univnet
1.0.0
Univnet: Vocoder العصبي مع تمييزات طيفية متعددة الدقة لتوليد الموجة عالية الدقة
هذا هو تطبيق Pytorch غير رسمي لجانج وآخرون. (Kakao) ، Univnet .
يتم تحميل عينات الصوت!
تم تحميل كل من نتائج Univnet-C16 و C32 والأوزان التي تم تدريبها مسبقًا.
لكلا النموذجين ، يطابق تنفيذنا الدرجات الموضوعية (PESQ و RMSE) للورقة الأصلية.
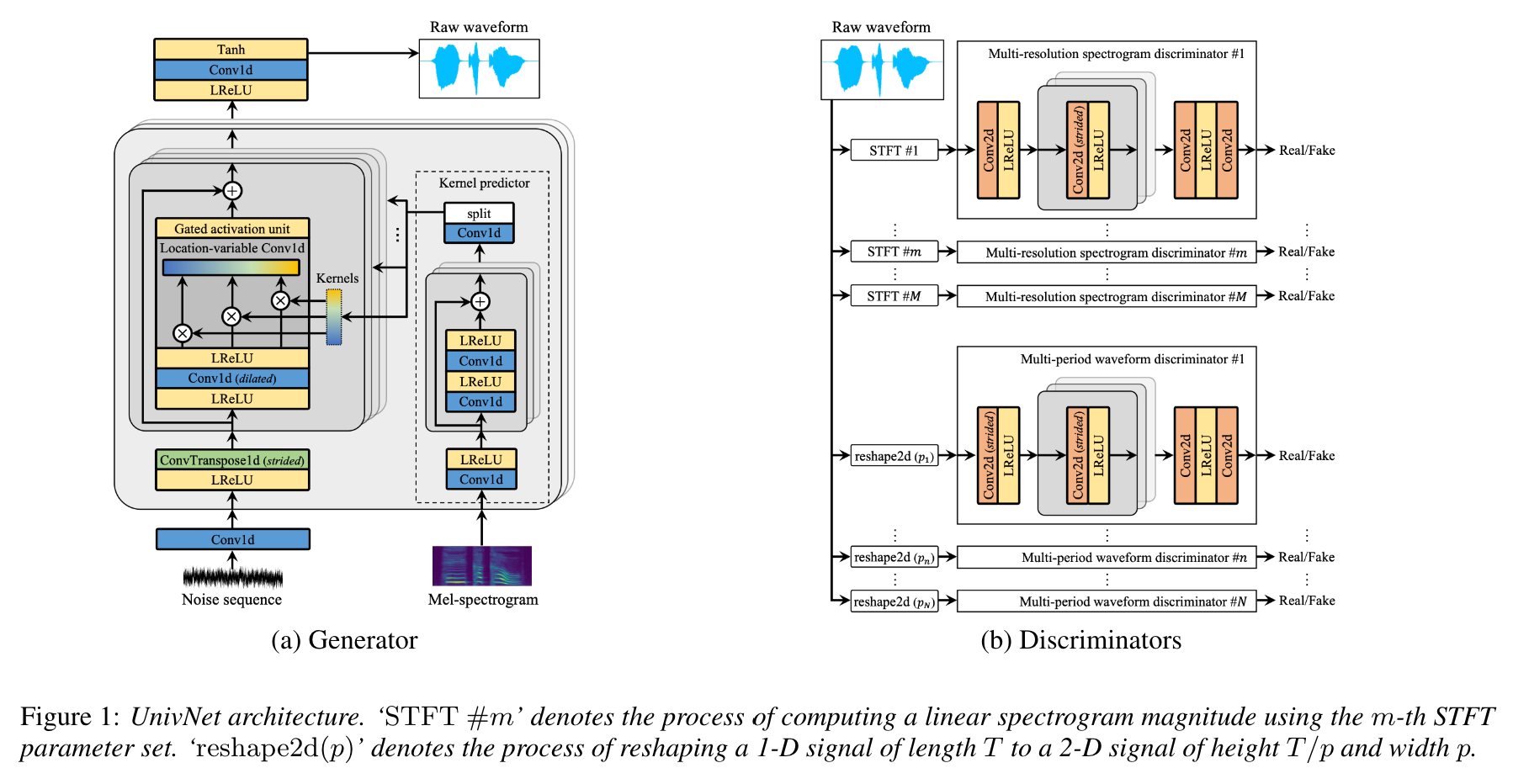
وفقًا لمؤلفي الورقة ، حصلت Univnet على أفضل النتائج الموضوعية بين المتفرجين العصبيين القائم على GAN (بما في ذلك HIFI-GAN) وكذلك تفوق HIFI GAN في تقييم شخصي. أيضا سرعة الاستدلال أسرع 1.5 مرة من HIFI-GAN.
يستخدم هذا المستودع نفس وظيفة طيف MEL-SPECTROOGR مثل HIFI-GAN الرسمية ، والتي تتوافق مع NVIDIA/TACOTRON2.
لدينا HyperParameters الحساب الافتراضي لدينا كما هو موضح أدناه ، وبعد الورقة الأصلية.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0يمكنك تعديل المقاييس الفائقة لتكون متوافقة مع نموذجك الصوتي.
يحتاج التنفيذ بعد التبعيات.
pip install -r requirements.txtإعداد البيانات
datasets/LibriTTS/train-clean-360 . ملاحظة: سيتم حفظ طيف MEL-SEMPTERGROOGHS المحسوبة من ملف الصوت كـ **.mel في البداية ، ثم يتم تحميلها من القرص بعد ذلك.
إعداد البيانات الوصفية
بعد التنسيق من NVIDIA/TACOTRON2 ، يجب تنسيق البيانات الوصفية على النحو التالي:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
البيانات الوصفية للقطار/التحقق من الصحة لتقسيم Libritts Clean-360 وهي تم إعدادها بالفعل في datasets/metadata . تم أخذ عينات من 5 ٪ من الكرامات -360 القطار بشكل عشوائي للتحقق من الصحة.
نظرًا لأن هذا النموذج هو Vocoder ، فإن النصوص لا تستخدم أثناء التدريب.
إعداد ملفات التكوين
قم بتشغيل cp config/default_c32.yaml config/config.yaml ثم تحرير config.yaml
اكتب مسار الجذر للقطار/التحقق من الصحة في قسم data . تقوم محمل البيانات بتوزيع قائمة الملفات داخل المسار بشكل متكرر.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirنحن نقدم البيانات الوصفية الافتراضية لتقسيم Libritts Train-Clean-360.
تعديل channel_size في gen للتبديل بين Univnet-C16 و C32.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2تمرين
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNTensorboard
tensorboard --logdir logs/ إذا كنت تقوم بتشغيل Tensorboard على جهاز بعيد ، فيمكنك فتح صفحة Tensorboard عن طريق إضافة خيار --bind_all .
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHيمكنك تنزيل النماذج التي تم تدريبها مسبقًا من رابط Google Drive أدناه. تم تدريب النماذج على انقسام Libritts Train-Clean-360.
انظر عينات الصوت في https://mindslab-ai.github.io/univnet/
قمنا بتقييم نموذجنا مع مجموعة التحقق من الصحة.
| نموذج | PESQ (↑) | RMSE (↓) | حجم النموذج |
|---|---|---|---|
| HIFI-GAN V1 | 3.54 | 0.423 | 14.01m |
| Univnet-C16 الرسمية | 3.59 | 0.337 | 4.00 م |
| لدينا Univnet-C16 | 3.60 | 0.317 | 4.00 م |
| Univnet-C32 الرسمية | 3.70 | 0.316 | 14.86 م |
| لدينا Univnet-C32 | 3.68 | 0.304 | 14.87 م |
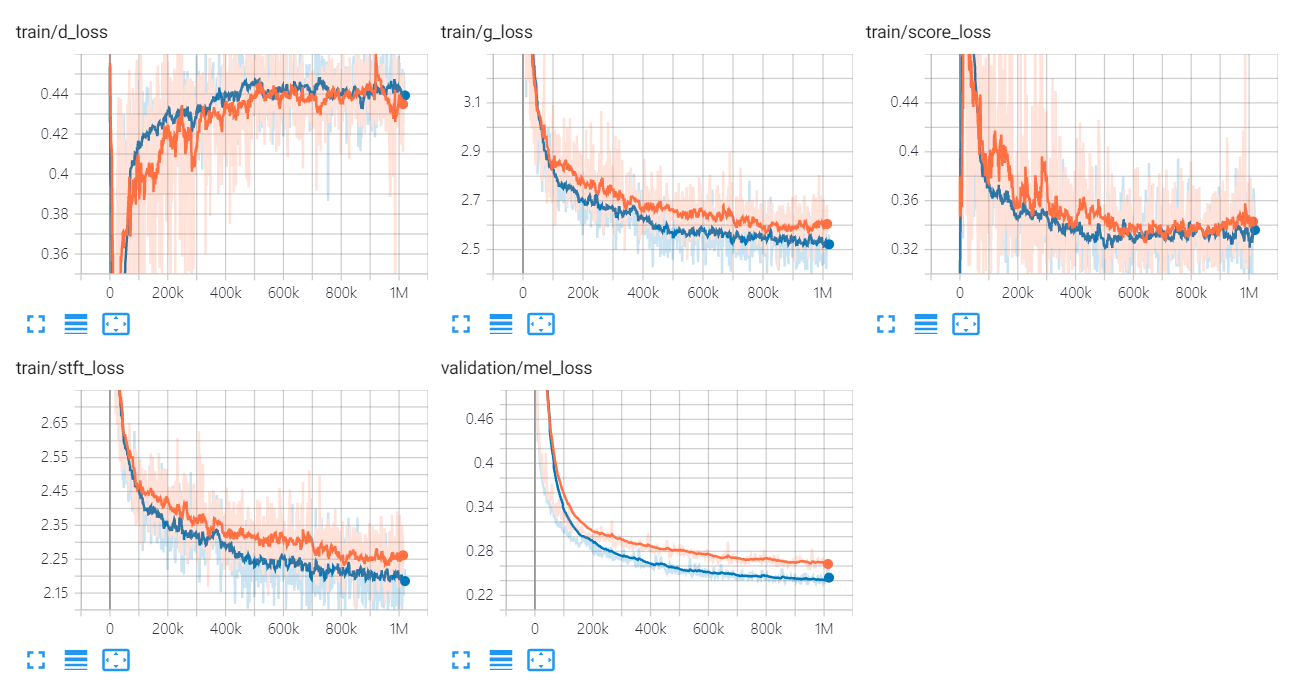
يتم سرد الرسوم البيانية لخسارة Univnet أدناه.
تشير الرسوم البيانية البرتقالية والأزرق إلى C16 و C32 ، على التوالي.
مؤلفو التنفيذ هم:
المساهمون هم:
شكر خاص ل
تم ترخيص هذا الرمز بموجب ترخيص BSD 3-CASE.
أشرنا إلى الرموز والمستودعات التالية.
أوراق
مجموعات البيانات


