univnet
1.0.0
Univnet: un vocoder neural con discriminadores de espectrograma de resolución múltiple para la generación de forma de onda de alta fidelidad
Esta es una implementación no oficial de Pytorch de Jang et al. (Kakao), Univnet .
¡Se cargan muestras de audio!
Se han cargado los resultados de Univnet-C16 como C32 y los pesos previamente capacitados.
Para ambos modelos, nuestra implementación coincide con los puntajes objetivos (PESQ y RMSE) del documento original.
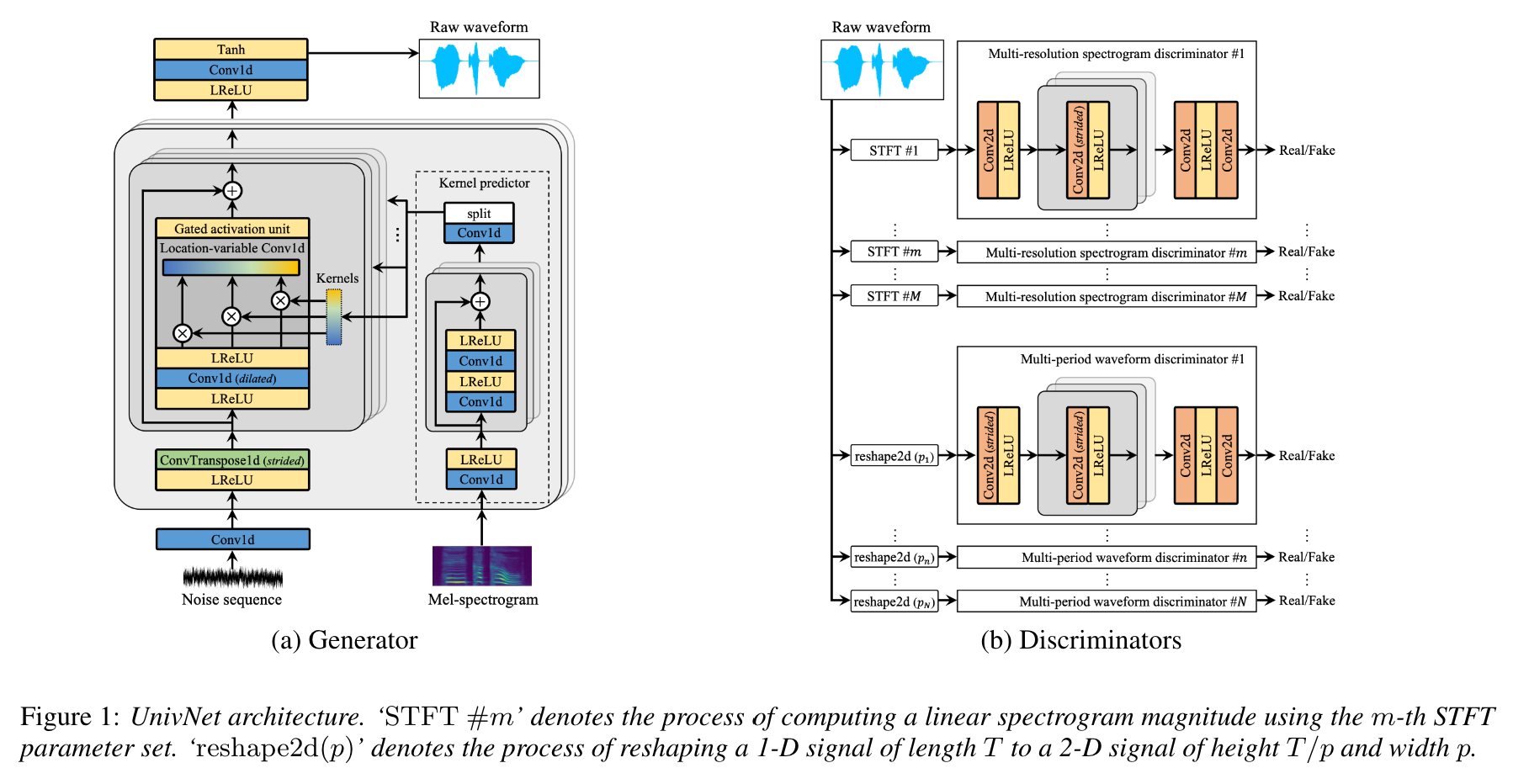
Según los autores del documento, Univnet obtuvo los mejores resultados objetivos entre los recientes vocoders neurales basados en GaN (incluido Hifi-Gan), así como superan a Hifi-Gan en una evaluación subjetiva. También su velocidad de inferencia es 1.5 veces más rápida que Hifi-Gan.
Este repositorio utiliza la misma función de espectrograma MEL que el Hifi-Gan oficial, que es compatible con Nvidia/Tacotron2.
Nuestros hiperparámetros de cálculo MEL predeterminado son los siguientes, siguiendo el documento original.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0Puede modificar los hiperparámetros para que sean compatibles con su modelo acústico.
La implementación necesita las siguientes dependencias.
pip install -r requirements.txtPreparación de datos
datasets/LibriTTS/train-clean-360 . Nota: Los espectrogramas MEL calculados a partir del archivo de audio se guardarán como **.mel al principio, y luego se cargarán desde el disco después.
Preparación de metadatos
Siguiendo el formato de Nvidia/Tacotron2, los metadatos deben formatearse como:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Metadatos de tren/validación para Libritts Train-Clean-360 Split y ya están preparados en datasets/metadata . El 5% de las expresiones de trenes-360 se muestrearon aleatoriamente para la validación.
Dado que este modelo es un vocoder, las transcripciones no se usan durante el entrenamiento.
Preparación de archivos de configuración
Ejecutar cp config/default_c32.yaml config/config.yaml y luego editar config.yaml
Escriba la ruta raíz del tren/validación en la sección data . La lista de archivos analiza la lista de archivos de la ruta de forma recursiva.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirProporcionamos los metadatos predeterminados para Libritts Train-Clean-360 Split.
Modifique channel_size en gen para cambiar entre Univnet-C16 y C32.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2Capacitación
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNTabla tensor
tensorboard --logdir logs/ Si está ejecutando TensorBoard en una máquina remota, puede abrir la página de TensorBoard agregando la opción --bind_all .
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHPuede descargar los modelos previamente capacitados desde el enlace de Google Drive a continuación. Los modelos fueron entrenados en Libritts Train-Clean-360 Split.
Ver muestras de audio en https://mindslab-ai.github.io/univnet/
Evaluamos nuestro modelo con conjunto de validación.
| Modelo | Pesq (↑) | RMSE (↓) | Tamaño del modelo |
|---|---|---|---|
| Hifi-Gan V1 | 3.54 | 0.423 | 14.01m |
| Univnet-C16 oficial | 3.59 | 0.337 | 4.00m |
| Nuestro univnet-C16 | 3.60 | 0.317 | 4.00m |
| Univnet-C32 oficial | 3.70 | 0.316 | 14.86m |
| Nuestro univnet-C32 | 3.68 | 0.304 | 14.87m |
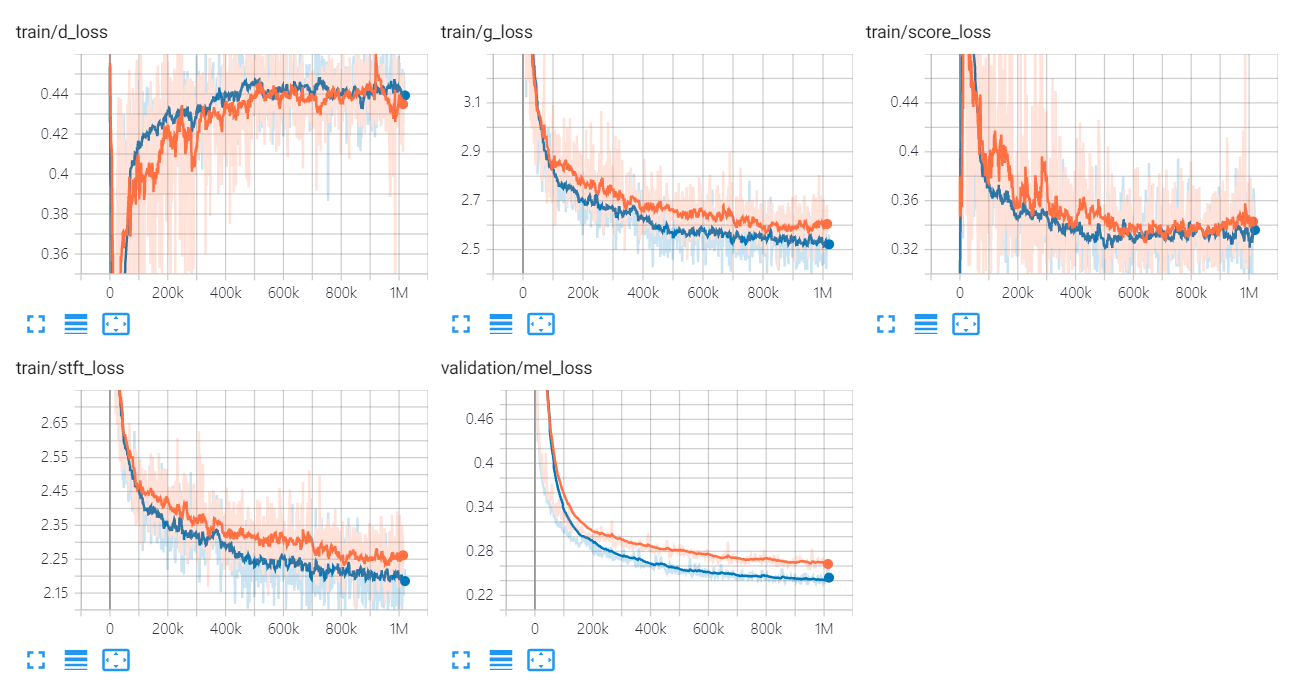
Los gráficos de pérdida de Univnet se enumeran a continuación.
Los gráficos naranja y azul indican C16 y C32, respectivamente.
Los autores de implementación son:
Los contribuyentes son:
Agradecimiento especial a
Este código tiene licencia bajo la licencia BSD 3 cláusula.
Referimos los siguientes códigos y repositorios.
Papeles
Conjuntos de datos


