LongQLoRA
1.0.0
Laporan Teknis: Longqlora: Metode yang efisien dan efektif untuk memperluas panjang konteks model bahasa besar
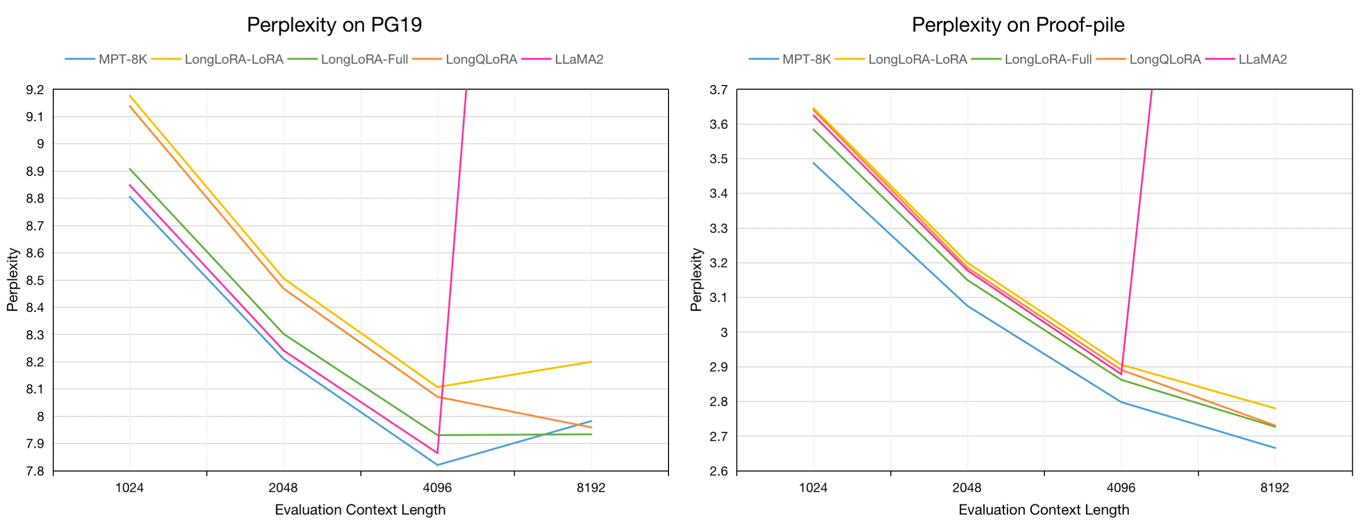
Longqlora adalah metode yang hemat memori dan efektif untuk memperluas panjang konteks model bahasa besar dengan GPU pelatihan yang lebih sedikit. Pada GPU 32GB V100 tunggal , Longqlora dapat memperpanjang panjang konteks LLAMA2 7B dan 13B dari 4096 menjadi 8192 dan bahkan menjadi 12k. Longqlora mencapai kinerja kebingungan kompetitif pada PG19 dan dataset bukti-pile setelah hanya 1000 langkah finetuning, model kami mengungguli Longlora dan sangat dekat dengan MPT-7B-8K.
Evaluasi Perplexity pada Validasi PG19 dan Dataset Tes Bukti-Pile dalam Konteks Evaluasi Panjang 8192:
| Model | Pg19 | Bukti-bajingan |
|---|---|---|
| Llama2-7b | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-lora-7b-8k | 8.20 | 2.78 |
| Longlora-full-7b-8k | 7.93 | 2.73 |
| Longqlora-7b-8k | 7.96 | 2.73 |
Evaluasi Perplexity model 7b pada validasi PG19 dan dataset tes bukti-pile dalam panjang konteks evaluasi dari 1024 hingga 8192:
Kami mencicipi sekitar 54k teks panjang dari dataset Redpajama ke model pretrained finetune, yang panjang tokennya mulai dari 4096 hingga 32768.
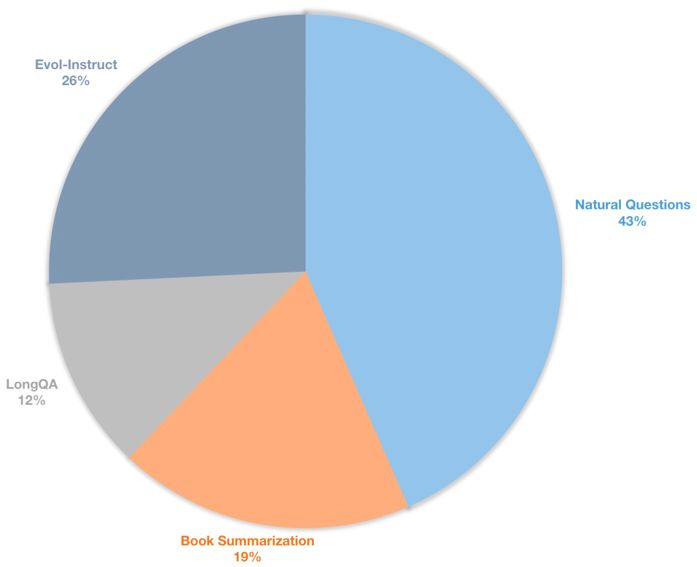
Kami juga membangun dataset instruksi konteks panjang untuk model obrolan yang diawasi. Dataset ini berisi data instruksi 39k, terutama termasuk peringkasan buku, pertanyaan alami, subset longqa dan evol-instruksi wizardlm. Untuk beradaptasi dengan panjang target 8192, jumlah token maks dari setiap data adalah 8192. Distribusi adalah sebagai berikut.
| Dataset | Keterangan |
|---|---|
| ? Longqlora-pretrain-data-54K | Termasuk 54212 data, digunakan untuk finetune pretrained model |
| ? Longqlora-sft-data-39k | Sertakan 38821 data, digunakan untuk finetune chat model |
| Model | Panjang konteks | Keterangan |
|---|---|---|
| ? Longqlora-llama2-7b-8k | 8192 | Finetuned dengan Longqlora-Pretrain-Data-54K untuk Langkah 1K Berdasarkan Llama2-7B |
| ? Longqlora-vicuna-13b-8k | 8192 | Finetuned dengan Longqlora-Sft-Data-39K untuk 1,7k Langkah Berdasarkan Vicuna-13b-V1.5 |
| ? Longqlora-llama2-7b-8k-lora | 8192 | Bobot Lora |
| ? Longqlora-vicuna-13b-8k-lora | 8192 | Bobot Lora |
Konfigurasi pelatihan disimpan di direktori Train_ARGS, beberapa parameter adalah sebagai berikut:
sft : Lakukan tugas SFT jika ditetapkan sebagai benar, jika tidak melakukan tugas pretraining.model_max_length : Panjang konteks target.max_seq_length : Panjang urutan maks dalam pelatihan, harus kurang dari atau sama dengan model_max_lengthlogging_steps : Kehilangan Log Pelatihan Setiap N Langkah.save_steps : Simpan model setiap N langkah.lora_rank : Peringkat Lora dalam pelatihan.Perpanjang panjang konteks model pretrained llama2-7b:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlPerpanjang Panjang Konteks Model Obrolan Vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlAnda dapat menggabungkan bobot lora ke model dasar:
cd script
python merge_lora.pyKesimpulan dengan model pretrained:
cd script/inference
python inference.pyObrolan dengan model obrolan:
cd script/inference
python chat.pyUnduh Dataset Evaluasi yang Dibuatkan oleh Llama2 oleh Longlora.
| Dataset |
|---|
| ? Pg19-validasi.bin |
| ? Pg19-test.bin |
| ? Proof-pile-test.bin |
Mengevaluasi kebingungan model. Anda dapat mengatur load_in_4bit sebagai benar untuk menyimpan memori:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binMengevaluasi kebingungan model dengan bobot lora:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binContoh-contoh yang dihasilkan oleh Longqlora-Vicuna-13b-8K ARS sebagai berikut.
Contoh generartion konteks panjang, panjang konteks input adalah antara 4096 dan 8192 yang lebih besar dari panjang konteks asli llama2.

Contoh generartion konteks pendek, model menjaga kinerja instruksi pendek berikut.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


