hifi gan
1.0.0
ในบทความของเราเราเสนอ Hifi-Gan: โมเดลที่ใช้ GAN สามารถสร้างคำพูดที่มีความเที่ยงตรงสูงได้อย่างมีประสิทธิภาพ
เราให้บริการการใช้งานและแบบจำลองที่ผ่านการฝึกอบรมของเราเป็นโอเพ่นซอร์สในที่เก็บนี้
บทคัดย่อ: งานล่าสุดเกี่ยวกับการสังเคราะห์คำพูดได้ใช้เครือข่ายฝ่ายตรงข้าม (GANS) เพื่อผลิตรูปคลื่นดิบ แม้ว่าวิธีการดังกล่าวจะช่วยปรับปรุงประสิทธิภาพการสุ่มตัวอย่างและการใช้หน่วยความจำ แต่คุณภาพตัวอย่างของพวกเขายังไม่ถึงแบบจำลองการกำเนิดแบบอัตโนมัติและการไหล ในงานนี้เราเสนอ HIFI-GAN ซึ่งบรรลุทั้งการสังเคราะห์เสียงพูดที่มีประสิทธิภาพและมีความเที่ยงตรงสูง เนื่องจากเสียงพูดประกอบด้วยสัญญาณไซน์ที่มีช่วงเวลาต่าง ๆ เราแสดงให้เห็นว่าการสร้างแบบจำลองรูปแบบเป็นระยะของเสียงเป็นสิ่งสำคัญสำหรับการเพิ่มคุณภาพตัวอย่าง การประเมินผลของมนุษย์แบบอัตนัย (คะแนนความคิดเห็นหมายถึง MOS) ของชุดข้อมูลลำโพงเดียวบ่งชี้ว่าวิธีการที่เราเสนอนั้นแสดงให้เห็นถึงความคล้ายคลึงกับคุณภาพของมนุษย์ในขณะที่สร้างเสียงสูง 22.05 kHz สูง 167.9 เท่าเร็วกว่าแบบเรียลไทม์บน V100 GPU เดียว เรายังแสดงให้เห็นถึงความหลากหลายของ Hifi-Gan ต่อการผกผันของ Mel-spectrogram ของลำโพงที่มองไม่เห็นและการสังเคราะห์คำพูดแบบ end-to-end ในที่สุด HIFI-GAN รุ่นเล็ก ๆ จะสร้างตัวอย่างเร็วกว่า CPU แบบเรียลไทม์ 13.4 เท่าที่มีคุณภาพเทียบเท่ากับคู่ค้าอัตโนมัติ
เยี่ยมชมเว็บไซต์ตัวอย่างของเราสำหรับตัวอย่างเสียง
LJSpeech-1.1/wavs python train.py --config config_v1.json
ในการฝึกอบรม V2 หรือ V3 Generator ให้แทนที่ config_v1.json ด้วย config_v2.json หรือ config_v3.json
จุดตรวจและสำเนาของไฟล์การกำหนดค่าจะถูกบันทึกไว้ในไดเรกทอรี cp_hifigan โดยค่าเริ่มต้น
คุณสามารถเปลี่ยนเส้นทางโดยการเพิ่ม --checkpoint_path
การสูญเสียการตรวจสอบความถูกต้องในระหว่างการฝึกอบรมกับเครื่องกำเนิด V1 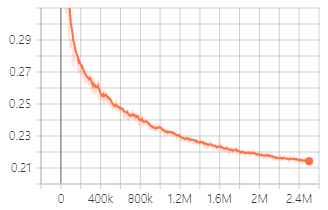
นอกจากนี้คุณยังสามารถใช้แบบจำลองที่ผ่านการฝึกอบรมที่เรามีให้
ดาวน์โหลดนางแบบ pretrained
รายละเอียดของแต่ละโฟลเดอร์มีดังนี้:
| ชื่อโฟลเดอร์ | เครื่องกำเนิดไฟฟ้า | ชุดข้อมูล | ปรับแต่ง |
|---|---|---|---|
| lj_v1 | V1 | ljspeech | เลขที่ |
| lj_v2 | V2 | ljspeech | เลขที่ |
| lj_v3 | V3 | ljspeech | เลขที่ |
| lj_ft_t2_v1 | V1 | ljspeech | ใช่ (tacotron2) |
| lj_ft_t2_v2 | V2 | ljspeech | ใช่ (tacotron2) |
| lj_ft_t2_v3 | V3 | ljspeech | ใช่ (tacotron2) |
| vctk_v1 | V1 | VCTK | เลขที่ |
| vctk_v2 | V2 | VCTK | เลขที่ |
| vctk_v3 | V3 | VCTK | เลขที่ |
| Universal_v1 | V1 | สากล | เลขที่ |
เราจัดทำแบบจำลองสากลด้วยน้ำหนัก discriminator ที่สามารถใช้เป็นฐานสำหรับการถ่ายโอนการเรียนรู้ไปยังชุดข้อมูลอื่น ๆ
.npy Audio File : LJ001-0001.wav
Mel-Spectrogram File : LJ001-0001.npy
ft_dataset และคัดลอกไฟล์ mel-spectrogram ที่สร้างขึ้นลง python train.py --fine_tuning True --config config_v1.json
test_files และคัดลอกไฟล์ WAV ลงในไดเรกทอรี python inference.py --checkpoint_file [generator checkpoint file path]
ไฟล์ WAV ที่สร้างขึ้นจะถูกบันทึกไว้ใน generated_files โดยค่าเริ่มต้น
คุณสามารถเปลี่ยนพา ธ ได้โดยเพิ่มตัวเลือก --output_dir
test_mel_files และคัดลอกไฟล์ mel-spectrogram ที่สร้างขึ้นลงในไดเรกทอรี python inference_e2e.py --checkpoint_file [generator checkpoint file path]
ไฟล์ WAV ที่สร้างขึ้นจะถูกบันทึกไว้ใน generated_files_from_mel โดยค่าเริ่มต้น
คุณสามารถเปลี่ยนพา ธ ได้โดยเพิ่มตัวเลือก --output_dir
เราอ้างถึง Waveglow, Melgan และ Tacotron2 เพื่อใช้สิ่งนี้


