LongQLoRA
1.0.0
기술 보고서 : LongQlora : 대형 언어 모델의 상황 길이를 확장하는 효율적이고 효과적인 방법
LongQlora는 훈련이 적은 GPU가 적은 대형 언어 모델의 컨텍스트 길이를 확장하는 메모리 효율적이고 효과적인 방법입니다. 단일 32GB V100 GPU에서 Longqlora는 LLAMA2 7B 및 13B의 컨텍스트 길이를 4096 내지 8192로, 심지어 12K로 확장 할 수 있습니다. LongQlora는 1000 개의 Finetuning 단계 후에 PG19 및 Proof-Pile DataSet에서 경쟁력있는 당연한 성능을 달성하며, 모델은 Longlora를 능가하고 MPT-7B-8K에 매우 가깝습니다.
8192의 평가 컨텍스트 길이에서 PG19 검증 및 교정 파일 테스트 데이터 세트에 대한 평가 당함 :
| 모델 | PG19 | 증명서 |
|---|---|---|
| llama2-7b | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-Lora-7B-8K | 8.20 | 2.78 |
| longlora-ull-7b-8k | 7.93 | 2.73 |
| longqlora-7b-8k | 7.96 | 2.73 |
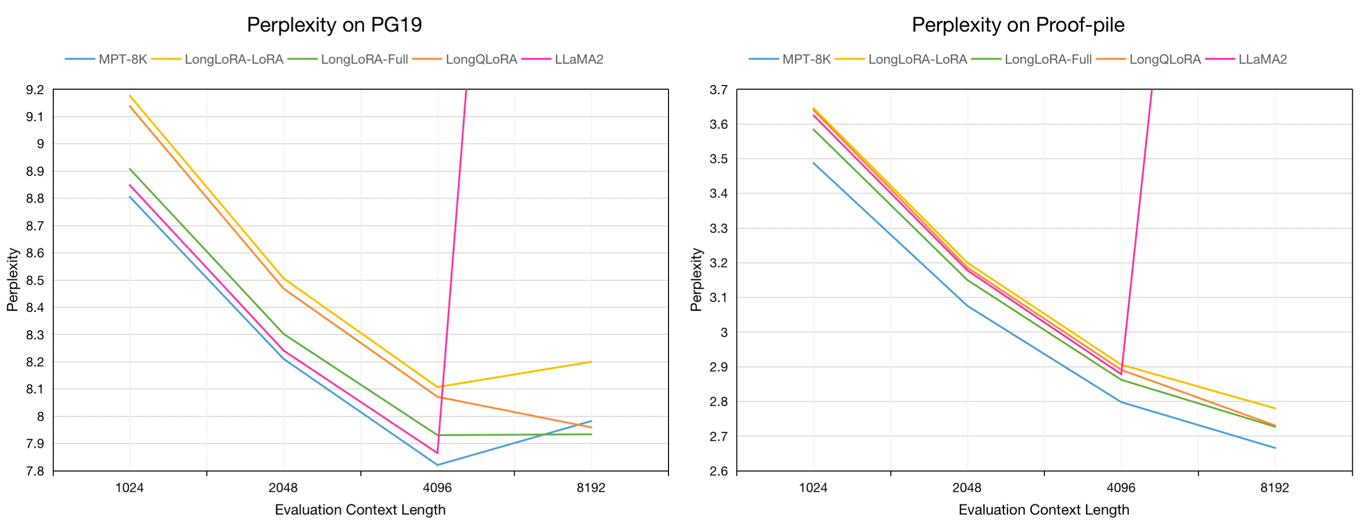
1024에서 8192까지의 평가 컨텍스트 길이에서 PG19 검증 및 증거 파일 테스트 데이터 세트에 대한 7B 모델의 평가 당도 :
우리는 Redpajama 데이터 세트에서 4096 ~ 32768 범위의 토큰 길이 범위의 사전 치료 된 모델에 대한 약 54k 길이의 텍스트를 샘플링합니다.
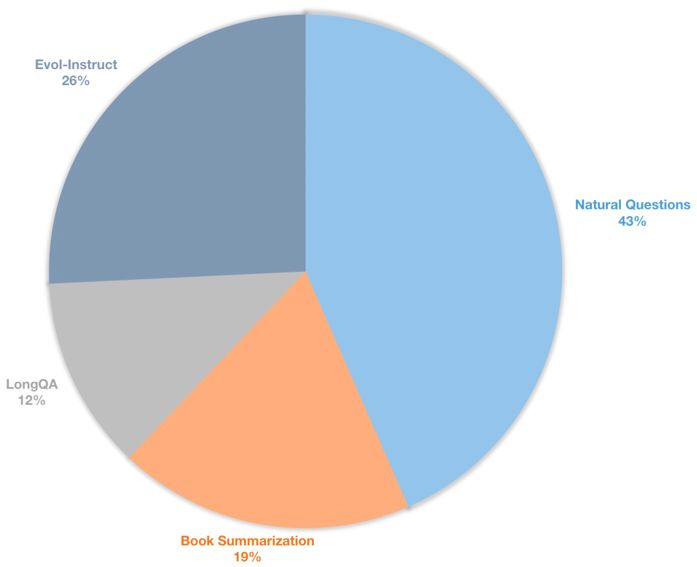
우리는 또한 감독 된 채팅 모델을위한 긴 컨텍스트 명령 데이터 세트를 구축합니다. 이 데이터 세트에는 주로 책 요약, 자연스러운 질문, LongQA의 하위 집합 및 Wizardlm의 Evol-Instruct를 포함한 39K 명령 데이터가 포함되어 있습니다. 목표 길이 8192에 적응하기 위해 각 데이터의 최대 토큰 수는 8192입니다. 분포는 다음과 같습니다.
| 데이터 세트 | 설명 |
|---|---|
| ? longqlora-pretrain-data-54k | 사전 미세 모델을 미세한 경우 54212 데이터를 포함하십시오 |
| ? longqlora-sft-data-39k | 채팅 모델을 미세 조정하는 데 사용되는 38821 데이터를 포함하십시오 |
| 모델 | 컨텍스트 길이 | 설명 |
|---|---|---|
| ? longqlora-llama2-7b-8k | 8192 | LLAMA2-7B를 기반으로 1K 단계에 대해 LongQlora-Pretrain-Data-54K로 Finetuned |
| ? longqlora-vicuna-13b-8k | 8192 | vicuna-13b-v1.5를 기반으로 1.7k 단계에 대해 longqlora-sft-data-39k로 Finetuned |
| ? longqlora-llama2-7b-8k-lora | 8192 | 로라 무게 |
| ? longqlora-vicuna-13b-8k-lora | 8192 | 로라 무게 |
교육 구성은 Train_args 디렉토리에 저장되며 일부 매개 변수는 다음과 같습니다.
sft : TRUE로 설정된 경우 SFT 작업을 수행하십시오. 그렇지 않으면 사전 연상 작업을 수행하십시오.model_max_length : 대상 컨텍스트 길이.max_seq_length : 훈련의 최대 시퀀스 길이는 model_max_length보다 작거나 동일해야합니다.logging_steps : 모든 n 단계마다 로그 훈련 손실.save_steps : 모든 n 단계마다 모델을 저장하십시오.lora_rank : LORA는 훈련에서 순위를 매겼습니다.사전에 걸린 모델 LLAMA2-7B의 컨텍스트 길이 확장 :
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yaml채팅 모델의 컨텍스트 길이 확장 vicuna-13b :
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlLORA 무게를 기본 모델로 병합 할 수 있습니다.
cd script
python merge_lora.py사전에 걸린 모델과의 추론 :
cd script/inference
python inference.py채팅 모델로 채팅 :
cd script/inference
python chat.pyllama2가 Longlora에 의해 토큰 화 된 평가 데이터 세트를 다운로드하십시오.
| 데이터 세트 |
|---|
| ? PG19- 검증 .BIN |
| ? pg19-test.bin |
| ? 증거-테스트 |
모델의 당혹감을 평가하십시오. 메모리를 저장하기 위해 load_in_4bit true로 설정할 수 있습니다.
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binLORA 가중치로 모델의 당혹감을 평가하십시오.
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binlongqlora-vicuna-13b-8k ars에 의해 생성 된 예.
긴 맥락 연소의 예에서, 입력 컨텍스트 길이는 4096에서 8192 사이이며, 이는 원래의 컨텍스트 길이보다 큰 LLAMA2입니다.

짧은 맥락 연소의 예, 모델은 짧은 지시의 성능을 유지합니다.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


