LongQLoRA
1.0.0
Technischer Bericht: LongQlora: Effiziente und effektive Methode zur Erweiterung der Kontextlänge großer Sprachmodelle
LongQlora ist eine speichereffiziente und effektive Methode, um die Kontextlänge großer Sprachmodelle mit weniger Trainings-GPUs zu erweitern. Bei einer einzelnen 32 GB V100 GPU kann LongQlora die Kontextlänge von LLAMA2 7B und 13B von 4096 auf 8192 und sogar auf 12K verlängern. LongQlora erzielt nach nur 1000 Finetuning-Schritten eine wettbewerbsfähige Verwirrungsleistung auf PG19- und Proof-Pile-Datensatz. Unser Modell übertrifft Longlora und liegt sehr nahe an MPT-7B-8K.
Bewertung Verwirrung bei PG19-Validierungs- und Proof-Pile-Testdatensätzen in der Bewertung der Kontextlänge von 8192:
| Modell | PG19 | Proof-Pile |
|---|---|---|
| LAMA2-7B | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-lora-7b-8k | 8.20 | 2.78 |
| Longlora-full-7b-8k | 7.93 | 2.73 |
| Longqlora-7b-8k | 7.96 | 2.73 |
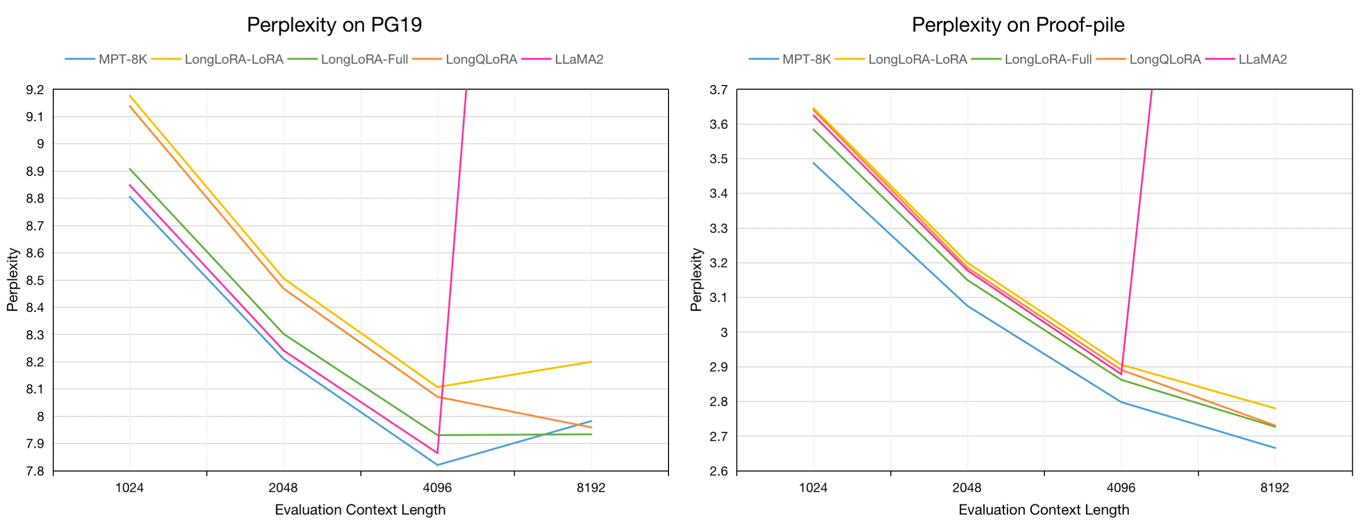
Bewertung der Verwirrung von 7B-Modellen zur PG19-Validierung und den Proof-Pile-Testdatensätzen in der Bewertungskontextlänge von 1024 bis 8192:
Wir probieren ungefähr 54.000 langen Text vom Redpajama -Datensatz bis hin zu Fintune PretRained Models, deren Tokenlängen zwischen 4096 und 32768 reichen.
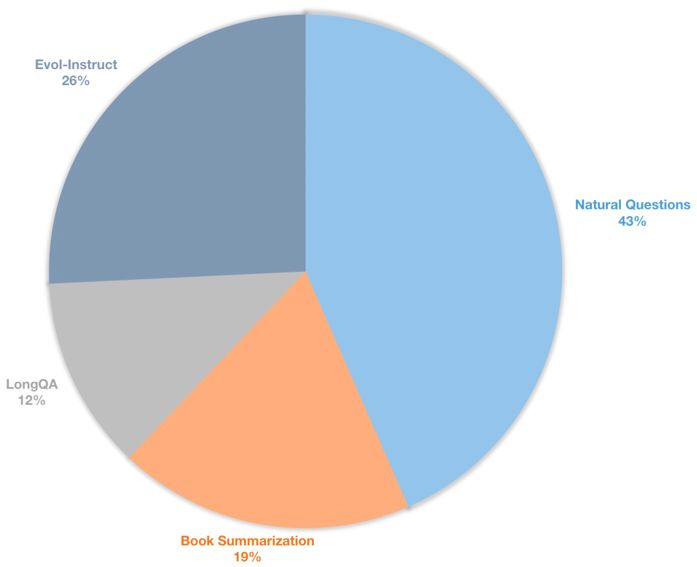
Wir erstellen auch einen langen Kontextanweisungsdatensatz für beaufsichtigte Finetuning -Chat -Modelle. Dieser Datensatz enthält 39K-Anweisungsdaten, hauptsächlich einschließlich Buchzusammenfassungen, natürliche Fragen, Untergruppe von LongQA und EVOL-Instruction of Assistent. Um sich an die Ziellänge von 8192 anzupassen, beträgt die maximale Token -Anzahl jeder Daten 8192. Die Verteilung ist wie folgt.
| Datensatz | Beschreibung |
|---|---|
| ? Longqlora-Grund-DATA-54K | Fügen Sie 54212 Daten ein, die zum Finetune -vorbereiteten Modell verwendet werden |
| ? Longqlora-sft-data-39k | Fügen Sie 38821 Daten ein, die zum Finetune -Chat -Modell verwendet werden |
| Modell | Kontextlänge | Beschreibung |
|---|---|---|
| ? Longqlora-Llama2-7b-8k | 8192 | Mit longqlora-pretrain-data-54k für 1k-Schritte basierend auf LLAMA2-7b beendet |
| ? Longqlora-vicuna-13b-8k | 8192 | Mit longqlora-sft-data-39k für 1,7.000 Schritte basierend auf Vicuna-13b-V1.5 beendet |
| ? LONGQLORA-LLLAMA2-7B-8K-LORA | 8192 | Lora Gewichte |
| ? Longqlora-vicuna-13b-8k-lora | 8192 | Lora Gewichte |
Die Trainingskonfigurationen werden im Verzeichnis des Train_args gespeichert. Einige Parameter sind wie folgt:
sft : Machen Sie die SFT -Aufgabe, wenn Sie als wahr festgelegt sind, andernfalls machen Sie Vorbereitungsaufgaben.model_max_length : Die Zielkontextlänge.max_seq_length : Die MAX -Sequenzlänge im Training sollte weniger als oder gleich der model_max_length seinlogging_steps : Log -Trainingsverlust jeder N -Schritte.save_steps : Speichern Sie das Modell jeder N -Schritte.lora_rank : Der Lora -Rang im Training.Erweitern Sie die Kontextlänge des vorbereiteten Modells LLAMA2-7B:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlErweitern Sie die Kontextlänge des Chat-Modells Vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlSie können das Lora -Gewicht mit dem Basismodell zusammenführen:
cd script
python merge_lora.pyInferenz mit vorbereitetem Modell:
cd script/inference
python inference.pyChat mit Chat -Modell:
cd script/inference
python chat.pyLaden Sie den von LLAMA2 von Longlora tokenisierten Evaluierungsdatensatz herunter.
| Datensatz |
|---|
| ? Pg19-Validation.bin |
| ? PG19-Test.bin |
| ? Proof-Pile-Test.bin |
Bewerten Sie die Verwirrung von Modellen. Sie können load_in_4bit als wahr einstellen, um den Speicher zu speichern:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binBewerten Sie die Verwirrung von Modellen mit Lora -Gewichten:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binDie von longqlora-vicuna-13b-8k ARS erzeugten Beispiele wie folgt.
Beispiele für den langen Kontextgenerarieren, die Eingangskontextlängen liegen zwischen 4096 und 8192, die größer als die ursprüngliche Kontextlänge von llama2 sind.

Beispiele für kurze Kontext -Generalion, Modell halten die Leistung der kurzen Anweisungen.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


