LongQLoRA
1.0.0
Rapport technique: Longqlora: méthode efficace et efficace pour étendre la durée du contexte des modèles de grande langue
Longqlora est une méthode économe en mémoire et efficace pour étendre la durée du contexte des modèles de gros langues avec moins de GPU de formation. Sur un seul GPU V100 de 32 Go , Longqlora peut étendre la longueur de contexte de LLAMA2 7B et 13B de 4096 à 8192 et même à 12k. Longqlora obtient des performances de perplexité compétitives sur PG19 et un ensemble de données de pile de preuve après seulement 1000 étapes de fintuning, notre modèle surpasse Longlora et est très proche de MPT-7B-8K.
Évaluation Perplexité sur les ensembles de données de validation PG19 et de test de preuve dans la durée du contexte d'évaluation de 8192:
| Modèle | Pg19 | Pile de preuve |
|---|---|---|
| Llama2-7b | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-lora-7b-8k | 8.20 | 2.78 |
| Longlora-full-7b-8k | 7.93 | 2.73 |
| Longqlora-7b-8k | 7.96 | 2.73 |
Évaluation Perplexité des modèles 7B sur les ensembles de données de validation PG19 et de test de preuve en longueur de contexte d'évaluation de 1024 à 8192:
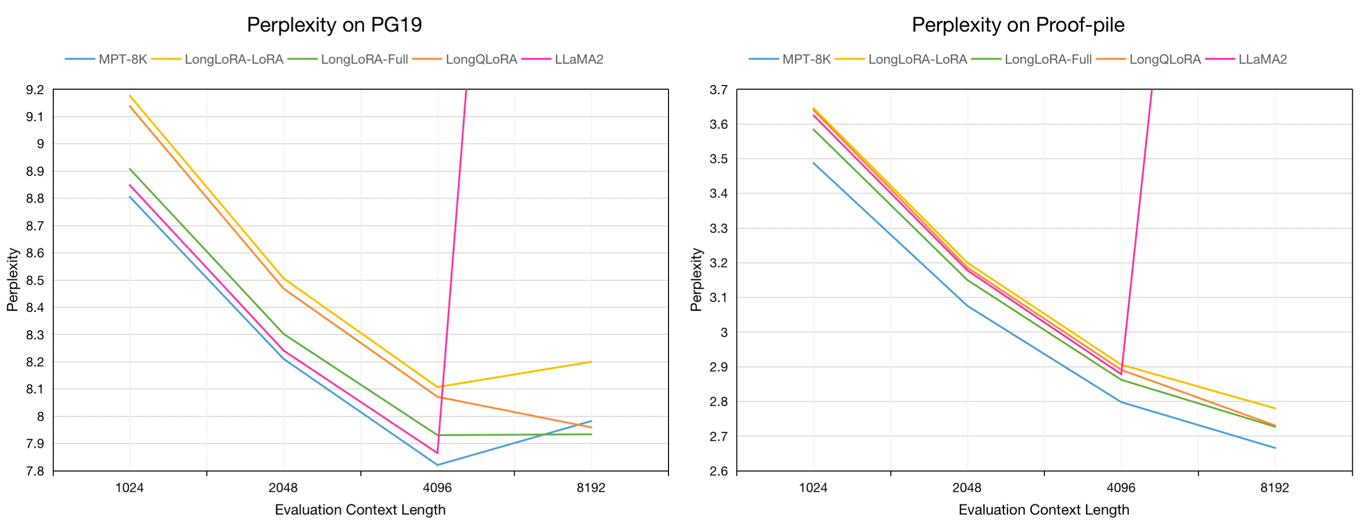
Nous échantillons environ 54k de texte de long de l'ensemble de données Redpajama aux modèles Finetune pré-étirés, dont les longueurs de jeton allant de 4096 à 32768.
Nous construisons également un long ensemble de données d'instructions de contexte pour les modèles de chat de finetuning supervisés. Cet ensemble de données contient 39k de données d'instructions, y compris principalement le résumé des livres, les questions naturelles, le sous-ensemble de Longqa et l'évol-instruit de Wizardlm. Afin de s'adapter à la longueur cible de 8192, le nombre de jetons max de chaque données est 8192. La distribution est la suivante.
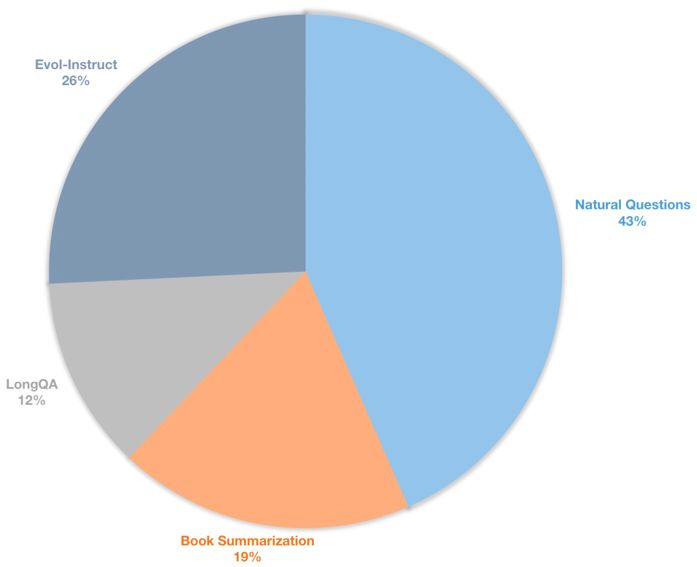
| Ensemble de données | Description |
|---|---|
| ? Longqlora-prétraigne-Data-54K | Inclure 54212 données, utilisée pour le modèle pré-entraîné Finetune |
| ? Longqlora-sft-data-39k | Inclure 38821 données, utilisée pour le modèle de chat finetune |
| Modèle | Durée du contexte | Description |
|---|---|---|
| ? Longqlora-lama2-7b-8k | 8192 | Finetuned avec longqlora-prétraigne-data-54k pour 1k étapes basées sur LLAMA2-7B |
| ? Longqlora-vicuna-13b-8k | 8192 | Finetuned avec longqlora-sft-data-39k pour 1,7k étapes basées sur vicuna-13b-v1.5 |
| ? Longqlora-lama2-7b-8k-lora | 8192 | Poids lora |
| ? Longqlora-vicuna-13b-8k-lora | 8192 | Poids lora |
Les configurations de formation sont enregistrées dans le répertoire Train_args, certains paramètres sont les suivants:
sft : Faites la tâche SFT si elle est définie comme vraie, sinon faites la tâche de pré-formation.model_max_length : la longueur du contexte cible.max_seq_length : la longueur de séquence maximale en formation doit être inférieure ou égale à Model_Max_Lengthlogging_steps : perte de formation de journal toutes les n étapes.save_steps : Enregistrez le modèle toutes les n étapes.lora_rank : Le rang de Lora en formation.Étendre la longueur du contexte du modèle pré-entraîné lama2-7b:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlÉtendez la durée du contexte du modèle de chat Vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlVous pouvez fusionner le modèle de poids LORA:
cd script
python merge_lora.pyInférence avec le modèle pré-entraîné:
cd script/inference
python inference.pyChat avec le modèle de chat:
cd script/inference
python chat.pyTéléchargez le jeu de données d'évaluation Tokenisé par LLAMA2 par Longlora.
| Ensemble de données |
|---|
| ? Pg19-validation.bin |
| ? PG19-test.bin |
| ? Preuve-pile-test.bin |
Évaluez la perplexité des modèles. Vous pouvez définir load_in_4bit comme vrai pour enregistrer la mémoire:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binÉvaluez la perplexité des modèles avec des poids LORA:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binLes exemples générés par Longqlora-vicuna-13b-8k ARS comme suit.
Exemples de génération de contexte long, les longueurs de contexte d'entrée se situent entre 4096 et 8192 qui sont plus grandes que la longueur de contexte d'origine de LLAMA2.

Exemples de génération de contexte court, modèle maintient les performances de l'instruction courte suivante.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


