DiffGAN TTS
1.0.0
Implementasi Pytorch dari Diffgan-TTS: Fidelity tinggi dan teks-ke-speech dengan gans difusi denoising
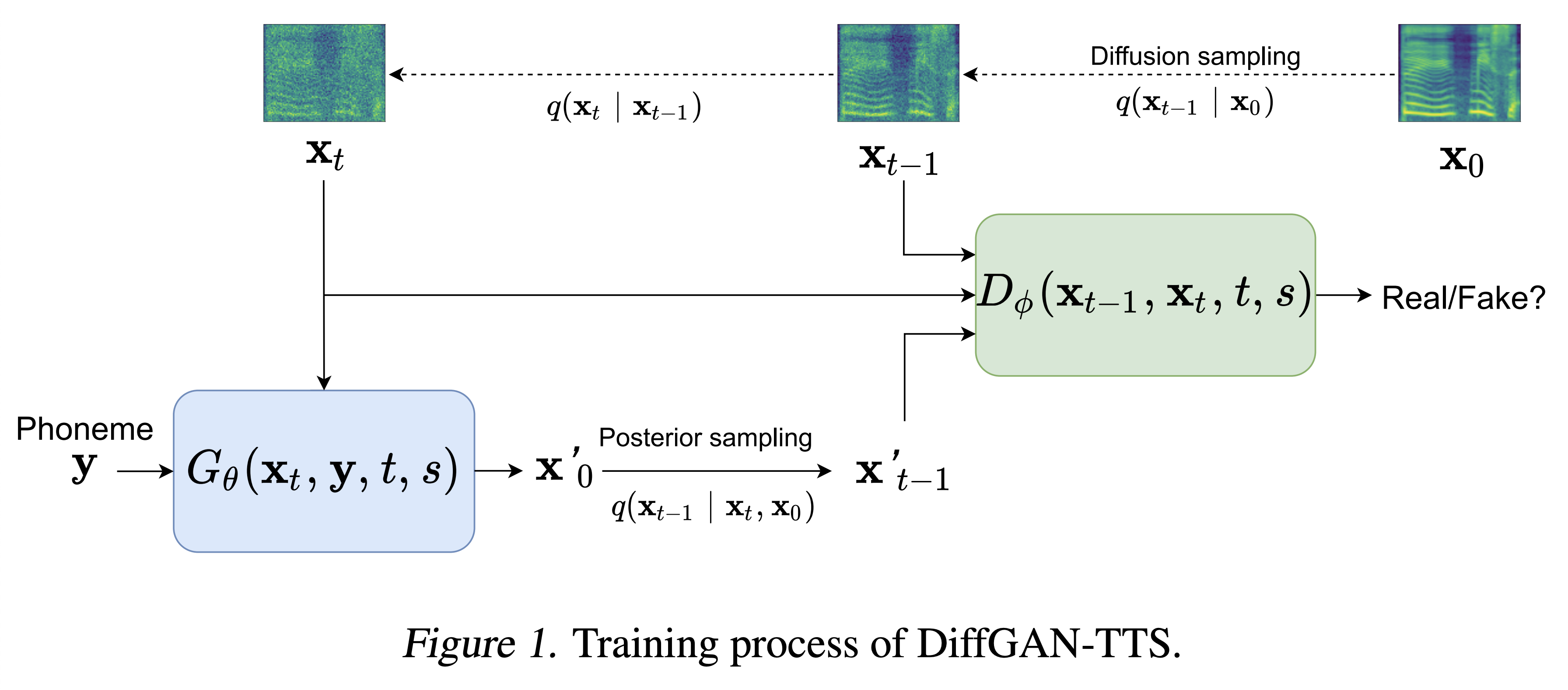
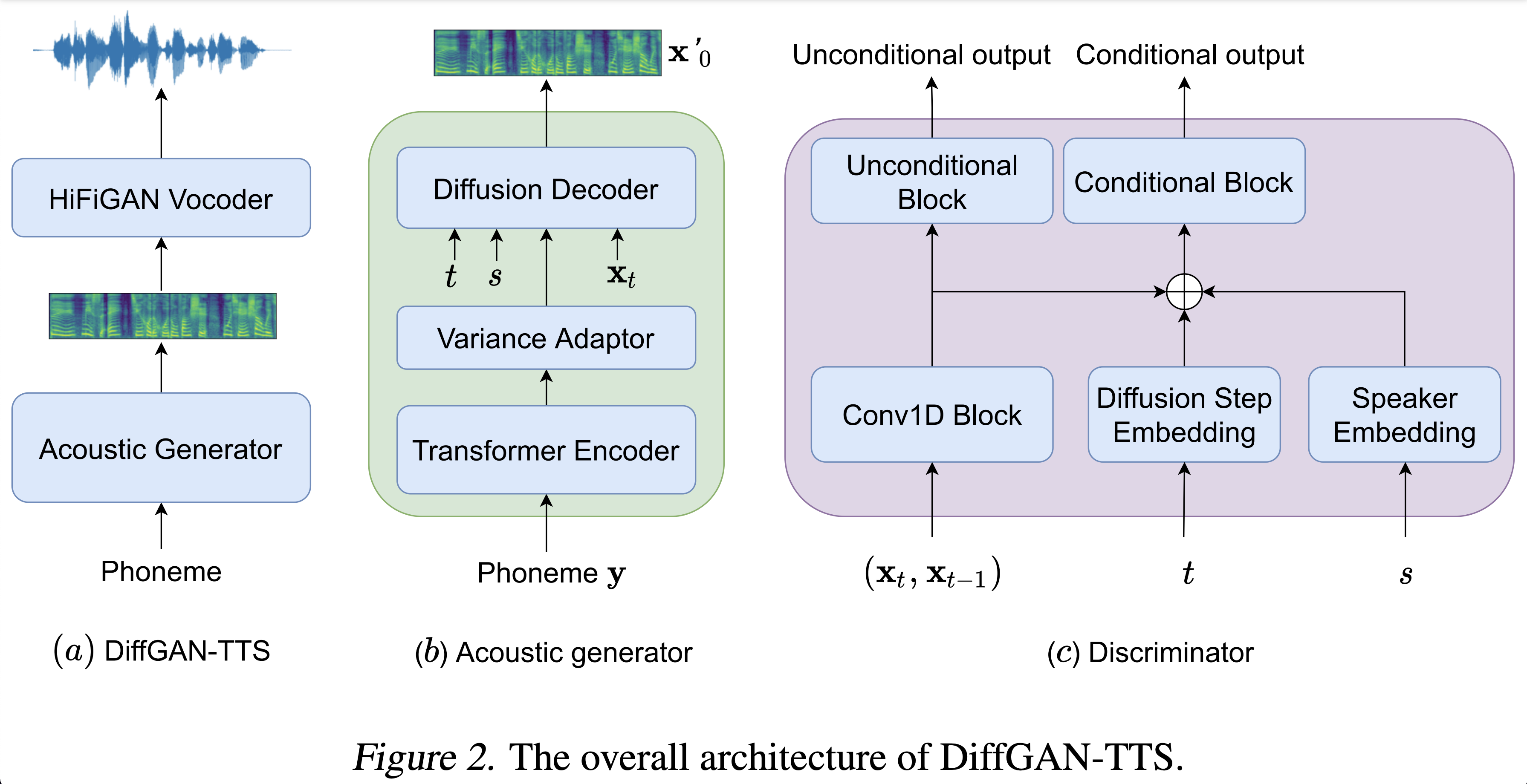
Sampel audio tersedia di /demo.
Dataset mengacu pada nama dataset seperti LJSpeech dan VCTK dalam dokumen berikut.
Model mengacu pada jenis model (pilih dari ' naif ', ' aux ', ' dangkal ').
Anda dapat menginstal dependensi Python dengan
pip3 install -r requirements.txt
Anda harus mengunduh model pretrained dan memasukkannya
output/ckpt/DATASET_naive/ untuk model ' naif '.output/ckpt/DATASET_shallow/ untuk model ' dangkal '. Harap dicatat bahwa pos pemeriksaan model ' dangkal ' berisi model ' dangkal ' dan ' aux ', dan kedua model ini akan berbagi semua direktori kecuali hasil di seluruh proses.Untuk TTS penutur tunggal , jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET
Untuk TTS multi-speaker , jalankan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --speaker_id SPEAKER_ID --restore_step RESTORE_STEP --mode single --dataset DATASET
Kamus speaker yang dipelajari dapat ditemukan di preprocessed_data/DATASET/speakers.json , dan ucapan yang dihasilkan akan dimasukkan ke dalam output/result/ .
Inferensi batch juga didukung, coba
python3 synthesize.py --source preprocessed_data/DATASET/val.txt --model MODEL --restore_step RESTORE_STEP --mode batch --dataset DATASET
Untuk mensintesis semua ucapan di preprocessed_data/DATASET/val.txt .
Laju pitch/volume/berbicara dari ucapan yang disintesis dapat dikontrol dengan menentukan rasio pitch/energi/durasi yang diinginkan. Misalnya, seseorang dapat meningkatkan tingkat berbicara sebesar 20 % dan mengurangi volume sebesar 20 % dengan
python3 synthesize.py --text "YOUR_DESIRED_TEXT" --model MODEL --restore_step RESTORE_STEP --mode single --dataset DATASET --duration_control 0.8 --energy_control 0.8
Harap dicatat bahwa kemampuan kontrol berasal dari FastSpeech2 dan bukan minat vital dari Diffgan-TTS.
Dataset yang didukung adalah
LJSPEECH: Dataset bahasa Inggris speaker tunggal terdiri dari 13100 klip audio pendek dari pembicara pembicara wanita bagian dari 7 buku non-fiksi, total sekitar 24 jam.
VCTK: CSTRK VCTK Corpus mencakup data pidato yang diucapkan oleh 110 penutur bahasa Inggris ( multi-speaker TTS ) dengan berbagai aksen. Setiap pembicara membacakan sekitar 400 kalimat, yang dipilih dari koran, jalur pelangi dan paragraf elisitasi yang digunakan untuk arsip aksen pidato.
Untuk TTS multi-speaker dengan embedder speaker eksternal, unduh rescnn softmax+triplet pretrained model Deepspeaker Philipperemy untuk penyematan speaker dan temukan di ./deepspeaker/pretrained_models/ .
Berlari
python3 prepare_align.py --dataset DATASET
untuk beberapa persiapan.
Untuk penyelarasan paksa, Montreal memaksa Aligner (MFA) digunakan untuk mendapatkan keberpihakan antara ucapan dan urutan fonem. Penyelarasan yang telah diekstraksi untuk set data disediakan di sini. Anda harus membuka ritsleting file di preprocessed_data/DATASET/TextGrid/ . Bergantian, Anda dapat menjalankan pelurus sendiri.
Setelah itu, jalankan skrip preprocessing dengan
python3 preprocess.py --dataset DATASET
Anda dapat melatih tiga jenis model: ' naif ', ' aux ', dan ' dangkal '.
Melatih Versi Naif (' Naif '):
Latih versi naif dengan
python3 train.py --model naive --dataset DATASET
Pelatihan Model Akustik Dasar untuk Versi Dangkal (' Aux '):
Untuk melatih versi dangkal, kita membutuhkan fastspeech2 pra-terlatih. Perintah di bawah ini akan memungkinkan Anda melatih modul FastSpeech2, termasuk dekoder bantu (Mel).
python3 train.py --model aux --dataset DATASET
Pelatihan Versi Dangkal (' Dangkal '):
Untuk memanfaatkan fastspeech2 pra-terlatih, termasuk decoder bantu (Mel), Anda harus lulus --restore_step dengan langkah terakhir pelatihan bantu FastSpeech2 sebagai perintah berikut.
python3 train.py --model shallow --restore_step RESTORE_STEP --dataset DATASET
Misalnya, jika pos pemeriksaan terakhir disimpan pada 200000 langkah selama pelatihan tambahan, Anda harus mengatur --restore_step dengan 200000 . Maka itu akan memuat dan membekukan model AUX dan kemudian melanjutkan pelatihan di bawah mekanisme difusi dangkal aktif.
Menggunakan
tensorboard --logdir output/log/DATASET
untuk melayani Tensorboard di Localhost Anda. Kurva kehilangan, sintesis mel-spectrograms, dan audio ditampilkan.
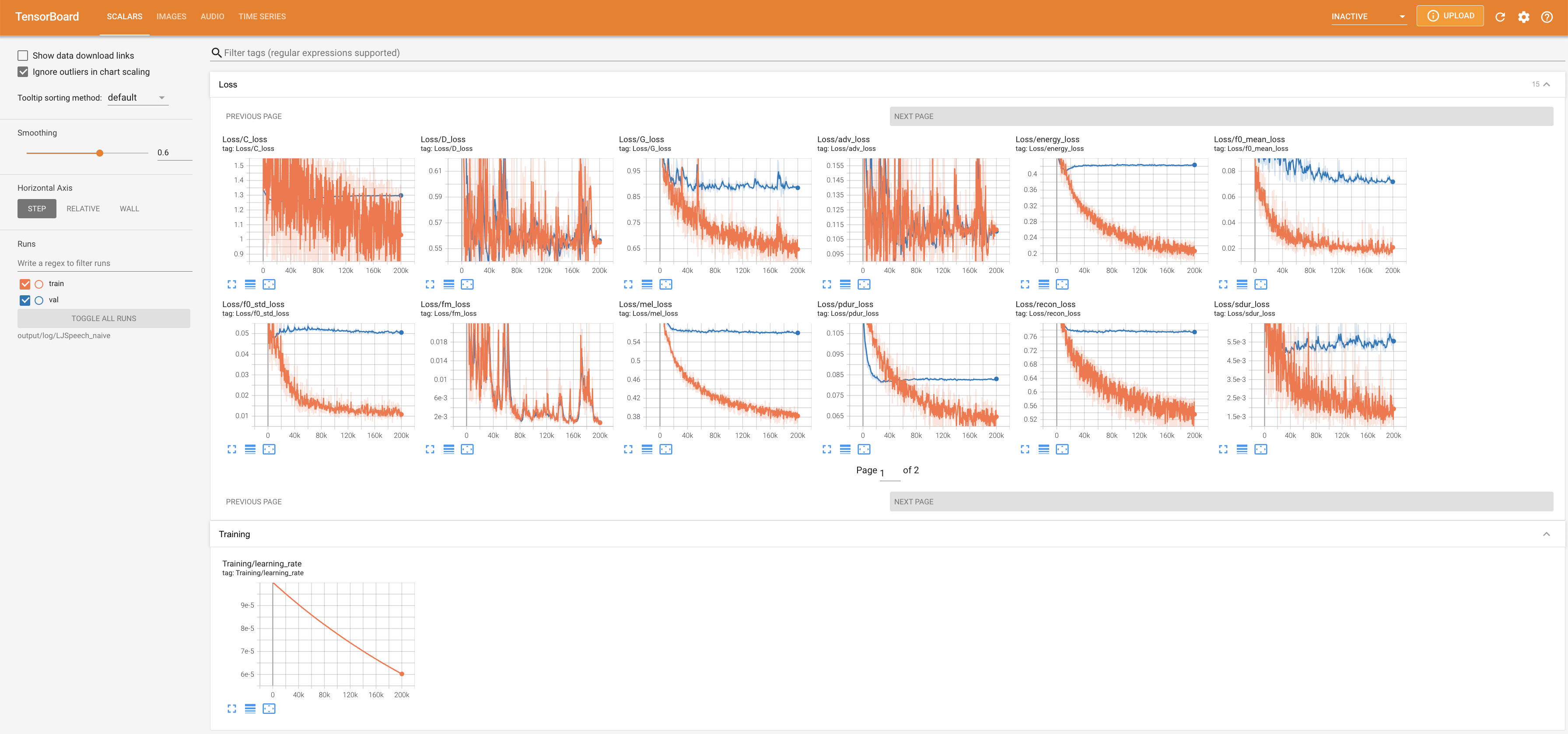
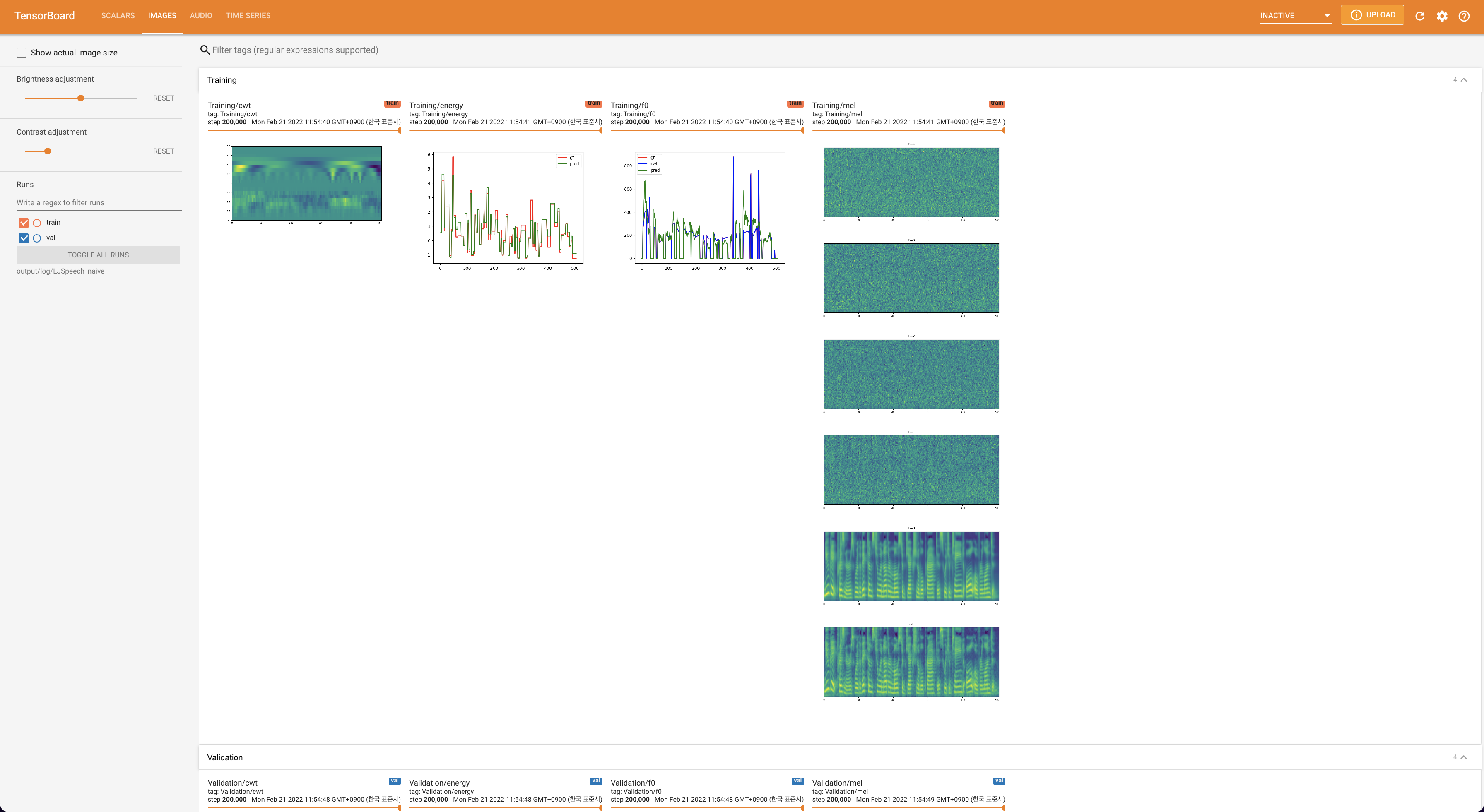
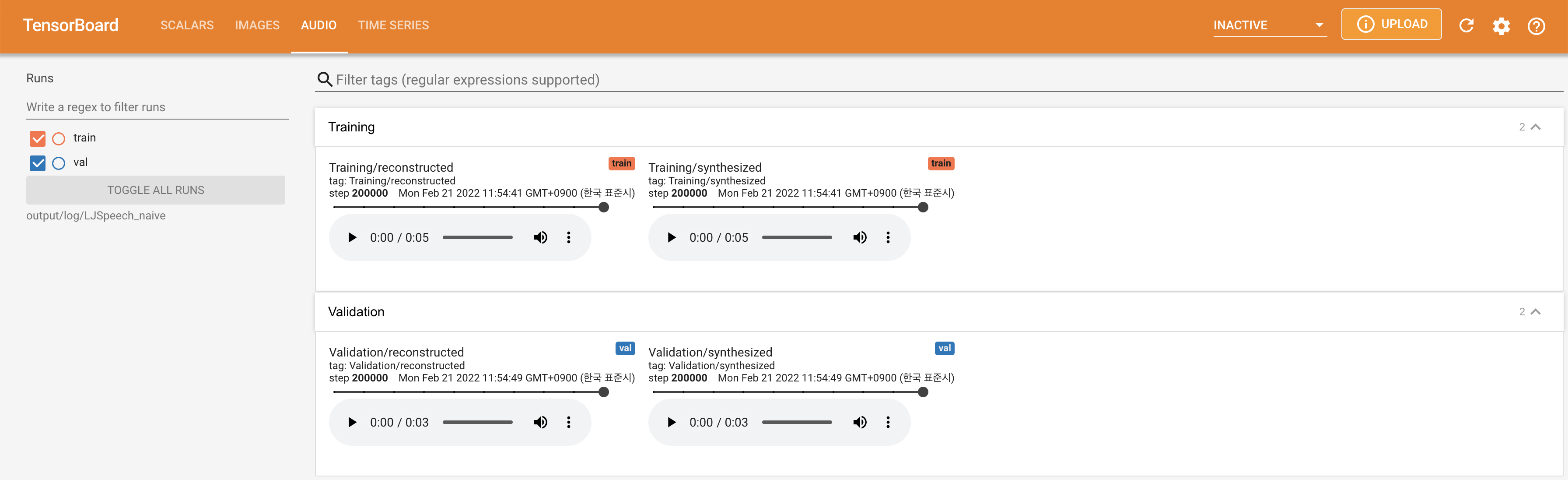
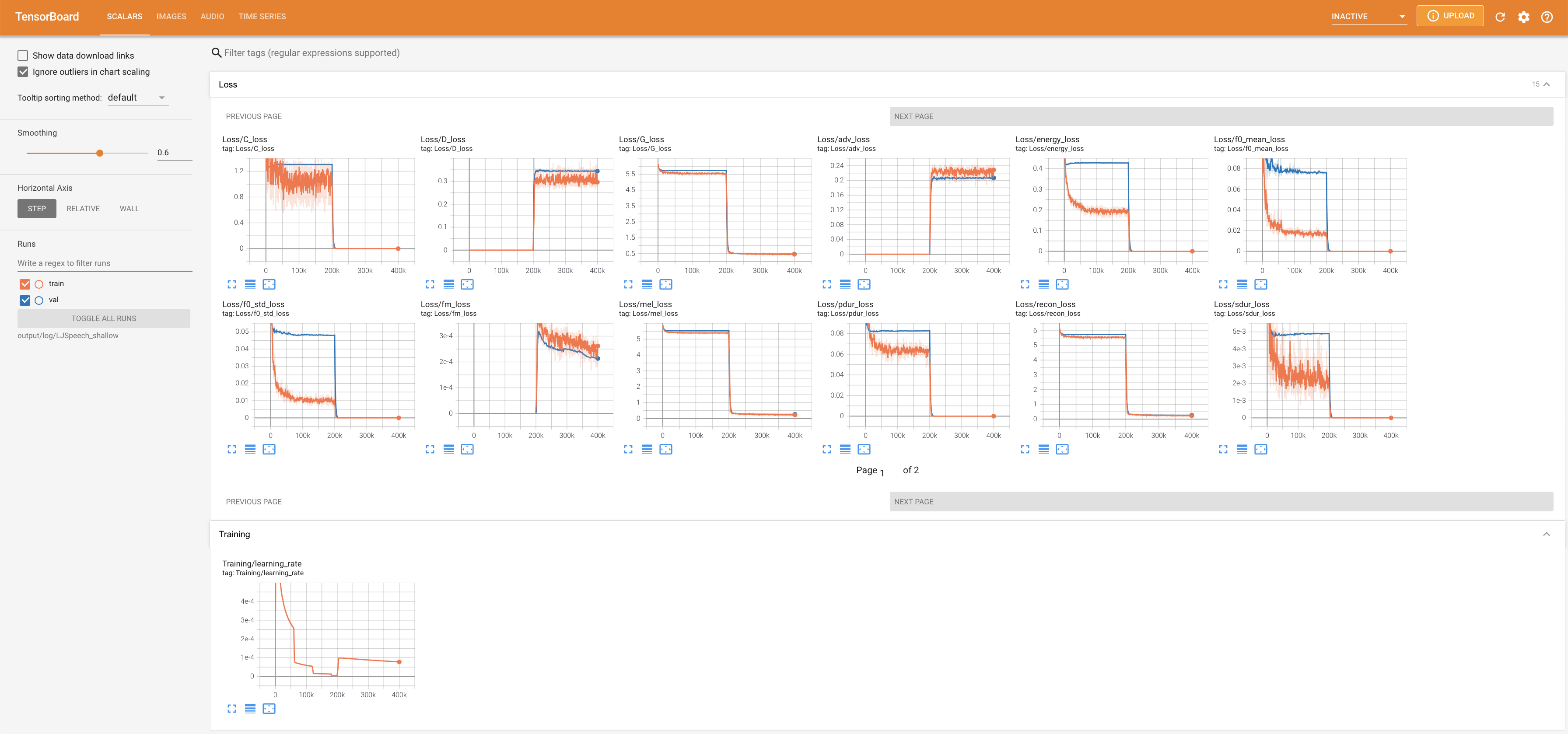
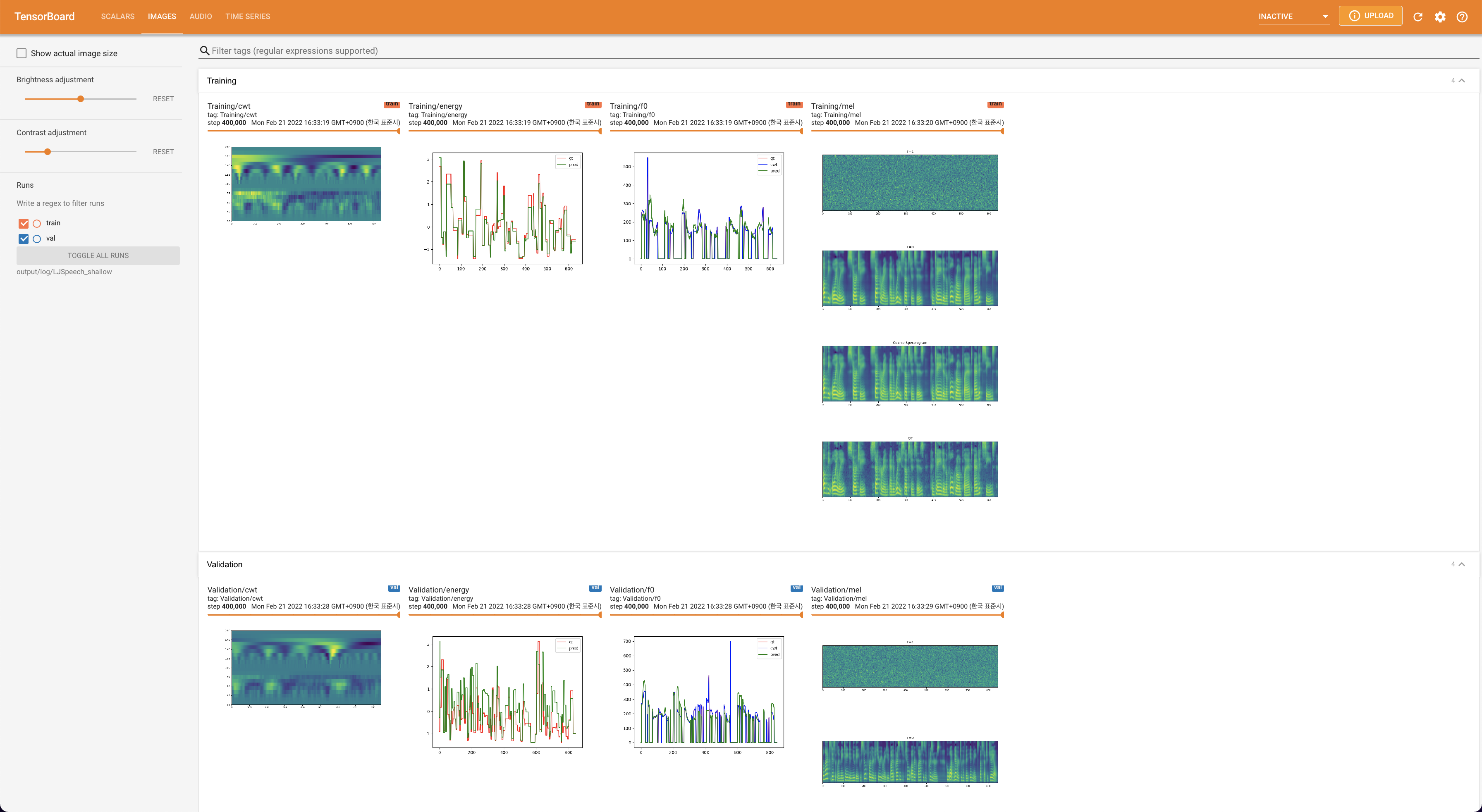
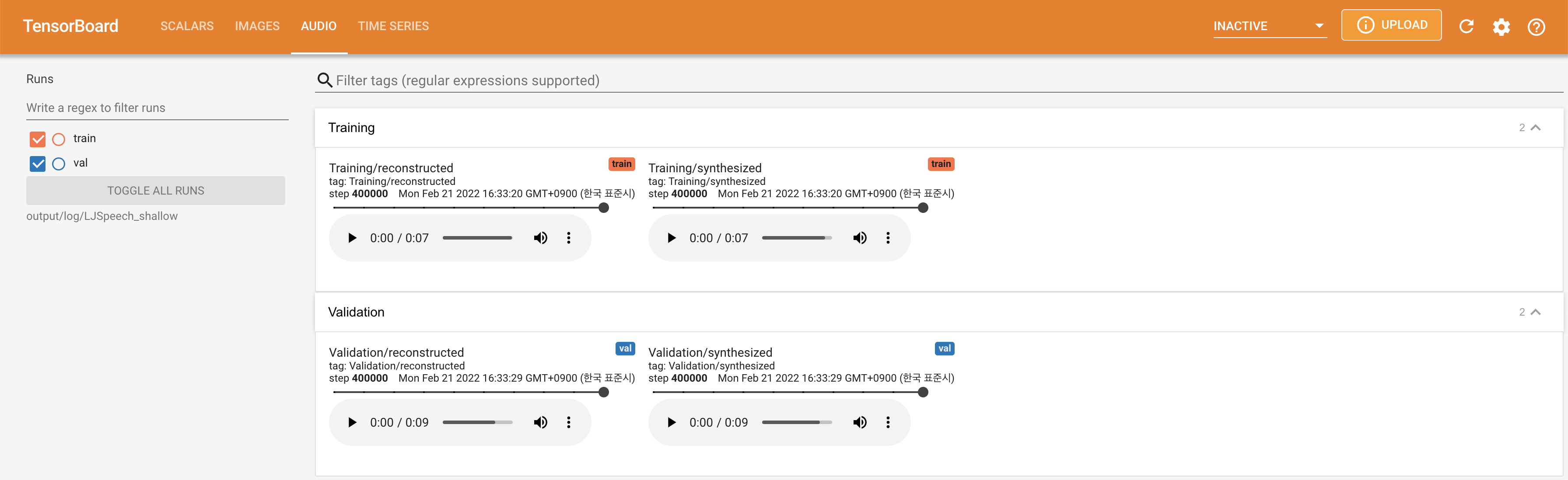
lambda_fm ditetapkan dengan nilai scala karena skalar skala dinamis dihitung sebagai l_recon/l_fm membuat model meledak.'none' dan 'DeepSpeaker' ).
Harap kutip repositori ini dengan "CITE Repositori ini" dari bagian sekitar (kanan atas halaman utama).


