hifi gan
1.0.0
우리 논문에서, 우리는 Hifi-Gan : 높은 충실도를 효율적으로 생성 할 수있는 GAN 기반 모델을 제안했습니다.
우리는이 저장소에서 구현 및 사전 처리 된 모델을 오픈 소스로 제공합니다.
초록 : 언어 합성에 관한 최근의 몇 가지 연구는 생성 적대성 네트워크 (GANS)를 사용하여 원시 파형을 생성했습니다. 이러한 방법은 샘플링 효율 및 메모리 사용을 향상 시키지만, 샘플 품질은 아직 자동 회귀 및 흐름 기반 생성 모델의 샘플 품질에 도달하지 못했습니다. 이 작업에서 우리는 효율적이고 고유 한 음성 합성을 달성하는 Hifi-Gan을 제안합니다. 음성 오디오가 다양한 기간을 가진 정현파 신호로 구성되므로 오디오의 정기 패턴을 모델링하는 것이 샘플 품질을 향상시키는 데 중요하다는 것을 보여줍니다. 단일 스피커 데이터 세트의 주관적인 인간 평가 (평균 의견 점수, MOS)는 우리의 제안 된 방법은 인간의 품질과 유사성을 나타내며 단일 V100 GPU에서 실시간보다 22.05 kHz 고 충실도 오디오 167.9 배 더 빠르게 생성 함을 나타냅니다. 우리는 또한 보이지 않는 스피커의 멜 스피어 그램 역전과 엔드 투 엔드 음성 합성에 대한 Hifi-Gan의 일반성을 보여줍니다. 마지막으로, Hifi-Gan의 작은 풋 프린트 버전은자가 회귀 대응 물과 비슷한 품질로 CPU의 실시간보다 13.4 배 빠른 샘플을 생성합니다.
오디오 샘플은 데모 웹 사이트를 방문하십시오.
LJSpeech-1.1/wavs 로 옮깁니다 python train.py --config config_v1.json
v2 또는 v3 생성기를 훈련 시키려면 config_v1.json config_v2.json 또는 config_v3.json 으로 교체하십시오.
체크 포인트 및 구성 파일의 사본은 기본적으로 cp_hifigan 디렉토리에 저장됩니다.
--checkpoint_path 옵션을 추가하여 경로를 변경할 수 있습니다.
V1 생성기를 사용한 훈련 중에 검증 손실. 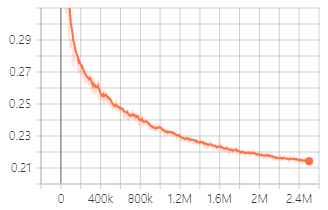
우리가 제공하는 사전 취사 모델을 사용할 수도 있습니다.
사전 각인 모델을 다운로드하십시오
각 폴더의 세부 사항은 다음과 같습니다.
| 폴더 이름 | 발전기 | 데이터 세트 | 미세 조정 |
|---|---|---|---|
| LJ_V1 | v1 | ljspeech | 아니요 |
| LJ_V2 | v2 | ljspeech | 아니요 |
| lj_v3 | v3 | ljspeech | 아니요 |
| LJ_FT_T2_V1 | v1 | ljspeech | 예 (Tacotron2) |
| LJ_FT_T2_V2 | v2 | ljspeech | 예 (Tacotron2) |
| LJ_FT_T2_V3 | v3 | ljspeech | 예 (Tacotron2) |
| vctk_v1 | v1 | vctk | 아니요 |
| vctk_v2 | v2 | vctk | 아니요 |
| vctk_v3 | v3 | vctk | 아니요 |
| Universal_v1 | v1 | 만능인 | 아니요 |
우리는 Universal 모델에 다른 데이터 세트로 전송을위한 기반으로 사용될 수있는 판별 자 가중치를 제공합니다.
.npy 여야합니다. Audio File : LJ001-0001.wav
Mel-Spectrogram File : LJ001-0001.npy
ft_dataset 폴더를 만들고 생성 된 멜 스펙트럼 파일을 복사하십시오. python train.py --fine_tuning True --config config_v1.json
test_files 디렉토리를 만들고 wav 파일을 디렉토리로 복사하십시오. python inference.py --checkpoint_file [generator checkpoint file path]
생성 된 WAV 파일은 기본적으로 generated_files 에 저장됩니다.
--output_dir 옵션을 추가하여 경로를 변경할 수 있습니다.
test_mel_files 디렉토리를 만들고 생성 된 Mel-Spectrogram 파일을 디렉토리로 복사하십시오. python inference_e2e.py --checkpoint_file [generator checkpoint file path]
생성 된 WAV 파일은 기본적으로 generated_files_from_mel 에 저장됩니다.
--output_dir 옵션을 추가하여 경로를 변경할 수 있습니다.
우리는 이것을 구현하기 위해 WaveGlow, Melgan 및 Tacotron2를 언급했습니다.


