univnet
1.0.0
UNIVNET: Ein neuronaler Vokoder mit Multi-Auflösungs-Spektrogramm-Diskriminatoren für die Erzeugung von Wellenform mit hoher Fidelität
Dies ist eine inoffizielle Pytorch -Implementierung von Jang et al. (Kakao), Univnet .
Audio -Samples werden hochgeladen!
Sowohl Univnet-C16- als auch C32-Ergebnisse und die vorgebreiteten Gewichte wurden hochgeladen.
Für beide Modelle entspricht unsere Implementierung mit den Zielwerten (PESQ und RMSE) des Originalpapiers.
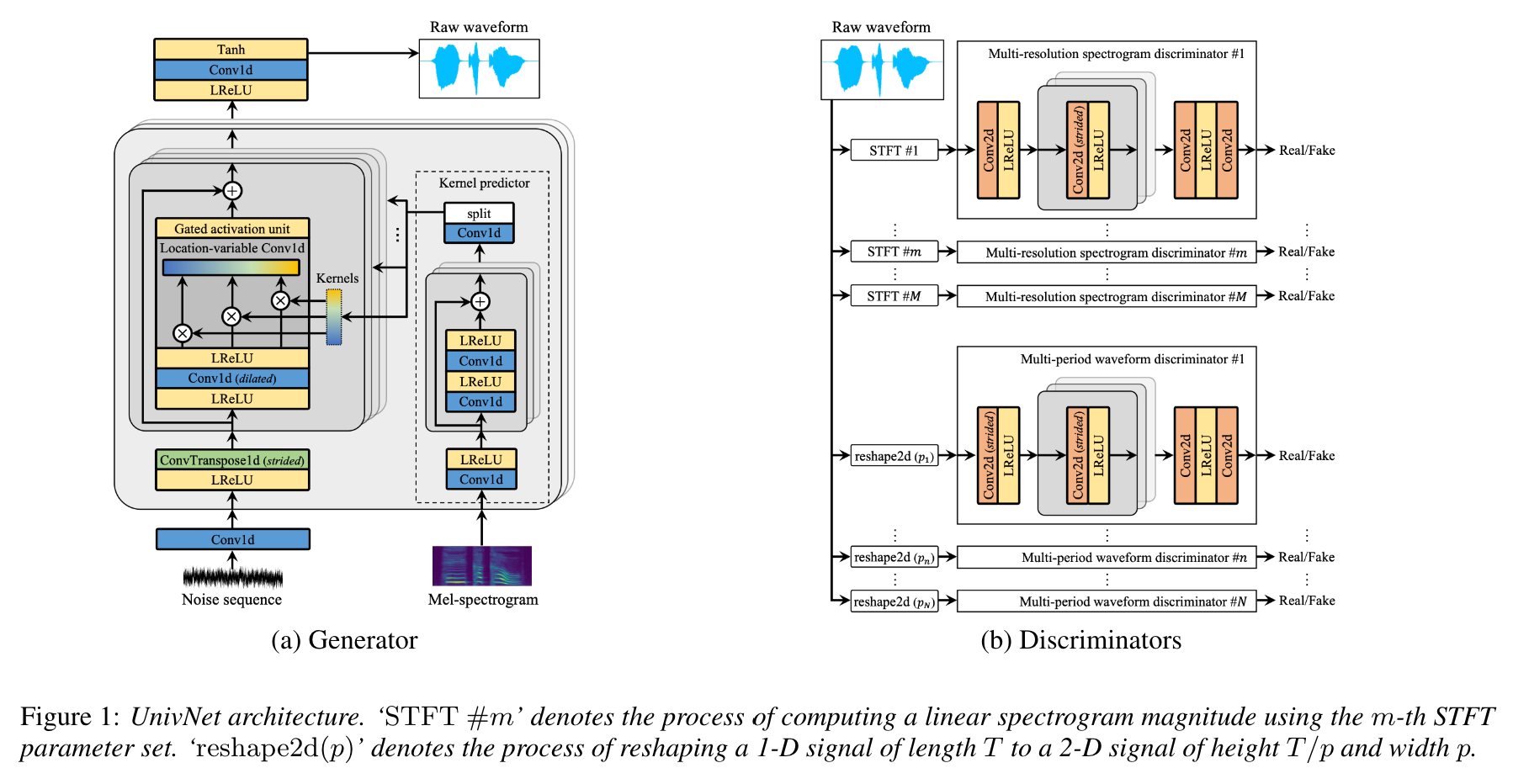
Nach Angaben der Autoren des Papiers erzielte Univnet die besten objektiven Ergebnisse unter den jüngsten neuronalen Vokördern auf GaN-basierten Basis (einschließlich Hifigan) sowie die Outperformance von Hifi-Gan in einer subjektiven Bewertung. Auch seine Inferenzgeschwindigkeit ist 1,5-mal schneller als Hifi -gan.
Dieses Repository verwendet die gleiche Melspektogrammfunktion wie das offizielle Hifi-Gan, das mit NVIDIA/TACOTRON2 kompatibel ist.
Unsere Standard -Mel -Berechnungshyperparameter finden Sie unten dem Originalpapier.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0Sie können die Hyperparameter so ändern, dass sie mit Ihrem akustischen Modell kompatibel sind.
Der Implementierungsbedarf nach Abhängigkeiten.
pip install -r requirements.txtDaten vorbereiten
datasets/LibriTTS/train-clean-360 . Hinweis: Die aus der Audio-Datei berechneten Melspektrogramme werden zuerst als **.mel gespeichert und dann anschließend von der Festplatte geladen.
Vorbereitung von Metadaten
Nach dem Format von Nvidia/Tacotron2 sollte die Metadaten als formatiert werden:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Zug-/Validierungsmetadaten für Libritts Train-Clean-360-Split und sind bereits in datasets/metadata erstellt. 5% der Zug-Clean-360-Äußerungen wurden zufällig zur Validierung abgetastet.
Da dieses Modell ein Vokoder ist, werden die Transkripte während des Trainings nicht verwendet.
Vorbereitung von Konfigurationsdateien
Führen Sie cp config/default_c32.yaml config/config.yaml aus und bearbeiten Sie dann config.yaml
Schreiben Sie den Wurzelweg von Zug/Validierung im data auf. Die Data Loader Parse -Liste der Dateien im Pfad rekursiv.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirWir bieten die Standardmetadaten für die Libritts Train-Clean-360-Split an.
Ändern Sie channel_size in gen , um zwischen UNIVNET-C16 und C32 zu wechseln.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2Ausbildung
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNTensorboard
tensorboard --logdir logs/ Wenn Sie Tensorboard auf einem Remote -Computer ausführen, können Sie die Tensorboard -Seite öffnen, indem Sie die Option --bind_all hinzufügen.
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHSie können die vorgeborenen Modelle aus dem folgenden Google Drive-Link herunterladen. Die Modelle wurden auf der Libritts Train-Clean-360-Split ausgebildet.
Siehe Audio-Samples unter https://mindslab-ai.github.io/univnet/
Wir haben unser Modell mit Validierungssatz bewertet.
| Modell | Pesq (↑) | Rmse (↓) | Modellgröße |
|---|---|---|---|
| Hifi -gan V1 | 3.54 | 0,423 | 14.01m |
| Offizielle Univnet-C16 | 3.59 | 0,337 | 4,00 m |
| Unser Univnet-C16 | 3.60 | 0,317 | 4,00 m |
| Offizielle Univnet-C32 | 3.70 | 0,316 | 14,86 m |
| Unser Univnet-C32 | 3.68 | 0,304 | 14,87 m |
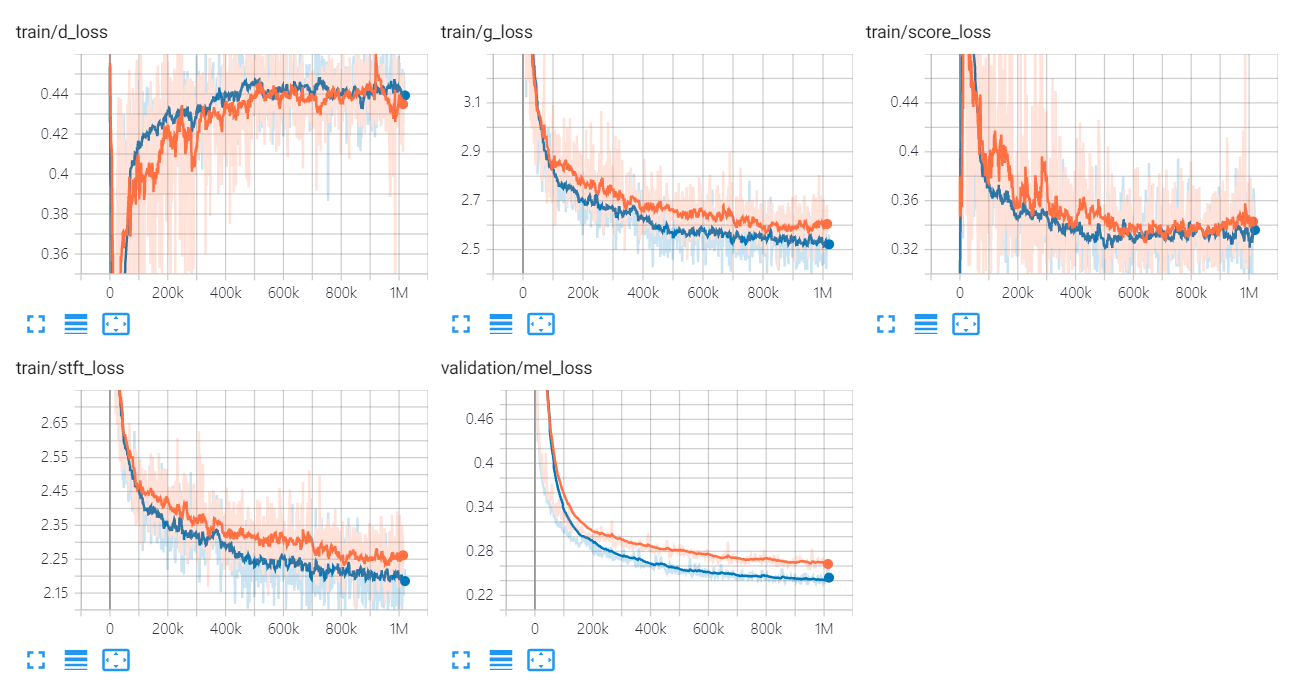
Die Verlustdiagramme von Univnet sind unten aufgeführt.
Die orange und blauen Diagramme geben C16 bzw. C32 an.
Implementierungsautoren sind:
Mitwirkende sind:
Besonderer Dank an
Dieser Code ist unter BSD 3-Clause-Lizenz lizenziert.
Wir haben nach Codes und Repositorys verwiesen.
Papiere
Datensätze


