univnet
1.0.0
Univnet : 고 충실도 파형 생성을위한 다중 해상도 스펙트로 그램 판별자가있는 신경 보코더
이것은 Jang et al. (Kakao), Univnet .
오디오 샘플이 업로드되었습니다!
Univnet-C16 및 C32 결과와 미리 훈련 된 가중치가 모두 업로드되었습니다.
두 모델 모두 구현은 원본 용지의 목표 점수 (PESQ 및 RMSE)와 일치합니다.
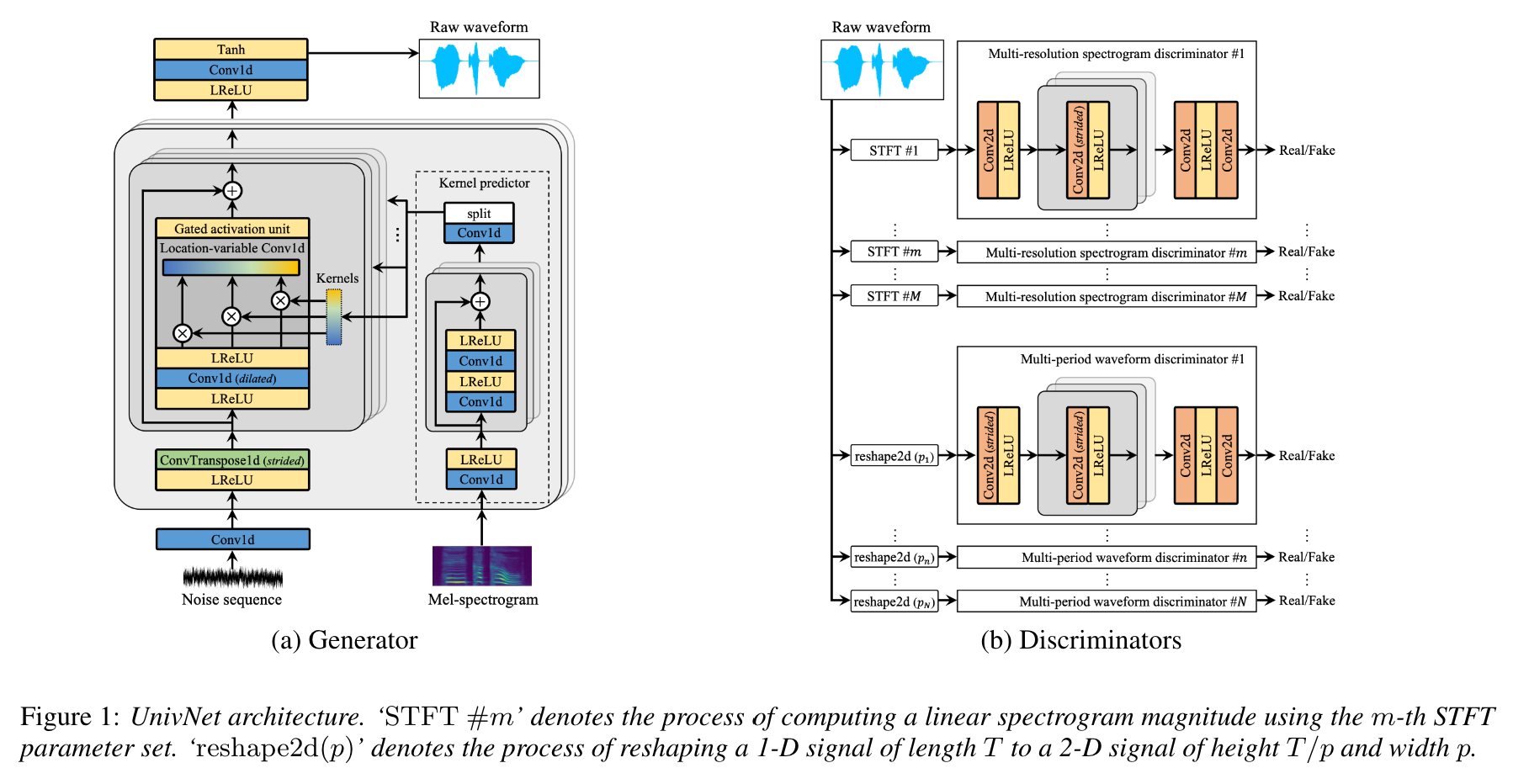
이 논문의 저자에 따르면, Univnet은 최근 GAN 기반 신경 보코더 (Hifi-Gan 포함)와 주관적인 평가에서 Hifi-Gan보다 우수한 객관적인 결과를 얻었습니다. 또한 추론 속도는 Hifi-Gan보다 1.5 배 빠릅니다.
이 저장소는 NVIDIA/TACOTRON2와 호환되는 공식 HIFI-GAN과 동일한 MEL- 스피어 그램 기능을 사용합니다.
기본 MEL 계산과 파라미터는 원래 용지를 따르는 다음과 같습니다.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0음향 모델과 호환되도록 하이퍼 파라미터를 수정할 수 있습니다.
구현은 종속성에 따라 필요합니다.
pip install -r requirements.txt데이터 준비
datasets/LibriTTS/train-clean-360 에 내용을 압축하고 배치하십시오. 참고 : 오디오 파일에서 계산 된 Mel-Spectrograms는 처음에는 **.mel 로 저장된 다음 나중에 디스크에서로드됩니다.
메타 데이터 준비
nvidia/tacotron2의 형식에 따라 메타 데이터는 다음과 같이 형식화되어야합니다.
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Libritts의 열차/검증 메타 데이터 Train-Clean-360 스플릿이며 이미 datasets/metadata 에서 준비되어 있습니다. 기차 청소 -360 발화의 5%가 검증을 위해 무작위로 샘플링되었습니다.
이 모델은 보코더이므로 훈련 중에 전 사체가 사용되지 않습니다 .
구성 파일 준비
cp config/default_c32.yaml config/config.yaml 실행 한 다음 config.yaml 편집하십시오
data 섹션에 열차/검증의 루트 경로를 기록하십시오. 데이터 로더는 경로 내 파일 목록을 재귀 적으로 구문 분석합니다.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirLibritts Train-Clean-360 스플릿의 기본 메타 데이터를 제공합니다.
Univnet-C16과 C32 사이를 전환하도록 gen 에서 channel_size 수정하십시오.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2훈련
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUN텐서 보드
tensorboard --logdir logs/ 원격 컴퓨터에서 텐서 보드를 실행중인 경우 --bind_all 옵션을 추가하여 Tensorboard 페이지를 열 수 있습니다.
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATH아래의 Google 드라이브 링크에서 미리 훈련 된 모델을 다운로드 할 수 있습니다. 이 모델은 Libritts Train-Clean-360 분할에서 훈련되었습니다.
https://mindslab-ai.github.io/univnet/에서 오디오 샘플을 참조하십시오.
검증 세트로 모델을 평가했습니다.
| 모델 | PESQ (↑) | RMSE (↓) | 모델 크기 |
|---|---|---|---|
| Hifi-gan v1 | 3.54 | 0.423 | 14.01m |
| 공식 Univnet-C16 | 3.59 | 0.337 | 4.00m |
| Univnet-C16 | 3.60 | 0.317 | 4.00m |
| 공식 Univnet-C32 | 3.70 | 0.316 | 14.86m |
| Univnet-C32 | 3.68 | 0.304 | 14.87m |
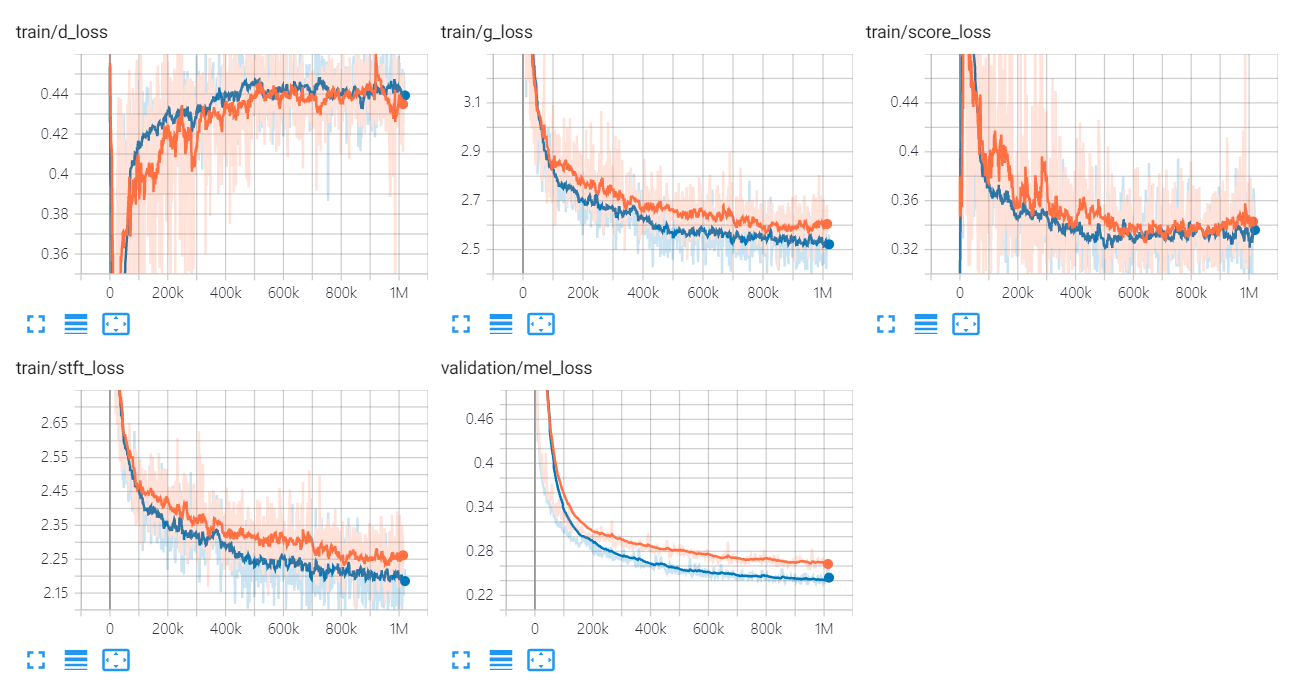
Univnet의 손실 그래프는 다음과 같습니다.
오렌지 및 파란색 그래프는 각각 C16 및 C32를 나타냅니다.
구현 저자는 다음과 같습니다.
기고자는 다음과 같습니다.
특별한 감사
이 코드는 BSD 3-Clause 라이센스에 따라 라이센스가 부여됩니다.
우리는 다음과 같은 코드와 저장소를 참조했습니다.
서류
데이터 세트


