univnet
1.0.0
UNIVNET:高忠実度の波形生成のための多解像度分光図判別器を備えたニューラルボコーダー
これは、Jang et alの非公式のPytorch実装です。 (kakao)、univnet 。
オーディオサンプルがアップロードされます!
Univnet-C16とC32の両方の結果と事前に訓練された重みがアップロードされています。
両方のモデルについて、実装は元の論文の客観的スコア(PESQおよびRMSE)と一致します。
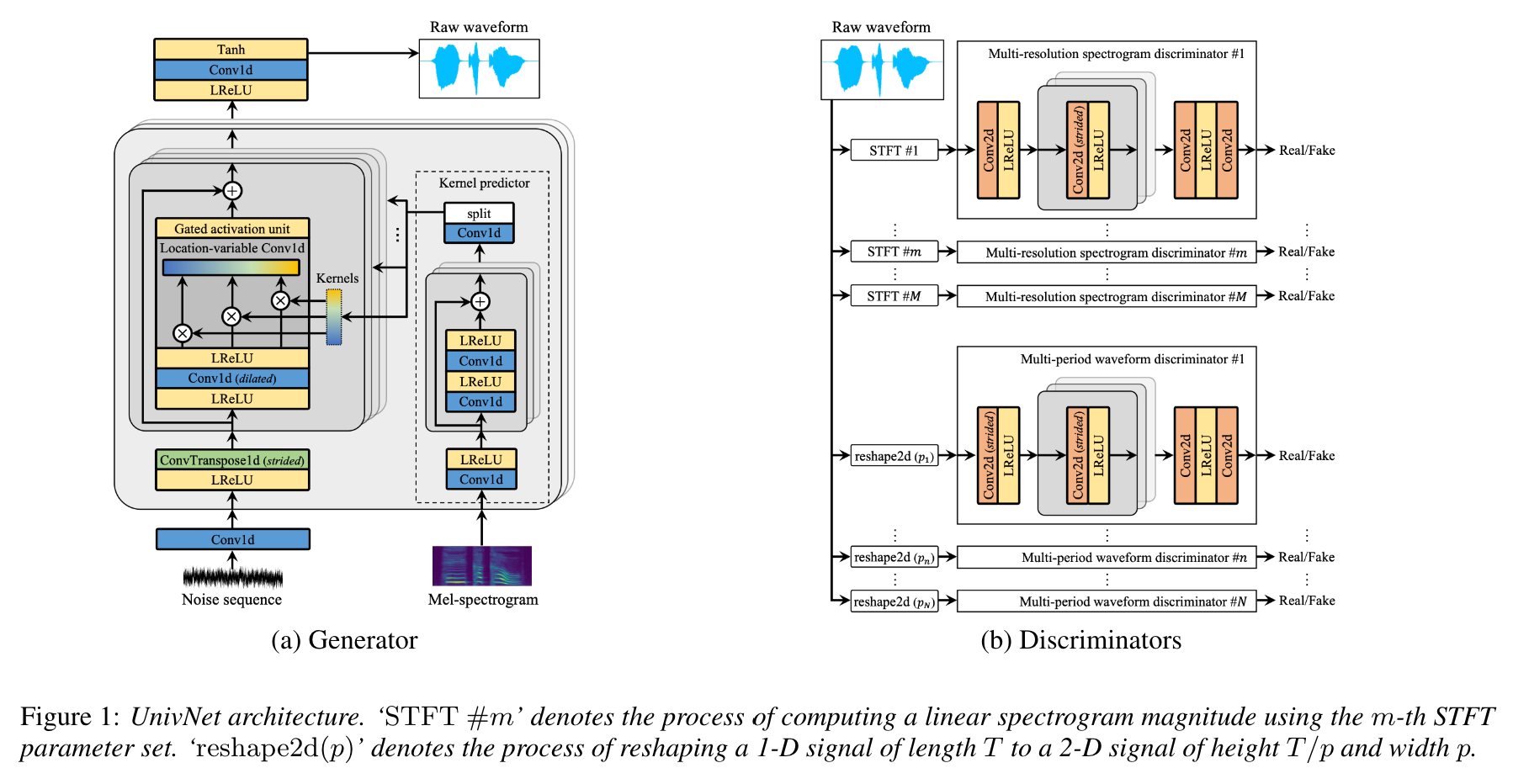
この論文の著者によると、Univnetは、最近のGANベースのニューラルボコーダー(HIFI-GANを含む)の間で最良の客観的な結果を取得し、主観的評価でHIFI-GANを上回った。また、その推論速度はHifi-Ganの1.5倍高速です。
このリポジトリは、Nvidia/Tacotron2と互換性のある公式Hifi-Ganと同じMelspectrogram機能を使用しています。
デフォルトのMEL計算ハイパーパラメーターは、元の論文に従って以下のとおりです。
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0ハイパーパラメータを変更して、音響モデルと互換性があります。
依存関係に従う必要があります。
pip install -r requirements.txtデータの準備
datasets/LibriTTS/train-clean-360の下に配置します。注:オーディオファイルから計算されたメルセプレクトログラムは、最初は**.melとして保存され、その後ディスクからロードされます。
メタデータの準備
nvidia/tacotron2の形式に従って、メタデータは次のようにフォーマットする必要があります。
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Libritts Train-Clean-360分割の列車/検証メタデータ。 datasets/metadataですでに準備されています。トレインクリーン-360発話の5%は、検証のためにランダムにサンプリングされました。
このモデルはボコーダーであるため、トランプスクリプトはトレーニング中に使用されません。
構成ファイルの準備
cp config/default_c32.yaml config/config.yamlを実行し、 config.yamlを編集します
dataセクションにトレイン/検証のルートパスを書き留めます。データローダーは、パス内のファイルのリストを再帰的に解析します。
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirLibritts Train-Clean-360分割のデフォルトのメタデータを提供します。
genのchannel_size変更して、Univnet-C16とC32を切り替えます。
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2トレーニング
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNテンソルボード
tensorboard --logdir logs/リモートマシンでテンソルボードを実行している場合は、 --bind_allオプションを追加してテンソルボードページを開くことができます。
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATH以下のGoogleドライブリンクから事前に訓練されたモデルをダウンロードできます。モデルは、Libritts Train-Clean-360分割でトレーニングされました。
https://mindslab-ai.github.io/univnet/でオーディオサンプルを参照してください
検証セットでモデルを評価しました。
| モデル | pesq(↑) | rmse(↓) | モデルサイズ |
|---|---|---|---|
| Hifi-Gan V1 | 3.54 | 0.423 | 14.01m |
| 公式Univnet-C16 | 3.59 | 0.337 | 4.00m |
| Univnet-C16 | 3.60 | 0.317 | 4.00m |
| 公式Univnet-C32 | 3.70 | 0.316 | 14.86m |
| 私たちのUnivnet-C32 | 3.68 | 0.304 | 14.87m |
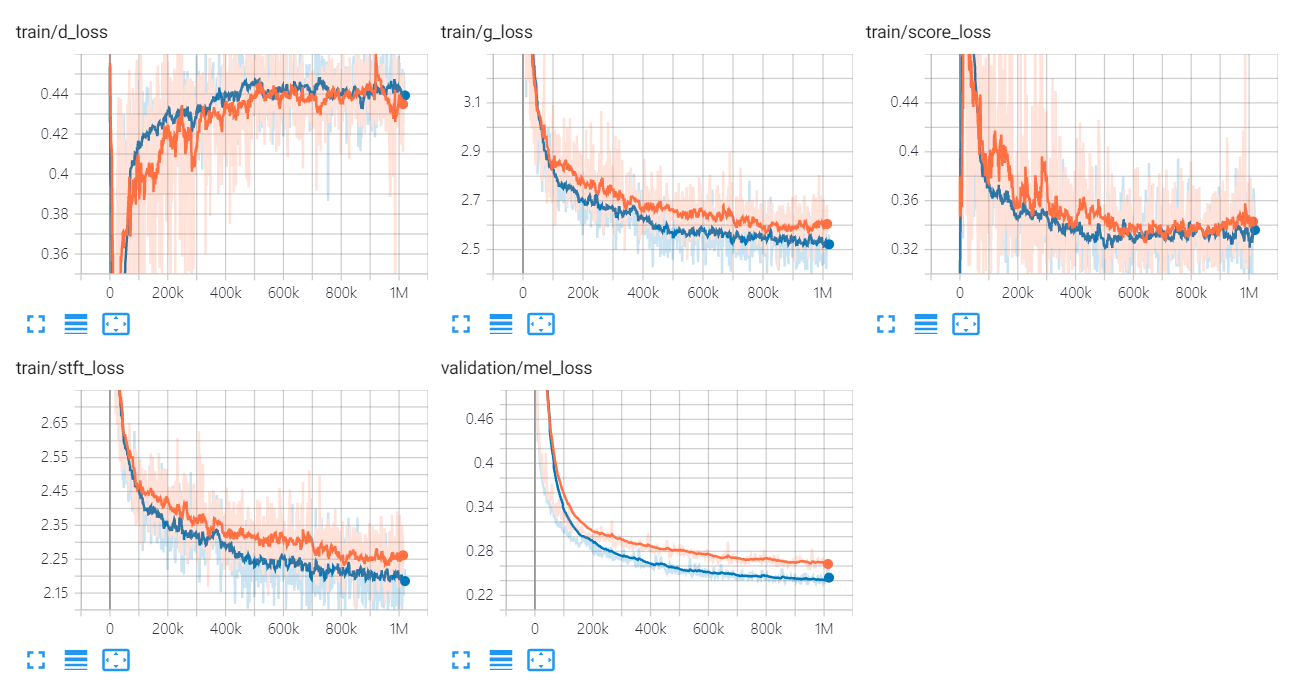
Univnetの損失グラフを以下に示します。
オレンジと青のグラフは、それぞれC16とC32を示しています。
実装著者は次のとおりです。
貢献者は次のとおりです。
に感謝します
このコードは、BSD 3-Clauseライセンスの下でライセンスされています。
次のコードとリポジトリを参照しました。
論文
データセット


