DiffGAN TTS
1.0.0
Implementação de Pytorch de DiffGan-TTS: alta fidelidade e eficiente Texto-fala com Gans de difusão de denoishing
Amostras de áudio estão disponíveis em /demonstração.
O conjunto de dados refere -se aos nomes de conjuntos de dados como LJSpeech e VCTK nos seguintes documentos.
O modelo refere -se aos tipos de modelo (escolha de ' ingênuo ', ' aux ', ' raso ').
Você pode instalar as dependências do Python com
pip3 install -r requirements.txt
Você tem que baixar os modelos pré -teremam e colocá -los em
output/ckpt/DATASET_naive/ para o modelo " ingênuo ".output/ckpt/DATASET_shallow/ para modelo ' raso '. Observe que o ponto de verificação do modelo ' raso ' contém modelos ' rasos ' e ' aux ', e esses dois modelos compartilharão todos os diretórios, exceto os resultados durante todo o processo.Para um tts de alto-falante , execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Para um TTS de vários falantes , execute
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
O dicionário de alto -falantes instruídos pode ser encontrado em preprocessed_data/DATASET/speakers.json , e os enunciados gerados serão colocados em output/result/ .
A inferência em lote também é suportada, tente
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Para sintetizar todos os enunciados em preprocessed_data/DATASET/val.txt .
A taxa de afinação/volume/fala dos enunciados sintetizados pode ser controlada especificando as taxas desejadas de afinação/energia/duração. Por exemplo, pode -se aumentar a taxa de fala em 20 % e diminuir o volume em 20 % em
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Observe que a controlabilidade é originada no FastSpeech2 e não é um interesse vital do DiffGan-TTS.
Os conjuntos de dados suportados são
LJSPEECH: Um conjunto de dados em inglês de um único alto-falante consiste em 13100 clipes de áudio curtos de uma falante lendo passagens de 7 livros de não ficção, aproximadamente 24 horas no total.
VCTK: O CSTR VCTK Corpus inclui dados de fala proferidos por 110 falantes de inglês ( TTS de vários falantes ) com vários sotaques. Cada orador lê cerca de 400 frases, que foram selecionadas em um jornal, a passagem do arco -íris e um parágrafo de elicitação usado para o arquivo de sotaque da fala.
Para um TTS multi-falante com o orador externo incorporador, faça o download do Modelo de Pré-Priendido de Rescnn Softmax+Tripleto do Philipperemy Deepaker para o alto-falante incorporando e localize-o em ./deepspeaker/pretrained_models/ .
Correr
python3 prepare_align.py --dataset DATASET
para alguns preparativos.
Para o alinhamento forçado, o alinhador forçado de Montreal (MFA) é usado para obter os alinhamentos entre os enunciados e as seqüências de fonemas. Alinhamentos pré-extraídos para os conjuntos de dados são fornecidos aqui. Você precisa descompactar os arquivos em preprocessed_data/DATASET/TextGrid/ . Como alternativa, você pode executar o alinhador sozinho.
Depois disso, execute o script de pré -processamento por
python3 preprocess.py --dataset DATASET
Você pode treinar três tipos de modelo: ' ingênuo ', ' aux ' e ' raso '.
Treinando versão ingênua (' ingênua '):
Treine a versão ingênua com
python3 train.py --model naive --dataset DATASET
Treinando modelo acústico básico para versão rasa (' aux '):
Para treinar a versão rasa, precisamos de um FastSpeech2 pré-treinado. O comando abaixo permitirá que você treine os módulos FastSpeech2, incluindo o decodificador auxiliar (MEL).
python3 train.py --model aux --dataset DATASET
Treinando versão rasa (' rasa '):
Para aproveitar o FastSpeech2 pré-treinado, incluindo o decodificador auxiliar (MEL), você deve passar --restore_step com a etapa final do treinamento auxiliar do FastSpeech2 como o comando a seguir.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Por exemplo, se o último ponto de verificação for salvo em 200000 etapas durante o treinamento auxiliar, você deverá definir --restore_step com 200000 . Em seguida, ele carregará e congelará o modelo AUX e continuará o treinamento sob o mecanismo de difusão rasa ativa.
Usar
tensorboard --logdir output/log/DATASET
Para servir o Tensorboard em sua localhost. As curvas de perda, os espectrogramas MEL sintetizados e os áudios são mostrados.
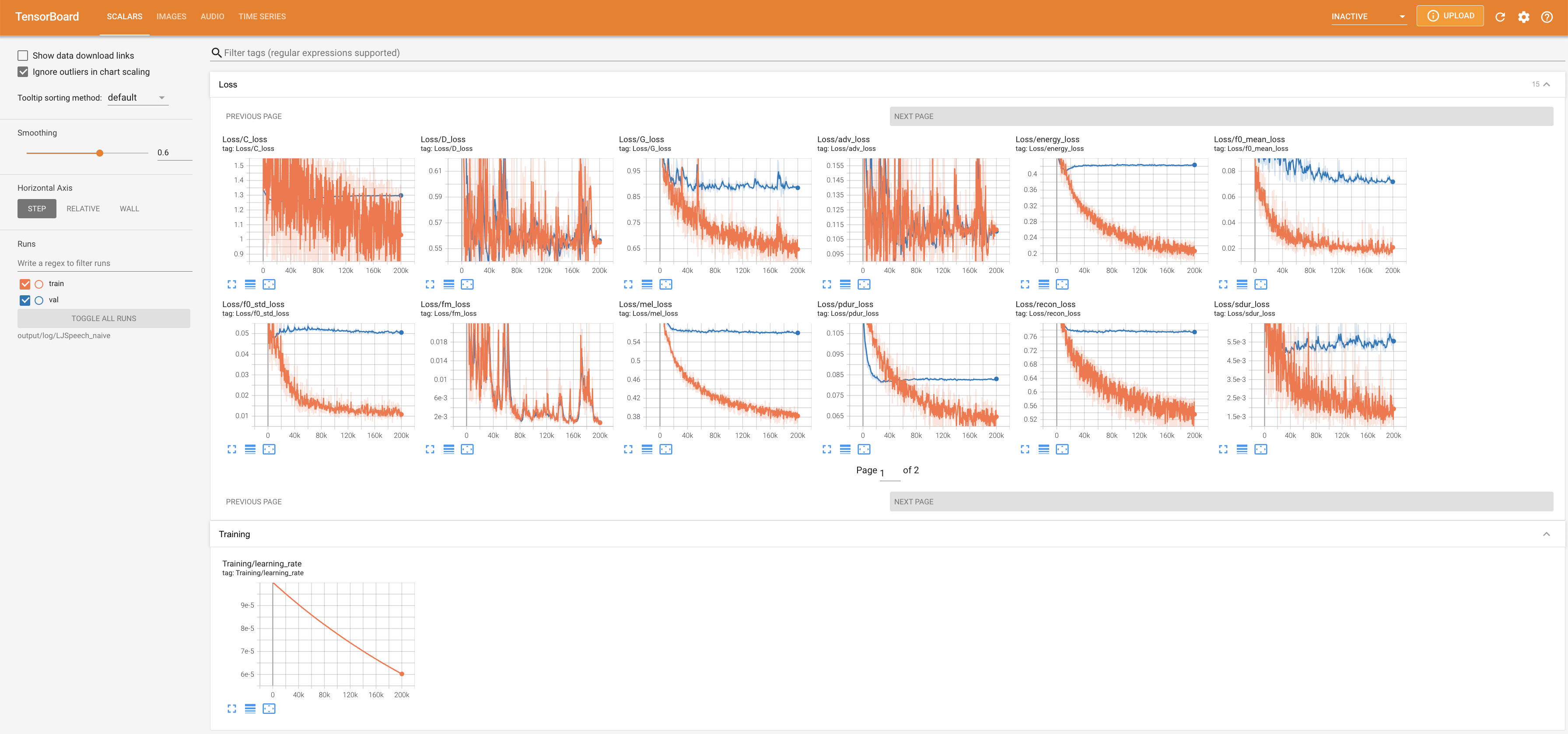
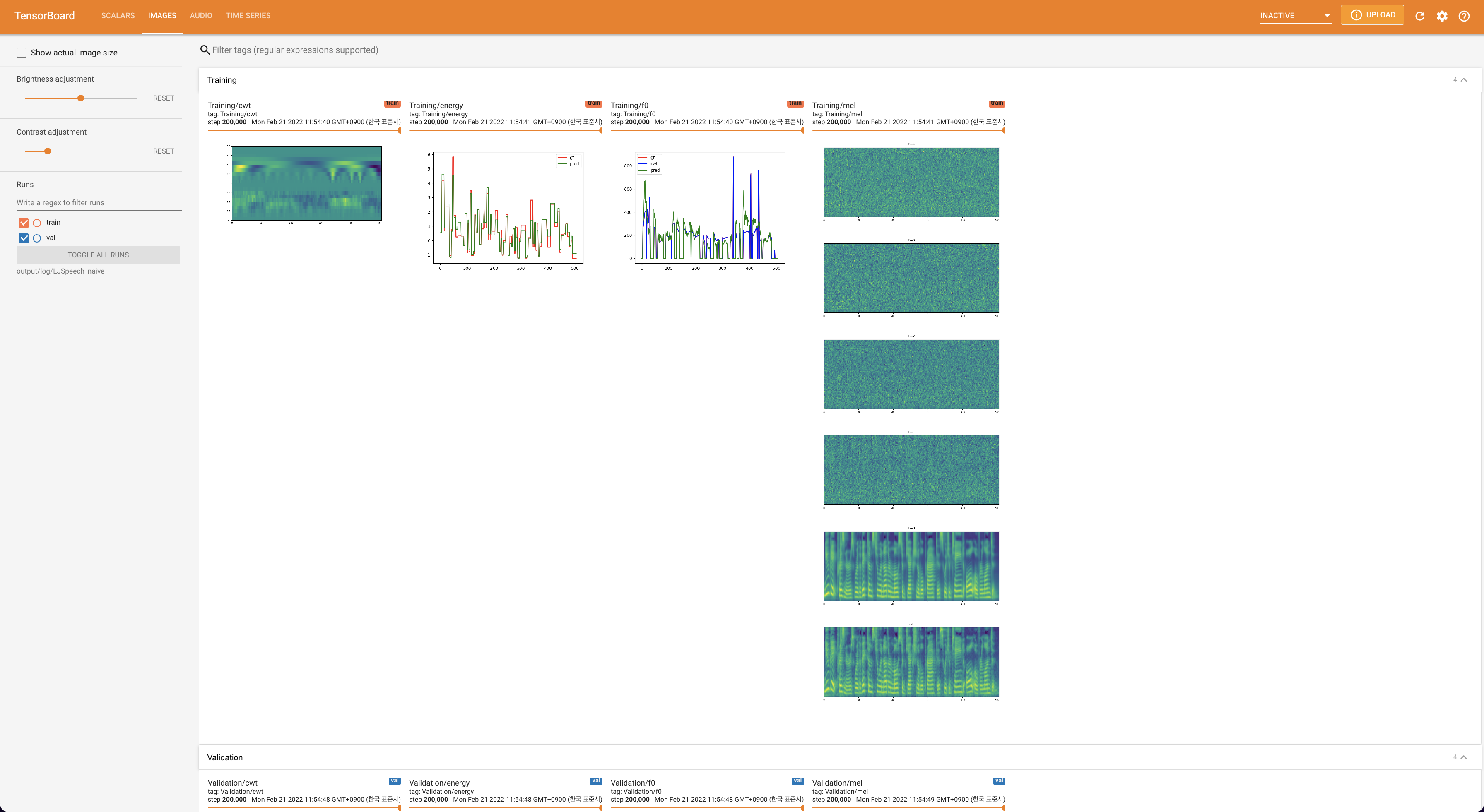
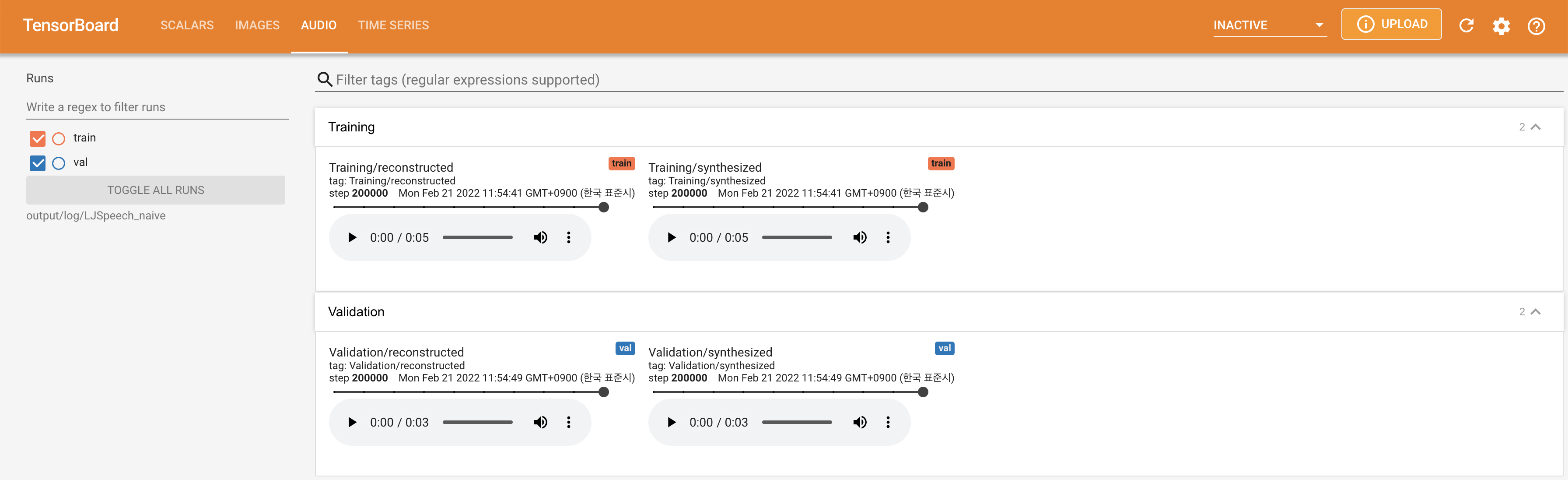
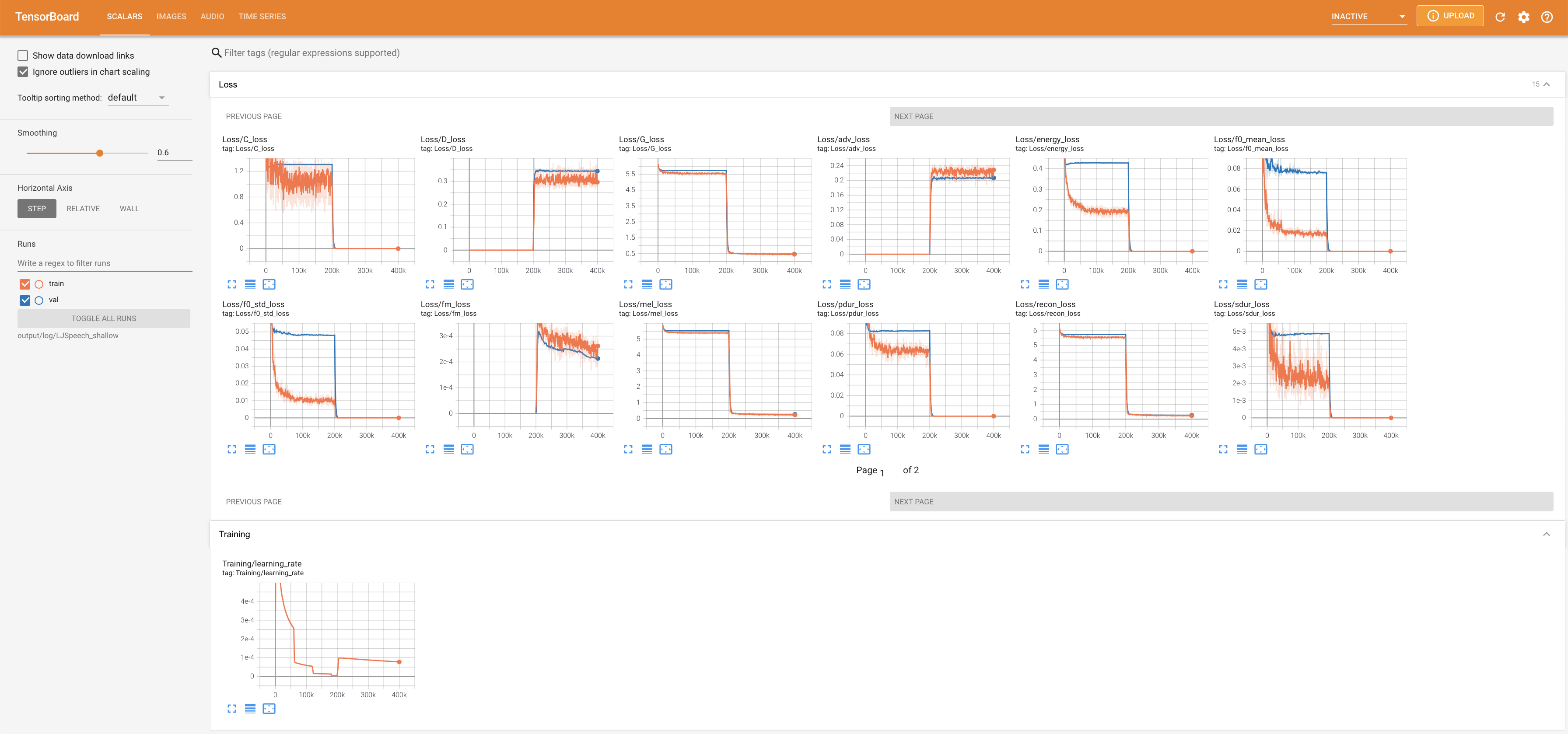
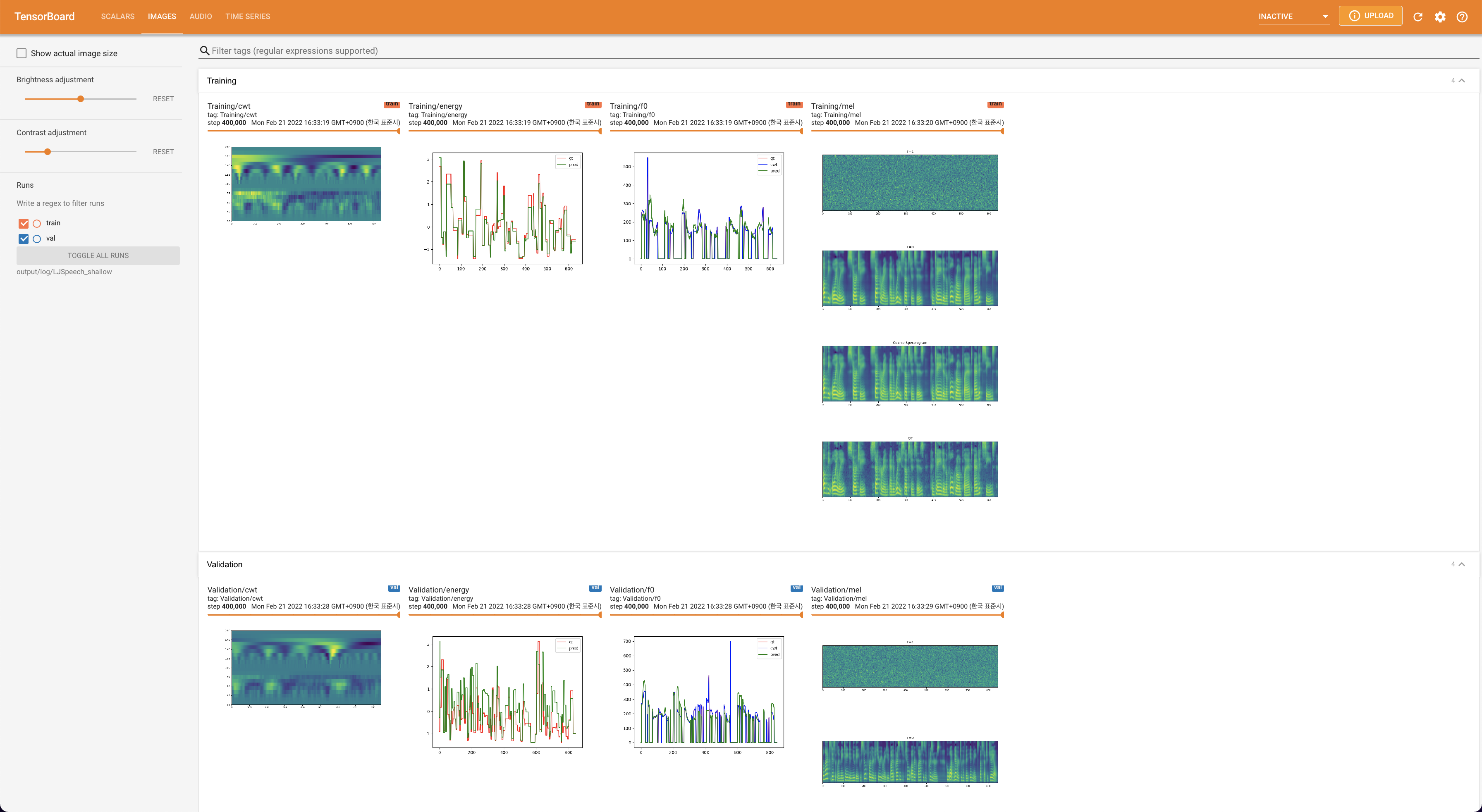
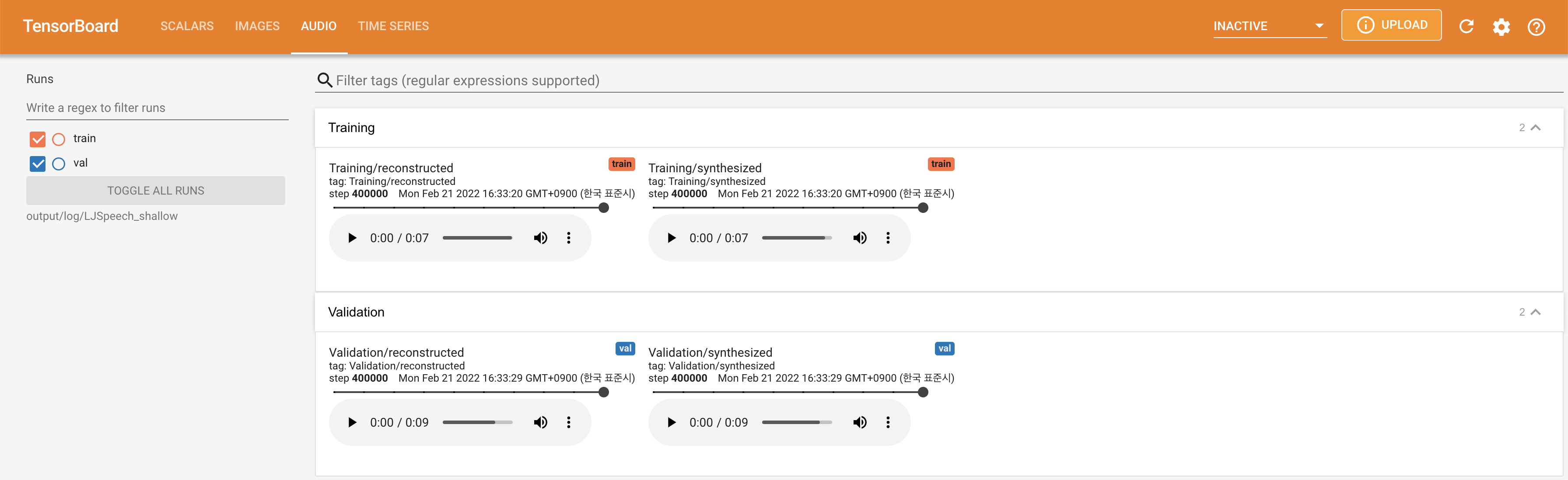
lambda_fm é fixado em um valor de Scala, pois o escalar dinamicamente escalado calculado como l_recon/l_fm torna o modelo explodido.'none' e 'DeepSpeaker' ).
Cite este repositório pelo "citar este repositório" da seção Sobre (canto superior direito da página principal).


