LongQLoRA
1.0.0
Технический отчет: Longqlora: эффективный и эффективный метод расширения длины контекста крупных языковых моделей
LongQlora-это эффективный и эффективный метод для расширения длины контекста больших языковых моделей с меньшим обучающим графическим процессором. На одном графическом процессоре 32 ГБ V100 Longqlora может расширять длину контекста Llama2 7b и 13b с 4096 до 8192 и даже до 12K. LongQlora достигает конкурентной производительности недоумения на PG19 и наборе данных о том, что только 1000 этапов создания, наша модель превосходит Longlora и очень близок к MPT-7B-8K.
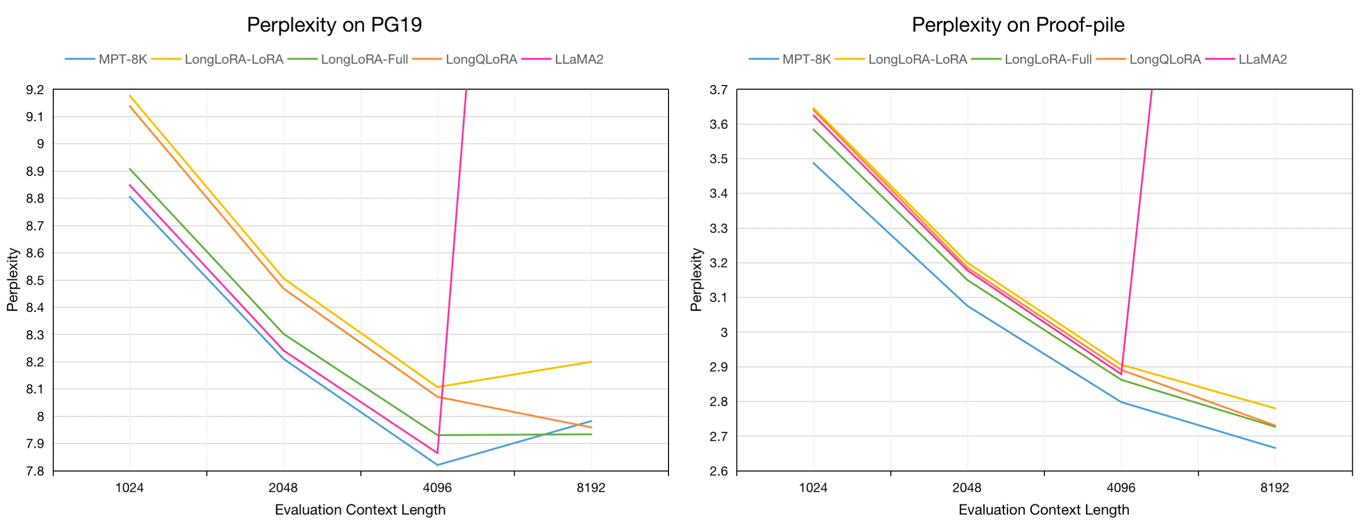
Оценка недоумения на наборе данных проверки PG19 и проверки проверки в течение длины контекста оценки 8192:
| Модель | PG19 | Доказычная |
|---|---|---|
| Llama2-7B | > 1000 | > 1000 |
| MPT-7B-8K | 7,98 | 2.67 |
| Longlora-Lora-7b-8k | 8.20 | 2.78 |
| Longlora-full-7b-8k | 7.93 | 2.73 |
| Longqlora-7b-8k | 7,96 | 2.73 |
Оценка недоумения моделей 7B на наборах данных проверки PG19 и проверки проверки в течение длины контекста оценки от 1024 до 8192:
Мы попробовали около 54 тыс. Текст от набора данных Redpajama до Minetune, предварительно проведенных, чьи токеновые длины в диапазоне от 4096 до 32768.
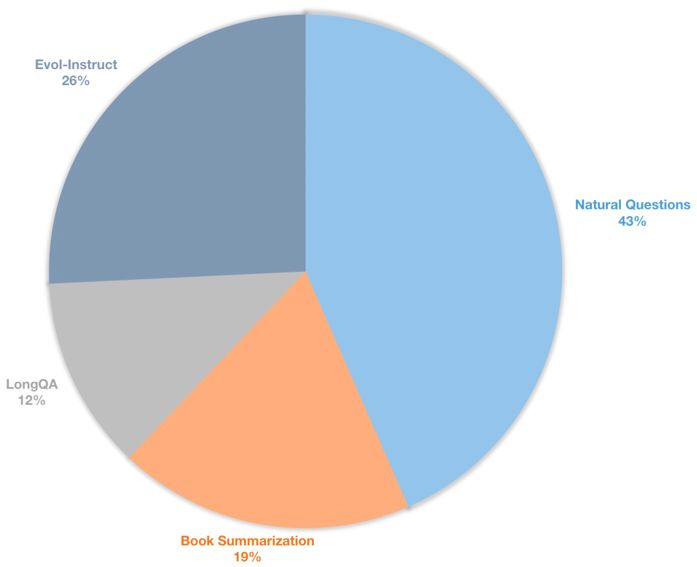
Мы также создаем длинный набор данных инструкции для контролируемых моделей чата. Этот набор данных содержит данные об инструкциях 39K, в основном включающие в себя суммирование книг, естественные вопросы, подмножество LongQA и Evol-Instruct of Wizardlm. Чтобы адаптироваться к целевой длине 8192, максимальное число токенов каждого данные составляет 8192. Распределение следующее.
| Набор данных | Описание |
|---|---|
| ? Longqlora-Pretrain-Data-54K | Включите данные 54212, используемые для Menetune Pretending Model |
| ? Longqlora-Sft-Data-39K | Включите данные 38821, используемые для модели чата Finetune |
| Модель | Контекст длины | Описание |
|---|---|---|
| ? Longqlora-Llama2-7b-8k | 8192 | Создан Longqlora-Pretrain-Data-54K для 1K шагов на основе Llama2-7B |
| ? Longqlora-Vicuna-13b-8k | 8192 | Создан Longqlora-Sft-Data-39K для 1,7 тыс. |
| ? Longqlora-Llama2-7b-8k-Lora | 8192 | Лора веса |
| ? Longqlora-Vicuna-13b-8k-Lora | 8192 | Лора веса |
Учебные конфигурации сохраняются в каталоге Train_args, некоторые параметры следующие:
sft : DO SFT Задача, если установить как истинное, в противном случае выполняйте задачу предварительной подготовки.model_max_length : целевая длина контекста.max_seq_length : максимальная длина последовательности в обучении должна быть меньше или равна model_max_lengthlogging_steps : Log Training Потеряйте каждые n шагов.save_steps : сохранить модель каждые n шагов.lora_rank : LORA Rang в тренировках.Расширить длину контекста предварительной модели Llama2-7B:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlРасширить длину контекста чата модели Vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlВы можете объединить вес LORA с базовой моделью:
cd script
python merge_lora.pyВывод с предварительной моделью:
cd script/inference
python inference.pyЧат с моделью чата:
cd script/inference
python chat.pyЗагрузите набор данных оценки, токенированный Llama2 Longlora.
| Набор данных |
|---|
| ? Pg19-validation.bin |
| ? Pg19-test.bin |
| ? Proof-Pile-test.bin |
Оценить недоумение моделей. Вы можете установить load_in_4bit как true, чтобы сохранить память:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binОцените недоумение моделей с весами LORA:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binПримеры, полученные LongQlora-Vicuna-13B-8K ARS следующим образом.
Примеры длинного контекста, длина входного контекста находится между 4096 и 8192, которые больше, чем исходная длина контекста Llama2.

Примеры короткого контекста, модель, сохраняйте производительность короткой инструкции следующей.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


