DiffGAN TTS
1.0.0
تنفيذ Pytorch من Diffgan-TTS: عالي الدقة والكفاءة النصية إلى الكلام مع تقليل الانتشار gans
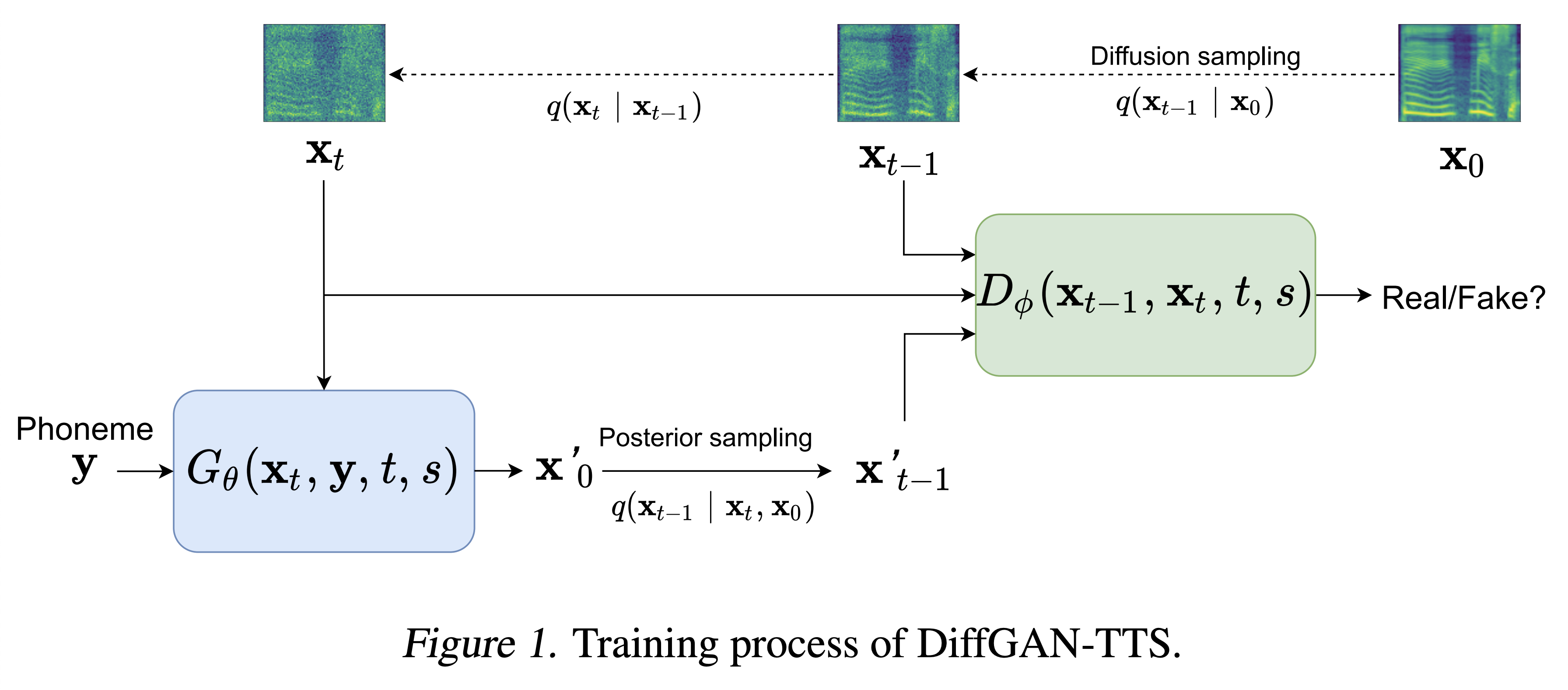
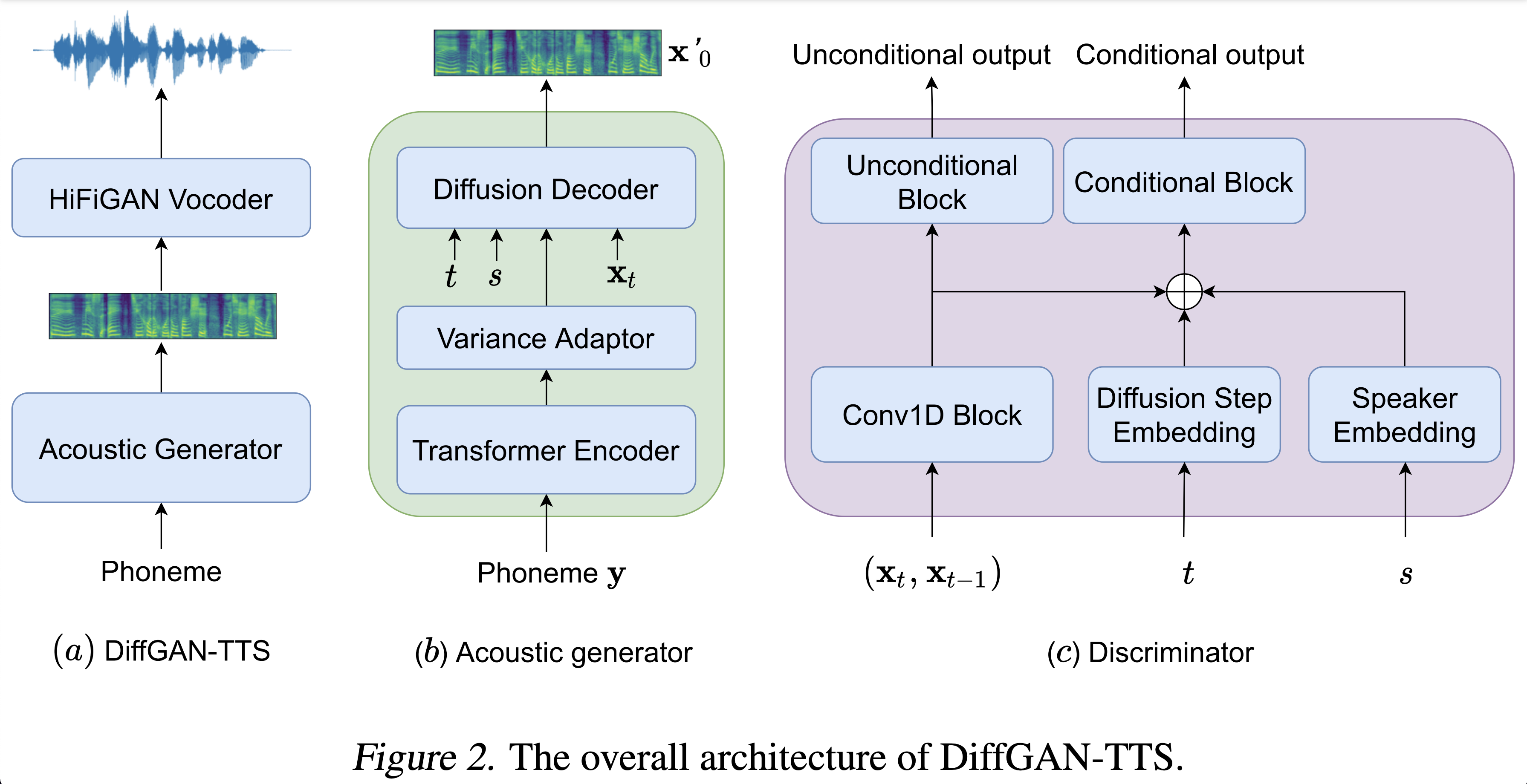
عينات الصوت متوفرة في /العرض التوضيحي.
تشير مجموعة البيانات إلى أسماء مجموعات البيانات مثل LJSpeech و VCTK في المستندات التالية.
يشير النموذج إلى أنواع النموذج (اختر من " ساذجة " ، " aux " ، " ضحلة ").
يمكنك تثبيت تبعيات Python مع
pip3 install -r requirements.txt
يجب عليك تنزيل النماذج المسبقة ووضعها في
output/ckpt/DATASET_naive/ لنموذج " ساذج ".output/ckpt/DATASET_shallow/ لنموذج " الضحلة ". يرجى ملاحظة أن نقطة تفتيش النموذج " الضحل " تحتوي على كل من طرازي " الضحلة " و " AUX " ، وسيشارك هذان النموذجان جميع الدلائل باستثناء النتائج طوال العملية.للحصول على TTS واحد ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
للحصول على TTS متعددة المتحدثين ، قم بتشغيل
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
يمكن العثور على قاموس مكبرات الصوت المستفادة في preprocessed_data/DATASET/speakers.json output/result/
يتم دعم استنتاج الدُفعات أيضًا ، حاول
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
لتوليف جميع الكلمات في preprocessed_data/DATASET/val.txt .
يمكن السيطرة على معدل الملعب/الحجم/التحدث للكلمات التوليف عن طريق تحديد نسب الملعب/الطاقة/المدة المطلوبة. على سبيل المثال ، يمكن للمرء زيادة معدل التحدث بنسبة 20 ٪ وتقليل الحجم بنسبة 20 ٪ بنسبة 20 ٪
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
يرجى ملاحظة أن قابلية التحكم نشأت من Fastspeade2 وليس مصلحة حيوية لـ Diffgan-TTS.
مجموعات البيانات المدعومة
LJSPEEDE: تتكون مجموعة بيانات إنجليزية واحدة من 13100 مقاطع صوتية قصيرة من ممرات مكبرات الصوت من 7 كتب غير خيالية ، حوالي 24 ساعة في المجموع.
VCTK: يتضمن CSTR VCTK Corpus بيانات الكلام التي ينطقها 110 مكبرات صوت باللغة الإنجليزية ( TTS متعددة المتحدثين ) مع لهجات مختلفة. يقرأ كل متحدث حوالي 400 جملة ، تم اختيارها من إحدى الصحف ، وممر قوس قزح وفقرة استنباط تستخدم لأرشيف لهجة الكلام.
للحصول على TTS متعددة الكلام مع مكبر صوت خارجي ، قم بتنزيل نموذج RAVERMAX+TREPLET PRESTERED من Deepspeaker من Philipperemy لدمجه ويحدد موقعه ./deepspeaker/pretrained_models/
يجري
python3 prepare_align.py --dataset DATASET
لبعض الاستعدادات.
بالنسبة للمحاذاة القسرية ، يتم استخدام Montreal القسري Aligner (MFA) للحصول على المحاذاة بين الكلمات وتسلسلات الصوت. يتم توفير محاذاة مسبقًا لمجموعات البيانات هنا. يجب عليك إلغاء ضغط الملفات في preprocessed_data/DATASET/TextGrid/ . بالتناوب ، يمكنك تشغيل جهاز Aligner بنفسك.
بعد ذلك ، قم بتشغيل البرنامج النصي المسبق
python3 preprocess.py --dataset DATASET
يمكنك تدريب ثلاثة أنواع من النماذج: " ساذجة " و " aux " و " الضحلة ".
تدريب النسخة الساذجة (" ساذجة "):
تدريب النسخة الساذجة مع
python3 train.py --model naive --dataset DATASET
تدريب النموذج الصوتي الأساسي للإصدار الضحل (' aux '):
لتدريب النسخة الضحلة ، نحتاج إلى fastspech2 المدربة مسبقًا. سيتيح لك الأمر أدناه تدريب وحدات Fastspeade2 ، بما في ذلك وحدة فك ترميز (MEL) المساعد (MEL).
python3 train.py --model aux --dataset DATASET
تدريب النسخة الضحلة (" ضحلة "):
للاستفادة من Fastspeesh2 المدربة مسبقًا ، بما في ذلك وحدة فك ترميز (MEL) المساعد (MEL) ، يجب أن تمر- --restore_step مع الخطوة الأخيرة من تدريب Fastspeade2 المساعد كأمر التالي.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
على سبيل المثال ، إذا تم حفظ نقطة التفتيش الأخيرة في 200000 خطوة خلال التدريب الإضافي ، فيجب عليك تعيين --restore_step مع 200000 . ثم سيتم تحميل نموذج AUX وتجميده ثم متابعة التدريب تحت آلية الانتشار الضحلة النشطة.
يستخدم
tensorboard --logdir output/log/DATASET
لخدمة Tensorboard على مضيفك المحلي. يتم عرض منحنيات الخسارة ، وتوليف الطيف الطيف ، والسمعات.
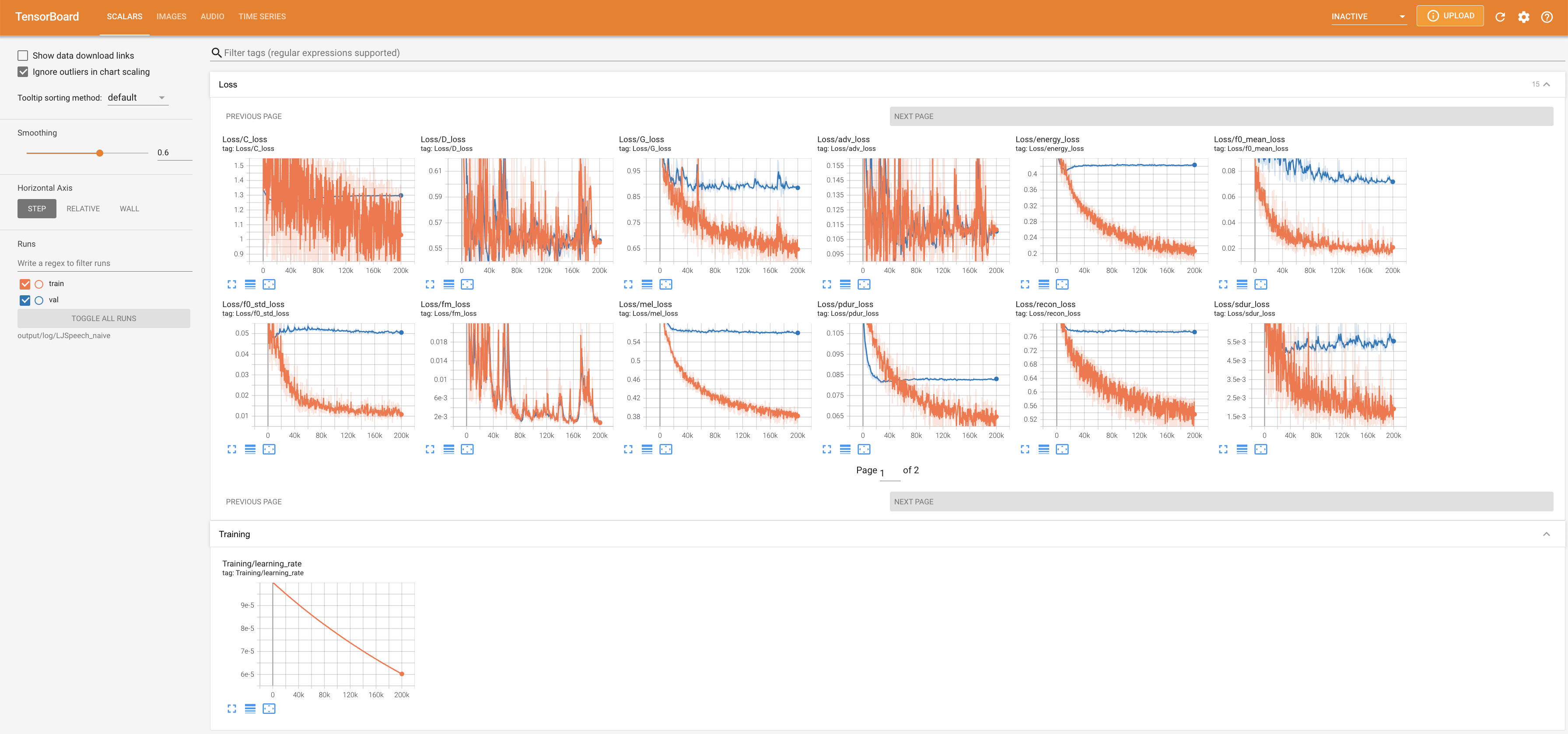
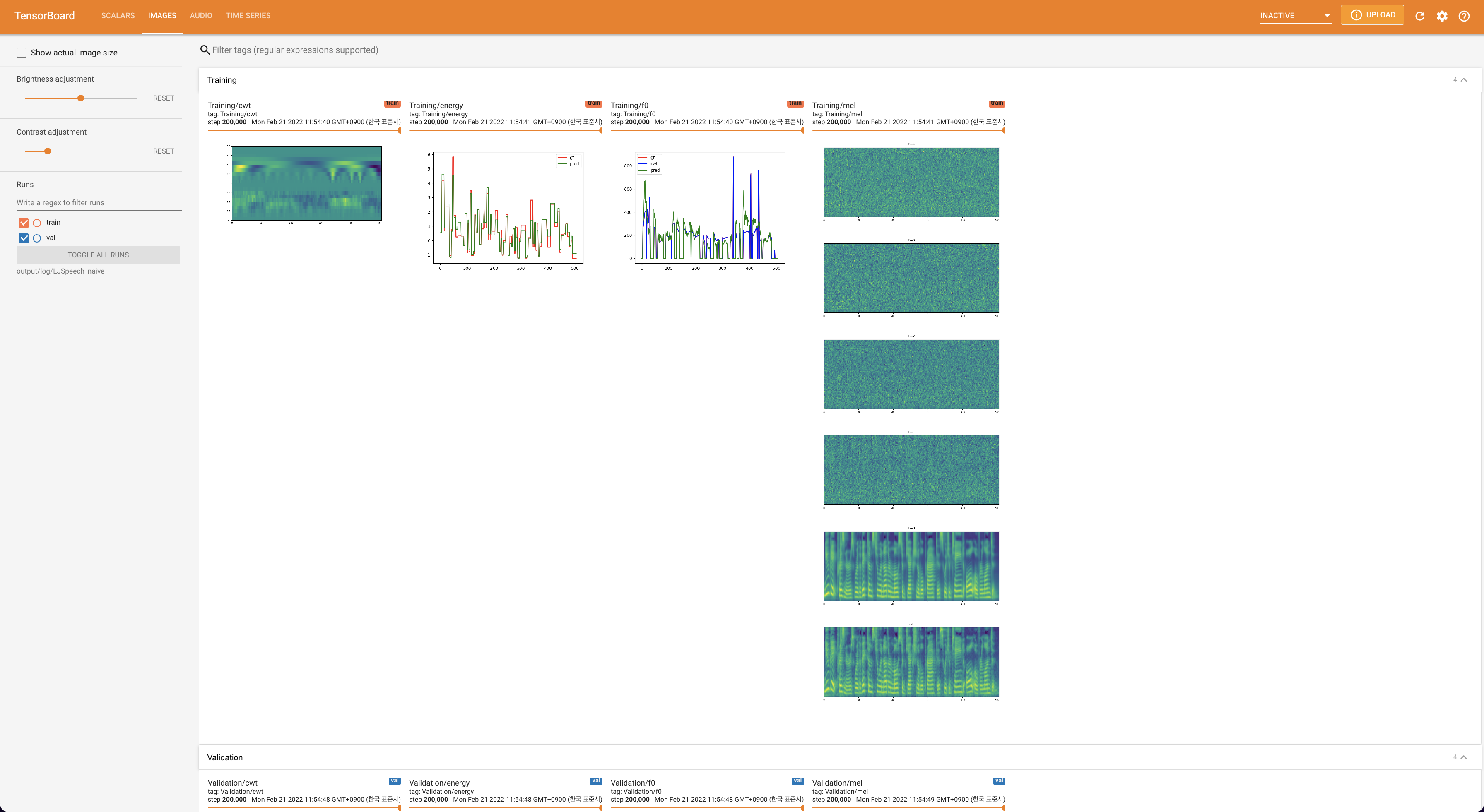
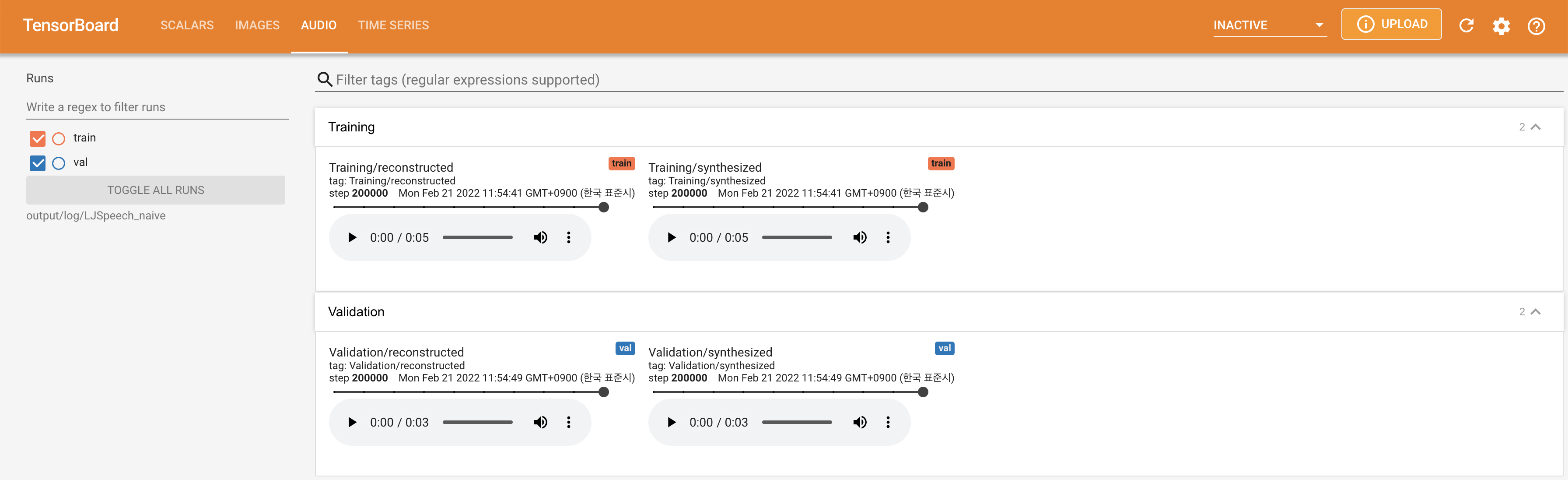
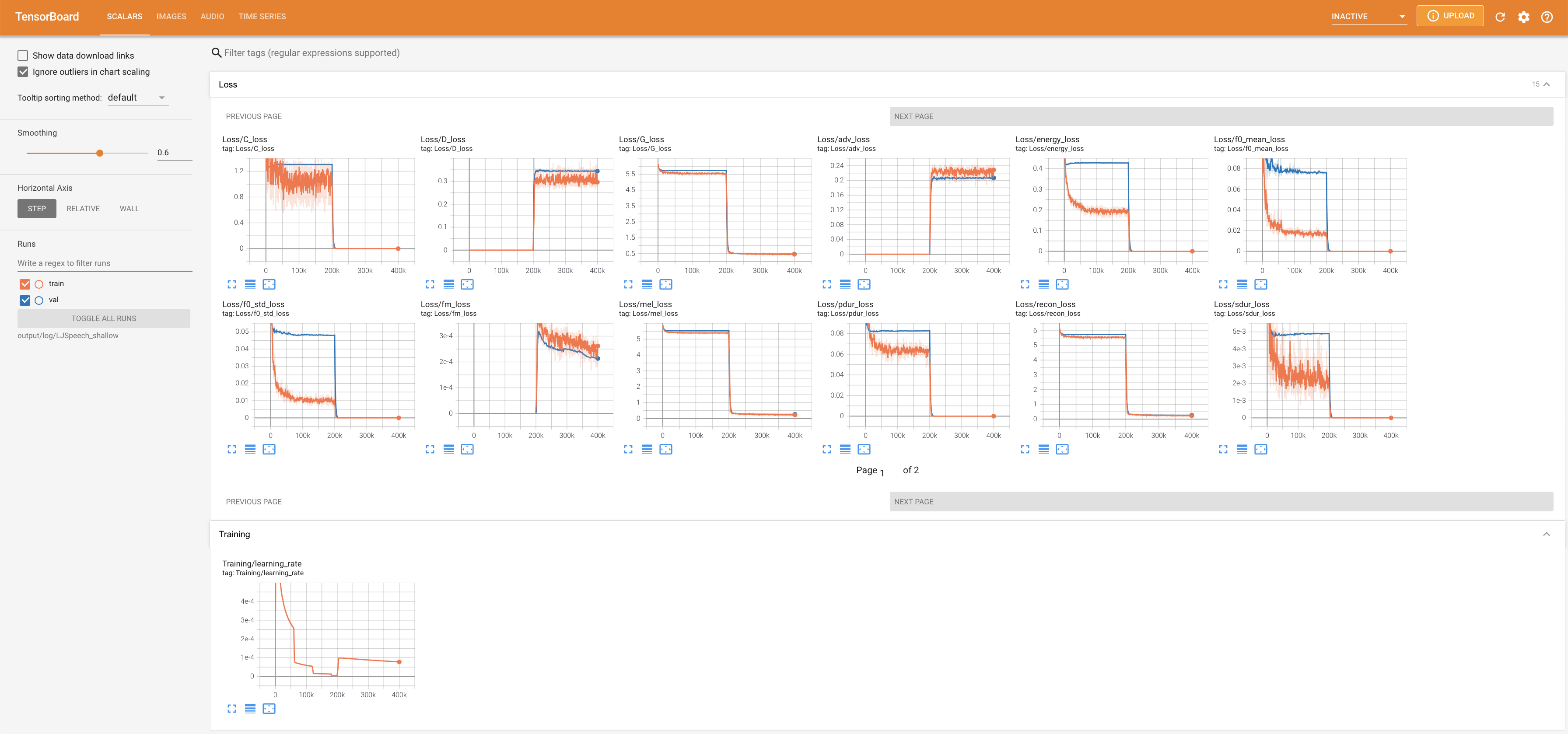
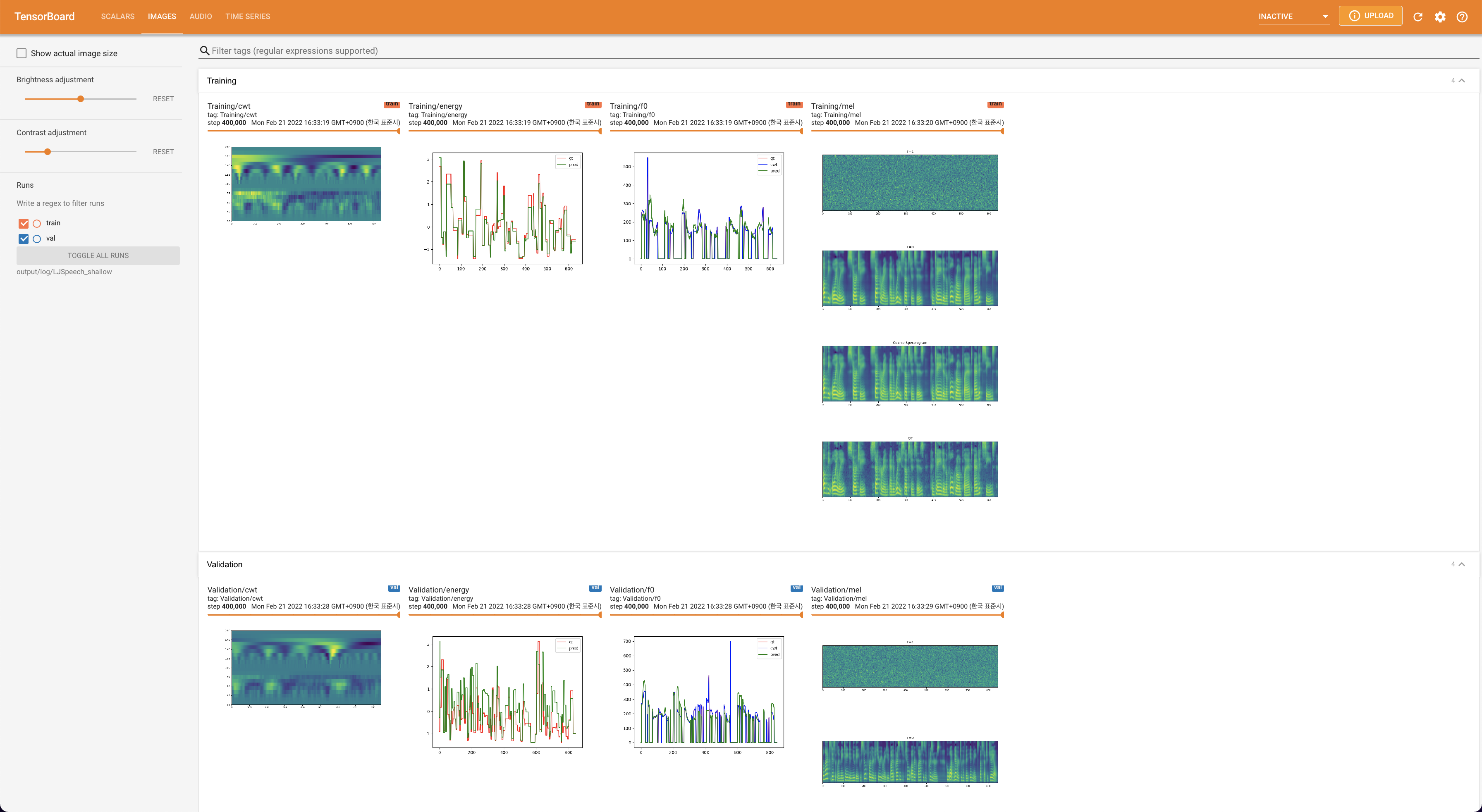
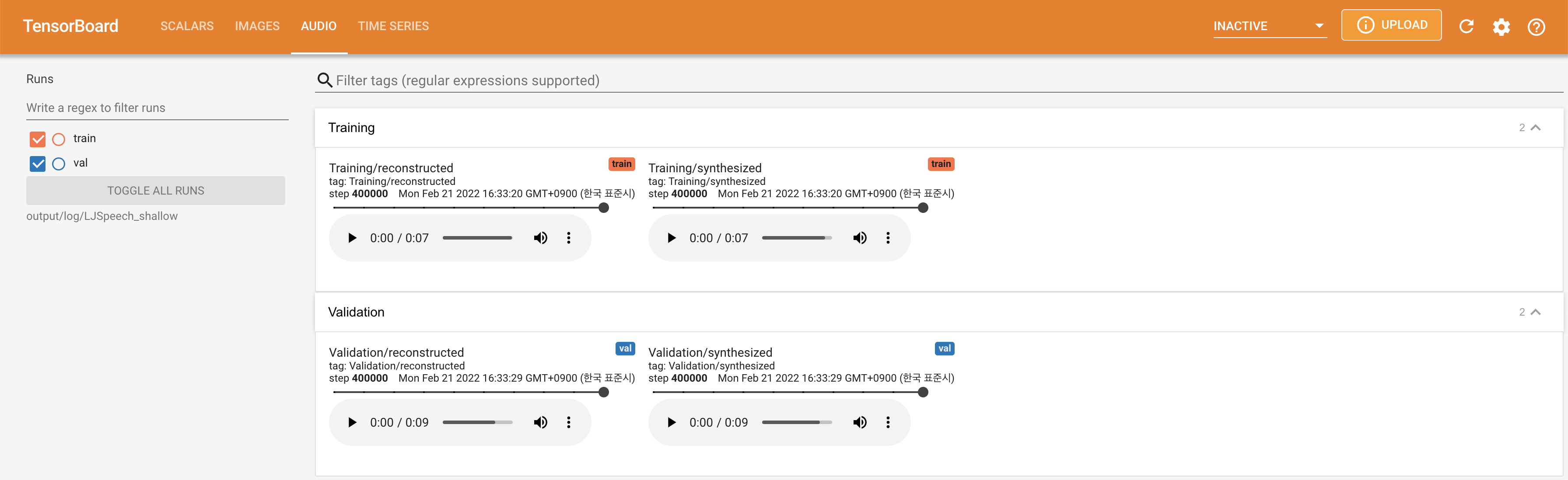
lambda_fm على قيمة Scala لأن القياس المقيد ديناميكيًا محسوبًا كـ L_Recon/L_FM يجعل النموذج ينفجر.'none' و 'DeepSpeaker' ).
يرجى الاستشهاد بهذا المستودع من خلال "استشهد بهذا المستودع" من القسم (أعلى يمين الصفحة الرئيسية).


