univnet
1.0.0
Univnet: um vocoder neural com discriminadores de espectrograma de várias resolução para geração de formas de onda de alta fidelidade
Esta é uma implementação não oficial de Pytorch de Jang et al. (Kakao), Univnet .
Amostras de áudio são carregadas!
Os resultados do UnivNet-C16 e C32 e os pesos pré-treinados foram enviados.
Para ambos os modelos, nossa implementação corresponde às pontuações objetivas (PESQ e RMSE) do artigo original.
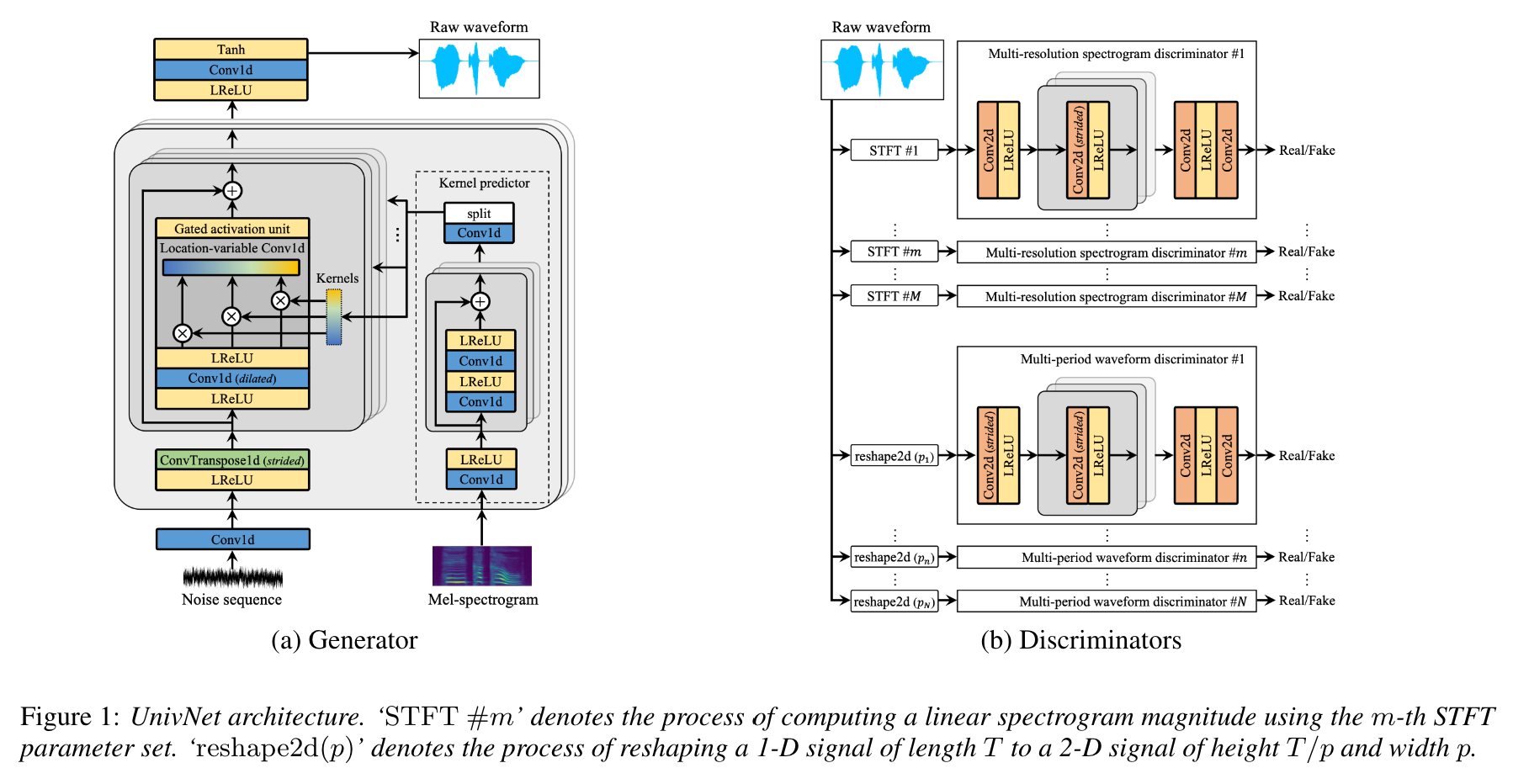
De acordo com os autores do artigo, a Univnet obteve os melhores resultados objetivos entre os recentes vocoders neurais baseados em GaN (incluindo o HIFI-GAN), bem como superar o HIFI-GAN em uma avaliação subjetiva. Além disso, sua velocidade de inferência é 1,5 vezes mais rápida que o HIFI-GAN.
Este repositório usa a mesma função de espectrograma MEL que o HIFI-GAN oficial, que é compatível com NVIDIA/TACOTRON2.
Nossos hiperparâmetros de cálculo MEL padrão são os abaixo, seguindo o papel original.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0Você pode modificar os hiperparâmetros para serem compatíveis com seu modelo acústico.
A implementação precisa de dependências seguintes.
pip install -r requirements.txtPreparando dados
datasets/LibriTTS/train-clean-360 . NOTA: Os espectrogramas MEL calculados a partir do arquivo de áudio serão salvos como **.mel a princípio e depois carregados do disco posteriormente.
Preparando metadados
Após o formato de Nvidia/Tacotron2, os metadados devem ser formatados como:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Os metadados de trem/validação para o Libritts Train-Clean-360 Split e já estão preparados em datasets/metadata . 5% dos enunciados do trem-C-360 foram amostrados aleatoriamente para validação.
Como esse modelo é um vocoder, as transcrições não são usadas durante o treinamento.
Preparando arquivos de configuração
Execute cp config/default_c32.yaml config/config.yaml e depois edite config.yaml
Anote o caminho raiz do trem/validação na seção data . A lista de arquivos do carregador de dados dentro do caminho recursivamente.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirFornecemos os metadados padrão para a divisão Libritts-Clean-360.
Modifique channel_size em gen para alternar entre UnivNet-C16 e C32.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2Treinamento
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNTensorboard
tensorboard --logdir logs/ Se você estiver executando o Tensorboard em uma máquina remota, poderá abrir a página do Tensorboard adicionando --bind_all .
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHVocê pode baixar os modelos pré-treinados no link do Google Drive abaixo. Os modelos foram treinados na divisão de Libritts-Clean-360.
Veja amostras de áudio em https://mindslab-ai.github.io/univnet/
Avaliamos nosso modelo com o conjunto de validação.
| Modelo | Pesq (↑) | Rmse (↓) | Tamanho do modelo |
|---|---|---|---|
| HIFI-GAN V1 | 3.54 | 0,423 | 14.01m |
| Univnet-C16 oficial | 3.59 | 0,337 | 4,00m |
| Nosso Univnet-C16 | 3.60 | 0,317 | 4,00m |
| Univnet-C32 oficial | 3.70 | 0,316 | 14,86m |
| Nosso Univnet-C32 | 3.68 | 0,304 | 14,87m |
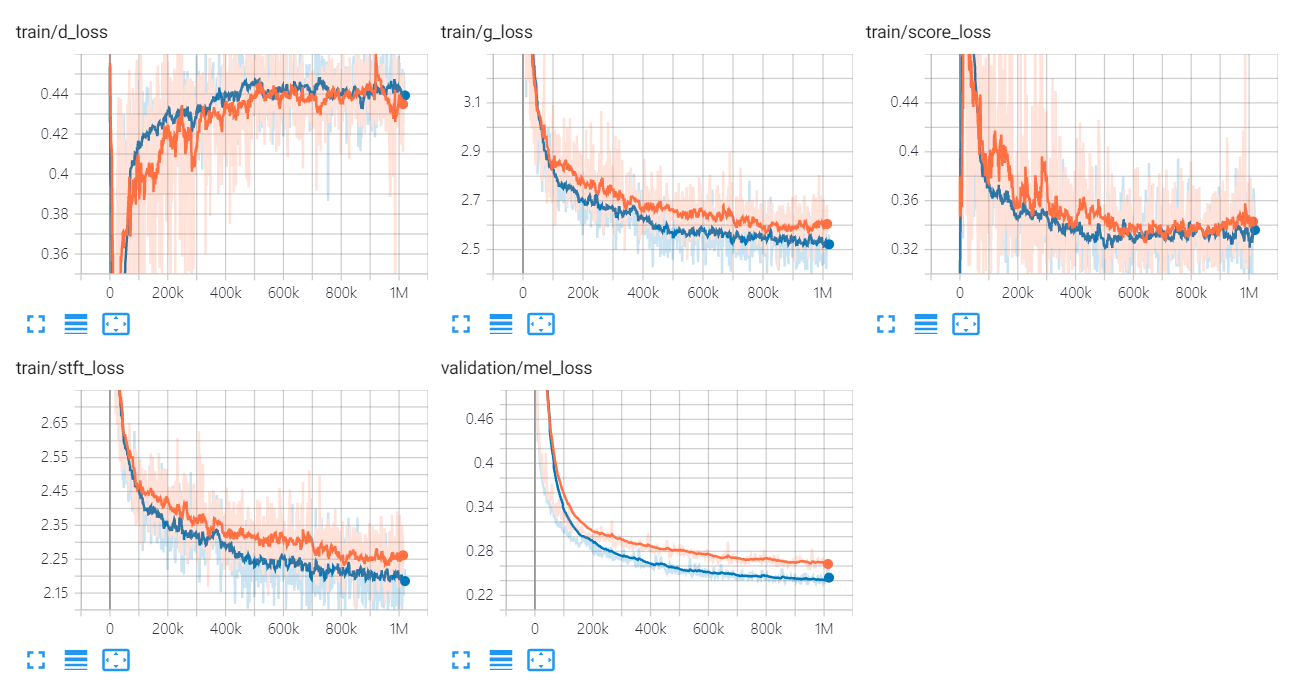
Os gráficos de perda do Univnet estão listados abaixo.
Os gráficos laranja e azul indicam C16 e C32, respectivamente.
Os autores de implementação são:
Os colaboradores são:
Agradecimentos especiais a
Este código é licenciado sob licença de 3 cláusulas BSD.
Referimos os seguintes códigos e repositórios.
Papéis
Conjuntos de dados


