DiffGAN TTS
1.0.0
Pytorch-Implementierung von Diffgan-TTs: Hochgeschwindige und effiziente Text-zu-Sprache mit Denoising-Diffusions-Gans
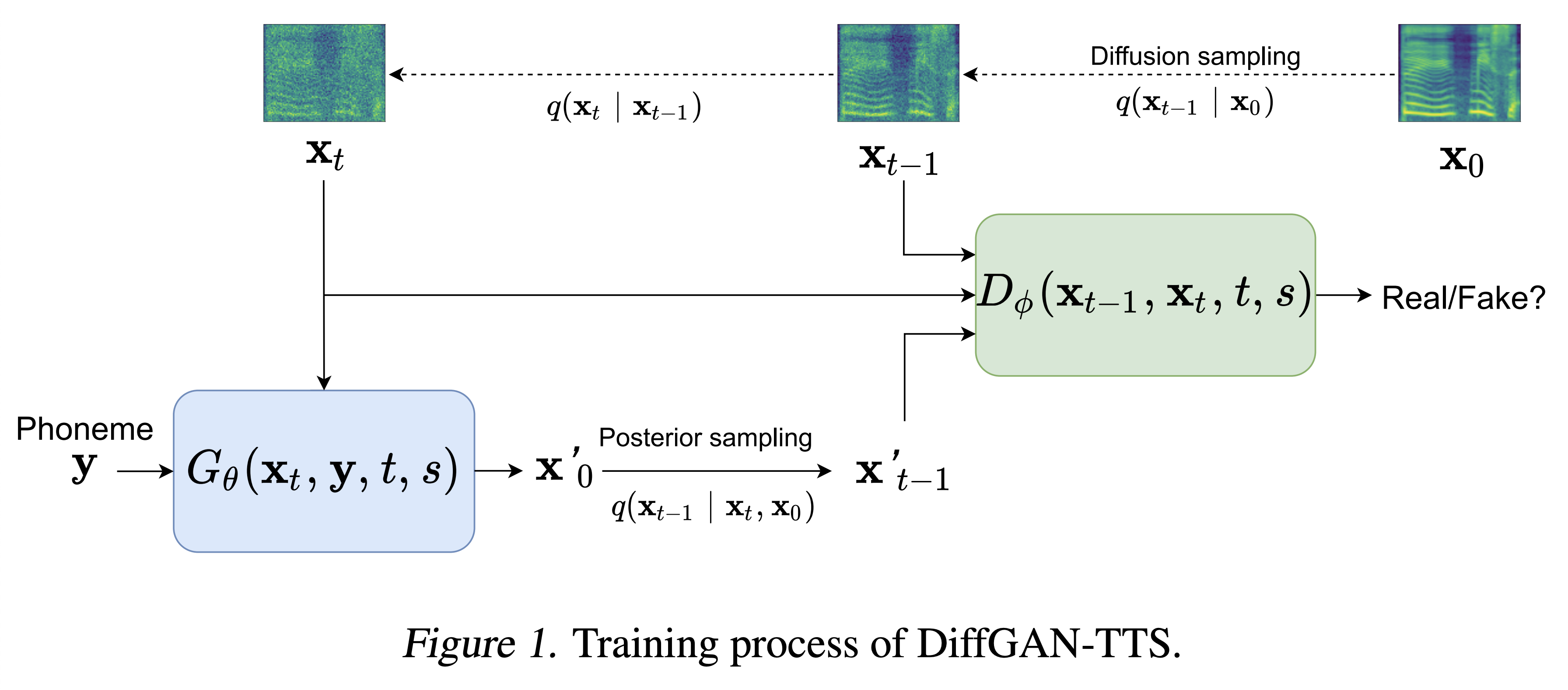
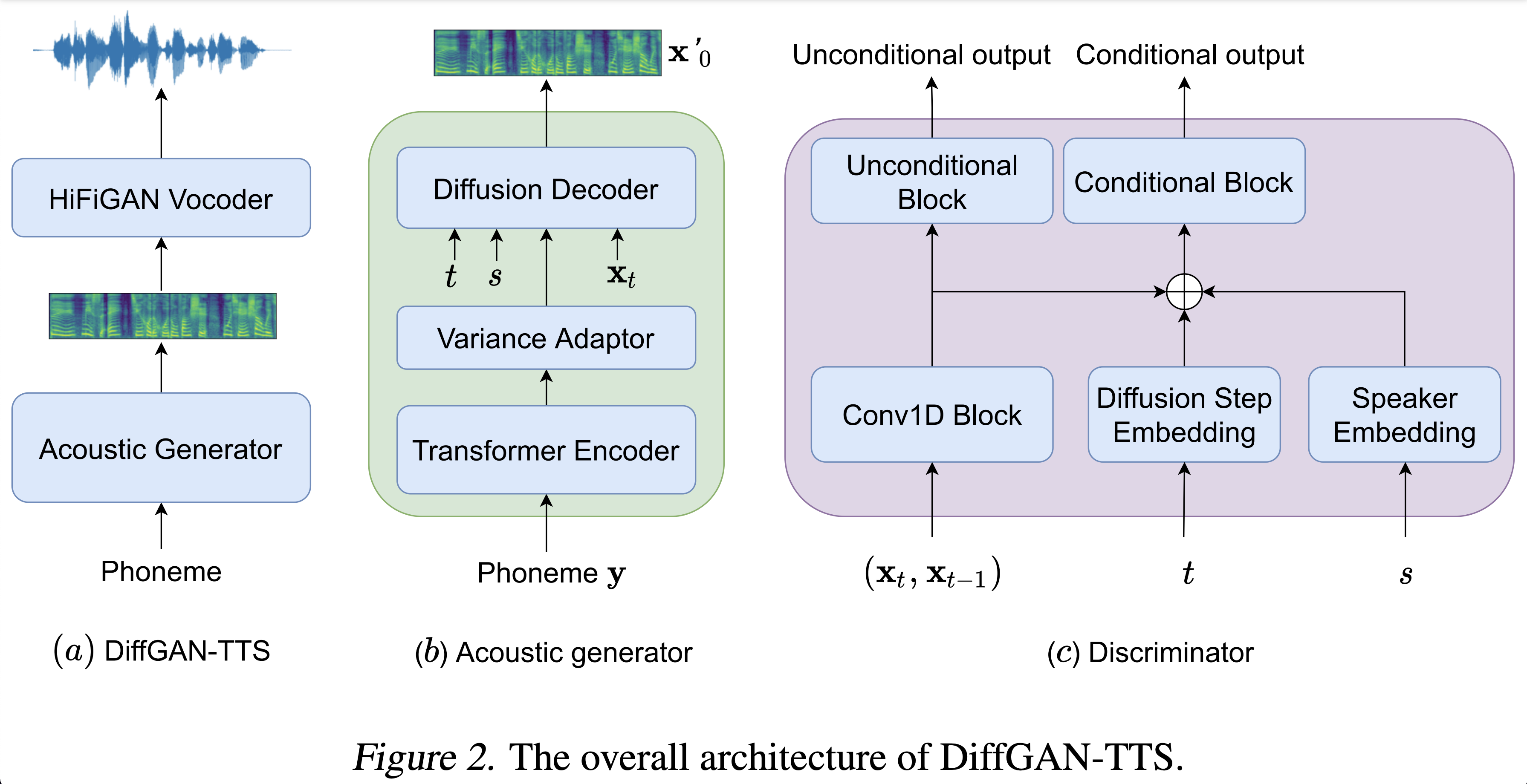
Audio -Samples sind bei /Demo erhältlich.
Datensatz bezieht sich auf die Namen von Datensätzen wie LJSpeech und VCTK in den folgenden Dokumenten.
Das Modell bezieht sich auf die Arten von Modell (wählen Sie aus " Naive ", " aux ", " flach ").
Sie können die Python -Abhängigkeiten mit installieren
pip3 install -r requirements.txt
Sie müssen die vorbereiteten Modelle herunterladen und sie einsetzen
output/ckpt/DATASET_naive/ für ' naive ' Modell.output/ckpt/DATASET_shallow/ für ' flaches ' Modell. Bitte beachten Sie, dass der Kontrollpunkt des " flachen " Modells sowohl " flache " als auch " Aux " -Modelle enthält, und diese beiden Modelle teilen alle Verzeichnisse mit Ausnahme der Ergebnisse im gesamten Prozess.Für einen TTS mit einem Lautsprecher laufen Sie
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Für einen Multi-Sprecher-TTS laufen
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Das Wörterbuch der gelehrten Sprecher finden Sie unter preprocessed_data/DATASET/speakers.json , und die generierten Äußerungen werden in output/result/ .
Batch -Inferenz wird ebenfalls unterstützt, versuchen Sie es
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
So synthetisieren Sie alle Äußerungen in preprocessed_data/DATASET/val.txt .
Die Tonhöhe/Volumen-/Sprechrate der synthetisierten Äußerungen kann durch Angabe der gewünschten Pitch/Energy/Dauer -Verhältnisse gesteuert werden. Zum Beispiel kann man die Sprechrate um 20 % erhöhen und das Volumen um 20 % verringern
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Bitte beachten Sie, dass die Kontrollierbarkeit von Fastspeech2 stammt und kein wesentliches Interesse an Diffgan-TTs.
Die unterstützten Datensätze sind
LJSpeech: Ein englischer Datensatz mit einem Lautsprecher besteht aus 13100 kurzen Audioclips einer weiblichen Lautsprecherin, die Passagen aus 7 Sachbüchern mit insgesamt ca. 24 Stunden liest.
VCTK: Das CSTR-VCTK-Korpus enthält Sprachdaten, die von 110 englischen Sprechern ( Multi-Sprecher-TTs ) mit verschiedenen Akzenten ausgesprochen werden. Jeder Sprecher liest etwa 400 Sätze vor, die aus einer Zeitung, der Regenbogenpassage und einem für das Archiv der Sprachakzent verwendeten Erhebungsabsatz ausgewählt wurden.
Download für ein Multi-Sprecher-TTS mit einem externen Lautsprecher-Einbettder Rescnn Softmax+Triplet Pretrainierte Modell von Philipperemy's Deepspeaker für den Lautsprecher-Einbettung und lokalisiert es in ./deepspeaker/pretrained_models/ .
Laufen
python3 prepare_align.py --dataset DATASET
Für einige Vorbereitungen.
Für die erzwungene Ausrichtung wird Montreal erzwungene Aligner (MFA) verwendet, um die Ausrichtungen zwischen den Äußerungen und den Phonemsequenzen zu erhalten. Vorextrahierte Ausrichtungen für die Datensätze werden hier bereitgestellt. Sie müssen die Dateien in preprocessed_data/DATASET/TextGrid/ entpacken. Alternativ können Sie den Aligner selbst ausführen.
Führen Sie danach das Vorverarbeitungskript durch
python3 preprocess.py --dataset DATASET
Sie können drei Arten von Modellen trainieren: " naiv ", " aux " und " flach ".
Training naive Version (' naive '):
Trainieren Sie die naive Version mit
python3 train.py --model naive --dataset DATASET
Training grundlegendes akustisches Modell für flache Version (' Aux '):
Um die flache Version zu trainieren, benötigen wir einen vorgebliebenen Fastspeech22. Mit dem folgenden Befehl können Sie die Fastspeech2 -Module trainieren, einschließlich Auxiliary (Mel) Decoder.
python3 train.py --model aux --dataset DATASET
Training flache Version (' flach '):
Um vorgeborenes Fastspeech2, einschließlich Auxiliary (Mel --restore_step Decoder, zu nutzen.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Wenn der letzte Kontrollpunkt beispielsweise während des Hilfstrainings bei 200000 Schritten gespeichert wird, müssen Sie mit 200000 --restore_step festgelegt. Dann wird das Aux -Modell geladen und gefriert und dann das Training unter dem aktiven flachen Diffusionsmechanismus fortgesetzt.
Verwenden
tensorboard --logdir output/log/DATASET
Tensorboard auf Ihrem örtlichen Haus servieren. Die Verlustkurven, synthetisierte Melspektrogramme und Audios werden gezeigt.
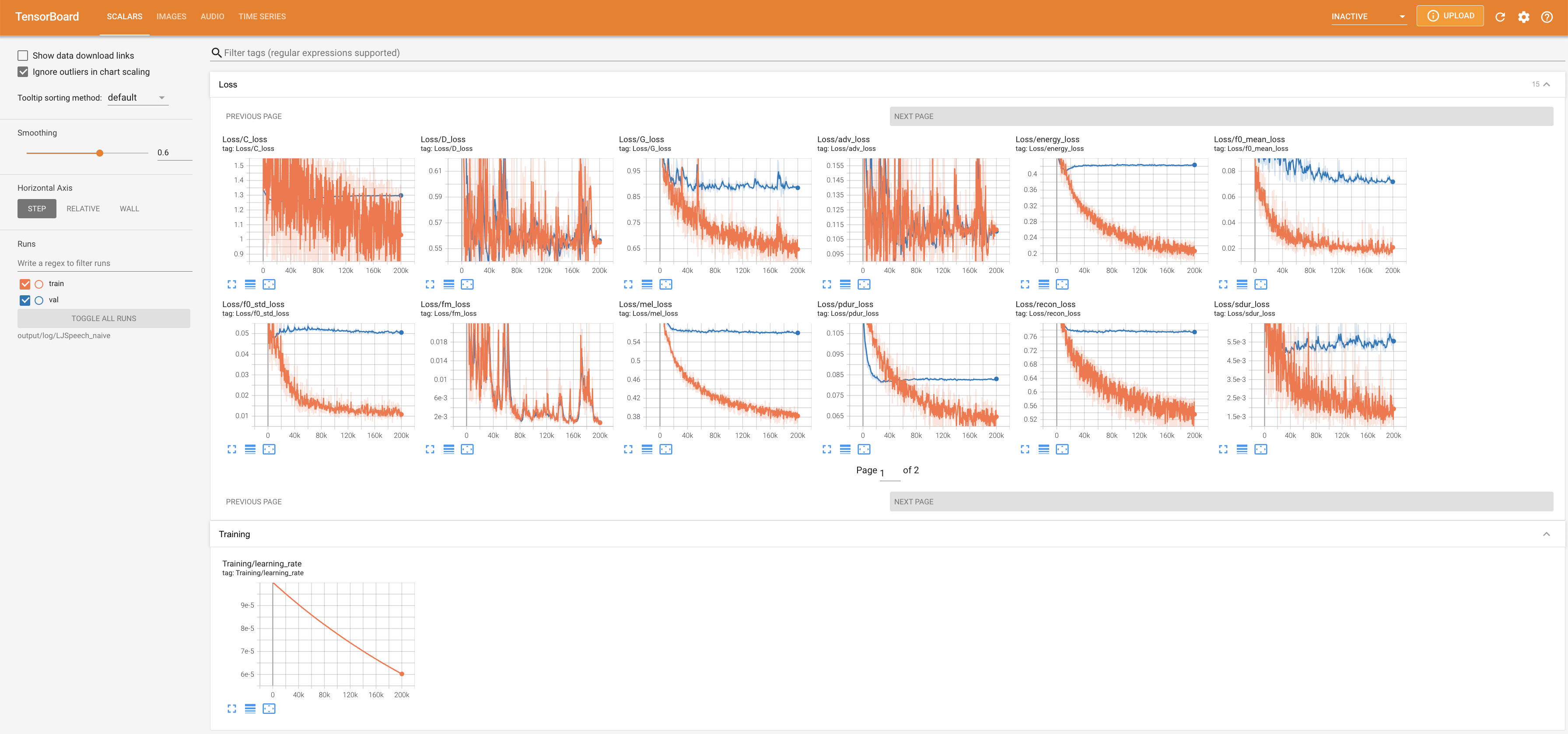
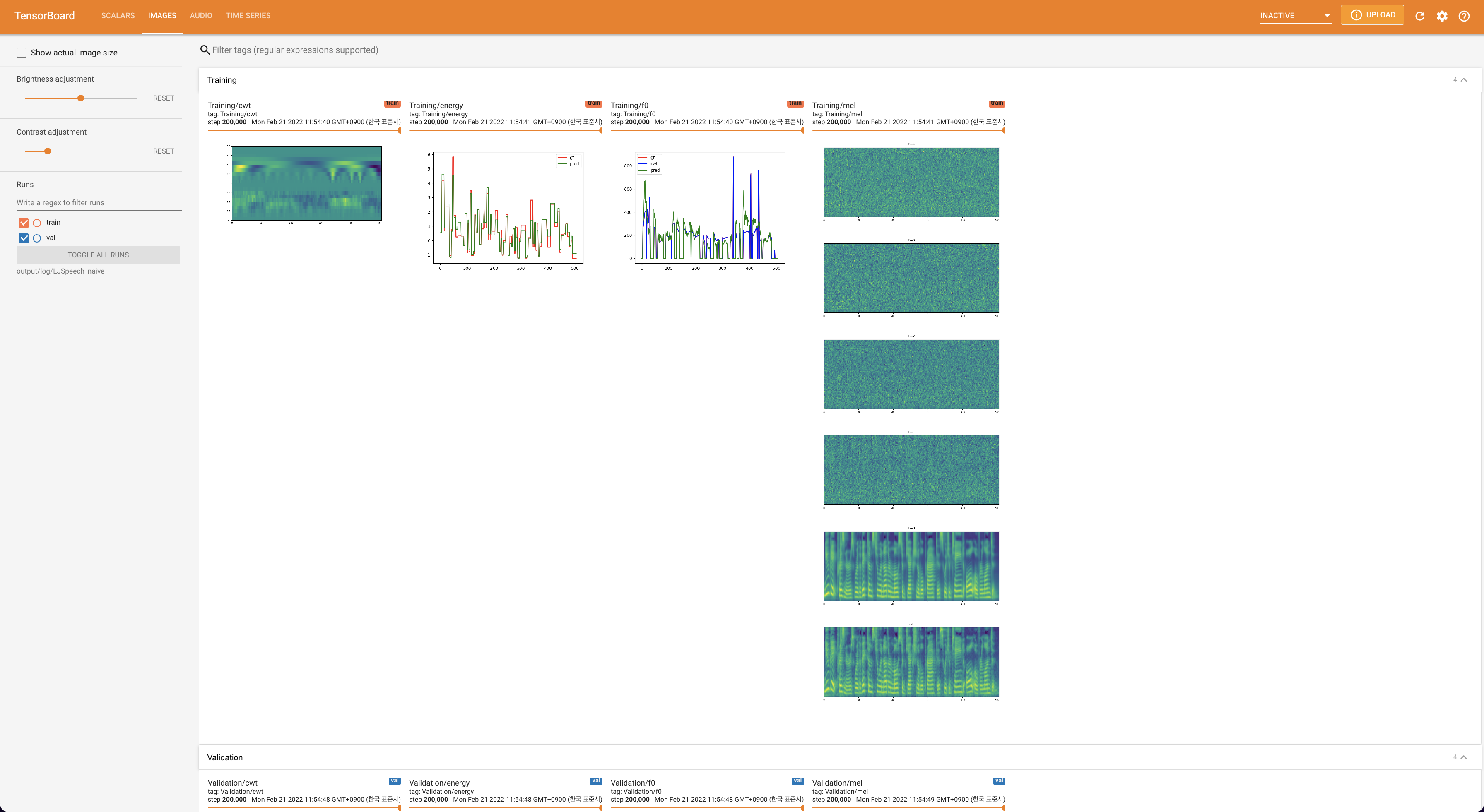
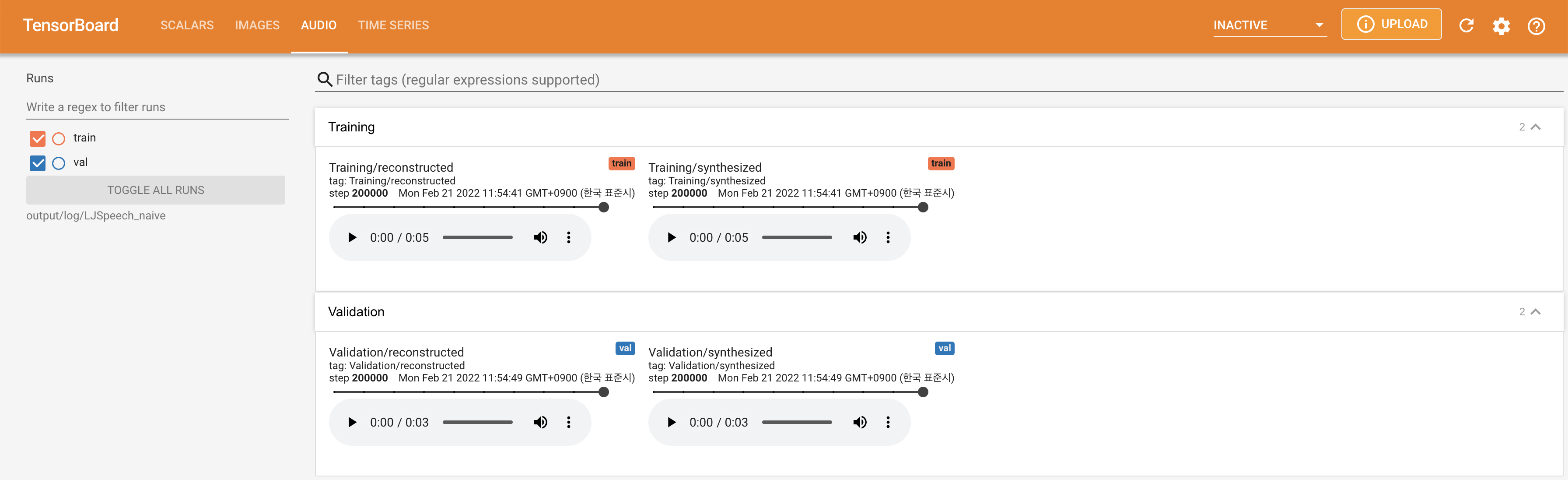
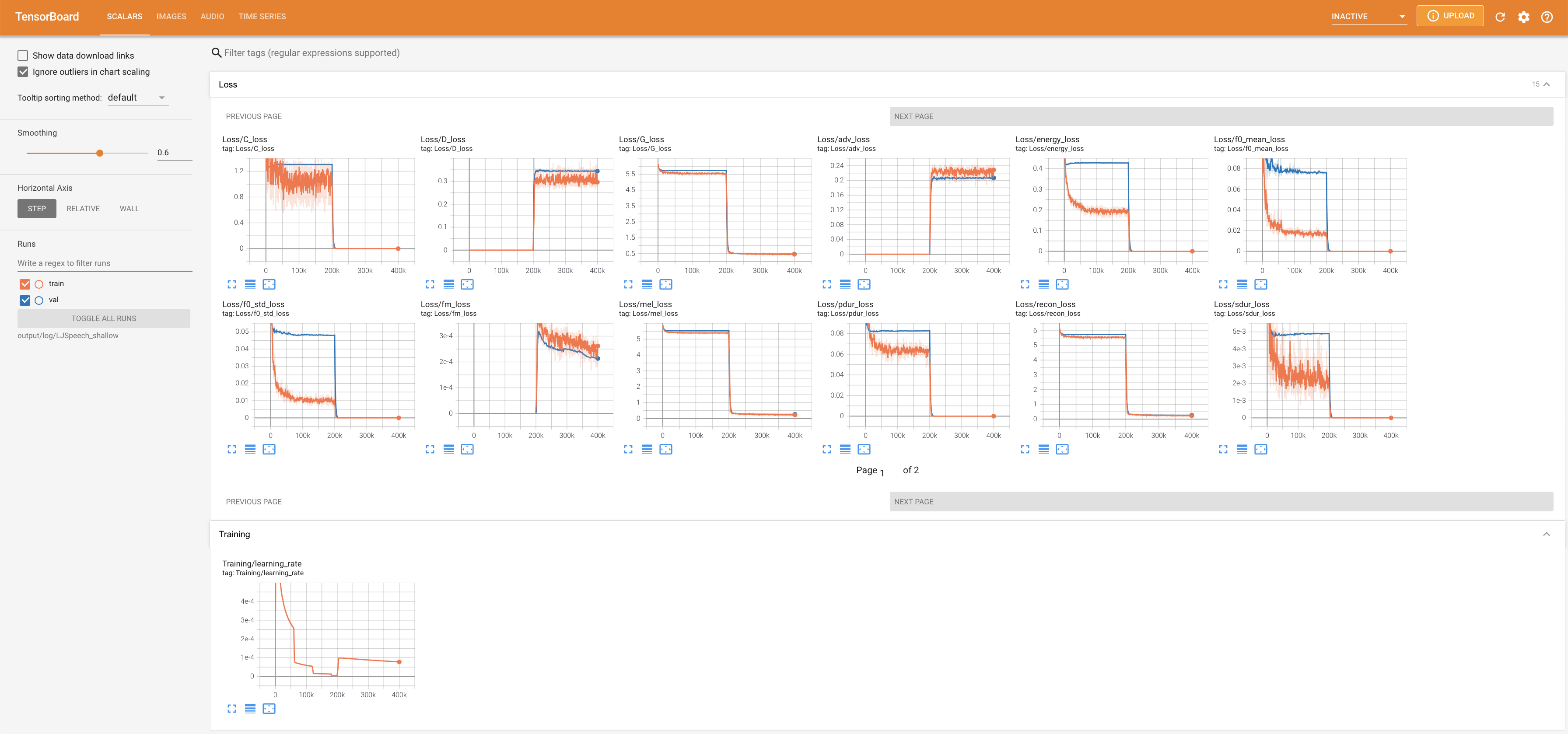
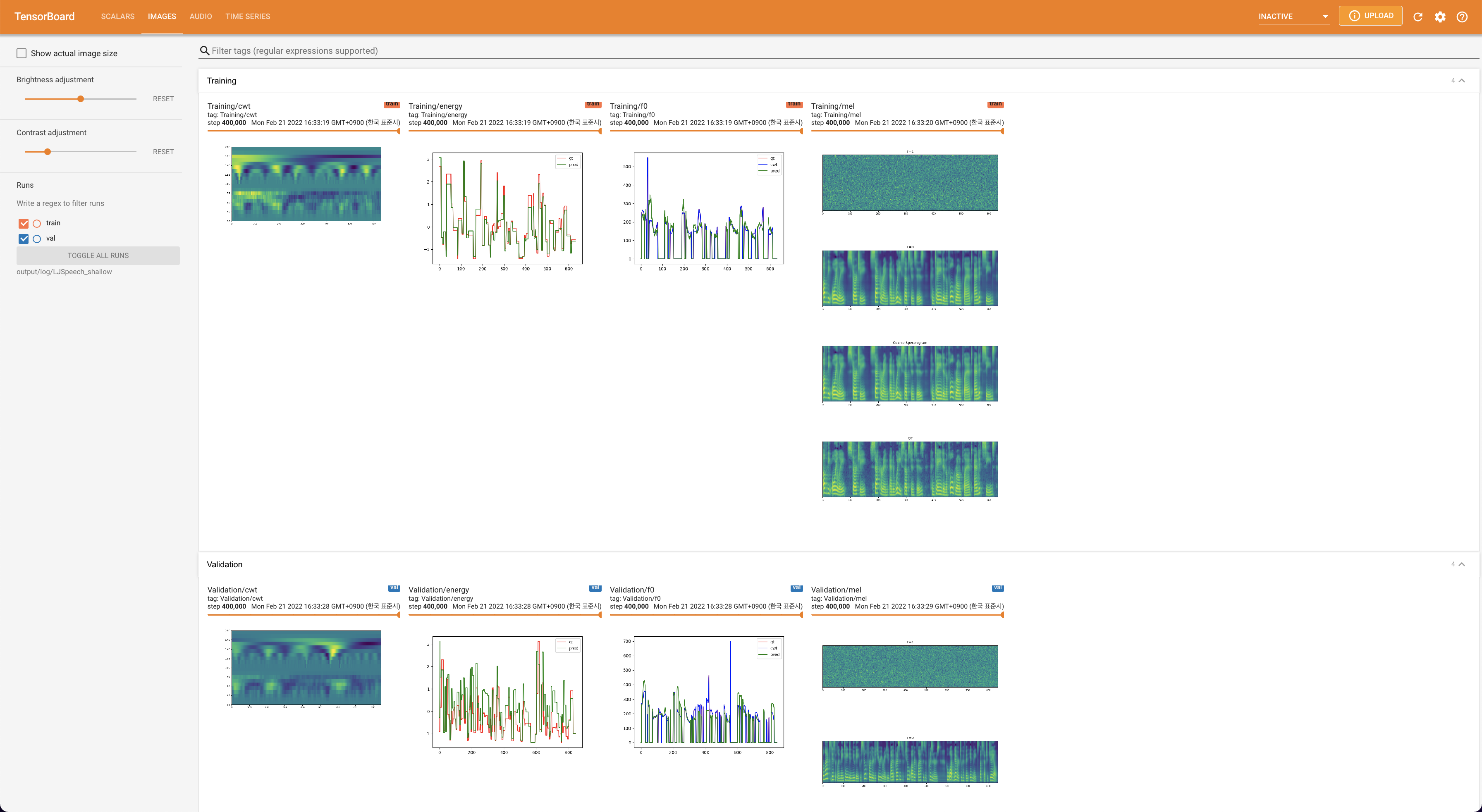
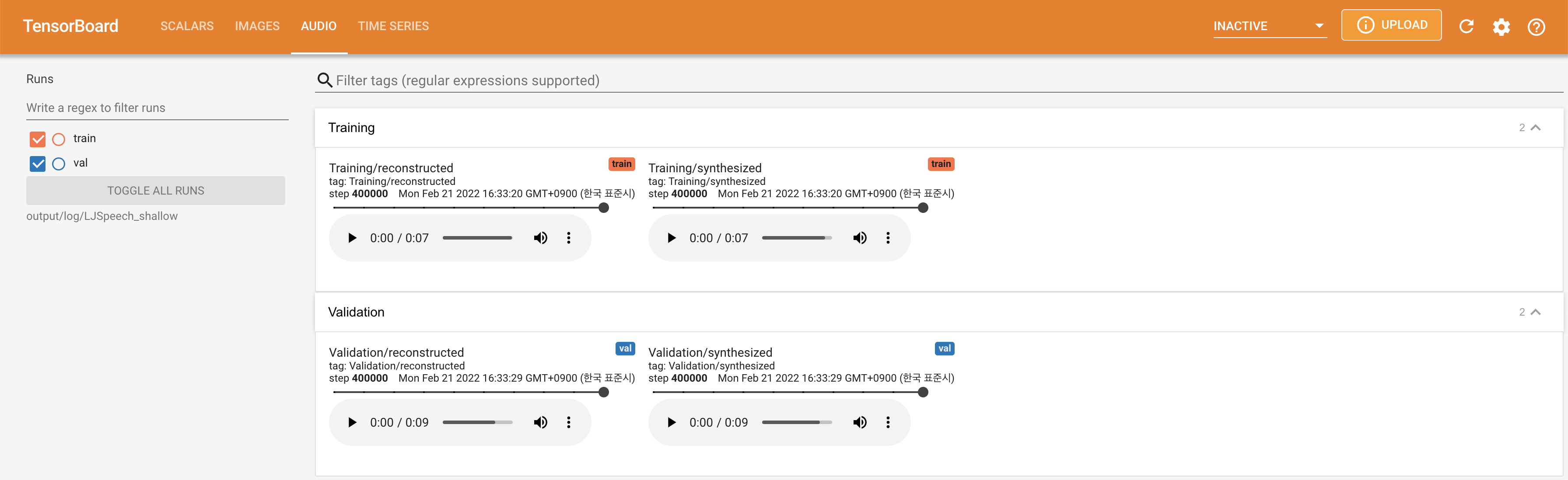
lambda_fm ist auf einen Skala -Wert befestigt, da der dynamisch skalierte Skalar, der als L_RECON/L_FM berechnet wurde, das Modell explodieren lässt.'none' und 'DeepSpeaker' ) einstellen.
Bitte zitieren Sie dieses Repository durch das "Zitieren Sie dieses Repository" des Abschnitts (oben rechts auf der Hauptseite).


