Alpaca CoT
1.0.0
中文| Englisch

Dies ist das Repository für das Alpaca-CoT -Projekt, mit dem eine FIFT-Plattform (Instruction Fonetuning) mit umfangreicher Anweisungssammlung (insbesondere die COT-Datensätze) und eine einheitliche Schnittstelle für verschiedene großsprachige Modelle und parametereffiziente Methoden erstellt werden sollen. Wir erweitern ständig unsere Datenerfassung für die Anweisungseinstellung und integrieren mehr LLMs und mehr parametereffizientere Methoden. Zusätzlich haben wir einen neuen Zweig tabular_llm erstellt, um ein tabellarisches LLM zum Lösen von Tabellen -Intelligenzaufgaben zu erstellen.
Sie sind herzlich eingeladen, uns nicht gesammelte Datensätze (oder deren Quellen) zu versorgen. Wir werden sie einheitlich formatieren, das Alpaka -Modell (und andere LLMs in der frühen Zukunft) mit diesen Datensätzen ausbilden, die Modell -Checkpoints Open Source durchführen und umfangreiche empirische Studien durchführen. Wir hoffen, dass unser Projekt einen bescheidenen Beitrag zum Open-Source-Prozess großer Sprachmodelle leisten und seinen Schwellenwert für NLP-Forscher verringern kann, um loszulegen.

Wenn Sie neben Lora andere Methoden verwenden möchten, installieren Sie bitte die bearbeitete Version in unserem Projekt pip install -e ./peft .
12.8: LLM InternLM wurde zusammengeführt.
8.16: 4bit quantization ist für lora , qlora und adalora verfügbar.
8.16: Parametereffiziente Methoden Qlora , Sequential adapter und Parallel adapter wurden zusammengeführt.
7.24: LLM ChatGLM v2 wurde zusammengeführt.
7.20: LLM Baichuan wurde zusammengeführt.
6.25: Modellbewertungscode, einschließlich Belle und MMCU.
GPT4Tools , Auto CoT , pCLUE sind hinzugefügt.tabular_llm wird erstellt, um ein tabellarisches LLM zu erstellen. Wir erfassen Befehlsfeineinstellungsdaten für tabellbezogene Aufgaben wie die Beantwortung von Tabellenfragestellen und verwenden sie, um LLMs in diesem Repo zu feinstimmen.MOSS wurde zusammengeführt.GAOKAO , camel , FLAN-Muffin , COIG werden gesammelt und formatiert.webGPT , dolly , baize , hh-rlhf , OIG(part) werden gesammelt und formatiert.multi-turn conversation von @paulcx hinzugefügt.firefly , instruct , Code Alpaca werden gesammelt und formatiert, die hier zu finden sind.Parameter merging , Local chatting , Batch predicting und Web service building von @Weberr hinzugefügt.GPTeacher , Guanaco , HC3 , prosocial-dialog , belle-chat&belle-math , xP3 und natural-instructions werden gesammelt und formatiert.CoT_CN_data.json finden Sie hier. 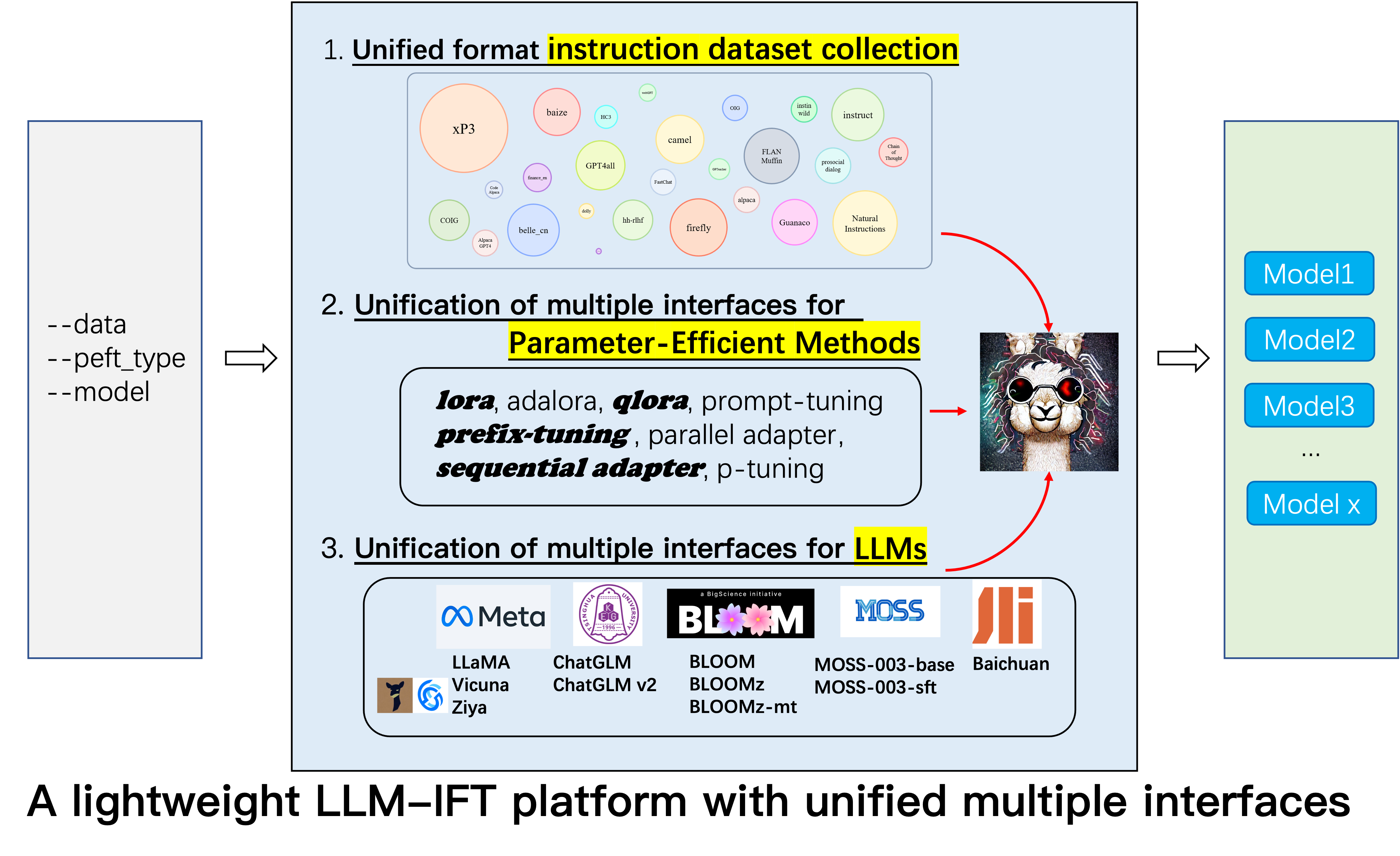
Lama [1] ist eine großartige Arbeit, die die erstaunliche Null-Shot- und wenige Fähigkeiten zum Schuss zeigt. Es reduziert die Kosten für Trainings-, Flossenkosten und die Verwendung wettbewerbsfähiger Großsprachenmodelle. Vor kurzem, um die Fähigkeit zu steigern, die Fähigkeit von Lama, Stanford Alpaca [2], llama-7b auf 52K-Anweisungsdaten, die durch die Selbststruktur- [3] -Techniken generiert wurden, auf 52K-Anweisungsdaten zu steigern. Gegenwärtig hat die LLM-Forschungsgemeinschaft jedoch immer noch drei Herausforderungen: 1. Selbst Lama-7b hat immer noch hohe Anforderungen an die Rechenressourcen; 2. Es gibt nur wenige Open -Source -Datensätze für die Befehlsfonetuning; und 3. Es mangelt es an empirischer Untersuchungen über die Auswirkungen verschiedener Arten von Anweisungen auf Modellfähigkeiten, wie z.
Zu diesem Zweck schlagen wir dieses Projekt vor, das verschiedene Verbesserungen nutzt, die anschließend vorgeschlagen wurden, mit den folgenden Vorteilen:
7b , 13b und 30b -Versionen von Lama -Modellen können auf einem einzigen 80G A100 leicht trainiert werden. Nach unserem Kenntnisstand studiert diese Arbeit die erste, die COT -Argumentation basierend auf Lama und Alpaka studiert. Daher verdichten wir unsere Arbeit auf Alpaca-CoT .
Die relative Größe der gesammelten Datensätze kann in diesem Diagramm angezeigt werden:
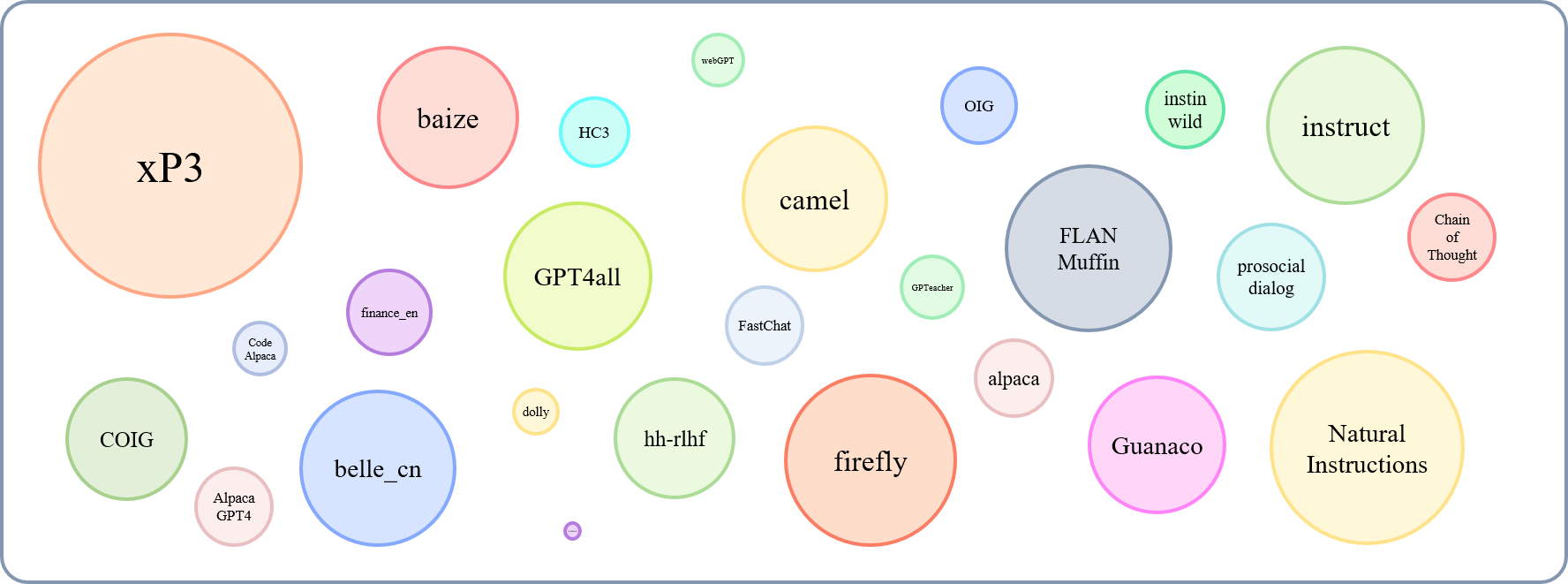
In Bezug auf dies (@yaodongc) haben wir jeden gesammelten Datensatz gemäß den folgenden Regeln gekennzeichnet:
(Lang) linguale Tags:
(Aufgabe) Aufgabenmarke:
(Gen) Generation-Methode:
| Datensatz | Nums | Lang | Aufgabe | Gen | Typ | Src | URL |
|---|---|---|---|---|---|---|---|
| Gedankenkette | 74771 | En/cn | Mt | Hg | unterrichten | Annotieren Sie COT für vorhandene Daten | herunterladen |
| Gpt4all | 806199 | En | Mt | Col | Code, Geschichten und Dialoge | Destillation von GPT-3,5-Turbo | herunterladen |
| Gpteigner | 29013 | En | Mt | Si | Allgemein, Rollenspiel, Toolformer | GPT-4 & Toolformer | herunterladen |
| Guanaco | 534610 | Ml | Mt | Si | Verschiedene sprachliche Aufgaben | Text-Davinci-003 | herunterladen |
| HC3 | 37175 | En/cn | Ts | MISCHEN | Dialogbewertung | Mensch oder Chatgpt | herunterladen |
| Alpaka | 52002 | En | Mt | Si | Allgemeiner Anweisungen | Text-Davinci-003 | herunterladen |
| Natürliche Anweisungen | 5040134 | Ml | Mt | Col | Verschiedene NLP -Aufgaben | menschliche Annotierdatensätze Sammlung | herunterladen |
| Belle_cn | 1079517 | CN | Ts/mt | Si | General, mathematisches Denken, Dialog | Text-Davinci-003 | herunterladen |
| Instinwild | 52191 | En/cn | Mt | Si | Generation, Open-QA, Mind-Storm | Text-Davinci-003 | herunterladen |
| prosoziales Dialog | 165681 | En | Ts | MISCHEN | Dialog | GPT-3 schreibt Fragen + Menschen Feedback manuell um | herunterladen |
| Finance_en | 68912 | En | Ts | Col | Finanzbezogene QA | Gpt3.5 | herunterladen |
| XP3 | 78883588 | Ml | Mt | Col | Eine Sammlung von Eingabeaufforderungen und Datensätzen in 46 Sprachen und 16 NLP -Aufgaben | menschliche Annotierdatensätze Sammlung | herunterladen |
| Firefly | 1649398 | CN | Mt | Col | 23 NLP -Aufgaben | menschliche Annotierdatensätze Sammlung | herunterladen |
| anweisen | 888969 | En | Mt | Col | Augmented von GPT4ALL, ALPACA, Open-Source-Meta-Datensätzen | Augmentation wird mit den von Allenai bereitgestellten fortschrittlichen NLP -Tools durchgeführt | herunterladen |
| Code Alpaka | 20022 | En | Ts | Si | Codegenerierung, Bearbeitung, Optimierung | Text-Davinci-003 | herunterladen |
| ALPACA_GPT4 | 52002 | En/cn | Mt | Si | Allgemeiner Anweisungen | Erzeugt von GPT-4 mit Alpaka | herunterladen |
| Webgpt | 18994 | En | Ts | MISCHEN | Informationsabruf (IR) QA | Fein abgestimmter GPT-3, jeder Befehl hat zwei Ausgänge. Wählen Sie besser aus | herunterladen |
| Dolly 2.0 | 15015 | En | Ts | Hg | geschlossene QA, Zusammenfassung und etc, Wikipedia als Referenzen | menschliche Annotation | herunterladen |
| Fries | 653699 | En | Mt | Col | Eine Sammlung von Alpaka-, Quora-, Stackoverflow- und Medquad -Fragen | menschliche Annotierdatensätze Sammlung | herunterladen |
| HH-RLHF | 284517 | En | Ts | MISCHEN | Dialog | Dialog zwischen menschlichen und RLHF -Modellen | herunterladen |
| Oig (Teil) | 49237 | En | Mt | Col | aus verschiedenen Aufgaben erstellt, wie z. B. Frage und Beantwortung | Verwenden der Datenvergrößerung, Annotated Datasets Collection Human | herunterladen |
| Gaokao | 2785 | CN | Mt | Col | Multiple-Choice-, Füll- und offene Fragen aus der Prüfung | menschliche Annotation | herunterladen |
| Kamel | 760620 | En | Mt | Si | Rollenspielgespräche in der KI-Gesellschaft, Code, Mathematik, Physik, Chemie, Biolog | GPT-3,5-Turbo | herunterladen |
| Flan-Muffin | 1764800 | En | Mt | Col | 60 NLP -Aufgaben | menschliche Annotierdatensätze Sammlung | herunterladen |
| Coig (Flaginstruktur) | 298428 | CN | Mt | Col | Sammeln Sie Fron-Prüfung, übersetzte, menschliche Anweisungen zur Wertausrichtung und kontrafakturale Korrektur mehr-Runden-Chat | Verwendung automatischer Werkzeug- und manueller Überprüfung | herunterladen |
| Gpt4tools | 71446 | En | Mt | Si | Eine Sammlung von Werkzeuganweisungen | GPT-3,5-Turbo | herunterladen |
| Sharechat | 1663241 | En | Mt | MISCHEN | Allgemeiner Anweisungen | Crowdsourcing, um Gespräche zwischen Menschen und Chatgpt (Sharegpt) zu sammeln | herunterladen |
| Auto COT | 5816 | En | Mt | Col | Arithmetik-, gesunden Menschen-, symbolische und andere logische Argumentationsaufgaben | menschliche Annotierdatensätze Sammlung | herunterladen |
| MOOS | 1583595 | En/cn | Ts | Si | Allgemeiner Anweisungen | Text-Davinci-003 | herunterladen |
| Ultrachat | 28247446 | En | Fragen zur Welt, zum Schreiben und der Schöpfung, Unterstützung bei existierenden Materialien | Zwei separate GPT-3,5-Turbo | herunterladen | ||
| Chinesisch-medizinisch | 792099 | CN | Ts | Col | Fragen zur medizinischen Beratung | kriechen | herunterladen |
| CSL | 396206 | CN | Mt | Col | Papiertextgenerierung, Keyword -Extraktion, Textübersicht und Textklassifizierung | kriechen | herunterladen |
| pclue | 1200705 | CN | Mt | Col | Allgemeiner Anweisungen | herunterladen | |
| News_Commentary | 252776 | CN | Ts | Col | übersetzen | herunterladen | |
| Stackllama | Todo | En |
Hier können Sie alle formatierten Daten herunterladen. Dann sollten Sie sie in den Datenordner einfügen.
Hier können Sie alle Kontrollpunkte herunterladen, die von hier an verschiedenen Arten von Anweisungsdaten geschult wurden. Nachdem Sie LoRA_WEIGHTS (in generate.py ) auf den lokalen Pfad eingestellt haben, können Sie die Modellinferenz direkt ausführen.
Alle Daten in unserer Sammlung sind in die gleichen Vorlagen formatiert, wobei jede Probe wie folgt ist:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
Beachten Sie, dass wir für COT-Datensätze zunächst die von Flan bereitgestellte Vorlage verwenden, um den ursprünglichen Datensatz in verschiedene Formen der Kette der Gedanken zu ändern, und sie dann in das obige Format umwandeln. Das Formatierungsskript finden Sie hier.
pip install -r requirements.txt
Beachten Sie, dass Python> = 3.9 beim Finetuning -Chatglm sicherstellen.
Peft
pip install -e ./peft
Damit die Forscher systematische IFT -Forschung zu LLMs durchführen können, haben wir verschiedene Arten von Anweisungsdaten, integrierte mehrere LLMs und einheitliche Schnittstellen gesammelt, wodurch das Anpassen der gewünschten Kollokation einfach ist:
--model_type : Setzen Sie die LLM, die Sie verwenden möchten. Derzeit werden [Lama, Chatglm, Bloom, Moss] unterstützt. Die beiden letztgenannten haben starke chinesische Fähigkeiten, und in Zukunft werden mehr LLMs integriert.--peft_type : Setzen Sie das von Ihnen gebrauchte PEFT. Derzeit werden [Lora, Adalora, Präfix -Tuning, P -Tuning, Eingabeaufforderung] unterstützt.--data : Legen Sie den für IFT verwendeten Datentyp ein, um die gewünschte Compliance-Fähigkeit flexibel anzupassen. Zum Beispiel für starke Argumentationsfähigkeit "Alpaka-Cot", für starke chinesische Fähigkeiten, "Belle1.5m", für die Codierung und die Fähigkeit zur Erzeugung von Geschichten, "GPT4all" und für finanzielle Reaktionsfähigkeit, festgelegte "Finanzen" festlegen.--model_name_or_path : Dies wird so eingestellt, dass verschiedene Versionen der Modellgewichte für das Ziel LLM --model_type geladen werden. Um beispielsweise die 13B-Version von Lama von Gewichten zu laden, können Sie Decapoda-Research/LLAMA-13B-HF festlegen.Single GPU
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
HINWEIS: Für mehrere Datensätze können Sie --data like --data ./data/alpaca.json ./data/finance.json <path2yourdata_1> verwenden
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Beachten Sie, dass load_in_8bit noch nicht für chatglm geeignet ist, daher muss batch_size kleiner sein als andere.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
Beachten Sie, dass Sie auch den lokalen Pfad (wo LLM -Gewichte gespeichert sind) an --model_name_or_path übergeben können. Und der Datentyp --data kann frei nach Ihren Interessen festgelegt werden.
Multiple GPUs
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
Beachten Sie, dass load_in_8bit noch nicht für chatglm geeignet ist, daher muss batch_size kleiner sein als andere.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
Weitere Details zu Geldfetze und Inferenz finden Sie hier, wo wir geändert haben. Beachten Sie, dass die saved-xxx7b Der Speicherpfad für Lora-Gewichte und Lama-Gewichte werden automatisch aus dem Umarmungsgesicht heruntergeladen.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
Dieses Papier wählt zwei Bewertungsbenchmarks, Belle-Eval und MMCU, aus, um die LLM-Kompetenzen auf Chinesisch umfassend zu bewerten.
Belle-Eval wird mit ChatGPT durch Selbststruktur konstruiert, das 1.000 verschiedene Anweisungen enthält, die 10 Kategorien umfassen, die gemeinsame NLP-Aufgaben (z. B. QA) und herausfordernde Aufgaben (z. B. Code und Mathematik) abdecken. Wir verwenden ChatGPT, um die Modellantworten basierend auf den goldenen Antworten zu bewerten. Dieser Benchmark gilt als Bewertung der AGI-Fähigkeit (Anweisungsverfolgung).
MMCU ist eine Sammlung chinesischer Multiple -Choice -Fragen in vier beruflichen Disziplinen von Medizin, Recht, Psychologie und Bildung (EG, Gaokao -Prüfung). Es ermöglicht LLMs, Untersuchungen in der menschlichen Gesellschaft auf Multiple-Choice-Test durchzuführen, was es zur Bewertung der Breite und Tiefe des Wissens über LLMs über mehrere Disziplinen geeignet ist.
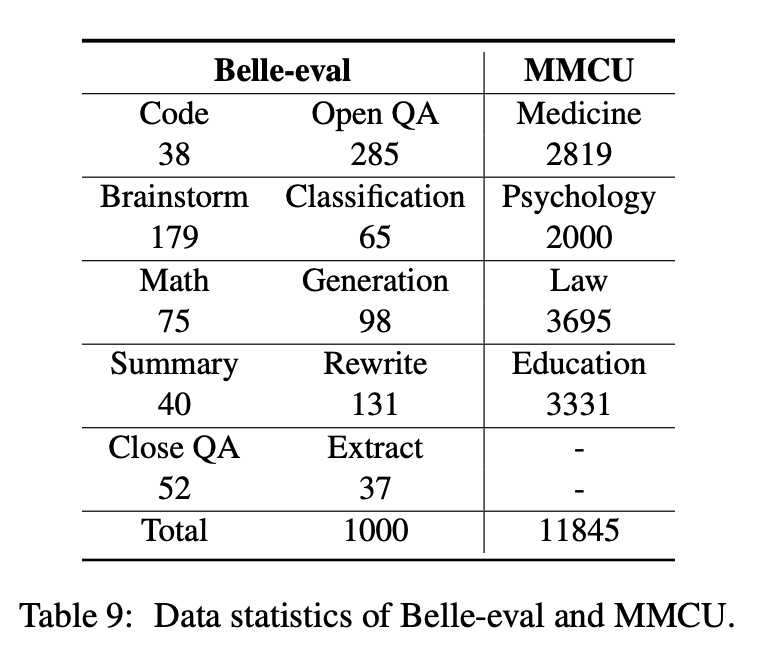
Datenstatistiken von Belle-Eval und MMCU sind in der obigen Tabelle angezeigt.
Wir führen Experimente durch, um die drei Hauptfaktoren für LLMs für Anweisungen zu untersuchen: LLM-Grundlagen, parametereffiziente Methoden, chinesische Befehlsdatensätze.
Für offene LLMs testen wir vorhandene LLMs und LLMs, die mit Lora auf Alpaca-GPT4 auf Belle-Eval bzw. MMCU abgestimmt sind.
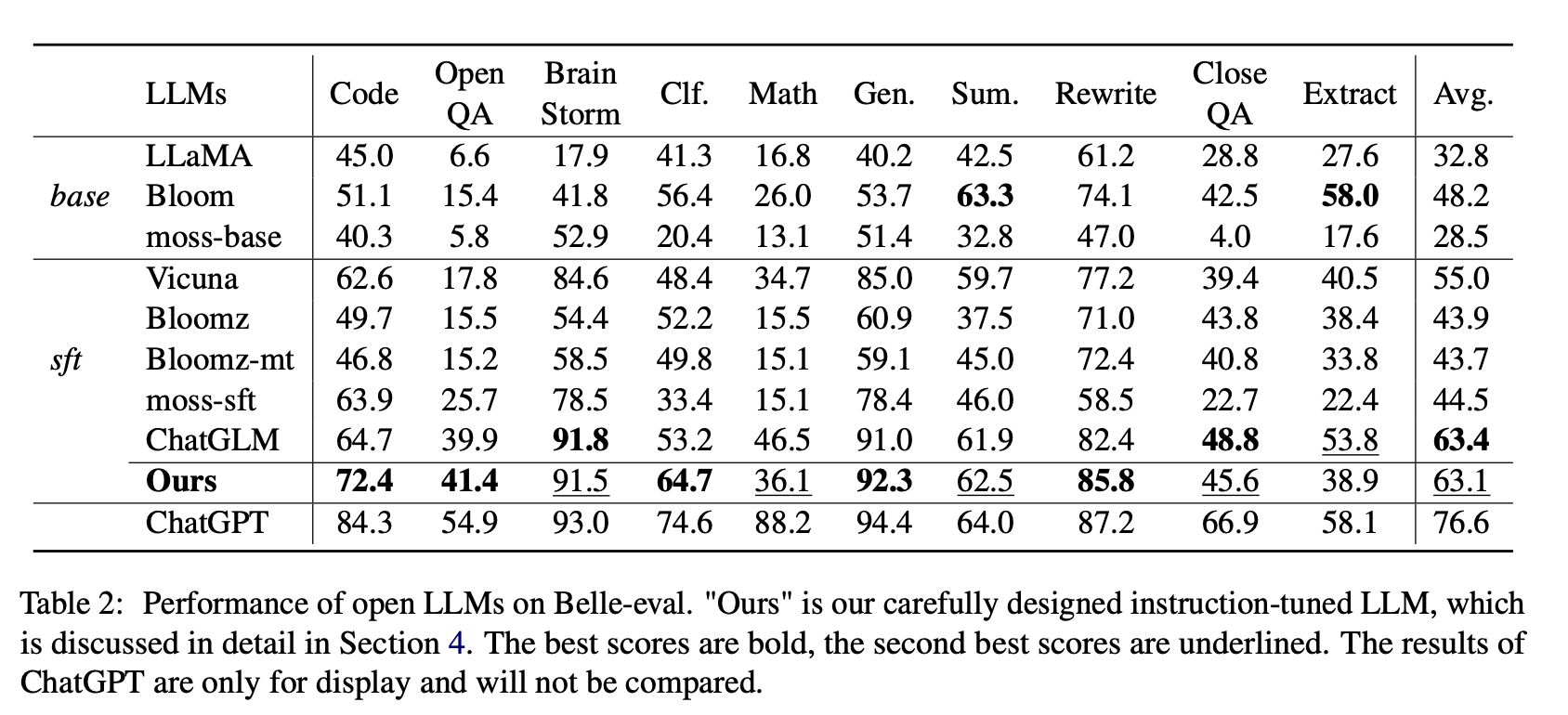
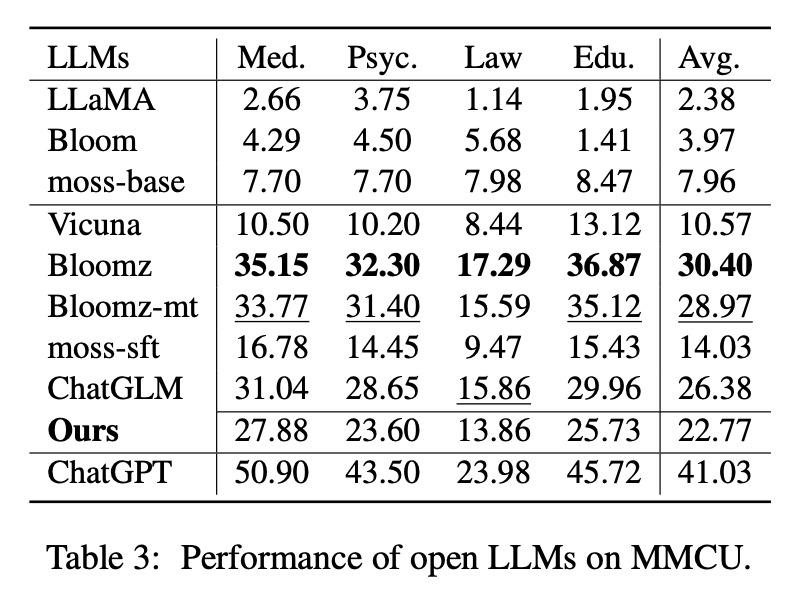
Tabelle 2 zeigt die Punktzahlen von offenen LLMs auf Belle-Eval. Tabelle 3 zeigt die Genauigkeit von LLMs auf MMCU. Sie stimmen alle offenen LLMs mit derselben parametereffizienten Methode LORA und demselben Anweisungsdatensatz Alpaka-GPT4 gut ab.
Experimentelle Ergebnisse:
Bewertung vorhandener LLMs
Leistung auf Belle-Eval
(1) Für Basis -LLMs führt Bloom das Beste aus.
(2) Für SFT LLMs übertrifft Chatglm andere durch große Ränder, dank der Tatsache, dass es mit den meisten chinesischen Token und HFRL ausgebildet ist.
(3) Die Kategorien der offenen QA, Mathematik, Closeqa und Extrakt sind für bestehende offene LLMs immer noch eine große Herausforderung.
(4) Vicuna und Moos-SFT haben klare Verbesserungen im Vergleich zu ihren Basen, Lama bzw. Moos-Base.
(5) Im Gegensatz dazu wird die Leistung von SFT-Modellen Bloomz und Bloomz-MT im Vergleich zur Basismodellblüte reduziert, da sie tendenziell eine kürzere Reaktion erzeugen.
Leistung auf MMCU
(1) Alle Basis-LLMs funktionieren schlecht, da es fast schwierig ist, Inhalte im angegebenen Format vor der Feinabstimmung, z. B. Ausgangsoptionszahlen zu erzeugen.
(2) Alle SFT -LLMs übertreffen ihre entsprechenden Basis -LLMs. Insbesondere führt Bloomz das Beste aus (sogar schlägt Chatglm), da er die Optionsnummer direkt erzeugen kann, wie dies erforderlich ist, ohne andere irrelevante Inhalte zu generieren, was auch auf die Datenmerkmale seiner überwachten Feinabstimmungsdatensatz XP3 zurückzuführen ist.
(3) Unter den vier Disziplinen ist das Gesetz für LLMs am schwierigsten.
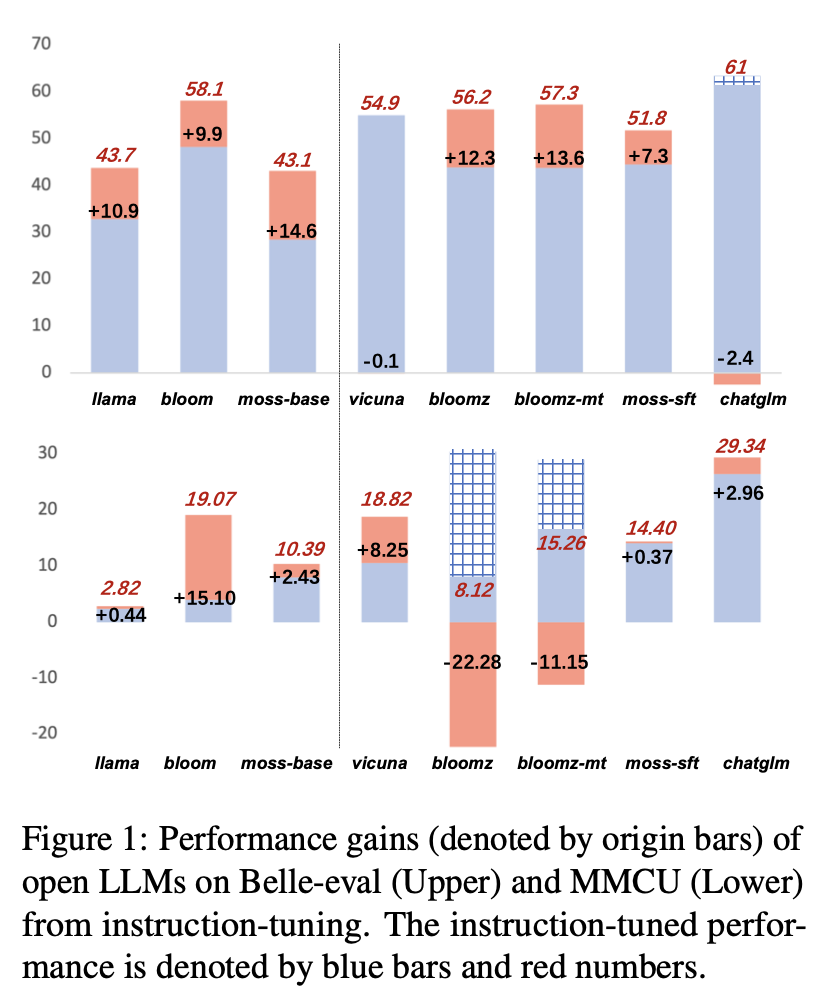
Die Leistungsergebnisse von LLMs nach Anweisungsabbau auf Alpaka-GPT4-ZH sind in Abbildung 1 dargestellt.
Unterrichtsstimmung verschiedener LLMs
(1) Bei Belle-Eval ist die Leistungsverbesserung von SFT-LLMs, die durch Anweisungsabstimmung mitgelegt wurden, nicht so signifikant wie die von Basis-LLMs, mit Ausnahme von SFT Bloomz und Bloomz-Mt.
. Chatglm nimmt HFRL an, das möglicherweise nicht mehr für weitere Anweisungsabstimmungen geeignet ist.
(3) Bei MMCU erzielen die meisten LLMs nach der Anweisungsabstimmung mit Ausnahme von Bloomz und Bloomz-MT, die die Leistung unerwartet erheblich verringert haben.
(4) Nach der Anweisungsabbau hat Bloom erhebliche Verbesserungen und hat bei beiden Benchmarks eine gute Leistung. Obwohl Chatglm konsequent blüht, erleidet es während der Anweisungsabstimmung den Leistungsverlust. Daher ist Bloom unter allen offenen LLMs in den nachfolgenden Experimenten zur Erforschung der chinesischen Unterrichtsabstimmung am besten als Grundmodell geeignet.
Für andere parametereffiziente Methoden als LORA sammelt das Papier einen Bereich von parametereffizienten Methoden, um die Anweisungsblüte auf dem Alpaca-GPT4-Datensatz zu stimmen.
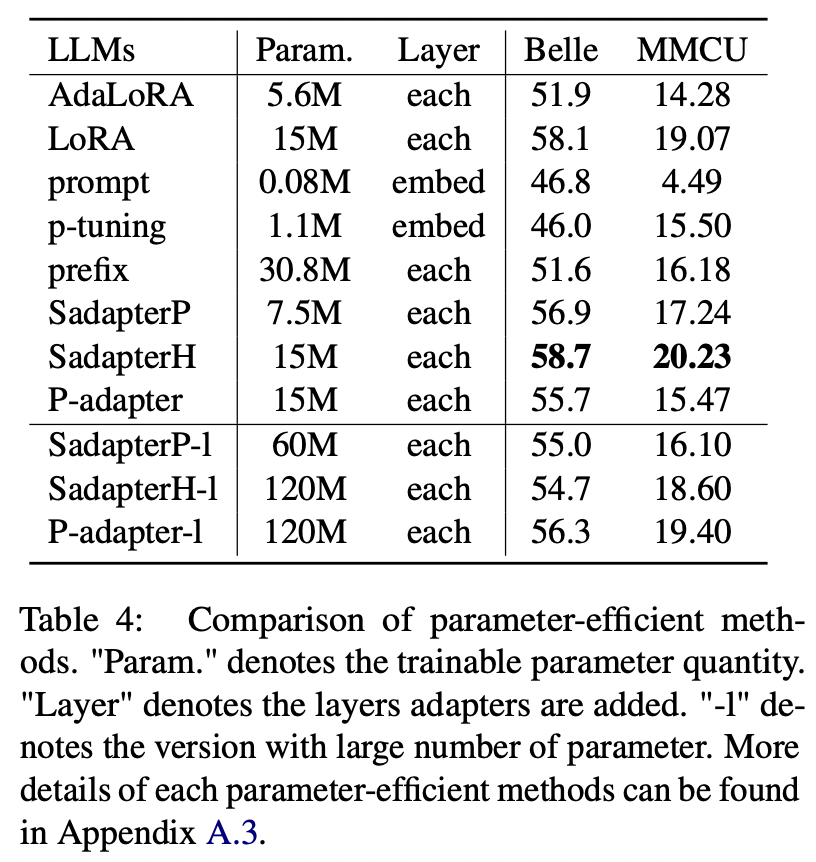
Experimentelle Ergebnisse:
Vergleich der parametereffizienten Methoden
(1) Sadapterh führt die besten unter allen parametereffizienten Methoden durch, die als Alternative zu Lora verwendet werden können.
(2) P-Tuning und schnelle Abtunigung unterdurchschnittlich andere durch große Ränder, was darauf hinweist, dass nur die Zugabe von trainierbaren Schichten in der Einbettungsschicht nicht ausreicht, um LLMs für Erzeugungsaufgaben zu unterstützen.
(3) Obwohl Adalora eine Verbesserung der Lora ist, hat seine Leistung einen klaren Rückgang, möglicherweise weil die trainierbaren Parameter der LORA für LLMs nicht zur weiteren Reduzierung geeignet sind.
(4) Vergleich der oberen und unteren Teile ist ersichtlich, dass die Erhöhung der Anzahl der trainierbaren Parameter für sequentielle Adapter (dh Sadapterp und Sadapterh) keinen Gewinn bringt, während das entgegengesetzte Phänomen für parallele Adapter beobachtet wird (dh p-Adapter)
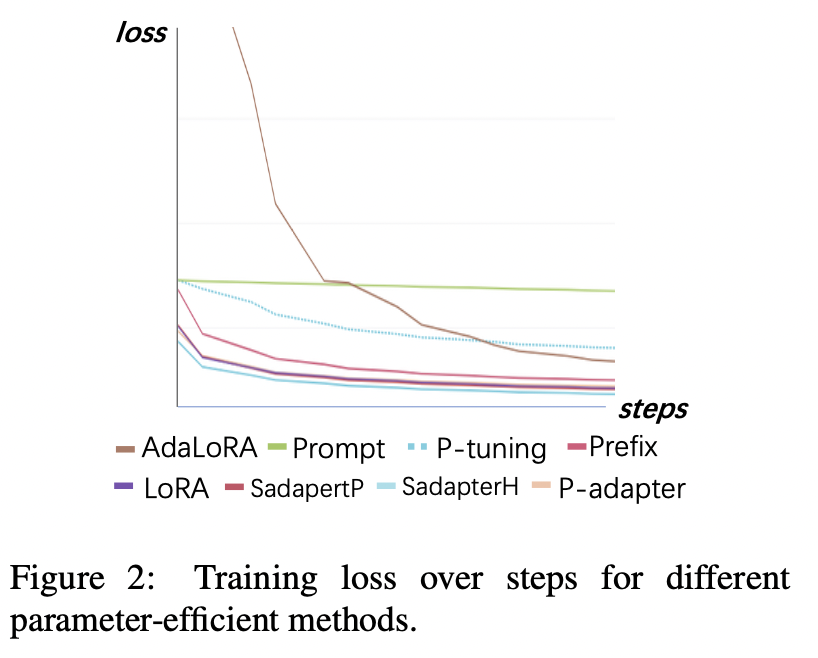
Trainingsverlust
(1) Einheitliche Abtunigung und P-Tuning konvergieren die langsamsten und weist nach Konvergenz die höchsten Verluste auf. Dies zeigt, dass Einbettungsadapter nicht für LLMs für Anweisungen geeignet sind.
.
(3) Die anderen Methoden können schnell in Trainingsdaten konvergieren und gut passen.
Für die Auswirkungen verschiedener Arten von chinesischen Unterrichtsdatensätzen sammeln Autoren beliebte offene chinesische Anweisungen (wie in Tabelle 5 gezeigt), um die Blüte mit LORA zu feinstimmen.
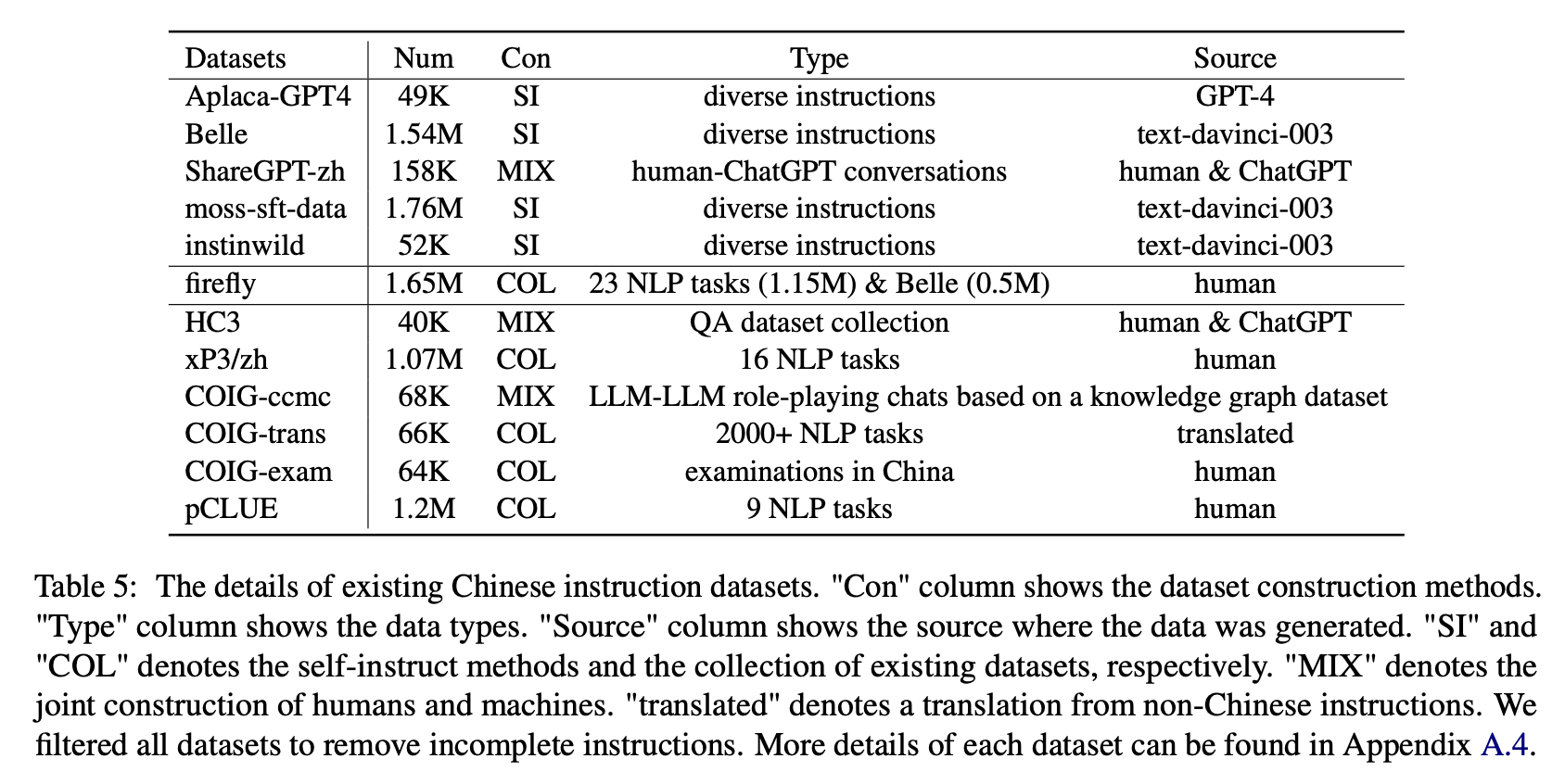
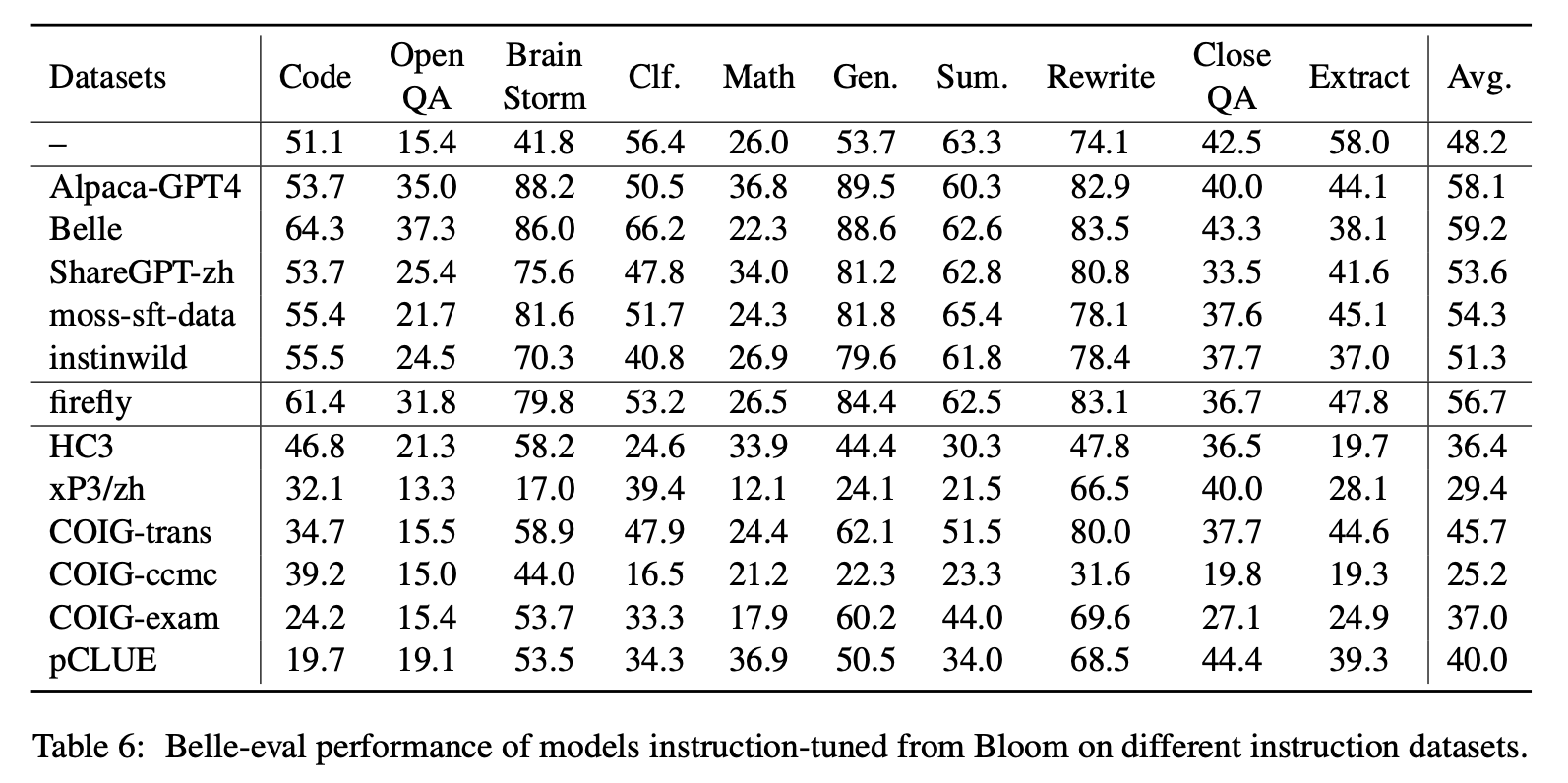
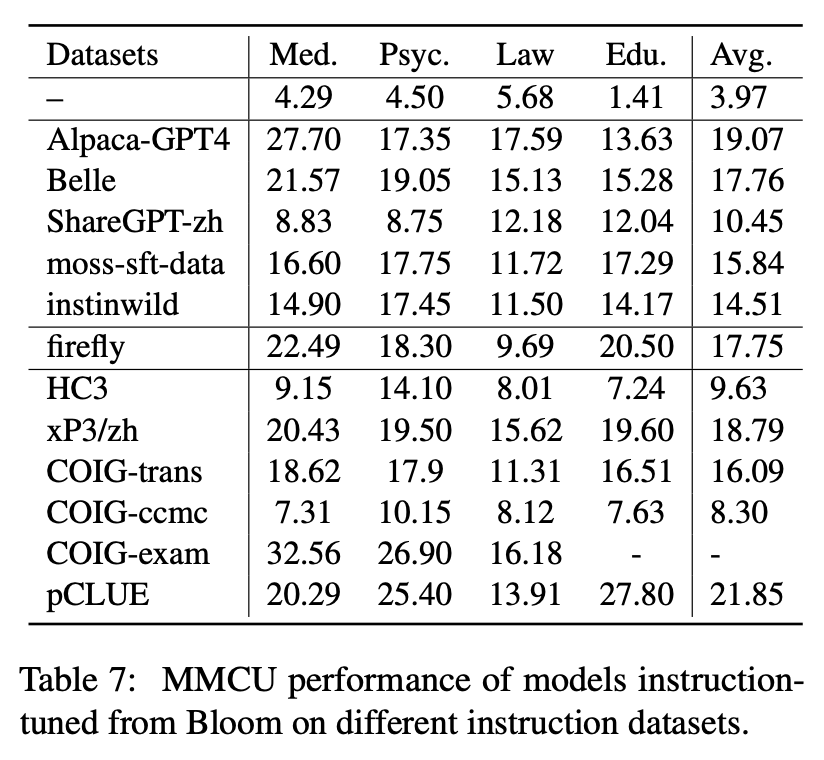
Tabelle 6 und Tabelle 7 zeigen die Feinabstimmung von Bloom in verschiedenen Befehlsdatensätzen.
Experimentelle Ergebnisse:
Leistung auf Belle-Eval
(1) Die von ChatGPT konstruierten Anweisungsdaten (z. B. mithilfe von Selbstinstruktionsmethoden oder das Sammeln realer menschlicher Chatgpt-Gespräche) verbessert die Anweisungsfähigkeit mit 3,1 ∼ 11-Punkte-Score konsequent.
(2) Unter diesen Datensätzen hat Belle aufgrund der größten Anweisungsdaten die beste Leistung. Die Leistung von Modellen, die auf Moos-STT-Daten ausgebildet sind und mehr Daten enthalten, ist unbefriedigend.
.
.
(5) Diese ChatGPT-basierten Daten haben hauptsächlich einen signifikanten Verbesserungseffekt auf Aufgaben der offenen Generation wie Hirnsturm und Generation, während es eine signifikante Abnahme der Aufgaben gibt, die hohe Leseverständnisfähigkeiten wie enge QA und Extrakt erfordern.
(6) Diese Anweisungsdatensätze verursachen Schäden an der Anweisungsfähigkeit des Modells, da die Form und Absicht jedes NLP- oder Prüfungsdatensatzes einheitlich sind, was leicht übermäßig ausgerichtet werden kann.
(7) Unter ihnen führt COIG-trans das Beste aus, da über 2000 verschiedene Aufgaben mit einer Vielzahl von Aufgabenanweisungen beteiligt sind. Im Gegensatz dazu haben XP3 und Coig-CCMC den schlimmsten negativen Einfluss auf die Modellleistung. Beide decken nur einige Arten von Aufgaben ab (Übersetzung und QS für die ersteren, kontrafaktischen Korrekturgespräche für letztere), die kaum die beliebten Anweisungen und Aufgaben für den Menschen abdecken.
Leistung auf MMCU
(1) Die Anweisungseinstellung in jedem Datensatz kann immer zu einer Leistungsverbesserung führen.
(2) Unter den im oberen Teil gezeigten ChatGPT-basierten Daten untersagt Sharegpt-Zh andere durch große Ränder. Dies kann darauf zurückzuführen sein, dass echte Benutzer selten Multiple -Choice -Fragen zu akademischen Themen stellen.
(3) Unter den im unteren Teil gezeigten Datensatz-Sammeldaten führt HC3 und COIG-CCMC zu der niedrigsten Genauigkeit, da die eindeutigen Fragen von HC3 nur 13K betragen, und das Aufgabenformat von COIG-CCMC unterscheidet sich signifikant von MMCU.
(4) Coig-Exam bringt die größte Genauigkeitsverbesserung mit sich und profitiert von dem ähnlichen Aufgabenformat wie MMCU.
Vier weitere Faktoren: COT, Expansion des chinesischen Wortschatzes, Sprache der Aufforderungen und Ausrichtung des Menschenwerts
Für COT vergleichen die Autoren die Leistung vor und nach dem Hinzufügen von COT-Daten während der Befehlsabteilung.
Experiment -Einstellungen:
Wir sammeln 9 COT -Datensätze und ihre Eingabeaufforderungen von Flan und übersetzen sie dann mit Google Translate in Chinese. Sie vergleichen die Leistung vor und nach dem Hinzufügen von COT-Daten während der Anweisungsabbau.
Beachten Sie zunächst die Möglichkeit, COT-Daten als "Alpaka-GPT4+COT" hinzuzufügen. Fügen Sie außerdem am Ende jeder Anweisung einen Satz "先思考 , 再决定" ("Schritt für Schritt" in Chinesisch zu denken, um das Modell zu induzieren, um auf Anweisungen basierend auf dem COT zu reagieren, und kennzeichnen Sie diese Weise als "Alpaka-gpt4+cot*".
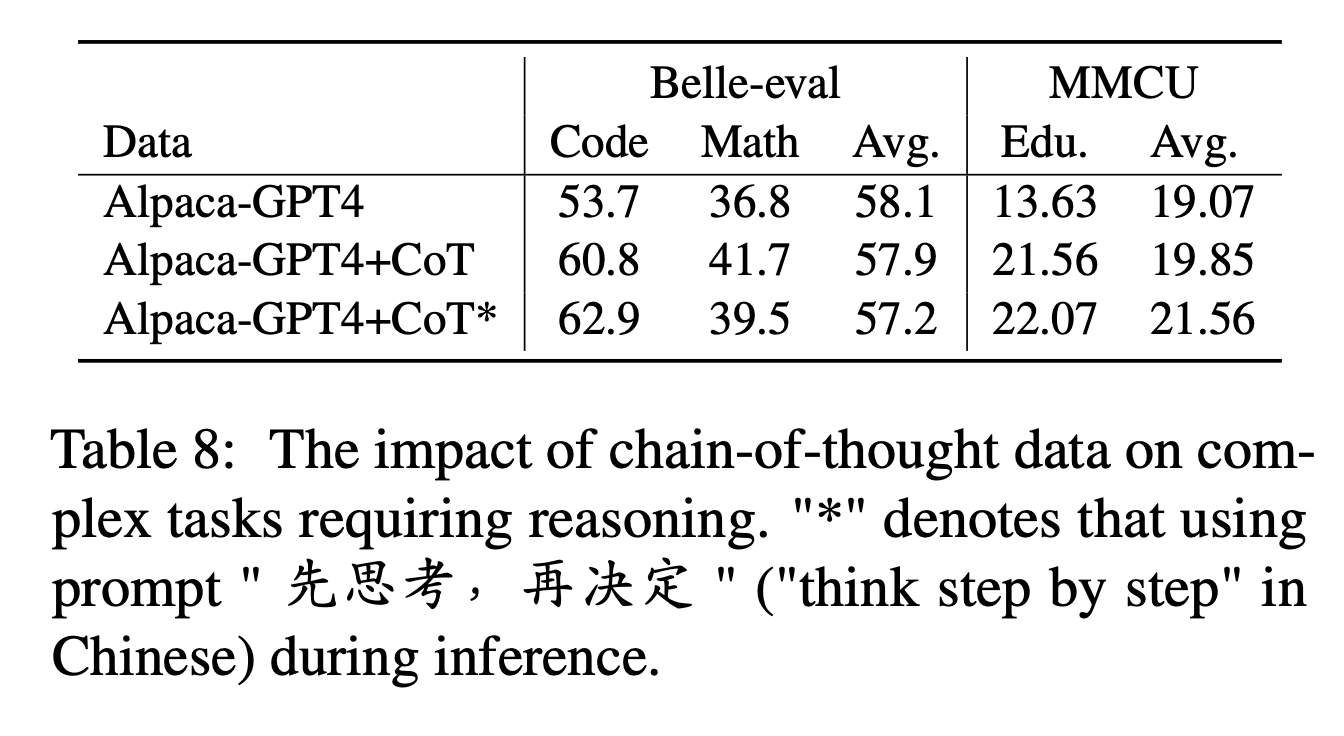
Experimentelle Ergebnisse:
"Alpaka-GPT4+COT" übertrifft "Alpaka-GPT4" in Code- und Mathematikaufgaben, die eine starke Argumentationsfähigkeit erfordern. Außerdem gibt es eine signifikante Verbesserung der MMCU -Bildungsaufgabe.
Wie in der Linie von "Alpaka-GPT4+COT*" "" COT*"gezeigt, kann der einfache Satz die Leistung von Argumentationsaufgaben Code und Bildung weiter verbessern, während die mathematische Leistung" alpaca-gpt4+cot "leicht unteren ist. Dies erfordert möglicherweise eine weitere Untersuchung robusterer Eingabeaufforderungen.
Für die Ausdehnung des chinesischen Wortschatzes testen die Autoren den Einfluss der Anzahl chinesischer Token im Vokabular des Tokenizers auf die Fähigkeit der LLMs, Chinesisch auszudrücken. Wenn sich beispielsweise ein chinesischer Charakter im Wortschatz befindet, kann es durch ein einzelnes Token dargestellt werden, da es sonst möglicherweise mehrere Token darstellt, um es darzustellen.
Experimenteinstellungen: Autoren führen hauptsächlich Experimente zu LLAMA durch, bei denen ein Satzstück (32K -Wortschatzgröße chinesischer Zeichen) verwendet wird, die weniger chinesische Zeichen als Bloom (250K) abdecken.
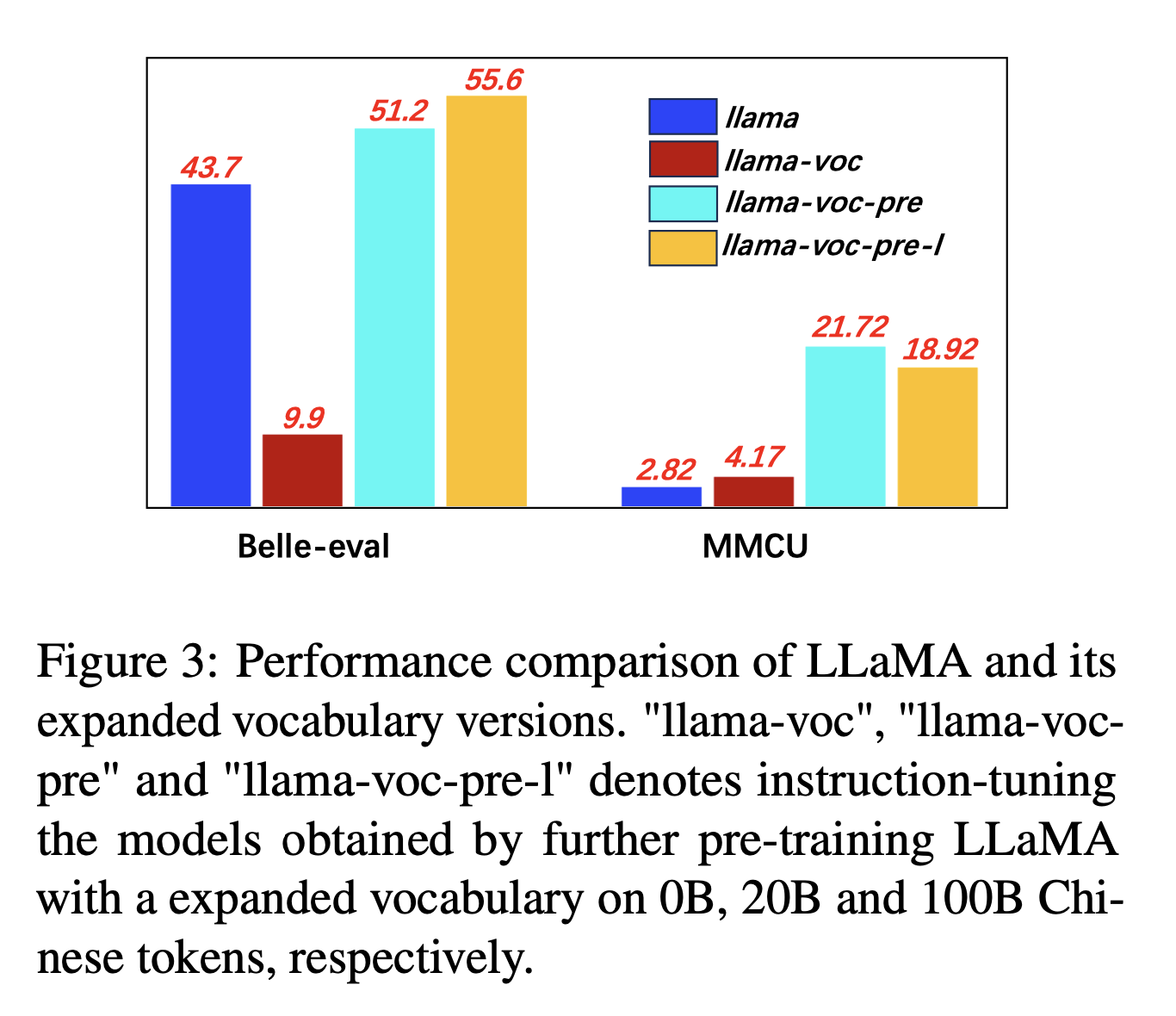
Experimentelle Ergebnisse:
Vorausbildung auf mehr chinesischem Korpus mit Ausbau des chinesischen Wortschatzes ist durchweg hilfreich für die Fähigkeit zur Anweisung.
Und Gegenintuitiv ist "Lama-voc-Pre-L" (100B) "LLAMA-VOC-PRE" (20B) auf MMCU unterlegen, was zeigt, dass die Voraussetzung auf mehr Daten möglicherweise nicht unbedingt zu einer höheren Leistung für akademische Prüfungen führt.
Für die Sprache der Eingabeaufforderungen testen die Autoren die Eignung der Befehlsfunktion für die Verwendung chinesischer Eingabeaufforderungen.
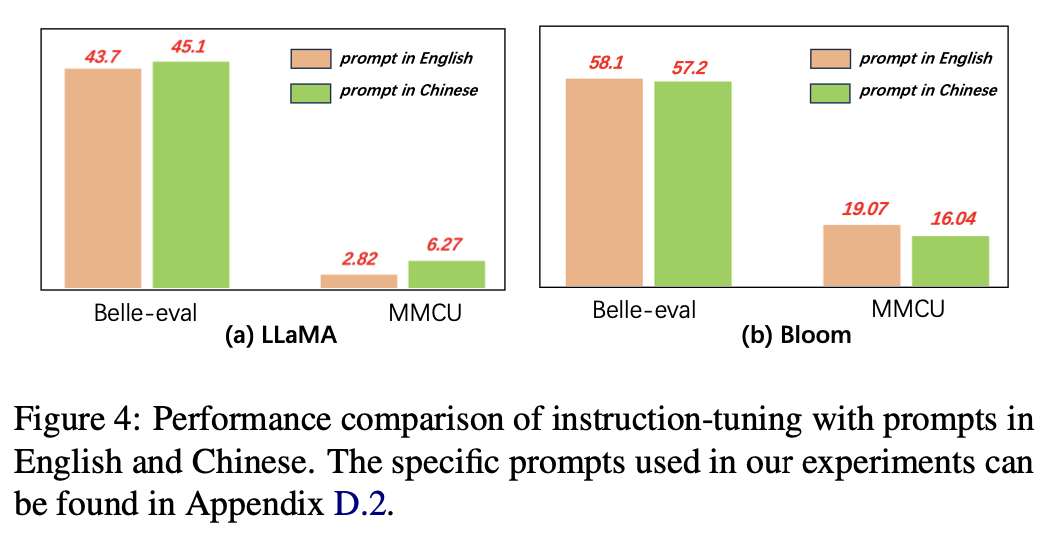
Abbildung 4 zeigt die Ergebnisse der Verwendung von chinesischen und englischen Eingaben basierend auf Lama und Blüte. Bei der Unterrichtsabstimmung kann die Verwendung chinesischer Eingaben im Vergleich zu englischen Eingaben die Leistung bei beiden Benchmarks verbessern, während das entgegengesetzte Phänomen auf der Blüte beobachtet werden kann.
Experimentelle Ergebnisse:
Für Modelle mit schwächeren chinesischen Fähigkeiten (z. B. Lama) können die Verwendung chinesischer Eingaben effektiv dazu beitragen, auf Chinesisch zu reagieren.
Für Modelle mit guten chinesischen Fähigkeiten (z. B. Bloom) kann die Verwendung von Eingabeaufforderungen in englischer Sprache (die Sprache, in der sie besser sind) das Modell besser leiten, um den Prozess der Feinabstimmung mit Anweisungen zu verstehen.
Um zu vermeiden, dass LLMs einen toxischen Gehalt erzeugen, ist es ein entscheidendes Problem, sie auf menschliche Werte auszurichten. Wir fügen Daten zur Ausrichtung des Menschen zu, die von Coig in Anweisungsabstimmungen erstellt wurden, um deren Auswirkungen zu untersuchen.
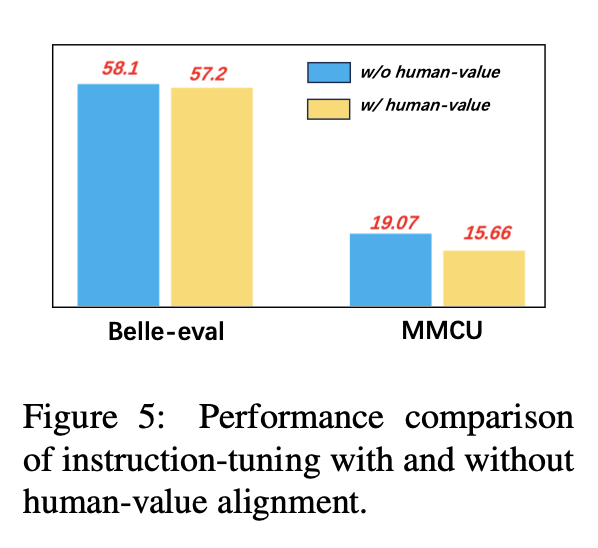
Abbildung 5 vergleicht die Ergebnisse der Anweisungseinstellung mit und ohne menschliche Wertausrichtung.
Experimentelle Ergebnisse: Die Ausrichtung des Menschen-Werts führt zu einem leichten Leistungsabfall. Wie man die Harmlosigkeit und Leistung von LLMs in Einklang bringt, ist eine Forschungsrichtung, die es wert ist, in Zukunft zu untersuchen.
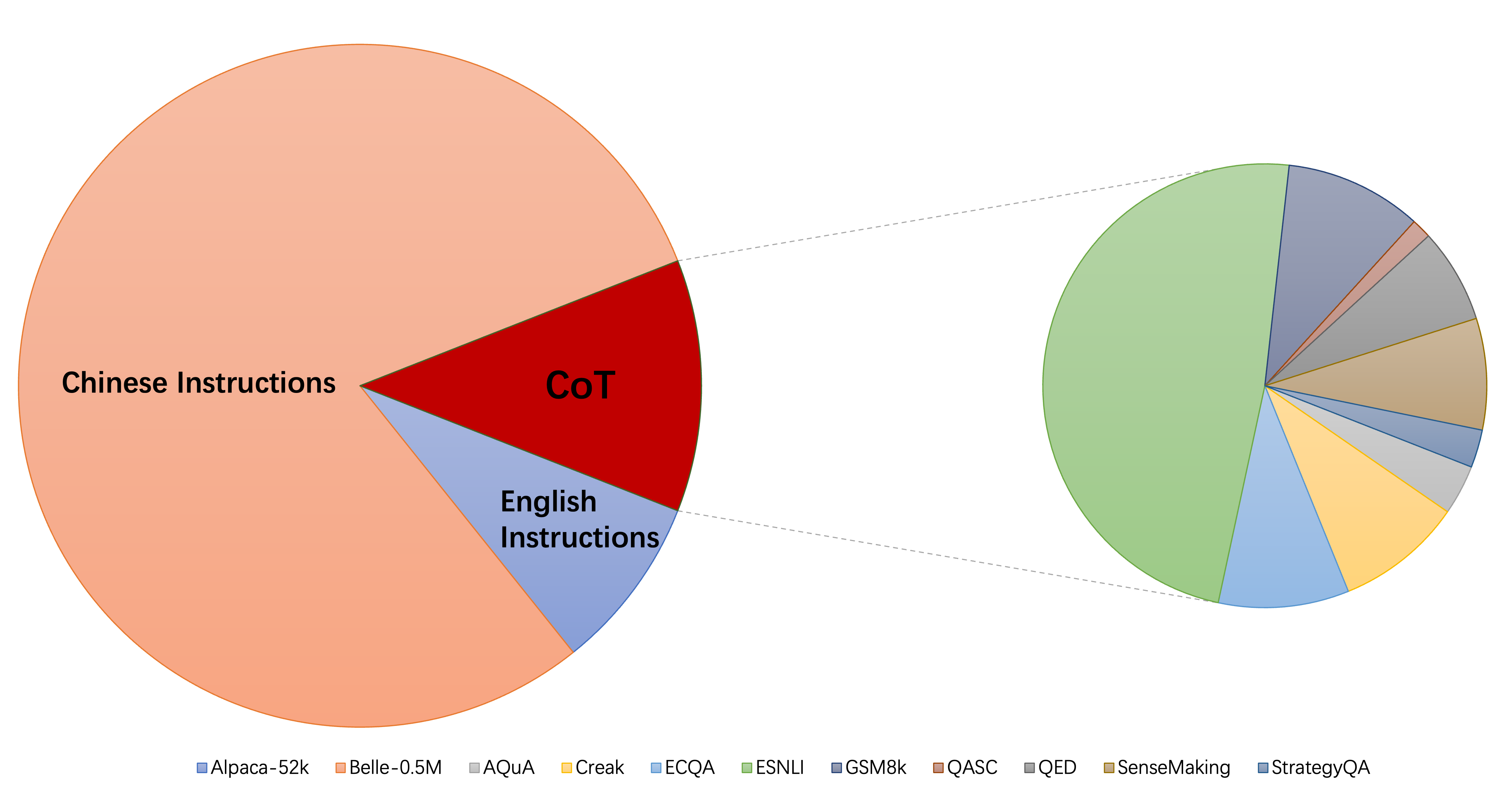 Die aktuelle Sammlung von Anweisungs-Finetuning-Datensätzen besteht hauptsächlich aus drei Teilen:
Die aktuelle Sammlung von Anweisungs-Finetuning-Datensätzen besteht hauptsächlich aus drei Teilen:
alpaca_data_cleaned.json : Über 52K Englisch-Anweisungsausbildungsmuster.CoT_data.json : 9 COT -Datensätze mit etwa 75.000 Proben. (veröffentlicht von Flan [7])belle_data_cn.json : ungefähr 0,5 m Chinesisch | Anweisungsausbildungsproben. (veröffentlicht von Belle [8]) "w/o cot" und "w/o cn" bezeichnen Modelle, die COT -Daten bzw. chinesische Anweisungen aus ihren Anweisungsfeindaten ausschließen.
"w/o cot" und "w/o cn" bezeichnen Modelle, die COT -Daten bzw. chinesische Anweisungen aus ihren Anweisungsfeindaten ausschließen.
Die obige Tabelle zeigt zwei Beispiele (die mit numerischen Berechnungen beteiligt sind), die eine bestimmte Menge an Argumentationsfähigkeit erfordern, korrekt zu reagieren. Wie in der mittleren Spalte gezeigt, erzeugt Ours w/o CoT nicht die richtige Antwort, was zeigt, dass die Argumentationsfähigkeit des Modells, sobald die Finetuning -Daten keine COT -Daten enthalten, erheblich abnimmt. Dies zeigt weiter, dass COT -Daten für LLM -Modelle von wesentlicher Bedeutung sind.

Die obige Tabelle zeigt zwei Beispiele, die die Möglichkeit erfordern, auf chinesische Anweisungen zu reagieren. Wie in der rechten Spalte gezeigt, ist entweder der generierte Inhalt Ours w/o CN unangemessen, oder die chinesischen Anweisungen werden von Ours w/o CN in englischer Sprache beantwortet. Dies zeigt, dass das Entfernen chinesischer Daten während der Finetuning dazu führt, dass das Modell chinesische Anweisungen nicht umgehen kann, und zeigt weiter, dass die Daten für die finanzielle Anweisung chinesischer Anweisungen erfasst werden müssen.

Die obige Tabelle zeigt ein relativ schwieriges Beispiel, das sowohl eine gewisse Anhäufung des Wissens über die chinesische Geschichte als auch eine logische und vollständige Fähigkeit erfordert, historische Ereignisse zu staatlich. Wie in dieser Tabelle gezeigt, können Ours w/o CN nur eine kurze und fehlerhafte Reaktion erzeugen, da aufgrund des Mangels an chinesischen Finetuning -Daten das entsprechende Wissen über die chinesische Geschichte natürlich fehlt. Obwohl Ours w/o CoT einige relevante chinesische historische Ereignisse auflistet, ist seine Ausdruckslogik selbst widersprüchlich, was durch den Mangel an COT-Daten verursacht wird. `
Zusammenfassend können die von unserem vollständigen Datensatz (englischen, chinesischen und cot -Befehlsdaten) abgeschlossenen Modelle das Modell Denken und die chinesischen Anweisungen den folgenden Fähigkeiten erheblich verbessern.
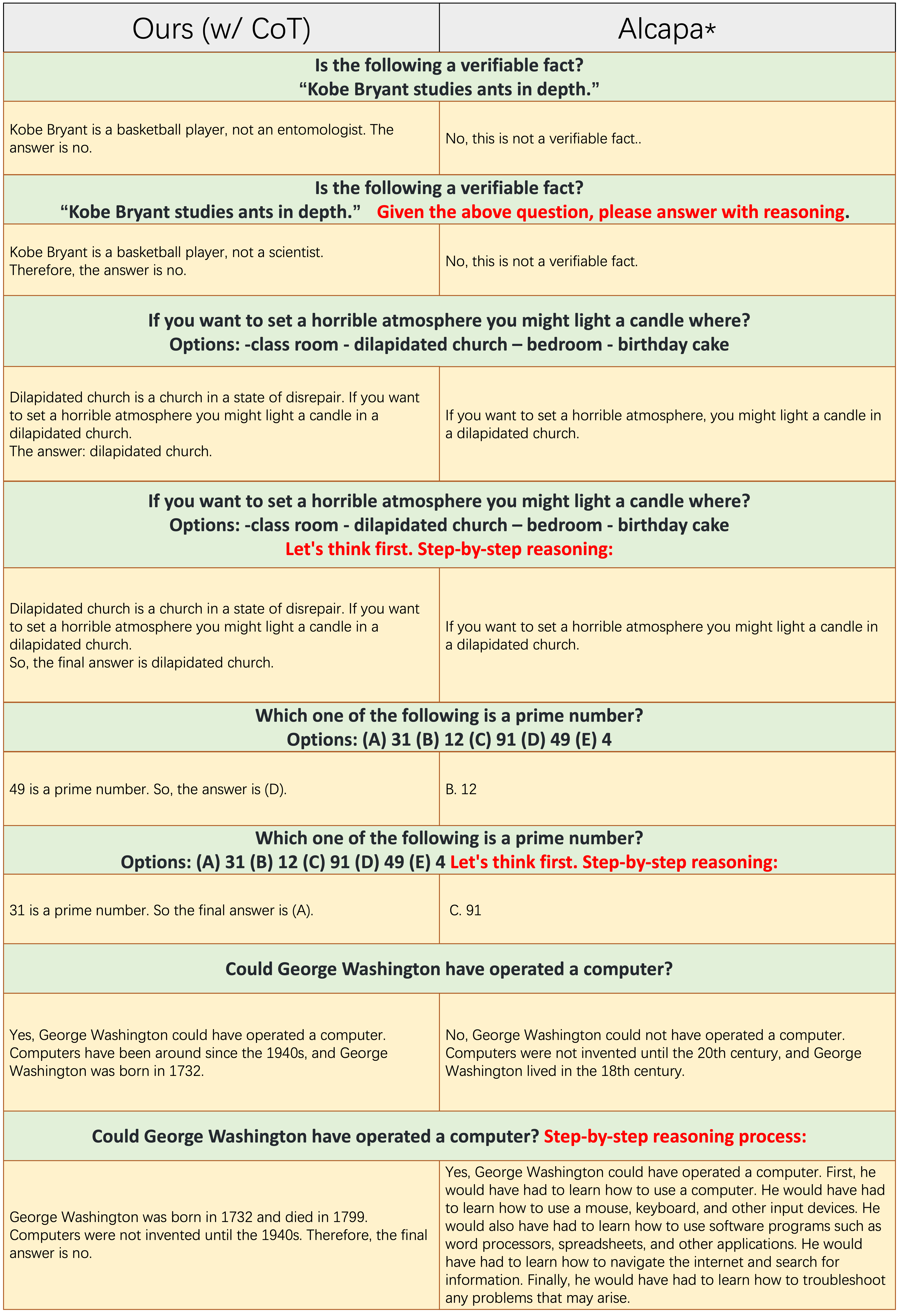 Die Proben jeder ungeraden Anzahl von Zeilen tragen die COT-Eingabeaufforderung nicht an, z. B. "Schritt-für-Schritt-Argumentation". Sowohl
Die Proben jeder ungeraden Anzahl von Zeilen tragen die COT-Eingabeaufforderung nicht an, z. B. "Schritt-für-Schritt-Argumentation". Sowohl Ours(w/CoT) als auch Alpaka basieren auf Lama-7b, und der einzige Unterschied zwischen ihnen zwei besteht darin, dass die Anweisungs-Finetuning-Daten von Ours(w/CoT) zusätzliche COT-Daten haben als die von Alpaka.
Aus der obigen Tabelle finden wir das:
Ours(w/CoT) erzeugen immer die richtige Begründung vor der Antwort, während Alpaka keine angemessene Begründung erzeugt, wie in den ersten 4 Beispielen (Commonsense -Fragen) gezeigt. Dies zeigt, dass die Verwendung von COT -Daten zur Finetuning die Argumentationsfähigkeit erheblich verbessern kann.Ours(w/CoT) hat die COT-Eingabeaufforderung (z. B. eine schrittweise "schrittweise" mit der Eingabefrage) nur geringe Auswirkungen auf einfache Beispiele (z. B. Fragen im gesunden Menschenverstand) und wirkt sich wichtig auf herausfordernde Fragen aus (z. B. Fragen, die Argumentation erfordern, wie die letzten vier Beispiele). Quantitativer Vergleich der Antworten auf chinesische Anweisungen. 
Unser Modell ist aus einem 7B -Lama über 52.000 englische Anweisungen und 0,5 m chinesische Anweisungen abgeschlossen. Stanford Alpaca (unsere Neuimplementierung) ist aus einem 7B -Lama über 52 -km -englische Anweisungen abgeschlossen. Belle ist aus einer 7B -Blüte in 2B chinesischen Anweisungen abgeschlossen.
Aus der obigen Tabelle können mehrere Beobachtungen gefunden werden:
ours (w/ CN) eine stärkere Fähigkeit, chinesische Anweisungen zu verstehen. Für das erste Beispiel unterscheidet Alpaka nicht zwischen dem instruction und input , während wir dies tun.ours (w/ CN) nicht nur den richtigen Code, sondern auch die entsprechende chinesische Annotation, während Alpaka dies nicht tut. Darüber hinaus kann Alpaka, wie in den 3-5-Beispielen gezeigt, nur auf chinesische Unterricht mit einer englischen Antwort reagieren.ours (w/ CN) bei Anweisungen, die eine offene Antwort erfordern (wie in den letzten beiden Beispielen gezeigt), noch verbessert werden. Die herausragende Leistung von Belle gegenüber solchen Anweisungen ist auf: 1. Das Blüte-Rückgrat-Modell auf viel mehr mehrsprachige Daten während der Vorausbildung zu finden; 2. Seine chinesischen Unterrichtsfonetuning -Daten sind mehr als unsere, dh 2m gegenüber 0,5 m. Quantitativer Vergleich der Antworten zu englischen Anweisungen. Der Zweck dieses Unterabschnitts besteht darin, zu untersuchen, ob die Finetuning für chinesische Anweisungen negativ auf Alpaka auswirkt. 
Aus der obigen Tabelle finden wir das:
ours (w/ CN) zeigt mehr Details als die von Alpaka, z. B. für das dritte Beispiel, ours (w/ CN) drei weitere Provinzen als Alpaka. Bitte zitieren Sie das Repo, wenn Sie die Datenerfassung, den Code und die experimentellen Ergebnisse in diesem Repo verwenden.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
Für Daten und Modelle zitieren bitte die Originaldaten, die parametereffizienten Methoden und die LLMS-Quelle.
Wir möchten Apus Ailme Lab unser besonderes Dank ausdrücken, wenn wir den 8 A100 -GPUs für die Experimente gesponsert haben.
(zurück nach oben)


