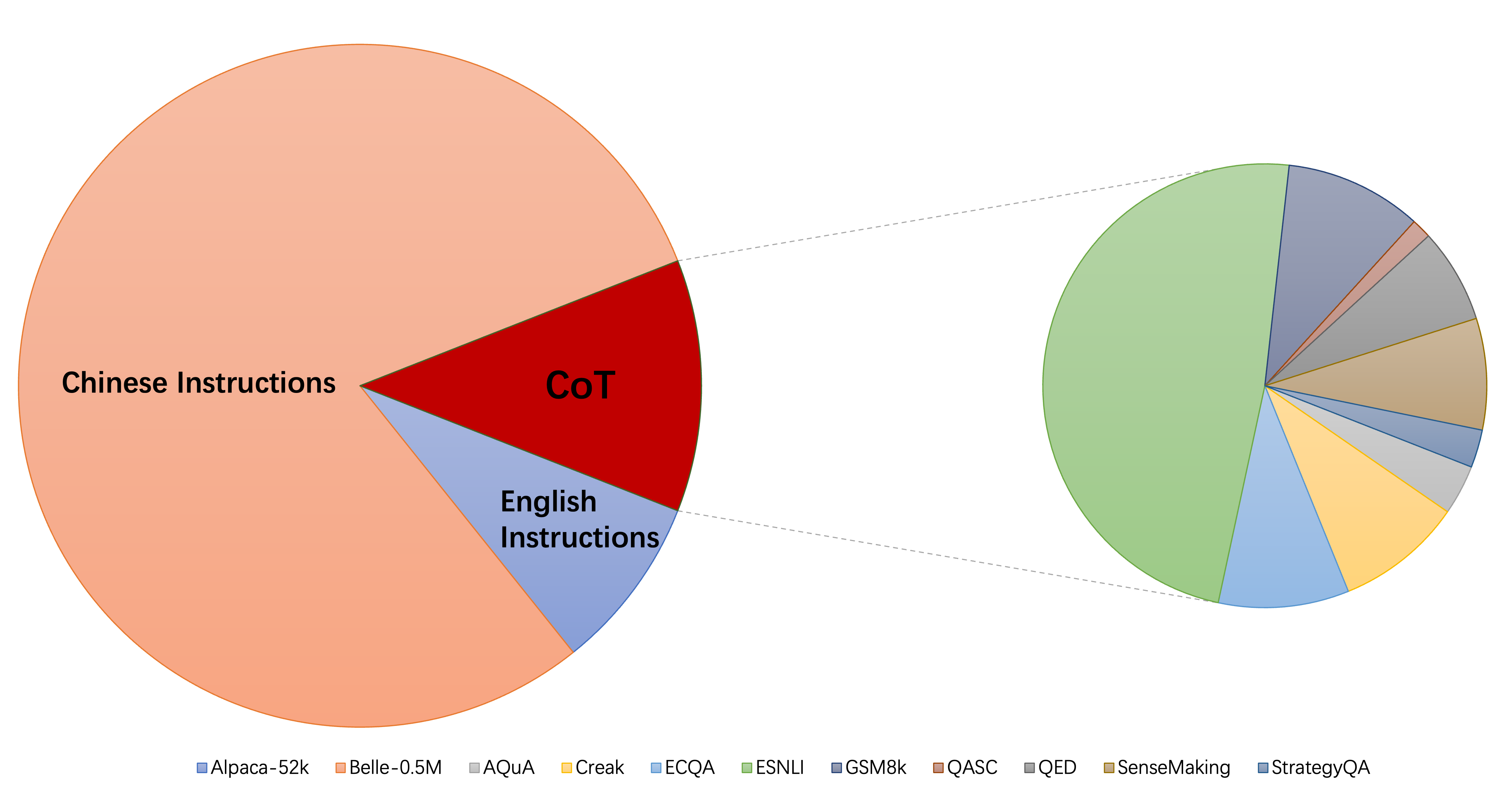 La collection actuelle d'ensembles de données d'instructions-Finetuning se compose principalement de trois parties:
La collection actuelle d'ensembles de données d'instructions-Finetuning se compose principalement de trois parties:
alpaca_data_cleaned.json : environ 52k échantillons de formation de suivi des instructions en anglais.CoT_data.json : 9 ensembles de données COT impliquant environ 75k échantillons. (Publié par Flan [7])belle_data_cn.json : environ 0,5 m chinois | échantillons de formation suivant les instructions. (Publié par Belle [8]) "W / O COT" et "W / O CN" désignent des modèles qui excluent respectivement les données du COT et les instructions chinoises de leurs instructions.
"W / O COT" et "W / O CN" désignent des modèles qui excluent respectivement les données du COT et les instructions chinoises de leurs instructions.
Le tableau ci-dessus montre deux exemples (impliquant des calculs numériques) qui nécessitent une certaine capacité de raisonnement à répondre correctement. Comme le montre la colonne du milieu, Ours w/o CoT ne parvient pas à générer la réponse correcte, ce qui montre qu'une fois que les données de finetuning ne contiennent pas de données COT, la capacité de raisonnement du modèle diminue considérablement. Cela démontre en outre que les données de COT sont essentielles pour les modèles LLM.

Le tableau ci-dessus montre deux exemples qui nécessitent la capacité de répondre aux instructions chinoises. Comme indiqué dans la colonne de droite, soit le contenu généré de Ours w/o CN est déraisonnable, soit les instructions chinoises sont répondues en anglais par Ours w/o CN . Cela montre que la suppression des données chinoises pendant les finetuning entraînera la naissance du modèle de gérer les instructions chinoises, et démontre en outre la nécessité de collecter des données de finetuning d'instructions chinoises.

Le tableau ci-dessus montre un exemple relativement difficile, qui nécessite à la fois une certaine accumulation de connaissances de l'histoire chinoise et une capacité logique et complète à énoncer les événements historiques. Comme le montre ce tableau, Ours w/o CN ne peut générer qu'une réponse courte et erronée, car en raison de l'absence de données chinoises en matière de finetun, la connaissance correspondante de l'histoire chinoise fait naturellement défaut. Bien que Ours w/o CoT répertorie certains événements historiques chinois pertinents, sa logique d'expression est l'auto-contradictoire, qui est causée par le manque de données de COT. '
En résumé, les modèles amenés à partir de notre ensemble de données complet (données d'anglais, de chinois et de COT) peuvent améliorer considérablement le raisonnement du modèle et les instructions chinoises après les capacités.
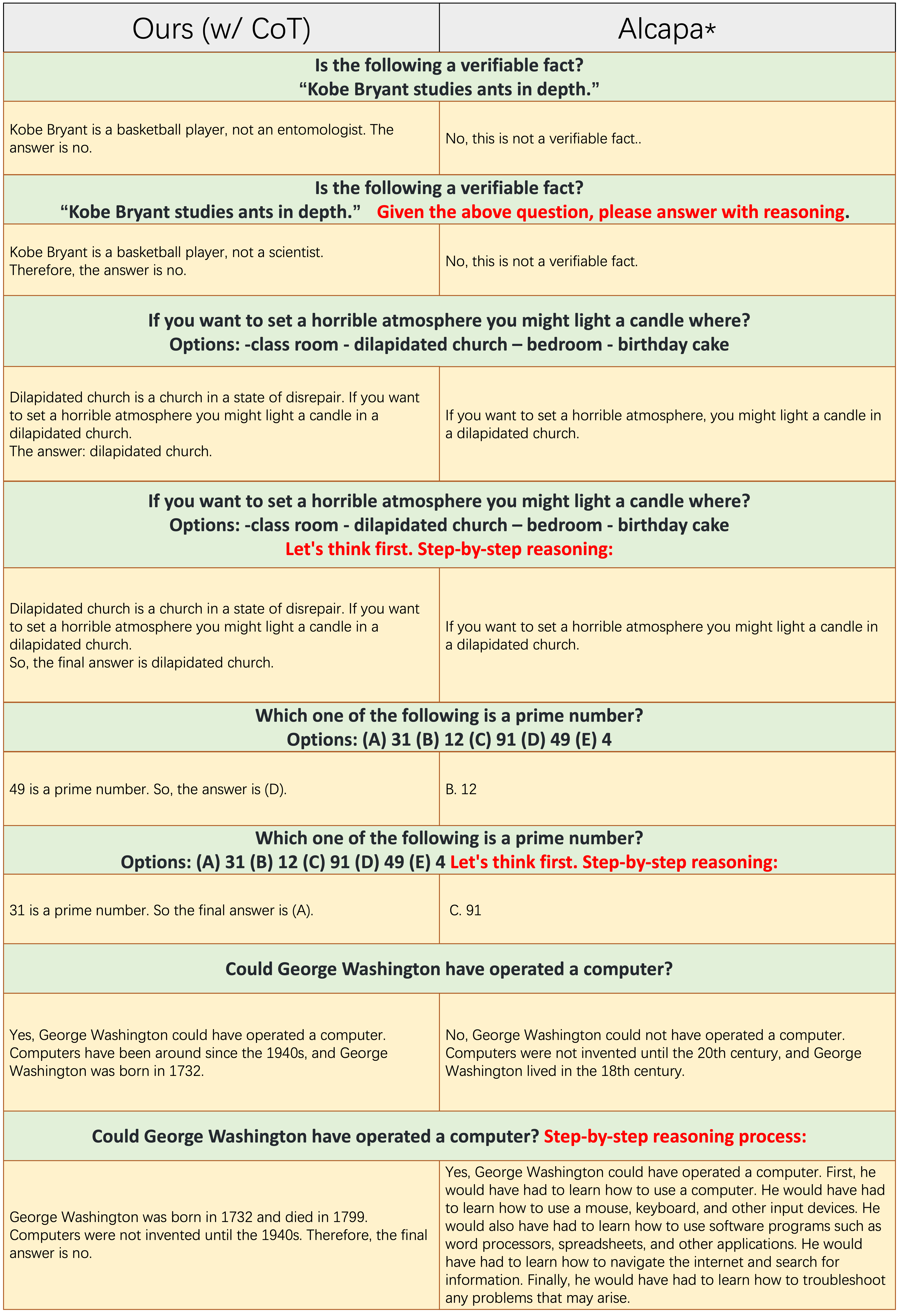 Les échantillons de chaque nombre impair de lignes n'appliquent pas l'invite de lit de lit, comme le «raisonnement étape par étape».
Les échantillons de chaque nombre impair de lignes n'appliquent pas l'invite de lit de lit, comme le «raisonnement étape par étape». Ours(w/CoT) et l'alpaga sont basés sur LLAMA-7B, et la seule différence entre eux deux est que les données d'instructions-finetuning de Ours(w/CoT) ont des données COT supplémentaires que celles de l'alpaga.
Depuis le tableau ci-dessus, nous constatons que:
Ours(w/CoT) génère toujours la justification correcte avant la réponse, tandis qu'Alpaga ne génére pas de justification raisonnable, comme le montre les 4 premiers exemples (questions de bon sens). Cela montre que l'utilisation des données de COT pour les fusions peut améliorer considérablement la capacité de raisonnement.Ours(w/CoT) , l'invite de COT (par exemple, le concaténer «étape par étape» avec la question d'entrée) a peu d'effet sur des exemples faciles (par exemple, des questions de bon sens) et a un effet important sur les questions difficiles (par exemple, les questions nécessitant un raisonnement, comme les quatre derniers exemples). Comparaison quantitative des réponses aux instructions chinoises. 
Notre modèle est financé à partir d'un lama 7b sur des instructions en anglais 52k et des instructions chinoises de 0,5 m. Stanford Alpaca (notre réimplémentation) est financé à partir d'un lama 7b sur les instructions en anglais 52k. Belle est entinée à partir d'une floraison 7B sur les instructions chinoises 2b.
Depuis le tableau ci-dessus, plusieurs observations peuvent être trouvées:
ours (w/ CN) a une plus grande capacité à comprendre les instructions chinoises. Pour le premier exemple, Alpaca ne fait pas la distinction entre la partie instruction et la partie input , pendant que nous le faisons.ours (w/ CN) fournit non seulement le code correct, mais fournit également l'annotation chinoise correspondante, contrairement à Alpaca. De plus, comme le montre les 3-5 exemples, l'alpaga ne peut répondre qu'à l'instruction chinoise avec une réponse en anglais.ours (w/ CN) sur les instructions nécessitant une réponse ouverte (comme le montre les deux derniers exemples) doivent encore être améliorées. Les performances exceptionnelles de Belle contre ces instructions sont dues à: 1. Son modèle de squelette Bloom rencontre des données beaucoup plus multilingues pendant la pré-formation; 2. Ses données de fin d'études de l'instruction chinoise sont plus que la nôtre, c'est-à-dire 2 m contre 0,5 m. Comparaison quantitative des réponses aux instructions en anglais. Le but de cette sous-section est d'explorer si le finetuning sur les instructions chinoises a un impact négatif sur l'alpaga. 
Depuis le tableau ci-dessus, nous constatons que:
ours (w/ CN) montre plus de détails que celle de l'alpaga, par exemple pour le troisième exemple, ours (w/ CN) répertorie trois provinces supplémentaires que l'alpaga. Veuillez citer le dépôt si vous utilisez la collecte de données, le code et les résultats expérimentaux dans ce référentiel.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Pour les données et les modèles, veuillez citer les données d'origine, les méthodes économes et économes par les paramètres et la source LLMS.
Nous tenons à exprimer notre gratitude spéciale à Apus Ailme Lab pour avoir parrainé les 8 GPU A100 pour les expériences.
(retour en haut)


