(อย่าลังเลที่จะแนะนำการเปลี่ยนแปลง)
เอกสาร
- การรวมกันเป็นตัวแทนและถ่าน: https://arxiv.org/pdf/1811.07240.pdf
- การเรียนรู้การถ่ายโอน tacotron: https://arxiv.org/pdf/1904.06508.pdf
- เวลา Phoneme จากความสนใจ: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- การฝึกอบรมแบบกึ่งผู้ดูแลเพื่อปรับปรุงประสิทธิภาพของข้อมูลในการสังเคราะห์คำพูดแบบ end-to-end-https://arxiv.org/pdf/1808.10128.pdf
- การฟังขณะพูด: ห่วงโซ่คำพูดโดยการเรียนรู้ลึก - https://arxiv.org/pdf/1707.04879.pdf
- การสูญเสียแบบ end-to-end generelized สำหรับการตรวจสอบลำโพง: https://arxiv.org/pdf/1710.10467.pdf
- ES-TACOTRON2: Multi-Task Tacotron 2 พร้อมเครือข่ายโดยประมาณที่ผ่านการฝึกอบรมมาล่วงหน้าสำหรับการลดปัญหาความไม่แน่นอน: https://www.mdpi.com/2078-2489/10/4/131/pdf
- Fastspeech: https://arxiv.org/pdf/1905.09263.pdf
- เรียนรู้การร้องเพลงจากคำพูด: https://arxiv.org/pdf/1912.10128.pdf
- tts-gan: https://arxiv.org/pdf/1909.11646.pdf
- พวกเขาใช้ระยะเวลาและคุณสมบัติทางภาษาสำหรับ EN2EN TTS
- ใกล้กับประสิทธิภาพของ Wavenet
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Melnet: https://arxiv.org/abs/1906.01083
- Aligntts: https://arxiv.org/pdf/2003.01950.pdf
- การสลายตัวของคำพูดที่ไม่ได้รับการดูแลผ่านคอขวดข้อมูลสาม
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- flowtron: https://arxiv.org/pdf/2005.05957.pdf
- ผกผัน autoregresive flow บน tacotron เช่นสถาปัตยกรรม
- Waveglow เป็น Vocoder
- สไตล์การพูดฝังด้วยส่วนผสมของแบบจำลองเกาส์เซียน
- แบบจำลองมีขนาดใหญ่และมีขนาดใหญ่กว่า Tacotron วานิลลา
- ค่า MOS นั้นดีกว่าการใช้ทาโคทตรอนสาธารณะ
- ระบบการใช้ข้อความแบบข้อความที่ฝึกอบรมได้อย่างมีประสิทธิภาพขึ้นอยู่กับเครือข่ายที่ลึกล้ำด้วยความสนใจที่นำทาง: https://arxiv.org/pdf/1710.08969.pdf
บทสรุปที่กว้างขวาง
end-to-end text-to-to-speech: http://arxiv.org/abs/2006.03575 (คลิกเพื่อขยาย)
- End2end Feed-Forward TTS การเรียนรู้
- การจัดตำแหน่งตัวละครได้ทำด้วยโมดูลการจัดตำแหน่งแยกต่างหาก
- ผู้จัดตำแหน่งทำนายความยาวของตัวละครแต่ละตัว - ที่ตั้งตรงกลางของถ่านพบว่ามีความยาวรวมของอักขระก่อนหน้า - ตำแหน่งถ่านจะถูกแก้ไขด้วยหน้าต่างแบบเกาส์เซียน WRT ความยาวเสียงจริง
- เอาต์พุตเสียงถูกคำนวณในโดเมน MU-LAW (ฉันไม่มีเหตุผลสำหรับเรื่องนี้)
- ใช้หน้าต่างเสียงเพียง 2 วินาทีสำหรับการ traning
- เครื่องกำเนิดไฟฟ้า GAN-TTS ใช้ในการสร้างสัญญาณเสียง
- RWD ถูกใช้เป็นตัวแบ่งระดับเสียง
- MELD: พวกเขาใช้สถาปัตยกรรมลึกหนาบางเป็นตัวแบ่งระดับสเปกโตรแกรมที่ทำให้เกิดปัญหาในการสร้างภาพขึ้นใหม่
- การสูญเสีย Spectrogram
- การใช้เพียงฟีดแบ็กที่เป็นปฏิปักษ์นั้นไม่เพียงพอที่จะเรียนรู้การจัดตำแหน่งถ่าน พวกเขาใช้ Spectrogram Loss B/W ที่ทำนายไว้ Spectrograms และรายละเอียดความจริงพื้นดิน
- โปรดทราบว่าโมเดลทำนายสัญญาณเสียง Spectrograms ด้านบนคำนวณจากเสียงที่สร้างขึ้น
- การห่อเวลาแบบไดนามิกใช้ในการคำนวณการจัดตำแหน่งที่มีต้นทุนน้อยที่สุด B/W ที่สร้างขึ้นด้วยความหมายและความจริงพื้นดิน
- มันเกี่ยวข้องกับวิธีการเขียนโปรแกรมแบบไดนามิกเพื่อค้นหาการจัดตำแหน่งที่น้อยที่สุด
- การสูญเสียความยาวของการจัดตำแหน่งใช้เพื่อลงโทษผู้จัดตำแหน่งสำหรับการทำนายที่แตกต่างจากความยาวเสียงจริง
- พวกเขาฝึกอบรมโมเดลด้วยชุดข้อมูลลำโพงหลายชุด แต่รายงานผลลัพธ์เกี่ยวกับลำโพงที่มีประสิทธิภาพดีที่สุด
- การศึกษาการระเหยความสำคัญของแต่ละองค์ประกอบ: (ความยาวและสเปกโตรแกรมลอส)> rwd> meld> phonemes> multispeakerDataset
- 2 เซ็นต์ของฉัน: มันเป็นรูปแบบการส่งต่อฟีดซึ่งให้การสังเคราะห์คำพูดจบ 2-end โดยไม่จำเป็นต้องฝึกอบรมโมเดล Vocoder แยกต่างหาก อย่างไรก็ตามมันเป็นรุ่นที่ซับซ้อนมากที่มีพารามิเตอร์ไฮเปอร์พารามิเตอร์จำนวนมากและรายละเอียดการใช้งาน นอกจากนี้ผลลัพธ์สุดท้ายไม่ได้ใกล้เคียงกับสถานะของศิลปะ ฉันคิดว่าเราจำเป็นต้องค้นหาอัลกอริทึมเฉพาะสำหรับการจัดตำแหน่งตัวละครซึ่งจะช่วยลดความจำเป็นในการปรับการรวมกันของอัลกอริทึมที่แตกต่างกัน
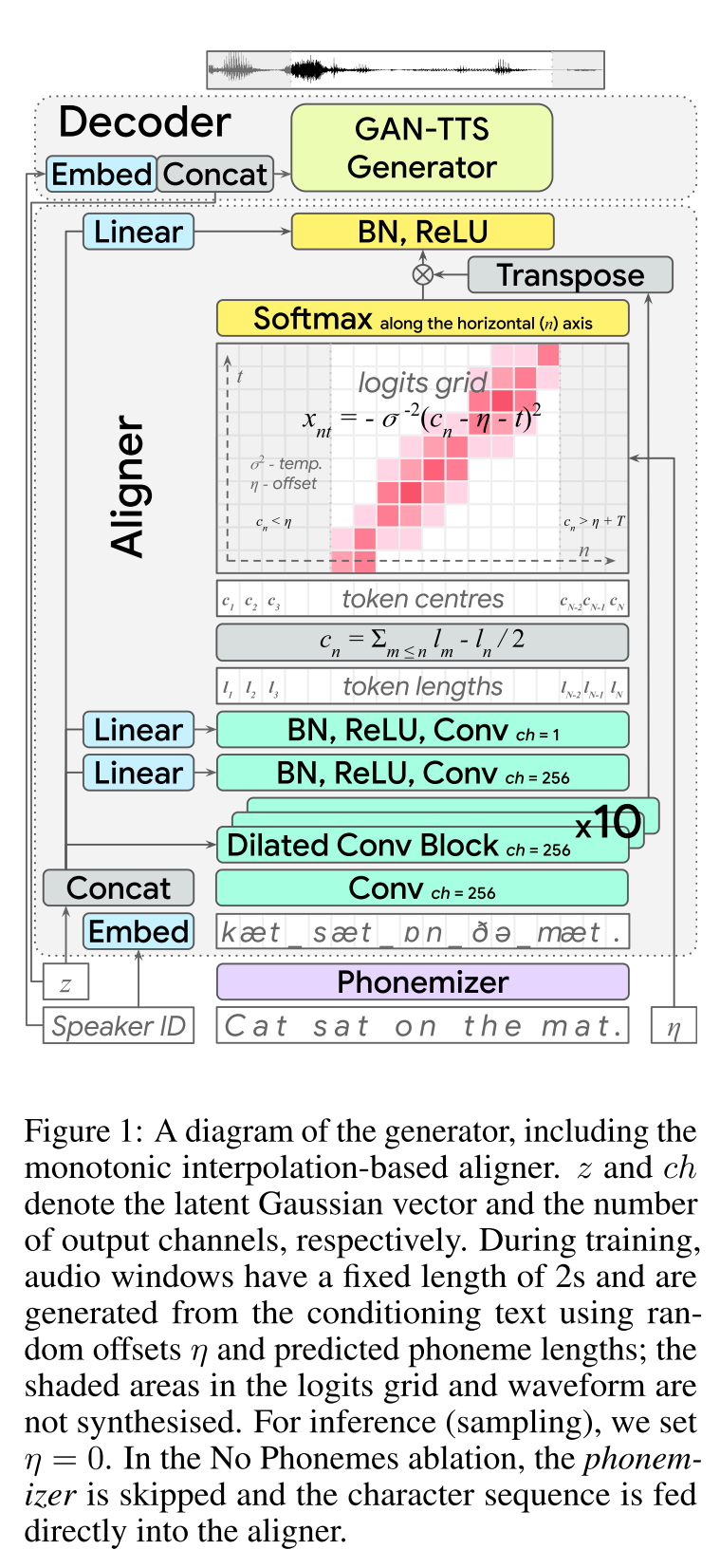
Fast Speech2: http://arxiv.org/abs/2006.04558 (คลิกเพื่อขยาย)
- ใช้ระยะเวลาฟอนิมที่สร้างโดย MFA เป็นฉลากเพื่อฝึกตัวควบคุมความยาว
- thay ใช้บรรทัดฐานระดับเฟรม F0 และ L2 (ข้อมูลความแปรปรวน) เป็นคุณสมบัติเพิ่มเติม
- โมดูลตัวทำนายความแปรปรวนทำนายข้อมูลความแปรปรวนในเวลาอนุมาน
- การปรับปรุงผลการศึกษาการระเหย: โมเดล <รุ่น + L2_NORM <รุ่น + L2_NORM + F0
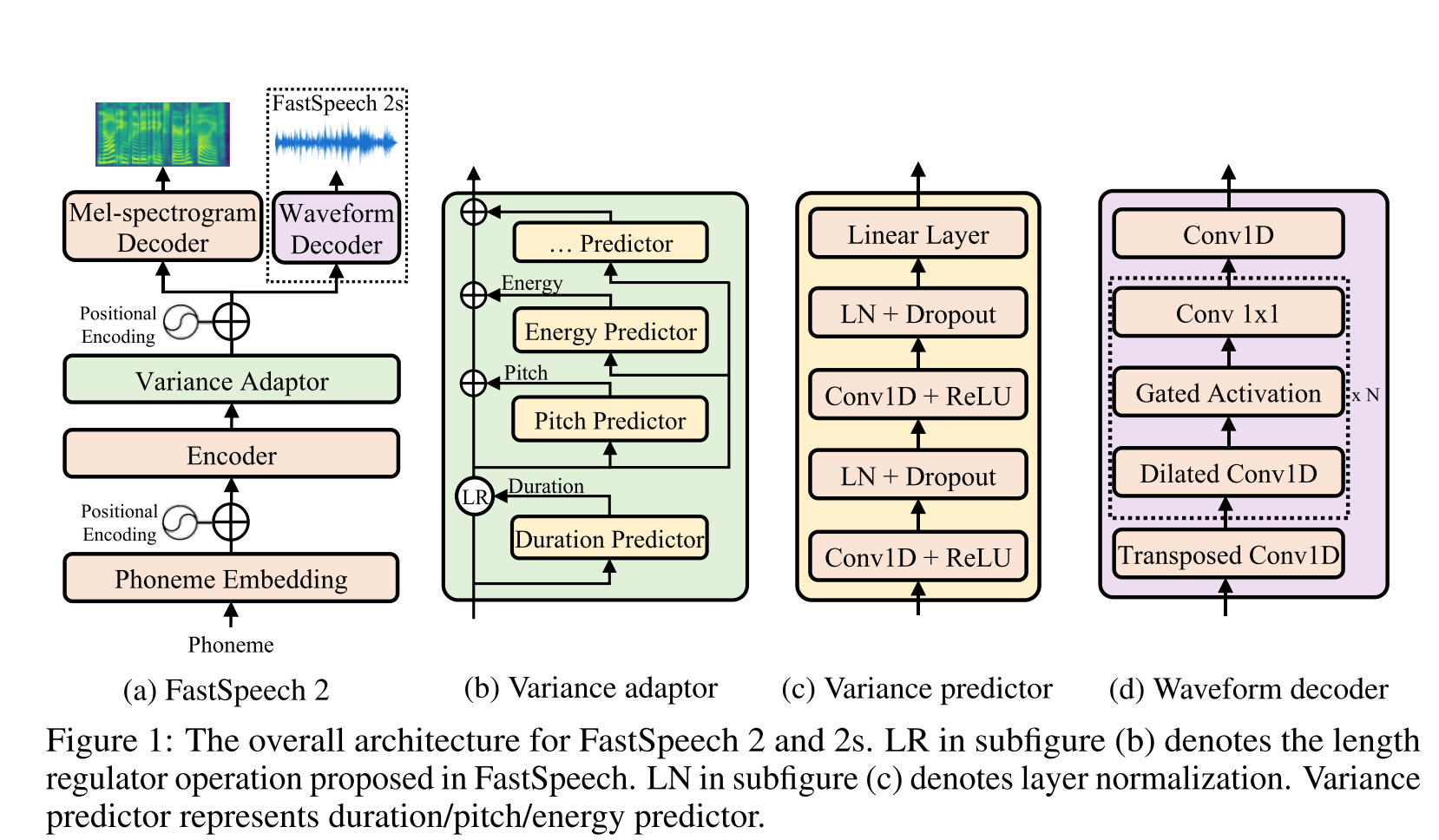
Glow-tts: https://arxiv.org/pdf/2005.11129.pdf (คลิกเพื่อขยาย)
- ใช้การค้นหาการจัดตำแหน่งแบบโมโนโทนิกเพื่อเรียนรู้การจัดตำแหน่ง b/w ข้อความและสเปกโทรครัม
- การจัดตำแหน่งนี้ใช้ในการฝึกตัวทำนายระยะเวลาที่จะใช้ในการอนุมาน
- ตัวเข้ารหัสแมปตัวละครแต่ละตัวเพื่อการแจกแจงแบบเกาส์
- ตัวถอดรหัสแมปแต่ละเฟรมสเปกโตรแกรมกับเวกเตอร์แฝงโดยใช้การไหลของการทำให้เป็นมาตรฐาน (เลเยอร์เรืองแสง)
- เอาต์พุตตัวเข้ารหัสและตัวถอดรหัสจัดเรียงกับ MAS
- ในการทำซ้ำแต่ละครั้งก่อนการจัดตำแหน่งที่น่าจะเป็นไปได้มากที่สุดจะพบได้โดย MAS และการจัดตำแหน่งนี้ใช้เพื่ออัปเดตพารามิเตอร์โหมด
- ตัวทำนายระยะเวลาได้รับการฝึกฝนให้ทำนายจำนวนเฟรมสเปกโทรครัมสำหรับแต่ละอักขระ
- ที่การอนุมานเฉพาะการทำนายระยะเวลาที่ใช้แทน MAS
- Encoder มีสถาปัตยกรรมของหม้อแปลง TTS พร้อมการอัปเดต 2 ครั้ง
- แทนที่จะใช้การเข้ารหัสตำแหน่งสัมบูรณ์พวกเขาใช้การเข้ารหัสตำแหน่ง realtive
- พวกเขายังใช้การเชื่อมต่อที่เหลือสำหรับตัวเข้ารหัส prenet
- ตัวถอดรหัสมีสถาปัตยกรรมเช่นเดียวกับรุ่นเรืองแสง
- พวกเขาฝึกอบรมทั้งรุ่นเดี่ยวและหลายลำโพง
- มันแสดงให้เห็นว่าการทดลอง Glow-TTS มีความแข็งแกร่งมากกว่าประโยคยาวเมื่อเทียบกับ Tacotron2 ต้นฉบับ
- เร็วกว่า Tacotron2 15 เท่าที่การอนุมาน
- 2 เซ็นต์ของฉัน: ตัวอย่างของพวกเขาฟังดูไม่เป็นธรรมชาติเหมือนทาโคทรอน ฉันเชื่อว่าโมเดลความสนใจปกติยังคงสร้างคำพูดที่เป็นธรรมชาติมากขึ้นเนื่องจากความสนใจเรียนรู้การแมปอักขระเพื่อสร้างโมเดลผลลัพธ์โดยตรง อย่างไรก็ตามการใช้ Glow-TTS อาจเป็นทางเลือกที่ดีสำหรับชุดข้อมูลที่ยาก
- ตัวอย่าง: https://github.com/jaywalnut310/glow-tts
- ที่เก็บ: https://github.com/jaywalnut310/glow-tts
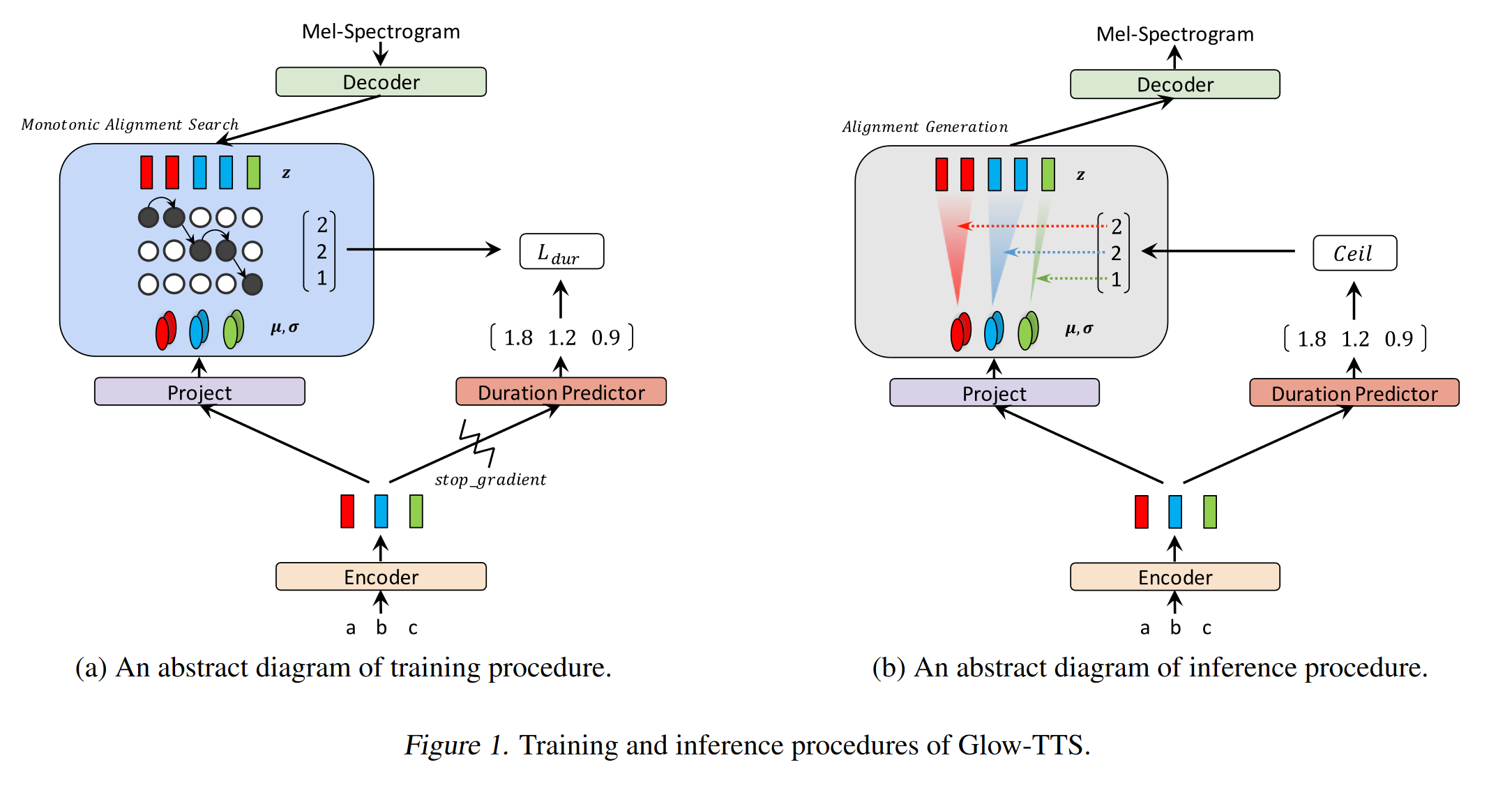
Non-Autoregressive Neural Text-to-Speech: http://arxiv.org/abs/1905.08459 (คลิกเพื่อขยาย)
- แบบจำลองที่ได้มาจาก Deep Voice 3 โดยใช้เลเยอร์ที่ไม่ใช่สิ่งอำนวยความสะดวก
- กระบวนทัศน์ของครูและนักเรียนเพื่อฝึกอบรมนักเรียน ANNON-AUTOREGRESSESSION ด้วยความสนใจหลายบล็อกจากรูปแบบครูอัตโนมัติ
- ครูใช้ในการสร้างการจัดตำแหน่งแบบข้อความกับสเปกตรัมเพื่อใช้โดยรุ่นนักเรียน
- แบบจำลองได้รับการฝึกฝนด้วยฟังก์ชั่นการสูญเสียสองฟังก์ชั่นสำหรับการจัดตำแหน่งความสนใจและการสร้างสเปกโตรแกรม
- บล็อกความสนใจหลายอย่างปรับแต่งการจัดตำแหน่งความสนใจโดยเลเยอร์
- นักเรียนใช้ความสนใจของผลิตภัณฑ์ดอทด้วยการสืบค้นคีย์และเวกเตอร์ แบบสอบถามเป็นเพียงเวกเตอร์การเข้ารหัสเชิงบวก คีย์และค่าเป็นเอาต์พุตตัวเข้ารหัส
- แบบจำลองที่เสนอนั้นเชื่อมโยงกับการเข้ารหัสตำแหน่งซึ่งต้องอาศัยค่าคงที่ที่แตกต่างกัน
ความสอดคล้องของตัวถอดรหัสสองครั้ง: https://erogol.com/solving-tention-problems-of-tts-models-with-double-decoder-conistency (คลิกเพื่อขยาย)
- โมเดลใช้ทาโคทรอนเหมือนสถาปัตยกรรม แต่มี 2 ตัวถอดรหัสและ postnet
- DDC ใช้ตัวถอดรหัสแบบซิงโครนัสสองตัวโดยใช้อัตราการลดที่แตกต่างกัน
- ตัวถอดรหัสใช้อัตราการลดที่แตกต่างกันดังนั้นพวกเขาจึงคำนวณเอาต์พุตในเม็ดที่แตกต่างกันและเรียนรู้ด้านต่าง ๆ ของข้อมูลอินพุต
- แบบจำลองนี้ใช้ความสอดคล้องระหว่างตัวถอดรหัสทั้งสองนี้เพื่อเพิ่มความทนทานของการจัดตำแหน่งแบบข้อความกับสเปกตรัมที่เรียนรู้
- โมเดลยังใช้การปรับแต่งกับเอาต์พุตตัวถอดรหัสสุดท้ายโดยใช้ postnet ซ้ำหลายครั้ง
- DDC ใช้การทำให้เป็นมาตรฐานแบบแบทช์ในโมดูล prenet และลดชั้นออกกลางคัน
- DDC ใช้การฝึกอบรมแบบค่อยเป็นค่อยไปเพื่อลดเวลาการฝึกอบรมทั้งหมด
- เราใช้เครื่องกำเนิดไฟฟ้า Melgan แบบหลายวงเป็นนักร้องที่ได้รับการฝึกฝนด้วยการแยกแยะหน้าต่างแบบสุ่มหลายแบบแตกต่างจากงานดั้งเดิม
- เราสามารถฝึกอบรมโมเดล DDC ได้ใน 2 วันด้วย GPU เดียวและรุ่นสุดท้ายสามารถสร้างได้เร็วกว่าการพูดแบบเรียลไทม์บน CPU หน้าตัวอย่าง: https://erogol.github.io/ddc-samples/ รหัส: https://github.com/mozilla/tts
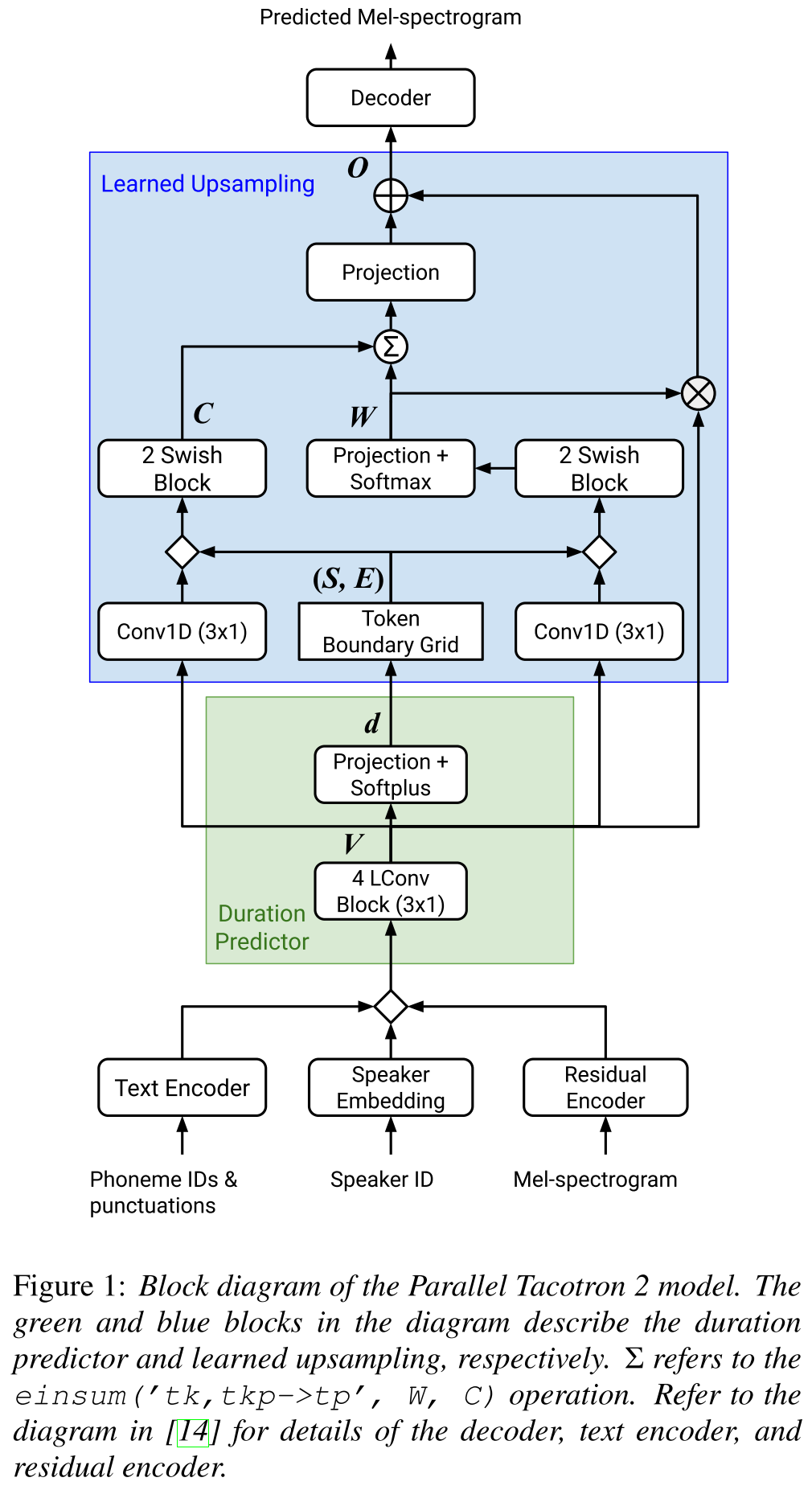
Tacotron2 Parallel: http://arxiv.org/abs/2103.14574 (คลิกเพื่อขยาย)
- ไม่ต้องการข้อมูลระยะเวลาภายนอก
- แก้ปัญหาการจัดตำแหน่งระหว่างสเปคโตรแกรมของจริงและพื้นดินโดยการสูญเสีย Soft-DTW
- ระยะเวลาที่คาดการณ์จะถูกแปลงเป็นการจัดตำแหน่งโดยฟังก์ชั่นการแปลงที่เรียนรู้แทนที่จะเป็นตัวควบคุมความยาวเพื่อแก้ปัญหาการปัดเศษ
- เรียนรู้แผนที่ความสนใจเหนือ "กริดขอบเขตโทเค็น" ซึ่งคำนวณจากระยะเวลาที่คาดการณ์ไว้
- ตัวถอดรหัสถูกสร้างขึ้นบนบล็อก "Convolutions น้ำหนักเบา" 6 "
- VAE ใช้ในการฉายภาพสเปกโตรแกรมอินพุตไปยังคุณสมบัติแฝงและรวมเข้ากับตัวละคร Embeddings เป็นอินพุตไปยังเครือข่าย
- Soft-DTW มีการคำนวณอย่างเข้มข้นเนื่องจากคำนวณความแตกต่างของคู่สำหรับเฟรมสเปกโทรคทั้งหมด พวกเขาห้ามมันด้วยหน้าต่างเส้นทแยงมุมบางอย่างเพื่อลดค่าใช้จ่าย
- วัตถุประสงค์ระยะเวลาสุดท้ายคือผลรวมของการสูญเสียระยะเวลาการสูญเสีย VAE และการสูญเสียสเปกตรัม
- พวกเขาใช้ชุดข้อมูลที่เป็นกรรมสิทธิ์สำหรับการทดลองเท่านั้น
- บรรลุ MOS เดียวกันกับรุ่น Tacotron2 และมีประสิทธิภาพสูงกว่า ParallelTacotron
- หน้าตัวอย่าง : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- รหัส : ยังไม่มีรหัส
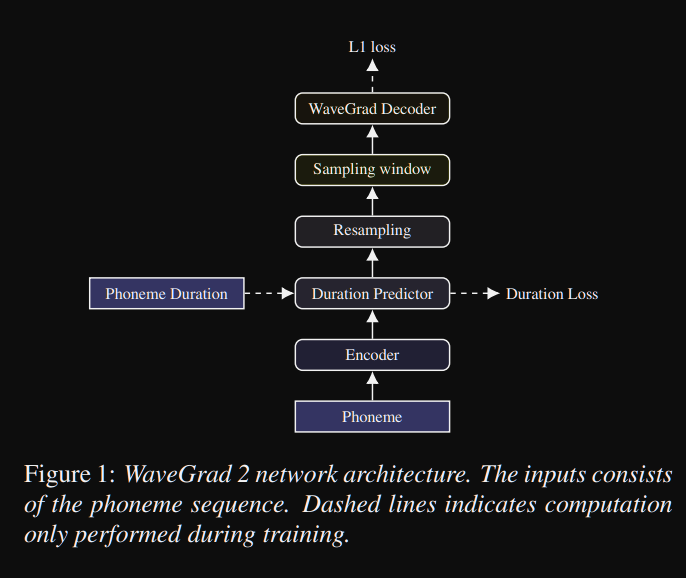
wavegrad2: https://arxiv.org/pdf/2106.09660.pdf (คลิกเพื่อขยาย)
- มันคำนวณรูปคลื่นดิบโดยตรงจากลำดับฟอนิม
- Tacotron2 Like Encoder Model ใช้เพื่อคำนวณการเป็นตัวแทนที่ซ่อนอยู่จากหน่วยเสียง
- tacotron ที่ไม่ได้รับผลกระทบเช่นตัวทำนายระยะเวลาที่อ่อนนุ่มเพื่อจัดตำแหน่งตัวแทนที่ที่ซ่อนอยู่กับเอาท์พุท
- พวกเขาขยายการแสดงที่ซ่อนอยู่ด้วยระยะเวลาที่คาดการณ์ไว้และตัวอย่างหน้าต่างบางบานเพื่อแปลงเป็นรูปคลื่น
- พวกเขาสำรวจขนาดหน้าต่างที่แตกต่างกันระหว่าง 64 และ 256 เฟรมที่สอดคล้องกับการพูด 0.8 และ 3.2 วินาที พวกเขาพบว่ายิ่งใหญ่จะดีกว่า
- หน้าสาธิต : ไม่มีอะไรไกล
- รหัส : ยังไม่มีรหัส
เอกสารหลายลำโพง
- การฝึกอบรมระบบการพูดข้อความประสาทแบบหลายลำโพงโดยใช้ Speech Corpora Immalanced Speech Corpora-https://arxiv.org/abs/1904.00771
- Deep Voice 2-https://papers.nips.cc/paper/6889-deep-voice-2-multi-speaker-neural-text-to-speech.pdf
- ตัวอย่างการปรับตัวที่มีประสิทธิภาพ TTS - https://openreview.net/pdf?id=rkzjuoacfx
- วิธีการฝัง Wavenet + ลำโพง
- Voice Loop - https://arxiv.org/abs/1707.06588
- การสร้างแบบจำลองพื้นที่แฝงหลายลำโพงเพื่อปรับปรุงระบบประสาท TTS อย่างรวดเร็วลงทะเบียนลำโพงใหม่และเพิ่มเสียงพรีเมี่ยม - https://arxiv.org/pdf/1812.05253.pdf
- ถ่ายโอนการเรียนรู้จากการตรวจสอบลำโพงไปยังการสังเคราะห์ข้อความหลายข้อความถึงพูด-https://arxiv.org/pdf/1806.04558.pdf
- ติดตั้งลำโพงใหม่ตามตัวอย่างสั้น ๆ ที่ไม่ได้กำหนด - https://arxiv.org/pdf/1802.06984.pdf
- การสูญเสียแบบ end-to-end ทั่วไปสำหรับการตรวจสอบผู้พูด-https://arxiv.org/abs/1710.10467
บทสรุปที่กว้างขวาง
การเรียนรู้แบบกึ่งผู้ดูแลสำหรับการสังเคราะห์ข้อความหลายลำโพงต่อการพูดโดยใช้การแสดงคำพูดแบบไม่ต่อเนื่อง: http://arxiv.org/abs/2005.08024
- ฝึกอบรมโมเดล TTS หลายลำโพงที่มีข้อมูลคู่ยาวเพียงหนึ่งชั่วโมง (การจัดตำแหน่งแบบข้อความกับเสียง) และข้อมูลที่ไม่มีคู่ (เฉพาะ)
- มันเรียนรู้หนังสือรหัสที่มีคำแต่ละคำตรงกับหน่วยเสียงเดียว
- หนังสือรหัสถูกจัดแนวกับหน่วยเสียงโดยใช้ข้อมูลที่จับคู่และอัลกอริทึม CTC
- หนังสือรหัสนี้ฟังก์ชั่นเช่นพร็อกซีเพื่อประเมินลำดับฟอนิมโดยปริยายของข้อมูลที่ไม่ได้จับคู่
- พวกเขาสแต็ก TACOTRON2 โมเดลด้านบนเพื่อดำเนินการ TTS โดยใช้รหัสฝังรหัสที่สร้างขึ้นโดยส่วนเริ่มต้นของโมเดล
- พวกเขาเอาชนะวิธีการมาตรฐานในการตั้งค่าข้อมูลคู่ยาว 1 ชั่วโมง
- พวกเขาไม่รายงานผลลัพธ์ข้อมูลที่จับคู่เต็ม
- พวกเขาไม่มีการศึกษาการระเหยที่ดีซึ่งน่าสนใจเพื่อดูว่าส่วนต่าง ๆ ของแบบจำลองมีส่วนช่วยในการปฏิบัติงานอย่างไร
- พวกเขาใช้กริฟฟิน-ลิมเป็นคำสั่งดังนั้นจึงมีพื้นที่สำหรับการปรับปรุง
หน้าตัวอย่าง: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
รหัส: https://github.com/ttaoretw/semi-tts 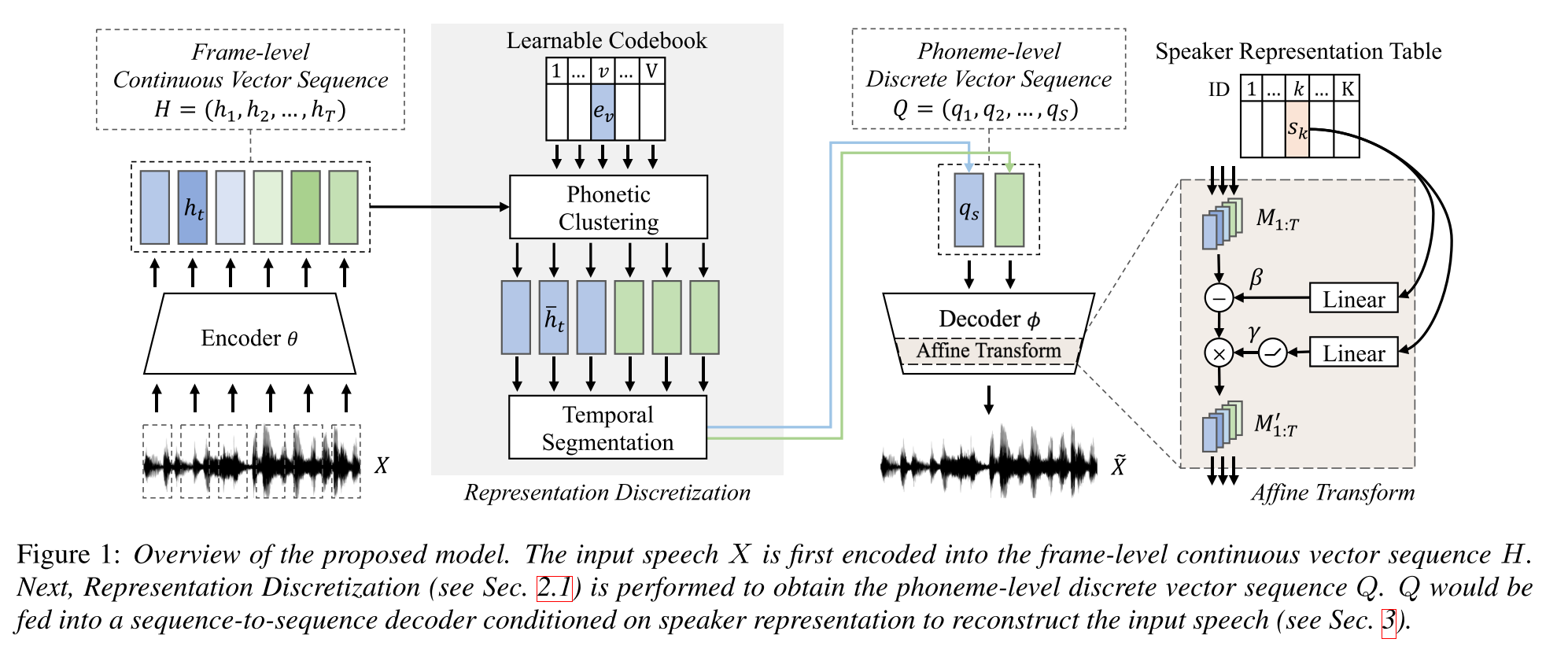
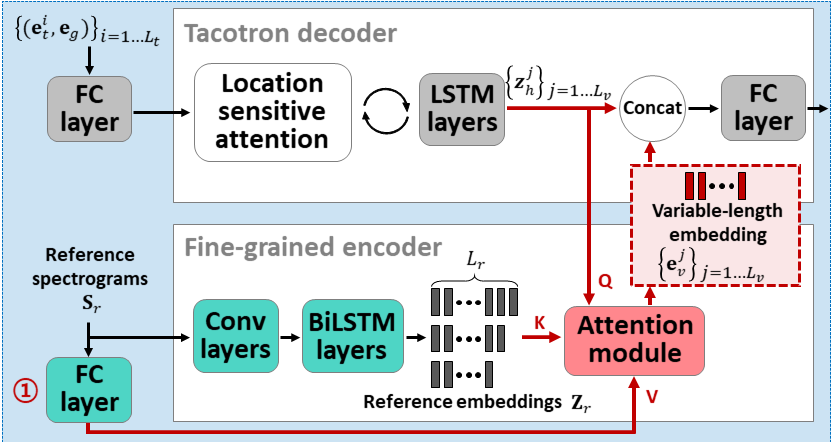
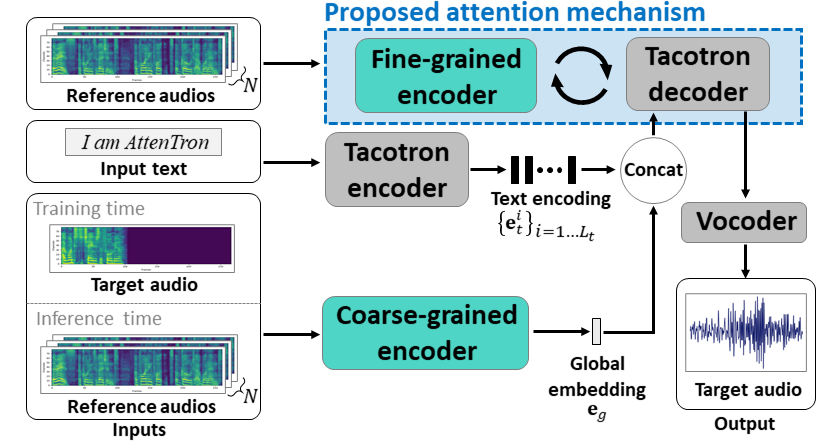
Attentron: การฝังความยาวตัวแปรที่ใช้ความสนใจไม่กี่ครั้ง: https://arxiv.org/abs/2005.08484
- ใช้ตัวเข้ารหัสสองตัวเพื่อเรียนรู้ลำโพงขึ้นอยู่กับคุณสมบัติ
- Coarse Encoder เรียนรู้เวกเตอร์ฝังลำโพงทั่วโลกตามสเปคตรัมอ้างอิงที่ให้ไว้
- Fine Encoder เรียนรู้ความยาวของตัวแปรที่ฝังอยู่เพื่อรักษามิติชั่วคราวในความร่วมมือกับโมดูลความสนใจ
- ความสนใจเลือกเฟรม Spectrogram อ้างอิงที่สำคัญเพื่อสังเคราะห์คำพูดเป้าหมาย
- ฝึกอบรมรุ่นก่อนด้วยชุดข้อมูลลำโพงเดียวก่อน (LJSpeech สำหรับ iters 30k)
- ปรับแต่งโมเดลด้วยชุดข้อมูลหลายลำโพง (VCTK สำหรับ iters 70k)
- มันประสบความสำเร็จในการวัดที่ดีขึ้นเล็กน้อยเมื่อเปรียบเทียบกับการใช้ X-vectors จากรูปแบบการจำแนกประเภทลำโพงและเครื่องเข้ารหัสเสียงอ้างอิงที่ใช้ VAE
หน้าตัวอย่าง: https://hyperconnect.github.io/attentron/
ไปยัง Universal Text-to-Speech: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
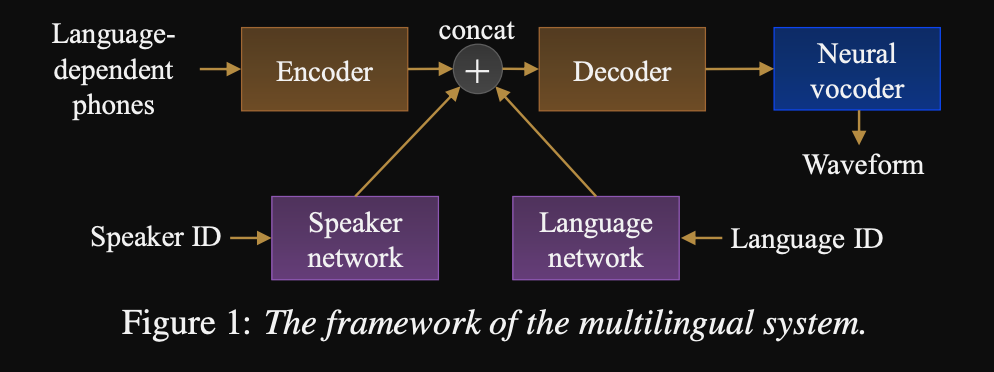
- เฟรมเวิร์กสำหรับลำดับการเรียงลำดับ TTS หลายภาษาหลายภาษา
- โมเดลได้รับการฝึกฝนด้วยชุดข้อมูลที่มีขนาดใหญ่และไม่สมดุลสูงมาก
- โมเดลสามารถเรียนรู้ภาษาใหม่ด้วย 6 นาทีและลำโพงใหม่ที่มีข้อมูล 20 วินาทีหลังจากการฝึกอบรมครั้งแรก
- สถาปัตยกรรมโมเดลเป็นเครือข่ายตัวเข้ารหัสแบบใช้เครื่องเข้ารหัสที่มีเครือข่ายลำโพงและเครือข่ายภาษาสำหรับผู้พูดและภาษา เอาต์พุตของเครือข่ายเหล่านี้จะถูกเชื่อมต่อกับเอาต์พุตตัวเข้ารหัส
- เครือข่ายปรับอากาศใช้เวกเตอร์ร้อนหนึ่งตัวซึ่งเป็นตัวแทนของผู้พูดหรือ ID ภาษาและโครงการเพื่อเป็นตัวแทนปรับอากาศ
- พวกเขาใช้ wavenet vocoder สำหรับการแปลง mel-spectrograms ที่คาดการณ์ไว้เป็นเอาต์พุตรูปคลื่น
- พวกเขาใช้ภาษาขึ้นอยู่กับอินพุตของหน่วยเสียงที่ไม่ได้ใช้ร่วมกันระหว่างภาษา
- พวกเขาสุ่มตัวอย่างแต่ละชุดขึ้นอยู่กับความถี่ผกผันของแต่ละภาษาในชุดข้อมูล ดังนั้นแต่ละชุดการฝึกอบรมมีการกระจายแบบสม่ำเสมอผ่านภาษาช่วยบรรเทาความไม่สมดุลของภาษาในชุดข้อมูลการฝึกอบรม
- สำหรับการเรียนรู้ลำโพง/ภาษาใหม่พวกเขาปรับแต่งโมเดล Decoder ENCODER ด้วยเครือข่ายปรับอากาศ พวกเขาไม่ได้ฝึกอบรมโมเดล Wavenet
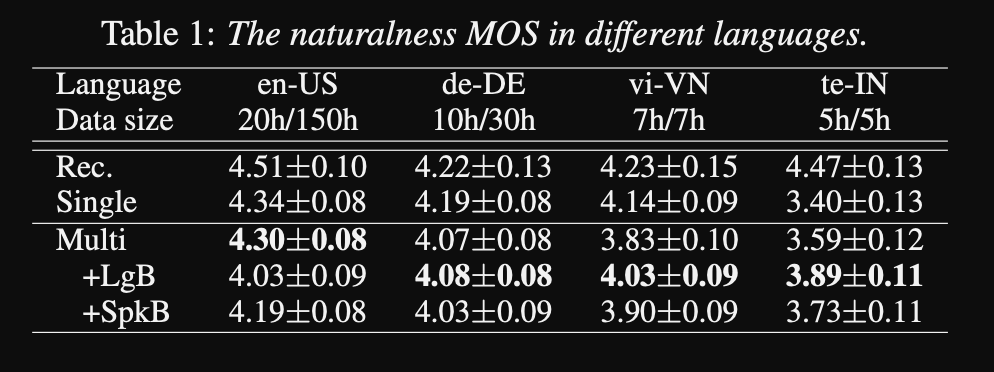
- พวกเขาใช้การบันทึกระดับมืออาชีพ 1250 ชั่วโมงจาก 50 ภาษาสำหรับการฝึกอบรม
- พวกเขาใช้อัตราการสุ่มตัวอย่าง 16kHz สำหรับตัวอย่างเสียงทั้งหมดและการตัดแต่งความเงียบที่จุดเริ่มต้นและจุดสิ้นสุดของแต่ละคลิป
- พวกเขาใช้ 4 V100 GPU สำหรับการฝึกอบรม แต่พวกเขาไม่ได้พูดถึงระยะเวลาที่พวกเขาฝึกฝนแบบจำลอง
- ผลการวิจัยพบว่าโมเดลลำโพงเดี่ยวดีกว่าวิธีการที่เสนอใน MOS Metric
- นอกจากนี้การใช้เครือข่ายการปรับสภาพเป็นสิ่งสำคัญสำหรับภาษาหางยาวในชุดข้อมูลเนื่องจากพวกเขาปรับปรุง MOS Metric สำหรับพวกเขา แต่ทำให้ประสิทธิภาพของภาษาทรัพยากรสูงลดลง
- เมื่อพวกเขาเพิ่มลำโพงใหม่พวกเขาสังเกตว่าการใช้ข้อมูลมากกว่า 5 นาทีจะทำให้ประสิทธิภาพของโมเดลลดลง พวกเขาอ้างว่าเนื่องจากการบันทึกเหล่านี้ไม่สะอาดเท่ากับการบันทึกต้นฉบับการใช้งานมากขึ้นส่งผลกระทบต่อประสิทธิภาพทั่วไปของโมเดล
- โมเดลหลายภาษาสามารถฝึกอบรมได้ด้วยข้อมูลเพียง 6 นาทีสำหรับลำโพงและภาษาใหม่ในขณะที่รุ่นลำโพงเดียวต้องใช้เวลา 3 ชั่วโมงในการฝึกอบรมและไม่สามารถบรรลุค่า MOS ที่คล้ายกันเป็นแบบจำลองหลายภาษา 6 นาที
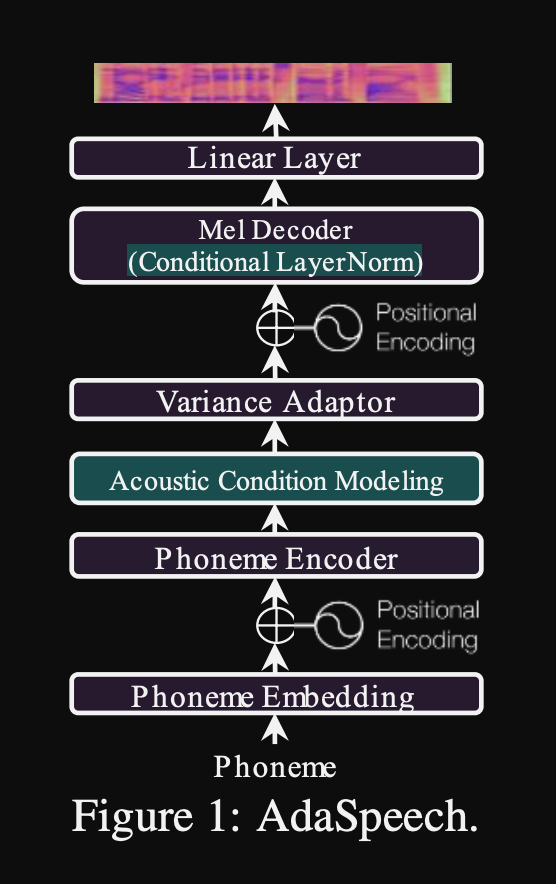
adaspeech: ข้อความที่ปรับได้เป็นคำพูดสำหรับเสียงที่กำหนดเอง: https://openreview.net/pdf?id=drynvt7gg4l
- พวกเขาเสนอระบบที่สามารถปรับให้เข้ากับคุณสมบัติอะคูสติกอินพุตที่แตกต่างกันของผู้ใช้และใช้จำนวนพารามิเตอร์ขั้นต่ำเพื่อให้ได้สิ่งนี้
- สถาปัตยกรรมหลักขึ้นอยู่กับโมเดล FastSpeech2 ที่ใช้ตัวทำนายระดับเสียงและความแปรปรวนเพื่อเรียนรู้ความละเอียดที่ละเอียดยิ่งขึ้นของคำพูดอินพุต
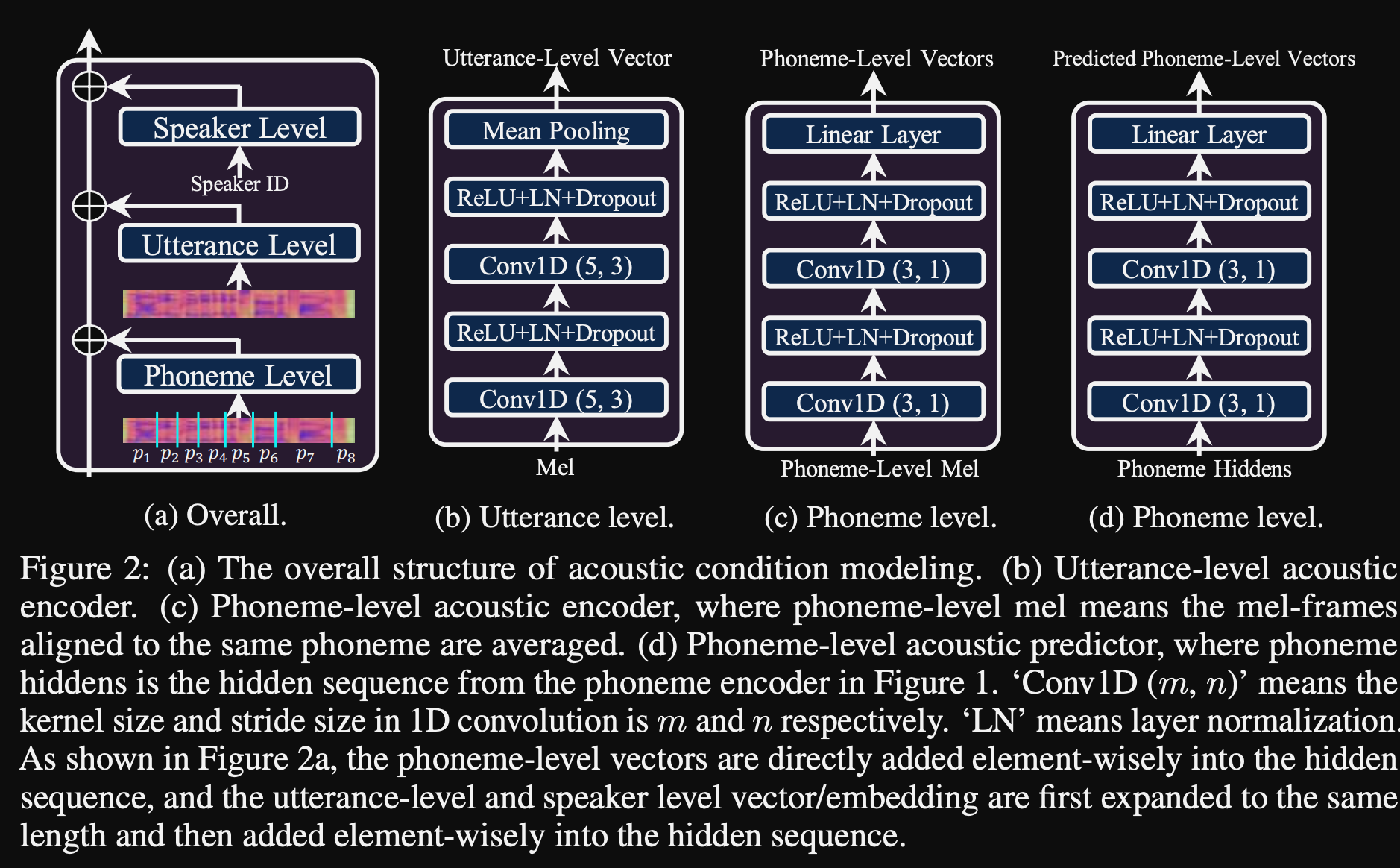
- พวกเขาใช้ 3 เครือข่ายการปรับสภาพเพิ่มเติม
- ระดับคำพูด มันต้องใช้ mel-spectrogram ของคำพูดอ้างอิงเป็นอินพุต
- ระดับเสียง ใช้ระดับฟอนิม mel-spectrograms เป็นอินพุตและคำนวณเวกเตอร์ปรับอากาศระดับเสียง mel-spectrograms ระดับฟอนิมคำนวณโดยการใช้เฟรมสเปกโตรแกรมเฉลี่ยในระยะเวลาของแต่ละฟอนิม
- Phoneme Level 2. ใช้เอาต์พุต phoneme encoder เป็นอินพุต สิ่งนี้แตกต่างจากเครือข่ายด้านบนโดยใช้ข้อมูล Phoneme โดยไม่ต้องเห็น spectrograms
- เครือข่ายการปรับสภาพทั้งหมดเหล่านี้และ back-bone fastspeech2 ใช้เลเยอร์การทำให้เป็นมาตรฐานของเลเยอร์
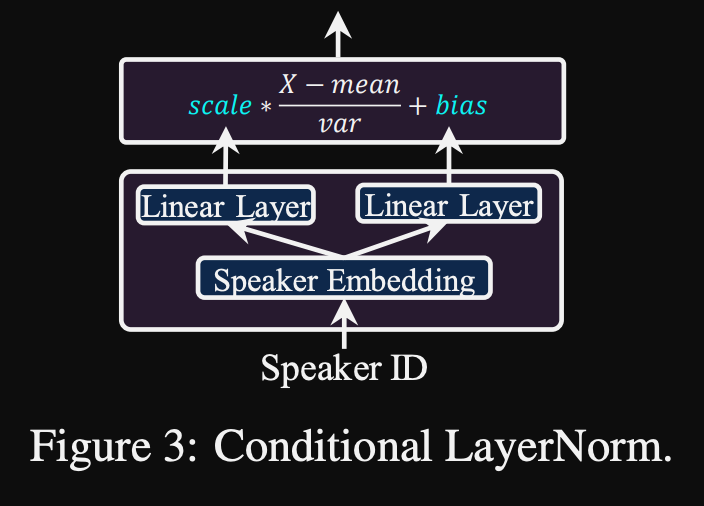
- การทำให้เป็นมาตรฐานเลเยอร์แบบมีเงื่อนไข พวกเขาเสนอการปรับแต่งเฉพาะพารามิเตอร์สเกลและอคติของแต่ละเลเยอร์การทำให้เป็นมาตรฐานแต่ละชั้นเมื่อโมเดลได้รับการปรับแต่งสำหรับลำโพงใหม่ พวกเขาฝึกอบรมโมดูลการปรับสภาพลำโพงสำหรับแต่ละเลเยอร์มาตรฐานเลเยอร์ที่ส่งออกมาตราส่วนและค่าอคติ (พวกเขาใช้โมดูลปรับอากาศลำโพงหนึ่งตัวต่อบล็อกหม้อแปลง)
- หมายความว่าคุณจัดเก็บโมดูลการปรับสภาพลำโพงสำหรับลำโพงใหม่แต่ละตัวเท่านั้นและทำนายค่าสเกลและอคติที่การอนุมานในขณะที่คุณเก็บโมเดลที่เหลือไว้เหมือนกัน
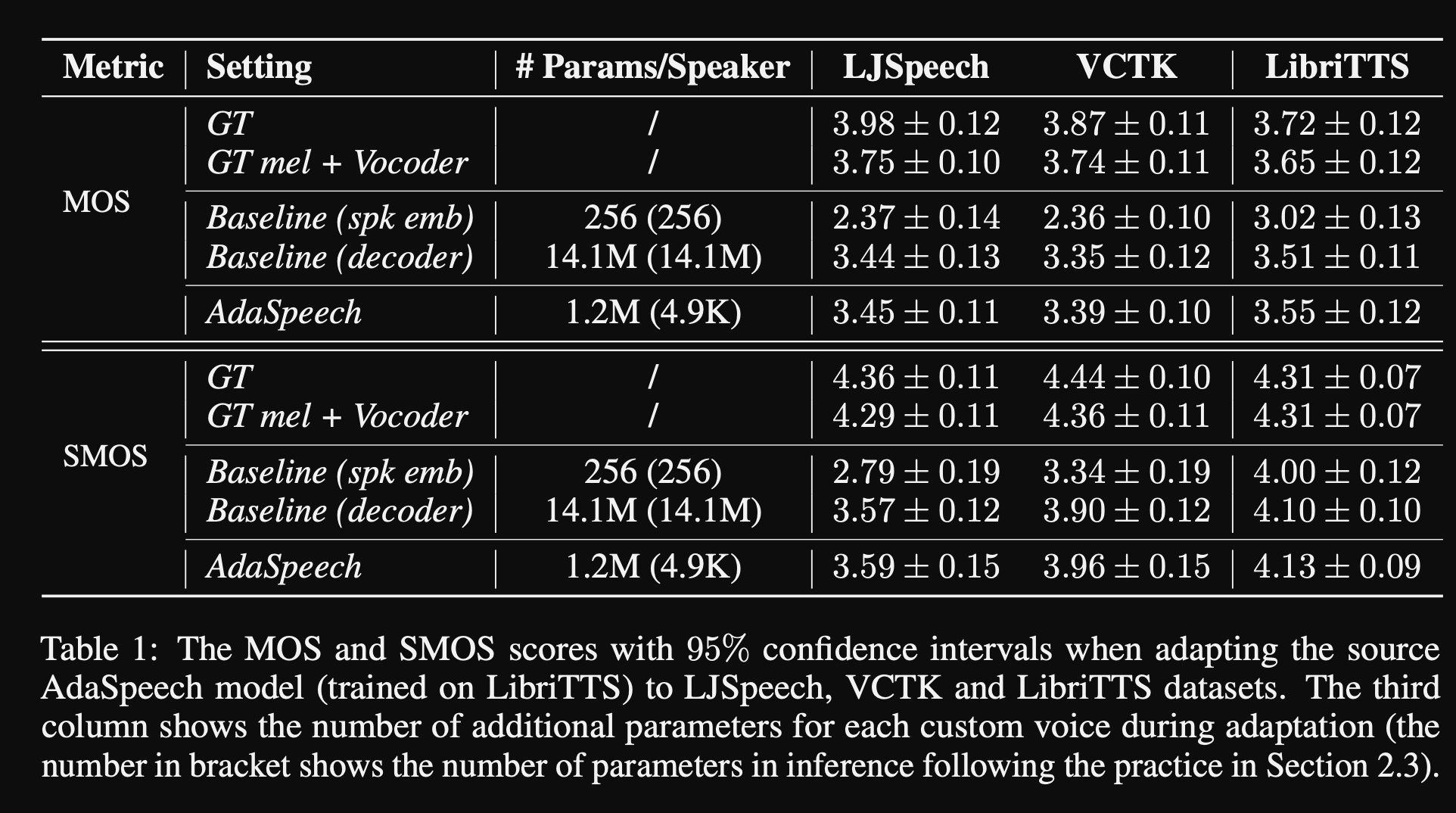
- ในการทดลองพวกเขาฝึกอบรมแบบจำลองก่อนหน้านี้ในชุดข้อมูล Libritts และปรับแต่งด้วย VCTK และ LJSpeech
- ผลการวิจัยพบว่าการใช้การทำให้เป็นมาตรฐานของเลเยอร์แบบมีเงื่อนไขนั้นดีกว่า 2 baselines ซึ่งใช้เฉพาะการฝังลำโพงและการถอดรหัสเครือข่ายที่ปรับแต่ง
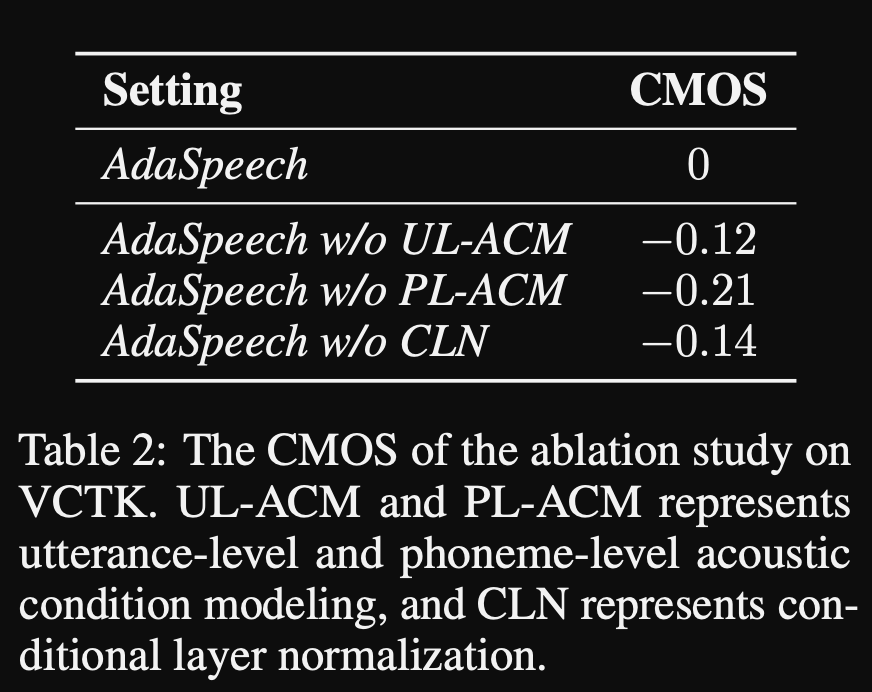
- การศึกษาการระเหยของพวกเขาแสดงให้เห็นว่าส่วนที่สำคัญที่สุดของแบบจำลองคือเครือข่าย“ ระดับเสียง” ตามด้วยการทำให้เป็นมาตรฐานเลเยอร์แบบมีเงื่อนไขและเครือข่าย“ ระดับคำพูด” ตามลำดับ
- หนึ่งในด้านล่างของกระดาษคือแทบจะไม่มีการเปรียบเทียบกับวรรณกรรมและทำให้ผลลัพธ์ยากขึ้นในการประเมินอย่างเป็นกลาง
หน้าตัวอย่าง: https://speechresearch.github.io/adaspeech/

ความสนใจ
- กลไกความสนใจในสถานที่สำหรับการสังเคราะห์ยาวรูปแบบยาว-https://arxiv.org/pdf/1910.10288.pdf
นักร้อง
Melgan: https://arxiv.org/pdf/1910.06711.pdf
ParallelWavegan: https://arxiv.org/pdf/1910.11480.pdf
- การสูญเสีย STFT หลายระดับ
- ~ 1m พารามิเตอร์รุ่น (เล็กมาก)
- แย่กว่า Wavernn เล็กน้อย
การปรับปรุง fftnet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
การสร้างรูปแบบคลื่นเสียงพูดโดยใช้ neuralnetworks convolutional ด้วยเสียงรบกวนและอินพุตเป็นระยะ
- 150.162.46.34:8080/ICASSP2019/ICASSP2019/pdfs/0007045.pdf
สู่การบรรลุคำแนะนำสากลที่แข็งแกร่ง
- https://arxiv.org/pdf/1811.06292.pdf
LPCNET
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
excitenet
- https://arxiv.org/pdf/1811.04769v3.pdf
เจลป์: การทำนายเชิงเส้นที่ตื่นเต้นสำหรับการสังเคราะห์คำพูดจาก mel-spectrogram
- https://arxiv.org/pdf/1904.03976V3.pdf
การสังเคราะห์คำพูดที่มีความซื่อสัตย์สูงด้วยเครือข่ายที่เป็นปฏิปักษ์: https://arxiv.org/abs/1909.11646
- gan-tts, การสังเคราะห์คำพูดแบบ end-to-end
- ใช้คุณสมบัติระยะเวลาและภาษาศาสตร์
- คุณลักษณะระยะเวลาและอะคูสติกถูกคาดการณ์โดยแบบจำลองเพิ่มเติม
- การแยกแยะหน้าต่างแบบสุ่ม: การบริโภคตัวอย่างเสียงทั้งหมด แต่เป็นหน้าต่างแบบสุ่ม
- RWD หลายตัว มีเงื่อนไขบางอย่างและไม่มีเงื่อนไขบางอย่าง (ปรับอากาศตามคุณสมบัติอินพุต)
- Punchline: ใช้หน้าต่างตัวอย่างแบบสุ่มที่มีขนาดหน้าต่างที่แตกต่างกันสำหรับ D.
- ผลลัพธ์ที่ใช้ร่วมกันเสียงเชิงกลที่แสดงขีด จำกัด ของคุณสมบัติอะคูสติกที่ไม่ใช่เส้นประสาท
Multi-band Melgan: https://arxiv.org/abs/2005.05106
- ใช้การสูญเสีย PWGAN แทนการสูญเสียการจับคู่คุณสมบัติ
- การใช้สนามที่เปิดกว้างขนาดใหญ่ช่วยเพิ่มประสิทธิภาพของโมเดลอย่างมีนัยสำคัญ
- เครื่องกำเนิดไฟฟ้า pretraining สำหรับ iters 200k
- การทำนายสัญญาณเสียงหลายวง ผลลัพธ์คือผลรวมของการทำนายวงดนตรีที่แตกต่างกัน 4 แบบด้วยตัวกรองการสังเคราะห์ PQMF
- รุ่น Multi-band มีพารามิเตอร์ 1.9m (ค่อนข้างเล็ก)
- อ้างว่าเร็วกว่า Melgan 7x
- ในชุดข้อมูลภาษาจีน: MOS 4.22
Waveglow: https://arxiv.org/abs/1811.00002
- โมเดลขนาดใหญ่มาก (พารามิเตอร์ 268m)
- ยากที่จะฝึกอบรมตั้งแต่บน GPU 12GB สามารถใช้ขนาดแบทช์ 1 เท่านั้น
- การอนุมานแบบเรียลไทม์เนื่องจากการใช้งาน Convolutions
- ขึ้นอยู่กับการไหลของการทำให้เป็นปกติแบบกลับด้าน (การสอนที่ยอดเยี่ยม https://blog.evjang.com/2018/01/nf1.html)
- โมเดลเรียนรู้และการแมปที่ได้รับการจับคู่ตัวอย่างเสียงไปยัง mel-spectrograms ด้วยการสูญเสียความน่าจะเป็นสูงสุด
- ในเครือข่ายการอนุมานทำงานในทิศทางย้อนกลับและให้ mel-specs ถูกแปลงเป็นตัวอย่างเสียง
- การฝึกอบรมได้ดำเนินการโดยใช้ 8 NVIDIA V100 พร้อม RAM 32GB ขนาดแบทช์ 24 (แพง)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, รหัส: https://github.com/tianrengao/squeezewave
- ~ 5-13x เร็วกว่าแบบเรียลไทม์
- Waveglow Redanduncies: ตัวอย่างเสียงยาว, upsamples mel-specs, ขนาดช่องขนาดใหญ่ในฟังก์ชัน WN
- แก้ไข: ตัวอย่างเสียงที่สั้นกว่า แต่สั้นกว่าเป็นอินพุต (l = 2000, c = 8 vs l = 64, c = 256)
- L = 64 ตรงกับความละเอียดของ Mel-Spec ดังนั้นจึงไม่จำเป็นต้องทำการสุ่มตัวอย่าง
- ใช้ความซับซ้อนที่ไม่สามารถแยกได้อย่างลึกซึ้งในโมดูล WN
- ใช้ convolution ปกติแทนที่จะขยายเนื่องจากตัวอย่างเสียงสั้นลง
- อย่าแยกเอาต์พุตโมดูลออกเป็นส่วนที่เหลือและเอาต์พุตเครือข่ายโดยสมมติว่าเวกเตอร์เหล่านี้เกือบจะเหมือนกัน
- การฝึกอบรมได้ดำเนินการโดยใช้ Titan RTX 24GB Batch Size 96 สำหรับการทำซ้ำ 600K
- MOS on LJSpeech: Waveglow - 4.57, Squeezewave (l = 128 C = 256) - 4.07 และ Squeezewave (L = 64 C = 256) - 3.77
- รุ่นที่เล็กที่สุดมีตัวอย่าง 21k ต่อวินาทีบน Raspi3
Wavegrad: https://arxiv.org/pdf/2009.00713.pdf
- มันขึ้นอยู่กับการแพร่กระจายความน่าจะเป็นและการเปลี่ยนแปลงของ Lagenvin
- แนวคิดพื้นฐานคือการเรียนรู้ฟังก์ชั่นที่แมปการกระจายที่รู้จักไปยังการกระจายข้อมูลเป้าหมายซ้ำ ๆ
- พวกเขารายงาน 0.2 ปัจจัยเรียลไทม์ใน GPU แต่ประสิทธิภาพของ CPU ไม่ได้ใช้ร่วมกัน
- ในรหัสตัวอย่างด้านล่างผู้เขียนรายงานว่าโมเดลมาบรรจบกันหลังจากการฝึกอบรม 2 วันใน GPU เดียว
- คะแนน MOS บนกระดาษนั้นไม่เพียงพอ แต่แสดงให้เห็นถึงประสิทธิภาพที่เทียบเท่ากับรุ่นที่รู้จักเช่น Wavernn และ Wavenet
รหัส: https://github.com/ivanvovk/wavegrad 
จากอินเทอร์เน็ต (บล็อกวิดีโอ ฯลฯ )
วิดีโอ
การอภิปรายกระดาษ
- Tacotron 2: https://www.youtube.com/watch?v=2iARXXM-V9W
การพูดคุย
- พูดคุยเกี่ยวกับการผลักดันพรมแดนของข้อความประสาทไปยังคำพูดโดย Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- พูดคุยเกี่ยวกับการสังเคราะห์ข้อความตามแบบจำลองการพูดแบบจำลองโดย Heiga Zen, 2017
- วิดีโอ: https://youtu.be/nsrsrytkkt8
- สไลด์: https://research.google.com/pubs/pub45882.html
- บทช่วยสอนเกี่ยวกับการสังเคราะห์ข้อความพารามิเตอร์เป็นภาษากับการพูดที่ ISCA ODYESSY 2020 โดย Xin Wang, 2020
- วิดีโอ: https://youtu.be/wce7sycdzai
- สไลด์: http://tonywangx.github.io/slide.html#dec-2020
- หลักสูตรการประมวลผลคำพูดของ ISCA เกี่ยวกับ Neural Vocoders, 2022
- องค์ประกอบพื้นฐานของนักร้องประสาท: https://youtu.be/m833q5i-zys
- แบบจำลองการกำเนิดแบบลึกสำหรับการบีบอัดการพูด (LPCNET): https://youtu.be/7ksnfx3plgw
- Neural Auto-Regressive, Source-Filter และ Glottal Vocoders: https://youtu.be/gprmxdberx0
- สไลด์: http://tonywangx.github.io/slide.html#jul-2020
- การสังเคราะห์คำพูดจากการถอดรหัสประสาทของประโยคพูด | AISC: https://www.youtube.com/watch?v=MNDTMDPMNMO
- การสังเคราะห์ text-to-speech generative: https://www.youtube.com/watch?v=J4MVEANKING
- การสังเคราะห์คำพูดสำหรับอุตสาหกรรมเกม: https://www.youtube.com/watch?v=aohaye4a-2q
ทั่วไป
- รีวิวระบบข้อความที่ทันสมัยถึงพูด: https://www.youtube.com/watch?v=8RXLSC-ZCRY
สมุดบันทึก Jupyter
- บทช่วยสอนเกี่ยวกับนักร้องประสาทที่เลือก: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
บล็อก
- Text to Speech สถาปัตยกรรมการเรียนรู้ลึก: http://www.erogol.com/text-speech-deep-learning-architectures/


