univnet
1.0.0
Univnet: un vocodeur neural avec des discriminateurs de spectrogrammes multi-résolution pour la génération de formes d'onde à haute fidélité
Il s'agit d'une mise en œuvre non officielle de Pytorch de Jang et al. (Kakao), Univnet .
Les échantillons audio sont téléchargés!
Les résultats UniVnet-C16 et C32 et les poids pré-formés ont été téléchargés.
Pour les deux modèles, notre implémentation correspond aux scores objectifs (PESQ et RMSE) du papier d'origine.
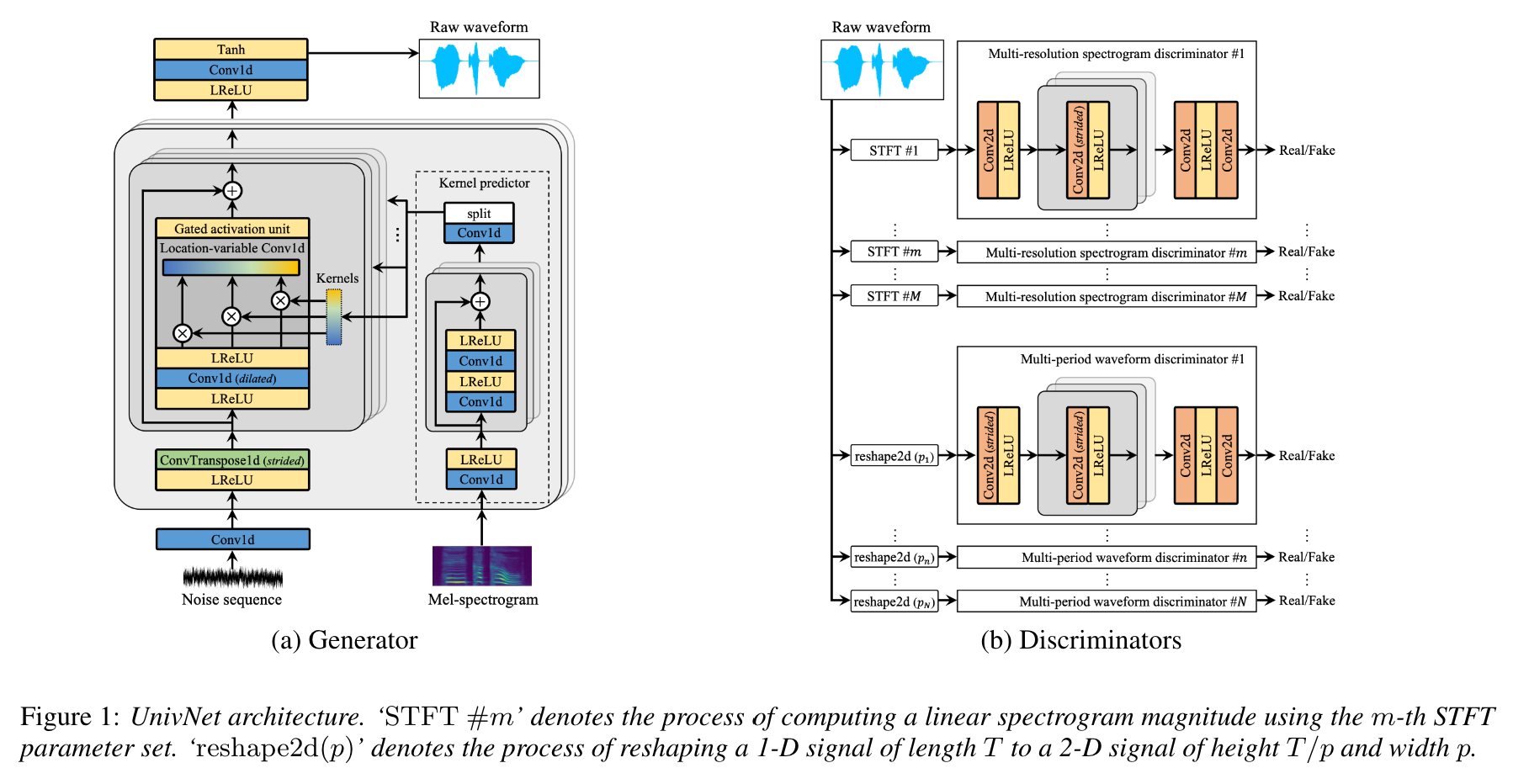
Selon les auteurs de l'article, UnivNet a obtenu les meilleurs résultats objectifs parmi les vocodeurs neuronaux récents basés sur GaN (y compris HiFI-AG) ainsi que la surperformance HIFI-AG dans une évaluation subjective. De plus, sa vitesse d'inférence est 1,5 fois plus rapide que Hifi-Gan.
Ce référentiel utilise la même fonction MEL-spectrogramme que le HIFI-AG officiel, qui est compatible avec NVIDIA / TACOTRON2.
Nos hyperparamètres de calcul MEL par défaut sont comme ci-dessous, suivant le papier d'origine.
audio :
n_mel_channels : 100
filter_length : 1024
hop_length : 256 # WARNING: this can't be changed.
win_length : 1024
sampling_rate : 24000
mel_fmin : 0.0
mel_fmax : 12000.0Vous pouvez modifier les hyperparamètres pour être compatibles avec votre modèle acoustique.
La mise en œuvre nécessite des dépendances suivantes.
pip install -r requirements.txtPréparer des données
datasets/LibriTTS/train-clean-360 . Remarque: Les spectrogrammes MEL calculés à partir du fichier audio seront enregistrés comme **.mel au début, puis chargés à partir du disque par la suite.
Préparation des métadonnées
Après le format de Nvidia / Tacotron2, les métadonnées doivent être formatées comme:
path_to_wav|transcript|speaker_id
path_to_wav|transcript|speaker_id
...
Métadata de trains / validation pour les libritts Train-Clean-360 Split et sont déjà préparés dans datasets/metadata . 5% des énoncés Train-Clean-360 ont été échantillonnés au hasard pour la validation.
Étant donné que ce modèle est un vocodeur, les transcriptions ne sont pas utilisées pendant la formation.
Préparation des fichiers de configuration
Exécuter cp config/default_c32.yaml config/config.yaml puis modifier config.yaml
Notez le chemin racine du train / validation dans la section data . Le chargeur de données analyse la liste des fichiers dans le chemin de manière récursive.
data :
train_dir : ' datasets/ ' # root path of train data (either relative/absoulte path is ok)
train_meta : ' metadata/libritts_train_clean_360_train.txt ' # relative path of metadata file from train_dir
val_dir : ' datasets/ ' # root path of validation data
val_meta : ' metadata/libritts_train_clean_360_val.txt ' # relative path of metadata file from val_dirNous fournissons les métadonnées par défaut pour les Libritts Train-Clean-360 Split.
Modifiez channel_size dans gen pour basculer entre UnivNet-C16 et C32.
gen :
noise_dim : 64
channel_size : 32 # 32 or 16
dilations : [1, 3, 9, 27]
strides : [8, 8, 4]
lReLU_slope : 0.2Entraînement
python trainer.py -c CONFIG_YAML_FILE -n NAME_OF_THE_RUNTensorboard
tensorboard --logdir logs/ Si vous exécutez Tensorboard sur une machine distante, vous pouvez ouvrir la page Tensorboard en ajoutant l'option --bind_all .
python inference.py -p CHECKPOINT_PATH -i INPUT_MEL_PATH -o OUTPUT_WAV_PATHVous pouvez télécharger les modèles pré-formés à partir du lien Google Drive ci-dessous. Les modèles ont été formés sur la scission des Libritts Train-Clean-360.
Voir des échantillons audio sur https://mindslab-ai.github.io/univnet/
Nous avons évalué notre modèle avec un ensemble de validation.
| Modèle | PESQ (↑) | RMSE (↓) | Taille du modèle |
|---|---|---|---|
| Hifi-gan v1 | 3.54 | 0,423 | 14.01m |
| Univnet-C16 officiel | 3.59 | 0,337 | 4.00m |
| Notre Univnet-C16 | 3.60 | 0,317 | 4.00m |
| Univnet-C32 officiel | 3.70 | 0,316 | 14.86m |
| Notre Univnet-C32 | 3.68 | 0,304 | 14.87m |
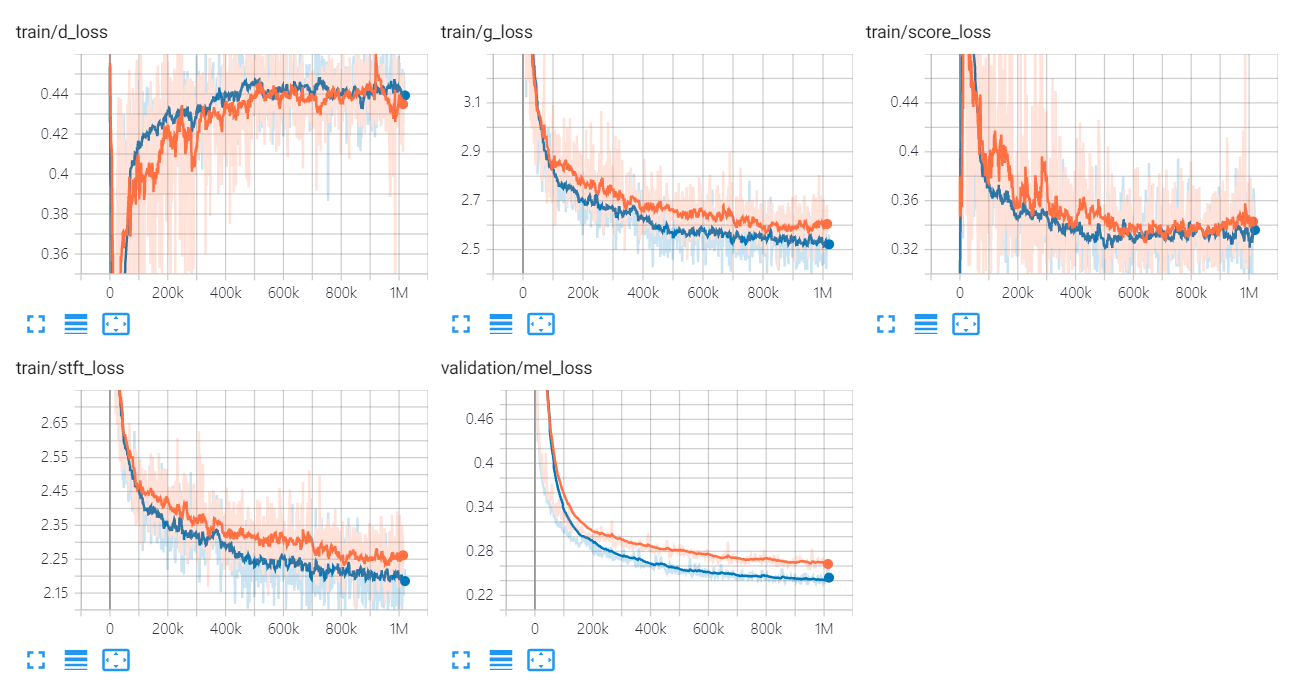
Les graphiques de perte d'Univnet sont répertoriés ci-dessous.
Les graphiques orange et bleus indiquent respectivement C16 et C32.
Les auteurs de l'implémentation sont:
Les contributeurs sont:
Un merci spécial à
Ce code est sous licence sous licence BSD 3-CLAUSE.
Nous avons référé les codes et les référentiels suivants.
Papiers
Ensembles de données


