DiffGAN TTS
1.0.0
Implementación de Pytorch de Diffgan-TTS: alta fidelidad y texto a voz eficiente con Gans de difusión de renovación
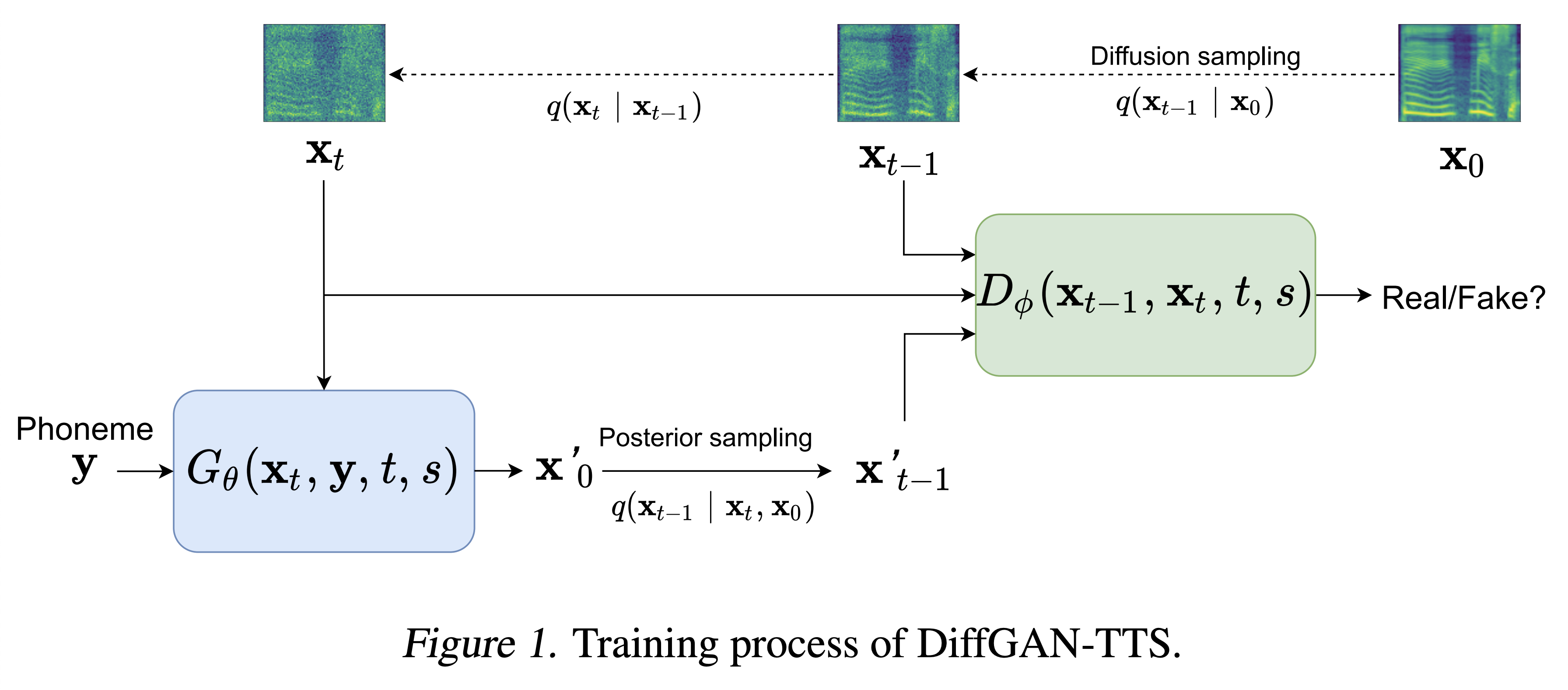
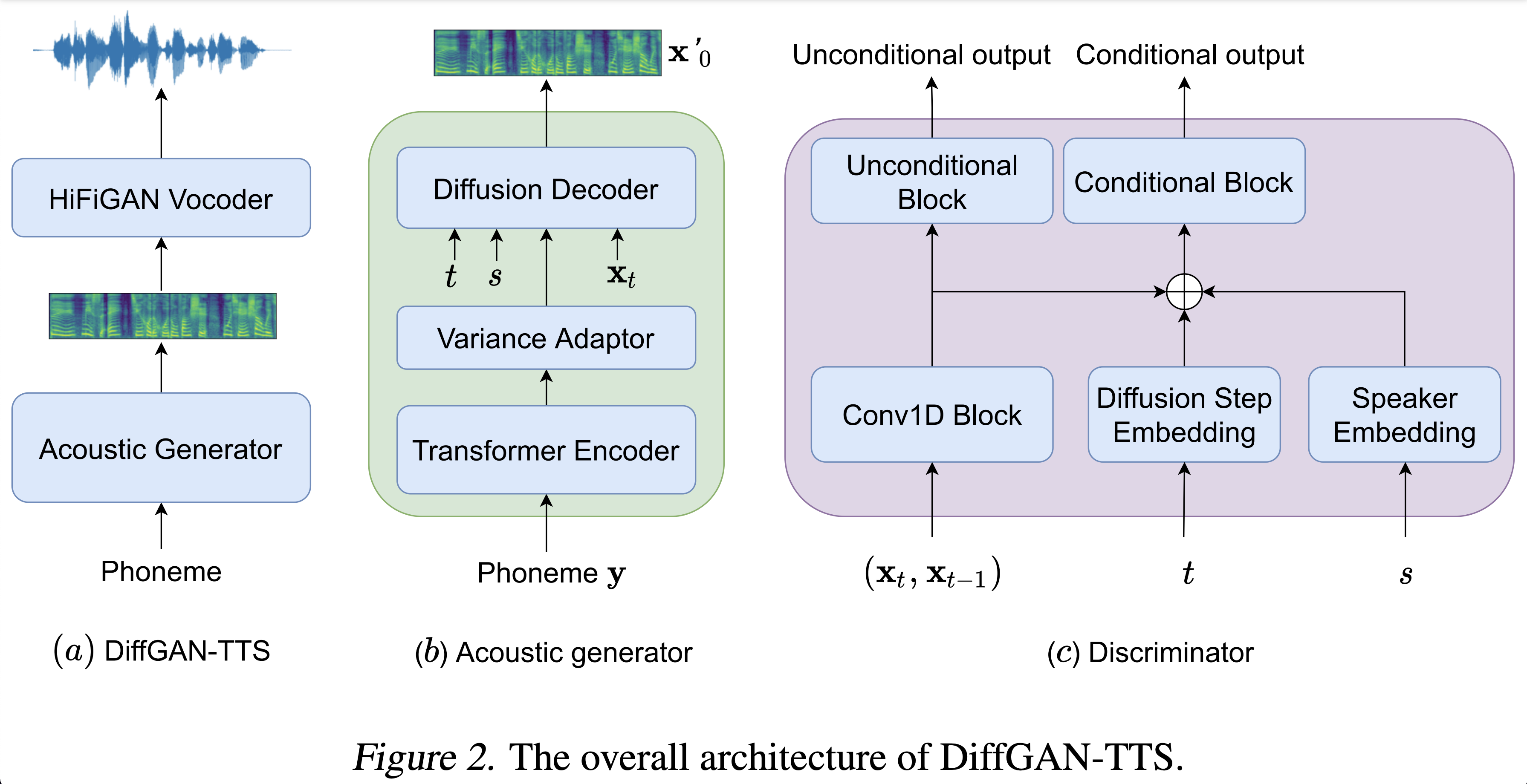
Las muestras de audio están disponibles en /demostración.
El conjunto de datos se refiere a los nombres de conjuntos de datos como LJSpeech y VCTK en los siguientes documentos.
El modelo se refiere a los tipos de modelo (elija entre ' ingenuo ', ' aux ', ' superficial ').
Puede instalar las dependencias de Python con
pip3 install -r requirements.txt
Tienes que descargar los modelos previos a la aparición y ponerlos en
output/ckpt/DATASET_naive/ para el modelo ' ingenuo '.output/ckpt/DATASET_shallow/ para el modelo ' Shallow '. Tenga en cuenta que el punto de control del modelo ' poco profundo ' contiene modelos ' superficiales ' y ' aux ', y estos dos modelos compartirán todos los directorios, excepto los resultados en todo el proceso.Para un TTS de un solo hablante , ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Para un TTS de múltiples altavoces , ejecute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
El diccionario de los altavoces aprendidos se puede encontrar en preprocessed_data/DATASET/speakers.json , y las expresiones generadas se colocarán en output/result/ .
También es compatible con la inferencia por lotes, intente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todas las expresiones en preprocessed_data/DATASET/val.txt .
La tasa de tono/volumen/habla de las expresiones sintetizadas se puede controlar especificando las relaciones de tono/energía/duración deseadas. Por ejemplo, uno puede aumentar la tasa de habla en un 20 % y disminuir el volumen en un 20 % en
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Tenga en cuenta que la capacidad de control se origina en FastSpeech2 y no es un interés vital de Diffgan-TTS.
Los conjuntos de datos compatibles son
LJSPEECH: un conjunto de datos en inglés de un solo hablador consta de 13100 clips de audio cortos de una altavoz femenina que lee pasajes de 7 libros de no ficción, aproximadamente 24 horas en total.
VCTK: El corpus CSTR VCTK incluye datos del habla pronunciados por 110 hablantes de inglés ( TTS de múltiples altavoces ) con varios acentos. Cada orador lee alrededor de 400 oraciones, que fueron seleccionadas de un periódico, el pasaje del arco iris y un párrafo de obtención utilizado para el archivo de acento del habla.
Para un TTS de múltiples altavoces con un incrustador de altavoces externo, descargue el modelo de retraso previo al petróleo rescnn Softmax+de Filipperemy's DeepSpeaker para la incrustación del altavoz y lo ubique ./deepspeaker/pretrained_models/
Correr
python3 prepare_align.py --dataset DATASET
para algunos preparativos.
Para la alineación forzada, el alineador forzado de Montreal (MFA) se usa para obtener las alineaciones entre las expresiones y las secuencias de fonema. Aquí se proporcionan alineaciones preextracidas para los conjuntos de datos. Debe descomprimir los archivos en preprocessed_data/DATASET/TextGrid/ . Alternativamente, puede ejecutar el alineador usted mismo.
Después de eso, ejecute el script de preprocesamiento por
python3 preprocess.py --dataset DATASET
Puede entrenar tres tipos de modelo: ' ingenuo ', ' aux ' y ' superficial '.
Entrenamiento de la versión ingenua (' ingenuo '):
Entrena la versión ingenua con
python3 train.py --model naive --dataset DATASET
Entrenamiento Modelo acústico básico para la versión poco profunda (' Aux '):
Para entrenar la versión poco profunda, necesitamos un FastSpeech2 pre-entrenado. El siguiente comando le permitirá entrenar los módulos FastSpeech2, incluido el decodificador auxiliar (MEL).
python3 train.py --model aux --dataset DATASET
Entrenamiento de la versión superficial (' superficial '):
Para aprovechar FastSpeech2 previamente entrenado, incluido el decodificador auxiliar (MEL), debe pasar --restore_step con el paso final del entrenamiento auxiliar de FastSpeech2 como el siguiente comando.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Por ejemplo, si el último punto de control se guarda en 200000 pasos durante la capacitación auxiliar, debe configurar --restore_step con 200000 . Luego se cargará y congelará el modelo AUX y luego continuará el entrenamiento bajo el mecanismo de difusión poco profundo activo.
Usar
tensorboard --logdir output/log/DATASET
para servir tensorboard en su localhost. Se muestran las curvas de pérdida, los espectrogramas MEL sintetizados y los audios.
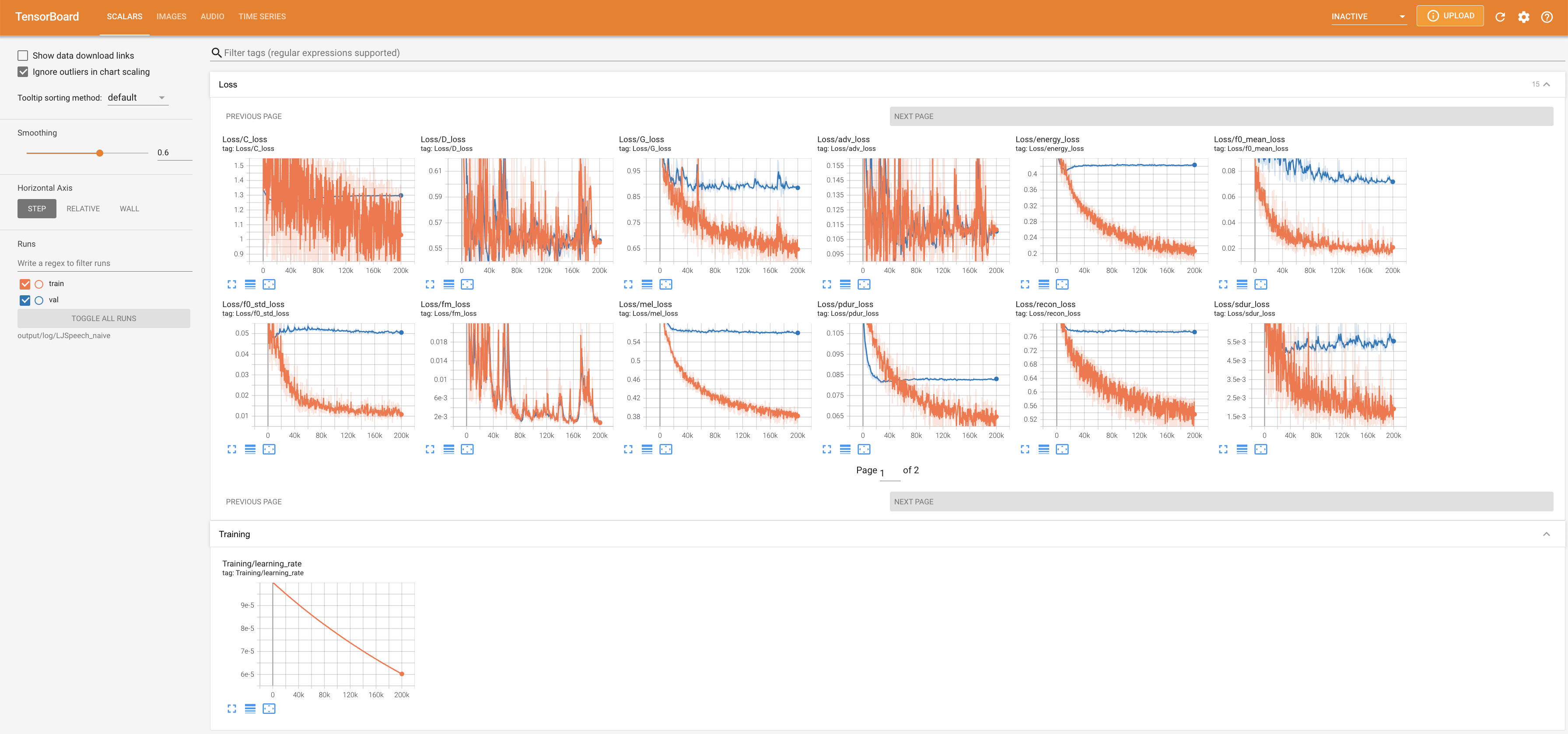
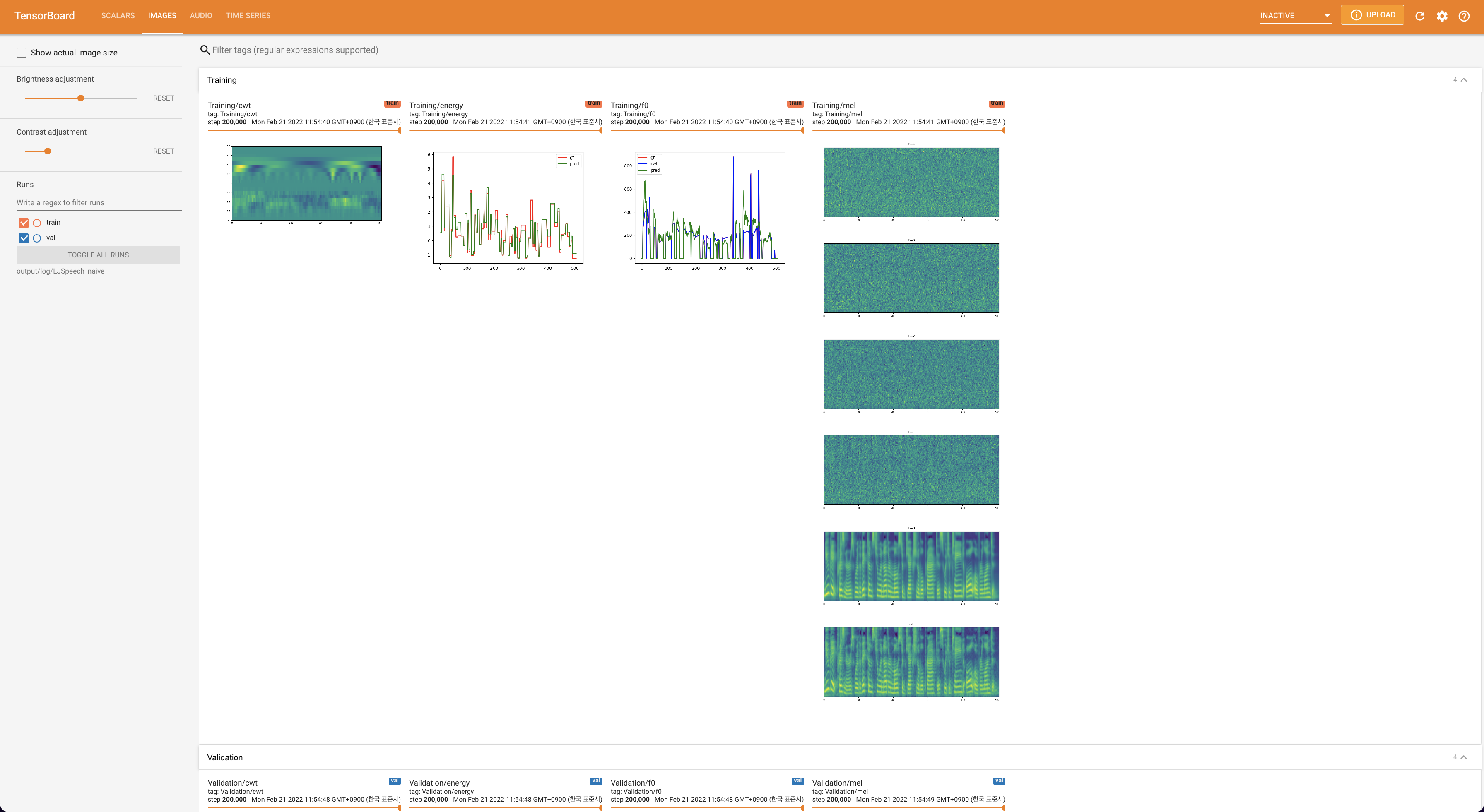
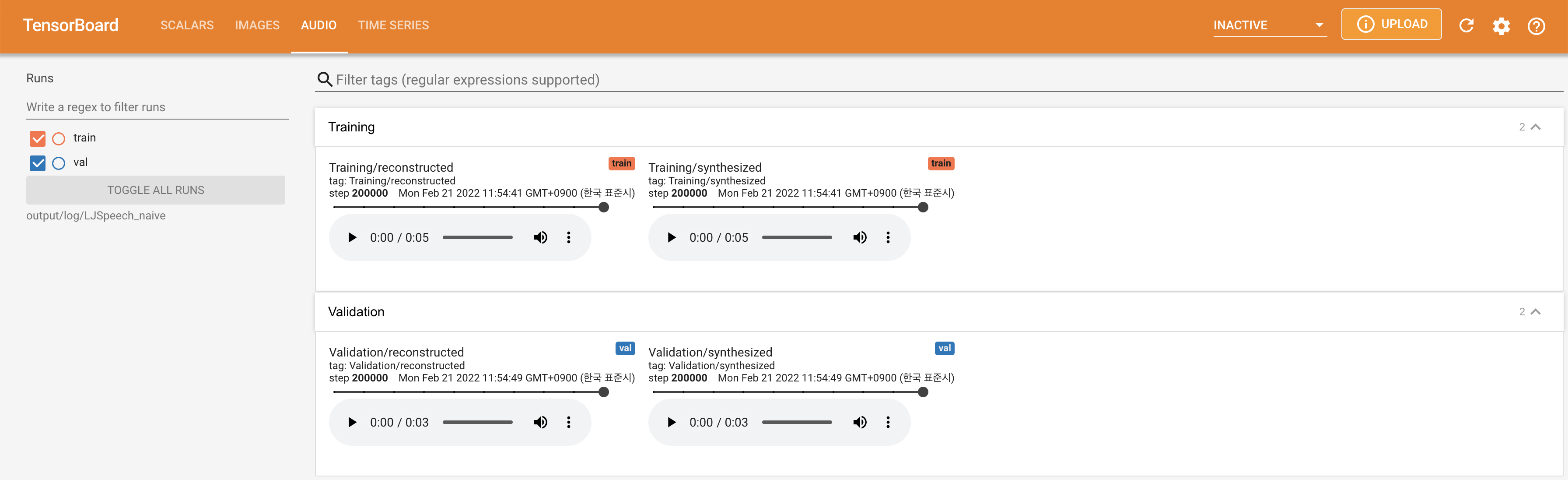
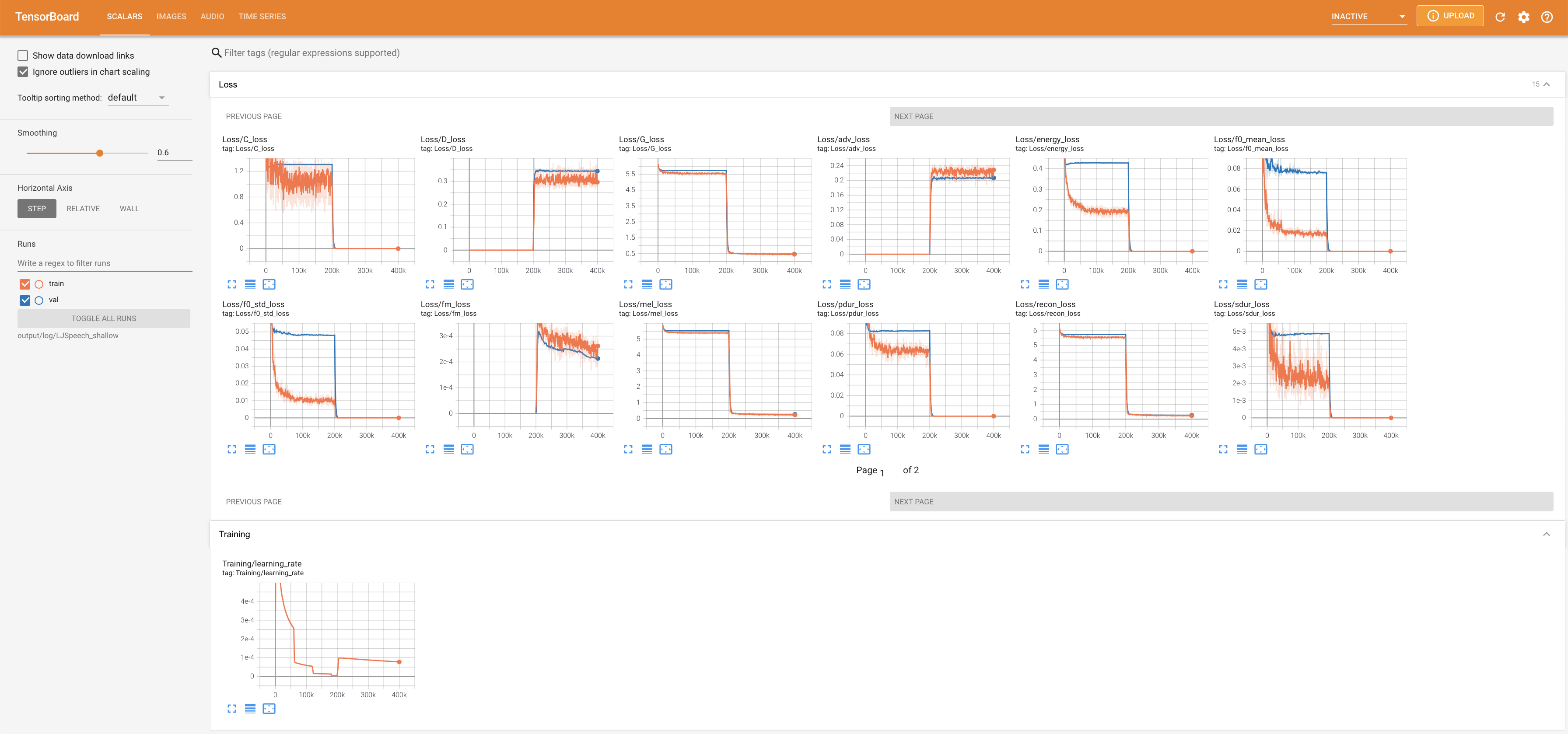
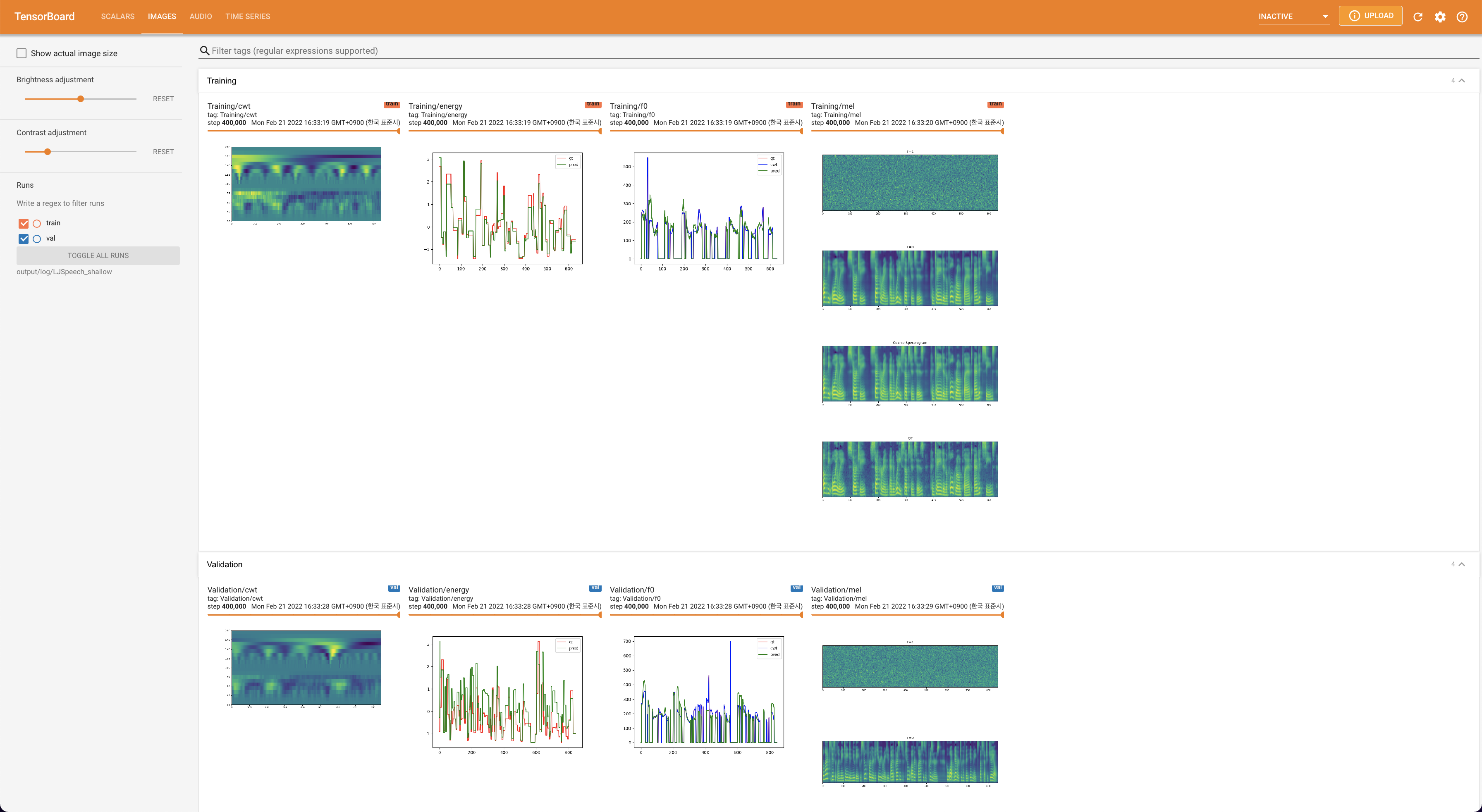
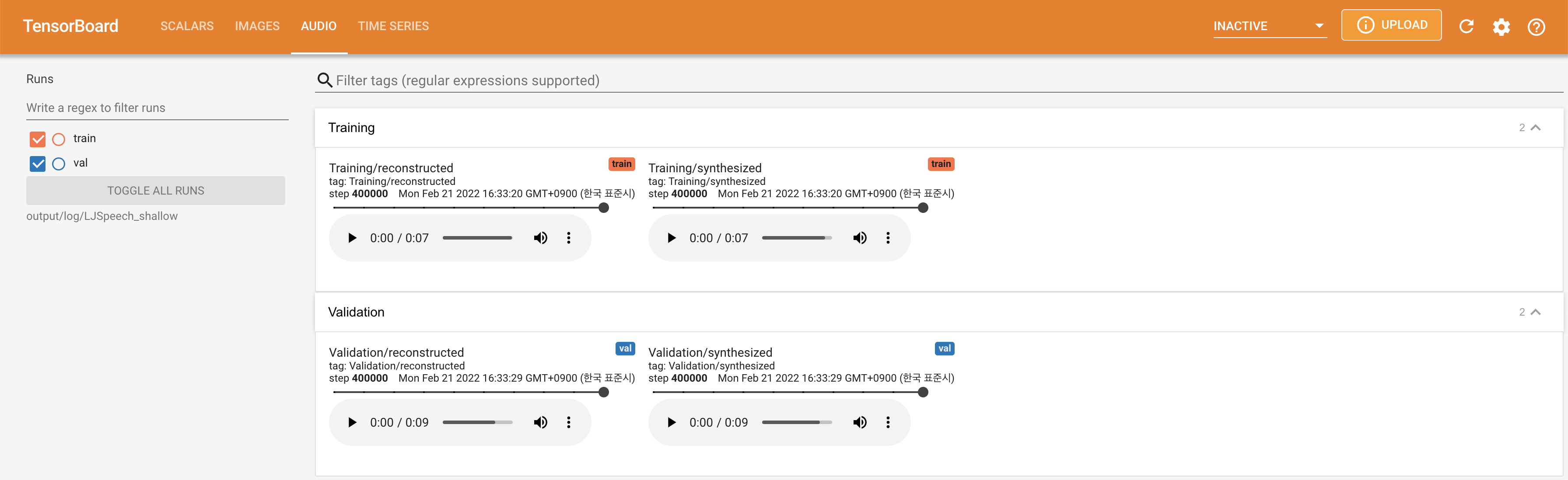
lambda_fm se fija a un valor Scala ya que el escalar a escala dinámica calculada como l_recon/l_fm hace que el modelo explote.'none' y 'DeepSpeaker' ).
Cite este repositorio por el "cita este repositorio" de la sección Acerca de (arriba a la derecha de la página principal).


