Alpaca CoT
1.0.0
中文| Bahasa inggris

Ini adalah repositori untuk proyek Alpaca-CoT , yang bertujuan untuk membangun platform instruksi finetuning (IFT) dengan koleksi instruksi yang luas (terutama dataset COT) dan antarmuka terpadu untuk berbagai model bahasa besar dan metode efisien parameter. Kami terus-menerus memperluas pengumpulan data penyetelan instruksi kami, dan mengintegrasikan lebih banyak LLM dan metode yang lebih efisien parameter. Selain itu, kami membuat cabang baru tabular_llm untuk membangun LLM tabular untuk menyelesaikan tugas intelijen tabel.
Anda dipersilakan untuk memberi kami set data pengumpulan instruksi yang tidak dikumpulkan (atau sumbernya). Kami akan memformatnya secara seragam, melatih model alpaca (dan LLM lainnya di awal masa depan) dengan kumpulan data ini, open source pos pemeriksaan model, dan melakukan studi empiris yang luas. Kami berharap bahwa proyek kami dapat memberikan kontribusi sederhana untuk proses open-source dari model bahasa besar, dan mengurangi ambang batas bagi para peneliti NLP untuk memulai.

Jika Anda ingin menggunakan metode lain selain Lora, silakan instal versi yang diedit di Project pip install -e ./peft .
12.8: LLM InternLM digabungkan.
8.16: 4bit quantization tersedia untuk lora , qlora dan adalora .
8.16: Metode Efisien Parameter Qlora , Sequential adapter dan Parallel adapter digabungkan.
7.24: LLM ChatGLM v2 digabungkan.
7.20: llm Baichuan digabungkan.
6.25: Tambahkan kode evaluasi model, termasuk Belle dan MMCU.
GPT4Tools , Auto CoT , pCLUE ditambahkan.tabular_llm dibuat untuk membangun LLM tabel. Kami mengumpulkan data penyempurnaan instruksi untuk tugas-tugas terkait tabel seperti pertanyaan tabel menjawab dan menggunakannya untuk menyempurnakan LLMS dalam repo ini.MOSS digabungkan.GAOKAO , camel , FLAN-Muffin , COIG dikumpulkan dan diformat.webGPT , dolly , baize , hh-rlhf , OIG(part) dikumpulkan dan diformat.multi-turn conversation oleh @Paulcx.firefly , instruct , Code Alpaca dikumpulkan dan diformat, yang dapat ditemukan di sini.Parameter merging , Local chatting , Batch predicting dan Web service building oleh @Weberr.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 dan natural-instructions dikumpulkan dan diformat.CoT_CN_data.json dapat ditemukan di sini. 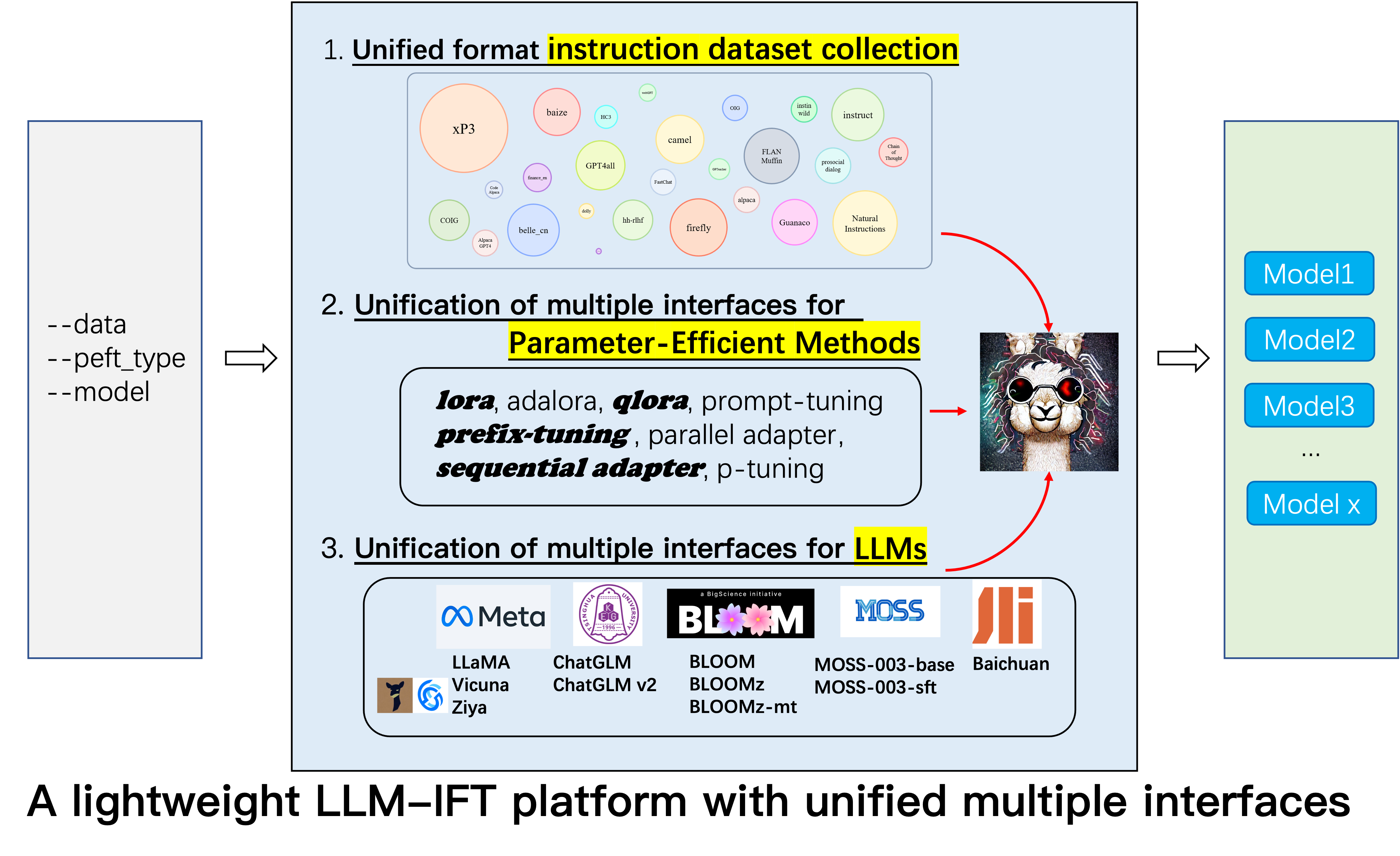
Llama [1] adalah karya hebat yang menunjukkan kemampuan zero-shot dan beberapa-shot yang menakjubkan. Ini secara signifikan mengurangi biaya pelatihan, finetuning, dan menggunakan model bahasa besar yang kompetitif, yaitu, LLAMA-13B mengungguli GPT-3 (175B) dan LLAMA-65B bersaing dengan PALM-540B. Baru-baru ini, untuk meningkatkan kemampuan mengikuti instruksi dari Llama, Stanford Alpaca [2] Finetuned Llama-7b pada data pengikut instruksi 52K yang dihasilkan oleh teknik instruktur diri [3]. Namun, saat ini, komunitas riset LLM masih menghadapi tiga tantangan: 1. Bahkan LLAMA-7B masih memiliki persyaratan tinggi untuk sumber daya komputasi; 2. Ada beberapa set data sumber terbuka untuk instruksi finetuning; dan 3. Ada kurangnya studi empiris tentang dampak berbagai jenis pengajaran pada kemampuan model, seperti kemampuan untuk menanggapi instruksi Cina dan penalaran COT.
Untuk tujuan ini, kami mengusulkan proyek ini, yang memanfaatkan berbagai perbaikan yang kemudian diusulkan, dengan keunggulan berikut:
7b , 13b dan 30b model LLAMA dapat dengan mudah dilatih pada 80G A100 tunggal. Sepengetahuan kami, pekerjaan ini adalah yang pertama mempelajari penalaran COT berdasarkan Llama dan Alpaca. Karena itu, kami menyingkat pekerjaan kami ke Alpaca-CoT .
Ukuran relatif dari dataset yang dikumpulkan dapat ditunjukkan oleh grafik ini:
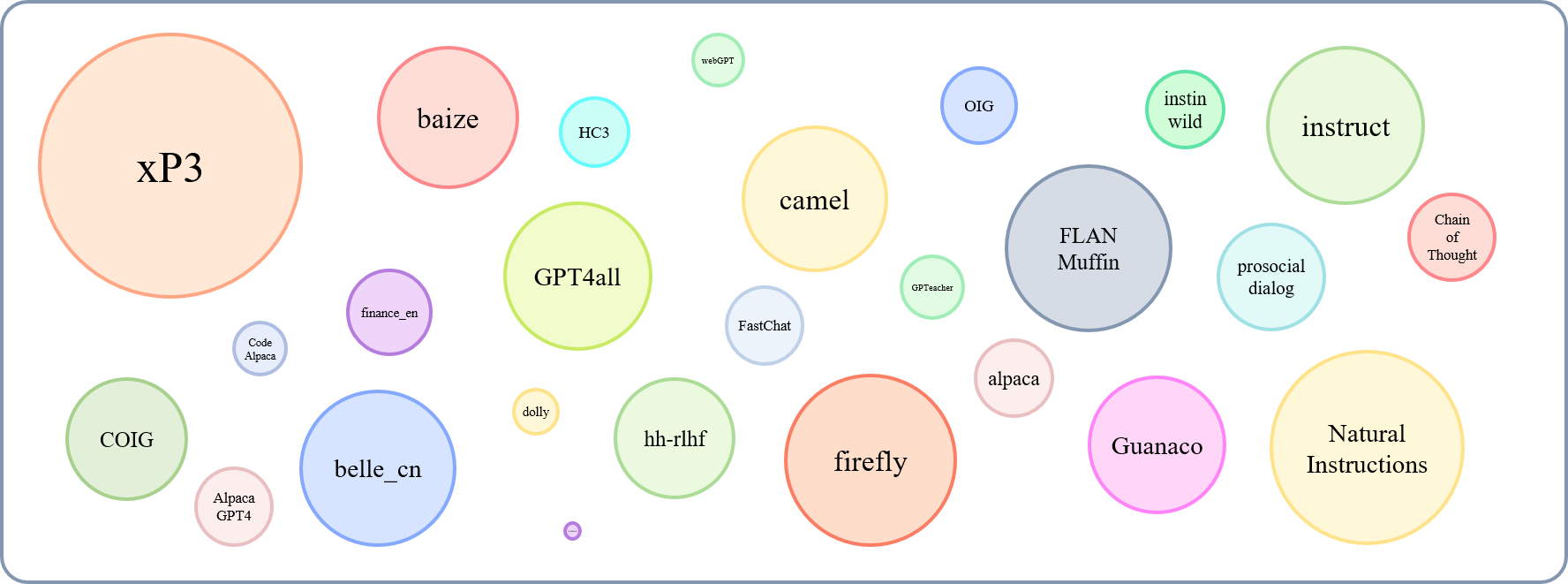
Mengacu pada ini (@yaodongc), kami memberi label setiap dataset yang dikumpulkan sesuai dengan aturan berikut:
(Lang) Lingual-Tags:
(Tugas) Tugas-Tag:
(Gen) Metode generasi:
| Dataset | Nums | Lang | Tugas | Gen | Jenis | SRC | Url |
|---|---|---|---|---|---|---|---|
| Rantai pemikiran | 74771 | En/cn | Mt | HG | Instruksikan dengan alasan ranjang | COT anotasi pada data yang ada | unduh |
| Gpt4all | 806199 | En | Mt | Col | kode, cerita, dan dialog | Distilasi dari GPT-3.5-Turbo | unduh |
| GPTEACHER | 29013 | En | Mt | Si | Umum, Roleplay, alat pahat | GPT-4 & ToolFormer | unduh |
| Guanaco | 534610 | Ml | Mt | Si | berbagai tugas linguistik | Text-Davi-003 | unduh |
| HC3 | 37175 | En/cn | Ts | MENCAMPUR | Evaluasi Dialog | manusia atau chatgpt | unduh |
| Alpaca | 52002 | En | Mt | Si | Instruksi Umum | Text-Davi-003 | unduh |
| Instruksi alami | 5040134 | Ml | Mt | Col | beragam tugas NLP | Koleksi Dataset Beranotasi Manusia | unduh |
| belle_cn | 1079517 | Cn | TS/MT | Si | Jenderal, Penalaran Matematika, Dialog | Text-Davi-003 | unduh |
| Instinwild | 52191 | En/cn | Mt | Si | Generasi, Open-QA, Mind-Storm | Text-Davi-003 | unduh |
| Dialog Prososial | 165681 | En | Ts | MENCAMPUR | dialog | GPT-3 Menulis ulang pertanyaan + umpan balik manusia secara manual | unduh |
| FINANCE_EN | 68912 | En | Ts | Col | QA terkait keuangan | Gpt3.5 | unduh |
| xp3 | 78883588 | Ml | Mt | Col | Kumpulan Prompt & Dataset di 46 Bahasa & 16 Tugas NLP | Koleksi Dataset Beranotasi Manusia | unduh |
| Firefly | 1649398 | Cn | Mt | Col | 23 tugas NLP | Koleksi Dataset Beranotasi Manusia | unduh |
| menginstruksikan | 888969 | En | Mt | Col | ditambah gpt4all, alpaca, dataset meta open-source | Augmentasi dilakukan dengan menggunakan alat NLP canggih yang disediakan oleh Allenai | unduh |
| Kode Alpaca | 20022 | En | Ts | Si | pembuatan kode, pengeditan, optimasi | Text-Davi-003 | unduh |
| Alpaca_gpt4 | 52002 | En/cn | Mt | Si | Instruksi Umum | dihasilkan oleh GPT-4 menggunakan alpaca | unduh |
| Webgpt | 18994 | En | Ts | MENCAMPUR | Pengambilan Informasi (IR) QA | GPT-3 yang disempurnakan, masing-masing instruksi memiliki dua output, pilih yang lebih baik | unduh |
| Dolly 2.0 | 15015 | En | Ts | HG | QA tertutup, peringkasan dan dll, wikipedia sebagai referensi | manusia beranotasi | unduh |
| kain tebal dr wol kasar | 653699 | En | Mt | Col | Koleksi dari pertanyaan Alpaca, Quora, Stackoverflow dan Medquad | Koleksi Dataset Beranotasi Manusia | unduh |
| HH-RLHF | 284517 | En | Ts | MENCAMPUR | dialog | Dialog antara model manusia dan RLHF | unduh |
| Oig (bagian) | 49237 | En | Mt | Col | dibuat dari berbagai tugas, seperti pertanyaan dan jawaban | Menggunakan augmentasi data, koleksi dataset beranotasi manusia | unduh |
| Gaokao | 2785 | Cn | Mt | Col | Pertanyaan pilihan ganda, isi-dalam-blok dan terbuka dari pemeriksaan | manusia beranotasi | unduh |
| unta | 760620 | En | Mt | Si | Percakapan Permainan Peran dalam Masyarakat AI, Kode, Matematika, Fisika, Kimia, Biolog | GPT-3.5-turbo | unduh |
| Flan-muffin | 1764800 | En | Mt | Col | 60 Tugas NLP | Koleksi Dataset Beranotasi Manusia | unduh |
| Coig (Flaginstruct) | 298428 | Cn | Mt | Col | Kumpulkan Ujian Fron, Diterjemahkan, Instruksi Penyelarasan Nilai Manusia dan Koreksi Koreksi Multi-Bulu Obrolan | Menggunakan alat otomatis dan verifikasi manual | unduh |
| GPT4TOOLS | 71446 | En | Mt | Si | kumpulan instruksi terkait alat | GPT-3.5-turbo | unduh |
| Sharechat | 1663241 | En | Mt | MENCAMPUR | Instruksi Umum | crowdsourcing untuk mengumpulkan percakapan antara orang dan chatgpt (sharegpt) | unduh |
| Rekanan otomatis | 5816 | En | Mt | Col | Aritmatika, Advonsense, Simbolik, dan Tugas Penalaran Logis Lainnya | Koleksi Dataset Beranotasi Manusia | unduh |
| LUMUT | 1583595 | En/cn | Ts | Si | Instruksi Umum | Text-Davi-003 | unduh |
| Ultrachat | 28247446 | En | Pertanyaan tentang dunia, menulis dan penciptaan, bantuan materi yang ada | Dua GPT-3.5-turbo terpisah | unduh | ||
| Medis Cina | 792099 | Cn | Ts | Col | Pertanyaan tentang Saran Medis | merangkak | unduh |
| CSL | 396206 | Cn | Mt | Col | Pembuatan Teks Kertas, Ekstraksi Kata Kunci, Ringkasan Teks dan Klasifikasi Teks | merangkak | unduh |
| pclue | 1200705 | Cn | Mt | Col | Instruksi Umum | unduh | |
| news_commentary | 252776 | Cn | Ts | Col | menerjemahkan | unduh | |
| Stackllama | todo | En |
Anda dapat mengunduh semua data yang diformat di sini. Maka Anda harus memasukkannya ke dalam folder data.
Anda dapat mengunduh semua pos pemeriksaan yang dilatih tentang berbagai jenis data instruksi dari sini. Kemudian, setelah mengatur LoRA_WEIGHTS (di generate.py ) ke jalur lokal, Anda dapat secara langsung menjalankan inferensi model.
Semua data dalam koleksi kami diformat ke dalam templat yang sama, di mana setiap sampel adalah sebagai berikut:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Perhatikan bahwa, untuk kumpulan data COT, pertama-tama kami menggunakan templat yang disediakan oleh FLAN untuk mengubah dataset asli menjadi berbagai bentuk rantai-pemikiran, dan kemudian mengubahnya ke format di atas. Script pemformatan dapat ditemukan di sini.
pip install -r requirements.txt
Perhatikan itu, pastikan Python> = 3.9 saat finetuning chatglm.
Peft
pip install -e ./peft
Agar para peneliti dapat melakukan penelitian IFT sistematis pada LLM, kami telah mengumpulkan berbagai jenis data instruksi, beberapa LLM terintegrasi, dan antarmuka terpadu, membuatnya mudah untuk menyesuaikan kolokasi yang diinginkan:
--model_type : Atur LLM yang ingin Anda gunakan. Saat ini, [llama, chatglm, bloom, moss] didukung. Dua yang terakhir memiliki kemampuan Cina yang kuat, dan lebih banyak LLM akan diintegrasikan di masa depan.--peft_type : Atur PEFT yang ingin Anda gunakan. Saat ini, [Lora, Adalora, tuning awalan, t tuning, prompt] didukung.--data : Atur tipe data yang digunakan untuk IFT untuk secara fleksibel menyesuaikan kemampuan kepatuhan perintah yang diinginkan. Misalnya, untuk kemampuan penalaran yang kuat, menetapkan "alpaca-cot", untuk kemampuan Cina yang kuat, menetapkan "belle1.5m", untuk kemampuan pengkodean dan pembuatan cerita, menetapkan "gpt4all", dan untuk kemampuan respons terkait keuangan, menetapkan "keuangan".--model_name_or_path : Ini diatur untuk memuat berbagai versi bobot model untuk target llm --model_type . Misalnya, untuk memuat bobot versi 13B LLAMA, Anda dapat mengatur Decapoda-Research/LLAMA-13B-HF.GPU tunggal
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
Catatan: Untuk beberapa set data, Anda dapat menggunakan --data seperti --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Perhatikan bahwa load_in_8bit belum cocok untuk chatglm, jadi batch_size harus lebih kecil dari yang lain.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Perhatikan bahwa Anda juga dapat melewati jalur lokal (di mana bobot llm disimpan) ke --model_name_or_path . Dan tipe data --data dapat ditetapkan secara bebas sesuai dengan minat Anda.
Gpus berganda
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Perhatikan bahwa load_in_8bit belum cocok untuk chatglm, jadi batch_size harus lebih kecil dari yang lain.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Rincian lebih lanjut tentang instruksi finetuing dan inferensi dapat ditemukan di sini tempat kami memodifikasi. Perhatikan bahwa folder saved-xxx7b adalah jalur penyimpanan untuk beban lora, dan bobot llama diunduh secara otomatis dari wajah pelukan.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Makalah ini memilih dua tolok ukur evaluasi, Belle-Eval dan MMCU, untuk secara komprehensif mengevaluasi kompetensi LLM dalam bahasa Cina.
Belle-eval dibangun oleh mandiri dengan chatgpt, yang memiliki 1.000 instruksi beragam yang melibatkan 10 kategori yang mencakup tugas NLP umum (misalnya, QA) dan tugas yang menantang (misalnya, kode dan matematika). Kami menggunakan chatgpt untuk menilai respons model berdasarkan jawaban emas. Benchmark ini dianggap sebagai penilaian kemampuan AGI (mengikuti instruksi).
MMCU adalah kumpulan pertanyaan pilihan ganda Cina dalam empat disiplin kedokteran profesional, hukum, psikologi dan pendidikan (misalnya, pemeriksaan Gaokao). Ini memungkinkan LLM untuk mengikuti ujian dalam masyarakat manusia dengan cara uji pilihan ganda, membuatnya cocok untuk mengevaluasi luas dan kedalaman pengetahuan tentang LLM di berbagai disiplin ilmu.
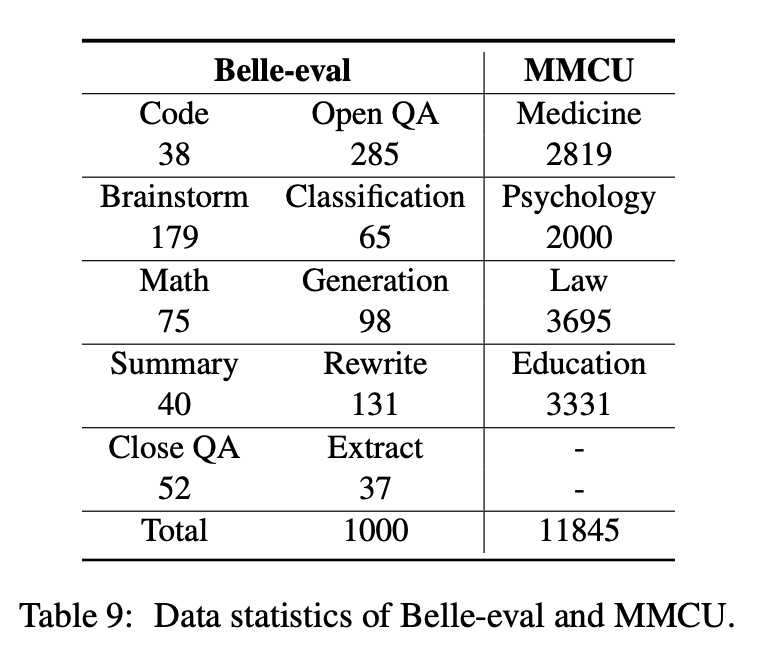
Statistik data Belle-Eval dan MMCU ditunjukkan pada tabel di atas.
Kami melakukan eksperimen untuk mempelajari tiga faktor utama dalam pengajaran LLMS: Basis LLM, metode efisien parameter, set data instruksi Cina.
Untuk LLM terbuka, kami menguji LLMS dan LLMS yang ada disesuaikan dengan LORA di Alpaca-GPT4 pada Belle-Eval dan MMCU, masing-masing.
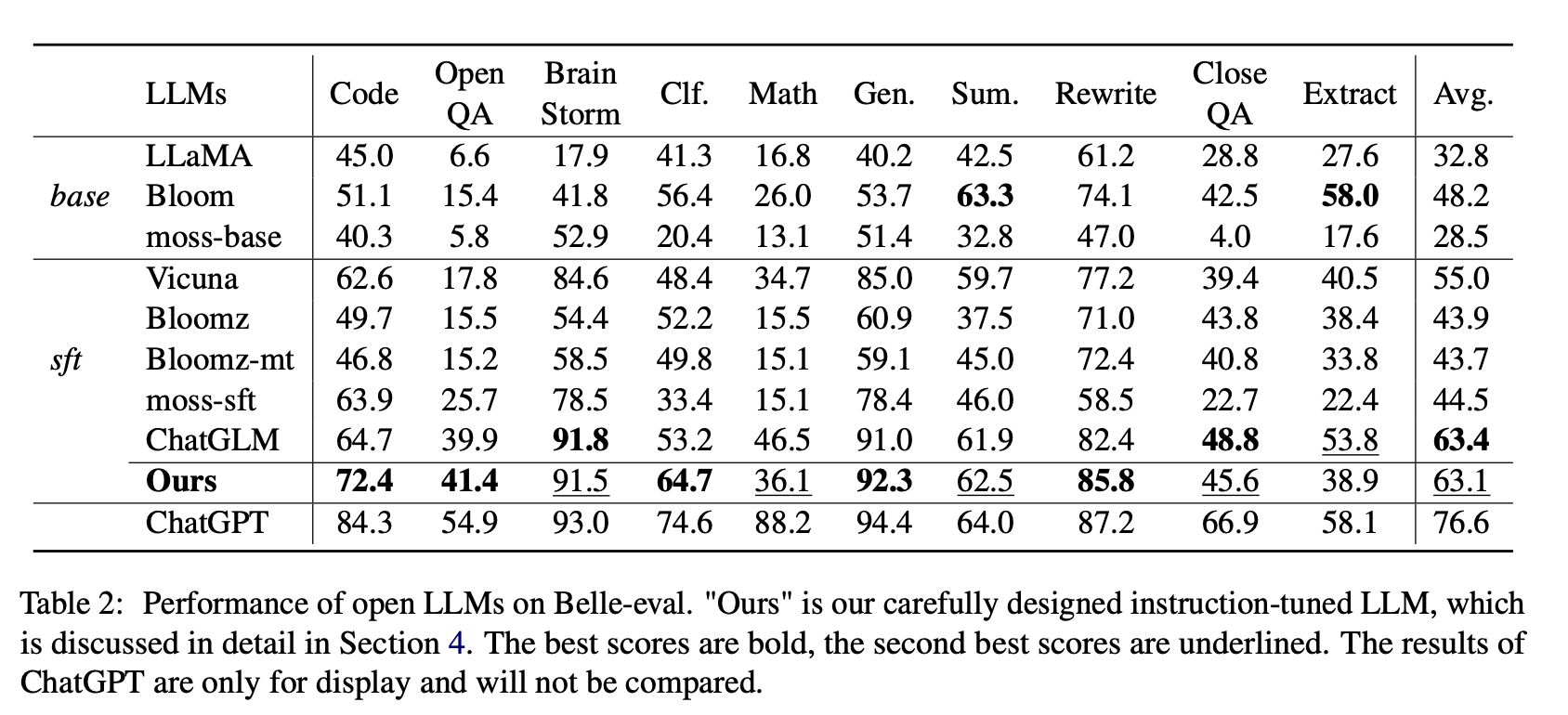
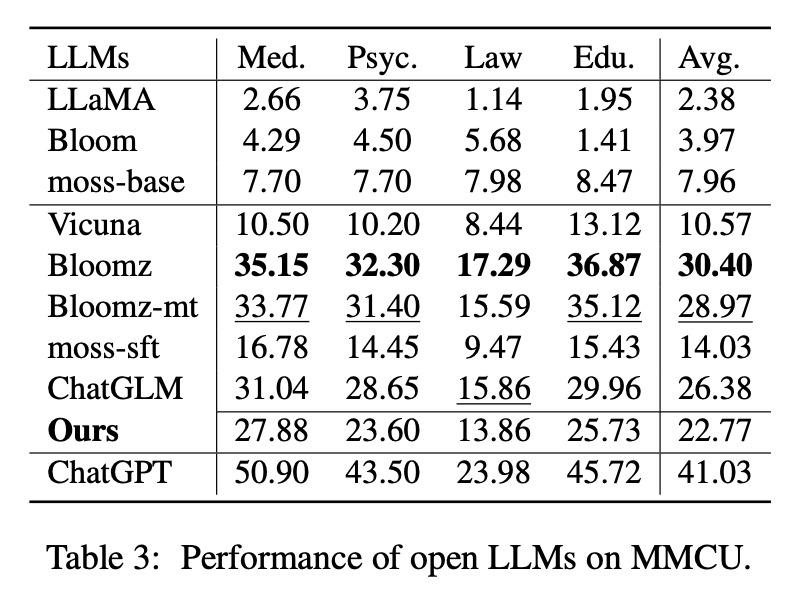
Tabel 2 menunjukkan skor Open LLMS pada Belle-Eval. Tabel 3 menunjukkan keakuratan LLMS pada MMCU. Mereka menyempurnakan semua LLM terbuka dengan metode parameter-efisien yang sama LORA dan dataset instruksi yang sama Alpaca-GPT4.
Hasil Eksperimen:
Evaluasi LLM yang ada
Kinerja di Belle-Eval
(1) Untuk LLMS dasar, Bloom melakukan yang terbaik.
(2) Untuk SFT LLMS, ChatGLM mengungguli orang lain dengan margin besar, berkat fakta bahwa itu dilatih dengan token dan HFRL paling banyak Cina.
(3) Kategori QA, Matematika, CloseQA, dan ekstrak terbuka masih sangat menantang untuk LLM terbuka yang ada.
(4) Vicuna dan Moss-SFT memiliki perbaikan yang jelas dibandingkan dengan basis, Llama dan basis lumut mereka.
(5) Sebaliknya, kinerja model SFT, Bloomz dan Bloomz-MT, berkurang dibandingkan dengan model dasar mekar, karena mereka cenderung menghasilkan respons yang lebih pendek.
Kinerja di MMCU
(1) Semua LLM dasar berkinerja buruk karena hampir sulit untuk menghasilkan konten dalam format yang ditentukan sebelum menyempurnakan, misalnya, mengeluarkan nomor opsi.
(2) Semua LLMS SFT mengungguli LLMS basis yang sesuai. Secara khusus, Bloomz melakukan yang terbaik (bahkan mengalahkan chatglm) karena dapat menghasilkan nomor opsi secara langsung seperti yang diperlukan tanpa menghasilkan konten yang tidak relevan lainnya, yang juga disebabkan oleh karakteristik data dari dataset fine-tuning XP3 yang diawasi.
(3) Di antara empat disiplin ilmu, hukum adalah yang paling menantang bagi LLM.
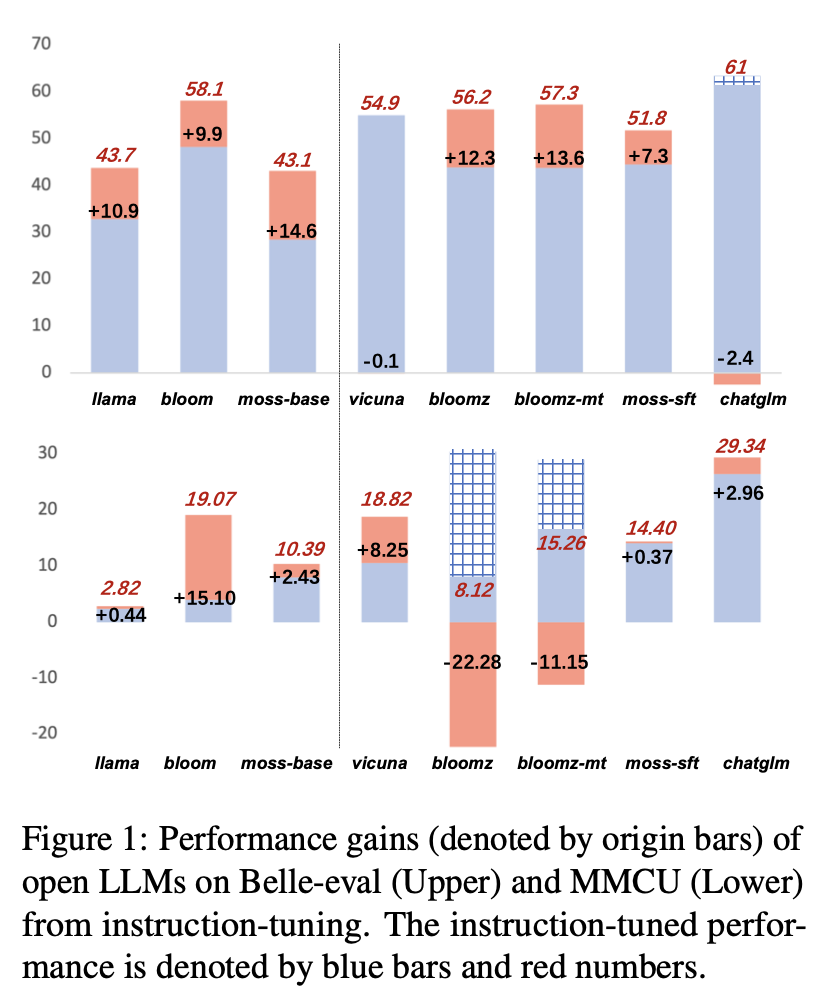
Hasil kinerja LLMS setelah penyetelan instruksi pada alpaca-GPT4-ZH ditunjukkan pada Gambar 1.
Instruksi-Menyetel LLMS yang berbeda
(1) Pada Belle-Eval, peningkatan kinerja SFT LLMS yang dibawa oleh pengajaran pengajaran tidak sama pentingnya dengan LLMS basis, kecuali untuk SFT Bloomz dan Bloomz-MT.
(2) Vicuna dan Chatglm menghadapi kinerja turun setelah penyetelan instruksi, karena Vicuna dilatih dari percakapan orang-orang-orang yang nyata, dengan kualitas yang lebih baik daripada Alpaca-GPT4. ChatGLM mengadopsi HFRL, yang mungkin tidak lagi cocok untuk penyetelan instruksi lebih lanjut.
(3) Pada MMCU, sebagian besar LLM mencapai peningkatan kinerja setelah penyetelan instruksi, dengan pengecualian Bloomz dan Bloomz-MT, yang secara tak terduga telah secara signifikan mengurangi kinerja.
(4) Setelah penyetelan instruksi, Bloom memiliki peningkatan yang signifikan dan berkinerja baik pada kedua tolok ukur. Meskipun chatglm mengalahkan mekar secara konsisten, ia menderita penurunan kinerja selama pengajaran. Oleh karena itu, di antara semua LLM terbuka, Bloom paling cocok sebagai model fondasi dalam percobaan selanjutnya untuk eksplorasi pengajaran pengajaran Cina.
Untuk metode yang efisien parameter selain LORA, kertas mengumpulkan berbagai metode efisien parameter untuk pengajaran-tune mekar pada dataset ALPACA-GPT4.
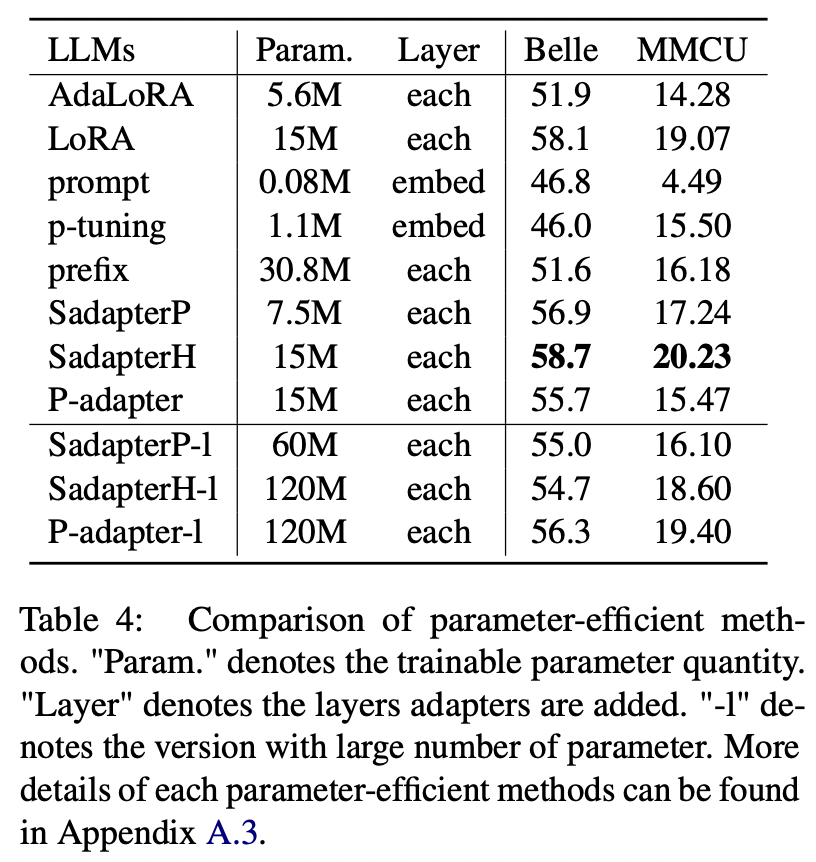
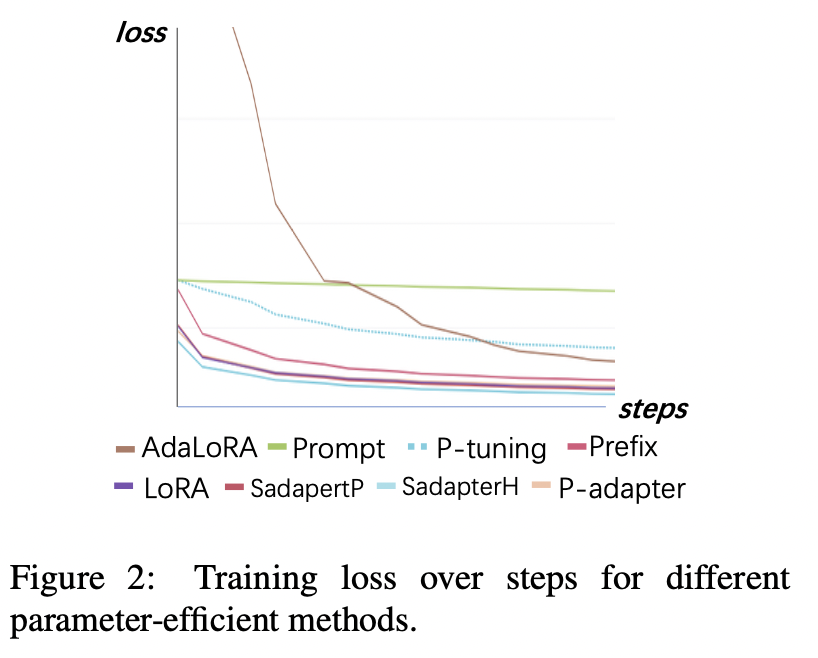
Hasil Eksperimen:
Perbandingan metode parameter-efisien
(1) Sadapterh melakukan yang terbaik di antara semua metode efisien parameter, yang dapat digunakan sebagai alternatif untuk LORA.
(2) P-tuning dan tuning yang cepat berkinerja buruk dengan margin besar, menunjukkan bahwa hanya menambahkan lapisan yang dapat dilatih di lapisan embedding tidak cukup untuk mendukung LLM untuk tugas pembuatan.
(3) Meskipun Adalora merupakan peningkatan LORA, kinerjanya memiliki penurunan yang jelas, mungkin karena parameter Lora yang dapat dilatih untuk LLM tidak cocok untuk pengurangan lebih lanjut.
(4) Membandingkan bagian atas dan bawah, dapat dilihat bahwa meningkatkan jumlah parameter yang dapat dilatih untuk adaptor berurutan (yaitu, Sadapterp dan Sadapterh) tidak membawa gain, sedangkan fenomena yang berlawanan diamati untuk adaptor paralel (yaitu, adapter-p)
Kehilangan pelatihan
(1) Tuning dan p-tuning yang cepat menyatu paling lambat dan memiliki kerugian tertinggi setelah konvergensi. Ini menunjukkan bahwa adapter hanya embedding tidak cocok untuk pengajaran-tuning LLMS.
(2) Kehilangan awal Adalora sangat tinggi karena membutuhkan pembelajaran simultan dari alokasi anggaran parameter, yang membuat model tidak dapat menyesuaikan data pelatihan dengan baik.
(3) Metode lain dapat dengan cepat menyatu dengan data pelatihan dan cocok dengan baik.
Untuk dampak dari berbagai jenis set data instruksi Cina, penulis mengumpulkan instruksi Cina terbuka yang populer (seperti yang ditunjukkan pada Tabel 5) untuk menyempurnakan mekar dengan Lora.
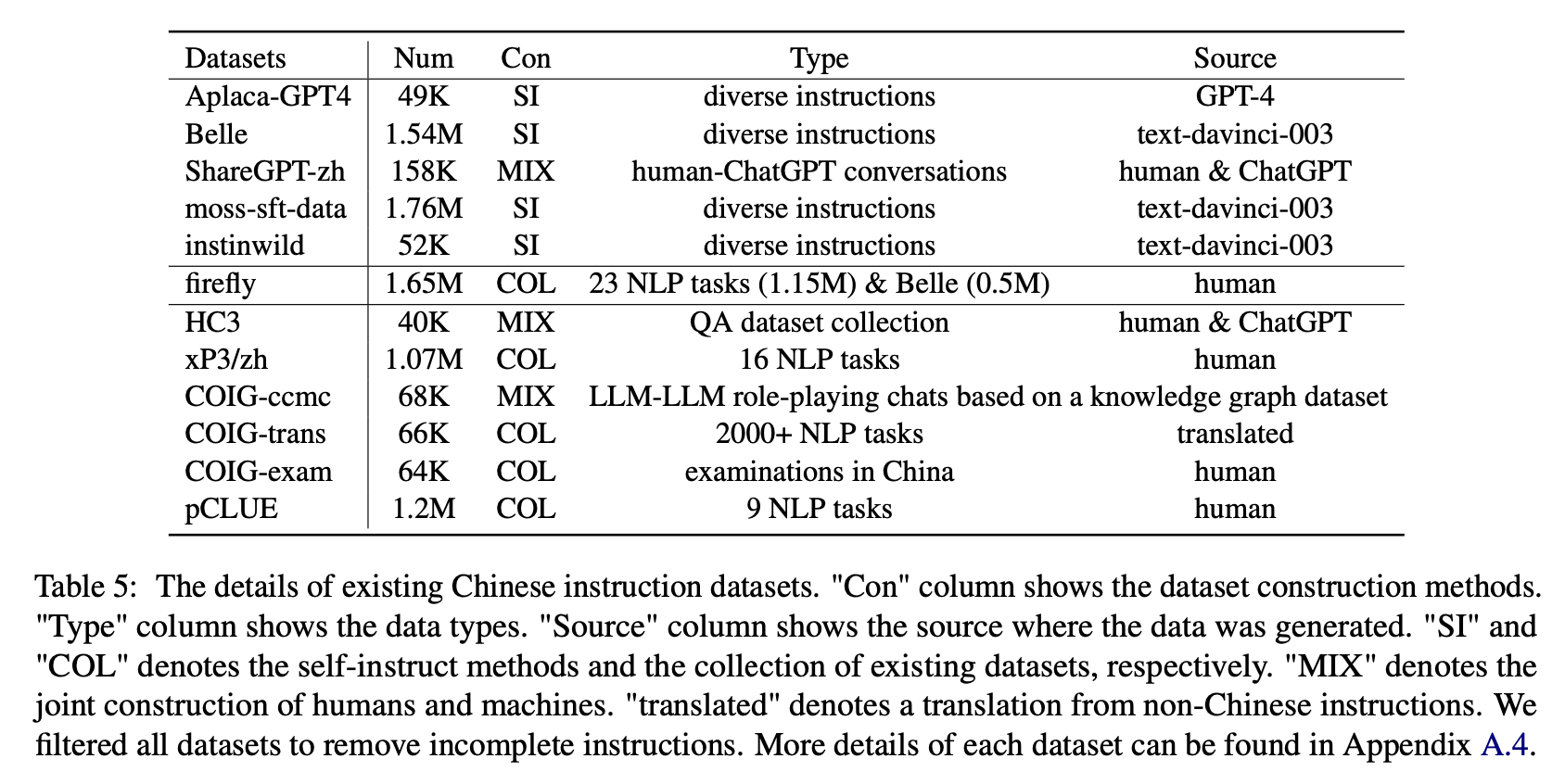
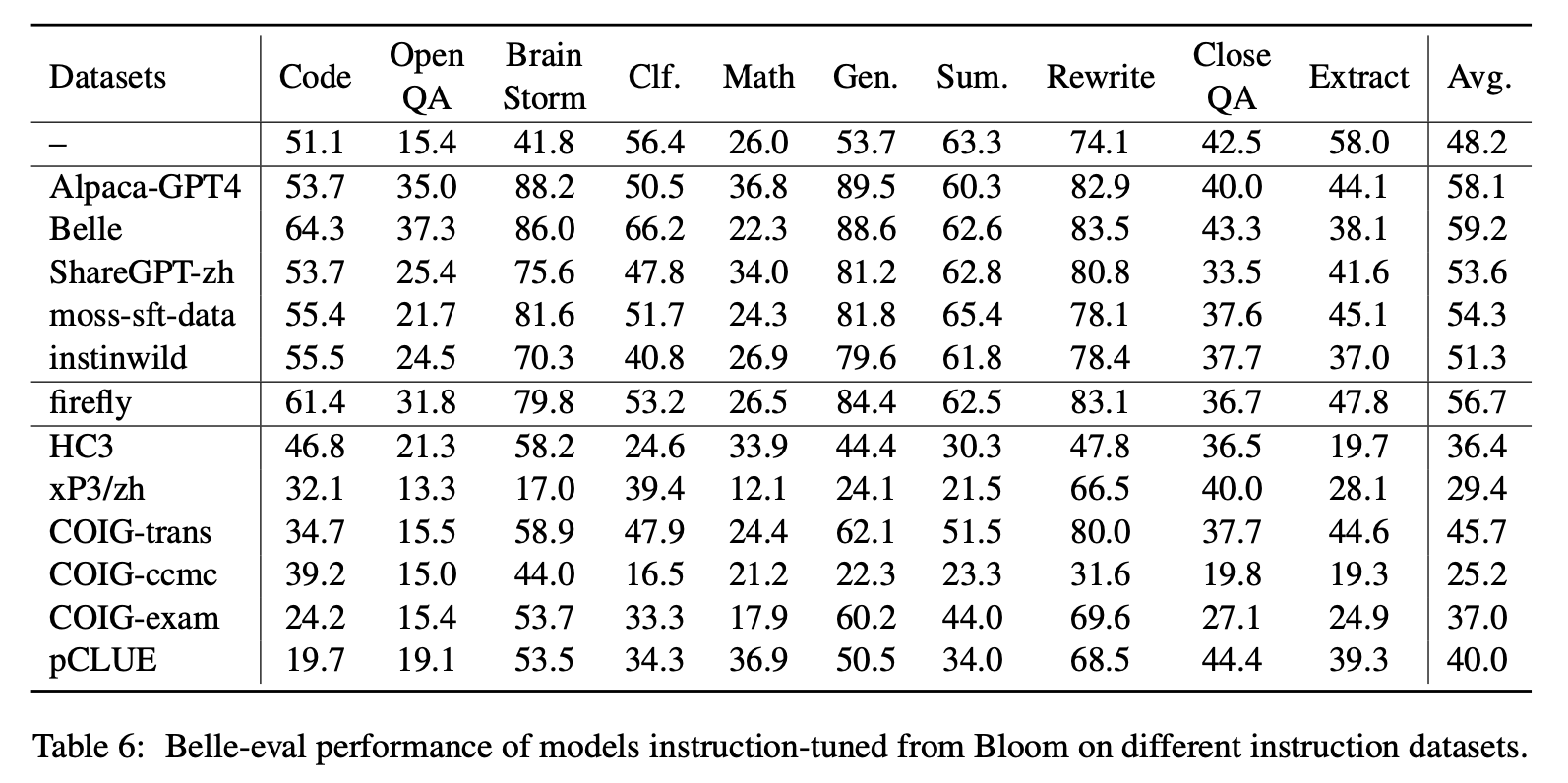
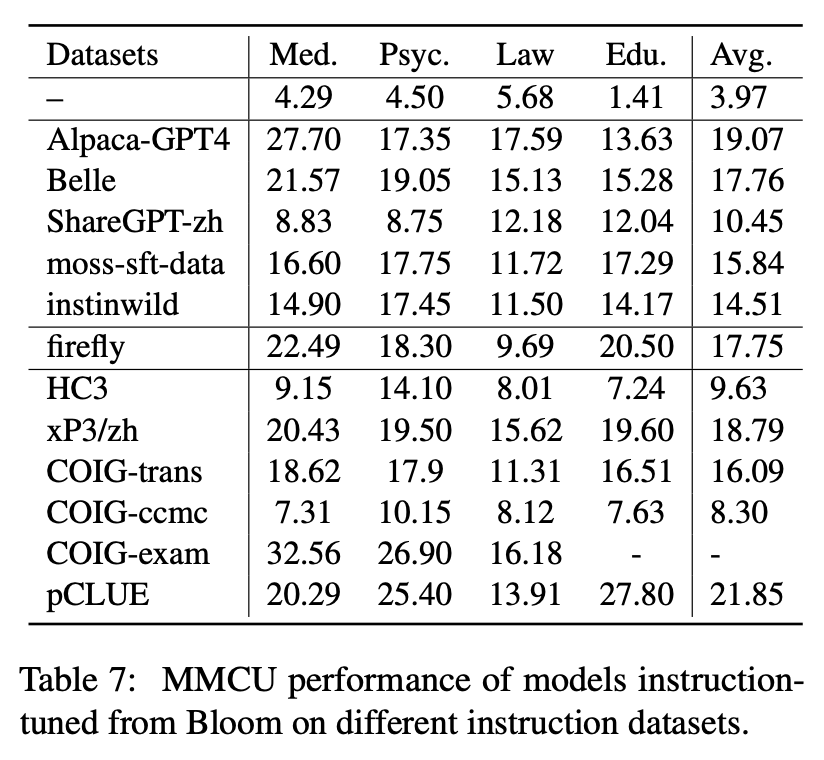
Tabel 6 dan Tabel 7 menunjukkan fine-tuning Bloom pada dataset instruksi yang berbeda.
Hasil Eksperimen:
Kinerja di Belle-Eval
(1) Data instruksi yang dibangun oleh chatgpt (misalnya, menggunakan metode instruksi sendiri atau mengumpulkan percakapan chatgpt manusia nyata) secara konsisten meningkatkan kemampuan mengikuti instruksi dengan skor skor 11 poin 3,1 ∼ meningkat.
(2) Di antara set data ini, Belle memiliki kinerja terbaik karena jumlah data instruksi terbesar. Namun, kinerja model yang dilatih pada data lumut-sft, yang berisi lebih banyak data yang dibangun dengan cara yang sama, tidak memuaskan.
(3) Kinerja yang dibawa oleh instruksi ALPACA-GPT4 adalah yang terbaik kedua, dengan hanya 49k yang sebanding dengan 1,54M Belle.
(4) InstinWild membawa keuntungan kinerja paling sedikit di antara mereka karena instruksi benih yang dirayapi dari tweet ("di Wild") tidak selengkap yang (seperti alpaca) yang dirancang dengan cermat oleh manusia.
(5) Data berbasis chatgpt ini terutama memiliki efek peningkatan yang signifikan pada tugas-tugas pembuatan terbuka seperti badai dan generasi otak, sementara ada penurunan tugas yang signifikan yang membutuhkan keterampilan pemahaman membaca yang tinggi, seperti QA dan ekstrak dekat.
(6) Kumpulan data instruksi ini menyebabkan kerusakan pada kemampuan mengikuti instruksi model, karena bentuk dan maksud dari setiap NLP atau dataset pemeriksaan adalah kesatuan, yang dapat dengan mudah diatasi.
(7) Di antara mereka, Coig-Trans melakukan yang terbaik karena melibatkan lebih dari 2000 tugas yang berbeda dengan berbagai macam instruksi tugas. Sebaliknya, XP3 dan COIG-CCMC memiliki dampak negatif terburuk pada kinerja model. Keduanya hanya mencakup beberapa jenis tugas (terjemahan dan QA untuk yang pertama, percakapan koreksi kontrafaktual untuk yang terakhir), yang hampir tidak mencakup instruksi dan tugas populer untuk manusia.
Kinerja di MMCU
(1) Penyetelan instruksi pada setiap dataset selalu dapat menghasilkan peningkatan kinerja.
(2) Di antara data berbasis chatgpt yang ditunjukkan pada bagian atas, Sharegpt-Zh berkinerja buruk dengan margin besar. Ini mungkin karena fakta bahwa pengguna nyata jarang mengajukan pertanyaan pilihan ganda tentang topik akademik.
(3) Di antara data pengumpulan dataset yang ditunjukkan pada bagian bawah, HC3 dan COIG-CCMC menghasilkan akurasi terendah karena pertanyaan unik HC3 hanya 13k, dan format tugas COIG-CCMC secara signifikan berbeda dari MMCU.
(4) COIG-EXAM membawa peningkatan akurasi terbesar, mendapat manfaat dari format tugas yang sama dengan MMCU.
Empat Faktor Lainnya: Rekanan, Perluasan Kosakata Cina, Bahasa Prompt dan Penyelarasan Nilai Manusia
Untuk COT, penulis membandingkan kinerja sebelum dan sesudah menambahkan data COT selama penyetelan instruksi.
Pengaturan Eksperimen:
Kami mengumpulkan 9 dataset COT dan petunjuknya dari Flan, dan kemudian menerjemahkannya ke dalam bahasa Mandarin menggunakan Google Translate. Mereka membandingkan kinerja sebelum dan sesudah menambahkan data COT selama penyetelan instruksi.
Pertama perhatikan cara untuk menambahkan data COT sebagai "alpaca-gpt4+cot". Selain itu, tambahkan kalimat "先思考 , 再决定" ("pikirkan langkah demi langkah" dalam bahasa Cina) di akhir setiap instruksi, untuk menginduksi model untuk menanggapi instruksi berdasarkan ranjang, dan memberi label dengan cara ini sebagai "alpaca-gpt4+cot*".
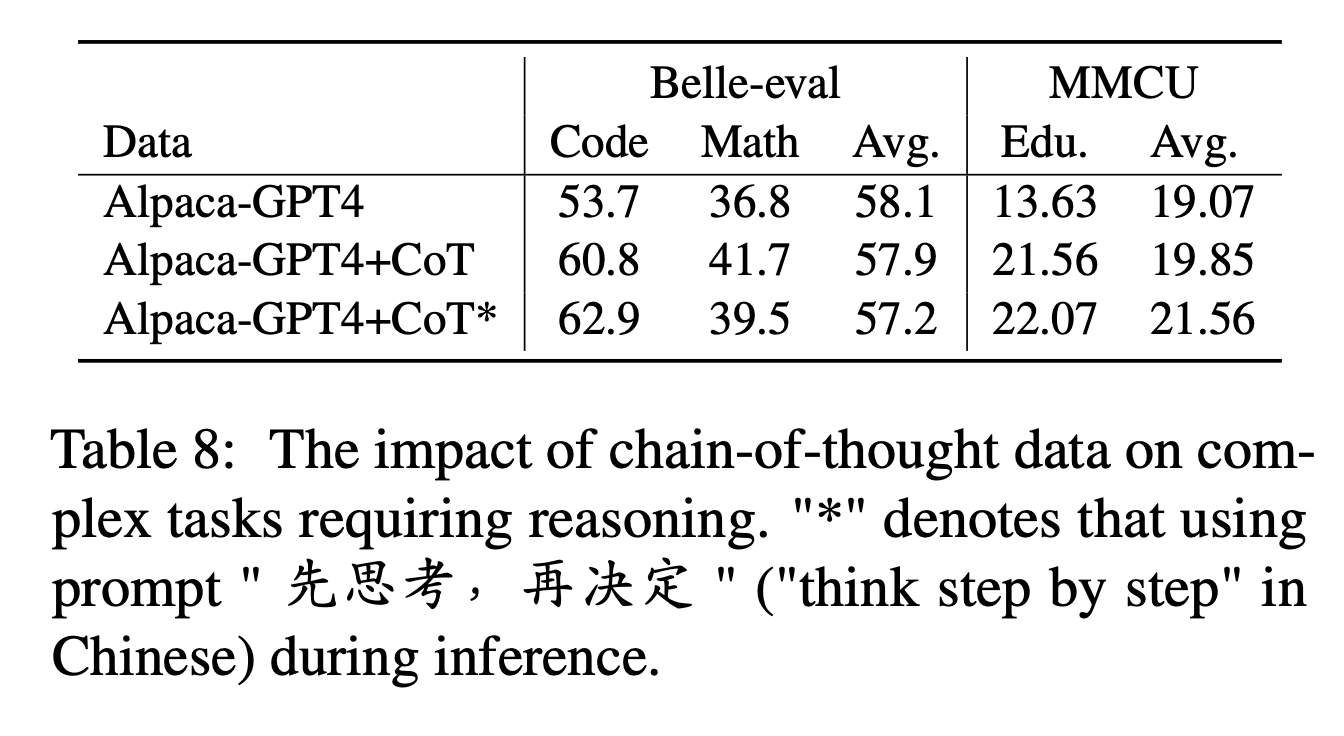
Hasil Eksperimen:
"ALPACA-GPT4+COT" mengungguli "Alpaca-GPT4" dalam tugas kode dan matematika yang membutuhkan kemampuan penalaran yang kuat. Selain itu, ada juga peningkatan yang signifikan dalam tugas pendidikan MMCU.
Seperti yang ditunjukkan pada baris "Alpaca-GPT4+COT*", kalimat sederhana dapat lebih meningkatkan kinerja kode dan pendidikan tugas penalaran, sedangkan kinerja matematika sedikit lebih rendah daripada "Alpaca-GPT4+COT". Ini mungkin memerlukan penjelajahan lebih lanjut dari petunjuk yang lebih kuat.
Untuk perluasan kosa kata Cina, penulis menguji pengaruh jumlah token Cina dalam kosakata tokenizer tentang kemampuan LLMS untuk mengekspresikan Cina. Misalnya, jika karakter Cina berada dalam kosakata, itu dapat diwakili oleh satu token, jika tidak, ia mungkin memerlukan banyak token untuk mewakilinya.
Pengaturan Eksperimen: Penulis terutama melakukan eksperimen di Llama, yang menggunakan kalimat (32K ukuran kosa kata karakter Cina) yang mencakup lebih sedikit karakter Cina daripada Bloom (250k).
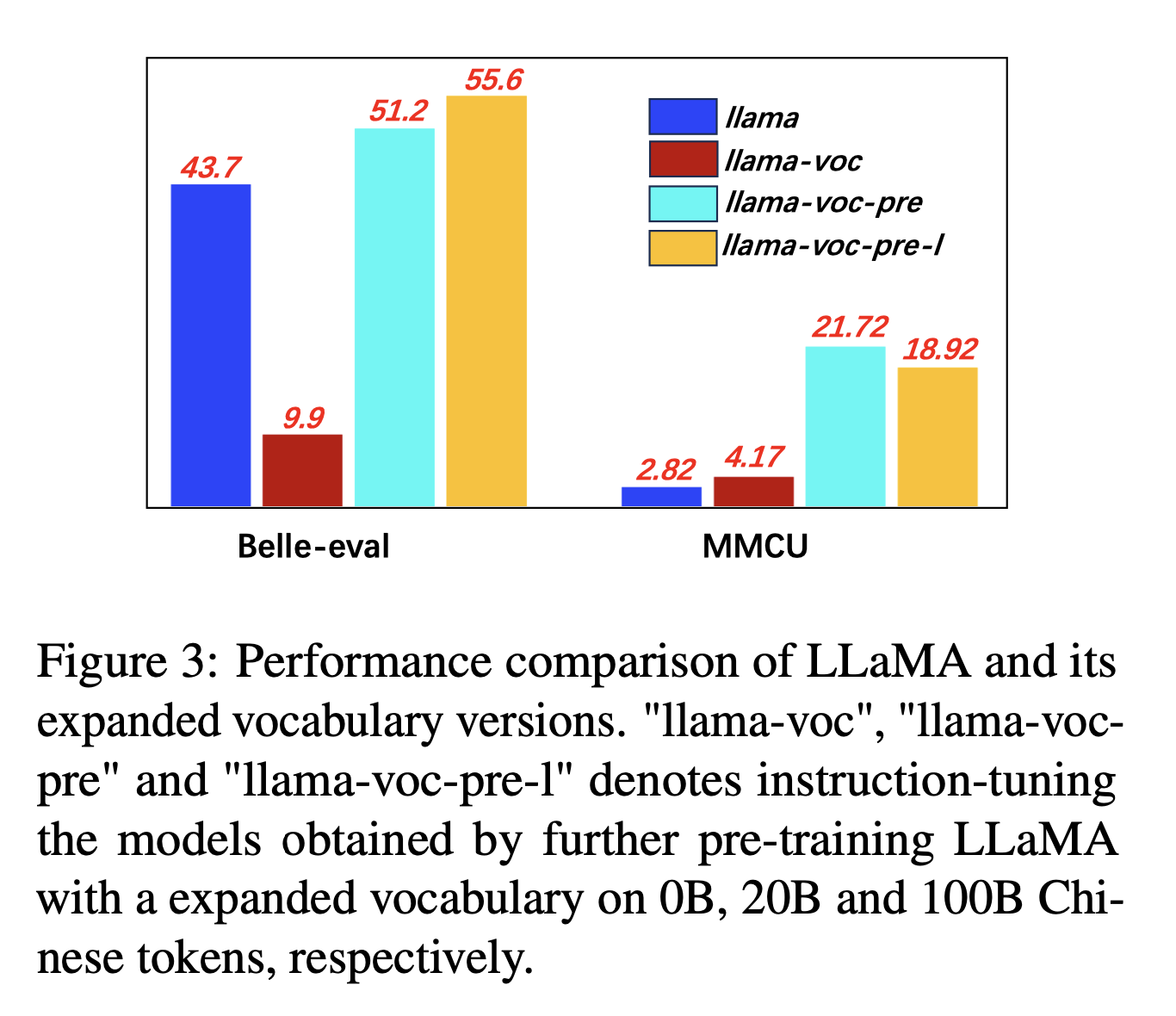
Hasil Eksperimen:
Pra-pelatihan pada lebih banyak korpus Cina dengan perluasan kosa kata Cina secara konsisten bermanfaat untuk kemampuan mengikuti instruksi.
Dan secara berlawanan, "llama-voc-pre-l" (100b) lebih rendah dari "llama-voc-pre" (20b) pada MMCU, yang menunjukkan bahwa pra-pelatihan pada lebih banyak data mungkin tidak selalu mengarah pada kinerja yang lebih tinggi untuk ujian akademik.
Untuk bahasa petunjuk, penulis menguji kesesuaian penyempurnaan instruksi untuk menggunakan petunjuk Cina.
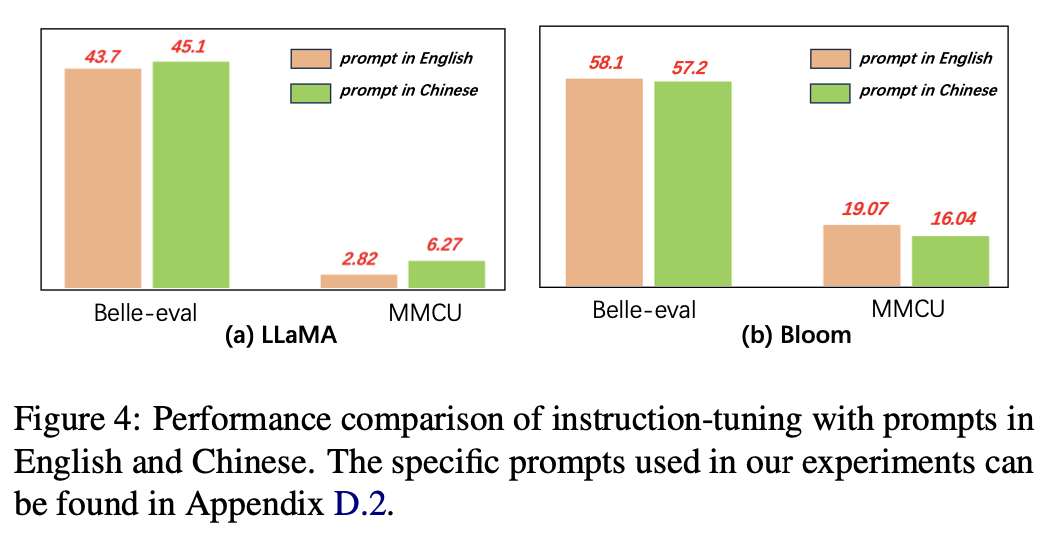
Gambar 4 menunjukkan hasil menggunakan permintaan Cina dan Inggris berdasarkan Llama dan Bloom. Ketika instruksi-tuning llama, menggunakan petunjuk Cina dapat meningkatkan kinerja pada kedua tolok ukur dibandingkan dengan petunjuk bahasa Inggris, sementara fenomena yang berlawanan dapat diamati saat mekar.
Hasil Eksperimen:
Untuk model dengan kemampuan Cina yang lebih lemah (misalnya, Llama), menggunakan petunjuk Cina dapat secara efektif membantu merespons dalam bahasa Cina.
Untuk model dengan kemampuan Cina yang baik (misalnya, mekar), menggunakan petunjuk dalam bahasa Inggris (bahasa yang lebih baik) dapat memandu model dengan lebih baik untuk memahami proses penyempurnaan dengan instruksi.
Untuk menghindari LLMS menghasilkan konten beracun, menyelaraskannya dengan nilai -nilai manusia adalah masalah yang penting. Kami menambahkan data penyelarasan nilai manusia yang dibangun oleh CoIG ke dalam pengajaran untuk mengeksplorasi dampaknya.
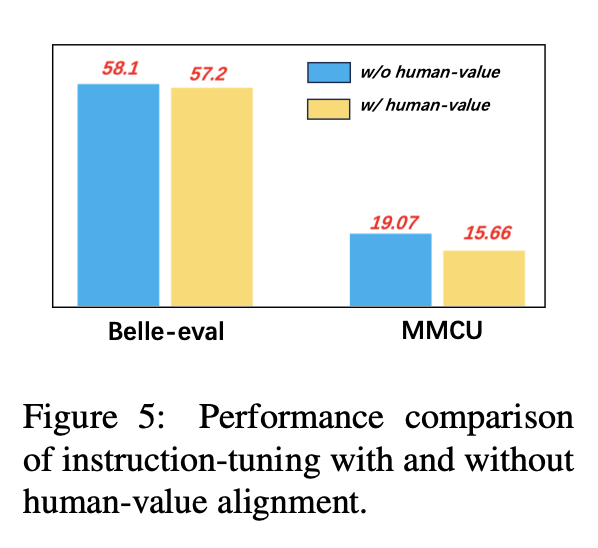
Gambar 5 membandingkan hasil penyetelan instruksi dengan dan tanpa penyelarasan nilai manusia.
Hasil Eksperimen: Penyelarasan nilai manusia menghasilkan sedikit penurunan kinerja. Bagaimana menyeimbangkan ketidakberdayaan dan kinerja LLMS adalah arah penelitian yang patut dieksplorasi di masa depan.
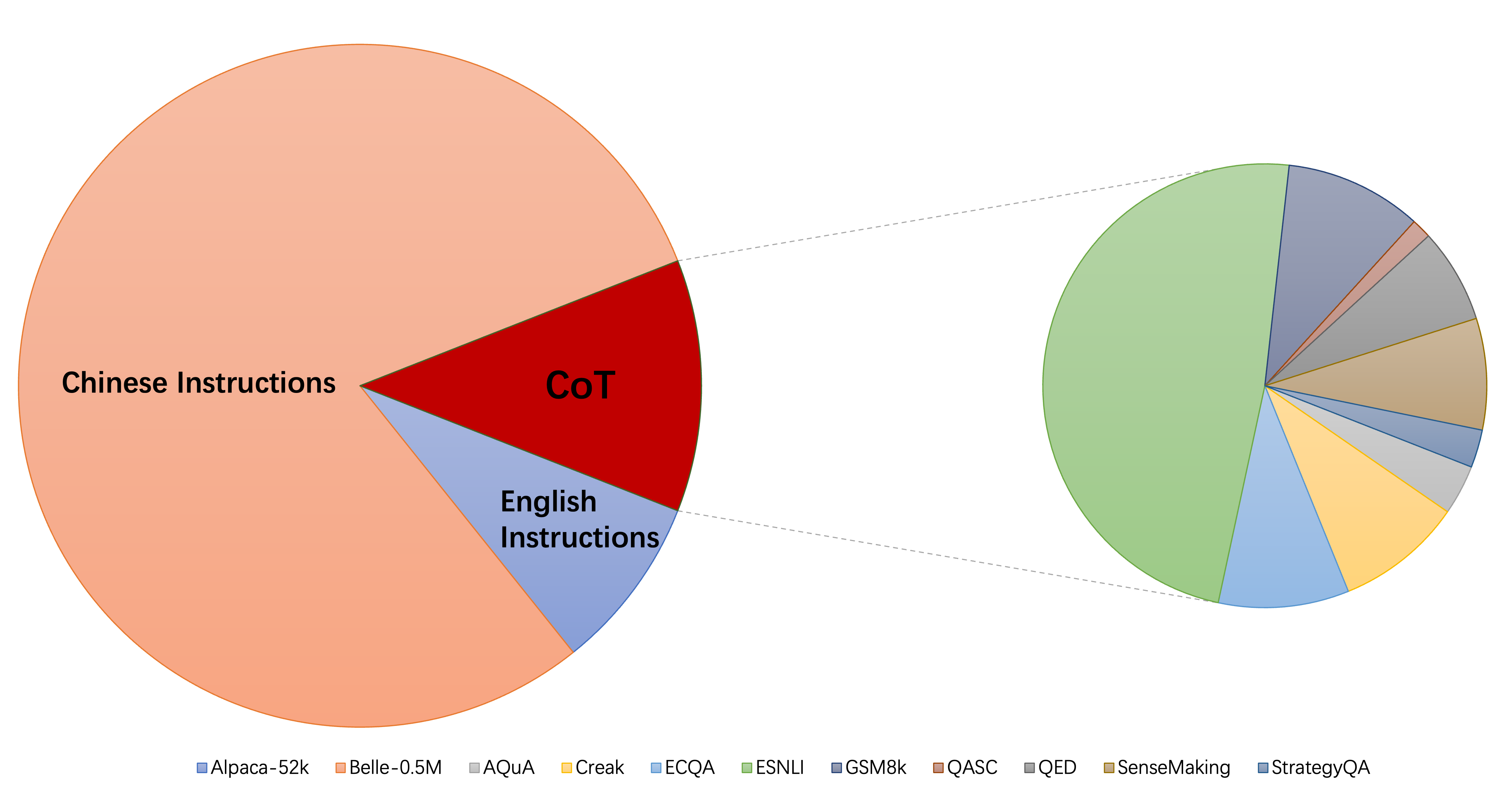 Koleksi dataset pembagian instruksi saat ini terutama terdiri dari tiga bagian:
Koleksi dataset pembagian instruksi saat ini terutama terdiri dari tiga bagian:
alpaca_data_cleaned.json : sekitar 52k sampel pelatihan mengikuti instruksi bahasa Inggris.CoT_data.json : 9 Dataset COT yang melibatkan sekitar 75k sampel. (Diterbitkan oleh Flan [7])belle_data_cn.json : Sekitar 0,5m Cina | Sampel pelatihan mengikuti instruksi. (Diterbitkan oleh Belle [8]) "W/o cot" dan "w/o cn" menunjukkan model yang mengecualikan data COT dan instruksi Cina dari instruksi mereka masing -masing data finetuning.
"W/o cot" dan "w/o cn" menunjukkan model yang mengecualikan data COT dan instruksi Cina dari instruksi mereka masing -masing data finetuning.
Tabel di atas menunjukkan dua contoh (melibatkan dengan perhitungan numerik) yang membutuhkan sejumlah kemampuan penalaran untuk merespons dengan benar. Seperti yang ditunjukkan di kolom tengah, Ours w/o CoT gagal menghasilkan respons yang benar, yang menunjukkan bahwa begitu data finetuning tidak mengandung data COT, kemampuan penalaran model menurun secara signifikan. Ini lebih lanjut menunjukkan bahwa data COT sangat penting untuk model LLM.

Tabel di atas menunjukkan dua contoh yang membutuhkan kemampuan untuk menanggapi instruksi Cina. Seperti yang ditunjukkan di kolom kanan, baik konten yang dihasilkan dari Ours w/o CN tidak masuk akal, atau instruksi Cina dijawab dalam bahasa Inggris oleh Ours w/o CN . Ini menunjukkan bahwa menghapus data Tiongkok selama finetuning akan menyebabkan model tidak dapat menangani instruksi Cina, dan lebih lanjut menunjukkan perlunya mengumpulkan data Finetuning instruksi Cina.

Tabel di atas menunjukkan contoh yang relatif sulit, yang membutuhkan akumulasi pengetahuan tertentu tentang sejarah Tiongkok dan kemampuan logis dan lengkap untuk menyatakan peristiwa sejarah. Seperti yang ditunjukkan dalam tabel ini, Ours w/o CN hanya dapat menghasilkan respons yang pendek dan salah, karena karena kurangnya data finetuning Cina, pengetahuan yang sesuai tentang sejarah Tiongkok secara alami kurang. Meskipun Ours w/o CoT mencantumkan beberapa peristiwa sejarah Tiongkok yang relevan, logika ekspresinya adalah kontradiktif, yang disebabkan oleh kurangnya data COT. `
Singkatnya, model -model Finetuned dari dataset lengkap kami (Bahasa Inggris, Cina, dan Data Instruksi COT) dapat secara signifikan meningkatkan penalaran model dan pengajaran Cina mengikuti kemampuan.
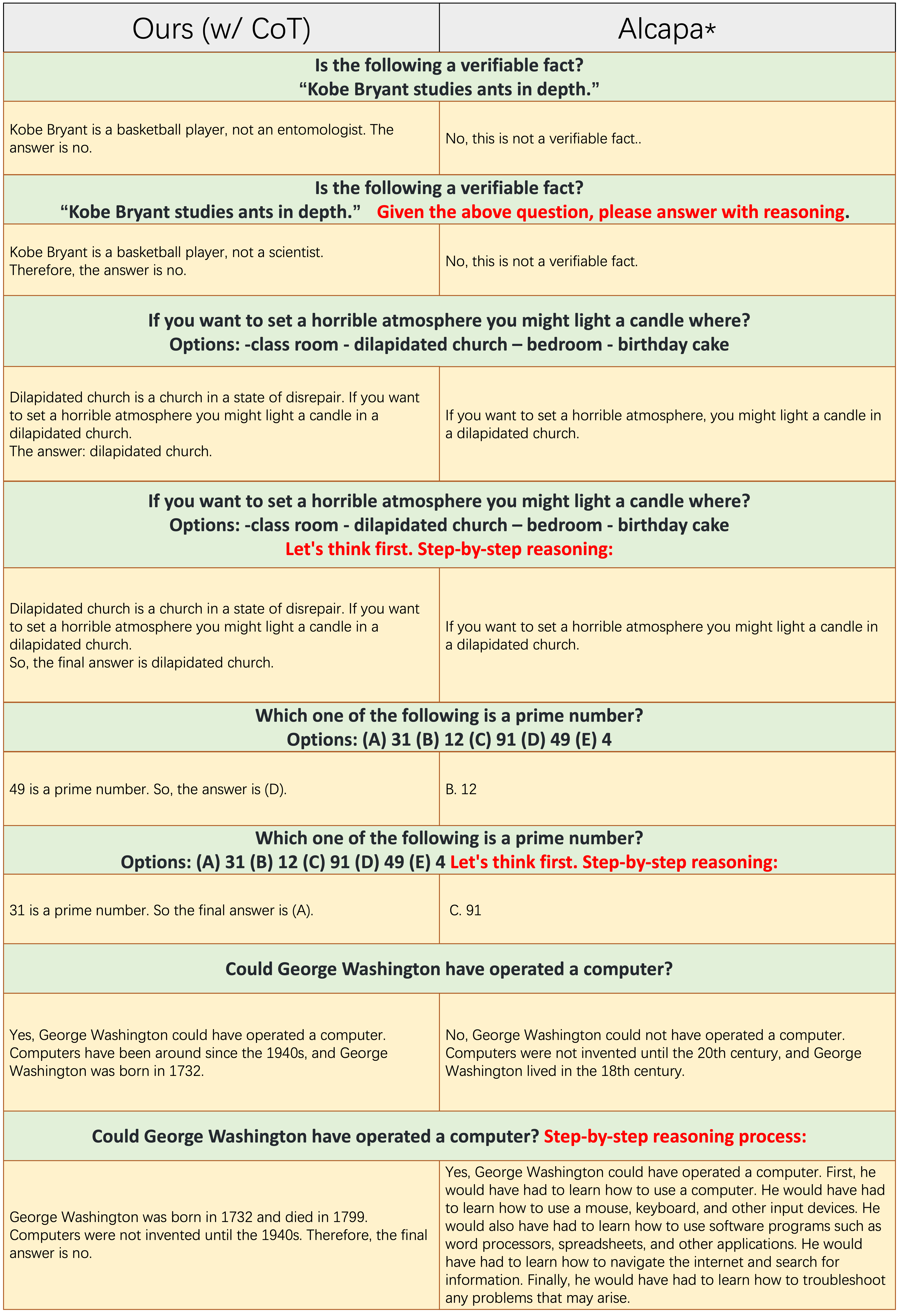 Sampel dari masing-masing jumlah baris yang ganjil tidak menerapkan prompt COT, seperti "penalaran langkah demi langkah." Baik
Sampel dari masing-masing jumlah baris yang ganjil tidak menerapkan prompt COT, seperti "penalaran langkah demi langkah." Baik Ours(w/CoT) dan alpaca didasarkan pada LLAMA-7B, dan satu-satunya perbedaan di antara mereka berdua adalah bahwa data pembagian instruksi Ours(w/CoT) memiliki data COT tambahan daripada Alpaca.
Dari tabel di atas, kami menemukan itu:
Ours(w/CoT) selalu menghasilkan alasan yang benar sebelum jawabannya, sementara alpaca gagal menghasilkan alasan yang masuk akal, seperti yang ditunjukkan dalam 4 contoh pertama (pertanyaan akal sehat). Ini menunjukkan bahwa menggunakan data COT untuk finetuning dapat secara signifikan meningkatkan kemampuan penalaran.Ours(w/CoT) , prompt COT (misalnya, 'langkah demi langkah' dengan pertanyaan input) memiliki sedikit efek pada contoh-contoh mudah (misalnya, pertanyaan akal sehat) dan memiliki efek penting pada pertanyaan yang menantang (misalnya, pertanyaan yang membutuhkan penalaran, seperti empat contoh terakhir). Perbandingan kuantitatif tanggapan terhadap instruksi Cina. 
Model kami diuraikan dari 7B llama pada instruksi bahasa Inggris 52k dan instruksi Cina 0,5m. Stanford Alpaca (penerapan ulang kami) diuraikan dari 7b llama dengan instruksi bahasa Inggris 52k. Belle diarahkan dari mekar 7B pada instruksi Cina 2B.
Dari tabel di atas, beberapa pengamatan dapat ditemukan:
ours (w/ CN) memiliki kemampuan yang lebih kuat untuk memahami instruksi Cina. Untuk contoh pertama, alpaca gagal membedakan antara bagian instruction dan bagian input , saat kami melakukannya.ours (w/ CN) tidak hanya menyediakan kode yang benar, tetapi juga memberikan anotasi Cina yang sesuai, sedangkan alpaca tidak. Selain itu, seperti yang ditunjukkan dalam contoh 3-5, alpaca hanya dapat menanggapi instruksi Cina dengan respons bahasa Inggris.ours (w/ CN) pada instruksi yang membutuhkan respons terbuka (seperti yang ditunjukkan dalam dua contoh terakhir) masih perlu ditingkatkan. Kinerja Belle yang luar biasa terhadap instruksi semacam itu adalah karena: 1. Model backbone mekarnya bertemu lebih banyak data multibahasa selama pra-pelatihan; 2. Data Finetuning Instruksi Cina lebih dari kami, yaitu, 2m vs 0,5m. Perbandingan kuantitatif tanggapan terhadap instruksi bahasa Inggris. Tujuan dari ayat ini adalah untuk mengeksplorasi apakah finetuning pada instruksi Cina memiliki dampak negatif pada alpaca. 
Dari tabel di atas, kami menemukan itu:
ours (w/ CN) menunjukkan lebih detail daripada alpaca, misalnya untuk contoh ketiga, ours (w/ CN) mencantumkan tiga provinsi lebih dari alpaca. Harap kutip repo jika Anda menggunakan pengumpulan data, kode, dan temuan eksperimental dalam repo ini.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Untuk data dan model, silakan mengutip data asli, metode yang efisien parameter dan sumber LLMS juga.
Kami ingin mengucapkan terima kasih khusus kepada Apus Ailme Lab untuk mensponsori 8 A100 GPU untuk percobaan.
(kembali ke atas)


