(N'hésitez pas à suggérer des changements)
Papiers
- Fusion des représentations phonèques et char: https://arxiv.org/pdf/1811.07240.pdf
- Tacotron Transfer Learning: https://arxiv.org/pdf/1904.06508.pdf
- Phonème timing de l'attention: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Formation semi-supervisée pour améliorer l'efficacité des données dans la synthèse de la parole de bout à fin - https://arxiv.org/pdf/1808.10128.pdf
- Écoute pendant la parole: chaîne de discours par Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Perte de fin à la fin de la fin à la vérification du haut-parleur: https://arxiv.org/pdf/1710.10467.pdf
- ES-Tacotron2: Tacotron multi-task 2 avec réseau estimé pré-entraîné pour réduire le problème exagéré: https://www.mdpi.com/2078-2489/10/4/131/pdf
- FastSpeech: https://arxiv.org/pdf/1905.09263.pdf
- Apprendre le chant de la parole: https://arxiv.org/pdf/1912.10128.pdf
- Tts -gan: https://arxiv.org/pdf/1909.11646.pdf
- Ils utilisent la durée et les caractéristiques linguistiques pour EN2EN TTS.
- Près des performances de Wavenet.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Tacotron conscient de la durée
- Melnet: https://arxiv.org/abs/1906.01083
- AlignTTS: https://arxiv.org/pdf/2003.01950.pdf
- Décomposition de la parole non supervisée via un goulot d'étranglement à triple information
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Flux autorégresif inverse sur le tacotron comme l'architecture
- Glugure d'onde comme vocodeur.
- Incorporation de style de la parole avec mélange de modèle gaussien.
- Le modèle est grand et plus propre que le tacotron à la vanille
- Les valeurs MOS sont largement meilleures que la mise en œuvre du tacotron public.
- Système de texte à dispection efficacement formable basé sur des réseaux de convolution profonde avec une attention guidée: https://arxiv.org/pdf/1710.08969.pdf
Résuménomètres expansifs
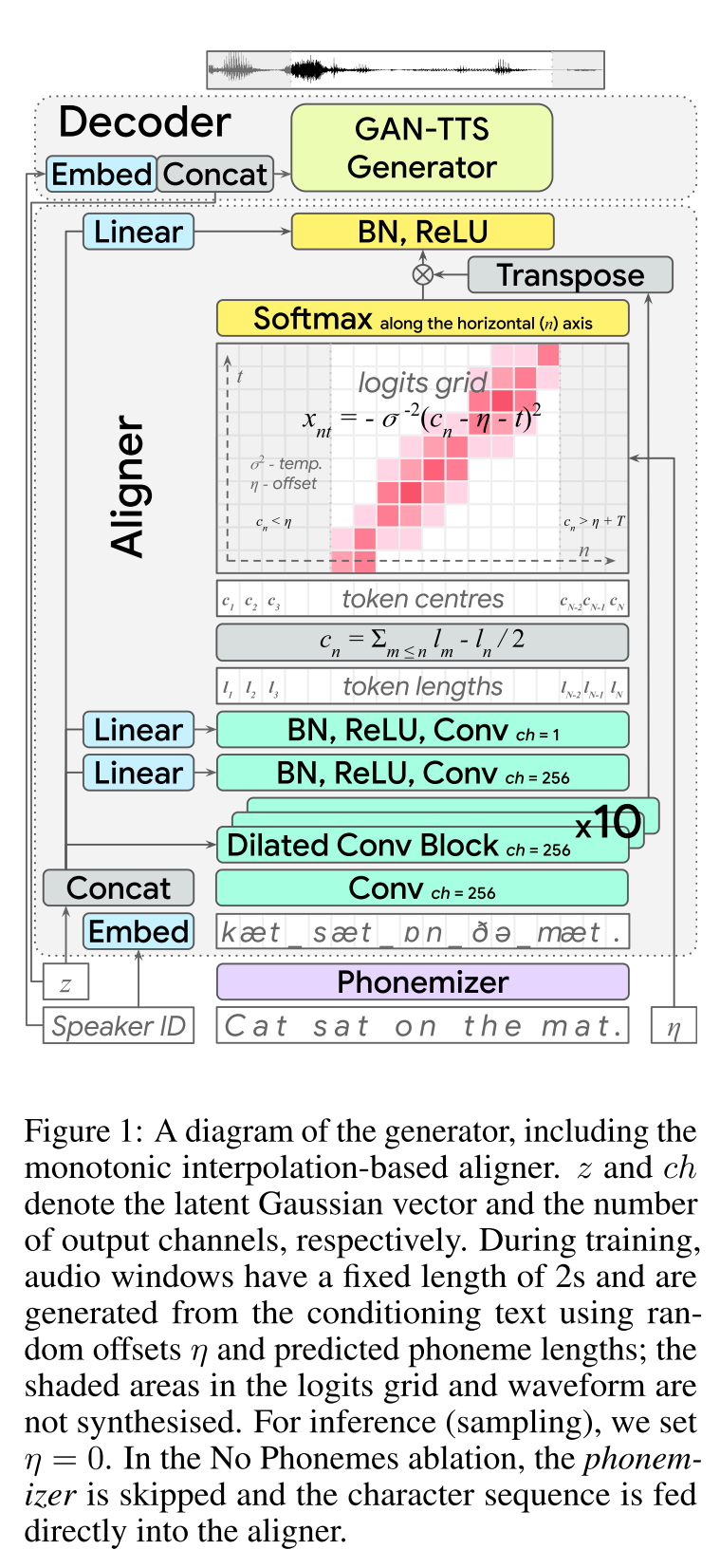
Text-to-to-speech adversaire de bout en bout: http://arxiv.org/abs/2006.03575 (cliquez pour développer)
- End2end Feed-Forward TTS Learning.
- L'alignement des caractères a été effectué avec un module d'aligneur séparé.
- L'aligneur prédit la longueur de chaque caractère. - L'emplacement central d'un char se trouve Wrt la longueur totale des caractères précédents. - Les positions de char sont interpolées avec une fenêtre gaussienne wrt la longueur audio réelle.
- La sortie audio est calculée dans le domaine MU-LAW. (Je n'ai pas de raisonnement pour ça)
- Utilisez seulement 2 fenêtres audio SEC pour le transfert.
- Le générateur GAN-TTS est utilisé pour produire un signal audio.
- RWD est utilisé comme discriminateur de niveau audio.
- MELD: Ils utilisent une architecture en profondeur comme discriminatrice de niveau de spectrogramme repaçant le problème comme reconstruction de l'image.
- Perte de spectrogramme
- Utiliser uniquement l'alimentation contradictoire ne suffit pas pour apprendre les alignements de char. Ils utilisent une perte de spectrogramme B / W Spectrogrammes prédits et des spécifications de vérité au sol.
- Notez que le modèle prédit des signaux audio. Les spectrogrammes ci-dessus sont calculés à partir de l'audio généré.
- Enveloppant du temps dynamique est utilisé pour calculer un alignement minimal à coût b / b les spectrogrammes générés et la vérification du sol.
- Il s'agit d'une approche de programmation dynamique pour trouver un alignement à coût minimal.
- La perte de longueur d'aligneur est utilisée pour pénaliser l'aligneur pour prédire différent de la longueur audio réelle.
- Ils forment le modèle avec un ensemble de données multi-enceintes mais rapportent les résultats sur le haut-parleur le plus performant.
- Étude d'ablation Importance de chaque composant: (Longloss et spectrogramloss)> RWD> MELD> Phonèmes> MultippeakerDataset.
- Mes 2 cents: il s'agit d'un modèle en avant qui fournit une synthèse de la parole END-2 sans avoir besoin de former un modèle de vocodeur séparé. Cependant, c'est un modèle très compliqué avec beaucoup d'hyperparamètres et les détails de la mise en œuvre. Le résultat final n'est pas non plus proche de l'état de l'art. Je pense que nous devons trouver des algorithmes spécifiques pour l'apprentissage des alignements de caractère qui réduiraient le besoin de régler une combinaison de différents algorithmes.
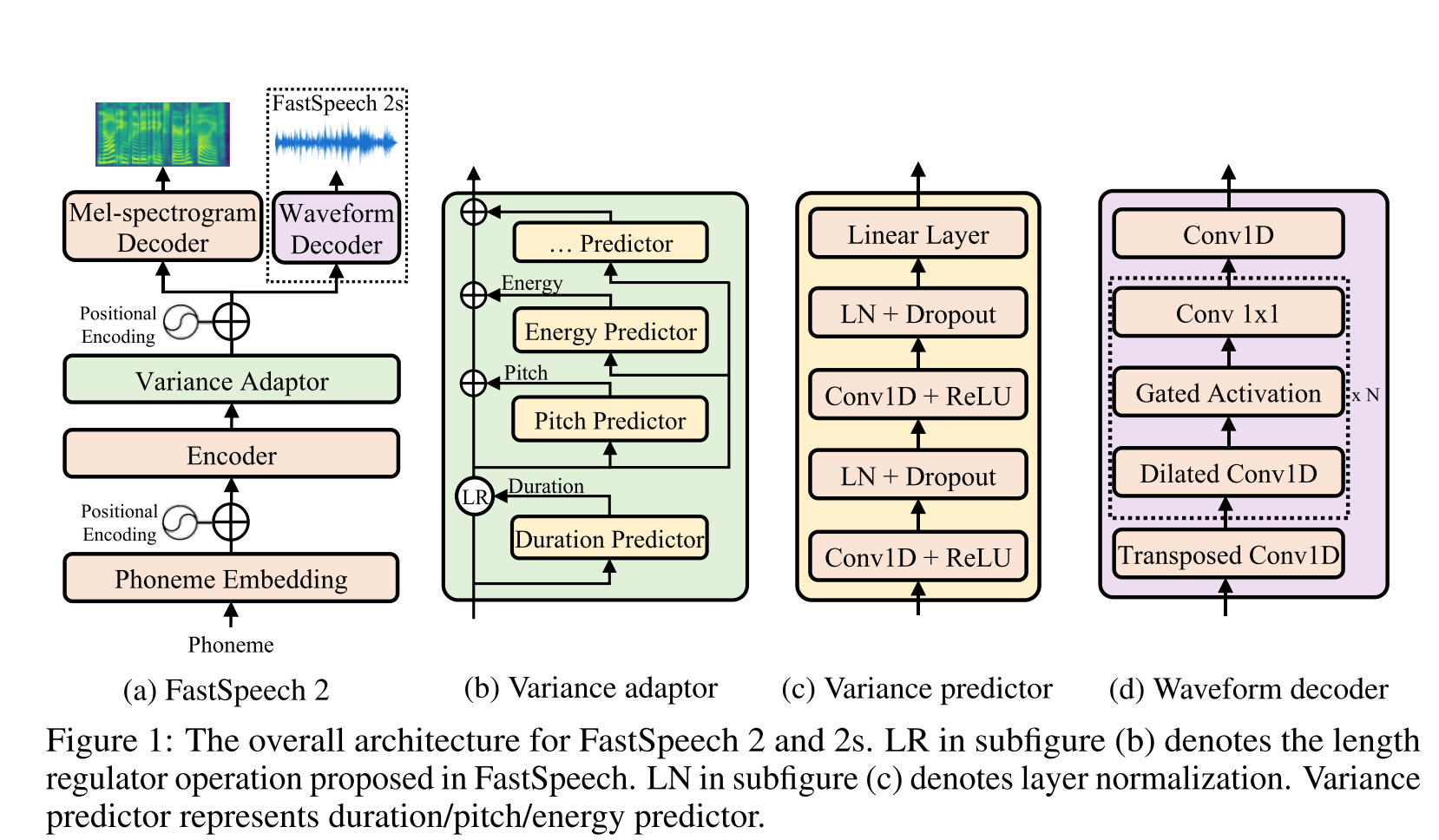
Fast Speech2: http://arxiv.org/abs/2006.04558 (cliquez pour développer)
- Utilisez des durées de phonème générées par le MFA comme étiquettes pour former un régulateur de longueur.
- Les normes de spectrogramme du niveau de trame F0 et L2 (informations de L2) sont en tant que fonctionnalités supplémentaires.
- Le module de prédicteur de variance prédit les informations de variance au moment de l'inférence.
- ABLATION Étude Améliorations des résultats: Modèle <
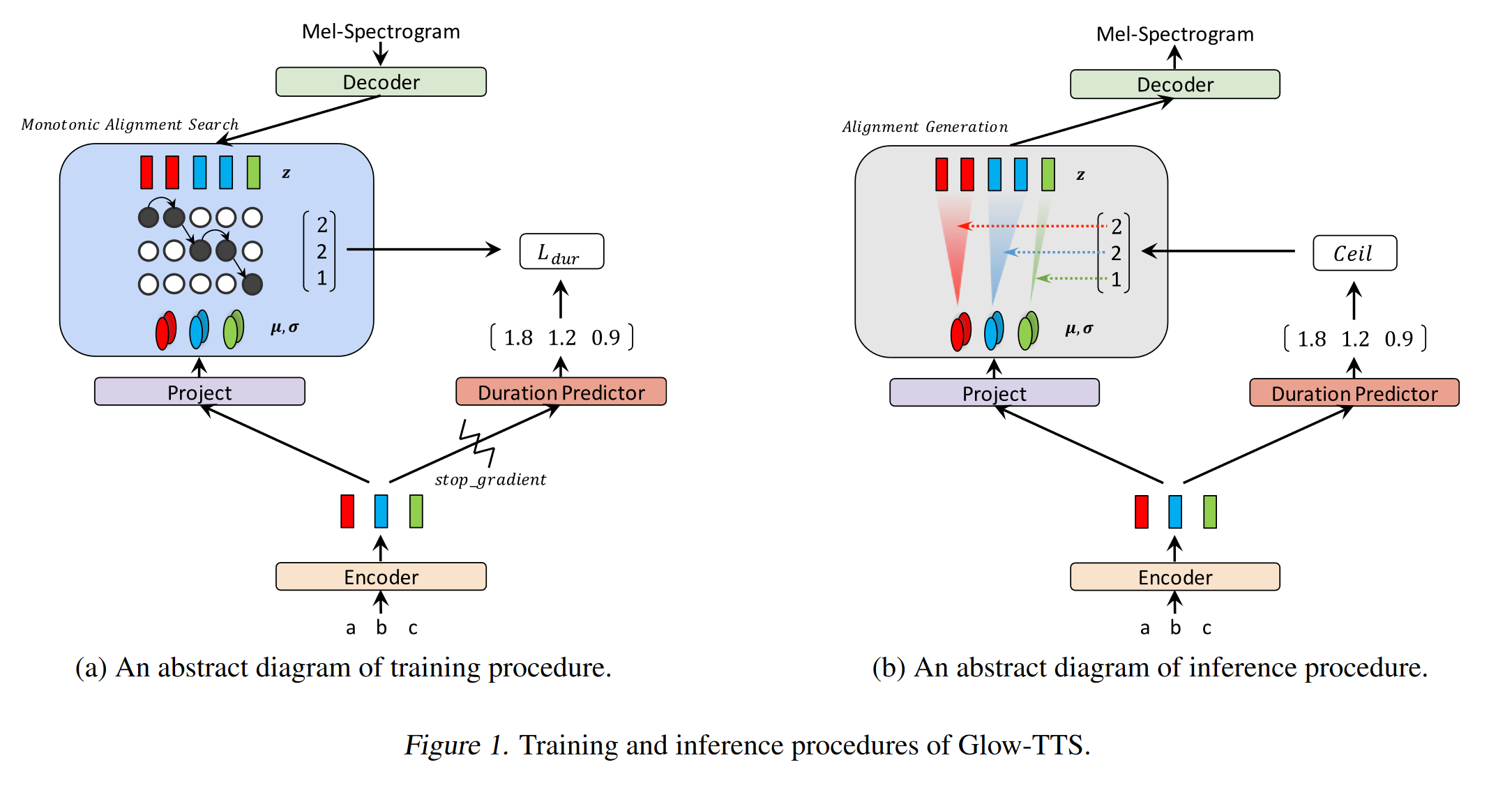
GLOW-TTS: https://arxiv.org/pdf/2005.11129.pdf (cliquez pour développer)
- Utilisez la recherche d'alignement monotone pour apprendre le texte et le spectrogramme d'alignement b / w
- Cet alignement est utilisé pour former un prédicteur de durée à utiliser à l'inférence.
- L'encodeur mappe chaque caractère à une distribution gaussienne.
- Le décodeur mappe chaque trame de spectrogramme à un vecteur latent en utilisant le flux de normalisation (couches de lueur)
- Les sorties de l'encodeur et du décodeur sont alignées avec le MAS.
- À chaque itération d'abord, l'alignement le plus probable est trouvé par MAS et cet alignement est utilisé pour mettre à jour les paramètres du mode.
- Un prédicteur de durée est formé pour prédire le nombre de trames de spectrogramme pour chaque caractère.
- À l'inférence, seul le prédicteur de durée est utilisé à la place du MAS
- Encodeur a l'architecture du transformateur TTS avec 2 mises à jour
- Au lieu d'un codage positionnel absolu, ils utilisent un codage positionnel immobilier.
- Ils utilisent également une connexion résiduelle pour le prénet de l'encodeur.
- Le décodeur a la même architecture que le modèle Glow.
- Ils forment à la fois un modèle unique et multi-haut-parleurs.
- Il est montré expérimentalement, Glow-TTS est plus robuste contre les phrases longues par rapport au Tacotron2 d'origine
- 15x plus vite que le tacotron2 à l'inférence
- Mes 2 cents: leurs échantillons ne semblent pas aussi naturels que le tacotron. Je crois que les modèles d'attention normaux génèrent toujours plus de discours naturels car l'attention apprend à cartographier directement les caractères pour modéliser les sorties. Cependant, l'utilisation de Glow-TTS pourrait être une bonne alternative pour les ensembles de données difficiles.
- Échantillons: https://github.com/jaywalnut310/glow-tts
- Référentiel: https://github.com/jaywalnut310/glow-tts
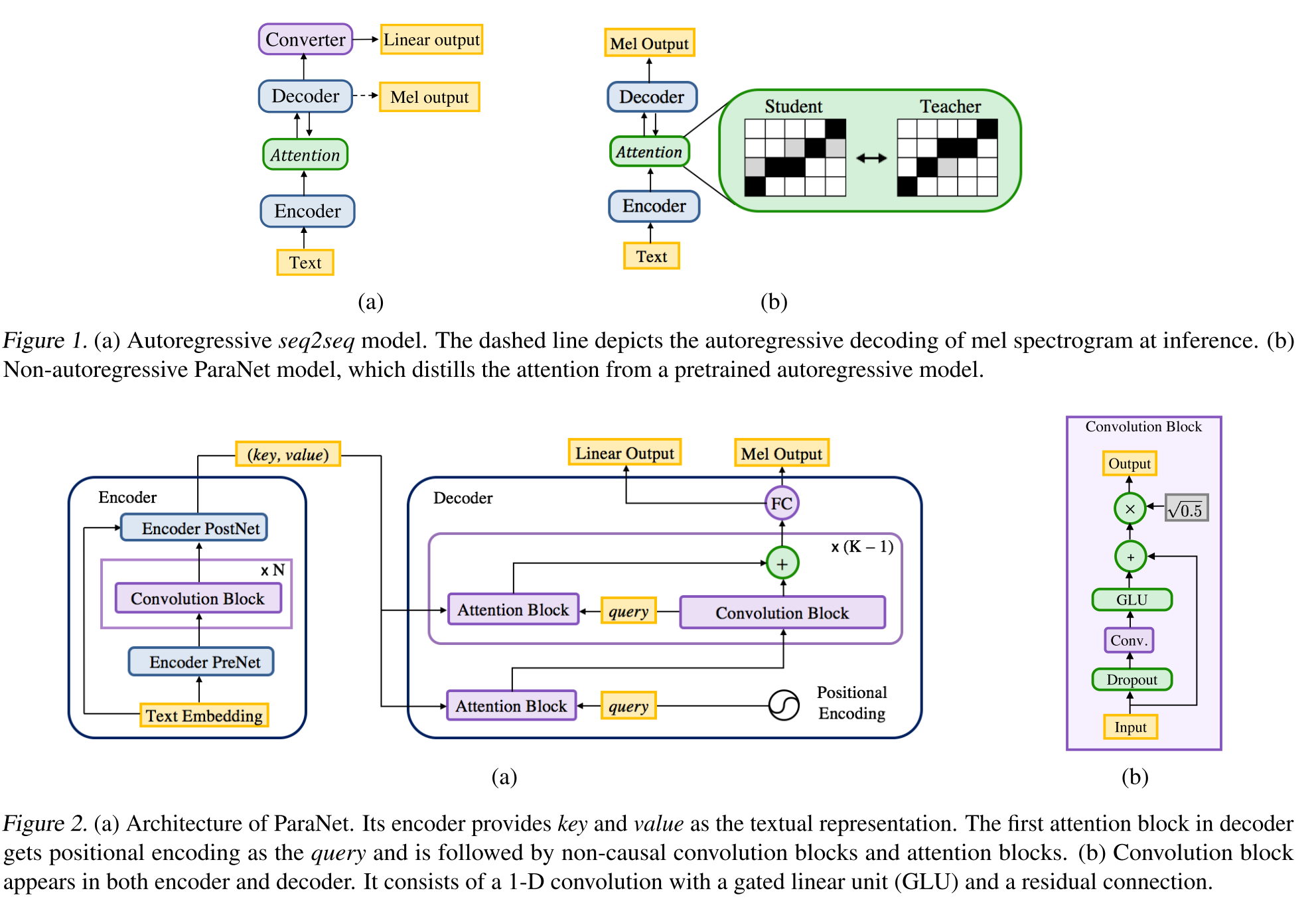
Text-to-to-to-to-to-to-to-to-to-to-to-to-to-to-speech: http://arxiv.org/abs/1905.08459 (cliquez pour développer)
- Une dérivation du modèle de voix profonde 3 utilisant des couches convolutionnelles non causales.
- Paradigme enseignant-élève pour former un élève annonce-autorégressif avec de multiples blocs d'attention d'un modèle de professeur autorégressif.
- L'enseignant est utilisé pour générer des alignements de texte à spectrogramme à utiliser par le modèle étudiant.
- Le modèle est formé avec deux fonctions de perte pour l'alignement de l'attention et la génération de spectrogramme.
- Les blocs d'attention multi-attention affinent la couche d'alignement d'attention par couche.
- L'élève utilise l'attention du produit de points avec des vecteurs de requête, de clé et de valeur. La requête n'est que des vecteurs de codage posititinal. La clé et la valeur sont les sorties de l'encodeur.
- Le modèle proposé est fortement lié au codage positionnel qui repose également sur différentes valeurs constantes.
Cohérence à double décodeur: https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder-consonistance (cliquez pour développer)
- Le modèle utilise une architecture de type tacotron mais avec 2 décodeurs et un postnet.
- DDC utilise deux décodeurs synchrones en utilisant différents taux de réduction.
- Les décodeurs utilisent différents taux de réduction, ils calculent donc les sorties dans différentes granularités et apprennent différents aspects des données d'entrée.
- Le modèle utilise la cohérence entre ces deux décodeurs pour augmenter la robustesse de l'alignement du texte à spectrogramme appris.
- Le modèle applique également un raffinement à la sortie du décodeur final en appliquant le postnet de manière itérative plusieurs fois.
- DDC utilise la normalisation par lots dans le module prénet et abandonne les couches d'abandon.
- DDC utilise une formation progressive pour réduire le temps de formation total.
- Nous utilisons un générateur de melgan multi-bandes comme vocodeur formé avec plusieurs discriminateurs de fenêtres aléatoires différemment de l'œuvre originale.
- Nous sommes en mesure de former un modèle DDC uniquement en 2 jours avec un seul GPU et le modèle final est capable de générer plus rapidement que le discours en temps réel sur un CPU. Page de démonstration: https://erogol.github.io/ddc-samples/ Code: https://github.com/mozilla/tts
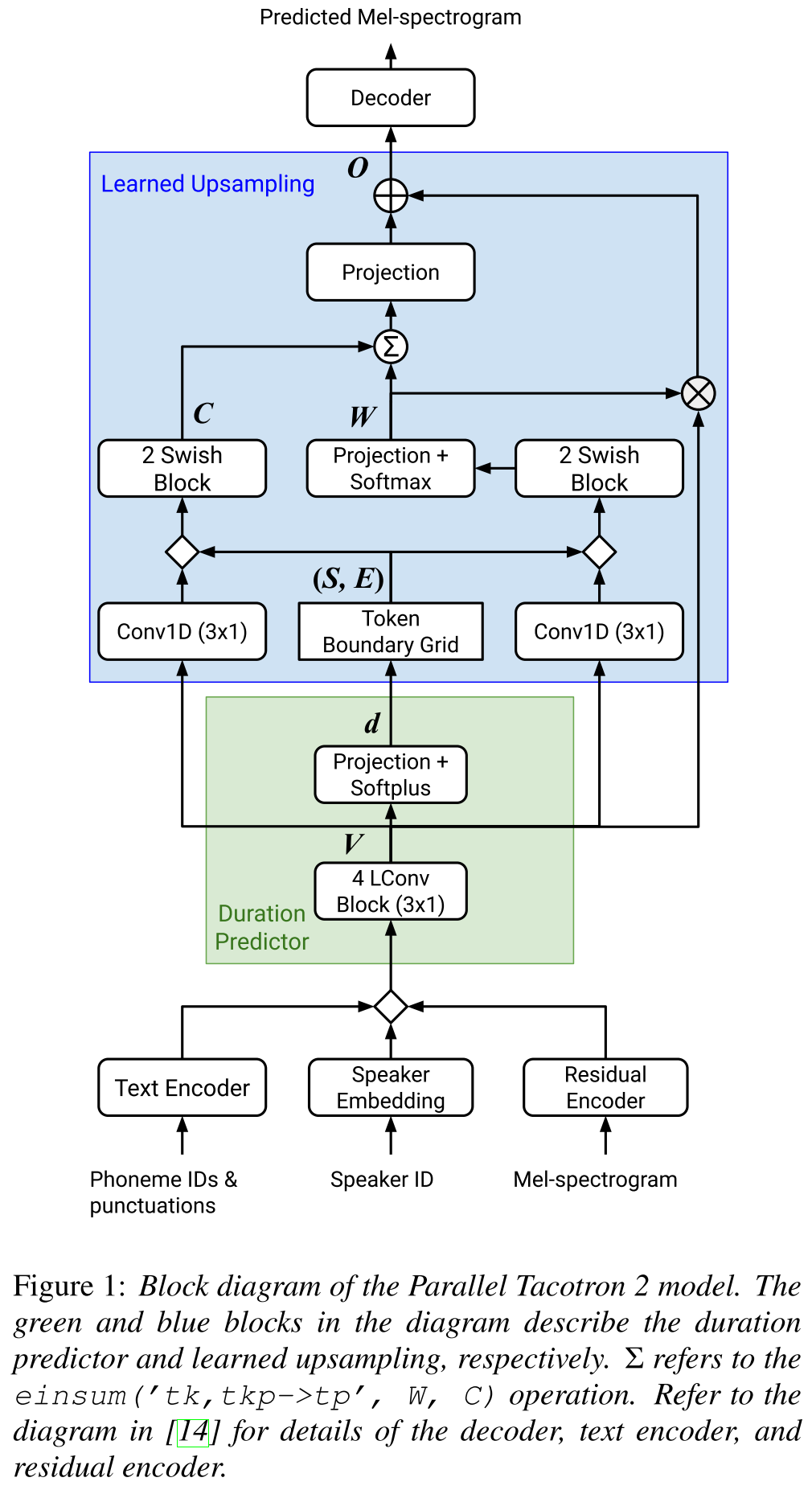
Tacotron parallèle2: http://arxiv.org/abs/2103.14574 (cliquez pour développer)
- Ne nécessite pas d'informations de durée externe.
- Résout les problèmes d'alignement entre les spectrogrammes réels et au sol par perte de soft-DTW.
- Les durées prévues sont converties en alignement par une fonction de conversion apprise, plutôt que par un régulateur de longueur, pour résoudre les problèmes d'arrondi.
- Apprend une carte d'attention sur les "grilles limites de jeton" qui sont calculées à partir de durées prévues.
- Le décodeur est construit sur des blocs de 6 "convolutions de poids légère".
- Un VAE est utilisé pour projeter des spectrogrammes d'entrée sur des caractéristiques latentes et fusionner avec les incorporations de caractères comme entrée au réseau.
- Soft-DTW est à forte intensité de calcul car il calcule la différence par paire pour toutes les trames de spectrogramme. Ils l'ont contrecrément avec une certaine fenêtre diagonale pour réduire les frais généraux.
- L'objectif de durée finale est la somme de la perte de durée, de la perte de Vae et de la perte de spectrogramme.
- Ils n'utilisent que des ensembles de données propriétaires pour les expériences ?.
- Atteint le même MOS avec le modèle Tacotron2 et surpasse le paralltacotron.
- Page de démonstration : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Code : pas de code jusqu'à présent
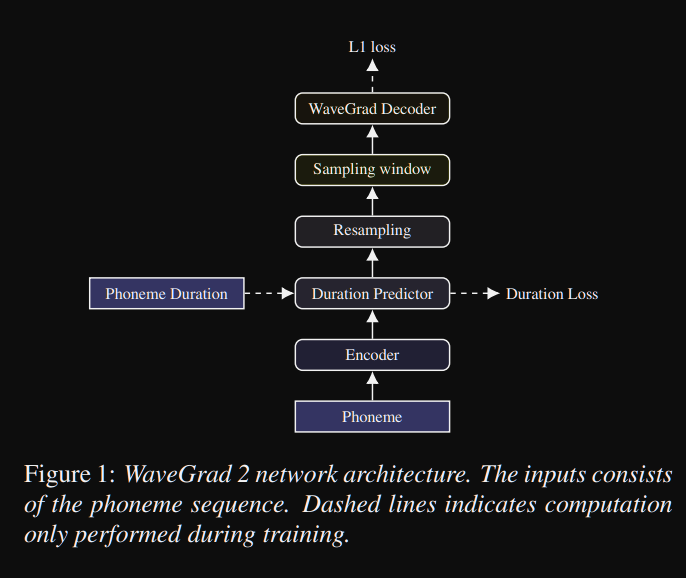
Wavegrad2: https://arxiv.org/pdf/2106.09660.pdf (cliquez pour développer)
- Il calcule la forme d'onde brute directement à partir d'une séquence de phonèmes.
- Un modèle d'encodeur de type Tacotron2 est utilisé pour calculer une représentation cachée des phonèmes.
- Prédicteur de tacotron non avantageux comme la durée douce pour aligner la représentation cachée avec la sortie.
- Ils élargissent la représentation cachée avec les durées prévues et échantillonnent une certaine fenêtre pour se convertir en forme d'onde.
- Ils ont exploré différentes tailles de fenêtre Netween 64 et 256 images correspondant à 0,8 et 3,2 secondes de discours. Ils ont constaté que le plus grand est le meilleur.
- Page de démonstration : rien jusqu'à présent
- Code : pas de code jusqu'à présent
Papiers multi-haut-parleurs
- Formation Systèmes de texte à vocation neuronaux multi-ordres à l'aide de sociétés de discours de haut-parleur - https://arxiv.org/abs/1904.00771
- Vocation profonde 2 - https://papers.nips.cc/paper/6889-deep-voice-2-Multi-Speaker-neural-Text-to-Speech.pdf
- Exemple de tts adaptatifs efficaces - https://openreview.net/pdf?id=rkzJuoacfx
- WAVENET + SPELER PROCHE D'INSCRIPTION
- Loop vocal - https://arxiv.org/abs/1707.06588
- Modélisation de l'espace latent multi-haut-parleurs pour améliorer les TTs neuronaux à inscrire rapidement un nouvel haut-parleur et à améliorer la voix premium - https://arxiv.org/pdf/1812.05253.pdf
- Transférer l'apprentissage de la vérification des conférenciers à la synthèse de texte à la parole multippeaker - https://arxiv.org/pdf/1806.04558.pdf
- Ajuster les nouveaux haut-parleurs basés sur un court échantillon non transcrit - https://arxiv.org/pdf/1802.06984.pdf
- Perte généralisée de fin à fin pour la vérification des conférenciers - https://arxiv.org/abs/1710.10467
Résuménomètres expansifs
Apprentissage semi-supervisé pour la synthèse de texte à la carte à la parole multipleur utilisant une représentation de la parole discrète: http://arxiv.org/abs/2005.08024
- Former un modèle TTS multi-haut-parleurs avec seulement une heure de données appariés (alignement de texte à la voix) et des données plus non appariées (seulement Voide).
- Il apprend un livre de code avec chaque mot de code correspond à un seul phonème.
- Le livre de code est aligné sur les phonèmes à l'aide des données appariées et de l'algorithme CTC.
- Ce livre de code fonctionne comme un proxy pour estimer implicitement la séquence de phonèmes des données non appariées.
- Ils empilent le modèle Tacotron2 en haut pour effectuer des TTS en utilisant les intégres de mot de code générés par la partie initiale du modèle.
- Ils ont battu les méthodes de référence dans un paramètre de données apparié de 1 heure.
- Ils ne signalent pas les résultats complets de données appariées.
- Ils n'ont pas une bonne étude d'ablation qui pourrait être intéressant de voir comment différentes parties du modèle contribuent à la performance.
- Ils utilisent Griffin-LIM comme vocodeur, il y a donc un espace pour l'amélioration.
Page de démonstration: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
Code: https://github.com/ttaoretw/semi-tts 
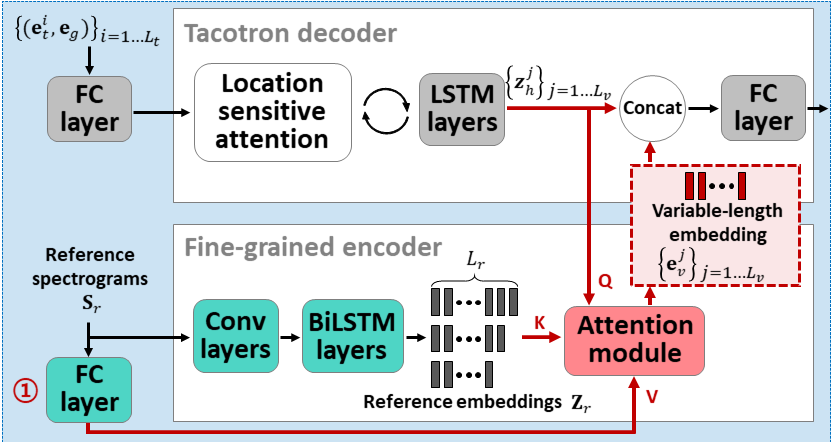
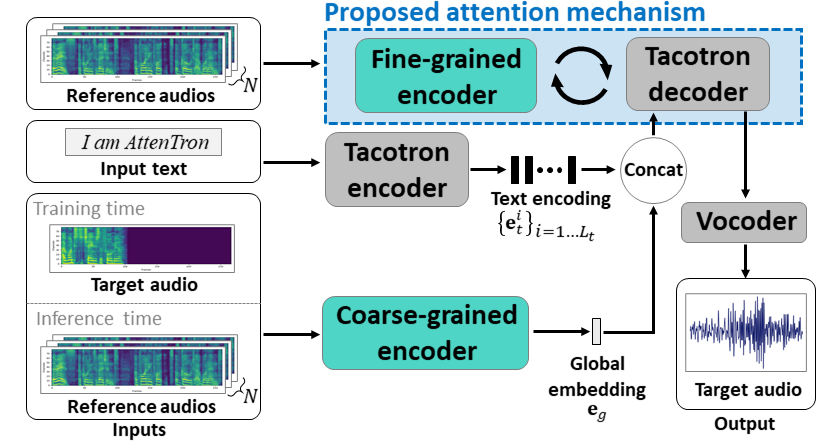
ATTENTRON: Texte-to-speech à quelques coups exploitant la longueur variable basée sur l'attention intégration: https://arxiv.org/abs/2005.08484
- Utilisez deux encodeurs pour apprendre les fonctionnalités dépendantes du haut-parleur.
- L'encodeur grossier apprend un haut-parleur global d'intégration de vecteur basé sur des spectrogrammes de référence fournis.
- Fine Encodeur apprend une longueur variable incorporant la dimension temporelle en coopération avec un module d'attention.
- L'attention sélectionne des cadres de spectrogramme de référence importants pour synthétiser la parole cible.
- Pré-entraînant le modèle avec un seul ensemble de données de haut-parleur (LJSpeech pour 30k iTERS.)
- Affinez le modèle avec un ensemble de données multi-haut-parleurs. (Vctk pour 70k iters.)
- Il réalise des métriques légèrement meilleures par rapport à l'utilisation des vecteurs X à partir du modèle de classification des haut-parleurs et de l'encodeur audio de référence basé sur VAE.
Page de démonstration: https://hyperconnect.github.io/Atventron/
Vers le texte universel à la dissection: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
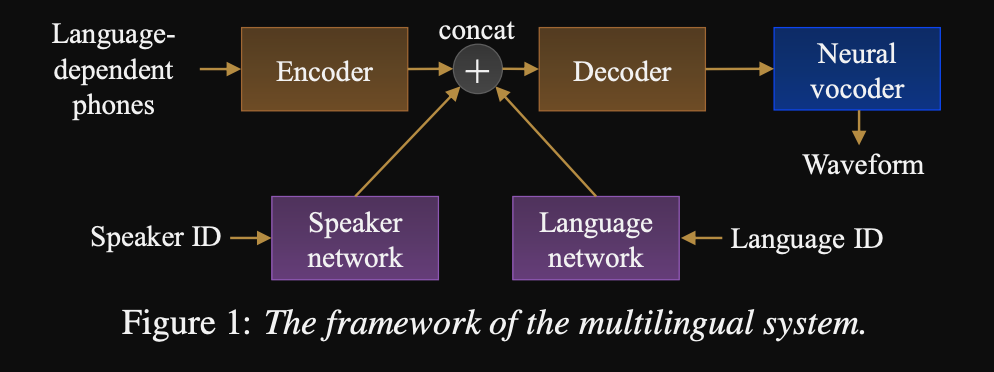
- Un cadre pour une séquence pour séquencer les TTS multilingues
- Le modèle est formé avec un très grand ensemble de données très déséquilibré.
- Le modèle est capable d'apprendre une nouvelle langue avec 6 minutes et un nouveau haut-parleur avec 20 secondes de données après la formation initiale.
- L'architecture du modèle est un réseau d'encodeur encodeur basé sur un transformateur avec un réseau de haut-parleurs et un réseau linguistique pour le conditinonage du haut-parleur et de la langue. Les sorties de ces réseaux sont concaténées à la sortie de l'encodeur.
- Les réseaux de conditionnement prennent un vecteur à un hot représentant le haut-parleur ou l'identification de la langue et le projette dans une représentation de conditionnement.
- Ils utilisent un vocodeur WAVENET pour convertir les spectrogrammes de MEL prédits en sortie de forme d'onde.
- Ils utilisent des entrées de phonèmes dépendants du langage qui ne sont pas partagés entre les langues.
- Ils échantillonnent chaque lot en fonction de la fréquence inverse de chaque langue dans l'ensemble de données. Ainsi, chaque lot de formation a une distribution uniforme sur les langues, atténuant le déséquilibre des langues dans l'ensemble de données de formation.
- Pour apprendre de nouveaux haut-parleurs / langues, ils affinent le modèle d'encodeur avec les réseaux de conditionnement. Ils ne forment pas le modèle Wavenet.
- Ils utilisent des enregistrements professionnels de 1250 heures de 50 langues pour la formation.
- Ils utilisent le taux d'échantillonnage de 16 kHz pour tous les échantillons audio et coupent les silences au début et la fin de chaque clip.
- Ils utilisent 4 GPU V100 pour la formation, mais ils ne mentionnent pas combien de temps ils ont formé le modèle.
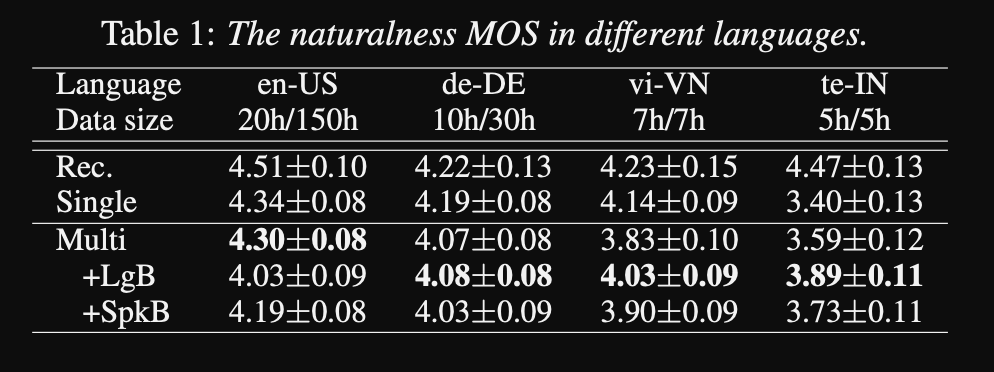
- Les résultats montrent que les modèles de haut-parleurs uniques sont meilleurs que l'approche proposée dans la métrique MOS.
- L'utilisation de réseaux de conditionnement est également important pour les langages à longue queue dans l'ensemble de données car ils améliorent la métrique MOS pour eux, mais altérez les performances des langues à haute ressource.
- Lorsqu'ils ajoutent un nouveau haut-parleur, ils observent que l'utilisation de plus de 5 minutes de données dégrade les performances du modèle. Ils affirment que, comme ces enregistrements ne sont pas aussi propres que les enregistrements originaux, l'utilisation de plus en plus affecte les performances générales du modèle.
- Le modèle multilingue est capable de s'entraîner avec seulement 6 minutes de données pour les nouveaux haut-parleurs et les langues tandis qu'un modèle de haut-parleur unique nécessite 3 heures pour s'entraîner et ne peut même pas atteindre des valeurs MOS similaires à celles du modèle multilingue de 6 minutes.
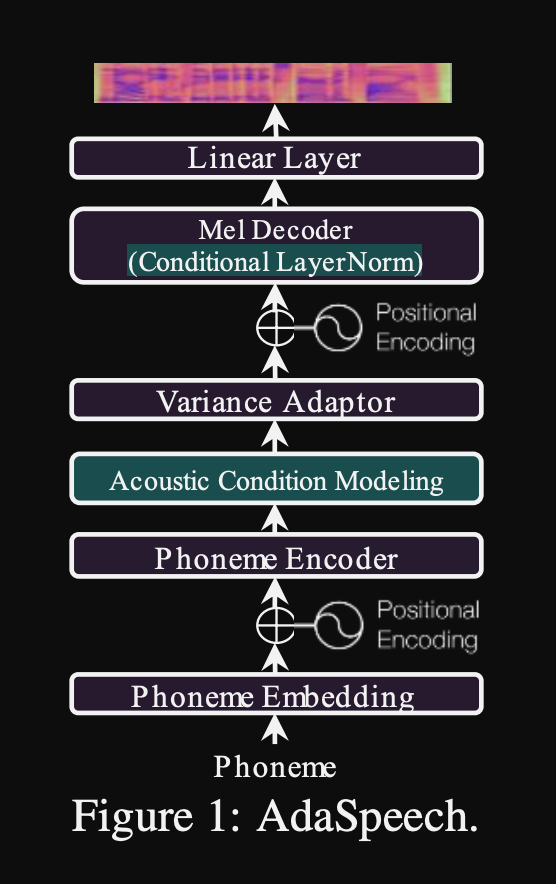
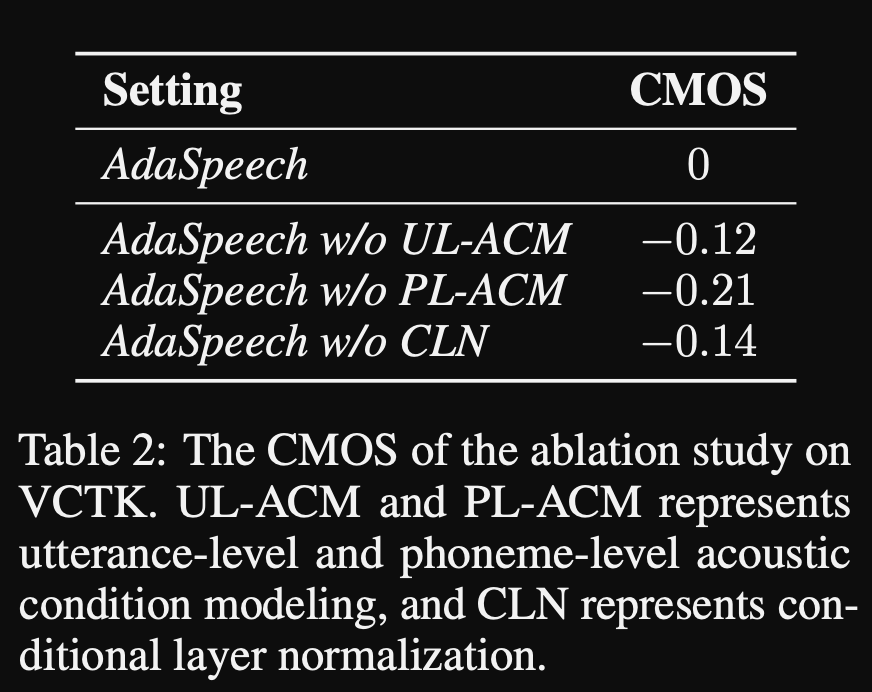
Adaspeech: Texte adaptatif à la parole pour la voix personnalisée: https://openreview.net/pdf?id=drynvt7gg4l
- Ils ont proposé un système qui peut s'adapter à différentes propriétés acoustiques d'entrée des utilisateurs et il utilise un nombre minimum de paramètres pour y parvenir.
- L'architecture principale est basée sur le modèle FastSpeech2 qui utilise des prédicteurs de hauteur et de variance pour apprendre les granularités les plus fines de la parole d'entrée.
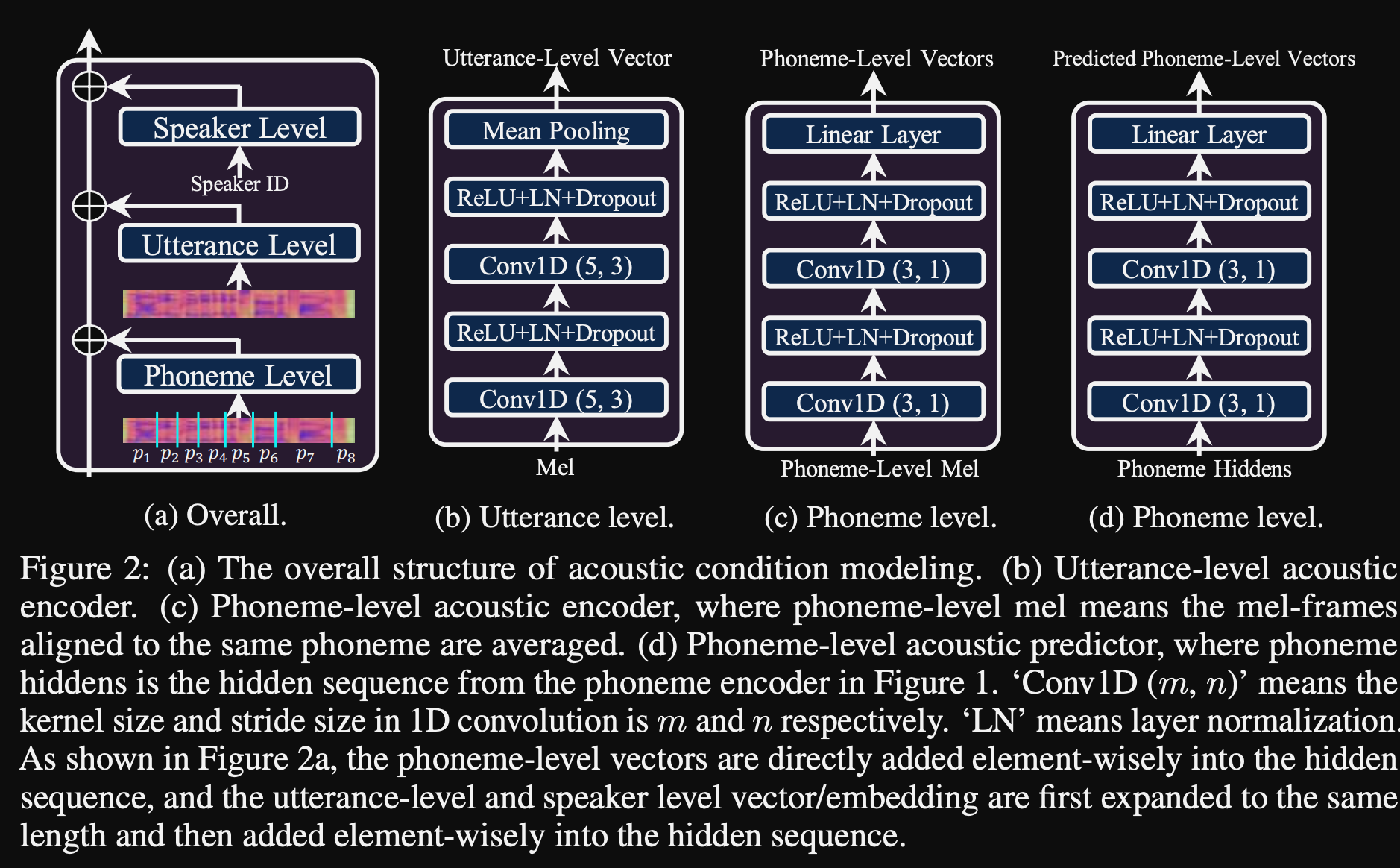
- Ils utilisent 3 réseaux de conditionnement supplémentaires.
- Niveau d'énoncé. Il faut du spectrogramme MEL de la parole de référence comme entrée.
- Niveau de phonème. Il prend des spectrogrammes de MEL au niveau du phonème comme entrée et calcule les vecteurs de conditionnement au niveau du phonème. Les spectrogrammes de MEL au niveau du phonème sont calculés en prenant le cadre du spectrogramme moyen dans la durée de chaque phonème.
- PHONEME NIVEAU 2. Il prend des sorties de codeur de phonème comme entrées. Cela diffère du réseau ci-dessus en utilisant simplement les informations de phonème sans voir les spectrogrammes.
- Tous ces réseaux de conditionnement et le back-os FastSpeech2 utilisent les couches de normalisation des calques.
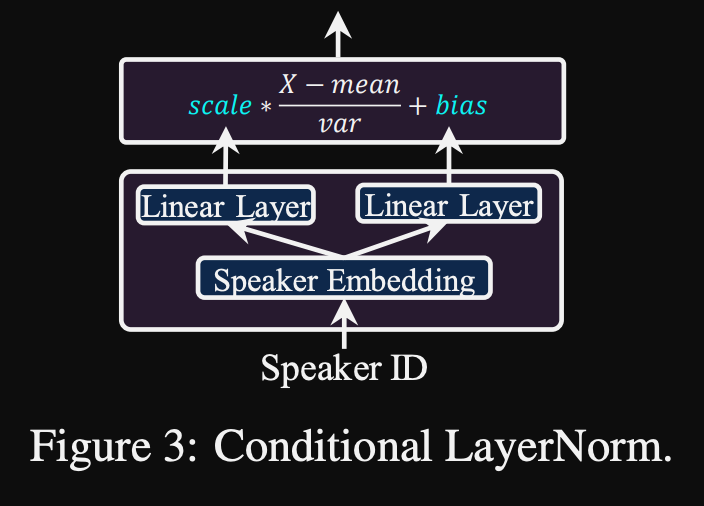
- Normalisation de la couche conditionnelle. Ils ne proposent que les paramètres d'échelle et de biais de l'échelle de chaque couche de normalisation de la couche lorsque le modèle est affiné pour un nouveau haut-parleur. Ils forment un module de conditionnement des haut-parleurs pour chaque couche de norme de couche qui publie une échelle et des valeurs de biais. (Ils utilisent un module de conditionnement de haut-parleur par bloc de transformateur.)
- Cela signifie que vous ne stockez que le module de conditionnement du haut-parleur pour chaque nouveau haut-parleur et prédisez les valeurs d'échelle et de biais à l'inférence lorsque vous gardez le reste du modèle.
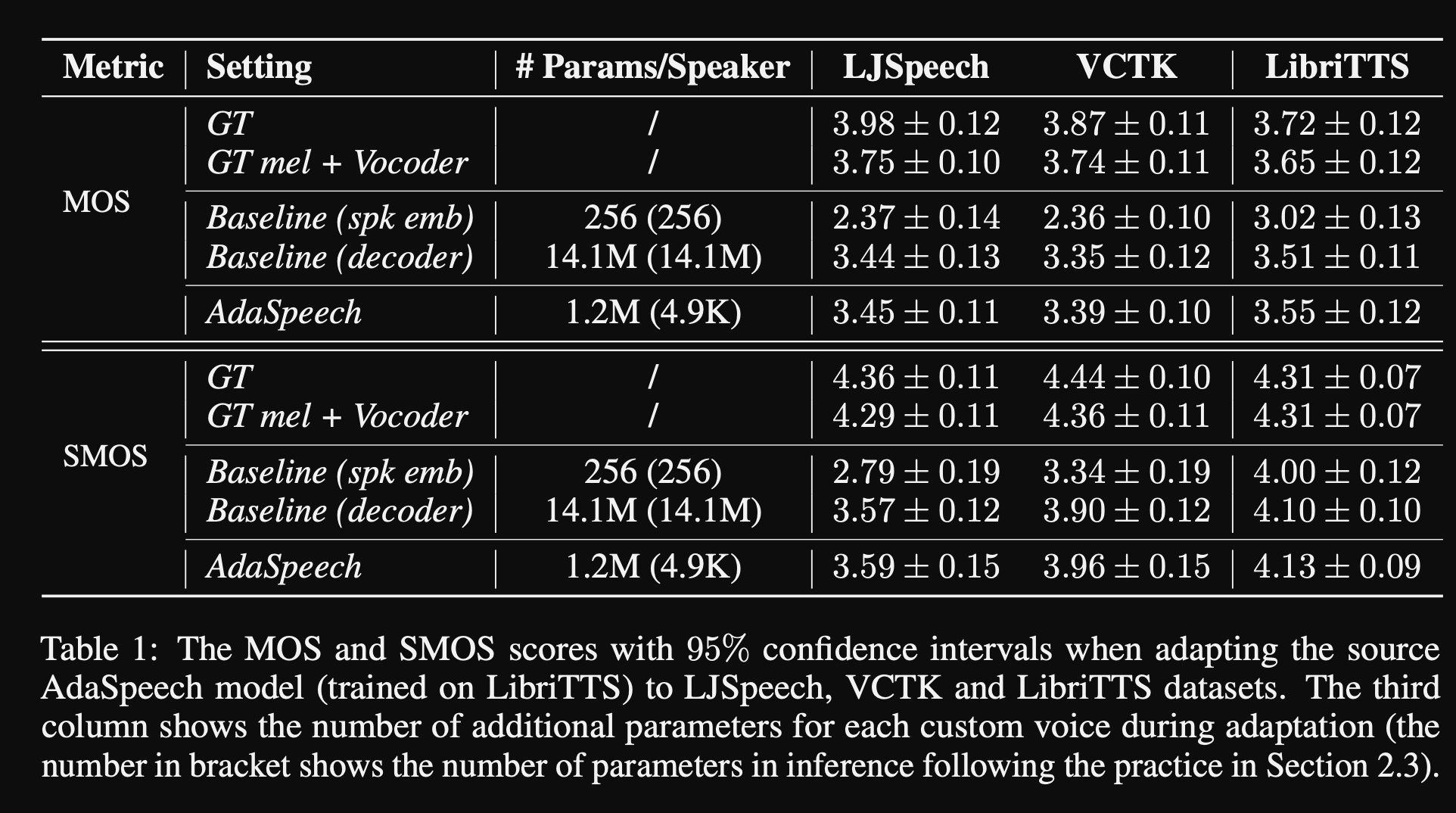
- Dans les expériences, ils forment avant la formation du modèle sur les libritts et affinez-le avec VCTK et LJSpeech
- Les résultats montrent que l'utilisation de la normalisation de la couche conditionnelle atteint mieux que leurs 2 lignes de base qui utilisent uniquement la mise en œuvre du haut-parleur et le réseau de décodeur.
- Leur étude d'ablation montre que la partie la plus importante du modèle est le réseau de «niveau de phonème» suivi d'une normalisation conditionnelle de la couche et d'un réseau de «niveau d'énoncé» dans un ordre.
- L'un important côté de l'article est qu'il n'y a presque aucune comparaison avec la littérature et que les résultats sont plus difficiles à évaluer objectivement.
Page de démonstration: https://speechresearch.github.io/adaspheech/

Attention
- Mécanismes d'attention relatives à l'emplacement pour une synthèse robuste de la forme de forme longue - https://arxiv.org/pdf/1910.10288.pdf
Vocodeurs
MELGAN: https://arxiv.org/pdf/1910.06711.pdf
ParallelWavegan: https://arxiv.org/pdf/1910.11480.pdf
- Perte de STFT à plusieurs échelles
- ~ 1M Paramètres du modèle (très petit)
- Un peu pire que Wavernn
Améliorer FFTNET
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
FFTNET
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Reconstruction de la forme d'onde de la parole à l'aide de neuralnetwetworks convolutionnels avec du bruit et des entrées périodiques
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
Vers réaliser une vocodage universel robuste
- https://arxiv.org/pdf/1811.06292.pdf
Lpcnet
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
Excitationt
- https://arxiv.org/pdf/1811.04769v3.pdf
Gelp: prédiction linéaire excitée par GAn pour la synthèse de la parole de spectrogramme
- https://arxiv.org/pdf/1904.03976v3.pdf
Synthèse de la parole haute fidélité avec réseaux adversaires: https://arxiv.org/abs/1909.11646
- Gan-tts, synthèse de la parole de bout en bout
- Utilise la durée et les fonctionnalités linguistiques
- La durée et les caractéristiques acoustiques sont prédites par des modèles supplémentaires.
- Discriminateur de fenêtres aléatoires: ingérez pas l'ensemble de l'échantillon de voix mais des fenêtres aléatoires.
- Plusieurs RWD. Certains conditionnels et certains inconditionnels. (conditionné sur les fonctionnalités d'entrée)
- Punchline: utilisez des fenêtres échantillonnées au hasard avec différentes tailles de fenêtre pour D.
- Les résultats partagés semblent mécaniques qui montrent les limites des caractéristiques acoustiques non neurales.
Multi-Band Melgan: https://arxiv.org/abs/2005.05106
- Utilisez des pertes PWGAN au lieu de la perte de correspondance des fonctionnalités.
- L'utilisation d'un champ réceptif plus grand augmente considérablement les performances du modèle.
- Générateur pré-formation pour 200k iTERS.
- Prédiction du signal vocal multi-bandes. La sortie est une sommation de 4 prédictions de bande différentes avec des filtres de synthèse PQMF.
- Le modèle multi-bandes a des paramètres de 1,9 m (assez petits).
- Affirmé être 7x plus vite que MELGAN
- Sur un ensemble de données chinois: MOS 4.22
Glow Wave: https://arxiv.org/abs/1811.00002
- Très grand modèle (paramètres de 268 m)
- Difficile à entraîner car sur un GPU de 12 Go, cela ne peut prendre que la taille du lot 1.
- Inférence en temps réel en raison de l'utilisation de convolutions.
- Basé sur un flux de normalisation invertable. (Excellent tutoriel https://blog.evjang.com/2018/01/nf1.html)
- Le modèle apprend et la cartographie inventible des échantillons audio aux spectrogrammes de MEL avec une perte de vraisemblance maximale.
- Le réseau d'inférence s'exécute dans le sens inverse et les spécifications de MEL sont converties en échantillons audio.
- La formation a été effectuée en utilisant 8 NVIDIA V100 avec 32 Go de RAM, Taille du lot 24. (Cher)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, code: https://github.com/tianrengao/squeezewave
- ~ 5-13x plus vite que le temps réel
- Redandounces de la lueur d'onde: longs échantillons audio, upSamples MEL-Specs, grandes dimensions de canal dans la fonction WN.
- Correction: des échantillons audio plus courts mais plus courts en entrée, (l = 2000, c = 8 vs l = 64, c = 256)
- L = 64 correspond à la résolution MEL-Spec, donc aucun échantillonnage nécessaire.
- Utilisez des convolutions séparables en profondeur dans les modules WN.
- Utilisez une convolution régulière au lieu de dilaté car les échantillons audio sont plus courts.
- Ne divisez pas les sorties du module en sortie résiduelle et réseau, en supposant que ces vecteurs sont presque identiques.
- La formation a été effectuée à l'aide de Titan RTX 24 Go de lot 96 pour 600k itérations.
- MOS sur LJSpeech: Glugure d'onde - 4,57, Squeezewave (L = 128 C = 256) - 4,07 et Squeezewave (L = 64 C = 256) - 3,77
- Le plus petit modèle a 21 000 échantillons par seconde sur RasPI3.
Wavegrad: https://arxiv.org/pdf/2009.00713.pdf
- Il est basé sur la diffusion de probabilité et la dynamique Lagenin
- L'idée de base est d'apprendre une fonction qui mappe une distribution connue pour cibler la distribution des données de manière itérative.
- Ils rapportent 0,2 facteur en temps réel sur un GPU, mais les performances du processeur ne sont pas partagées.
- Dans l'exemple de code ci-dessous, l'auteur rapporte que le modèle converge après 2 jours de formation sur un seul GPU.
- Les scores MOS sur le papier ne sont pas suffisamment comphérents, mais montrent des performances comparables à des modèles connus comme Wavernn et Wavenet.
Code: https://github.com/ivanvovk/wavegrad 
Depuis Internet (blogs, vidéos, etc.)
Vidéos
Discussion sur papier
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Pourparlers
- Parlez sur la poussée de la frontière du texte à la to-to-speech neuronal, par Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- Parlez sur la synthèse de texte vocale basée sur des modèles génératives, par Heiga Zen, 2017
- Vidéo: https://youtu.be/nsrsrytkkt8
- Diapositive: https://research.google.com/pubs/pub45882.html
- Tutoriels sur la synthèse du texte-vocation paramétrique neuronale à Isca Odyessy 2020, par Xin Wang, 2020
- Vidéo: https://youtu.be/wce7sycdzai
- Diapositive: http://tonywangx.github.io/slide.html#dec-2020
- Cours de traitement de la parole ISCA sur les vocodeurs neuronaux, 2022
- Composantes de base des vocodeurs neuronaux: https://youtu.be/m833q5i-zys
- Modèles génératifs profonds pour la compression de la parole (LPCNET): https://youtu.be/7ksnfx3plgw
- Neural Auto-Regressive, Source Filter et Glottal Vocoders: https://youtu.be/gprmxdberx0
- Diapositive: http://tonywangx.github.io/slide.html#jul-2020
- Synthèse de la parole du décodage neuronal des phrases parlées | AISC: https://www.youtube.com/watch?v=mndtmdpmnmo
- Synthèse générative de texte à la dissection: https://www.youtube.com/watch?v=j4mveanking
- Synthèse de la parole pour l'industrie du jeu: https://www.youtube.com/watch?v=aohaye4a-2q
Général
- Revue des systèmes de texte-to-speech moderne: https://www.youtube.com/watch?v=8RXLSC-ZCRY
Cahiers de jupyter
- Tutoriels sur des vocodeurs neuronaux sélectionnés: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
Blogs
- Texte à la parole Architectures d'apprentissage en profondeur: http://www.erogol.com/text-speech-deep-learning-architectures/


