LongQLoRA
1.0.0
テクニカルレポート:LongQlora:大規模な言語モデルのコンテキスト長を拡張するための効率的かつ効果的な方法
LongQloraは、トレーニングGPUを少なくして、大規模な言語モデルのコンテキスト長を拡張するためのメモリ効率の高い効果的な方法です。単一の32GB V100 GPUでは、LongQloraはLLAMA2 7Bと13Bのコンテキスト長を4096から8192に、さらには12Kに拡張できます。 Longqloraは、わずか1000個の微調整ステップの後、PG19とプルーフパイルデータセットで競争力のある困惑のパフォーマンスを達成し、モデルはロングロラを上回り、MPT-7B-8Kに非常に近いです。
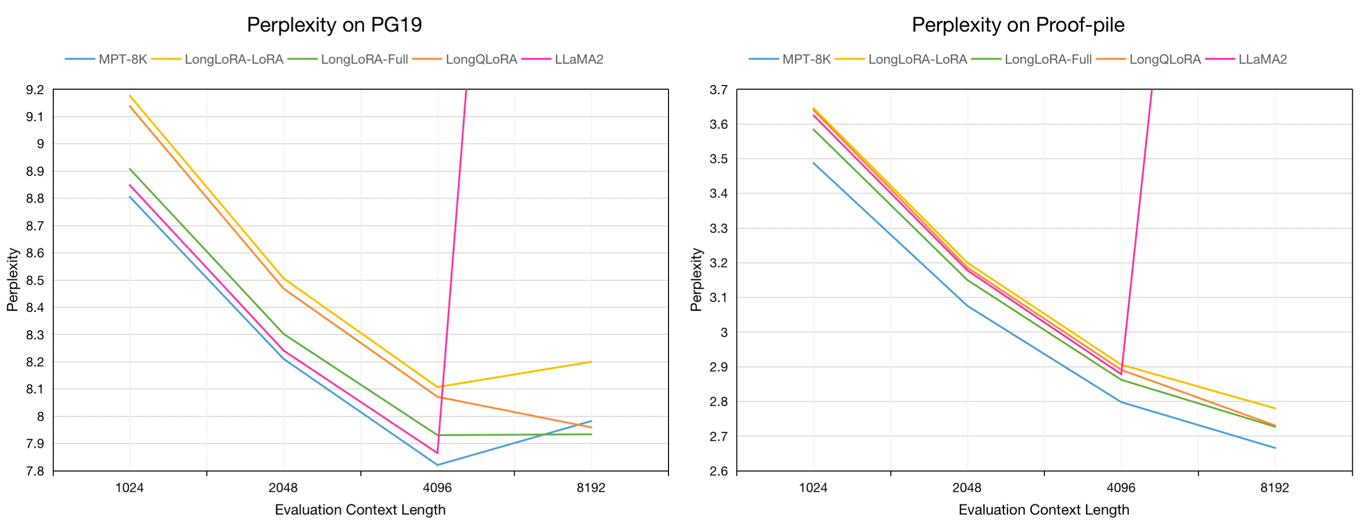
評価コンテキストの長さ8192のPG19検証およびプルーフパイルテストデータセットの評価困惑:
| モデル | PG19 | プルーフパイル |
|---|---|---|
| llama2-7b | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| longlora-lora-7b-8k | 8.20 | 2.78 |
| longlora-full-7b-8k | 7.93 | 2.73 |
| longqlora-7b-8k | 7.96 | 2.73 |
評価コンテキストの長さ1024から8192のPG19検証およびプルーフパイルテストデータセットの7Bモデルの評価困惑:
Redpajamaデータセットから、4096から32768の範囲のトークンの長さのFinetuneの前提型モデルまで、約54kのテキストをサンプリングします。
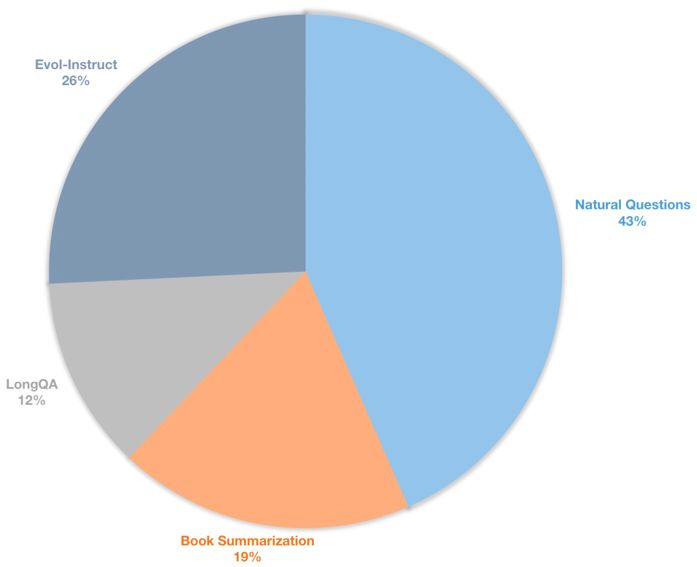
また、監視されたFinetuningチャットモデル用の長いコンテキスト命令データセットを構築します。このデータセットには、主に本の要約、自然な質問、longqaのサブセット、wizardlmのevol-intructを含む39kの命令データが含まれています。 8192の目標長に適応するために、各データの最大トークン数は8192です。分布は次のとおりです。
| データセット | 説明 |
|---|---|
| ?longqlora-pretrain-data-54k | 前処理されたモデルを微調整するために使用される54212データを含めます |
| ?longqlora-sft-data-39k | チャットモデルのFinetuneに使用される38821データを含めます |
| モデル | コンテキストの長さ | 説明 |
|---|---|---|
| ?longqlora-llama2-7b-8k | 8192 | llama2-7bに基づいて1kステップでlongqlora-pretrain-data-54kで微調ューされました |
| ?longqlora-vicuna-13b-8k | 8192 | vicuna-13b-v1.5に基づいて1.7kステップでlongqlora-sft-data-39kで微調整されました |
| ?longqlora-llama2-7b-8k-lora | 8192 | ロラウェイト |
| ?longqlora-vicuna-13b-8k-lora | 8192 | ロラウェイト |
トレーニング構成はTrain_Argsディレクトリに保存されます。一部のパラメーターは次のとおりです。
sft :SFTタスクを真に設定した場合は、事前に設定するタスクを行います。model_max_length :ターゲットコンテキストの長さ。max_seq_length :トレーニングの最大シーケンス長は、model_max_length以下でなければなりませんlogging_steps :nステップごとにログトレーニング損失。save_steps :すべてのnステップをモデルを保存します。lora_rank :トレーニングでLORAランク。事前処理されたモデルのコンテキストの長さを拡張するllama2-7b:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlチャットモデルのコンテキストの長さvicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlロラ重量をベースモデルにマージできます。
cd script
python merge_lora.py前処理モデルの推論:
cd script/inference
python inference.pyチャットモデルとのチャット:
cd script/inference
python chat.pyLongloraがLLAMA2によってトークン化された評価データセットをダウンロードします。
| データセット |
|---|
| ?pg19-validation.bin |
| ?pg19-test.bin |
| ?Proof-Pile-Test.bin |
モデルの困惑を評価します。 load_in_4bit trueとして設定してメモリを保存できます。
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binロラ重量でモデルの困惑を評価します。
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binlongqlora-vicuna-13b-8kによって生成された例は、次のように。
長いコンテキストGenerartionの例では、入力コンテキストの長さは4096〜8192の間で、llama2の元のコンテキスト長よりも大きいです。

短いコンテキスト生成の例、モデルは、短い指示のパフォーマンスをフォローします。

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


