univnet
1.0.0
Univnet: นักร้องประสาทที่มีการแยกแยะความละเอียดหลายสเปคตรัม
นี่คือการใช้งาน Pytorch อย่างไม่เป็นทางการของ Jang และคณะ (Kakao), Univnet
อัปโหลดตัวอย่างเสียง!
ทั้งผลลัพธ์ของ UnivNet-C16 และ C32 และน้ำหนักที่ได้รับการฝึกอบรมมาก่อนได้รับการอัปโหลดแล้ว
สำหรับทั้งสองรุ่นการใช้งานของเราตรงกับคะแนนวัตถุประสงค์ (PESQ และ RMSE) ของกระดาษต้นฉบับ
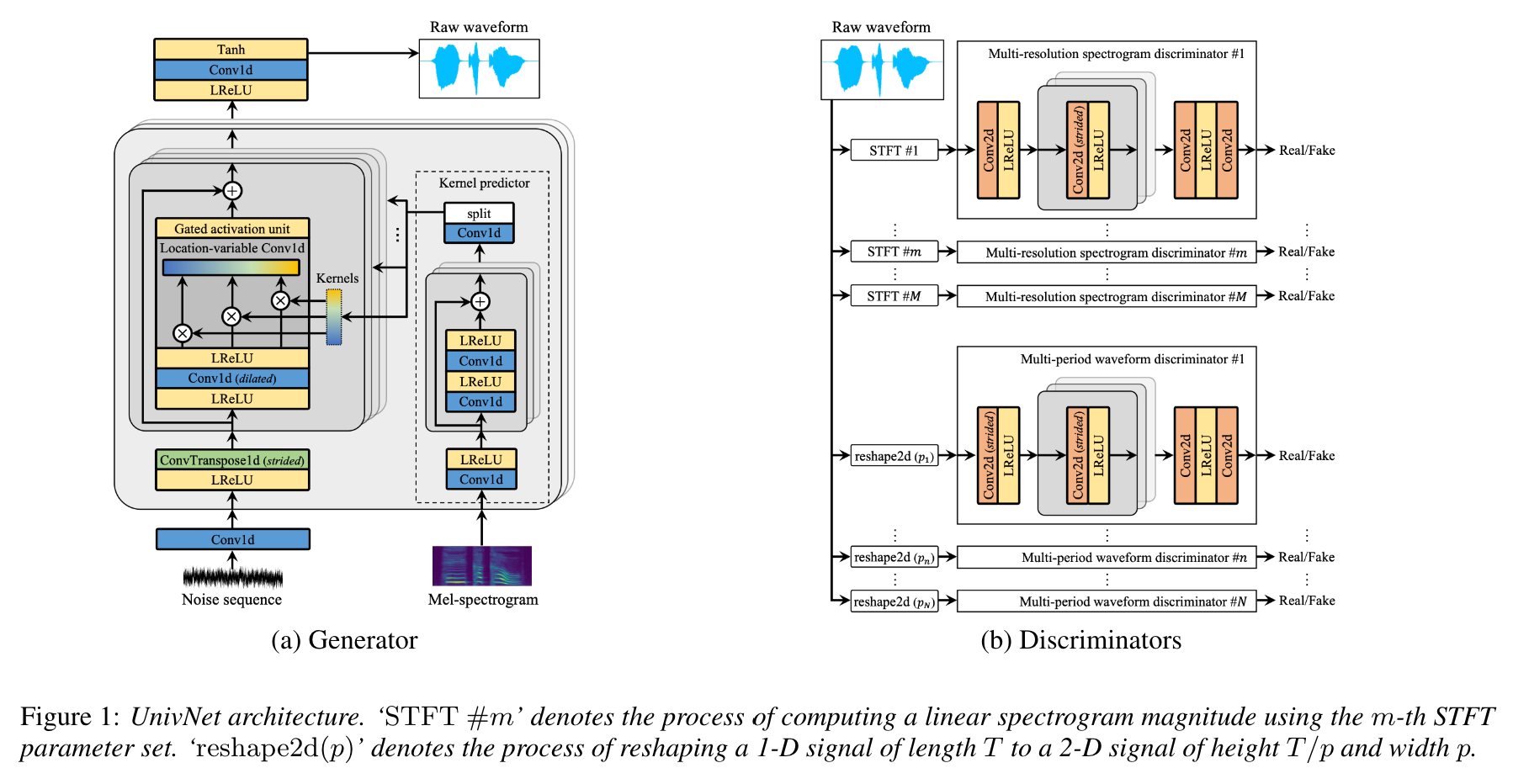
ตามที่ผู้เขียนบทความ UNIVNET ได้รับผลลัพธ์ที่ดีที่สุดในหมู่นักร้องประสาทที่ใช้ GAN เมื่อเร็ว ๆ นี้ (รวมถึง HIFI-GAN) รวมถึง HIFI-GAN ที่มีประสิทธิภาพสูงกว่าในการประเมินอัตนัย ความเร็วการอนุมานของมันเร็วกว่า HIFI-GAN 1.5 เท่า
พื้นที่เก็บข้อมูลนี้ใช้ฟังก์ชัน mel-spectrogram เดียวกันกับ HIFI-GAN อย่างเป็นทางการซึ่งเข้ากันได้กับ NVIDIA/TACOTRON2
การคำนวณค่าพารามิเตอร์ MEL เริ่มต้นของเรานั้นอยู่ด้านล่างตามกระดาษต้นฉบับ
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0คุณสามารถปรับเปลี่ยน hyperparameters ให้เข้ากันได้กับโมเดลอะคูสติกของคุณ
ความต้องการการดำเนินการตามการพึ่งพา
pip install -r requirements.txtการเตรียมข้อมูล
datasets/LibriTTS/train-clean-360 หมายเหตุ: mel-spectrograms ที่คำนวณจากไฟล์เสียงจะถูกบันทึกเป็น **.mel ในตอนแรกจากนั้นโหลดจากดิสก์หลังจากนั้น
เตรียมข้อมูลเมตา
ตามรูปแบบจาก NVIDIA/TACOTRON2 เมทาดาทาควรจัดรูปแบบเป็น:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
ข้อมูลเมตาของรถไฟ/การตรวจสอบความถูกต้องสำหรับ Libritts Train-Clean-360 Split และได้เตรียมไว้แล้วใน datasets/metadata 5% ของคำพูดที่ทำความสะอาดรถไฟ-360 ถูกสุ่มสุ่มเพื่อตรวจสอบความถูกต้อง
เนื่องจากรุ่นนี้เป็นคำแนะนำจึง ไม่ได้ ใช้การถอดเสียงในระหว่างการฝึกอบรม
การเตรียมไฟล์การกำหนดค่า
เรียกใช้ cp config/default_c32.yaml config/config.yaml จากนั้นแก้ไข config.yaml
เขียนเส้นทางรูทของรถไฟ/การตรวจสอบในส่วน data ข้อมูลตัวโหลดดาต้าพาร์ทิเตอร์ของไฟล์ภายในเส้นทางซ้ำ
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirเราให้ข้อมูลเมตาเริ่มต้นสำหรับการแยกรถไฟ-360
แก้ไข channel_size ใน gen เพื่อสลับระหว่าง UnivNet-C16 และ C32
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2การฝึกอบรม
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNบอร์ดบอร์ด
tensorboard --logdir logs/ หากคุณใช้ Tensorboard บนเครื่องรีโมตคุณสามารถเปิดหน้า Tensorboard โดยเพิ่ม --bind_all ตัวเลือก
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHคุณสามารถดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมล่วงหน้าได้จากลิงค์ Google Drive ด้านล่าง แบบจำลองได้รับการฝึกฝนเกี่ยวกับการแยกรถไฟ-360 Libritts
ดูตัวอย่างเสียงที่ https://mindslab-ai.github.io/univnet/
เราประเมินแบบจำลองของเราด้วยชุดการตรวจสอบความถูกต้อง
| แบบอย่าง | pesq (↑) | RMSE (↓) | ขนาดรุ่น |
|---|---|---|---|
| hifi-gan v1 | 3.54 | 0.423 | 14.01m |
| univnet-C16 อย่างเป็นทางการ | 3.59 | 0.337 | 4.00m |
| Univnet-C16 ของเรา | 3.60 | 0.317 | 4.00m |
| univnet-C32 อย่างเป็นทางการ | 3.70 | 0.316 | 14.86m |
| Univnet-C32 ของเรา | 3.68 | 0.304 | 14.87m |
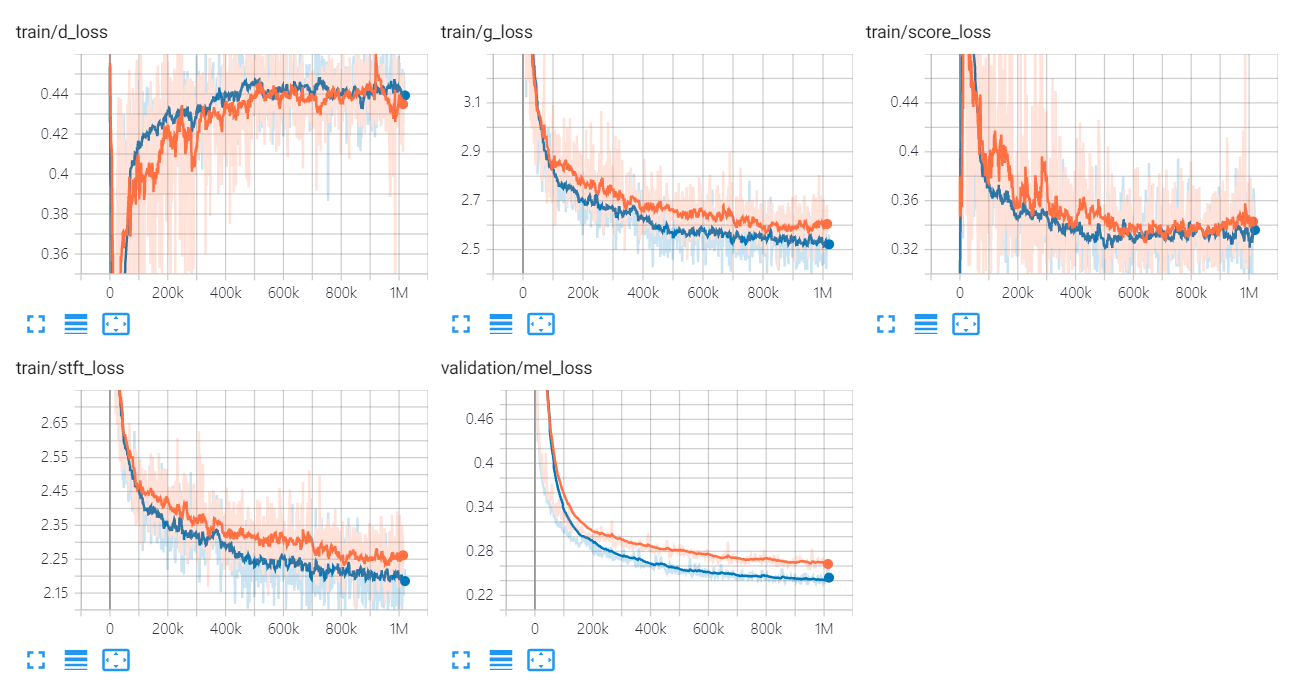
กราฟการสูญเสียของ Univnet มีการระบุไว้ด้านล่าง
กราฟสีส้มและสีน้ำเงินบ่งบอกถึง C16 และ C32 ตามลำดับ
ผู้เขียนการนำไปใช้คือ:
ผู้มีส่วนร่วมคือ:
ขอขอบคุณเป็นพิเศษ
รหัสนี้ได้รับอนุญาตภายใต้ใบอนุญาต BSD 3-cluse
เราอ้างถึงรหัสและที่เก็บต่อไปนี้
เอกสาร
ชุดข้อมูล


