Alpaca CoT
1.0.0
中文| Inglês

Este é o repositório para o projeto Alpaca-CoT , que visa criar uma plataforma Finetuning de Instruções (IFT) com extensa coleção de instruções (especialmente os conjuntos de dados do COT) e uma interface unificada para vários modelos de idiomas grandes e métodos eficientes em termos. Estamos constantemente expandindo nossa coleta de dados de ajuste de instrução e integrando mais métodos LLMs e mais eficientes em parâmetro. Além disso, criamos um novo ramo tabular_llm para criar um LLM tabular para resolver tarefas de inteligência de tabela.
Você é calorosamente bem-vindo para nos fornecer quaisquer conjuntos de dados de ajuste de instrução não coletados (ou suas fontes). Nós os formaremos uniformemente, treinaremos o modelo Alpaca (e outros LLMs no futuro inicial) com esses conjuntos de dados, de código aberto dos pontos de verificação do modelo e realizarão extensos estudos empíricos. Esperamos que nosso projeto possa fazer uma contribuição modesta para o processo de código aberto de grandes modelos de linguagem e reduzir seu limite para os pesquisadores da PNL começarem.

Se você deseja usar outros métodos além da Lora, instale a versão editada em nosso projeto pip install -e ./peft .
12.8: O LLM InternLM foi mesclado.
8.16: 4bit quantization está disponível para lora , qlora e adalora .
8.16: Métodos de parâmetro eficientes Qlora , Sequential adapter e Parallel adapter foram mesclados.
7.24: LLM ChatGLM v2 foi mesclado.
7.20: LLM Baichuan foi fundido.
6.25: Adicione o código de avaliação do modelo, incluindo Belle e MMCU.
GPT4Tools , Auto CoT , pCLUE são adicionados.tabular_llm é criado para criar um LLM tabular. Coletamos instruções de ajuste fino de dados para tarefas relacionadas à tabela, como resposta a perguntas da tabela, e os usamos para ajustar os LLMs neste repositório.MOSS foi fundido.GAOKAO , camel , FLAN-Muffin , COIG são coletados e formatados.webGPT , dolly , baize , hh-rlhf , OIG(part) são coletados e formatados.multi-turn conversation por @paulcx.firefly , instruct , Code Alpaca são coletados e formatados, que podem ser encontrados aqui.Parameter merging , Local chatting , Batch predicting e Web service building por @weberr.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 e natural-instructions são coletados e formatados.CoT_CN_data.json pode ser encontrado aqui. 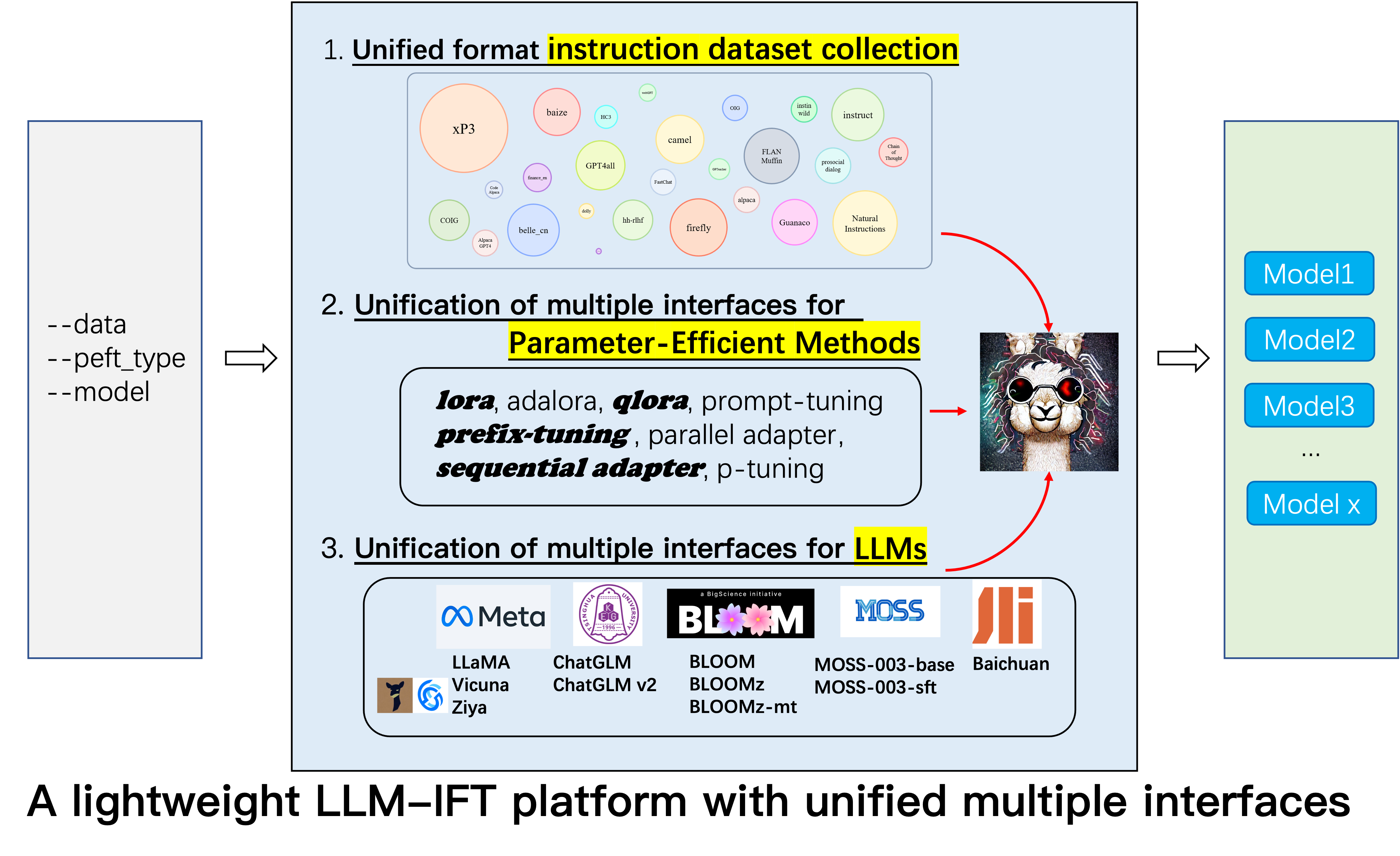
Llama [1] é um ótimo trabalho que demonstra a incrível habilidade de zero e poucos anos. Reduz significativamente o custo de treinamento, finetuning e uso de modelos de idiomas grandes competitivos, o IE, o LLAMA-13B supera o GPT-3 (175B) e o llama-65b é competitivo com o PALM-540B. Recentemente, para impulsionar a capacidade de acompanhar as instruções da LLAMA, Stanford Alpaca [2] Finetuned Llama-7b em 52k seguintes dados que seguem os dados gerados pelas técnicas de auto-estrutura [3]. No entanto, atualmente, a comunidade de pesquisa LLM ainda enfrenta três desafios: 1. Até a LLAMA-7B ainda possui altos requisitos para a computação de recursos; 2. Existem poucos conjuntos de dados de código aberto para a instrução finetuning; e 3. Há uma falta de estudo empírico sobre o impacto de vários tipos de instrução sobre as habilidades do modelo, como a capacidade de responder à instrução chinesa e ao raciocínio do COT.
Para esse fim, propomos este projeto, que aproveita várias melhorias que foram propostas posteriormente, com as seguintes vantagens:
7b , 13b e 30b dos modelos de llama podem ser facilmente treinadas em um único 80G A100. Até onde sabemos, este trabalho é o primeiro a estudar o raciocínio do COT baseado em lhama e alpaca. Portanto, abreviamos nosso trabalho para Alpaca-CoT .
O tamanho relativo dos conjuntos de dados coletados pode ser mostrado por este gráfico:
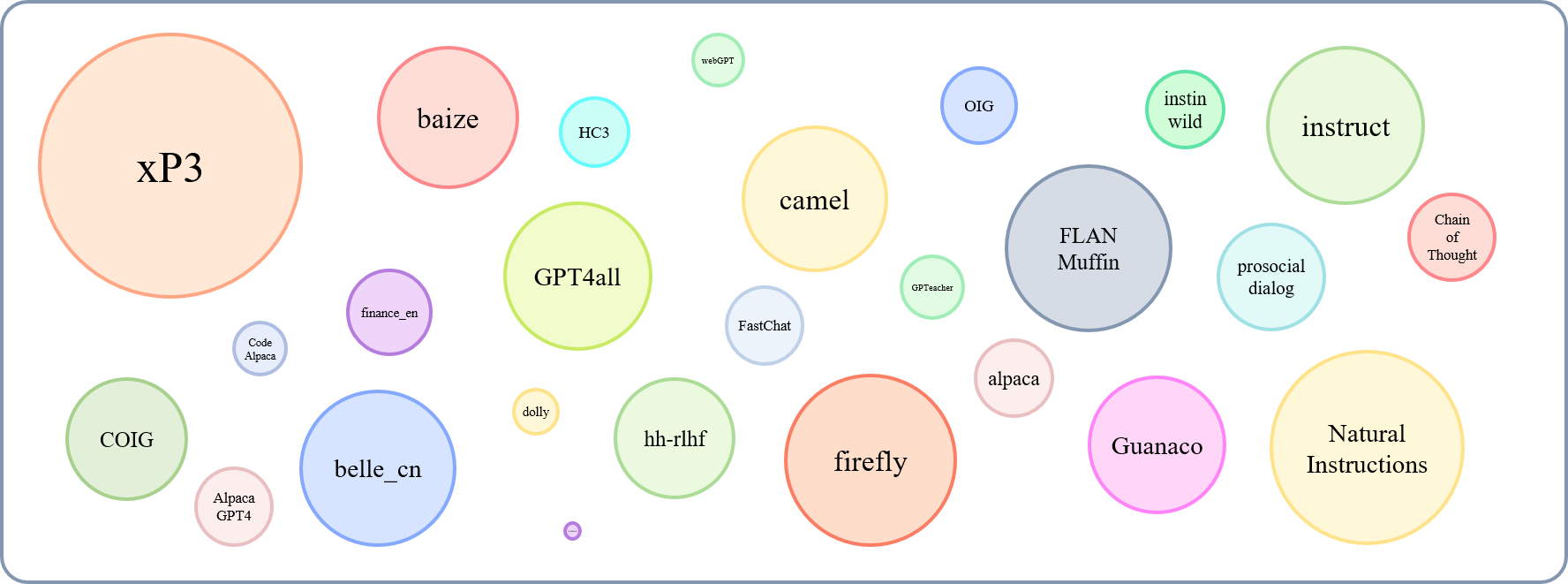
Referindo -se a isso (@yaodongc), rotulamos cada conjunto de dados coletado de acordo com as seguintes regras:
(Lang) Lingual-Tags:
(Tarefa) Tases de tarefas:
(Gen) geração-metódio:
| Conjunto de dados | Nums | Lang | Tarefa | Gen | Tipo | Src | Url |
|---|---|---|---|---|---|---|---|
| Cadeia de pensamento | 74771 | Pt/cn | Mt | Hg | Instrua com o raciocínio da BOT | Anotar o berço dos dados existentes | download |
| Gpt4all | 806199 | En | Mt | Col | Código, histórias e diálogos | Destilação do GPT-3.5-Turbo | download |
| Gptoacher | 29013 | En | Mt | SI | Geral, Roleplay, Ferramentas | GPT-4 e Ferramentas | download |
| Guanaco | 534610 | Ml | Mt | SI | várias tarefas linguísticas | Text-Davinci-003 | download |
| HC3 | 37175 | Pt/cn | Ts | MISTURA | Avaliação de diálogo | humano ou chatgpt | download |
| alpaca | 52002 | En | Mt | SI | Instrução geral | Text-Davinci-003 | download |
| Instruções naturais | 5040134 | Ml | Mt | Col | Diversas tarefas de PNL | Coleção de conjuntos de dados anotados humanos | download |
| belle_cn | 1079517 | Cn | TS/MT | SI | Raciocínio geral, matemático, diálogo | Text-Davinci-003 | download |
| instinwild | 52191 | Pt/cn | Mt | SI | Geração, Open-QA, tempestade mental | Text-Davinci-003 | download |
| diálogo pró -social | 165681 | En | Ts | MISTURA | diálogo | GPT-3 reescreve perguntas + feedback dos humanos manualmente | download |
| Finance_en | 68912 | En | Ts | Col | QA relacionado financeiro | GPT3.5 | download |
| xp3 | 78883588 | Ml | Mt | Col | Uma coleção de instruções e conjuntos de dados em 46 idiomas e 16 tarefas de NLP | Coleção de conjuntos de dados anotados humanos | download |
| Firefly | 1649398 | Cn | Mt | Col | 23 tarefas de PNL | Coleção de conjuntos de dados anotados humanos | download |
| instruir | 888969 | En | Mt | Col | Aumentado de GPT4all, Alpaca, Meta-fonte aberta DatAsets | Aumento realizado usando as ferramentas avançadas de PNL fornecidas por Allenai | download |
| Código Alpaca | 20022 | En | Ts | SI | Geração de código, edição, otimização | Text-Davinci-003 | download |
| ALPACA_GPT4 | 52002 | Pt/cn | Mt | SI | Instrução geral | gerado pelo GPT-4 usando alpaca | download |
| webgpt | 18994 | En | Ts | MISTURA | Recuperação de informações (IR) QA | GPT-3 ajustado, cada instrução tem duas saídas, selecione melhor | download |
| Dolly 2.0 | 15015 | En | Ts | Hg | QA fechado, resumo e etc, Wikipedia como referências | Humano anotado | download |
| baize | 653699 | En | Mt | Col | Uma coleção de Alpaca, Quora, Stackoverflow e Perguntas de Medquad | Coleção de conjuntos de dados anotados humanos | download |
| HH-RLHF | 284517 | En | Ts | MISTURA | diálogo | diálogo entre modelos humanos e RLHF | download |
| OIG (parte) | 49237 | En | Mt | Col | criado a partir de várias tarefas, como perguntas e respostas | Usando aumento de dados, coleção de conjuntos de dados anotados humanos | download |
| Gaokao | 2785 | Cn | Mt | Col | Múltipla escolha, preencher as perguntas em branco e aberta do exame | Humano anotado | download |
| camelo | 760620 | En | Mt | SI | Conversas de interpretação de papéis na sociedade de IA, código, matemática, física, química, biólogo | GPT-3.5-Turbo | download |
| Flan-Muffin | 1764800 | En | Mt | Col | 60 tarefas de PNL | Coleção de conjuntos de dados anotados humanos | download |
| Coig (flaginstruct) | 298428 | Cn | Mt | Col | Colete o exame de Fron, traduzido, instruções de alinhamento de valor humano e correção contrafactural de bate-papo multi-rodada | Usando ferramentas automáticas e verificação manual | download |
| Gpt4Tools | 71446 | En | Mt | SI | Uma coleção de instruções relacionadas à ferramenta | GPT-3.5-Turbo | download |
| Sharechat | 1663241 | En | Mt | MISTURA | Instrução geral | Crowdsourcing para coletar conversas entre pessoas e ChatGPT (compartilhamento) | download |
| Berço automático | 5816 | En | Mt | Col | Tarefas aritméticas, comuns, simbólicas e outras tarefas lógicas | Coleção de conjuntos de dados anotados humanos | download |
| MUSGO | 1583595 | Pt/cn | Ts | SI | Instrução geral | Text-Davinci-003 | download |
| Ultrachat | 28247446 | En | Perguntas sobre o mundo, escrita e criação, assistência em materiais existentes | Dois GPT-3.5-Turbo separados | download | ||
| Chinês-médico | 792099 | Cn | Ts | Col | Perguntas sobre conselhos médicos | arrastar | download |
| Csl | 396206 | Cn | Mt | Col | geração de texto em papel, extração de palavras -chave, resumo de texto e classificação de texto | arrastar | download |
| Pclue | 1200705 | Cn | Mt | Col | Instrução geral | download | |
| news_commentário | 252776 | Cn | Ts | Col | traduzir | download | |
| Stackllama | pendência | En |
Você pode baixar todos os dados formatados aqui. Então você deve colocá -los na pasta de dados.
Você pode baixar todos os pontos de verificação treinados em vários tipos de dados de instruções daqui. Então, depois de definir LoRA_WEIGHTS (no generate.py ) para o caminho local, você pode executar diretamente a inferência do modelo.
Todos os dados em nossa coleção são formatados nos mesmos modelos, onde cada amostra é a seguinte:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Observe que, para os conjuntos de dados do COT, primeiro usamos o modelo fornecido pela Flan para alterar o conjunto de dados original em vários formulários de cadeia de thoughts e depois convertê-lo no formato acima. O script de formatação pode ser encontrado aqui.
pip install -r requirements.txt
Observe que, verifique se Python> = 3.9 ao Finetuning Chatglm.
Peft
pip install -e ./peft
Para que os pesquisadores conduzam pesquisas sistemáticas de IFT sobre LLMs, coletamos diferentes tipos de dados de instruções, integrados múltiplos LLMs e interfaces unificadas, facilitando a personalização da localização desejada:
--model_type : defina o LLM que você deseja usar. Atualmente, [Llama, ChatGlm, Bloom, Moss] são suportados. Os dois últimos têm fortes capacidades chinesas e mais LLMs serão integrados no futuro.--peft_type : Defina o Peft que você deseja usar. Atualmente, [Lora, Adalora, ajuste de prefixo, ajuste P, Prompt] são suportados.--data : Defina o tipo de dados usado para o IFT para adaptar flexibilidade a capacidade de conformidade de comando desejada. Por exemplo, para uma forte capacidade de raciocínio, defina "Alpaca-COT", para uma forte habilidade chinesa, defina "Belle1.5m", para codificação e capacidade de geração de histórias, definir "GPT4all" e para capacidade de resposta relacionada financeira, definir "finanças".--model_name_or_path : Isso está definido para carregar versões diferentes dos pesos do modelo para o destino LLM --model_type . Por exemplo, para carregar a versão 13B dos pesos da LLAMA, você pode definir decapoda-research/llama-13b-hf.GPU único
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
Nota: Para vários conjuntos de dados, você pode usar --data como --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Observe que load_in_8bit ainda não é adequado para chatglm, portanto, Batch_Size deve ser menor que outros.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Observe que você também pode passar no caminho local (onde os pesos LLM salvos) para --model_name_or_path . E o tipo de dados --data pode ser definido livremente de acordo com seus interesses.
GPUs múltiplas
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Observe que load_in_8bit ainda não é adequado para chatglm, portanto, Batch_Size deve ser menor que outros.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Mais detalhes da finaneção e inferência de instrução podem ser encontrados aqui de onde modificamos. Observe que as pastas saved-xxx7b são o caminho de salvamento para os pesos da LORA, e os pesos de lhama são baixados automaticamente de abraçar o rosto.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Este artigo seleciona dois benchmarks de avaliação, Belle-Eval e MMCU, para avaliar de forma abrangente as competências da LLM em chinês.
A Belle-Eval é construída pela auto-estrutura com o ChatGPT, que possui 1.000 instruções diversas que envolvem 10 categorias que abrangem tarefas comuns de PNL (por exemplo, controle de qualidade) e tarefas desafiadoras (por exemplo, código e matemática). Usamos o ChatGPT para avaliar as respostas do modelo com base nas respostas douradas. Este benchmark é considerado como a avaliação da capacidade da AGI (seguinte a instrução).
O MMCU é uma coleção de perguntas de múltipla escolha chinesa em quatro disciplinas profissionais de medicina, direito, psicologia e educação (por exemplo, exame de Gaokao). Ele permite que os LLMs façam exames na sociedade humana de maneira ao teste de múltipla escolha, tornando-o adequado para avaliar a amplitude e a profundidade do conhecimento do LLMS em várias disciplinas.
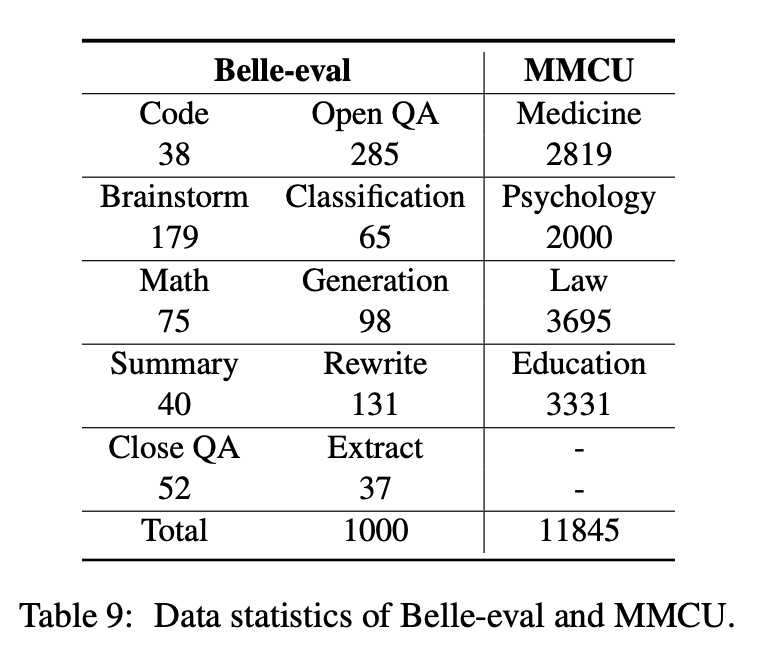
As estatísticas de dados de Belle-Eval e MMCU são mostradas na tabela acima.
Realizamos experimentos para estudar os três principais fatores em LLMs de ajuste de instrução: bases LLM, métodos com eficiência de parâmetro, conjuntos de dados de instruções chinesas.
Para o Open LLMS, testamos os LLMs e LLMs existentes com LORA no Alpaca-GPT4 em Belle-Eval e MMCU, respectivamente.
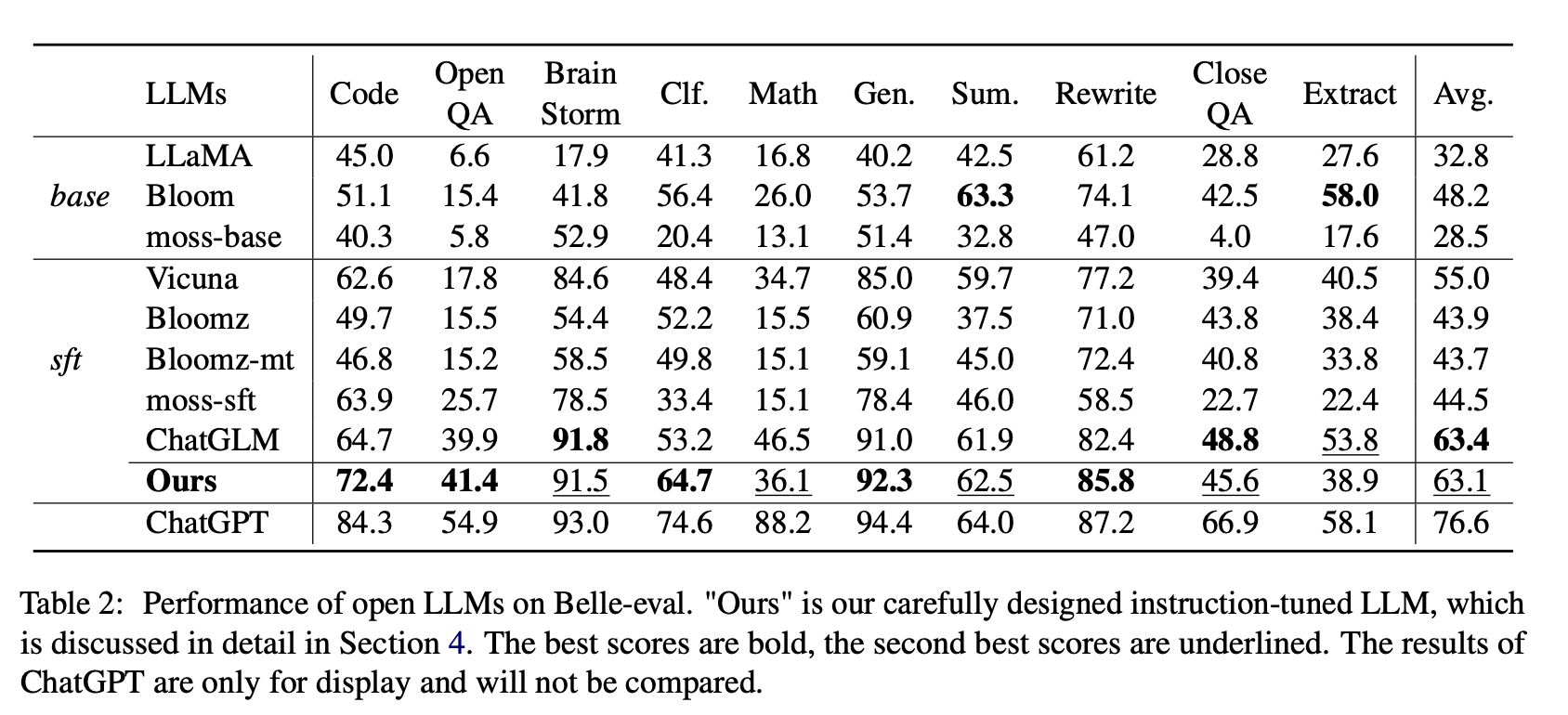
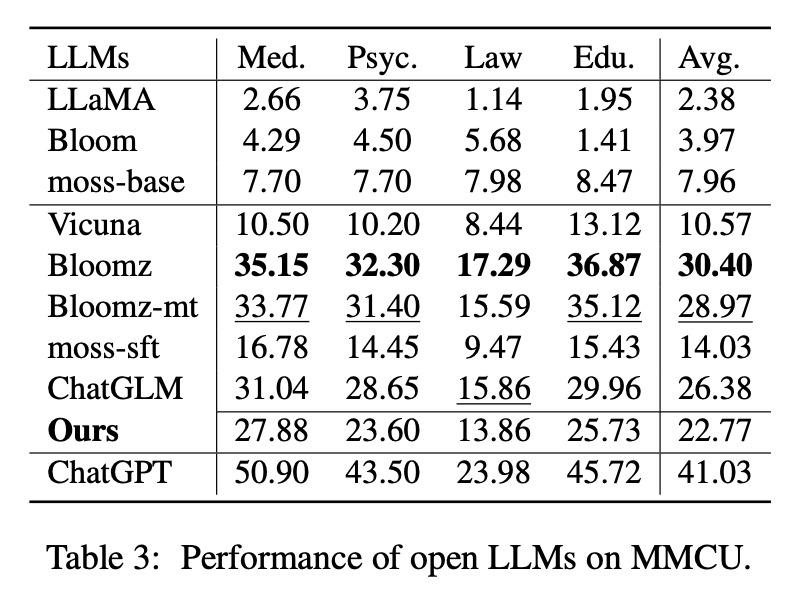
A Tabela 2 mostra as pontuações do Open LLMS no Belle-Eval. A Tabela 3 mostra a precisão do LLMS no MMCU. Eles ajustam todos os LLMs abertos com o mesmo método eficiente de parâmetro Lora e o mesmo conjunto de dados de instrução ALPACA-GPT4.
Resultados experimentais:
Avaliação dos LLMs existentes
Desempenho em Belle-Eval
(1) Para Base LLMS, a Bloom tem o melhor desempenho.
(2) Para a SFT LLMS, o ChatGlm supera os outros por grandes margens, graças ao fato de ser treinado com os tokens mais chineses e o HFRL.
(3) As categorias abertas de controle de qualidade, matemática, closeqa e extração ainda são muito desafiadoras para os LLMs abertos existentes.
(4) Vicuna e Moss-SFT têm melhorias claras em comparação com suas bases, lhama e Moss-Base, respectivamente.
(5) Por outro lado, o desempenho dos modelos SFT, Bloomz e Bloomz-MT, é reduzido em comparação com a flor do modelo base, porque eles tendem a gerar uma resposta mais curta.
Desempenho no MMCU
(1) Todos os LLMs básicos têm um desempenho ruim, porque é quase difícil gerar conteúdo no formato especificado antes do ajuste fino, por exemplo, números de opções de saída.
(2) Todos os SFT LLMs superam seus LLMs de base correspondentes, respectivamente. Em particular, a Bloomz executa o melhor (até vence o chatglm) porque pode gerar o número da opção diretamente, conforme necessário, sem gerar outro conteúdo irrelevante, o que também se deve às características dos dados de seu conjunto de dados de ajuste fino supervisionado XP3.
(3) Entre as quatro disciplinas, a lei é a mais desafiadora para os LLMs.
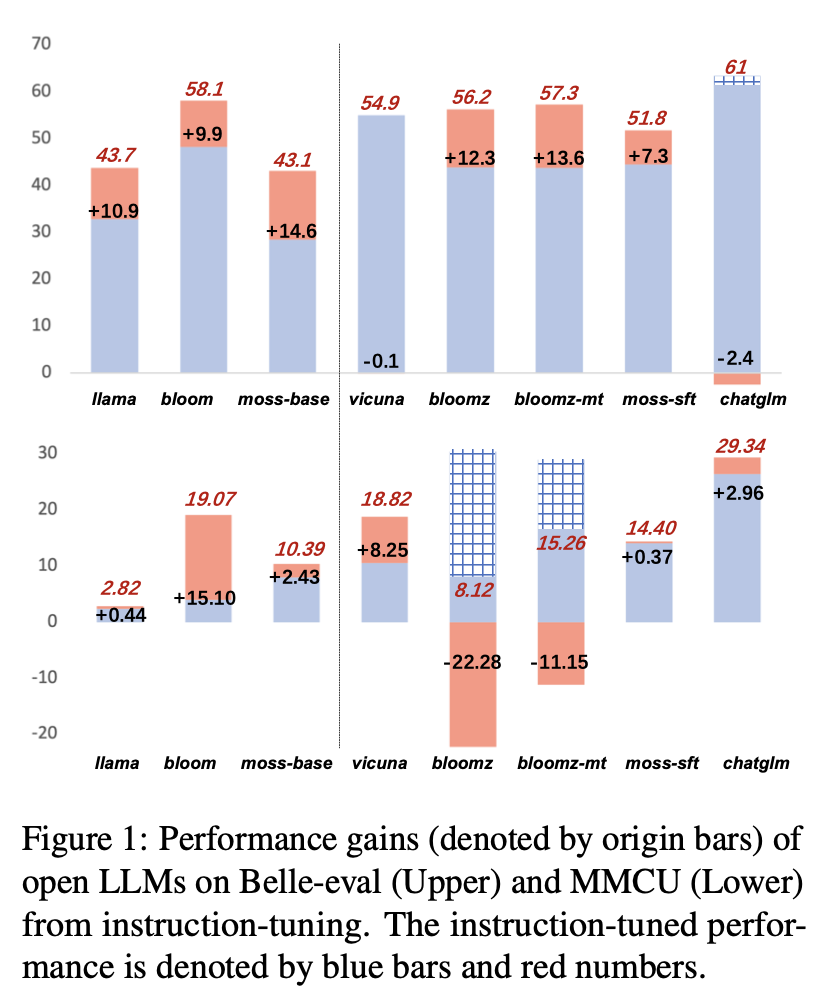
Os resultados de desempenho dos LLMs após o ajuste das instruções no ALPACA-GPT4-ZH são mostrados na Figura 1.
Ajuste de instrução LLMS diferentes
(1) Em Belle-Eval, a melhoria do desempenho do SFT LLMS trazida pelo ajuste de instrução não é tão significativa quanto a do Base LLMS, exceto a SFT Bloomz e a Bloomz-Mt.
(2) O desempenho do encontro de Vicuna e Chatglm cai após o ajuste das instruções, porque Vicuna é treinado em conversas reais de chatgpt humano, com melhor qualidade que o Alpaca-GPT4. O ChatGlm adota o HFRL, que pode não ser mais adequado para ajustes adicionais de instruções.
(3) No MMCU, a maioria dos LLMs alcançam o aumento de desempenho após o ajuste das instruções, com exceção de Bloomz e Bloomz-MT, que inesperadamente diminuíram significativamente o desempenho.
(4) Após o ajuste das instruções, a Bloom tem melhorias significativas e tem um bom desempenho nos dois benchmarks. Embora o ChatGlm venha a Bloom de forma consistente, ele sofre queda de desempenho durante o ajuste das instruções. Portanto, entre todos os LLMs abertos, a Bloom é mais adequada como modelo de fundação nos experimentos subsequentes para a exploração de ajuste de instrução chinesa.
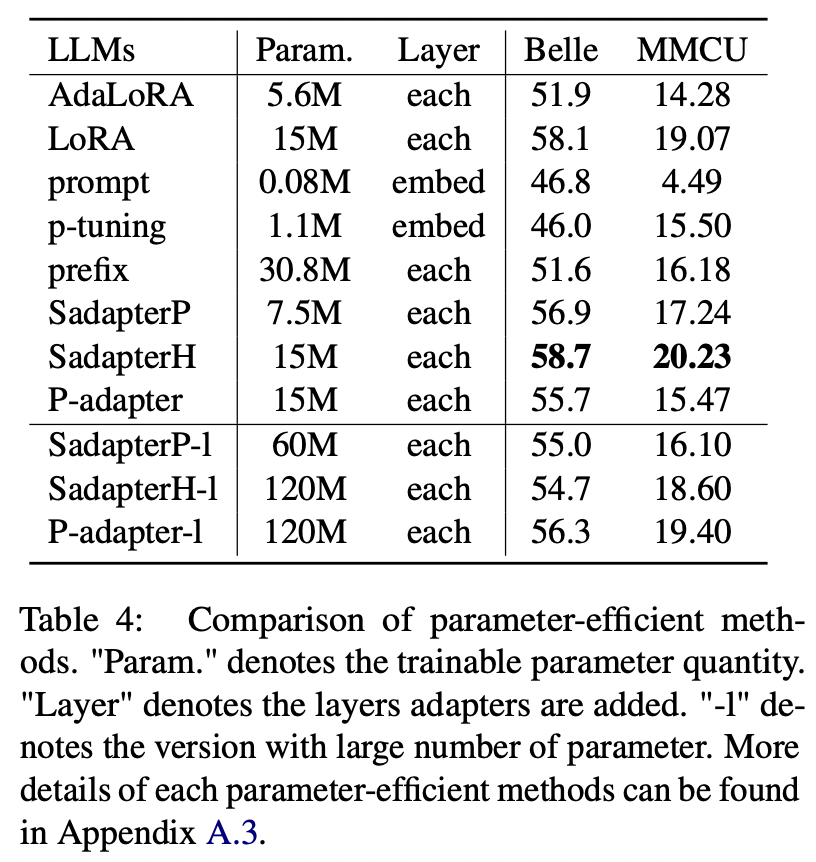
Para métodos eficientes em parâmetro que não sejam LORA, o artigo coleta uma variedade de métodos eficientes em parâmetro para combater a instrução no conjunto de dados ALPACA-GPT4.
Resultados experimentais:
Comparação de métodos eficientes em parâmetro
(1) SADAPTERH tem o melhor desempenho entre todos os métodos eficientes em parâmetro, que podem ser usados como alternativa ao LORA.
(2) O ajuste P e o ajuste rápido tem um desempenho abaixo do desempenho por grandes margens, indicando que apenas a adição de camadas treináveis na camada de incorporação não é suficiente para suportar LLMs para tarefas de geração.
(3) Embora Adalora seja uma melhoria da LORA, seu desempenho tem uma queda clara, possivelmente porque os parâmetros treináveis da LORA para LLMs não são adequados para redução adicional.
(4) Comparando as partes superior e inferior, pode-se observar que aumentar o número de parâmetros treináveis para adaptadores seqüenciais (ou seja, sadapterp e sadapterh) não traz ganho, enquanto o fenômeno oposto é observado para adaptadores paralelos (ou seja, p-adaptador)
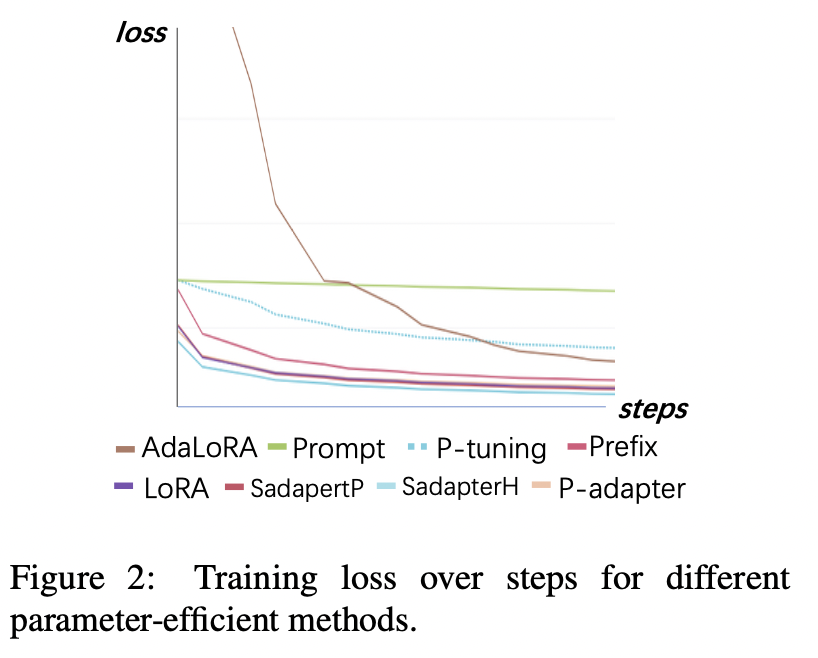
Perda de treinamento
(1) O ajuste rápido e o ajuste p convergem mais lentos e têm as maiores perdas após a convergência. Isso mostra que os adaptadores somente de incorporação não são adequados para o LLMS de ajuste de instrução.
(2) A perda inicial de Adalora é muito alta porque requer aprendizado simultâneo da alocação do orçamento de parâmetros, o que torna o modelo incapaz de se ajustar bem aos dados de treinamento.
(3) Os outros métodos podem convergir rapidamente nos dados de treinamento e encaixá -los bem.
Para o impacto de vários tipos de conjuntos de dados de instruções chinesas, os autores reúnem instruções abertas em chinês populares (como mostrado na Tabela 5) para ajustar a floração com a Lora.
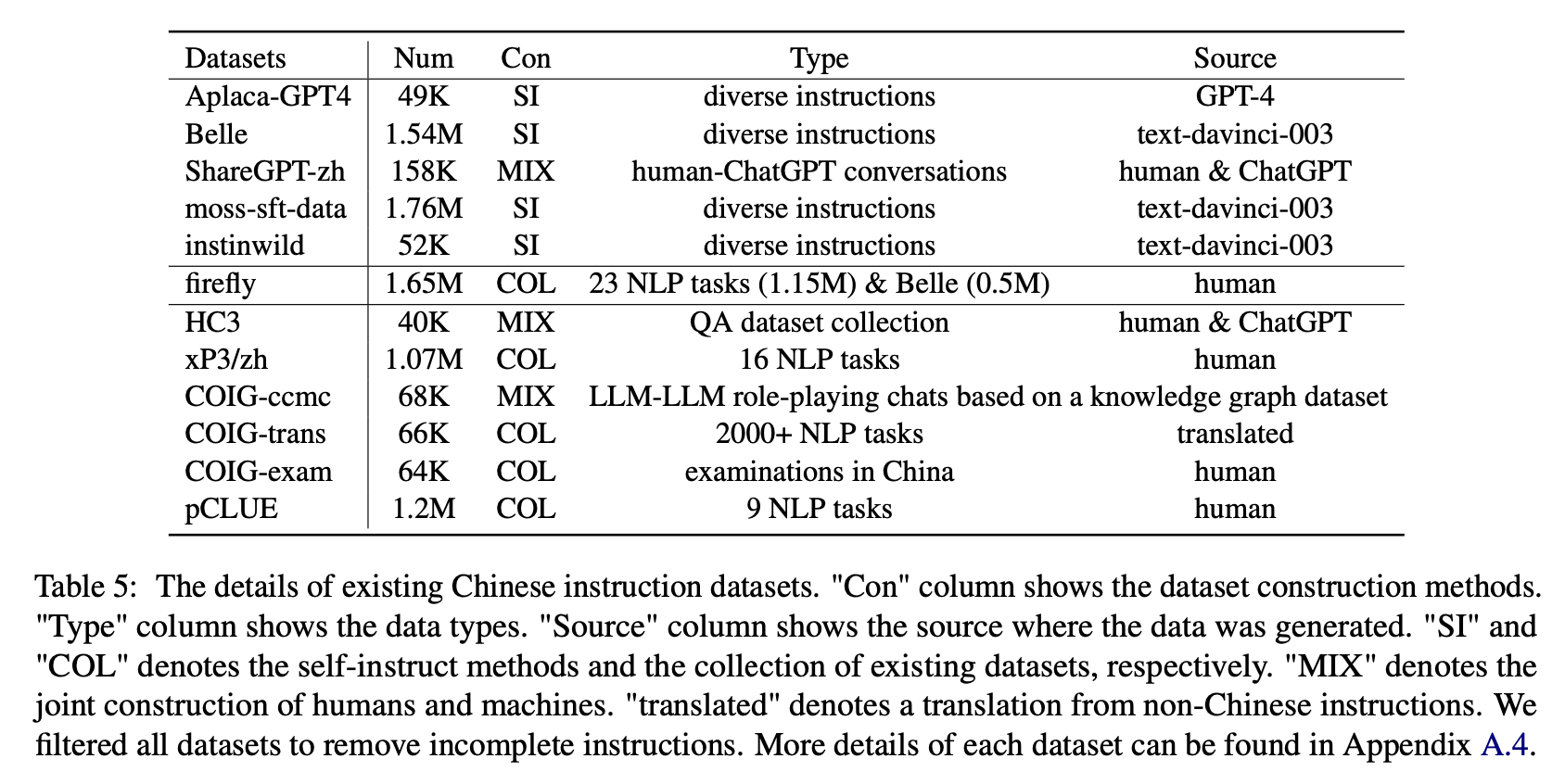
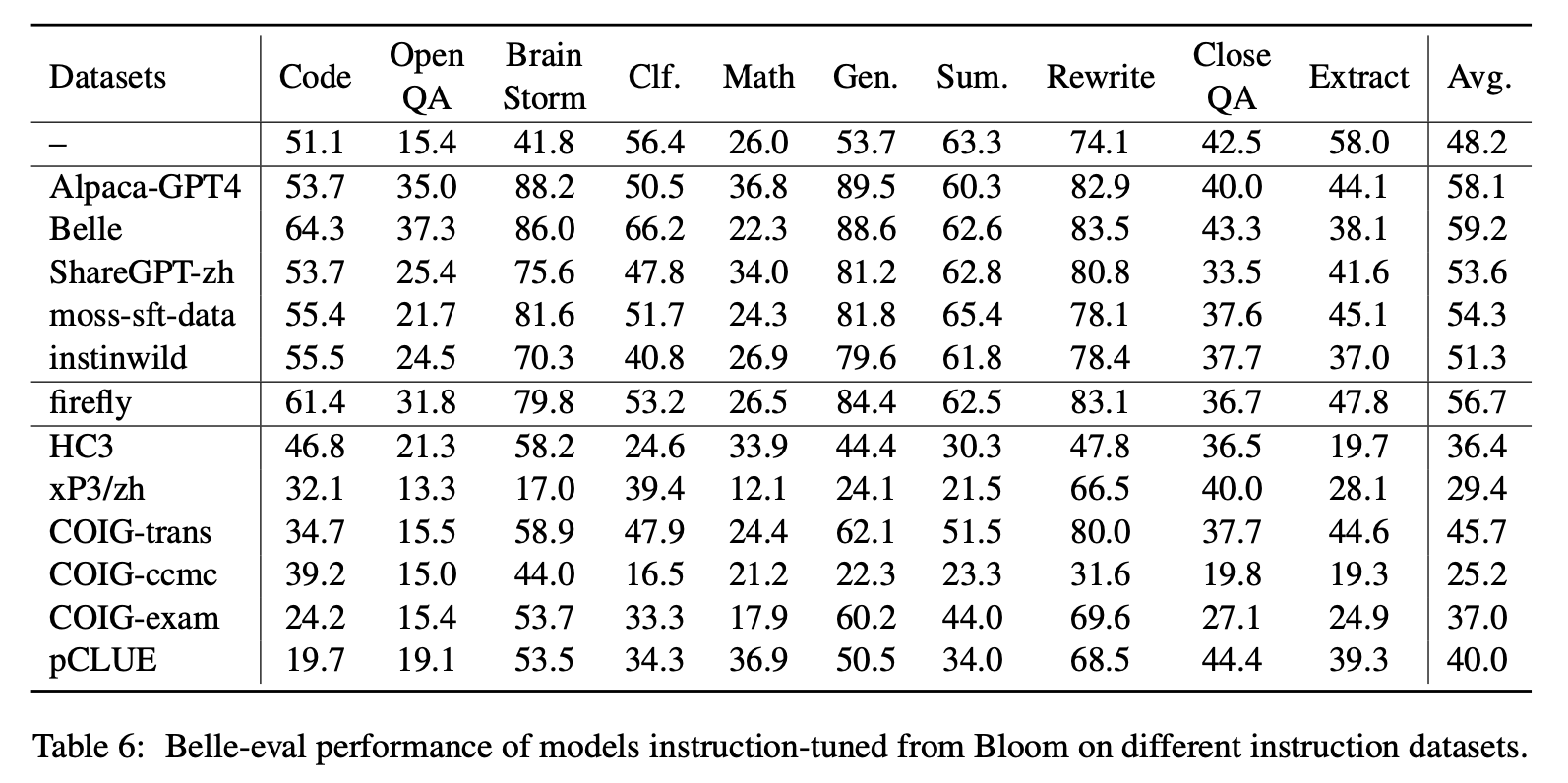
A Tabela 6 e a Tabela 7 mostram o ajuste fino de Bloom em diferentes conjuntos de dados de instruções.
Resultados experimentais:
Desempenho em Belle-Eval
(1) Os dados de instrução construídos pelo ChatGPT (por exemplo, usando métodos de auto-instrução ou coletando conversas reais de chatgpt) aprimoram consistentemente a capacidade de seguir a capacidade de seguir com o aumento de 3,1 ∼ 11 pontos.
(2) Entre esses conjuntos de dados, a Belle tem o melhor desempenho devido à maior quantidade de dados de instruções. No entanto, o desempenho dos modelos treinados em dados de musgo-sft, contendo mais dados incorporados de maneira semelhante, é insatisfatória.
(3) O desempenho trazido pelas instruções do ALPACA-GPT4 é o segundo melhor, com apenas 49k sendo comparável à Belle de 1,54m.
(4) O Instinwild traz os menores ganhos de desempenho entre eles, porque as instruções das sementes que ele rasteja do tweet ("em selvagem") não são tão abrangentes quanto as (como a alpaca) cuidadosamente projetadas por seres humanos.
(5) Esses dados baseados em chatGPT têm um efeito de melhoria significativo em tarefas de geração aberta, como tempestade e geração cerebral, enquanto há uma diminuição significativa nas tarefas que requerem altas habilidades de compreensão de leitura, como controle de qualidade e extrato.
(6) Esses conjuntos de dados de instruções causam danos à capacidade de acompanhamento de instruções do modelo, porque a forma e a intenção de cada conjunto de dados de PNL ou exame são unitários, que podem ser facilmente ajustados.
(7) Entre eles, o Coig-Trans tem o melhor desempenho, porque envolve mais de 2000 tarefas diferentes com uma ampla variedade de instruções de tarefas. Por outro lado, Xp3 e CoIG-CCMC têm o pior impacto negativo no desempenho do modelo. Ambos abrangem apenas alguns tipos de tarefas (tradução e controle de qualidade para o primeiro, conversas contrafactuais de correção para o último), que dificilmente cobrem as instruções e tarefas populares para os seres humanos.
Desempenho no MMCU
(1) O ajuste de instrução em cada conjunto de dados pode resultar em melhoria de desempenho.
(2) Entre os dados baseados em ChatGPT mostrados na parte superior, o ShareGPT-ZH tem um desempenho inferior a outros por grandes margens. Isso pode ser devido ao fato de que usuários reais raramente fazem perguntas de múltipla escolha sobre tópicos acadêmicos.
(3) Entre os dados de coleta de dados mostrados na parte inferior, o HC3 e o CoIG-CCMC resultam na menor precisão, porque as questões únicas do HC3 são apenas 13K, e o formato de tarefa do CoIG-CCMC é significativamente diferente do MMCU.
(4) O COIG-Exam traz a maior melhoria da precisão, beneficiando-se do formato de tarefa semelhante ao MMCU.
Quatro outros fatores: COT, expansão do vocabulário chinês, linguagem de instruções e alinhamento de valor humano
Para o COT, os autores comparam o desempenho antes e depois de adicionar dados do COT durante o ajuste das instruções.
Configurações do experimento:
Coletamos 9 conjuntos de dados do BOT e seus avisos de Flan e depois os traduzimos para o chinês usando o Google Translate. Eles comparam o desempenho antes e depois de adicionar dados do COT durante o ajuste das instruções.
Note primeiro a maneira de adicionar dados do COT como "alpaca-gpt4+berço". Além disso, adicione uma frase "先思考 , 再决定" ("Pense passo a passo" em chinês) no final de cada instrução, para induzir o modelo a responder a instruções com base no COT e rotular dessa maneira como "alpaca-gpt4+berço*".
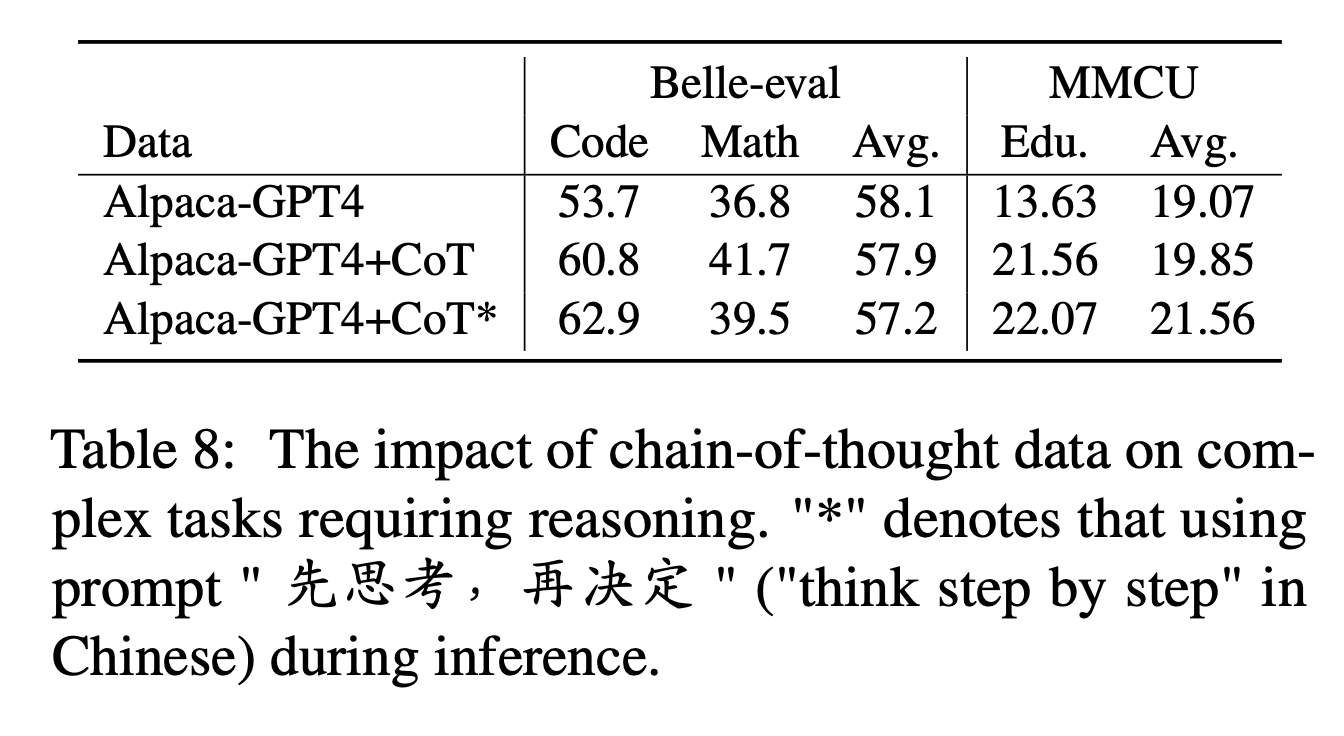
Resultados experimentais:
O "alpaca-gpt4+berço" supera "alpaca-gpt4" nas tarefas de código e matemática que exigem forte capacidade de raciocínio. Além disso, há também uma melhoria significativa na tarefa educacional da MMCU.
Conforme mostrado na linha de "Alpaca-GPT4+COT*", a frase simples pode melhorar ainda mais o desempenho do código e da educação das tarefas de raciocínio, enquanto o desempenho da matemática é ligeiramente inferior a "alpaca-gpt4+berço". Isso pode exigir uma exploração adicional de instruções mais robustas.
Para expansão do vocabulário chinês, os autores testam a influência do número de tokens chineses no vocabulário do tokenizador na capacidade do LLMS de expressar chinês. Por exemplo, se um caractere chinês estiver no vocabulário, poderá ser representado por um único token, caso contrário, poderá exigir vários tokens para representá -lo.
Configurações do experimento: Os autores conduzem principalmente experimentos no LLAMA, que usa a peça de frase (tamanho de 32 mil de vocabulário de caracteres chineses) cobrindo menos caracteres chineses do que Bloom (250K).
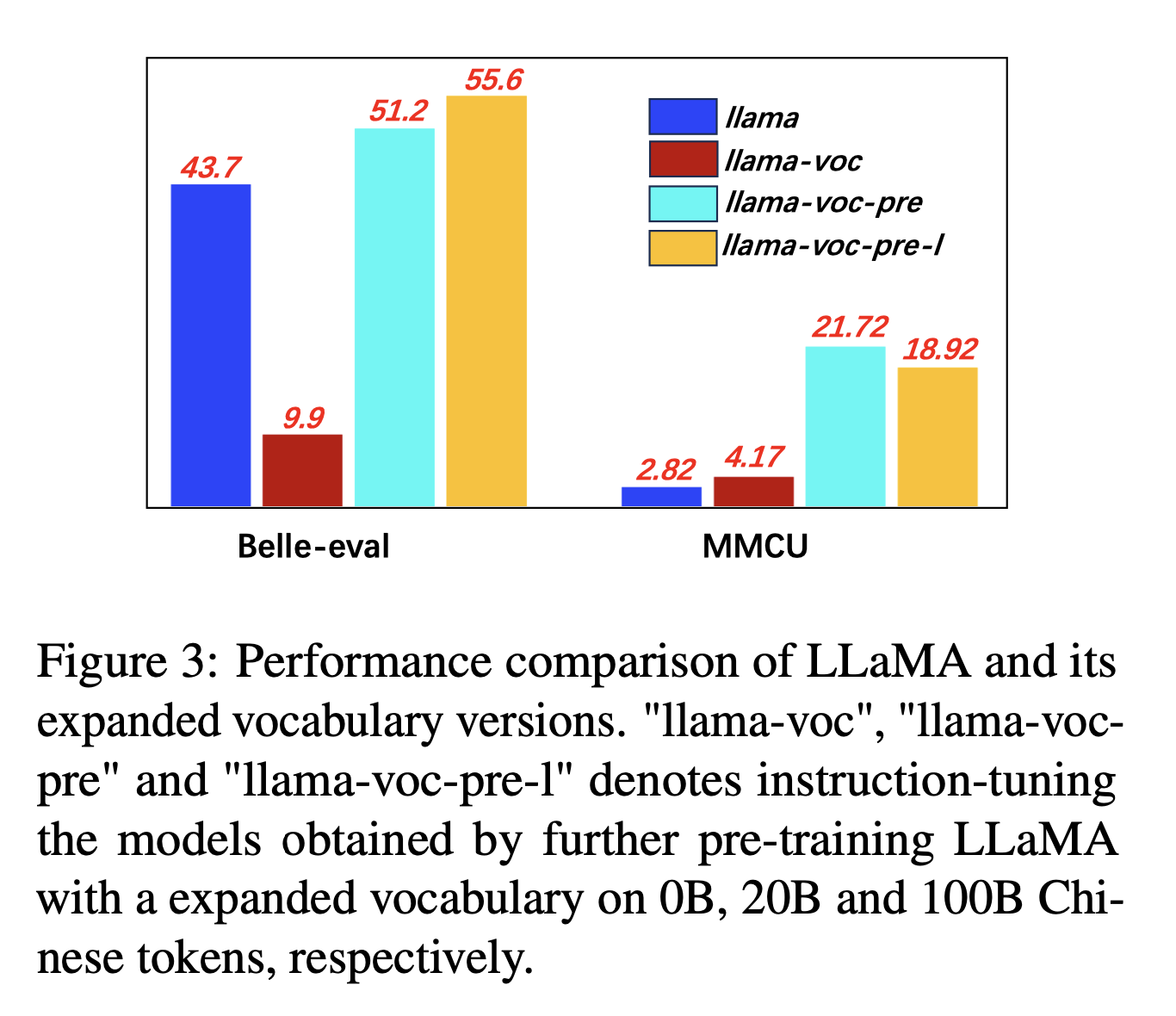
Resultados experimentais:
O pré-treinamento em mais corpus chinês com expansão do vocabulário chinês é constantemente útil para a capacidade de seguir as seguintes.
E contra-intuitivamente, "llama-voc-pre-l" (100b) é inferior a "llama-voc-pre" (20b) no MMCU, o que mostra que o pré-treinamento em mais dados pode não levar necessariamente a um desempenho mais alto para exames acadêmicos.
Para o idioma dos avisos, os autores testam a adequação das instruções para o uso de instruções chinesas.
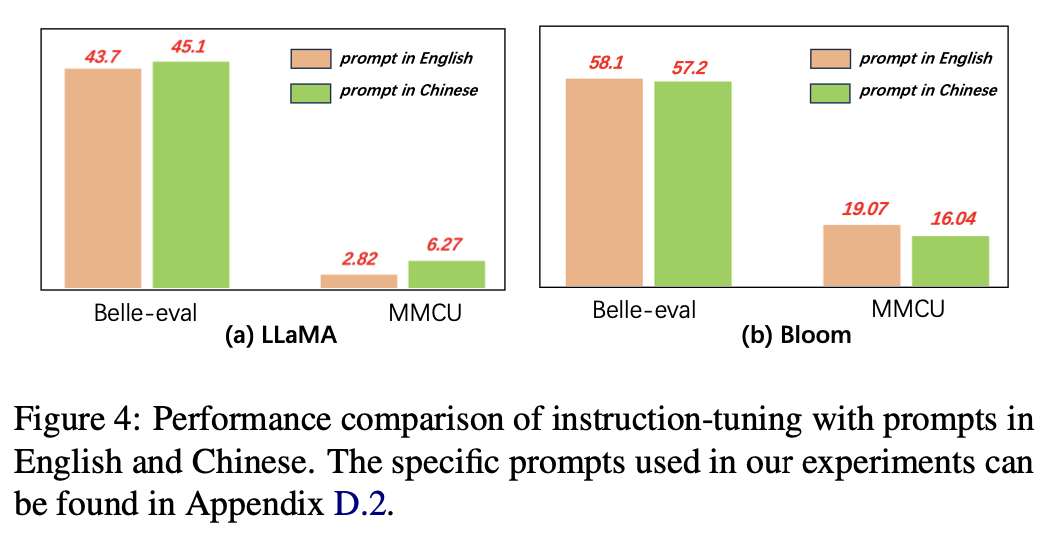
A Figura 4 mostra os resultados do uso de avisos chineses e ingleses com base em lhama e flor. Ao ajustar a lhama de instruções, o uso de instruções chinesas pode melhorar o desempenho nos dois benchmarks em comparação com os avisos em inglês, enquanto o fenômeno oposto pode ser observado em flor.
Resultados experimentais:
Para modelos com habilidades chinesas mais fracas (por exemplo, llama), o uso de instruções chinesas pode efetivamente ajudar a responder em chinês.
Para modelos com boas habilidades chinesas (por exemplo, Bloom), usando os avisos em inglês (o idioma em que são melhores) podem orientar melhor o modelo para entender o processo de ajuste fino com instruções.
Para evitar LLMs gerando conteúdo tóxico, alinhá -los com valores humanos é uma questão crucial. Adicionamos dados de alinhamento de valor humano construídos pela CoIG em ajuste de instrução para explorar seu impacto.
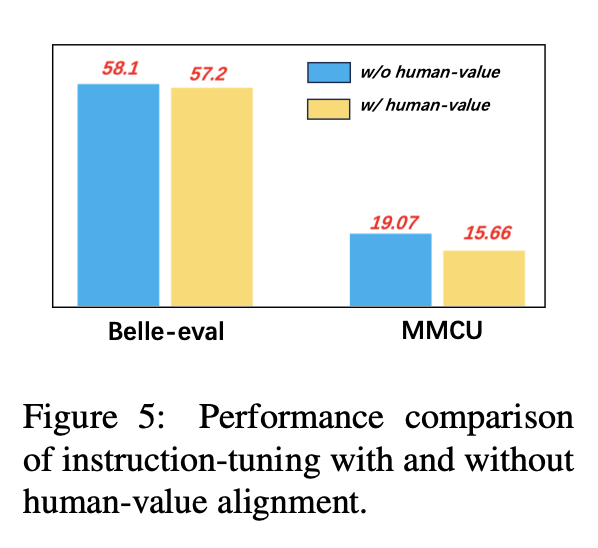
A Figura 5 compara os resultados do ajuste de instrução com e sem alinhamento de valor humano.
Resultados experimentais: O alinhamento do valor humano resulta em uma ligeira queda de desempenho. Como equilibrar a inovação e o desempenho do LLMS é uma direção de pesquisa que vale a pena explorar no futuro.
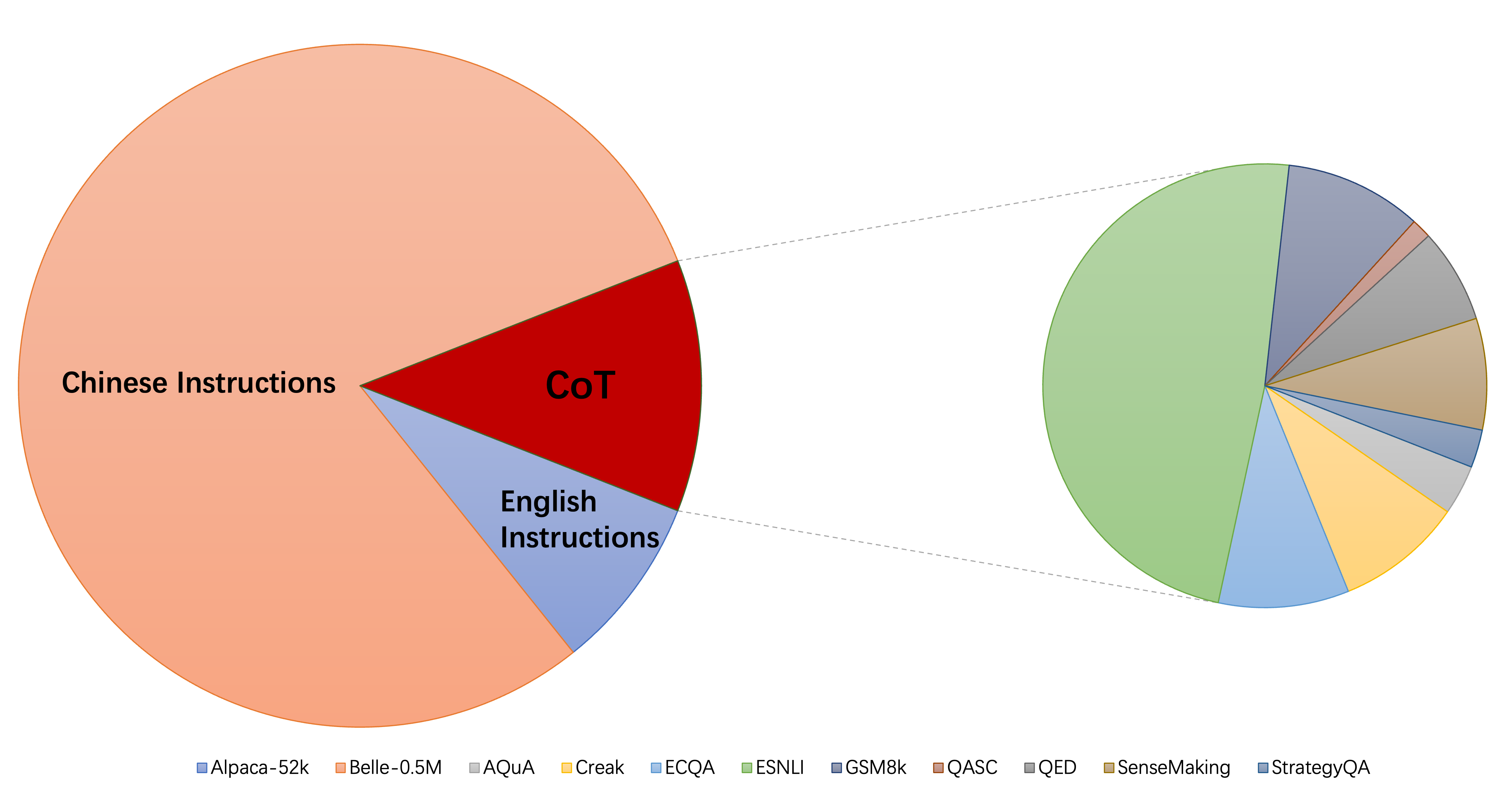 A coleção atual de conjuntos de dados de instrução-fineruning consiste principalmente de três partes:
A coleção atual de conjuntos de dados de instrução-fineruning consiste principalmente de três partes:
alpaca_data_cleaned.json : cerca de 52K de amostras de treinamento em inglês que seguem as instruções.CoT_data.json : 9 conjuntos de dados de COT envolvendo cerca de 75 mil amostras. (Publicado por Flan [7])belle_data_cn.json : cerca de 0,5m chinês | amostras de treinamento seguindo para instruções. (Publicado por Belle [8]) "W/O BOT" e "W/O CN" denotam modelos que excluem dados do COT e instruções chinesas de seus dados de fino de instrução, respectivamente.
"W/O BOT" e "W/O CN" denotam modelos que excluem dados do COT e instruções chinesas de seus dados de fino de instrução, respectivamente.
A tabela acima mostra dois exemplos (envolvendo cálculos numéricos) que requerem uma certa quantidade de capacidade de raciocínio para responder corretamente. Conforme mostrado na coluna do meio, Ours w/o CoT não gera a resposta correta, o que mostra que, uma vez que os dados do Finetuning não contêm dados do COT, a capacidade de raciocínio do modelo diminui significativamente. Isso demonstra ainda que os dados do COT são essenciais para os modelos LLM.

A tabela acima mostra dois exemplos que exigem a capacidade de responder às instruções chinesas. Conforme mostrado na coluna direita, o conteúdo gerado Ours w/o CN não é razoável, ou as instruções chinesas são respondidas em inglês pelo Ours w/o CN . Isso mostra que a remoção de dados chineses durante o Finetuning fará com que o modelo não consiga lidar com instruções chinesas e demonstrar ainda mais a necessidade de coletar dados de Finetuning de instrução chinesa.

A tabela acima mostra um exemplo relativamente difícil, que requer um certo acúmulo de conhecimento da história chinesa e uma capacidade lógica e completa de declarar eventos históricos. Como mostrado nesta tabela, Ours w/o CN só pode gerar uma resposta curta e errônea, porque, devido à falta de dados da Finetuning chinesa, o conhecimento correspondente da história chinesa está naturalmente falta. Embora Ours w/o CoT lista alguns eventos históricos chineses relevantes, sua lógica de expressão é auto-contraditória, causada pela falta de dados do COT. `
Em resumo, os modelos FinetUned do nosso conjunto de dados completo (dados de instruções em inglês, chinês e cot) podem melhorar significativamente o raciocínio do modelo e a instrução chinesa seguindo as habilidades.
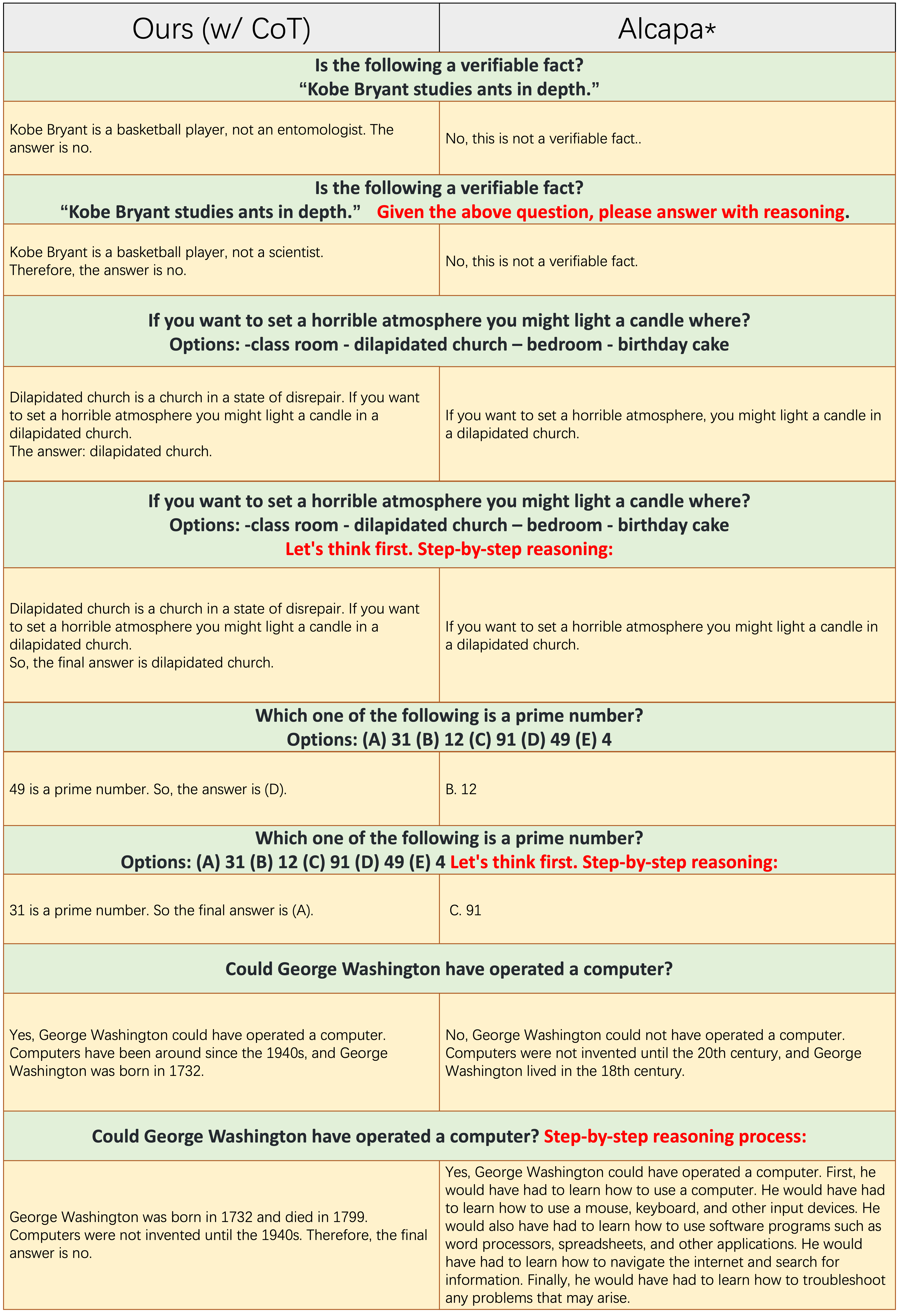 Amostras de cada número ímpar de linhas não aplicam o prompt do COT, como "raciocínio passo a passo". Tanto
Amostras de cada número ímpar de linhas não aplicam o prompt do COT, como "raciocínio passo a passo". Tanto Ours(w/CoT) quanto o ALPACA são baseados no LLAMA-7B, e a única diferença entre eles dois é que os dados do Ours(w/CoT) têm dados de COT extra do que o da ALPACA.
Da tabela acima, descobrimos que:
Ours(w/CoT) sempre gera a lógica correta antes da resposta, enquanto a Alpaca não gera qualquer justificativa razoável, como mostrado nos 4 primeiros exemplos (perguntas do senso comum). Isso mostra que o uso de dados COT para o Finetuning pode melhorar significativamente a capacidade de raciocínio.Ours(w/CoT) , o prompt do COT (por exemplo, concatenar 'passo a passo' com a pergunta de entrada) tem pouco efeito em exemplos fáceis (por exemplo, perguntas do senso comum) e tem um efeito importante em questões desafiadoras (por exemplo, perguntas que requerem raciocínio, como os últimos quatro exemplos). Comparação quantitativa das respostas às instruções chinesas. 
Nosso modelo é fino de uma llama 7B com instruções em inglês de 52k e instruções chinesas de 0,5m. Stanford Alpaca (nossa reimplementação) é finetuned a partir de uma lhama 7B com 52k instruções em inglês. Belle é finetuned a partir de uma flor de 7b em instruções chinesas 2B.
Da tabela acima, várias observações podem ser encontradas:
ours (w/ CN) tem uma capacidade mais forte de entender as instruções chinesas. Para o primeiro exemplo, a Alpaca falha em distinguir entre a parte instruction e a parte input , enquanto o fazemos.ours (w/ CN) não apenas fornece o código correto, mas também fornece a anotação chinesa correspondente, enquanto a Alpaca não. Além disso, como mostrado nos exemplos 3-5, a Alpaca só pode responder às instruções chinesas com uma resposta em inglês.ours (w/ CN) em instruções que exigem uma resposta aberta (como mostrado nos últimos dois exemplos) ainda precisam ser aprimoradas. O excelente desempenho de Belle contra essas instruções se deve a: 1. Seu modelo de backbone da Bloom encontra muito mais dados multilíngues durante o pré-treinamento; 2. Os dados do Finetuning de instrução chinesa são mais do que os nossos, ou seja, 2M vs 0,5m. Comparação quantitativa das respostas às instruções em inglês. O objetivo desta subseção é explorar se o Finetuning nas instruções chinesas tem um impacto negativo na alpaca. 
Da tabela acima, descobrimos que:
ours (w/ CN) mostra mais detalhes do que a da alpaca, por exemplo, para o terceiro exemplo, ours (w/ CN) listam mais três províncias que o Alpaca. Cite o repositório se você usar a coleta de dados, código e descobertas experimentais neste repositório.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Para dados e modelos, cite os dados originais, os métodos eficientes em parâmetro e a fonte LLMS também.
Gostaríamos de expressar nossa gratidão especial ao Apus Ailme Lab por patrocinar as 8 GPUs A100 para os experimentos.
(de volta ao topo)


