Alpaca CoT
1.0.0
中文| إنجليزي

هذا هو المستودع لمشروع Alpaca-CoT ، الذي يهدف إلى إنشاء منصة للتعليمات (IFT) مع مجموعة تعليمات واسعة النطاق (وخاصة مجموعات بيانات COT) وواجهة موحدة لمختلف نماذج اللغة الكبيرة وطرق المعلمة. نقوم باستمرار بتوسيع نطاق جمع بيانات تعليماتنا ، ودمج المزيد من LLMs وطرق أكثر كفاءة في الكفاءة. بالإضافة إلى ذلك ، أنشأنا فرعًا جديدًا tabular_llm لإنشاء LLM جدولي لحل مهام ذكاء الجدول.
نرحب بحرارة بتزويدنا بأي مجموعات بيانات غير متعلقة بالتعليمات (أو مصادرها). سنقوم بتنسيقهم بشكل موحد ، وندرب نموذج الألبكة (وغيرها من LLMs في المستقبل المبكرة) مع مجموعات البيانات هذه ، ومفتوح المصدر نقاط التفتيش النموذجية ، وإجراء دراسات تجريبية واسعة النطاق. نأمل أن يتمكن مشروعنا من تقديم مساهمة متواضعة في العملية المفتوحة للمصدر لنماذج اللغة الكبيرة ، وأن يقلل من عتبة الباحثين في NLP للبدء.

إذا كنت ترغب في استخدام طرق أخرى إلى جانب Lora ، فيرجى تثبيت الإصدار المعدل في Project pip install -e ./peft .
12.8: تم دمج LLM InternLM .
8.16: 4bit quantization متاحة لـ lora و qlora و adalora .
8.16: تم دمج أساليب Qlora الموفرة Sequential adapter Parallel adapter .
7.24: تم دمج LLM ChatGLM v2 .
7.20: تم دمج LLM Baichuan .
6.25: إضافة رمز تقييم النموذج ، بما في ذلك Belle و MMCU.
GPT4Tools ، Auto CoT ، pCLUE إضافة.tabular_llm لإنشاء LLM جدولي. نقوم بجمع بيانات صياغة تعليمات للمهام المتعلقة بالجدول مثل الإجابة على أسئلة الجدول واستخدامها لضبط LLMs في هذا الريبو.MOSS .GAOKAO ، camel ، FLAN-Muffin ، COIG وتنسيقها.webGPT ، dolly ، baize ، hh-rlhf ، OIG(part) يتم جمعها وتنسيقها.multi-turn conversation بواسطة paulcx.firefly ، instruct ، يتم جمع وتنسيق Code Alpaca وتنسيقها ، والتي يمكن العثور عليها هنا.Parameter merging الوظائف المضافة ، Local chatting ، Batch predicting Web service building بواسطة Weberr.GPTeacher ، Guanaco ، HC3 ، prosocial-dialog ، belle-chat&belle-math ، xP3 natural-instructions وتنسيقها.CoT_CN_data.json هنا. 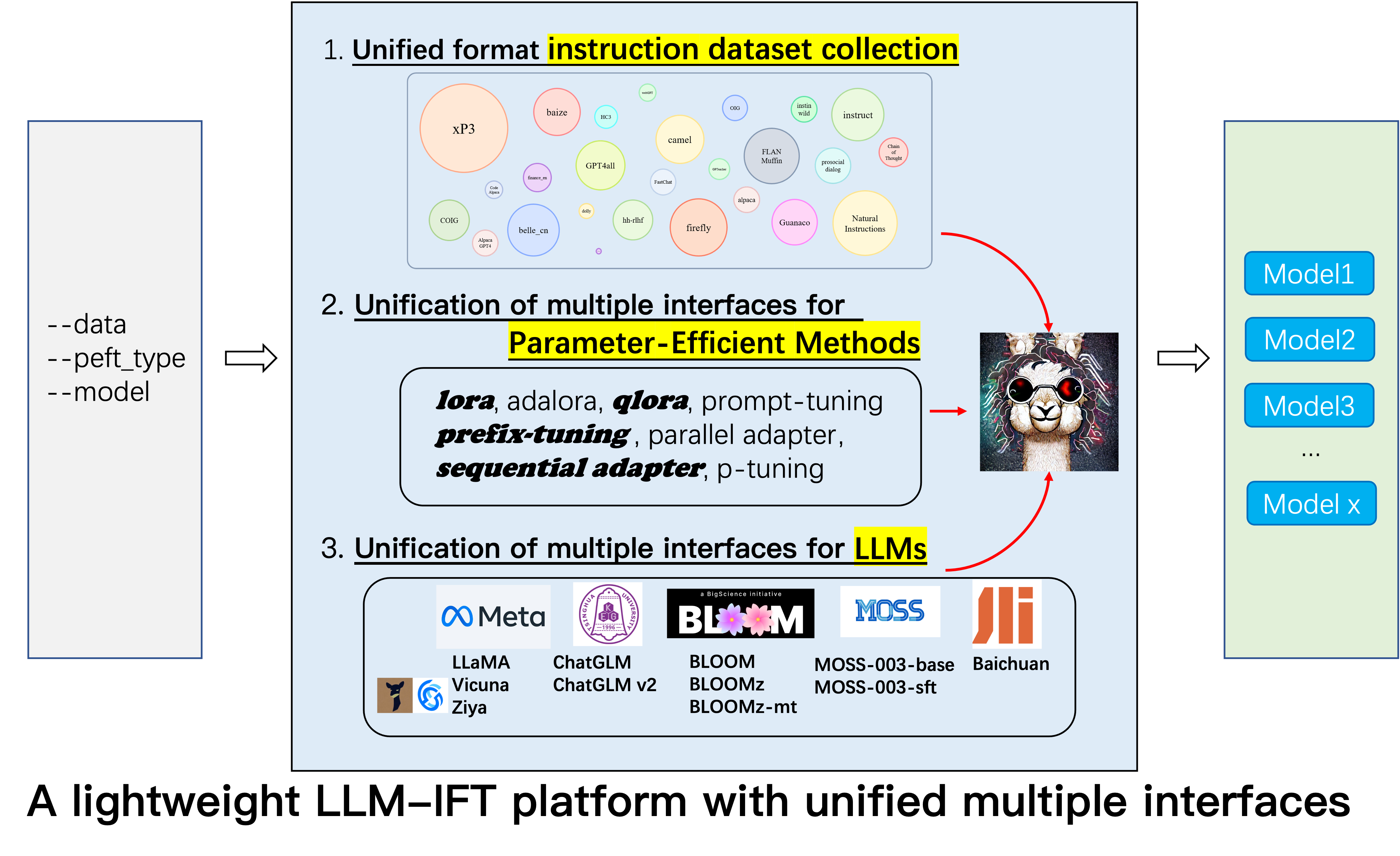
Llama [1] هو عمل رائع يوضح القدرة الصفر المذهلة وقدرة قليلة. إنه يقلل بشكل كبير من تكلفة التدريب ، والتحديد ، واستخدام نماذج اللغة الكبيرة التنافسية ، IE ، LLAMA-13B يتفوق على GPT-3 (175B) و LLAMA-65B تنافسية مع PALM-540B. في الآونة الأخيرة ، لتعزيز قدرة متابعة التعليمات في LLAMA ، Stanford Alpaca [2] LAMA-7B على بيانات 52K تتبع التعليمات التي تم إنشاؤها بواسطة تقنيات التقنية الذاتية [3]. ومع ذلك ، في الوقت الحالي ، لا يزال مجتمع أبحاث LLM يواجه ثلاثة تحديات: 1. حتى LLAMA-7B لا يزال لديه متطلبات عالية للحوسبة ؛ 2. هناك عدد قليل من مجموعات البيانات مفتوحة المصدر للتعليمات. و 3. هناك نقص في دراسة تجريبية حول تأثير أنواع مختلفة من التعليمات على قدرات النموذج ، مثل القدرة على الاستجابة للتعليم الصيني وتفكير المهد.
تحقيقًا لهذه الغاية ، نقترح هذا المشروع ، الذي يستفيد من التحسينات المختلفة التي تم اقتراحها لاحقًا ، مع المزايا التالية:
7b و 13b و 30b من نماذج Llama بسهولة على 80G A100. على حد علمنا ، هذا العمل هو أول من يدرس التفكير في سرير الأطفال على أساس لاما والألباكا. لذلك ، فإننا نختصر عملنا إلى Alpaca-CoT .
يمكن عرض الحجم النسبي لمجموعات البيانات التي تم جمعها بواسطة هذا الرسم البياني:
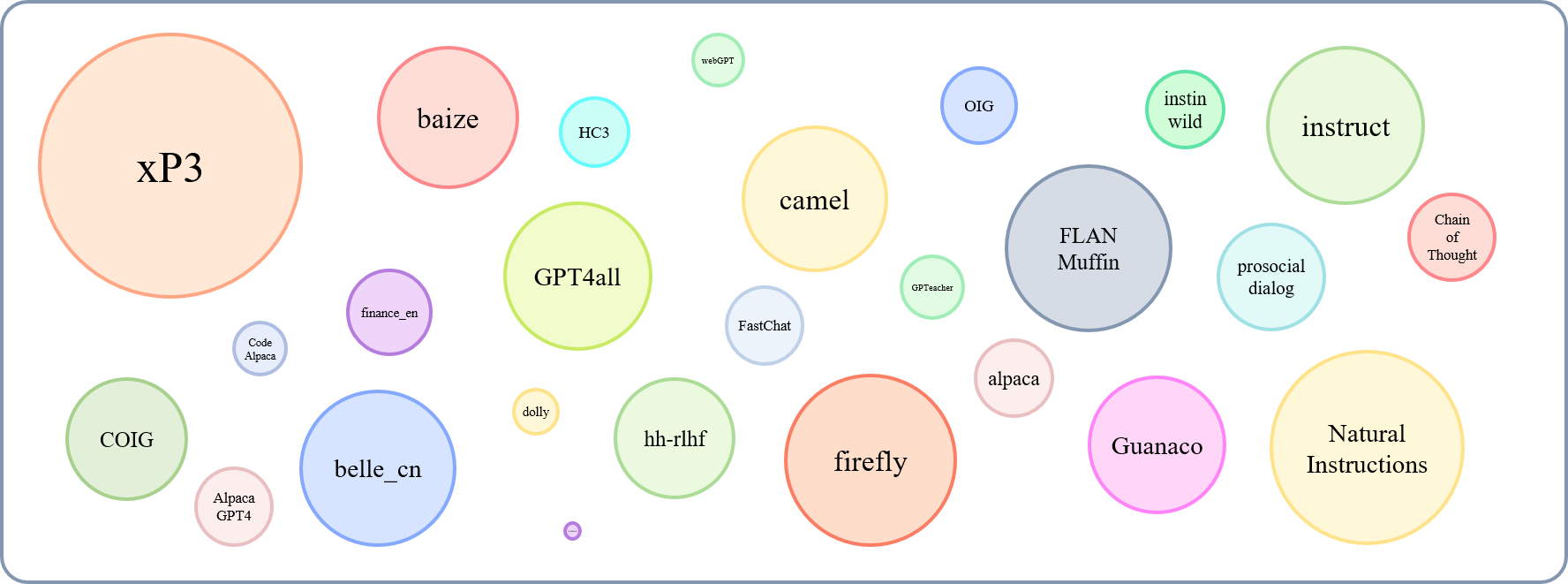
بالإشارة إلى هذا (@yaodongc) ، وصفنا كل مجموعة بيانات تم جمعها وفقًا للقواعد التالية:
(لانج) العلامات اللغوية:
(مهمة) علامات المهام:
(الجنرال) جيل-ميثود:
| مجموعة البيانات | أرقام | لانغ | مهمة | الجنرال | يكتب | SRC | عنوان URL |
|---|---|---|---|---|---|---|---|
| سلسلة من الفكر | 74771 | en/cn | MT | زئبق | تعليمات مع سرير الأطفال | التعليق على سرير الأطفال على البيانات الموجودة | تحميل |
| GPT4ALL | 806199 | en | MT | العقيد | رمز وقصص وحوار | التقطير من GPT-3.5 توربو | تحميل |
| GPTEACHER | 29013 | en | MT | سي | عام ، لعب الأدوار ، Toolformer | GPT-4 & Toolformer | تحميل |
| جواناكو | 534610 | مل | MT | سي | مهام لغوية مختلفة | نص davinci-003 | تحميل |
| HC3 | 37175 | en/cn | TS | مزج | تقييم الحوار | الإنسان أو شاتغبت | تحميل |
| الألبكة | 52002 | en | MT | سي | تعليمات عامة | نص davinci-003 | تحميل |
| التعليمات الطبيعية | 5040134 | مل | MT | العقيد | مهام NLP متنوعة | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| belle_cn | 1079517 | CN | TS/MT | سي | التفكير العام ، المنطق الرياضي ، الحوار | نص davinci-003 | تحميل |
| Instinwild | 52191 | en/cn | MT | سي | الجيل ، المفتوح QA ، عاصفة العقل | نص davinci-003 | تحميل |
| مربع حوار اجتماعي | 165681 | en | TS | مزج | حوار | يعيد GPT-3 إعادة كتابة الأسئلة + التعليقات البشر يدويًا | تحميل |
| finance_en | 68912 | en | TS | العقيد | QA المالي | GPT3.5 | تحميل |
| XP3 | 78883588 | مل | MT | العقيد | مجموعة من المطالبات ومجموعات البيانات عبر 46 من اللغات و 16 مهمة NLP | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| يراعة | 1649398 | CN | MT | العقيد | 23 مهام NLP | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| إرشاد | 888969 | en | MT | العقيد | معزز من GPT4ALL ، الألبكة ، مجموعات بيانات ميتا مفتوحة المصدر | تم إجراء زيادة باستخدام أدوات NLP المتقدمة التي توفرها Allenai | تحميل |
| رمز الألبكة | 20022 | en | TS | سي | توليد الكود ، التحرير ، التحسين | نص davinci-003 | تحميل |
| alpaca_gpt4 | 52002 | en/cn | MT | سي | تعليمات عامة | تم إنشاؤه بواسطة GPT-4 باستخدام الألبكة | تحميل |
| webgpt | 18994 | en | TS | مزج | استرجاع المعلومات (IR) QA | GPT-3 ، كل تعليمة تم ضبطها ، كل تعليمة لها مخرجان ، حدد واحد أفضل | تحميل |
| دوللي 2.0 | 15015 | en | TS | زئبق | QA مغلق ، تلخيص وما إلى ذلك ، ويكيبيديا كمراجع | مشروح الإنسان | تحميل |
| بايز | 653699 | en | MT | العقيد | مجموعة من أسئلة الألبكة والكورا و Stackoverflow و Medquad | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| HH-RLHF | 284517 | en | TS | مزج | حوار | مربع حوار بين نماذج الإنسان و RLHF | تحميل |
| OIG (جزء) | 49237 | en | MT | العقيد | تم إنشاؤها من مختلف المهام ، مثل السؤال والإجابة | باستخدام زيادة البيانات ، جمع مجموعات البيانات المشروحة البشرية | تحميل |
| غوكاو | 2785 | CN | MT | العقيد | أسئلة متعددة الخيارات ، ملء الفراغ والمفتوحة من الفحص | مشروح الإنسان | تحميل |
| جمل | 760620 | en | MT | سي | محادثات لعب الأدوار في مجتمع الذكاء الاصطناعي ، الكود ، الرياضيات ، الفيزياء ، الكيمياء ، البيولوجي | GPT-3.5 توربو | تحميل |
| flan-muffin | 1764800 | en | MT | العقيد | 60 مهام NLP | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| Coig (flaginstruct) | 298428 | CN | MT | العقيد | اجمع امتحان FRON ، تعليمات محاذاة القيمة البشرية المترجمة ، والتصحيح المضاد للتصحيح متعدد الدورات | استخدام الأداة التلقائية والتحقق اليدوي | تحميل |
| GPT4Tools | 71446 | en | MT | سي | مجموعة من الإرشادات المتعلقة بالأدوات | GPT-3.5 توربو | تحميل |
| Sharechat | 1663241 | en | MT | مزج | تعليمات عامة | التعهيد الجماعي لجمع المحادثات بين الأشخاص و ChatGPT (ShareGPT) | تحميل |
| سرير السيارات | 5816 | en | MT | العقيد | الحساب ، المنطقية ، مهام التفكير المنطقي وغيرها من المهام المنطقية | مجموعة مجموعات البيانات المشروحة البشرية | تحميل |
| طحلب | 1583595 | en/cn | TS | سي | تعليمات عامة | نص davinci-003 | تحميل |
| Ultrachat | 28247446 | en | أسئلة حول العالم والكتابة والخلق والمساعدة على المواد الموجودة | اثنان منفصل GPT-3.5 توربو | تحميل | ||
| صينية طبية | 792099 | CN | TS | العقيد | أسئلة حول المشورة الطبية | الزحف | تحميل |
| CSL | 396206 | CN | MT | العقيد | توليد نص الورق ، استخراج الكلمات الرئيسية ، تلخيص النص وتصنيف النص | الزحف | تحميل |
| PCLUE | 1200705 | CN | MT | العقيد | تعليمات عامة | تحميل | |
| news_commentary | 252776 | CN | TS | العقيد | يترجم | تحميل | |
| Stackllama | تودو | en |
يمكنك تنزيل جميع البيانات المنسقة هنا. ثم يجب عليك وضعها في مجلد البيانات.
يمكنك تنزيل جميع نقاط التفتيش المدربة على أنواع مختلفة من بيانات التعليمات من هنا. بعد ذلك ، بعد تعيين LoRA_WEIGHTS (في generate.py ) إلى المسار المحلي ، يمكنك تنفيذ استنتاج النموذج مباشرة.
يتم تنسيق جميع البيانات الموجودة في مجموعتنا في نفس القوالب ، حيث تكون كل عينة كما يلي:
[
{"instruction": instruction string,
"input": input string, # (may be empty)
"output": output string}
]
لاحظ أنه بالنسبة لمجموعات بيانات COT ، نستخدم أولاً القالب الذي توفره Flan لتغيير مجموعة البيانات الأصلية إلى أشكال سلسلة من الأفضل ، ثم تحويله إلى التنسيق أعلاه. يمكن العثور على نص تنسيق هنا.
pip install -r requirements.txt
لاحظ ذلك ، تأكد من Python> = 3.9 عند chatglm finetuning.
PEFT
pip install -e ./peft
لكي يقوم الباحثون بإجراء أبحاث IFT المنهجية على LLMS ، قمنا بجمع أنواع مختلفة من بيانات التعليمات ، و LLMs متعددة ، وواجهات موحدة ، مما يجعل من السهل تخصيص التجميع المطلوب:
--model_type : اضبط LLM الذي تريد استخدامه. حاليًا ، يتم دعم [Llama ، ChatGlm ، Bloom ، Moss]. الأخيرين لهما قدرات صينية قوية ، وسيتم دمج المزيد من LLMs في المستقبل.--peft_type : اضبط PEFT الذي تريد استخدامه. حاليًا ، يتم دعم [Lora ، Adalora ، ضبط البادئة ، ضبط P ، موجه].--data : قم بتعيين نوع البيانات المستخدم لـ IFT لتكييف قدرة امتثال الأوامر المرونة بمرونة. على سبيل المثال ، من أجل القدرة القوية على التفكير ، قم بتعيين "alpaca-cot" ، من أجل القدرة الصينية القوية ، وضع "Belle1.5m" ، من أجل توليد الترميز وتوليد القصة ، وضع "GPT4ALL" ، وللحصول على قدرة الاستجابة المالية ذات الصلة ، تعيين "التمويل".--model_name_or_path : تم تعيين هذا لتحميل إصدارات مختلفة من أوزان النموذج للهدف LLM --model_type . على سبيل المثال ، لتحميل إصدار LLAMA 13B من الأوزان ، يمكنك تعيين Decapoda-Research/Llama-13B-HF.وحدة معالجة الرسومات المفردة
python3 uniform_finetune.py --model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
ملاحظة: بالنسبة لمجموعات البيانات المتعددة ، يمكنك استخدام --data مثل --data ./data/alpaca.json ./data/finance.json <path2yourdata_1>
python3 uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
لاحظ أن load_in_8bit غير مناسب بعد لـ ChatGLM ، لذلك يجب أن يكون Batch_size أصغر من غيرها.
python3 uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 uniform_finetune.py ---model_type moss --model_name_or_path fnlp/moss-moon-003-sft
--data alpaca --lora_target_modules q_proj v_proj --per_gpu_train_batch_size 1
--learning_rate 3e-4 --epochs 3
python3 uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
لاحظ أنه يمكنك أيضًا تمرير المسار المحلي (حيث يتم حفظ أوزان LLM) إلى --model_name_or_path . ويمكن ضبط نوع البيانات --data بحرية وفقًا لمصالحك.
وحدات معالجة الرسومات المتعددة
torchrun --nnodes 1 --nproc_per_node $ngpu uniform_finetune.py $args --data $data python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy uniform_finetune.py
--model_type llama --model_name_or_path decapoda-research/llama-7b-hf
--data alpaca-belle-cot --lora_target_modules q_proj v_proj
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type chatglm --model_name_or_path THUDM/chatglm-6b
--data alpaca-belle-cot --lora_target_modules query_key_value
--lora_r 32 --lora_alpha 32 --lora_dropout 0.1 --per_gpu_train_batch_size 2
--learning_rate 2e-5 --epochs 1
لاحظ أن load_in_8bit غير مناسب بعد لـ ChatGLM ، لذلك يجب أن يكون Batch_size أصغر من غيرها.
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type bloom --model_name_or_path bigscience/bloomz-7b1-mt
--data alpaca-belle-cot --lora_target_modules query_key_value
--per_gpu_train_batch_size 4 --learning_rate 3e-4 --epochs 1
python3 -m torch.distributed.launch --nproc_per_node 4
--nnodes=1 --node_rank=0 --master_addr=xxx --master_port=yyy
uniform_finetune.py --model_type internlm --model_name_or_path internlm/internlm-7b
--data alpaca --lora_target_modules q_proj v_proj --lora_r 32 --lora_alpha 32
--lora_dropout 0.1 --per_gpu_train_batch_size 1 --learning_rate 2e-5 --epochs 1
--compute_dtype="fp32"
python3 generate.py --data alpaca-belle-cot --model_type llama
python3 generate.py --data alpaca-belle-cot --model_type chatglm
python3 generate.py --data alpaca-belle-cot --model_type bloom
يمكن العثور على مزيد من تفاصيل التعليمات المعيارية والاستدلال هنا من حيث قمنا بتعديلها. لاحظ أن المجلدات saved-xxx7b هي المسار حفظ أوزان Lora ، ويتم تنزيل أوزان Llama تلقائيًا من Hugging Face.
top_p=0.9,
#Moderately increase the probability threshold of nucleus sampling to increase the quantity of candidate tokens and increase generation diversity.
temperature=1.0,
#The previous low temperature parameter could lead to a severe polarization in the probability distribution of generated words, which degenerates the generation strategy into greedy decoding.
do_sample=True,
#do_sample parameter is set to False by default. After setting to True, the generation methods turn into beam-search multinomial sampling decoding strategy.
no_repeat_ngram_size=6,
#Configure the probability of the next repeating n-gram to 0, to ensure that there are no n-grams appearing twice. This setting is an empirical preliminary exploration.
repetition_penalty=1.8,
#For words that have appeared before, in the subsequent prediction process, we reduce the probability of their reoccurrence by introducing the repetition_penalty parameter. This setting is an empirical preliminary exploration.
python3 merge.py --model_type llama --size 7b --lora_dir xxx --merged_dir yyy
python3 server.py --model_type chatglm --size 6b --lora_dir xxx
python3 predict.py --model_type chatglm --size 6b --data for_dict_data --lora_dir xxx --result_dir yyy
python3 web.py --model_type chatglm --size 6b --lora_dir xxx
تختار هذه الورقة معايير التقييم ، Belle-Eval و MMCU ، لتقييم كفاءات LLM بشكل شامل باللغة الصينية.
تم بناء Belle-eval بواسطة بنية ذاتية مع ChatGPT ، والتي لديها 1000 تعليمات متنوعة تتضمن 10 فئات تغطي مهام NLP الشائعة (على سبيل المثال ، QA) والمهام الصعبة (على سبيل المثال ، الكود والرياضيات). نستخدم chatgpt لتقييم الاستجابات النموذجية بناءً على الإجابات الذهبية. يعتبر هذا المعيار بمثابة تقييم قدرة AGI (تتبع التعليمات).
MMCU هي مجموعة من أسئلة الاختيار الصيني من متعدد في أربعة تخصصات مهنية للطب والقانون وعلم النفس والتعليم (على سبيل المثال ، امتحان Gaokao). إنها تتيح LLMs لإجراء الامتحانات في المجتمع البشري بطريقة اختبار متعدد الخيارات ، مما يجعلها مناسبة لتقييم اتساع وعمق المعرفة من LLMs عبر تخصصات متعددة.
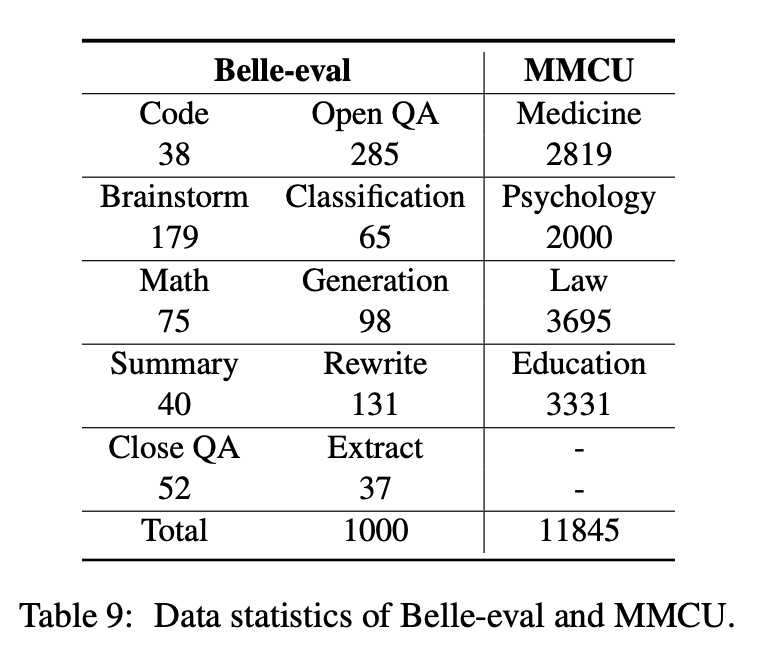
يتم عرض إحصائيات البيانات من Belle-eval و MMCU في الجدول أعلاه.
نقوم بإجراء تجارب لدراسة العوامل الرئيسية الثلاثة في Tuning Tuning LLMs: قواعد LLM ، طرق معلمة موفرة ، مجموعات بيانات التعليمات الصينية.
بالنسبة إلى LLMs المفتوحة ، نقوم باختبار LLMs الحالي و LLMs تم ضبطه مع Lora على الألباكا-GPT4 على Belle-eval و MMCU ، على التوالي.
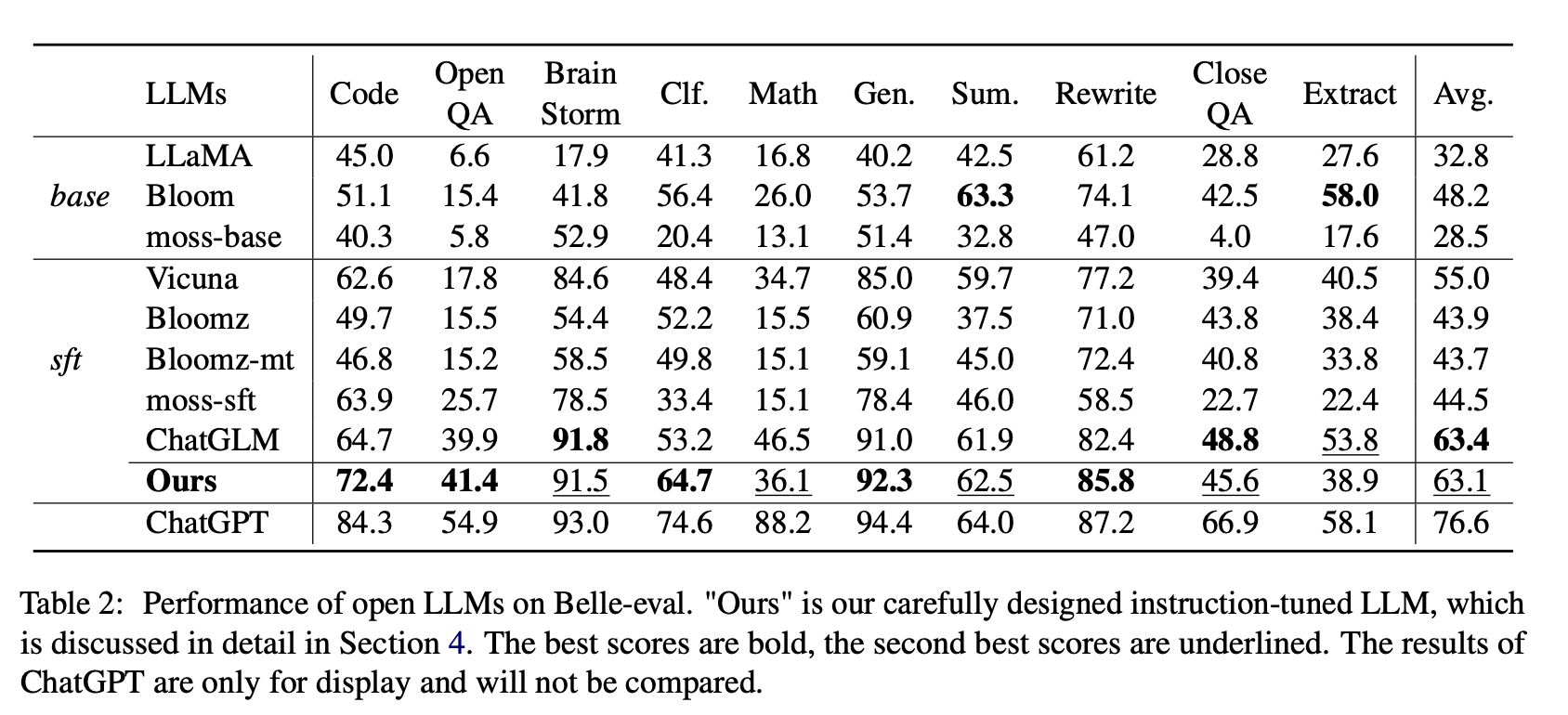
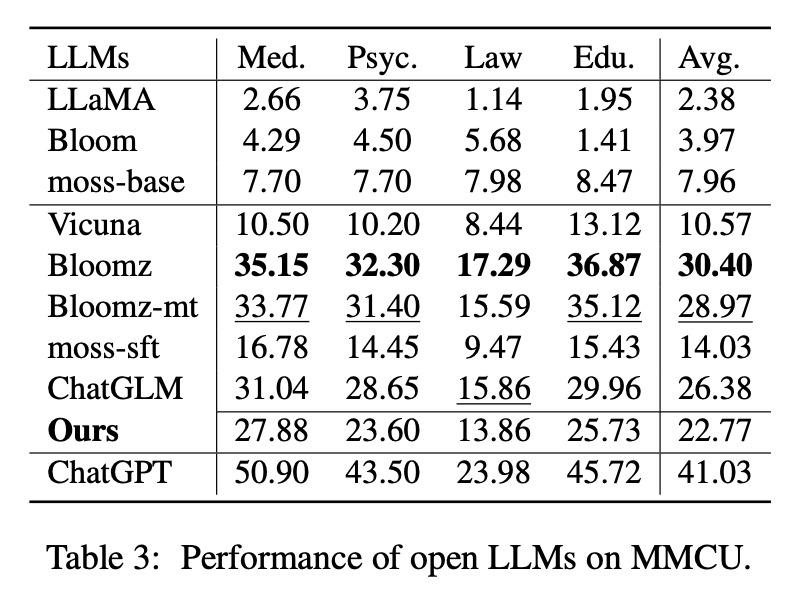
يوضح الجدول 2 عشرات LLMs المفتوحة على الحسناء. يوضح الجدول 3 دقة LLMS على MMCU. إنهم يقومون بضبط جميع LLMs المفتوحة بنفس طريقة LORA الموفرة للمعلمة ونفس مجموعة بيانات التعليمات الألباكا-GPT4.
النتائج التجريبية:
تقييم LLMs الحالية
الأداء على الحسناء
(1) لقاعدة LLMS ، بلوم يؤدي الأفضل.
(2) بالنسبة إلى SFT LLMS ، يتفوق ChatGlm على الآخرين بهوامش كبيرة ، وذلك بفضل حقيقة أنه تم تدريبه مع أكثر الرموز الصينية و HFRL.
(3) لا تزال فئات ضمان الجودة المفتوحة والرياضيات و CloorQa و Lext صعبة للغاية بالنسبة LLMs المفتوحة الحالية.
(4) لدى Vicuna و Moss-SFT تحسينات واضحة مقارنة بقواعدهما ، Llama و Moss-Base ، على التوالي.
(5) على النقيض من ذلك ، يتم تقليل أداء نماذج SFT ، Bloomz و Bloomz-MT ، مقارنة مع إزهار النموذج الأساسي ، لأنها تميل إلى توليد استجابة أقصر.
الأداء على MMCU
(1) تعمل جميع LLMs الأساسية بشكل سيء لأنه من الصعب تقريبًا إنشاء محتوى بالتنسيق المحدد قبل صقل الأرقام ، على سبيل المثال ، أرقام الخيارات.
(2) جميع SFT LLMS تتفوق على قاعدتها المقابلة LLMS ، على التوالي. على وجه الخصوص ، يقوم Bloomz بأفضل (حتى Beats ChatGlm) لأنه يمكن أن ينشئ رقم الخيار مباشرة كما هو مطلوب دون إنشاء محتوى آخر غير ذي صلة ، والذي يرجع أيضًا إلى خصائص البيانات الخاصة بمجموعة بيانات البيانات الخاضعة للإشراف XP3.
(3) من بين التخصصات الأربعة ، القانون هو الأكثر تحديا بالنسبة إلى LLMs.
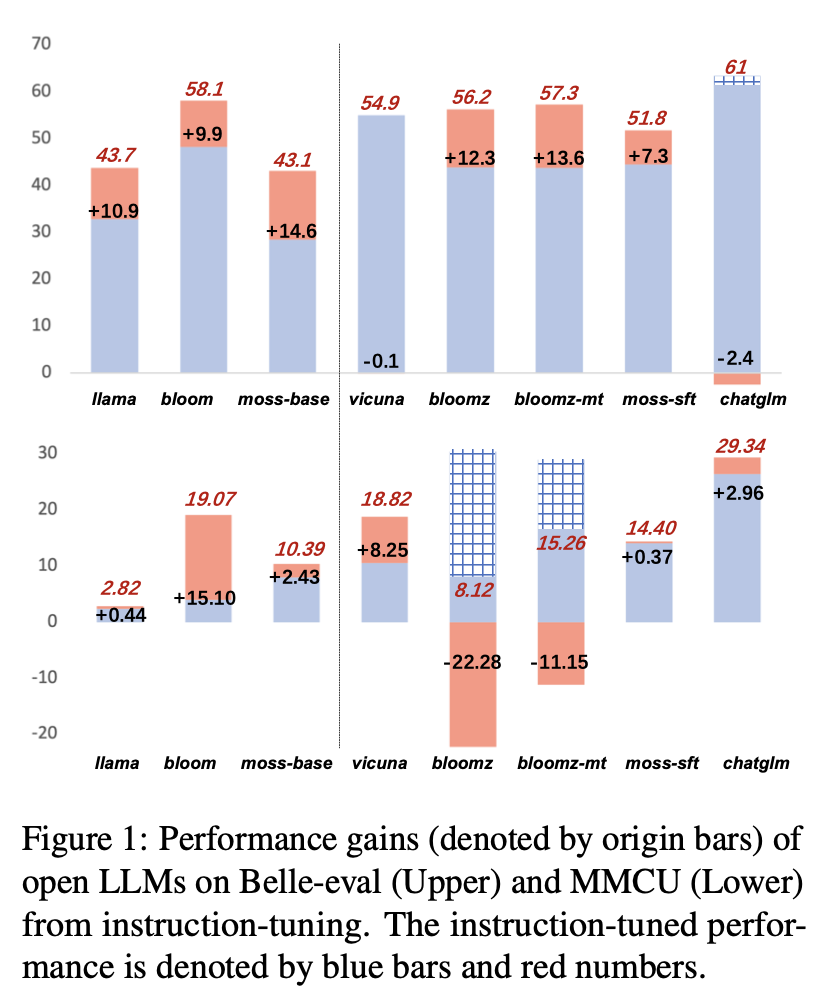
يتم عرض نتائج أداء LLMs بعد صقل التعليمات على الألبكة-GPT4-ZH في الشكل 1.
تعليمات صقل LLMs مختلفة
(1) في Belle-eval ، فإن تحسين أداء SFT LLMS الذي تم إحضاره عن طريق ضبط التعليمات ليس بنفس أهمية ذلك في قاعدة LLMS ، باستثناء SFT Bloomz و Bloomz-MT.
(2) تنخفض أداء Vicuna و ChatGlm بعد صقل التعليمات ، لأن Vicuna مدرّب من محادثات Chatgpt الحقيقية ، بجودة أفضل من Alpaca-GPT4. تعتمد ChatGlm HFRL ، والتي قد لا تكون مناسبة لمزيد من صياغة التعليمات.
(3) على MMCU ، تحقق معظم LLMs تعزيز الأداء بعد ضبط التعليمات ، باستثناء Bloomz و Bloomz-MT ، والتي انخفضت أداء بشكل غير متوقع بشكل غير متوقع.
(4) بعد ضبط التعليمات ، يتمتع بلوم بتحسينات كبيرة ويؤدي أداءً جيدًا على كلتا المعايير. على الرغم من أن chatglm يتفوق على بلوم باستمرار ، إلا أنه يعاني من انخفاض الأداء أثناء ضبط التعليمات. لذلك ، من بين جميع LLMs المفتوحة ، يعد Bloom هو الأكثر ملاءمة كنموذج أساس في التجارب اللاحقة لاستكشاف صياغة التعليمات الصينية.
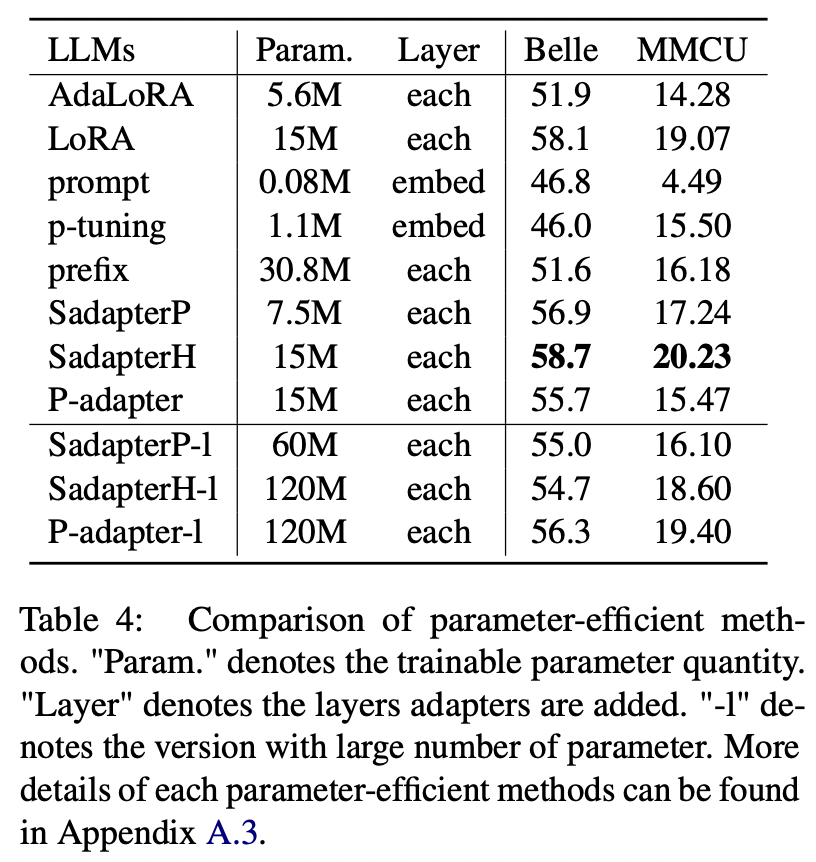
بالنسبة للطرق الموفرة للمعلمة بخلاف LORA ، تجمع الورقة مجموعة من الأساليب الموفرة للمعلمة لتزدهر نضيف التعليمات على مجموعة بيانات الألباكا-GPT4.
النتائج التجريبية:
مقارنة بين أساليب المعلمة
(1) يؤدي Sadapterh الأفضل بين جميع الطرق الموفرة للمعلمة ، والتي يمكن استخدامها كبديل لـ Lora.
(2) P-Tuning و STROFTING OFFERMONT OPHENTY من خلال هوامش كبيرة ، مما يشير إلى أن إضافة طبقات قابلة للدراب فقط في طبقة التضمين ليست كافية لدعم LLMs لمهام التوليد.
(3) على الرغم من أن Adalora هو تحسن في Lora ، إلا أن أدائها له انخفاض واضح ، ربما لأن المعلمات القابلة للتدريب في Lora لـ LLMs ليست مناسبة لمزيد من التخفيض.
(4) مقارنة الأجزاء العلوية والسفلية ، يمكن ملاحظة أن زيادة عدد المعلمات القابلة للتدريب للمحولات المتسلسلة (IE ، Sadapterp و Sadapterh) لا تجلب كسبًا ، في حين يتم ملاحظة الظاهرة المعاكسة للمحولات المتوازية (أي ، P-Adapter)
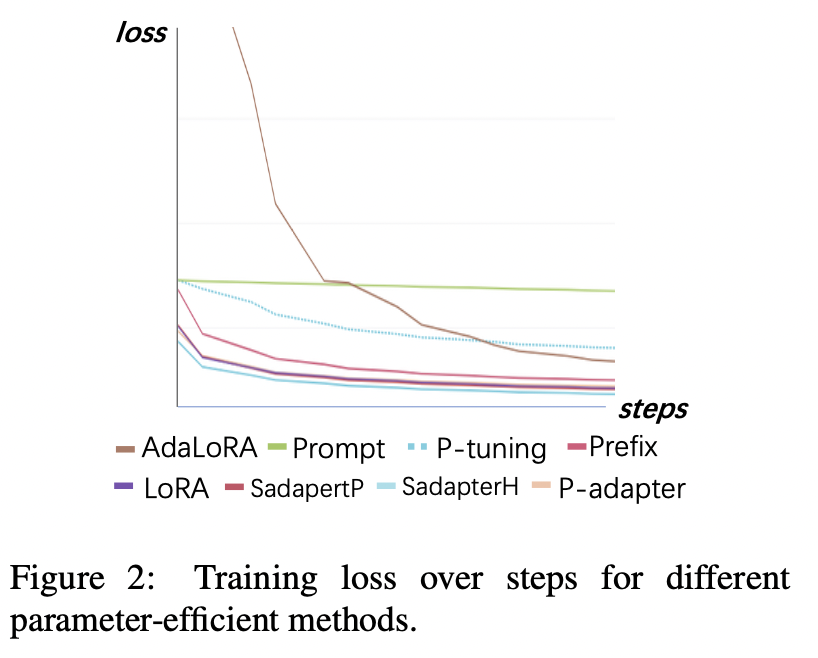
فقدان التدريب
(1) تتقارب الضبط السريع وصقل P أبطأ ولديه أعلى الخسائر بعد التقارب. هذا يدل على أن محولات التضمين فقط ليست مناسبة لتعليمات تعليمات LLMs.
(2) الخسارة الأولية لـ Adalora مرتفع جدًا لأنها تتطلب تعلمًا متزامنًا لتخصيص ميزانية المعلمة ، مما يجعل النموذج غير قادر على احتواء بيانات التدريب بشكل جيد.
(3) يمكن أن تتقارب الطرق الأخرى بسرعة في بيانات التدريب وتناسبها جيدًا.
لتأثير أنواع مختلفة من مجموعات بيانات التعليمات الصينية ، يجمع المؤلفون تعليمات صينية مفتوحة شهيرة (كما هو موضح في الجدول 5) لضبط الإزاحة مع Lora.
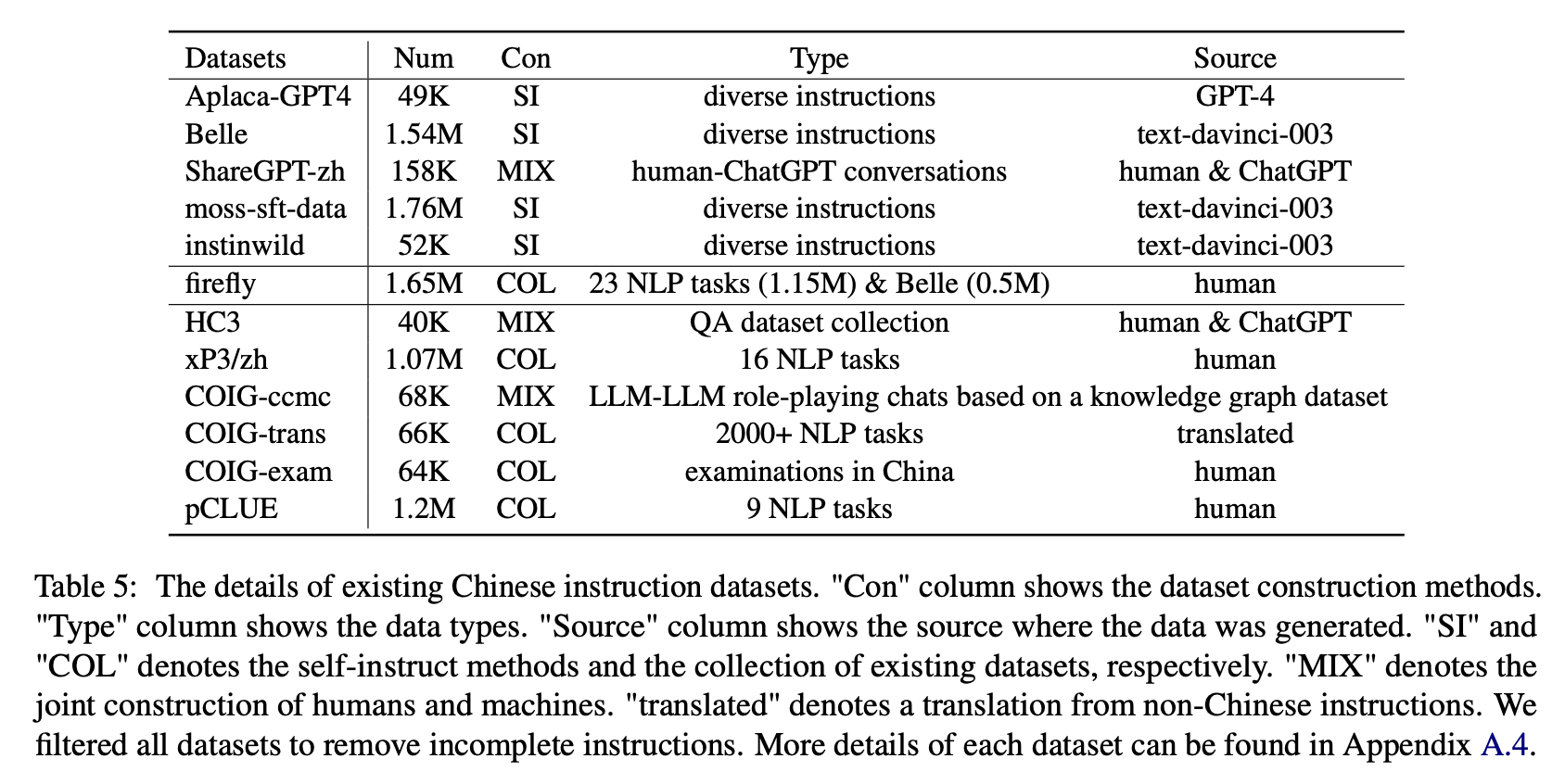
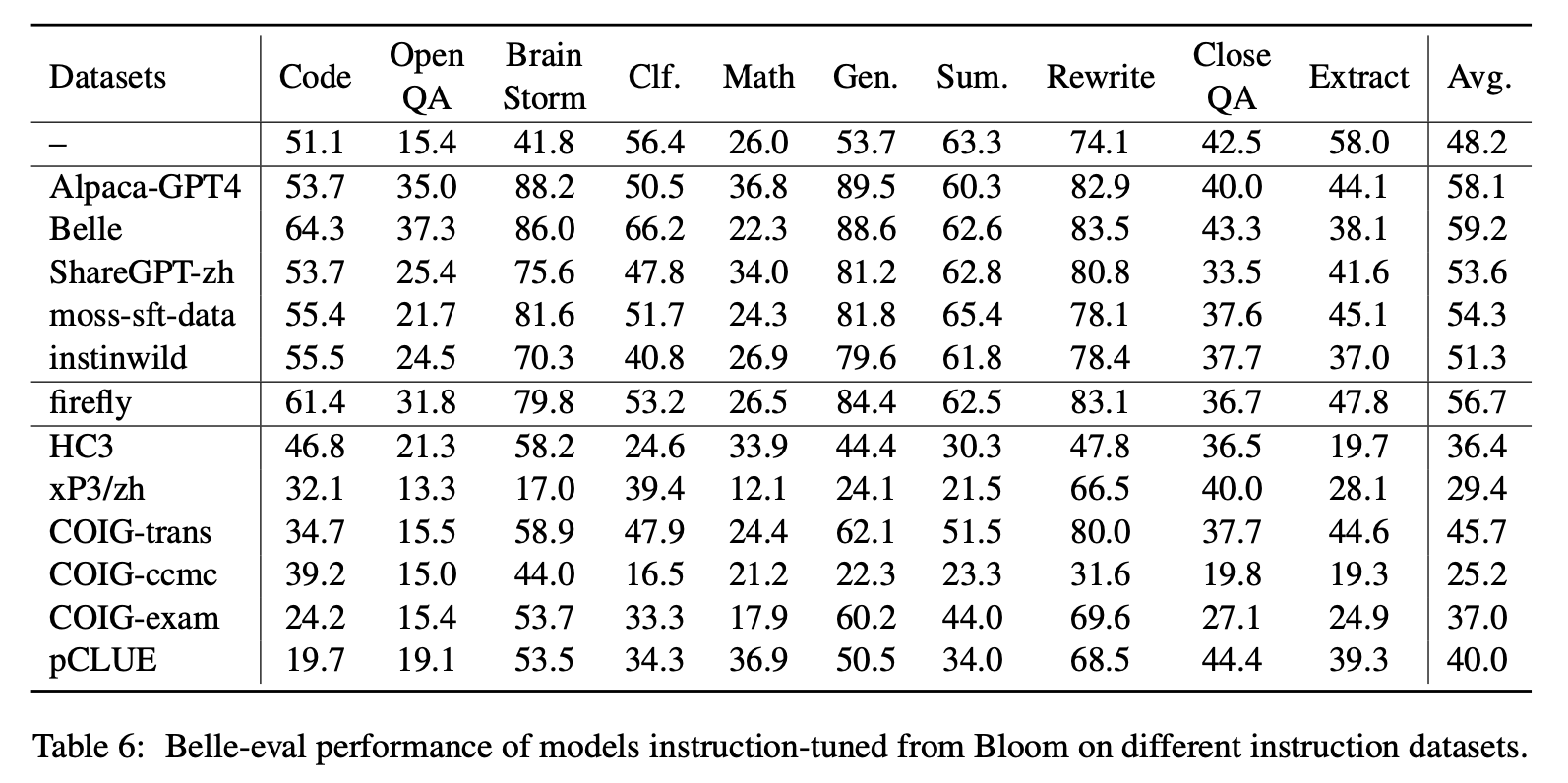
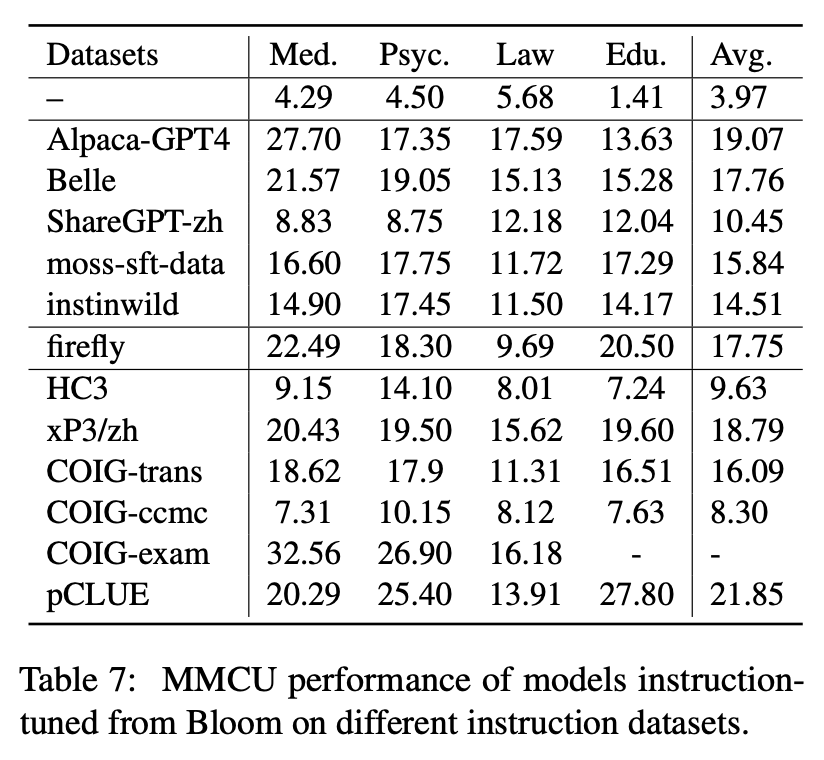
يوضح الجدول 6 والجدول 7 صقل بلوم على مجموعات بيانات التعليمات المختلفة.
النتائج التجريبية:
الأداء على الحسناء
(1) بيانات التعليمات التي تم إنشاؤها بواسطة chatgpt (على سبيل المثال ، باستخدام طرق التعيين الذاتي أو جمع محادثات تشاتغبت البشرية الحقيقية) تعزز باستمرار قدرة متابعة التعليمات مع زيادة درجة 3.1 ∼ 11 نقطة.
(2) من بين مجموعات البيانات هذه ، لدى Belle أفضل أداء بسبب أكبر قدر من بيانات التعليمات. ومع ذلك ، فإن أداء النماذج المدربة على moss-sft-data ، التي تحتوي على المزيد من البيانات المدمجة بطريقة مماثلة ، غير مرضٍ.
(3) الأداء الذي جلبته تعليمات الألباكا-GPT4 هو ثاني الأفضل ، حيث يكون 49 كيلو سوى مقارنته بـ 1.54 متر.
(4) يجلب InstinWild أقل مكاسب الأداء بينهم لأن تعليمات البذور التي تزحفها من تغريدة ("في البرية") ليست شاملة مثل تلك (مثل الألبكة) التي صممها البشر بعناية.
(5) لها هذه البيانات المستندة إلى chatgpt بشكل أساسي تأثير تحسين كبير على مهام التوليد المفتوح مثل عاصفة الدماغ وتوليدها ، في حين أن هناك انخفاضًا كبيرًا في المهام التي تتطلب مهارات فهم عالية القراءة ، مثل QA القريبة والاستخراج.
(6) تتسبب مجموعات بيانات التعليمات هذه في تلف قدرة متابعة تعليمات النموذج ، لأن شكل وقصد كل مجموعة بيانات NLP أو الفحص موحدة ، والتي يمكن تجهيزها بسهولة.
(7) من بينها ، يؤدي Coig-Trans الأفضل لأنه يتضمن أكثر من 2000 مهمة مختلفة مع مجموعة واسعة من تعليمات المهمة. على النقيض من ذلك ، فإن XP3 و Coig-CCMC لهما أسوأ تأثير سلبي على أداء النموذج. يغطي كلاهما فقط أنواع قليلة من المهام (الترجمة و QA للمحادثات السابقة للتصحيح المضاد للأخير) ، والتي بالكاد تغطي التعليمات والمهام الشائعة للبشر.
الأداء على MMCU
(1) يمكن أن يؤدي ضبط التعليمات على كل مجموعة بيانات دائمًا إلى تحسين الأداء.
(2) من بين البيانات المستندة إلى ChatGPT الموضحة في الجزء العلوي ، فإن sharegpt-zh يضعف الآخرين بهوامش كبيرة. قد يكون هذا بسبب حقيقة أن المستخدمين الحقيقيين نادراً ما يطرحون أسئلة متعددة حول الموضوعات الأكاديمية.
(3) من بين بيانات جمع البيانات الموضحة في الجزء السفلي ، ينتج عن HC3 و COIG-CCMC أدنى دقة لأن الأسئلة الفريدة لـ HC3 هي فقط 13K ، وتنسيق مهمة COIG-CCMC يختلف اختلافًا كبيرًا عن MMCU.
(4) يجلب Coig-Exam أكبر تحسين في الدقة ، ويستفيد من تنسيق المهمة المماثل مثل MMCU.
أربعة عوامل أخرى: سرير الأطفال ، توسع المفردات الصينية ، لغة المطالبات والمواءمة ذات القيمة الإنسانية
بالنسبة إلى COT ، يقارن المؤلفون الأداء قبل وبعد إضافة بيانات COT أثناء ضبط التعليمات.
إعدادات التجربة:
نجمع 9 مجموعات بيانات COT ومطالباتها من Flan ، ثم نترجمها إلى الصينية باستخدام Google Translate. يقارنون الأداء قبل وبعد إضافة بيانات COT أثناء ضبط التعليمات.
لاحظ أولاً طريقة إضافة بيانات COT باسم "alpaca-gpt4+cot". بالإضافة إلى ذلك ، أضف جملة "先思考 , 再决定 再决定" ("فكر خطوة بخطوة" باللغة الصينية) في نهاية كل تعليمات ، لحث النموذج على الاستجابة للتعليمات القائمة على المهد ، وتصنيف بهذه الطريقة باسم "الألباكا-GPT4+Cot*".
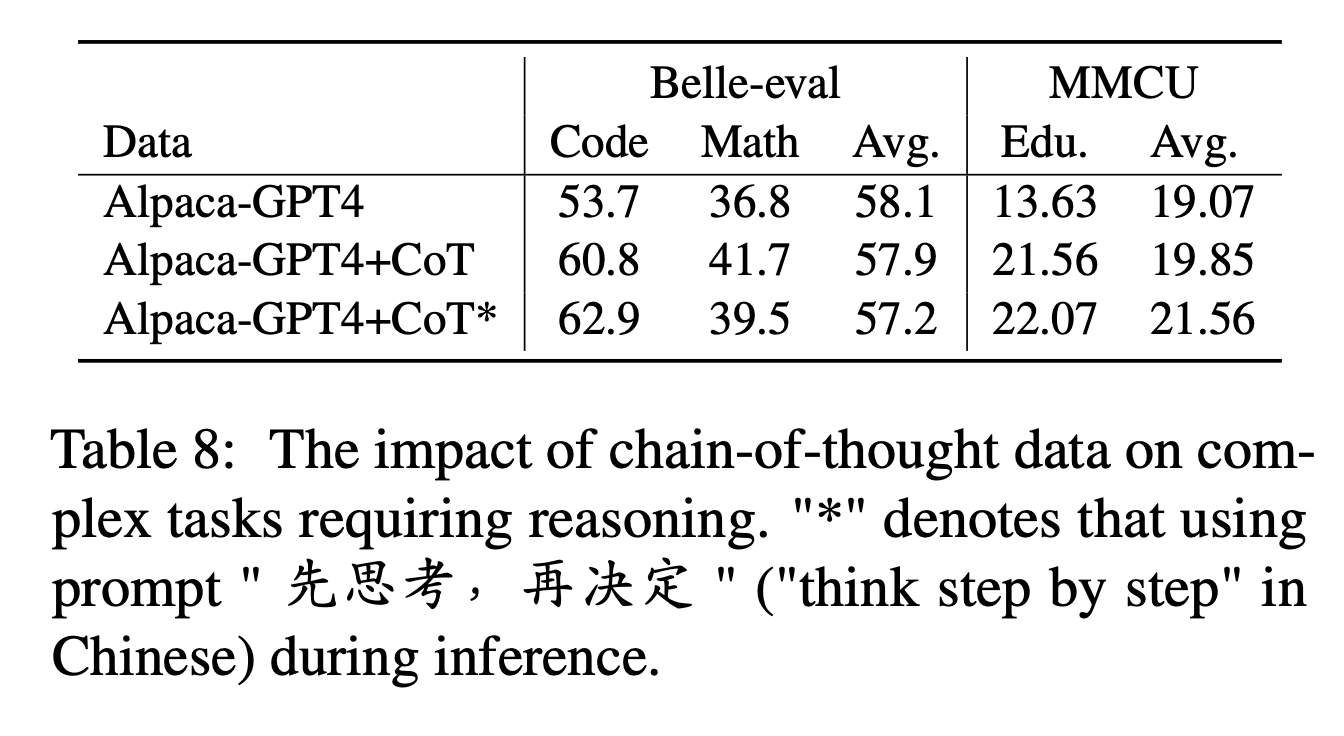
النتائج التجريبية:
"alpaca-gpt4+cot" يتفوق على "alpaca-gpt4" في مهام الكود والرياضيات التي تتطلب قدرة على التفكير القوية. علاوة على ذلك ، هناك أيضًا تحسن كبير في مهمة تعليم MMCU.
كما هو موضح في سطر "alpaca-gpt4+cot*" ، يمكن أن تزيد الجملة البسيطة من أداء رمز مهام التفكير والتعليم ، في حين أن أداء الرياضيات أقل شأناً من "alpaca-gpt4+cot". قد يتطلب هذا المزيد من استكشاف مطالبات أكثر قوة.
لتوسيع المفردات الصينية ، يختبر المؤلفون تأثير عدد الرموز الصينية في مفردات الرمز المميز حول قدرة LLMS على التعبير عن الصينيين. على سبيل المثال ، إذا كانت هناك شخصية صينية في المفردات ، فيمكن تمثيلها برمز واحد ، وإلا فقد يتطلب الأمر رموزًا متعددة لتمثيلها.
إعدادات التجربة: يقوم المؤلفون بشكل أساسي بإجراء تجارب على LLAMA ، والتي تستخدم Sentsexpiece (حجم المفردات 32K من الأحرف الصينية) التي تغطي عدد أقل من الأحرف الصينية من Bloom (250k).
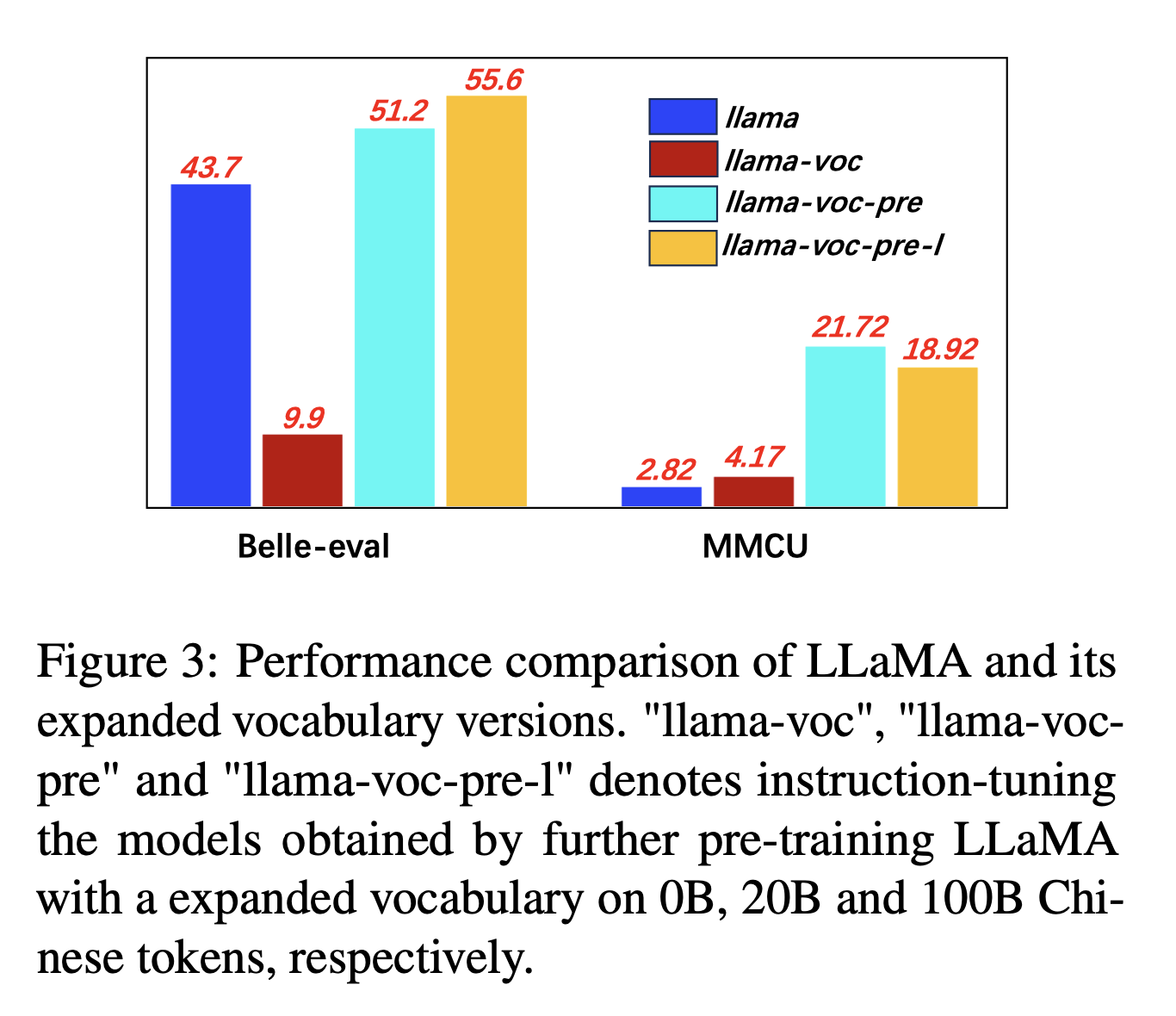
النتائج التجريبية:
إن التدريب المسبق على المزيد من الجسم الصيني مع التوسع في المفردات الصينية مفيد باستمرار لقدرة متابعة التعليمات.
وبشكل مضاد ، "llama-voc-pre-l" (100b) أدنى من "llama-voc-pre" (20B) على MMCU ، مما يدل على أن التدريب المسبق على المزيد من البيانات قد لا يؤدي بالضرورة إلى أداء أعلى للامتحانات الأكاديمية.
بالنسبة لغية المطالبات ، يختبر المؤلفون مدى ملاءمة تعليمات التثبيت لاستخدام المطالبات الصينية.
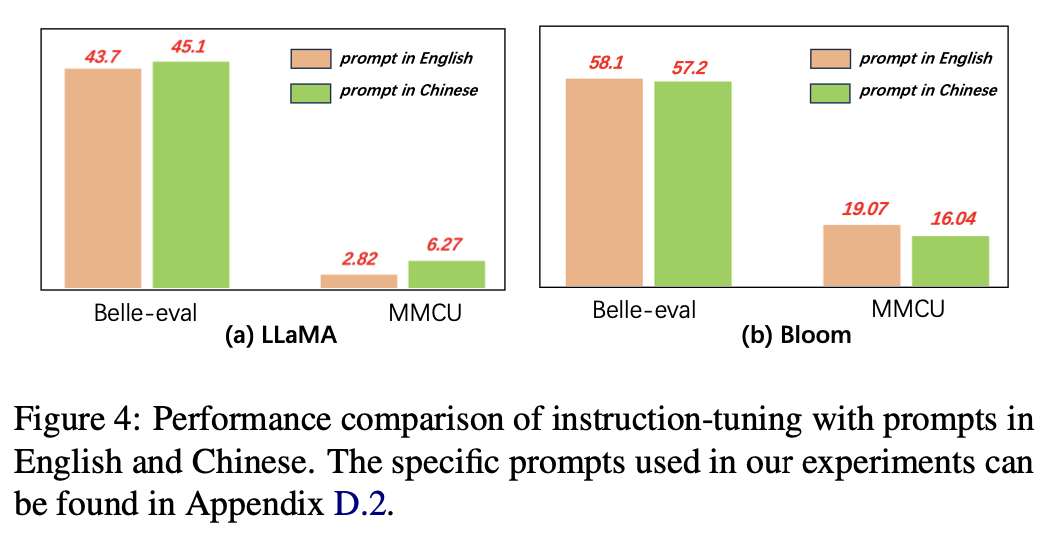
يوضح الشكل 4 نتائج استخدام المطالبات الصينية والإنجليزية على أساس Llama و Bloom. عند تعليمات تعليمات لاما ، يمكن أن يؤدي استخدام المطالبات الصينية إلى تحسين الأداء على كلا المعايير مقارنة بمطالبات اللغة الإنجليزية ، في حين يمكن ملاحظة الظاهرة المعاكسة على الإزهار.
النتائج التجريبية:
بالنسبة للنماذج ذات القدرات الصينية الأضعف (على سبيل المثال ، LLAMA) ، يمكن أن يساعد استخدام المطالبات الصينية بشكل فعال في الاستجابة باللغة الصينية.
بالنسبة للموديلات ذات القدرات الصينية الجيدة (على سبيل المثال ، بلوم) ، يمكن باستخدام مطالبات باللغة الإنجليزية (اللغة التي تكون أفضل في) توجيه النموذج بشكل أفضل لفهم عملية التثبيت مع التعليمات.
لتجنب LLMS لتوليد محتوى سام ، يعد محاذاة القيم الإنسانية مشكلة حاسمة. نضيف بيانات محاذاة القيمة البشرية التي صممها Coig إلى صياغة التعليمات لاستكشاف تأثيرها.
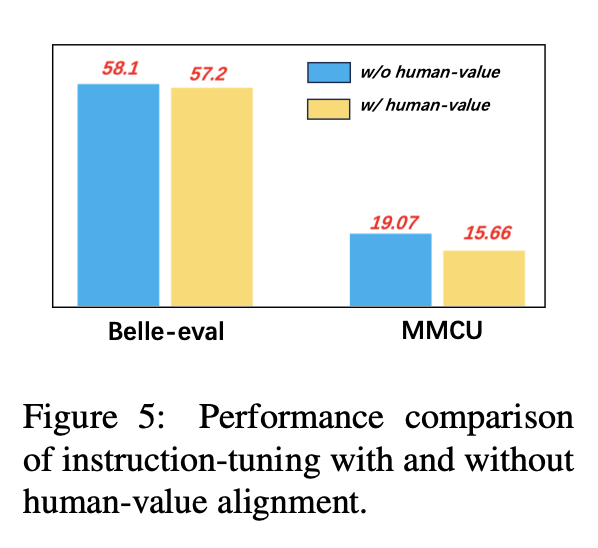
يقارن الشكل 5 نتائج صقل التعليمات مع أو بدون محاذاة قيمة الإنسان.
النتائج التجريبية: ينتج عن محاذاة القيمة الإنسانية انخفاضًا بسيطًا في الأداء. كيفية تحقيق التوازن بين الضرر وأداء LLMS هو اتجاه البحث يستحق الاستكشاف في المستقبل.
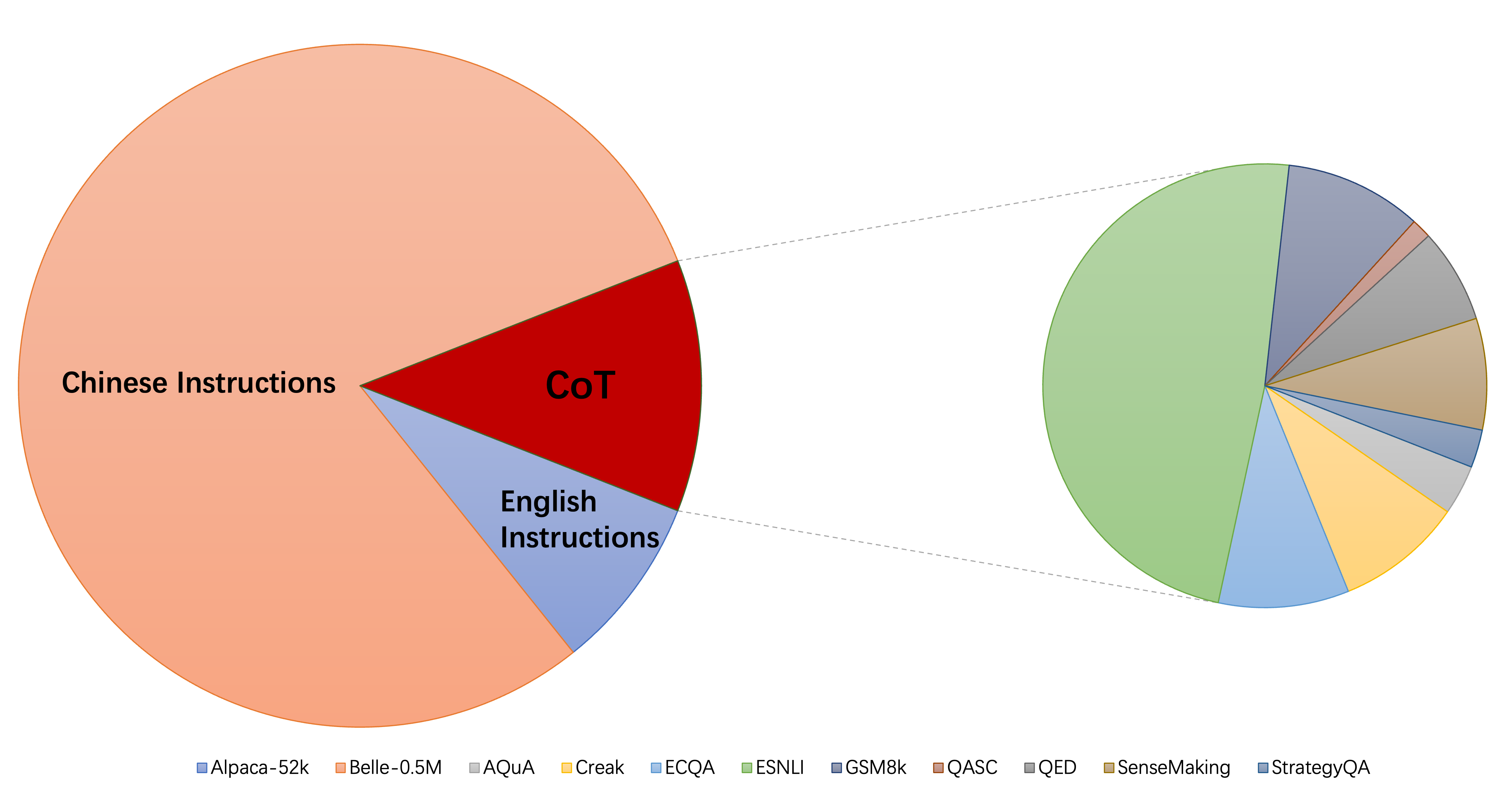 تتكون المجموعة الحالية من مجموعات بيانات التمهيديات بشكل أساسي من ثلاثة أجزاء:
تتكون المجموعة الحالية من مجموعات بيانات التمهيديات بشكل أساسي من ثلاثة أجزاء:
alpaca_data_cleaned.json : حوالي 52 ألف عينات تدريب متابعة للتعليمات الإنجليزية.CoT_data.json : 9 مجموعات بيانات COT تتضمن حوالي 75K عينة. (نشرته فلان [7])belle_data_cn.json : حوالي 0.5 متر صينية | عينات تدريب متابعة التعليمات. (نشرته بيل [8]) يشير "W/O COT" و "W/O CN" إلى النماذج التي تستبعد بيانات COT والتعليمات الصينية من بيانات التعليمات الخاصة بهم ، على التوالي.
يشير "W/O COT" و "W/O CN" إلى النماذج التي تستبعد بيانات COT والتعليمات الصينية من بيانات التعليمات الخاصة بهم ، على التوالي.
يوضح الجدول أعلاه مثالين (يتضمن مع حسابات عددية) يتطلب قدرًا معينًا من قدرة التفكير على الاستجابة بشكل صحيح. كما هو موضح في العمود الأوسط ، فشلنا Ours w/o CoT في توليد الاستجابة الصحيحة ، مما يدل على أنه بمجرد أن لا تحتوي البيانات على بيانات COT ، تنخفض قدرة التفكير بشكل كبير. هذا يوضح كذلك أن بيانات COT ضرورية لنماذج LLM.

يوضح الجدول أعلاه مثالين يتطلبان القدرة على الاستجابة للتعليمات الصينية. كما هو موضح في العمود الأيمن ، إما أن المحتوى الذي تم إنشاؤه Ours w/o CN غير معقول ، أو يتم الرد على التعليمات الصينية باللغة الإنجليزية من Ours w/o CN . هذا يدل على أن إزالة البيانات الصينية أثناء التحويلات اللاإرادية سيؤدي إلى عدم قدرة النموذج على التعامل مع التعليمات الصينية ، ويوضح أيضًا الحاجة إلى جمع بيانات التعليمات الصينية.

يوضح الجدول أعلاه مثالًا صعبًا نسبيًا ، والذي يتطلب تراكمًا معينًا لمعرفة التاريخ الصيني والقدرة المنطقية والكاملة على تحديد الأحداث التاريخية. كما هو موضح في هذا الجدول ، لا يمكن Ours w/o CN سوى توليد استجابة قصيرة وخاطئة فقط ، لأنه بسبب عدم وجود بيانات صينية للتكنولوجيا ، فإن المعرفة المقابلة للتاريخ الصيني تفتقر بشكل طبيعي. على الرغم من أن Ours w/o CoT يسرد بعض الأحداث التاريخية الصينية ذات الصلة ، إلا أن منطق التعبير هو المتناقض الذاتي ، وهو الناجم عن عدم وجود بيانات COT. `
باختصار ، يمكن للموديلات التي تم تحريكها من مجموعة البيانات الكاملة (بيانات تعليمات اللغة الإنجليزية والصينية والتهابية) تحسين التفكير النموذجي والتعليم الصيني بشكل كبير.
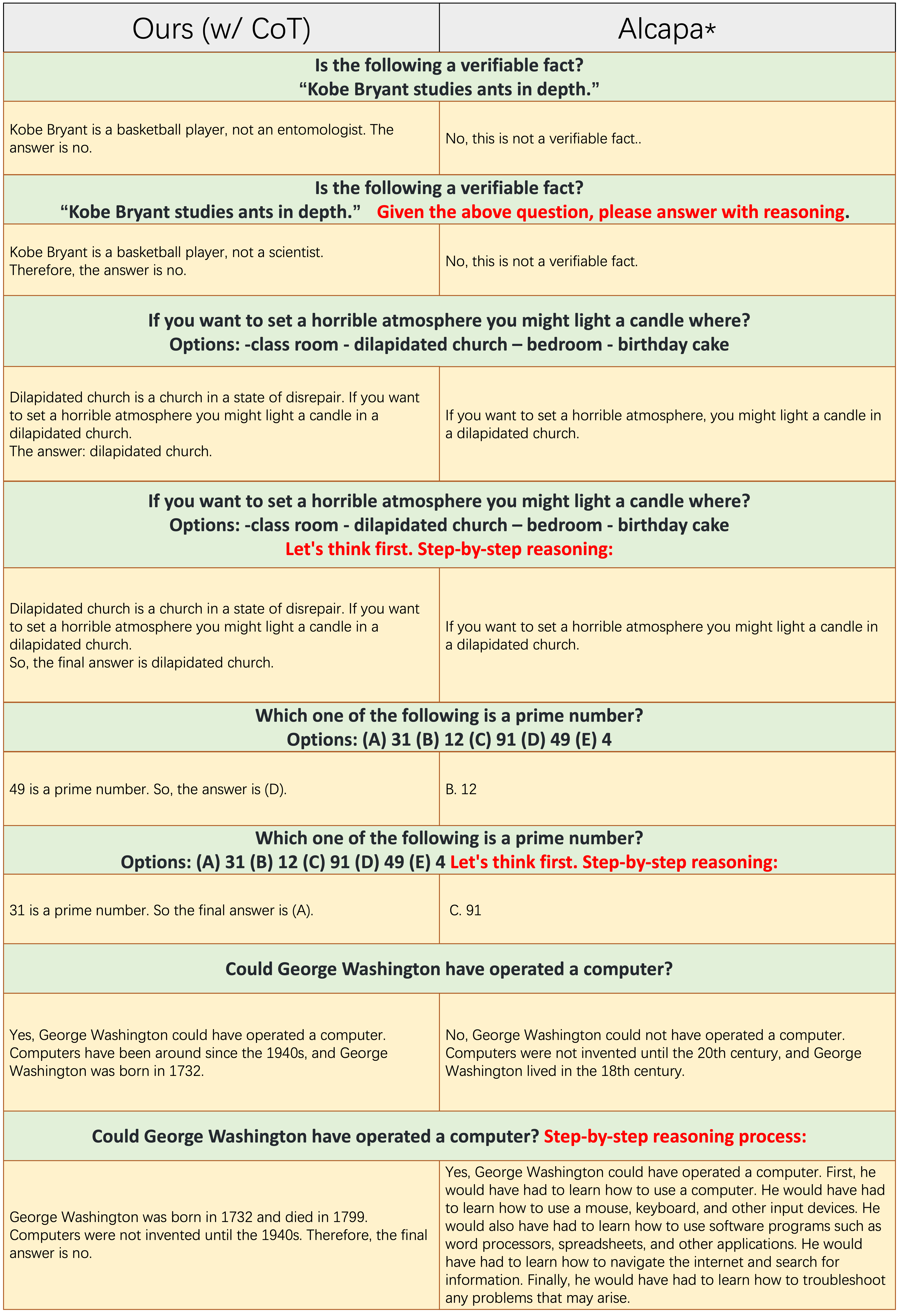 لا تطبق عينات من كل عدد فردي من الصفوف موجه COT ، مثل "التفكير خطوة بخطوة". يعتمد كل
لا تطبق عينات من كل عدد فردي من الصفوف موجه COT ، مثل "التفكير خطوة بخطوة". يعتمد كل Ours(w/CoT) و ALPACA على LLAMA-7B ، والفرق الوحيد بينهما اثنان هو أن بيانات التمهيديات Ours(w/CoT) لديها بيانات COT إضافية من الألبكة.
من الجدول أعلاه ، نجد ذلك:
Ours(w/CoT) دائمًا الأساس المنطقي الصحيح قبل الإجابة ، بينما تفشل الألبكة في توليد أي مبررات معقولة ، كما هو موضح في الأمثلة الأربعة الأولى (أسئلة المنطقية). هذا يدل على أن استخدام بيانات COT للتكنولوجيا يمكن أن يحسن قدرة التفكير بشكل كبير.Ours(w/CoT) ، فإن مطالبة COT (على سبيل المثال ، متسلسلة "خطوة بخطوة" مع سؤال الإدخال) لها تأثير ضئيل على أمثلة سهلة (على سبيل المثال ، أسئلة المنطقية) ولها تأثير مهم على الأسئلة الصعبة (على سبيل المثال ، الأسئلة التي تتطلب التفكير ، مثل الأمثلة الأربعة الأخيرة). المقارنة الكمية للاستجابات للتعليمات الصينية. 
تم تصميم نموذجنا من 7 ب llama على تعليمات اللغة الإنجليزية 52k وتعليمات صينية 0.5m. ستانفورد الألباكا (إعادة تنفيذنا) تم تحريكه من 7 ب لاما على تعليمات اللغة الإنجليزية 52k. يتم تحطيم الحسناء من بلوم 7B على تعليمات صينية 2 ب.
من الجدول أعلاه ، يمكن العثور على عدة ملاحظات:
ours (w/ CN) قدرة أقوى على فهم التعليمات الصينية. على سبيل المثال ، فشل الألبكة في التمييز بين جزء instruction وجزء input ، بينما نفعل ذلك.ours (w/ CN) الرمز الصحيح فحسب ، بل يوفر أيضًا التعليق التوضيحي الصيني المقابل ، في حين أن الألبكة لا. بالإضافة إلى ذلك ، كما هو موضح في الأمثلة 3-5 ، لا يمكن أن تستجيب الألبكة فقط للتعليم الصيني باستخدام استجابة باللغة الإنجليزية.ours (w/ CN) بشأن الإرشادات التي تتطلب استجابة مفتوحة (كما هو موضح في آخر مثالين). يرجع الأداء المتميز لـ Belle مقابل مثل هذه التعليمات إلى: 1. يواجه طراز Bloom Backbone بيانات متعددة اللغات خلال التدريب المسبق ؛ 2. إن بيانات التعليمات الصينية الخاصة بها هي أكثر من لدينا ، أي 2M مقابل 0.5 متر. المقارنة الكمية للاستجابات لتعليمات اللغة الإنجليزية. الغرض من هذا القسم الفرعي هو استكشاف ما إذا كان للتكوين المعاني على التعليمات الصينية تأثير سلبي على الألبكة. 
من الجدول أعلاه ، نجد ذلك:
ours (w/ CN) تفاصيل أكثر من استجابة الألبكة ، على سبيل المثال ، على سبيل المثال الثالث ، ours (w/ CN) ثلاث مقاطعات أخرى أكثر من الألبكة. يرجى الاستشهاد بالربط إذا كنت تستخدم جمع البيانات والرمز والنتائج التجريبية في هذا الريبو.
@misc{si2023empirical,
title={An Empirical Study of Instruction-tuning Large Language Models in Chinese},
author={Qingyi Si and Tong Wang and Zheng Lin and Xu Zhang and Yanan Cao and Weiping Wang},
year={2023},
eprint={2310.07328},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
بالنسبة للبيانات والموديلات ، يرجى الاستشهاد بالبيانات الأصلية وطرق الكفاءة المعلمة ومصدر LLMS أيضًا.
نود أن نعرب عن امتناننا الخاص لـ Apus Ailme Lab لرعايته لقيام وحدات معالجة الرسومات 8 A100 للتجارب.
(العودة إلى الأعلى)


