DiffGAN TTS
1.0.0
การใช้ Pytorch ของ diffgan-TTS: ความเที่ยงตรงสูงและมีประสิทธิภาพเป็นข้อความต่อการพูดด้วย denoising diffusion gans
ตัวอย่างเสียงมีให้ที่ /สาธิต
ชุดข้อมูล หมายถึงชื่อของชุดข้อมูลเช่น LJSpeech และ VCTK ในเอกสารต่อไปนี้
โมเดล หมายถึงประเภทของโมเดล (เลือกจาก ' ไร้เดียงสา ', ' aux ', ' ตื้น ')
คุณสามารถติดตั้งการพึ่งพา Python ด้วย
pip3 install -r requirements.txt
คุณต้องดาวน์โหลดโมเดลที่ผ่านการฝึกอบรมและใส่ไว้ใน
output/ckpt/DATASET_naive/ สำหรับโมเดล ' ไร้เดียงสา 'output/ckpt/DATASET_shallow/ สำหรับโมเดล ' ตื้น ' โปรดทราบว่าจุดตรวจของโมเดล ' ตื้น ' มีทั้งแบบจำลอง ' ตื้น ' และ ' AUX ' ทั้งสองรุ่นนี้จะแบ่งปันไดเรกทอรีทั้งหมดยกเว้นผลลัพธ์ตลอดกระบวนการทั้งหมดสำหรับ TTS ลำโพงเดียว Run
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
สำหรับ TTs หลายลำโพง
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
พจนานุกรมของลำโพงที่เรียนรู้สามารถพบได้ที่ preprocessed_data/DATASET/speakers.json และคำพูดที่สร้างขึ้นจะถูกนำไปใช้ใน output/result/
รองรับการอนุมานแบบแบทช์ด้วยลอง
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
เพื่อสังเคราะห์คำพูดทั้งหมดใน preprocessed_data/DATASET/val.txt
ระดับเสียง/ปริมาตร/การพูดของคำพูดสังเคราะห์สามารถควบคุมได้โดยการระบุอัตราส่วนระดับเสียง/พลังงาน/ระยะเวลาที่ต้องการ ตัวอย่างเช่นหนึ่งสามารถเพิ่มอัตราการพูดได้ 20 % และลดปริมาณลง 20 % โดย
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
โปรดทราบว่าความสามารถในการควบคุมได้มาจาก FastSpeech2 และไม่ใช่ความสนใจที่สำคัญของ diffgan-TTS
ชุดข้อมูลที่รองรับคือ
LJSpeech: ชุดข้อมูลภาษาอังกฤษ ลำโพงเดียว ประกอบด้วยคลิปเสียงสั้น 13100 คลิปของข้อความอ่านข้อความหญิงจากหนังสือสารคดี 7 เล่มรวมประมาณ 24 ชั่วโมง
VCTK: CSTR VCTK Corpus รวมถึงข้อมูลการพูดที่พูดโดยผู้พูดภาษาอังกฤษ 110 คน ( TTS หลายลำโพง ) ด้วยสำเนียงต่าง ๆ ผู้พูดแต่ละคนอ่านประมาณ 400 ประโยคซึ่งได้รับการคัดเลือกจากหนังสือพิมพ์ทางสายรุ้งและย่อหน้าที่ใช้สำหรับการเก็บถาวรคำพูด
สำหรับ TTS หลายลำโพงที่ มีลำโพง Embedder ดาวน์โหลด Rescnn Softmax+Triplet Pretrained Model ของ Deepspeaker ของ Philipperemy สำหรับการฝังลำโพงและค้นหาใน ./deepspeaker/pretrained_models/ deepspeaker/pretrained_models/
วิ่ง
python3 prepare_align.py --dataset DATASET
สำหรับการเตรียมการบางอย่าง
สำหรับการจัดตำแหน่งที่ถูกบังคับมอนทรีออลบังคับให้ผู้จัดตำแหน่ง (MFA) ใช้เพื่อให้ได้การจัดตำแหน่งระหว่างคำพูดและลำดับฟอนิม การจัดตำแหน่งที่สกัดไว้ล่วงหน้าสำหรับชุดข้อมูลมีให้ที่นี่ คุณต้องคลายซิปไฟล์ใน preprocessed_data/DATASET/TextGrid/ อีกวิธีหนึ่งคุณสามารถเรียกใช้การจัดตำแหน่งด้วยตัวเอง
หลังจากนั้นเรียกใช้สคริปต์การประมวลผลล่วงหน้าโดย
python3 preprocess.py --dataset DATASET
คุณสามารถฝึกอบรมแบบจำลองสามประเภท: ' ไร้เดียงสา ', ' aux ' และ ' ตื้น '
การฝึกอบรมเวอร์ชันไร้เดียงสา (' ไร้เดียงสา '):
ฝึกอบรมเวอร์ชั่นที่ไร้เดียงสาด้วย
python3 train.py --model naive --dataset DATASET
การฝึกอบรมโมเดลอะคูสติกพื้นฐานสำหรับเวอร์ชันตื้น (' aux '):
ในการฝึกอบรมรุ่นตื้นเราจำเป็นต้องได้รับการฝึกอบรมล่วงหน้า 2 คำสั่งด้านล่างจะช่วยให้คุณฝึกอบรมโมดูล FastSpeech2 รวมถึงตัวถอดรหัสเสริม (MEL)
python3 train.py --model aux --dataset DATASET
การฝึกอบรมเวอร์ชันตื้น (' ตื้น '):
ในการใช้ประโยชน์จาก FastSpeech2 ที่ผ่านการฝึกอบรมมาก่อนรวมถึงตัวถอดรหัสเสริม (MEL) คุณต้องผ่าน --restore_step ด้วยขั้นตอนสุดท้ายของการฝึกอบรมเสริม FastSpeech2 เป็นคำสั่งต่อไปนี้
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
ตัวอย่างเช่นหากจุดตรวจสอบล่าสุดถูกบันทึกไว้ที่ 200000 ขั้นตอนในระหว่างการฝึกอบรมเสริมคุณต้องตั้งค่า --restore_step ด้วย 200000 จากนั้นมันจะโหลดและแช่แข็งโมเดล AUX จากนั้นทำการฝึกอบรมต่อภายใต้กลไกการแพร่กระจายแบบตื้นที่ใช้งานอยู่
ใช้
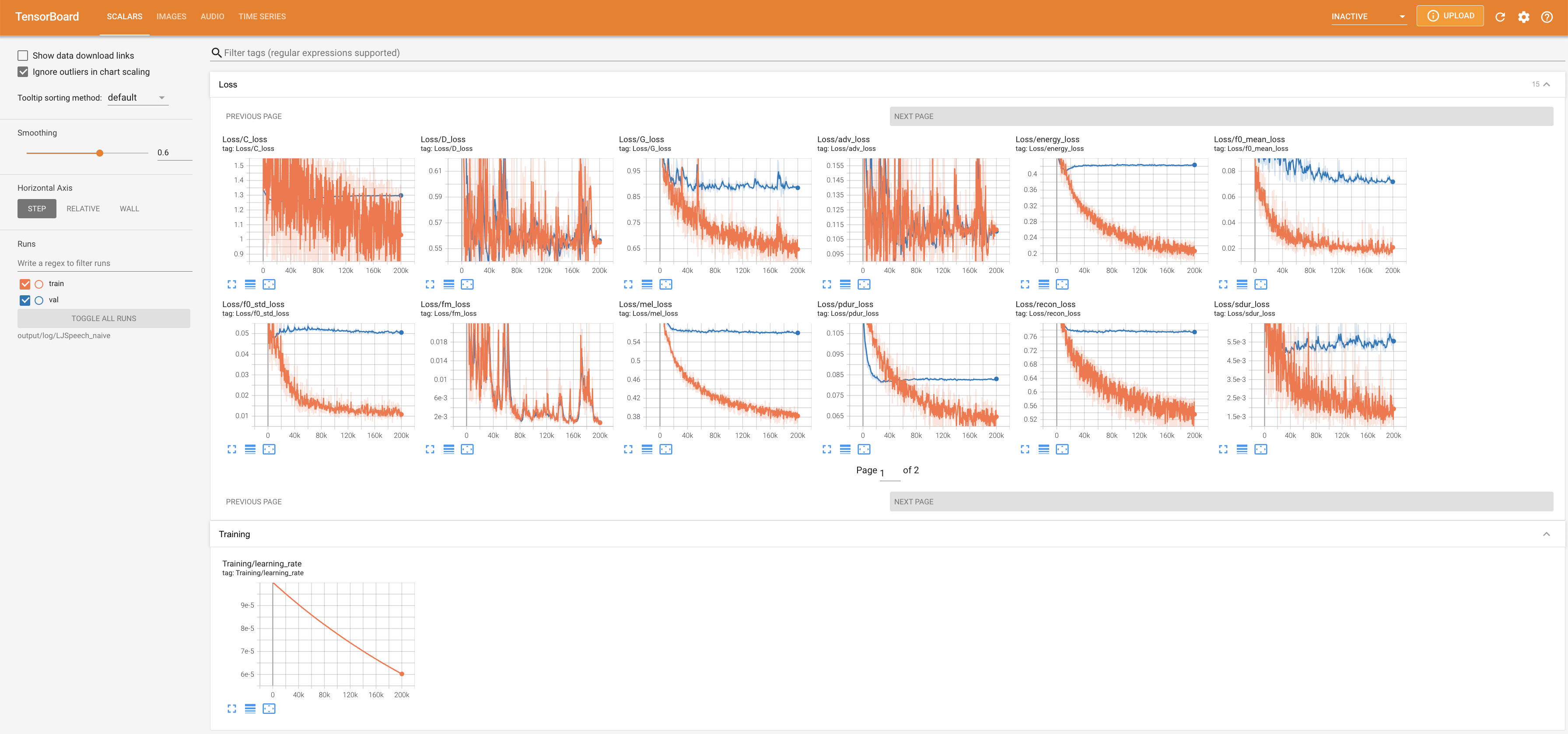
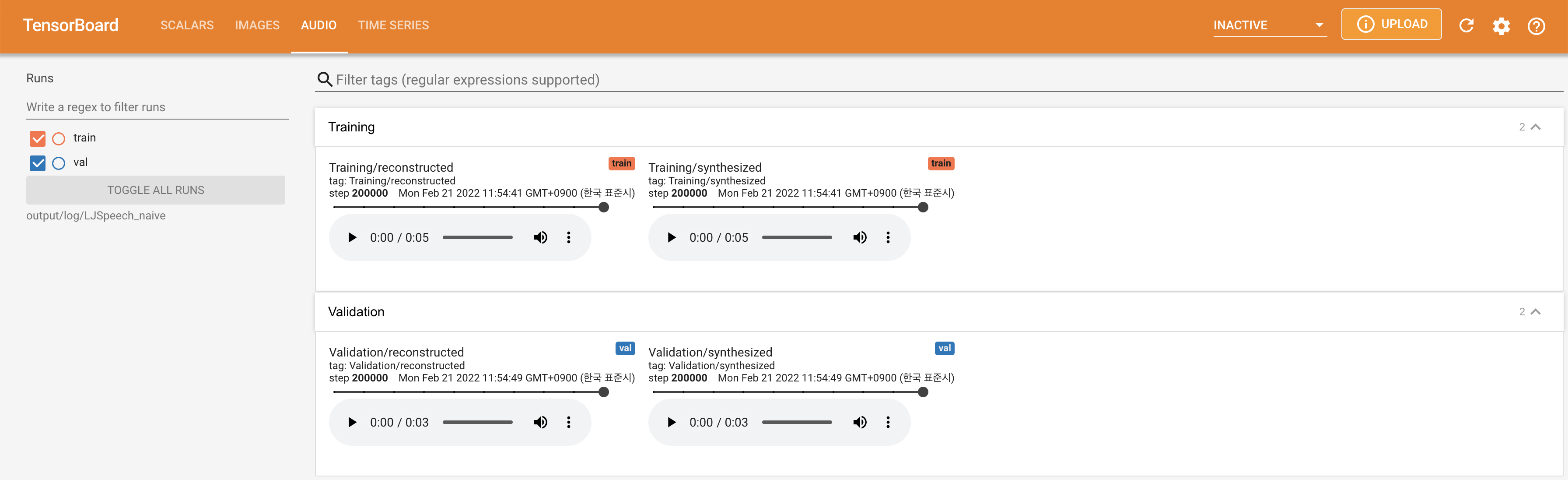
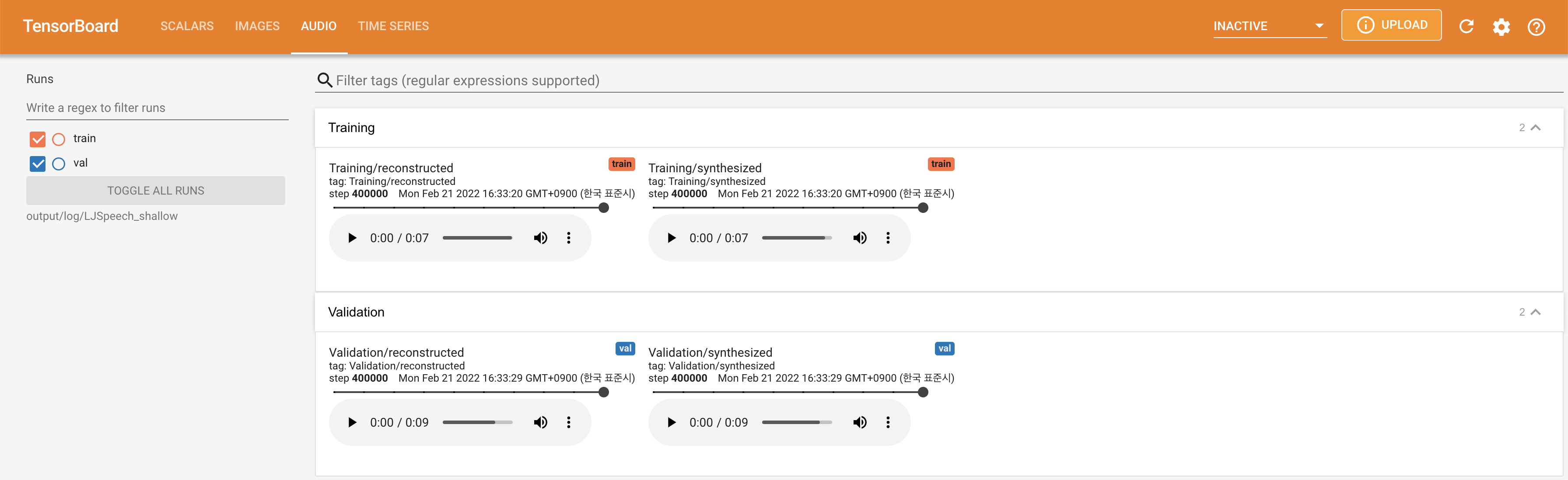
tensorboard --logdir output/log/DATASET
เพื่อให้บริการ Tensorboard บนบ้านของคุณ เส้นโค้งการสูญเสีย mel-spectrograms สังเคราะห์และเสียงจะแสดง
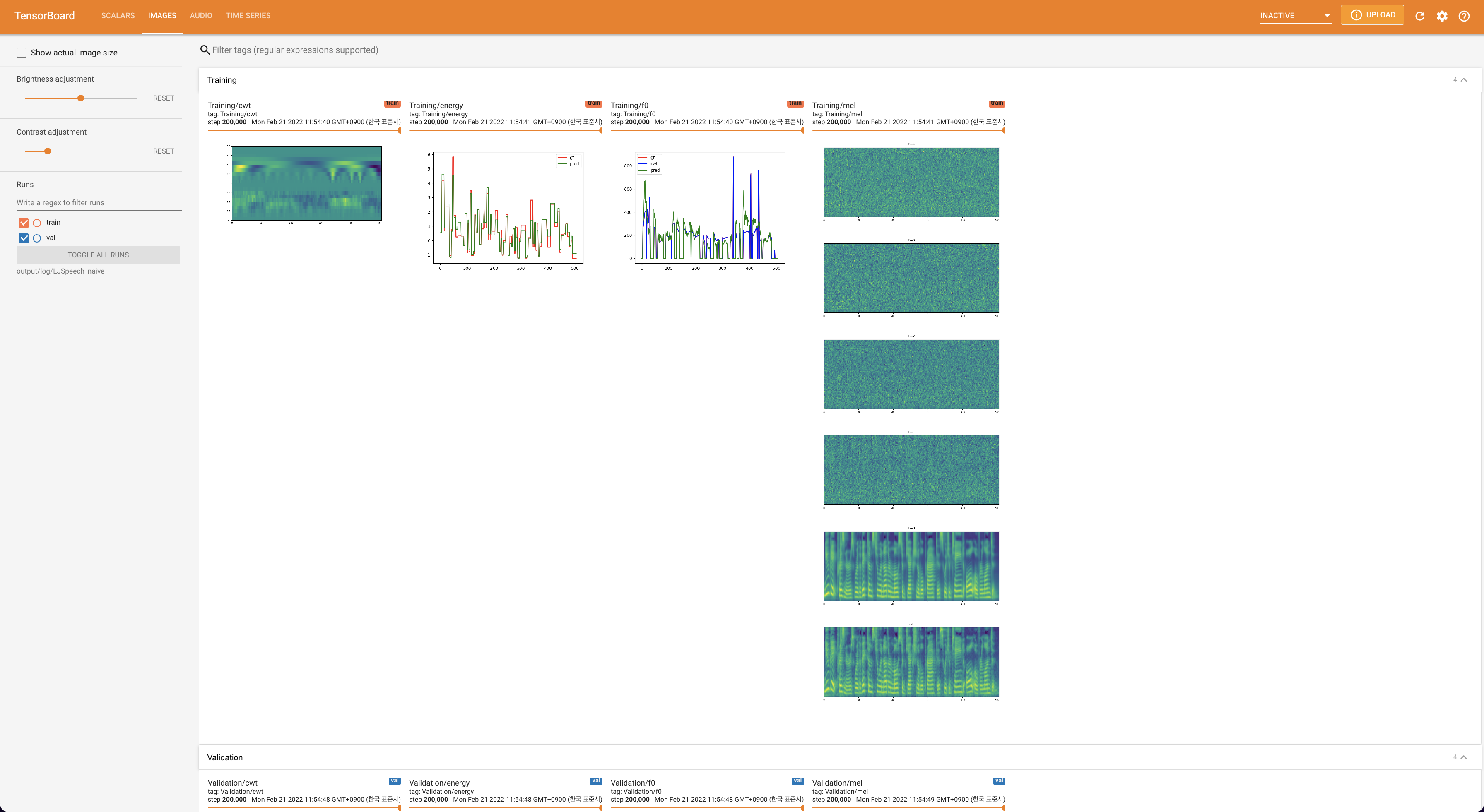
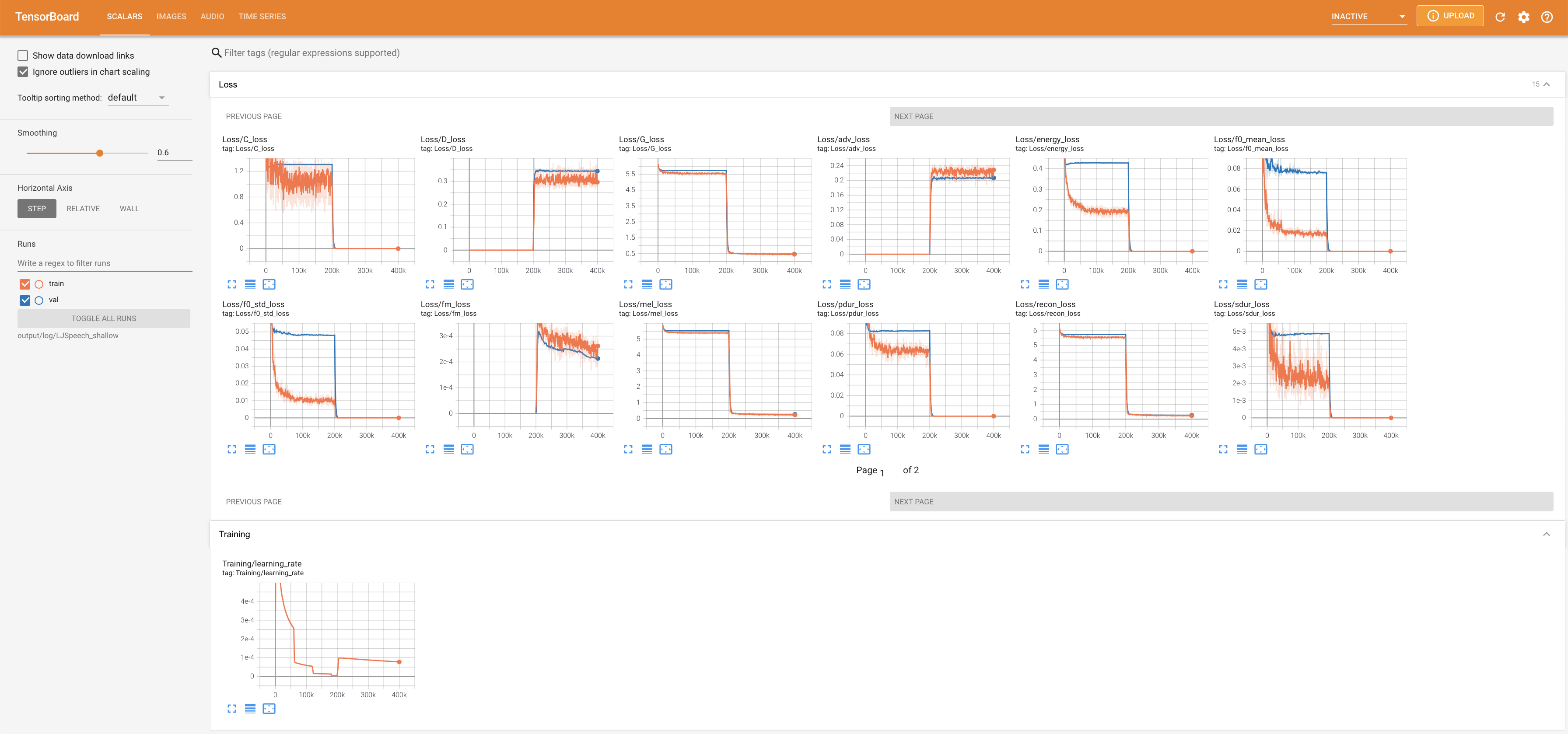
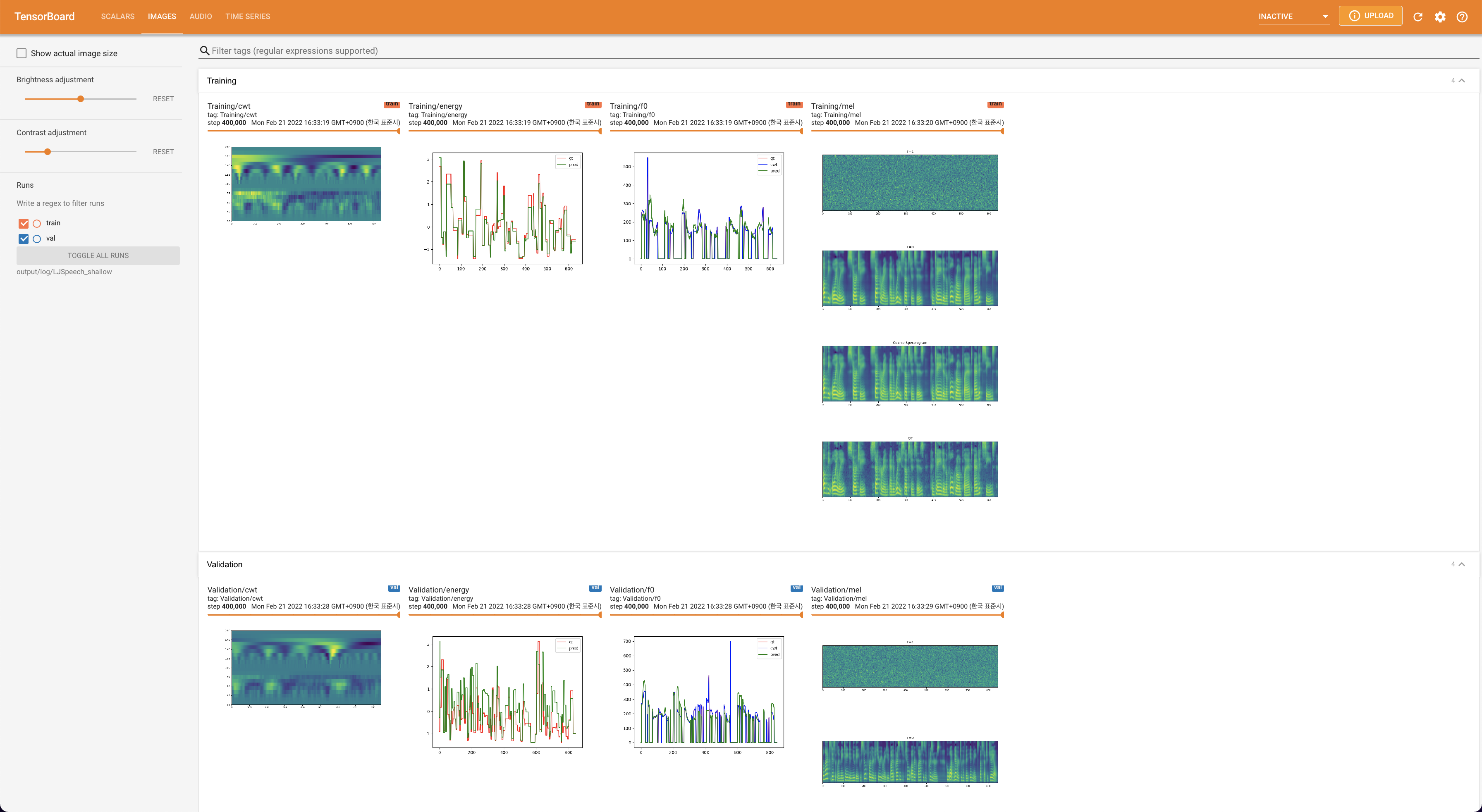
lambda_fm ได้รับการแก้ไขเป็นค่า SCALA เนื่องจากสเกลาร์สเกลสเกลแบบไดนามิกที่คำนวณเป็น L_RECON/L_FM ทำให้โมเดลระเบิด'none' และ 'DeepSpeaker' )
โปรดอ้างอิงพื้นที่เก็บข้อมูลนี้โดย "อ้างอิงที่เก็บนี้" ของส่วน เกี่ยวกับ (ขวาบนของหน้าหลัก)


