LongQLoRA
1.0.0
รายงานทางเทคนิค: LongQlora: วิธีที่มีประสิทธิภาพและมีประสิทธิภาพในการขยายความยาวบริบทของแบบจำลองภาษาขนาดใหญ่
LongQlora เป็นวิธีการที่มีประสิทธิภาพและมีประสิทธิภาพในการขยายความยาวบริบทของแบบจำลองภาษาขนาดใหญ่ที่มี GPUs การฝึกอบรมน้อยลง ใน 32GB V100 GPU , LongQlora สามารถขยายความยาวบริบทของ LLAMA2 7B และ 13B จาก 4096 เป็น 8192 และแม้กระทั่ง 12K LongQlora บรรลุประสิทธิภาพการแข่งขันที่น่ากลัวในชุดข้อมูล PG19 และ Proof-Pile หลังจากขั้นตอนการปรับระดับ 1,000 ขั้นตอนรุ่นของเรามีประสิทธิภาพสูงกว่า Longlora และอยู่ใกล้กับ MPT-7B-8K มาก
การประเมินความสับสนในการตรวจสอบความถูกต้องของ PG19 และชุดข้อมูลการทดสอบแบบไพ่ในการประเมินความยาวบริบทของการประเมิน 8192:
| แบบอย่าง | PG19 | ไพ่ |
|---|---|---|
| LLAMA2-7B | > 1,000 | > 1,000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-Lora-7b-8k | 8.20 | 2.78 |
| Longlora-full-7b-8k | 7.93 | 2.73 |
| Longqlora-7b-8k | 7.96 | 2.73 |
การประเมินความงุนงงของโมเดล 7B ในชุดข้อมูลการตรวจสอบความถูกต้องของ PG19 และการทดสอบแบบพกพาในความยาวบริบทการประเมินจาก 1024 ถึง 8192:
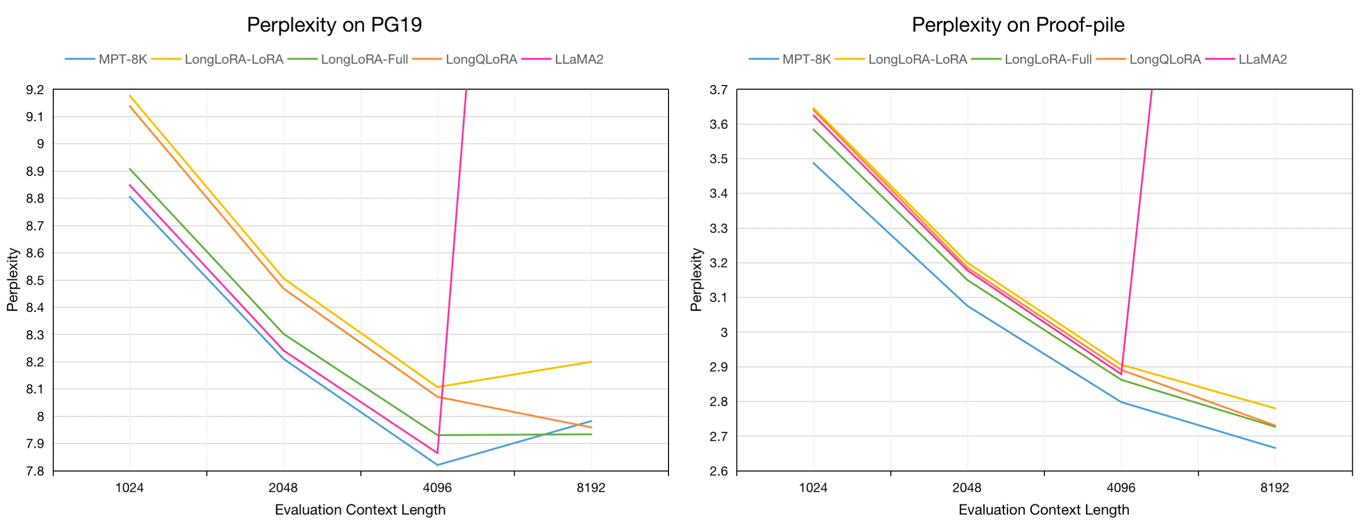
เราสุ่มตัวอย่างข้อความยาว 54K จากชุดข้อมูล Redpajama ไปยังรุ่น Finetune Pretrained ซึ่งมีความยาวโทเค็นตั้งแต่ 4096 ถึง 32768
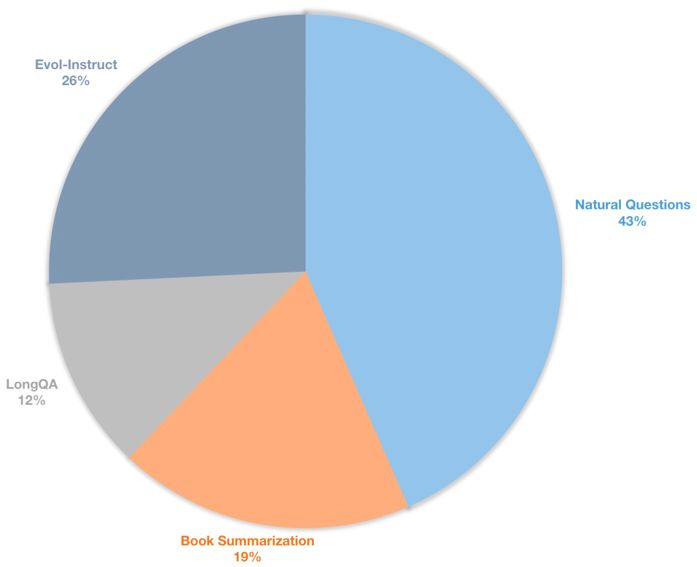
นอกจากนี้เรายังสร้างชุดข้อมูลการเรียนการสอนบริบทที่ยาวนานสำหรับโมเดลการแชท Finetuning ชุดข้อมูลนี้มีข้อมูลการเรียนการสอน 39K ส่วนใหญ่รวมถึงการสรุปหนังสือคำถามธรรมชาติชุดย่อยของ LongQa และ Evol-Instruct ของ Wizardlm เพื่อที่จะปรับให้เข้ากับความยาวเป้าหมายที่ 8192 จำนวนโทเค็นสูงสุดของแต่ละข้อมูลคือ 8192 การกระจายมีดังนี้
| ชุดข้อมูล | คำอธิบาย |
|---|---|
| ? longqlora-pretrain-data-54k | รวมข้อมูล 54212 ที่ใช้ในการปรับแต่งแบบจำลอง Finetune |
| ? longqlora-sft-data-39k | รวมข้อมูล 38821 ที่ใช้ในรูปแบบการแชท Finetune |
| แบบอย่าง | ความยาวบริบท | คำอธิบาย |
|---|---|---|
| ? longqlora-llama2-7b-8k | 8192 | Finetuned ด้วย longqlora-pretrain-data-54k สำหรับ 1k ขั้นตอนตาม llama2-7b |
| ? longqlora-vicuna-13b-8k | 8192 | Finetuned ด้วย longqlora-sft-data-39k สำหรับ 1.7k ขั้นตอนตาม vicuna-13b-v1.5 |
| ? longqlora-llama2-7b-8k-lora | 8192 | น้ำหนัก Lora |
| ? longqlora-vicuna-13b-8k-lora | 8192 | น้ำหนัก Lora |
การกำหนดค่าการฝึกอบรมจะถูกบันทึกไว้ในไดเรกทอรี Train_Args พารามิเตอร์บางอย่างมีดังนี้:
sft : ทำภารกิจ SFT ถ้าตั้งค่าเป็นจริงมิฉะนั้นจะทำภารกิจก่อนmodel_max_length : ความยาวบริบทเป้าหมายmax_seq_length : ความยาวลำดับสูงสุดในการฝึกอบรมควรน้อยกว่าหรือเท่ากับ model_max_lengthlogging_steps : บันทึกการสูญเสียการฝึกอบรมทุกขั้นตอนsave_steps : บันทึกโมเดลทุกขั้นตอน nlora_rank : อันดับ LORA ในการฝึกอบรมขยายความยาวบริบทของแบบจำลองที่ผ่านการฝึกอบรม LLAMA2-7B:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlขยายความยาวบริบทของโมเดลแชท Vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlคุณสามารถรวมน้ำหนัก LORA เข้ากับรุ่นพื้นฐาน:
cd script
python merge_lora.pyการอนุมานกับแบบจำลองที่ผ่านการฝึกอบรม:
cd script/inference
python inference.pyแชทกับโมเดลแชท:
cd script/inference
python chat.pyดาวน์โหลดชุดข้อมูลการประเมินผลโทเค็นโดย LLAMA2 โดย Longlora
| ชุดข้อมูล |
|---|
| ? pg19- validation.bin |
| ? pg19-test.bin |
| ? proof-pile-test.bin |
ประเมินความงุนงงของแบบจำลอง คุณสามารถตั้ง load_in_4bit เป็นจริงเพื่อบันทึกหน่วยความจำ:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binประเมินความงุนงงของแบบจำลองด้วยน้ำหนัก LORA:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binตัวอย่างที่สร้างขึ้นโดย Longqlora-vicuna-13b-8k ARS ดังนี้
ตัวอย่างของการจำแนกบริบทยาวความยาวบริบทของอินพุตอยู่ระหว่าง 4096 และ 8192 ซึ่งมีขนาดใหญ่กว่าความยาวบริบทดั้งเดิมของ LLAMA2

ตัวอย่างของการจำแนกบริบทสั้น ๆ แบบจำลองรักษาประสิทธิภาพของการสอนระยะสั้นต่อไปนี้

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


