DiffGAN TTS
1.0.0
Pytorch Implémentation de Diffgan-TT
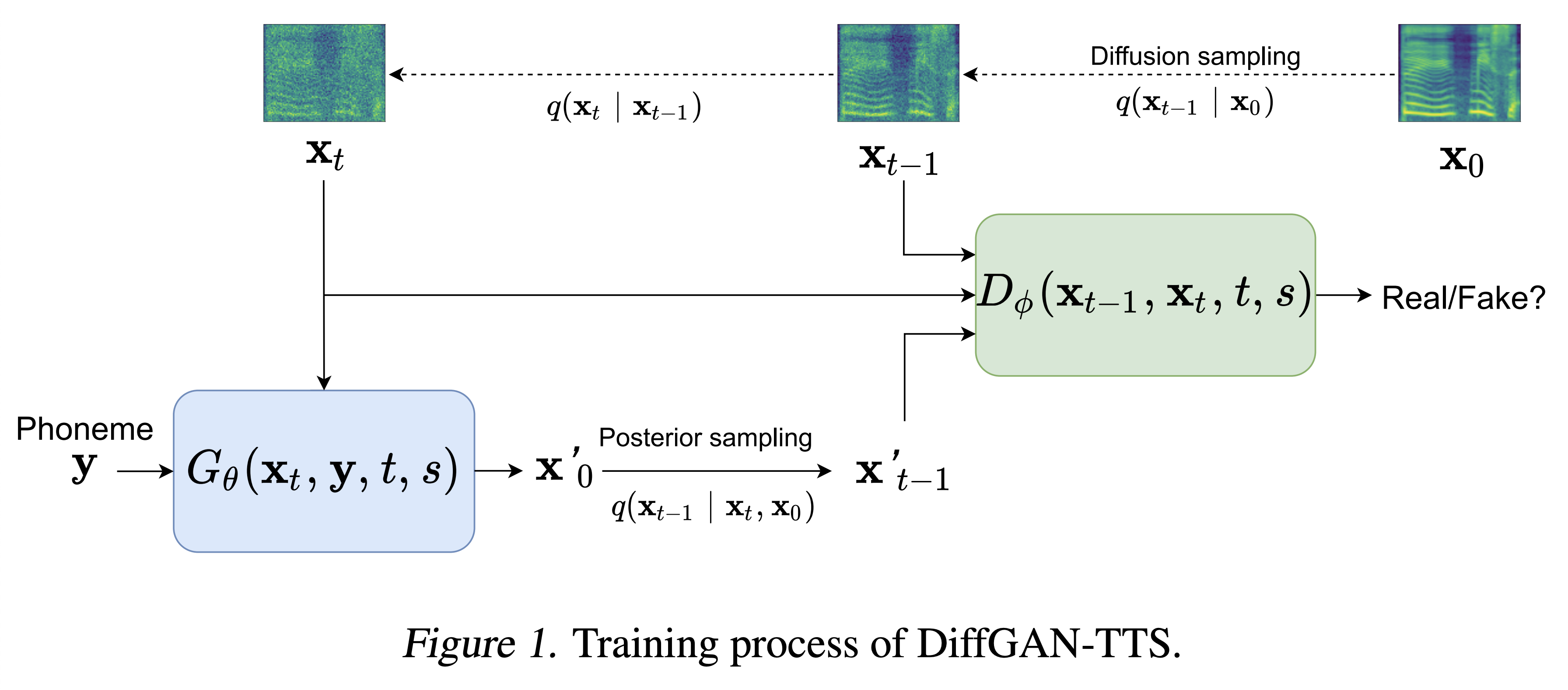
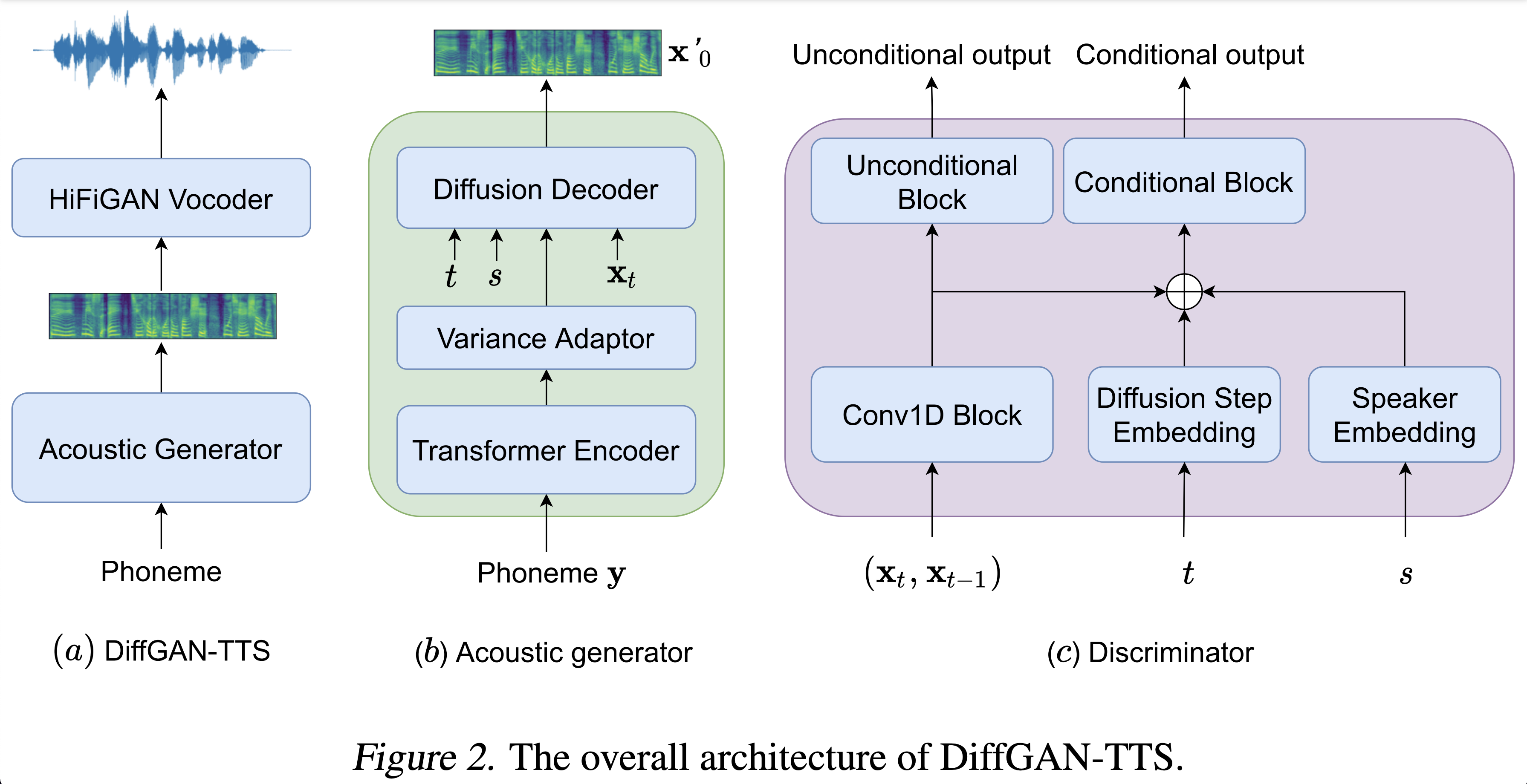
Des échantillons audio sont disponibles à / démo.
L'ensemble de données fait référence aux noms des ensembles de données tels que LJSpeech et VCTK dans les documents suivants.
Le modèle fait référence aux types de modèle (choisissez parmi « naïf », « aux », « superficiel »).
Vous pouvez installer les dépendances Python avec
pip3 install -r requirements.txt
Vous devez télécharger les modèles pré-entraînés et les mettre
output/ckpt/DATASET_naive/ pour le modèle « naïf ».output/ckpt/DATASET_shallow/ pour le modèle « peu profond ». Veuillez noter que le point de contrôle du modèle « peu profond » contient à la fois des modèles « peu profonds » et « AUX », et ces deux modèles partageront tous les répertoires, sauf les résultats tout au long du processus.Pour un TTS à un seul haut-parleur , courez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Pour un TTS multi-haut-parleurs , exécutez
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Le dictionnaire des enceintes savants peut être trouvé sur preprocessed_data/DATASET/speakers.json , et les énoncés générés seront placés en output/result/ .
L'inférence par lots est également prise en charge, essayez
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Pour synthétiser toutes les énoncés dans preprocessed_data/DATASET/val.txt .
La hauteur / volume / le taux de parole des énoncés synthétisés peut être contrôlé en spécifiant les rapports de pitch / énergie / durée souhaités. Par exemple, on peut augmenter le taux de parole de 20% et diminuer le volume de 20% par
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Veuillez noter que la contrôlabilité provient de FastSpeech2 et non un intérêt vital de Diffgan-TTS.
Les ensembles de données pris en charge sont
LJSPEECH: Un ensemble de données anglais à un seul haut-parleur se compose de 13100 clips audio courts d'une conférencière de lecture féminine de 7 livres non-fiction, environ 24 heures au total.
VCTK: Le corpus CSTR VCTK comprend les données de la parole prononcées par 110 anglophones ( TTS multi-ordres ) avec divers accents. Chaque conférencier lit environ 400 phrases, qui ont été sélectionnées dans un journal, le passage de l'arc-en-ciel et un paragraphe d'élicitation utilisé pour les archives d'accent de la parole.
Pour un TTS multi-haut-parleurs avec un intérêt de haut-parleur externe, téléchargez Rescnn Softmax + Triplet Pretraind Model of Philippermy's DeepPeaker pour le haut-parleur incorpore et le localisez dans ./deepspeaker/pretrained_models/ .
Courir
python3 prepare_align.py --dataset DATASET
pour certaines préparatifs.
Pour l'alignement forcé, l'aligneur forcé de Montréal (MFA) est utilisé pour obtenir les alignements entre les énoncés et les séquences de phonèmes. Les alignements pré-extractés pour les ensembles de données sont fournis ici. Vous devez décompresser les fichiers dans preprocessed_data/DATASET/TextGrid/ . Alternativement, vous pouvez exécuter l'aligneur par vous-même.
Après cela, exécutez le script de prétraitement par
python3 preprocess.py --dataset DATASET
Vous pouvez former trois types de modèle: « naïf », « aux » et « peu profonds ».
Formation Version naïve (« naïve »):
Former la version naïve avec
python3 train.py --model naive --dataset DATASET
Formation Modèle acoustique de base pour la version peu profonde (« Aux »):
Pour entraîner la version peu profonde, nous avons besoin d'un FastSpeech2 pré-formé. La commande ci-dessous vous permettra de former les modules FastSpeech2, y compris le décodeur auxiliaire (MEL).
python3 train.py --model aux --dataset DATASET
Formation Version superficielle (« superficielle »):
Pour tirer parti du décodeur FastSpeech2 pré-formé, y compris le décodeur auxiliaire (MEL), vous devez passer --restore_step avec la dernière étape de la formation Auxiliaire FastSpeech2 comme la commande suivante.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Par exemple, si le dernier point de contrôle est enregistré à 200000 étapes pendant la formation auxiliaire, vous devez définir --restore_step avec 200000 . Ensuite, il chargera et congelera le modèle AUX, puis continuera la formation sous le mécanisme de diffusion peu profond actif.
Utiliser
tensorboard --logdir output/log/DATASET
pour servir Tensorboard sur votre hôte local. Les courbes de perte, les spectrogrammes de MEL synthétisés et les audios sont affichés.
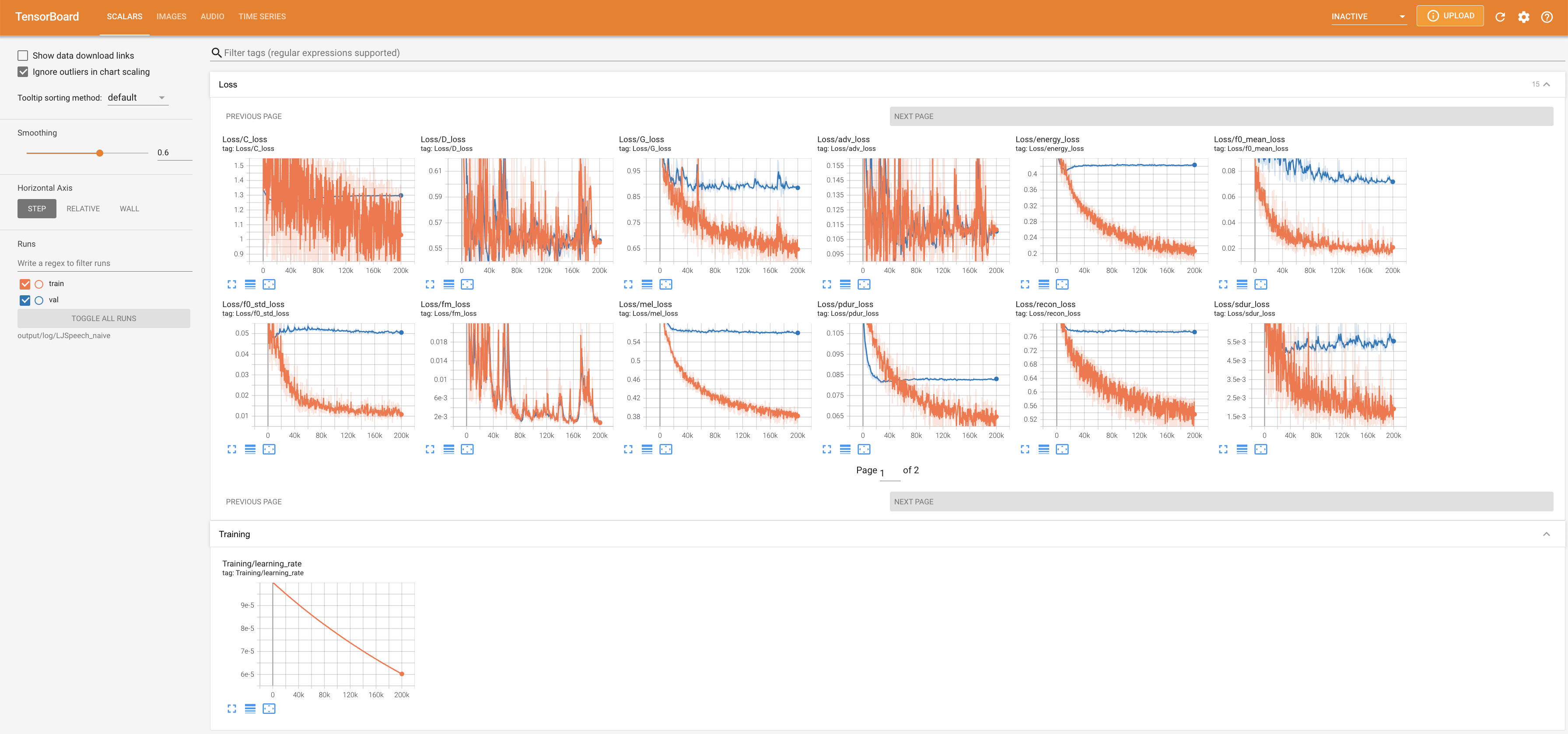
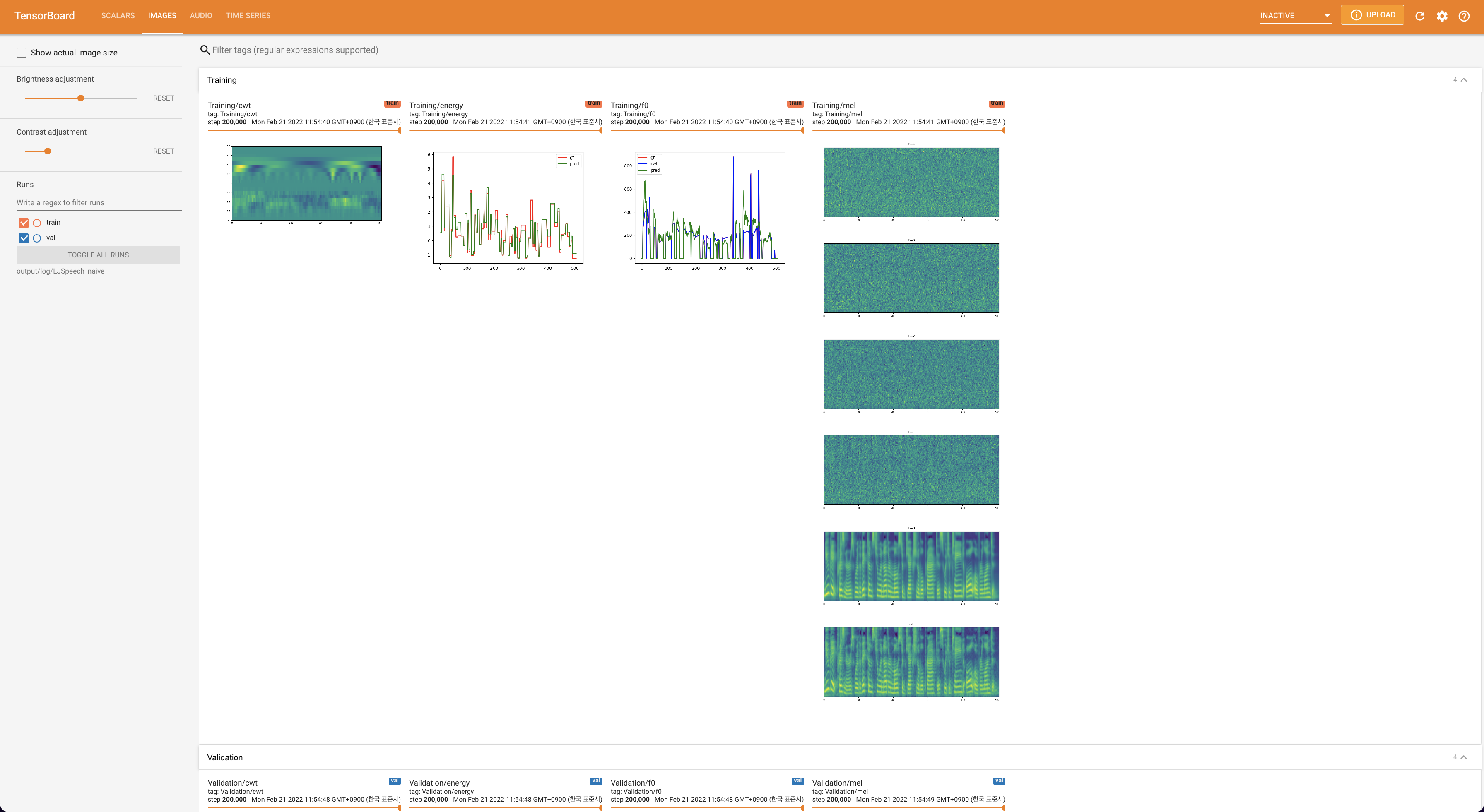
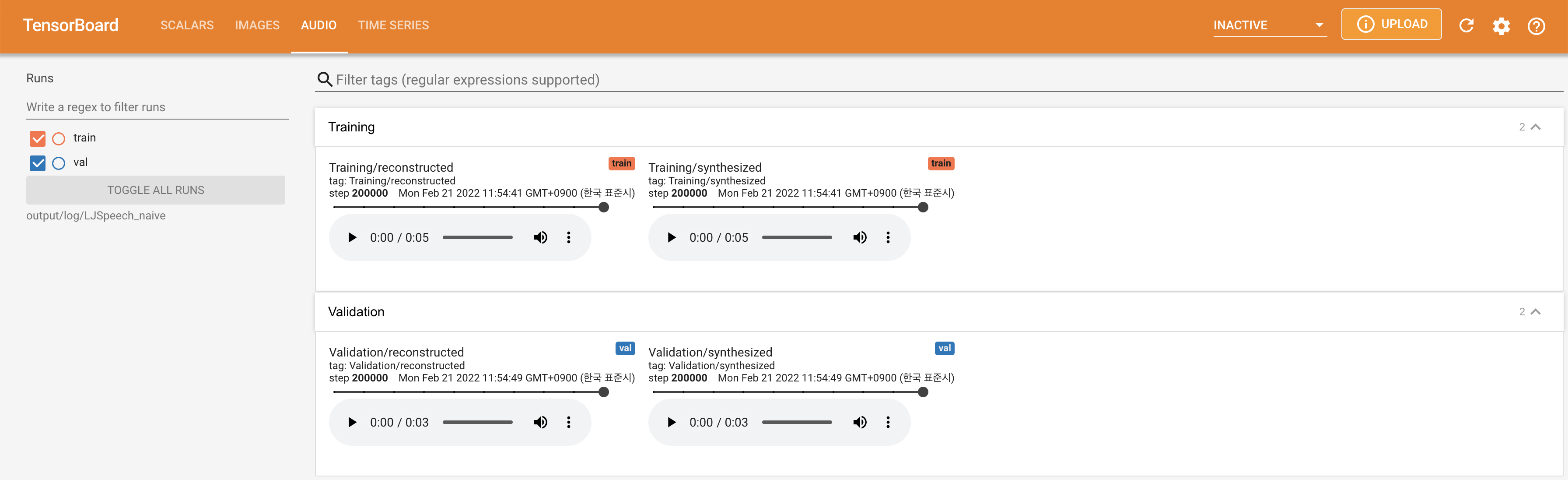
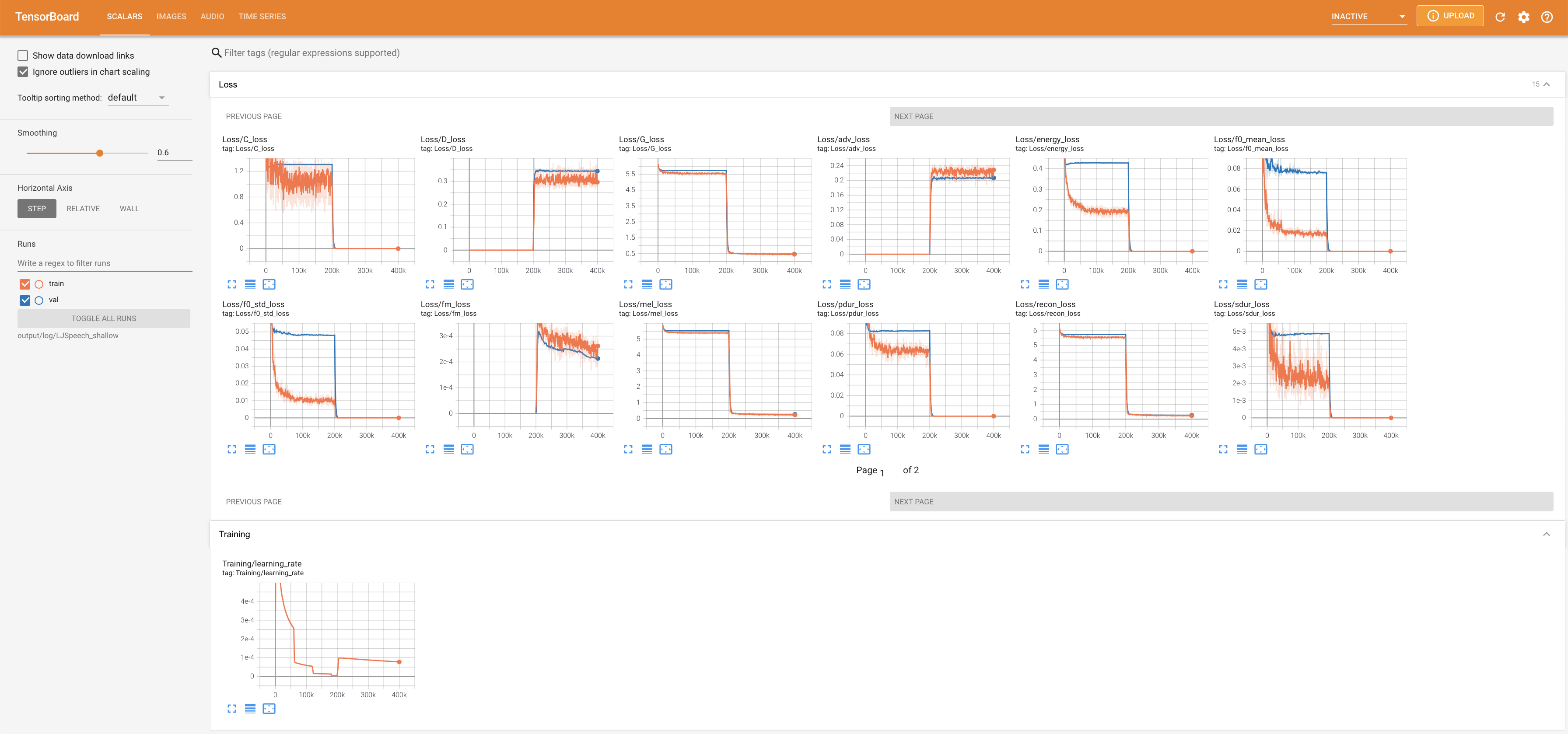
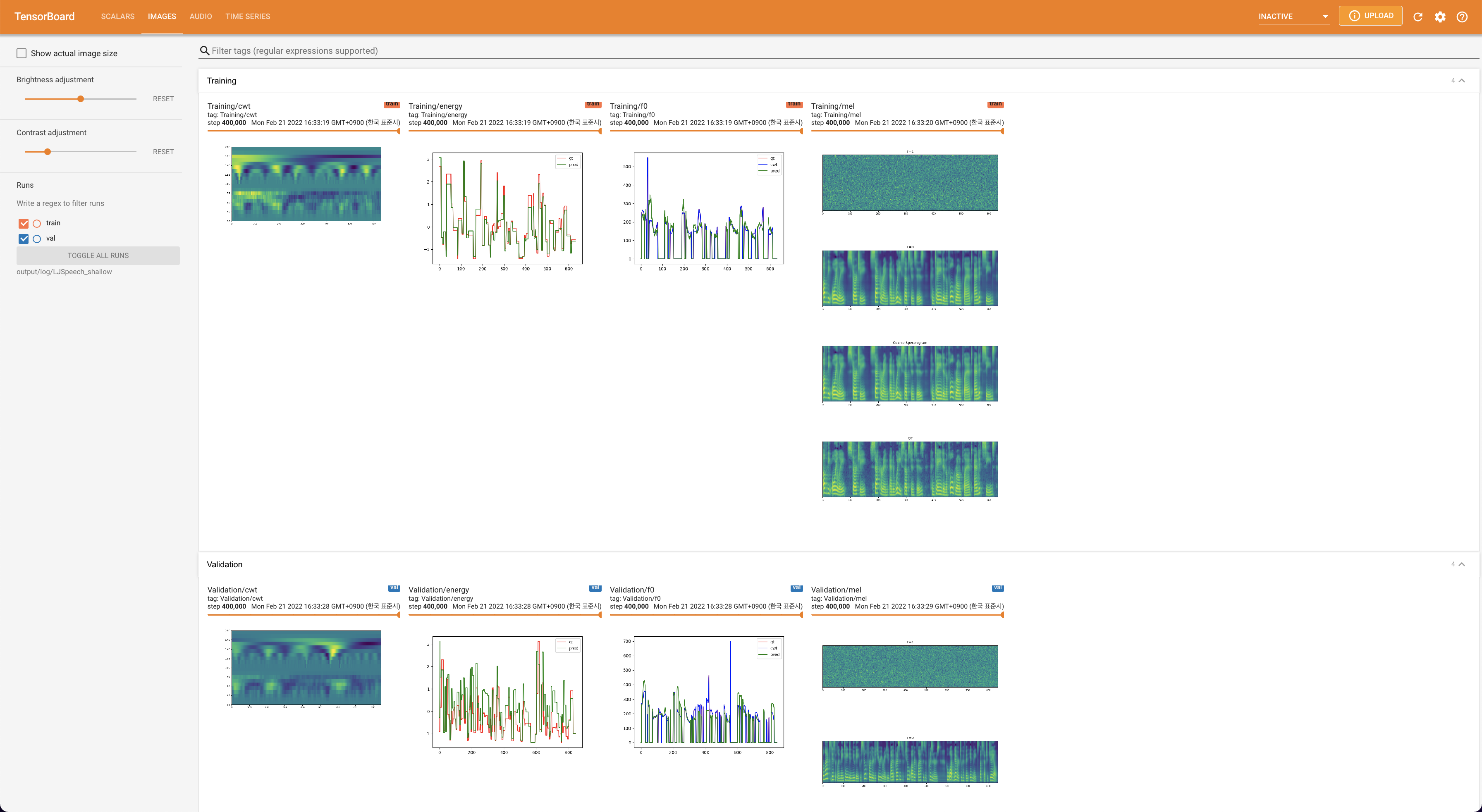
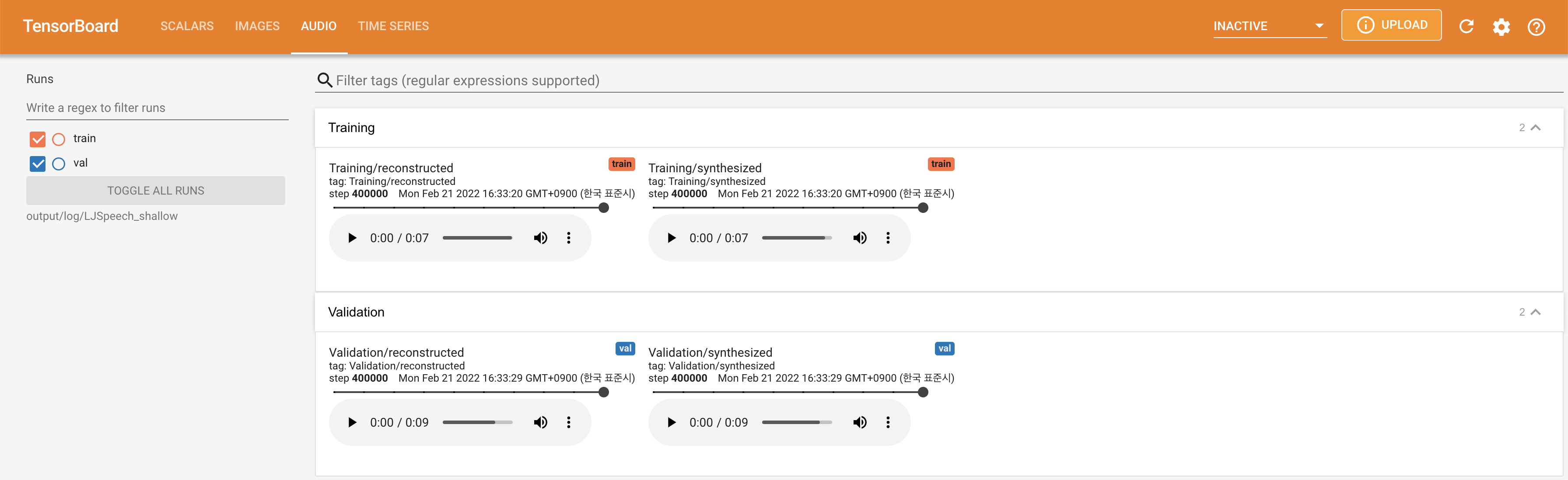
lambda_fm est fixé à une valeur scala car le scalaire à l'échelle dynamiquement calculé comme L_recon / L_FM fait exploser le modèle.'none' et 'DeepSpeaker' ).
Veuillez citer ce référentiel par le "Citez ce référentiel" de la section environ (en haut à droite de la page principale).


