LongQLoRA
1.0.0
Informe técnico: Longqlora: método eficiente y efectivo para extender la longitud de contexto de los modelos de idiomas grandes
Longqlora es un método eficiente y efectivo de la memoria para extender la longitud del contexto de los modelos de lenguaje grandes con menos GPU de capacitación. En una sola GPU de 32 GB V100 , Longqlora puede extender la longitud de contexto de LLAMA2 7B y 13B de 4096 a 8192 e incluso a 12k. Longqlora logra un rendimiento de perplejidad competitiva en PG19 y un conjunto de datos de prueba de prueba Después de solo 1000 pasos finos, nuestro modelo supera a Longlora y está muy cerca de MPT-7B-8K.
Perplejidad de evaluación en los conjuntos de datos de validación y prueba de prueba de prueba PG19 en la longitud del contexto de evaluación de 8192:
| Modelo | PG19 | Prueba |
|---|---|---|
| Llama2-7b | > 1000 | > 1000 |
| MPT-7B-8K | 7.98 | 2.67 |
| Longlora-lora-7b-8k | 8.20 | 2.78 |
| Longlora-Full-7B-8K | 7.93 | 2.73 |
| Longqlora-7b-8k | 7.96 | 2.73 |
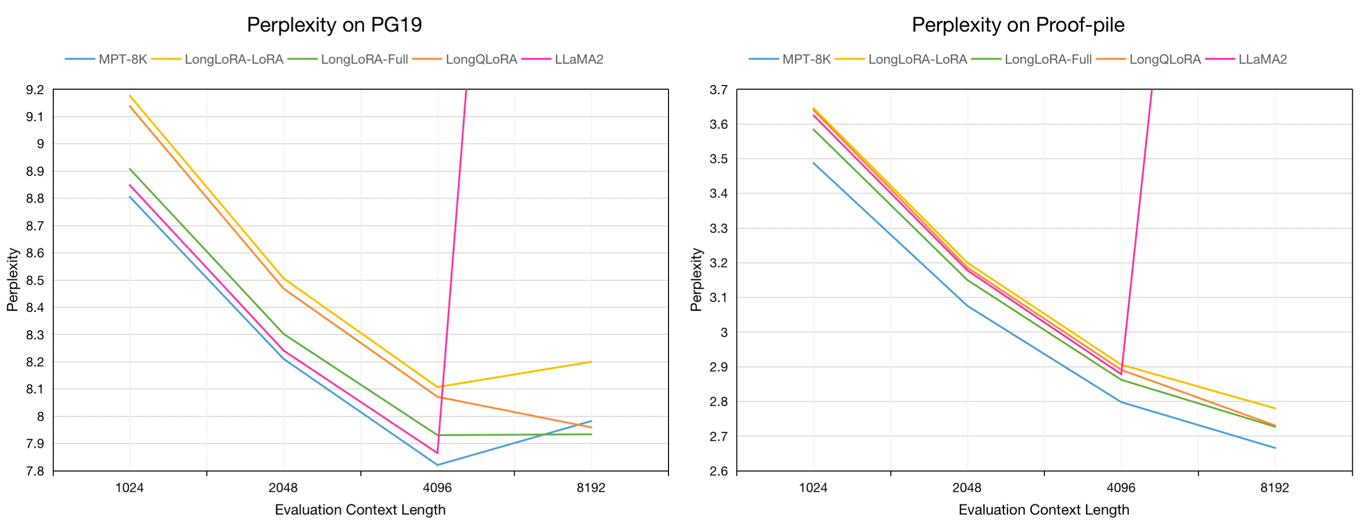
Perplejidad de evaluación de los modelos 7B en los conjuntos de datos de validación de PG19 y prueba de prueba en la longitud del contexto de evaluación de 1024 a 8192:
Muestra un texto de aproximadamente 54k de largo desde el conjunto de datos de Redpajama hasta los modelos Finetune Pretrados
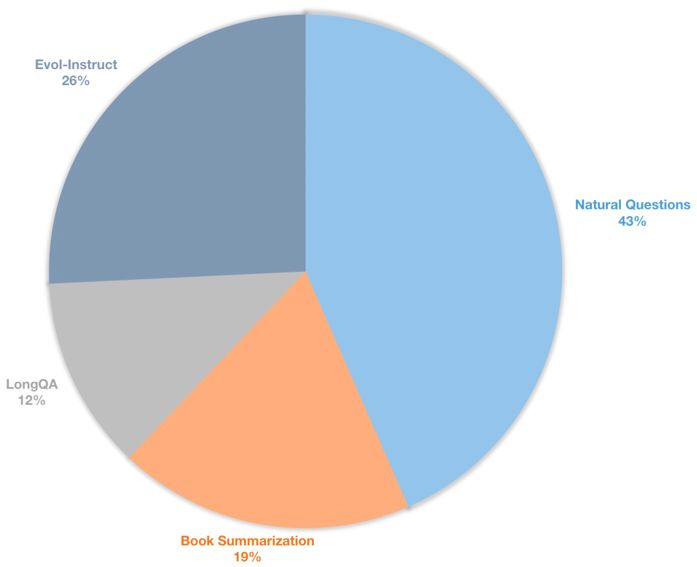
También creamos un conjunto de datos de instrucciones de contexto largo para modelos de chat de sintonización supervisados. Este conjunto de datos contiene datos de instrucciones de 39k, principalmente incluyendo resumen de libros, preguntas naturales, subconjunto de Longqa y Evol-Instructo de WizardLM. Para adaptarse a la longitud objetivo de 8192, el número de token máximo de cada datos es 8192. La distribución es la siguiente.
| Conjunto de datos | Descripción |
|---|---|
| ? Longqlora-pretrain-data-54k | Incluir datos 54212, utilizados para finetune el modelo previado |
| ? Longqlora-sft-data-39k | Incluye datos 38821, utilizados para Finetune Chat Model |
| Modelo | Longitud de contexto | Descripción |
|---|---|---|
| ? Longqlora-llama2-7b-8k | 8192 | Fineting con longqlora-pretrain-data-54k para 1k pasos basados en LLAMA2-7B |
| ? Longqlora-Vicuna-13B-8K | 8192 | Finetizado con Longqlora-Sft-Data-39k para 1.7k pasos basados en Vicuna-13B-V1.5 |
| ? Longqora-llama2-7b-8K-lora | 8192 | Pesos de Lora |
| ? Longqlora-Vicuna-13B-8K-Lora | 8192 | Pesos de Lora |
Las configuraciones de entrenamiento se guardan en el directorio Train_ARGS, algunos parámetros son los siguientes:
sft : Do SFT Tarea si se establece como verdadero, de lo contrario, realice la tarea previa a la altura.model_max_length : la longitud del contexto de destino.max_seq_length : la longitud de secuencia máxima en el entrenamiento, debe ser menor o igual a model_max_lengthlogging_steps : Registre la pérdida de entrenamiento cada n pasos.save_steps : guarde el modelo cada n pasos.lora_rank : El rango de Lora en el entrenamiento.Extender la longitud del contexto del modelo de petróleo Llama2-7b:
deepspeed train.py --train_args_file ./train_args/llama2-7b-pretrain.yamlExtender la duración del contexto del modelo de chat vicuna-13b:
deepspeed train.py --train_args_file ./train_args/vicuna-13b-sft.yamlPuede fusionar el peso de Lora al modelo base:
cd script
python merge_lora.pyInferencia con el modelo previamente:
cd script/inference
python inference.pyChat con el modelo de chat:
cd script/inference
python chat.pyDescargue el conjunto de datos de evaluación tokenizado por LLAMA2 por Longlora.
| Conjunto de datos |
|---|
| ? PG19-Validación. Bin |
| ? Pg19-test.bin |
| ? |
Evaluar la perplejidad de los modelos. Puede establecer load_in_4bit como verdadero para guardar la memoria:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binEvaluar la perplejidad de los modelos con pesos de lora:
cd script/evaluate
python evaluate.py
--batch_size 1
--base_model YeungNLP/LongQLoRA-Llama2-7b-8k
--peft_model LongQLoRA-Llama2-7b-8k-lora
--seq_len 8192
--context_size 8192
--sliding_window 8192
--data_path pg19-validation.binLos ejemplos generados por Longqlora-Vicuna-13B-8K ARS de la siguiente manera.
Ejemplos de Generación de contexto largo, las longitudes de contexto de entrada están entre 4096 y 8192, que son más grandes que la longitud de contexto original de Llama2.

Ejemplos de contexto corto GeneralTion, el modelo mantiene el rendimiento de la instrucción corta a continuación.

@misc{yang2023longqlora,
title={LongQLoRA: Efficient and Effective Method to Extend Context Length of Large Language Models},
author={Jianxin Yang},
year={2023},
eprint={2311.04879},
archivePrefix={arXiv},
primaryClass={cs.CL}
}


