DiffGAN TTS
1.0.0
Реализация Pytorch Diffgan-TTS: высокая точка и эффективная текст в речь с двойной диффузией Gans
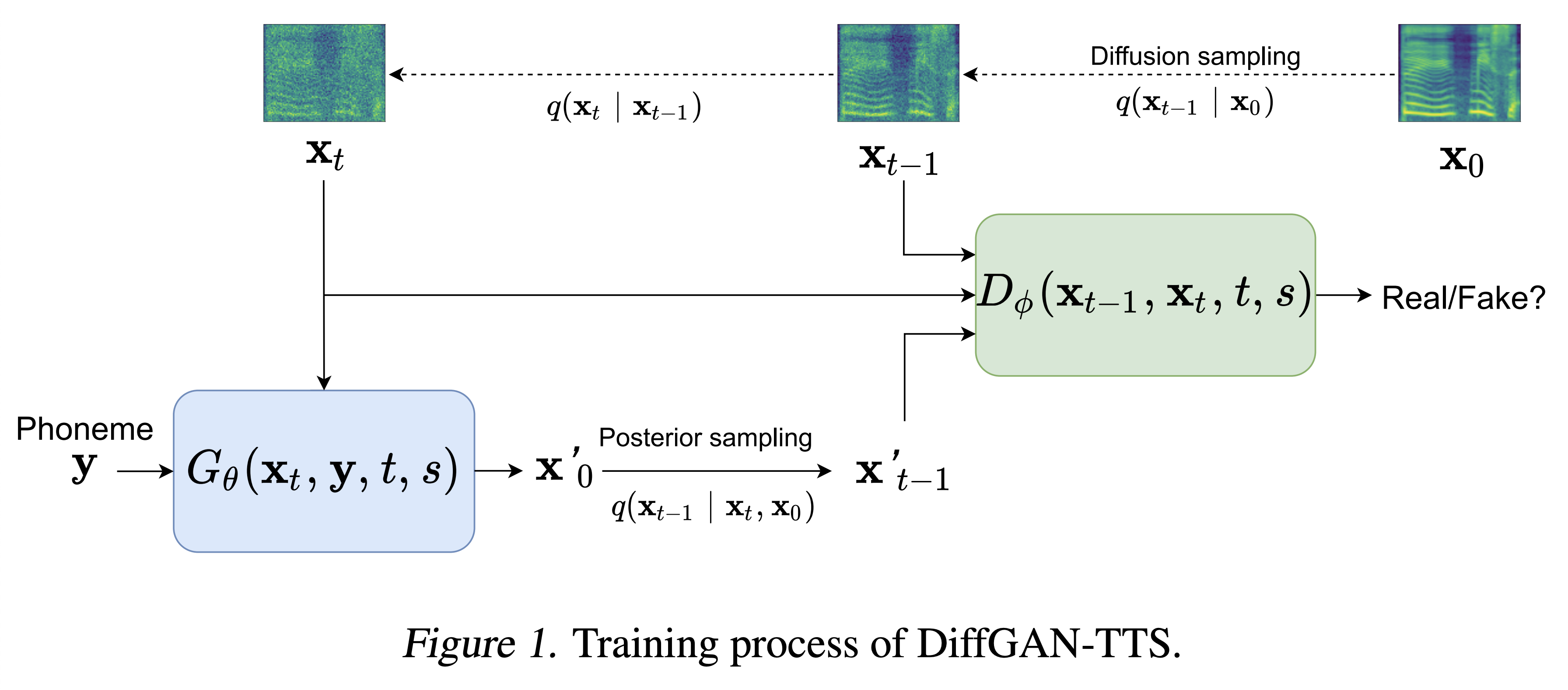
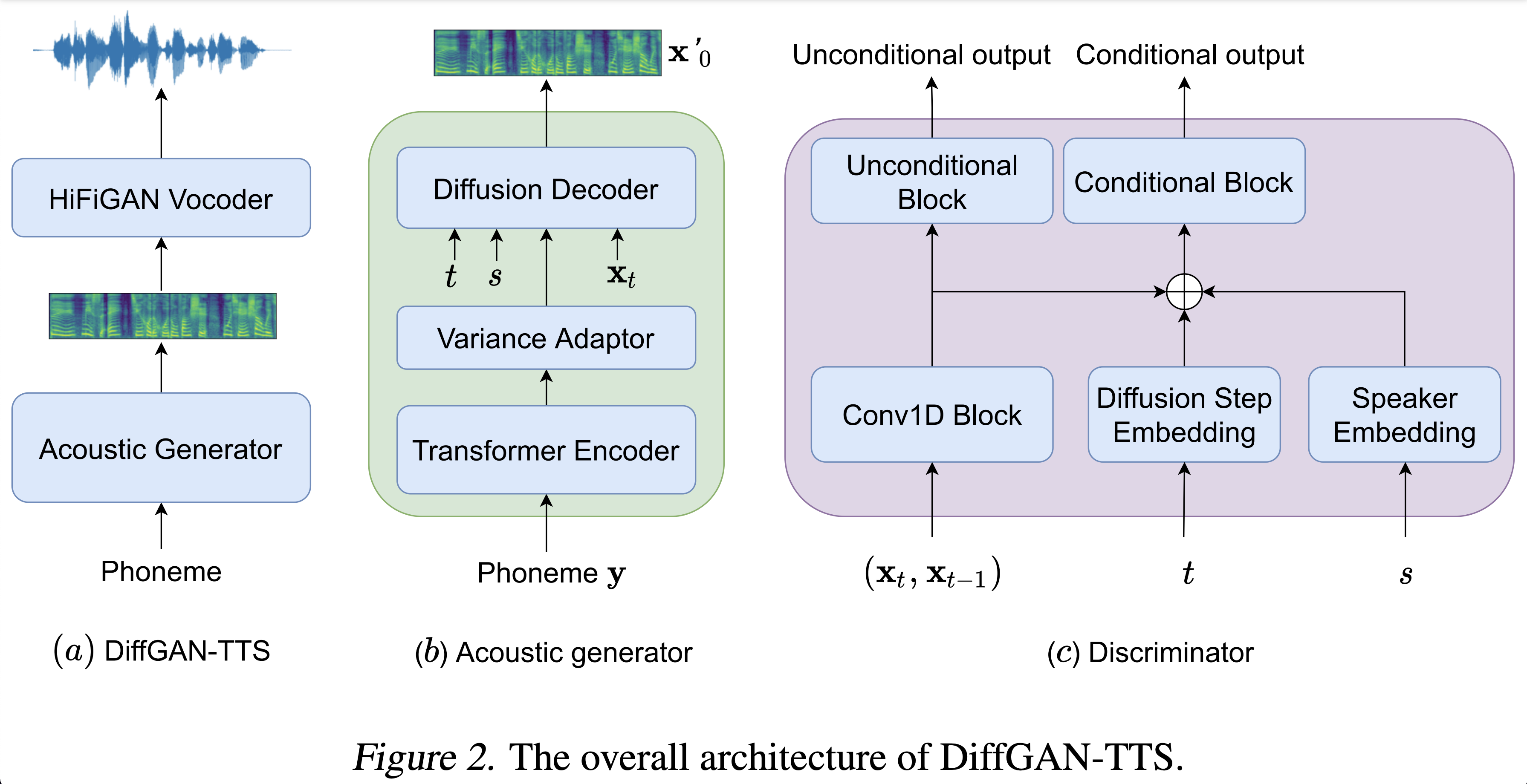
Образцы аудио доступны в /демо.
Набор данных относится к именам наборов данных, таких как LJSpeech и VCTK в следующих документах.
Модель относится к типам модели (выберите « Наив », « aux », « мелкий »).
Вы можете установить зависимости Python с
pip3 install -r requirements.txt
Вы должны скачать предварительно подготовленные модели и поместить их в
output/ckpt/DATASET_naive/ для « наивной » модели.output/ckpt/DATASET_shallow/ для « неглубокой » модели. Обратите внимание, что контрольная точка « мелкой » модели содержит как « мелкие », так и модели « Aux », и эти две модели будут использовать все каталоги, за исключением результатов на протяжении всего процесса.Для одноразовых TTS , бегите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Для многопрофильных TTS , запустите
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Словарь ученых докладчиков можно найти на preprocessed_data/DATASET/speakers.json output/result/
Пакетный вывод также поддерживается, попробуйте
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Чтобы синтезировать все высказывания в preprocessed_data/DATASET/val.txt .
Скорость шага/объема/разговора синтезированных высказываний можно контролировать, указав желаемый коэффициент высоты/энергии/продолжительности. Например, можно увеличить скорость разговора на 20 % и уменьшить объем на 20 % на
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Обратите внимание, что управляемость происходит от Fastspeech2, а не жизненно важного интереса Diffgan-TTS.
Поддерживаемые наборы данных
LJSPEECH: Английский набор данных с одним дивиксером состоит из 13100 коротких аудио-клипов женского поступления, чтения спикеров от 7 не художественных книг, в общей сложности примерно 24 часа.
VCTK: CSTR VCTK CORPUS включает в себя речевые данные, произнесенные 110 носителями английского языка ( многопрофильные TTS ) с различными акцентами. Каждый оратор читает около 400 предложений, которые были отобраны из газеты, радужный отрывок и абзац выявления, используемый для архива речевого акцента.
Для Multi-Speaker TTS с внешним динамиком Embedder загрузите Rescnn Softmax+триплетный предварительно предварительно предварительно проведенный модели DeepSpeaker Филипперей для динамика, внедряющего его и найдите его в ./deepspeaker/pretrained_models/ .
Бегать
python3 prepare_align.py --dataset DATASET
для некоторых приготовлений.
Для принудительного выравнивания Монреаль принудительный выравниватель (MFA) используется для получения выравнивания между высказываниями и последовательностями фонем. Предварительные выравнивания для наборов данных представлены здесь. Вы должны расстегнуть разанипировать файлы в preprocessed_data/DATASET/TextGrid/ . С другой стороны, вы можете запустить выравниватель самостоятельно.
После этого запустите сценарий предварительной обработки
python3 preprocess.py --dataset DATASET
Вы можете обучить три типа модели: « Наив », « Aux » и « мелкие ».
Обучение наивной версии (« Наив »):
Тренировать наивную версию с
python3 train.py --model naive --dataset DATASET
Обучение основной акустической модели для мелкой версии (« Aux »):
Чтобы тренировать мелкую версию, нам нужна предварительно обученная Fastspeech2. Команда ниже позволит вам обучить модули FastSpeech2, включая вспомогательный (MEL) декодер.
python3 train.py --model aux --dataset DATASET
Учебная неглубокая версия (« мелкая »):
Чтобы использовать предварительно обученный FastSpeech2, включая вспомогательный (MEL) декодер, вы должны пройти --restore_step с последним этапом вспомогательного обучения FastSpeech2 в качестве следующей команды.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Например, если последняя контрольная точка сохраняется в 200000 шагов во время вспомогательного обучения, вам нужно установить --restore_step с 200000 . Затем он загрузит и заморозит модель AUX, а затем продолжит обучение в рамках активного механизма мелкого диффузии.
Использовать
tensorboard --logdir output/log/DATASET
Подавать в Tensorboard на вашем местном хосте. Кривые потерь, синтезированные мель-спектрограммы и аудио показаны.
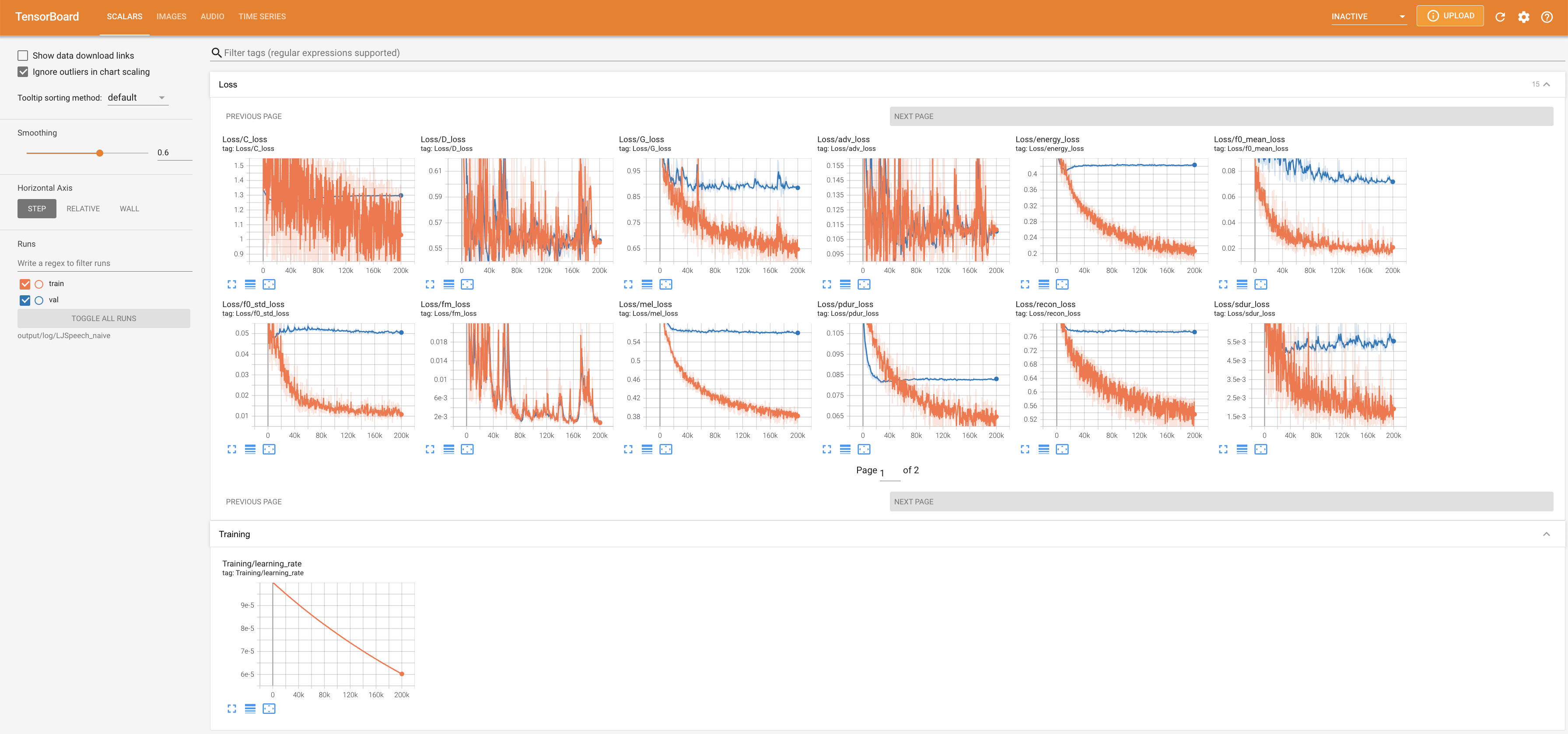
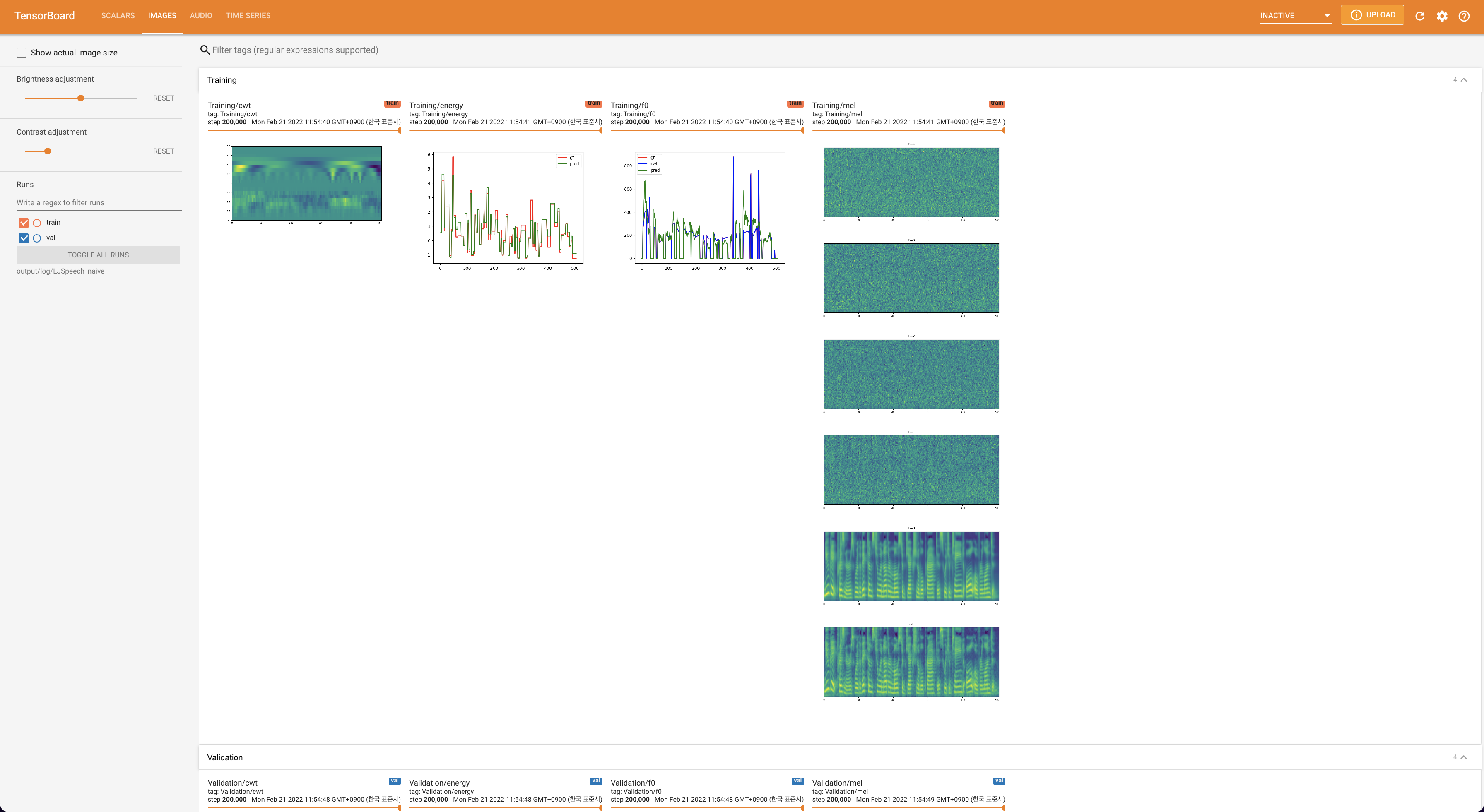
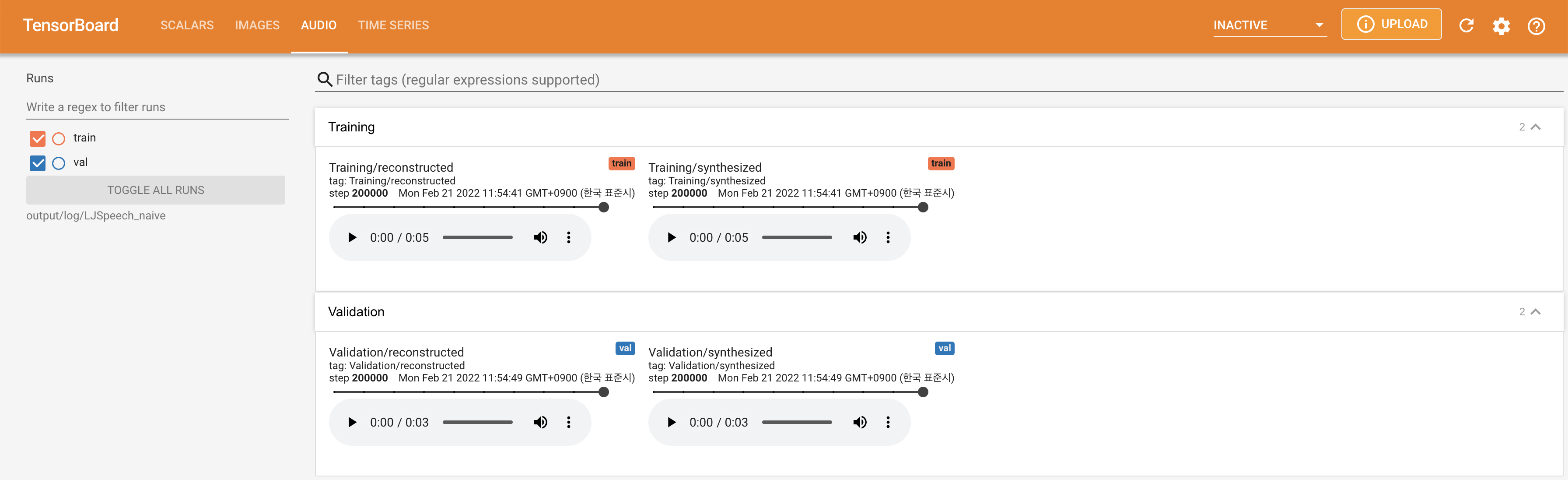
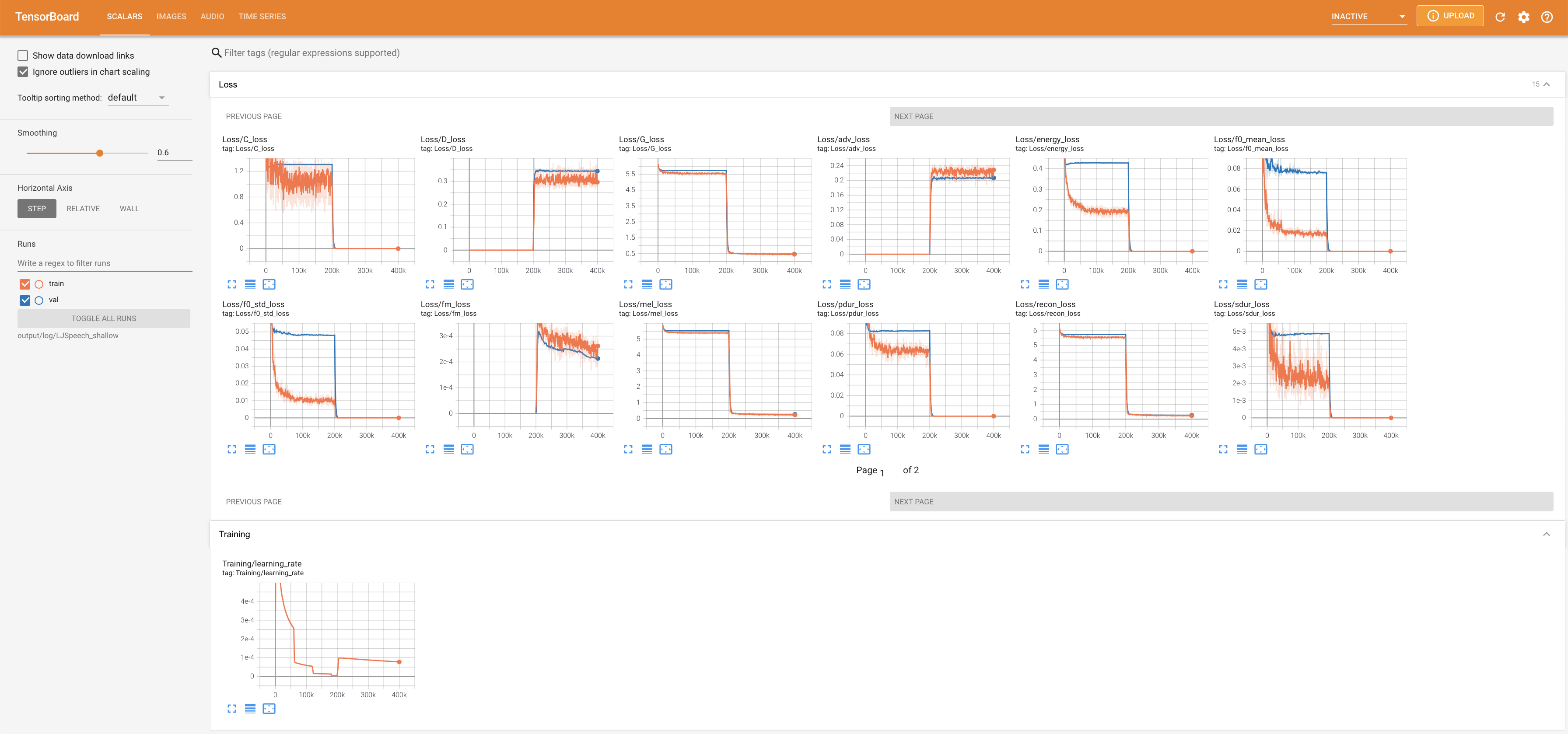
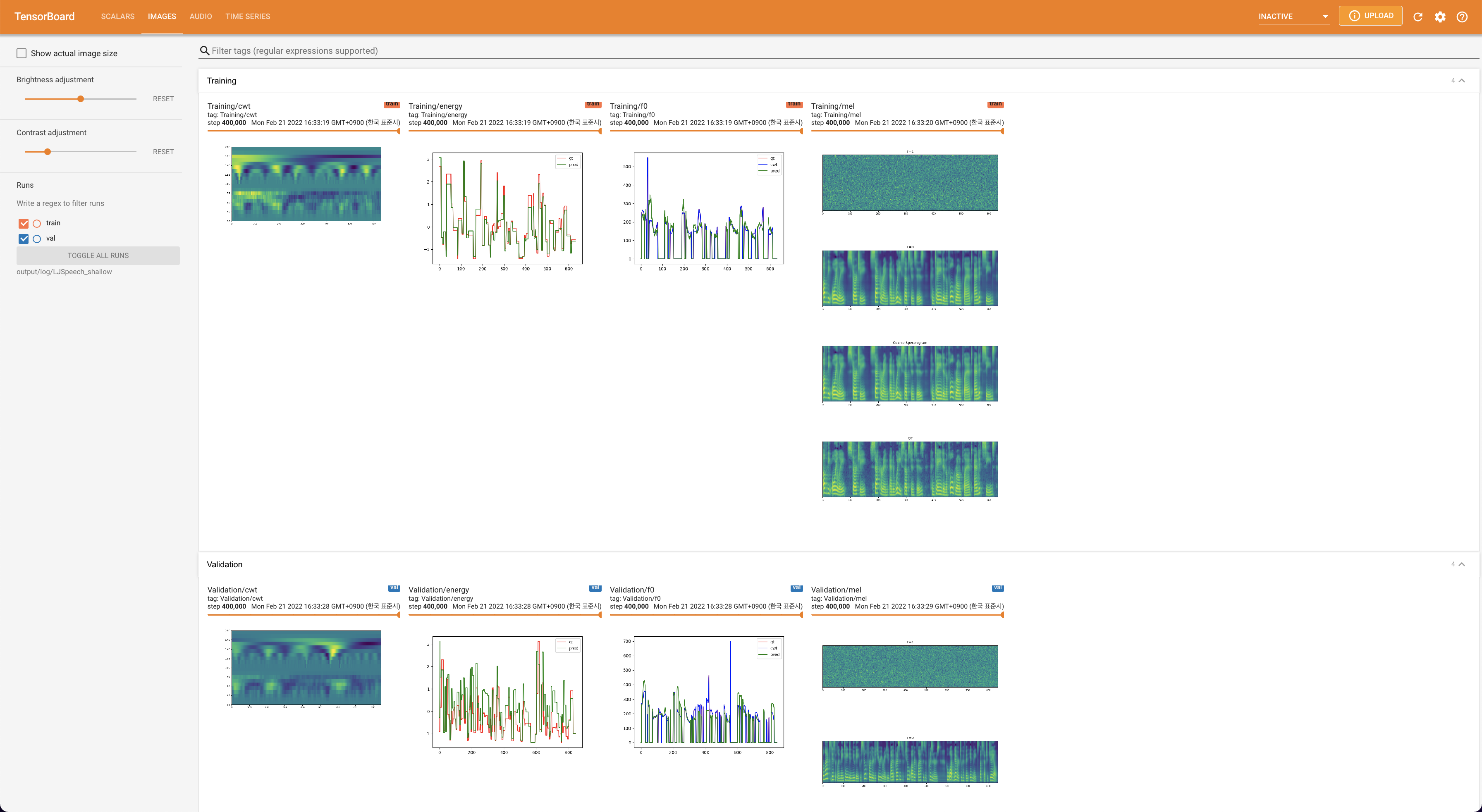
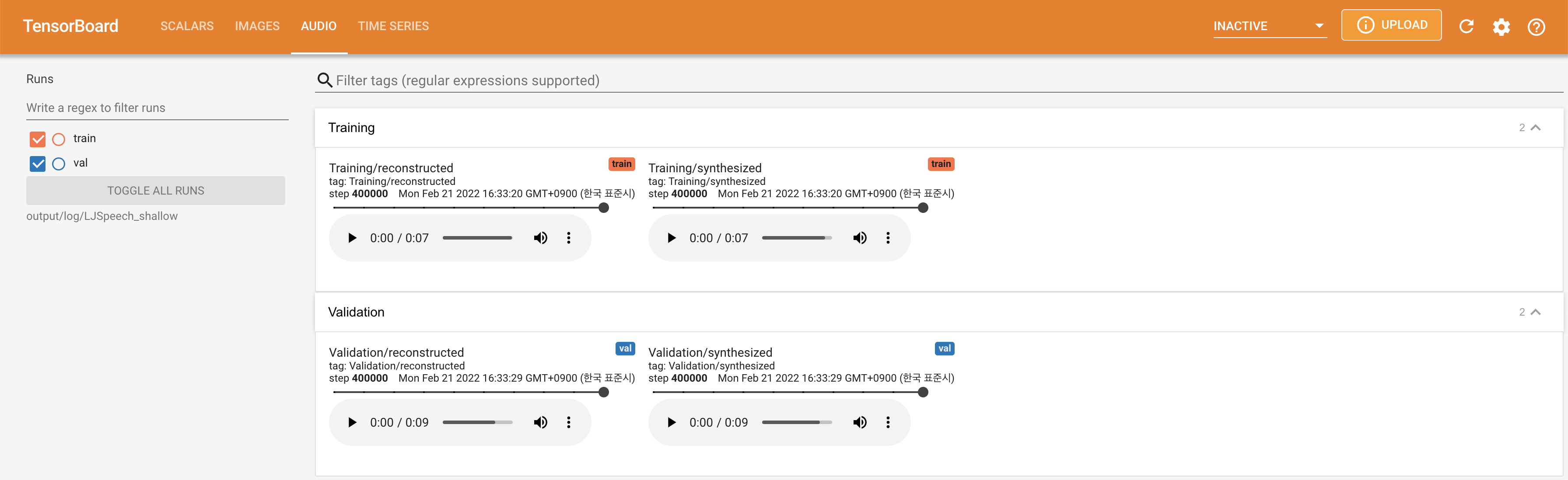
lambda_fm прикреплен к значению SCALA, поскольку динамически масштабированный скаляр, вычисленный как L_RECON/L_FM, заставляет модель взрываться.'none' и 'DeepSpeaker' ).
Пожалуйста, цитируйте этот репозиторий с помощью «цитируйте этот репозиторий» о разделе (верхняя правая на главной странице).


