(Не стесняйтесь предлагать изменения)
Документы
- Объединение фонем и чар.
- Tacotron Transfer Learning: https://arxiv.org/pdf/1904.06508.pdf
- Фонемное время от внимания: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Полуопервизированная обучение для повышения эффективности данных при синтезе речи-https://arxiv.org/pdf/1808.10128.pdf
- Слушание во время разговора: речевая цепочка от глубокого обучения - https://arxiv.org/pdf/1707.04879.pdf
- Generelised To-To-To-To-Cons для проверки динамика: https://arxiv.org/pdf/1710.10467.pdf
- ES-Tacotron2: Multi-Task Tacotron 2 с предварительно обученной оценочной сетью для снижения проблемы с чрезмерным
- Против чрезмерной головности
- Fastspeech: https://arxiv.org/pdf/1905.09263.pdf
- Обучение пению из речи: https://arxiv.org/pdf/1912.10128.pdf
- TTS-Gan: https://arxiv.org/pdf/1909.11646.pdf
- Они используют продолжительность и лингвистические особенности для En2en TTS.
- Рядом с Wavenet Performance.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Продолжительность знания такотрона
- Мелнет: https://arxiv.org/abs/1906.01083
- Aligntts: https://arxiv.org/pdf/2003.01950.pdf
- Неконтролируемое разложение речи через тройную информацию узкое место
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Обратный ауторегрессивный поток на такотроне, как архитектура
- Волновой хлопот как вокад.
- Стиль речи, внедряющий смесь гауссовой модели.
- Модель большая и ущерба, чем ванильный такотрон
- Значения MOS немного лучше, чем публичная реализация такотрона.
- Эффективно обучаемая система текста в речь, основанная на глубоких сверточных сетях с руководством с руководством: https://arxiv.org/pdf/1710.08969.pdf
Обширные резюме
Следует до самого досягаемости.
- End2end Feed-Forward TTS Learning.
- Выравнивание персонажа было сделано с помощью отдельного модуля выравнивателя.
- Выравниватель предсказывает длину каждого символа. - Центральное расположение символа найдено в общей длине предыдущих символов. - Позиции CHAR интерполируются с гауссовым окном с реальной длиной звука.
- Выход аудио вычисляется в домене MU-Law. (У меня нет причин для этого)
- Используйте только 2 секунды аудиоуди для транзинга.
- Генератор GAN-TTS используется для получения аудиосигнала.
- RWD используется в качестве дискриминатора уровня аудио.
- MELD: Они используют архитектуру Biggan Deep в качестве дискриминатора уровня спектрограммы, регулирующих проблему в качестве реконструкции изображения.
- Потеря спектрограммы
- Использовать только состязательной обратной спины недостаточно, чтобы выучить выравнивания Char. Они используют потерю спектрограммы B/W прогнозируемые спектрограммы и характеристики земли.
- Обратите внимание, что модель предсказывает аудиосигналы. Спектрограммы выше вычисляются из сгенерированного звука.
- Динамическая временная упаковка используется для вычисления минимальной стоимости выравнивания B/W, сгенерированных спектрограмм и грунтовой неверной.
- Это включает в себя динамический подход программирования, чтобы найти выравнивание минимальной стоимости.
- Потеря длины выравнивателя используется для наказания выравнивателя за прогнозирование иначе, чем реальная длина звука.
- Они обучают модель с помощью нескольких наборов данных динамиков, но сообщают о результатах о лучшем эффективном динамике.
- Абляционное исследование Важность каждого компонента: (LengthLoss и Spectrogramloss)> RWD> MELD> PHONEMES> MultispeakerDataset.
- Мои 2 цента: это модель подачи вперед, которая обеспечивает синтез речи в конце 2-й конца без необходимости обучать отдельную модель вокалу. Тем не менее, это очень сложная модель с большим количеством гиперпараметров и деталей реализации. Также конечный результат не близок к состоянию искусства. Я думаю, что нам нужно найти конкретные алгоритмы для выравнивания персонажей обучения, что уменьшило бы необходимость настройки комбинации различных алгоритмов.
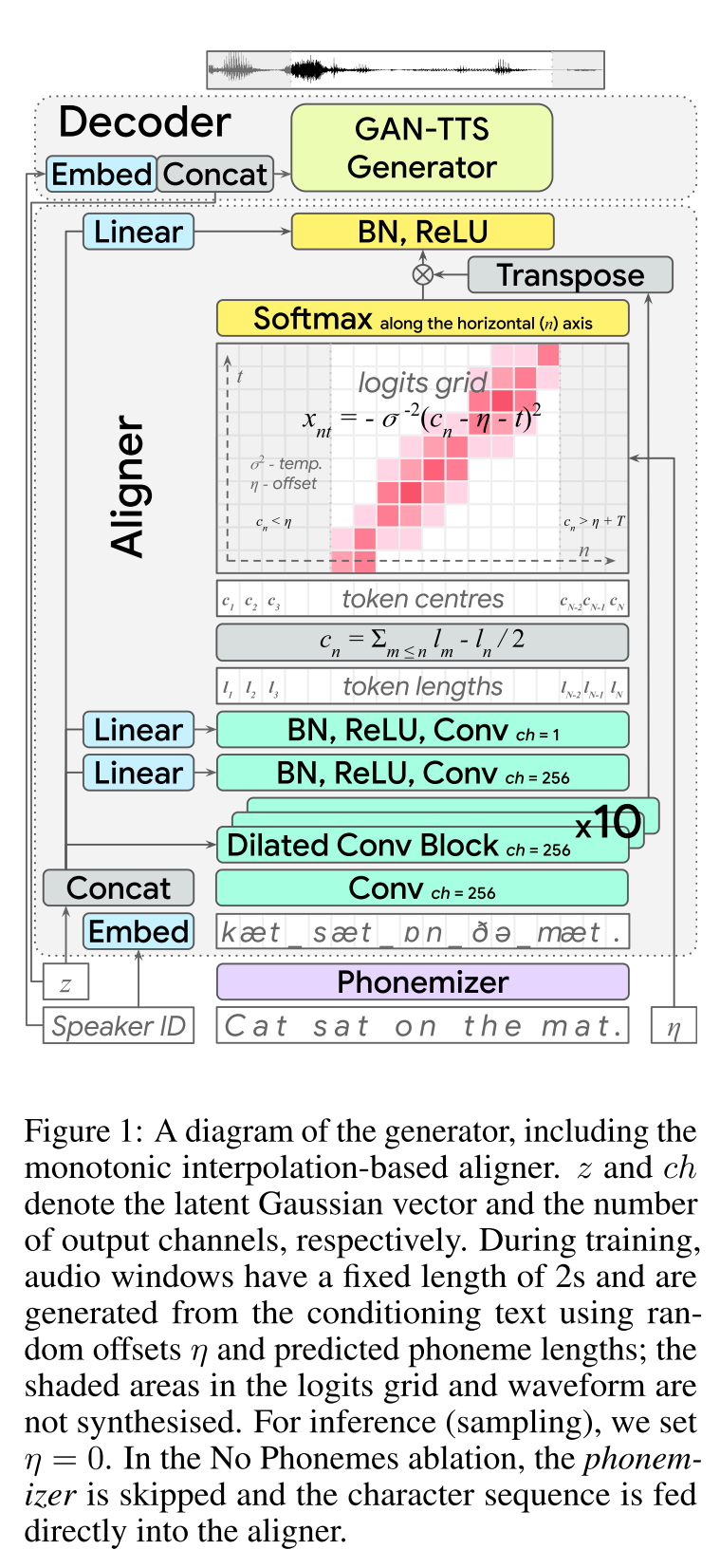
Быстрая речь 2: http://arxiv.org/abs/2006.04558 (нажмите, чтобы развернуть)
- Используйте фонемные продолжительности, генерируемые MFA в качестве меток для обучения регулятора длины.
- Thay использует нормы спектрограммы Spectrogram Spectrogram (информация о дисперсии) в качестве дополнительных функций.
- Модуль предиктора дисперсии прогнозирует информацию о дисперсии во время вывода.
- Усовершенствования результатов исследований абляции: модель <model + l2_norm <model + l2_norm + f0
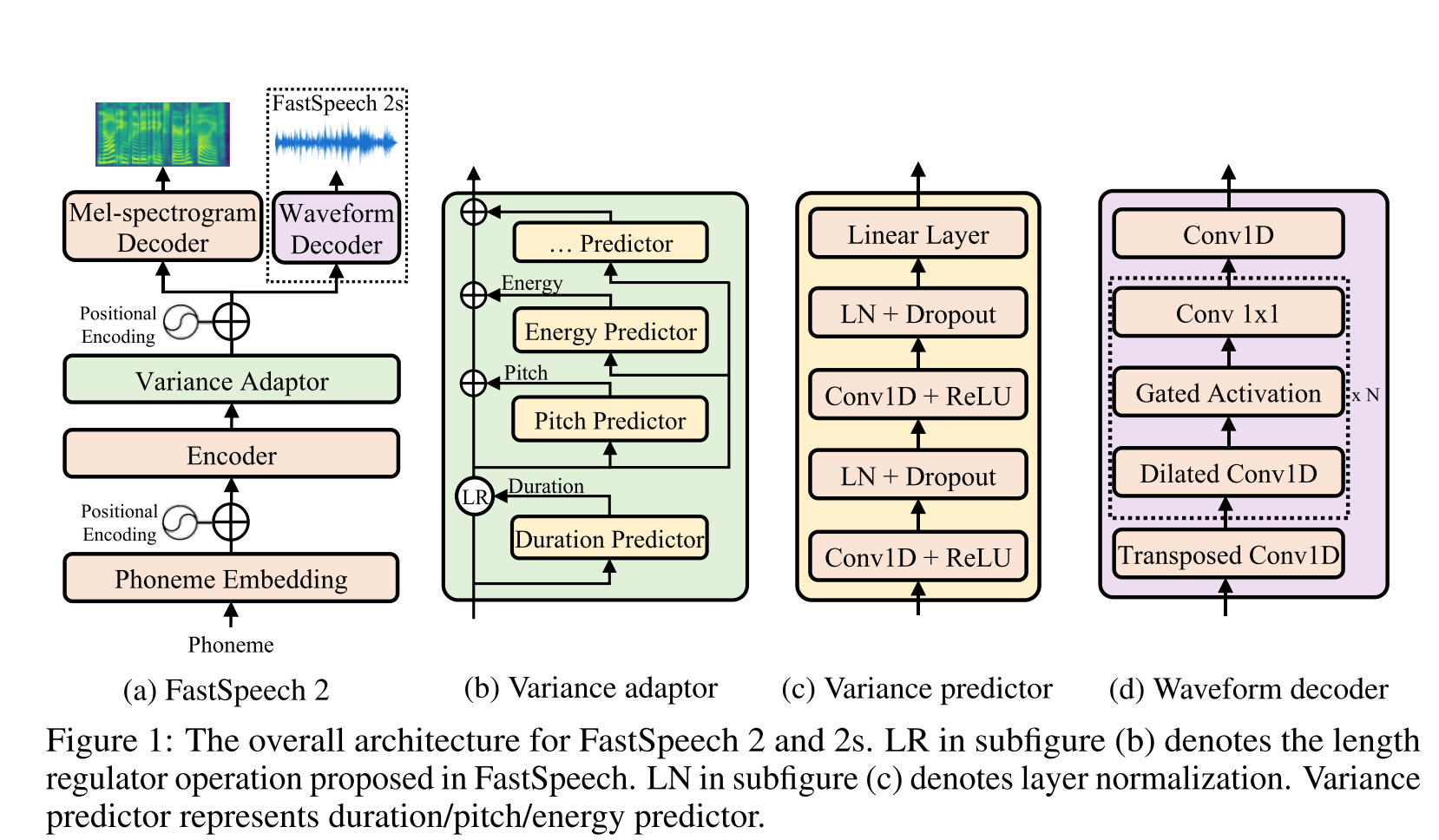
Glow-TTS: https://arxiv.org/pdf/2005.11129.pdf (нажмите, чтобы развернуть)
- Используйте монотонный поиск выравнивания, чтобы выучить текст и спектрограмму выравнивания B/W
- Это выравнивание используется для обучения предиктора продолжительности, который будет использоваться при выводе.
- Энкодер отображает каждый символ в гауссовом распределении.
- Декодер отображает каждую раму спектрограммы с скрытым вектором, используя нормализующий поток (слои свечения)
- Выходы энкодера и декодера выровнены с MAS.
- На каждой итерации сначала наиболее вероятное выравнивание обнаруживается MAS, и это выравнивание используется для обновления параметров режима.
- Проиктор продолжительности обучена прогнозировать количество кадров спектрограммы для каждого символа.
- При выводе только предиктор продолжительности используется вместо MAS
- Encoder имеет архитектуру TTS Transformer с 2 обновлениями
- Вместо абсолютного позиционного кодирования они используют недвижимое позиционное кодирование.
- Они также используют остаточное соединение для энкодера.
- Декодер имеет ту же архитектуру, что и модель свечения.
- Они тренируют как одиночную, так и с несколькими динамиками модель.
- Экспериментально показано, что Glow-TTS более устойчив по сравнению с длинными предложениями по сравнению с оригинальным Tacotron2
- В 15 раз быстрее, чем такотрон2 при выводе
- Мои 2 цента: их образцы звучат не так естественно, как такотрон. Я полагаю, что нормальные модели внимания все еще генерируют более естественную речь, поскольку внимание учится карту символов для непосредственного моделирования выходов. Однако использование Glow-TTS может быть хорошей альтернативой для жестких наборов данных.
- Образцы: https://github.com/jaywalnut310/glow-tts
- Репозиторий: https://github.com/jaywalnut310/glow-tts
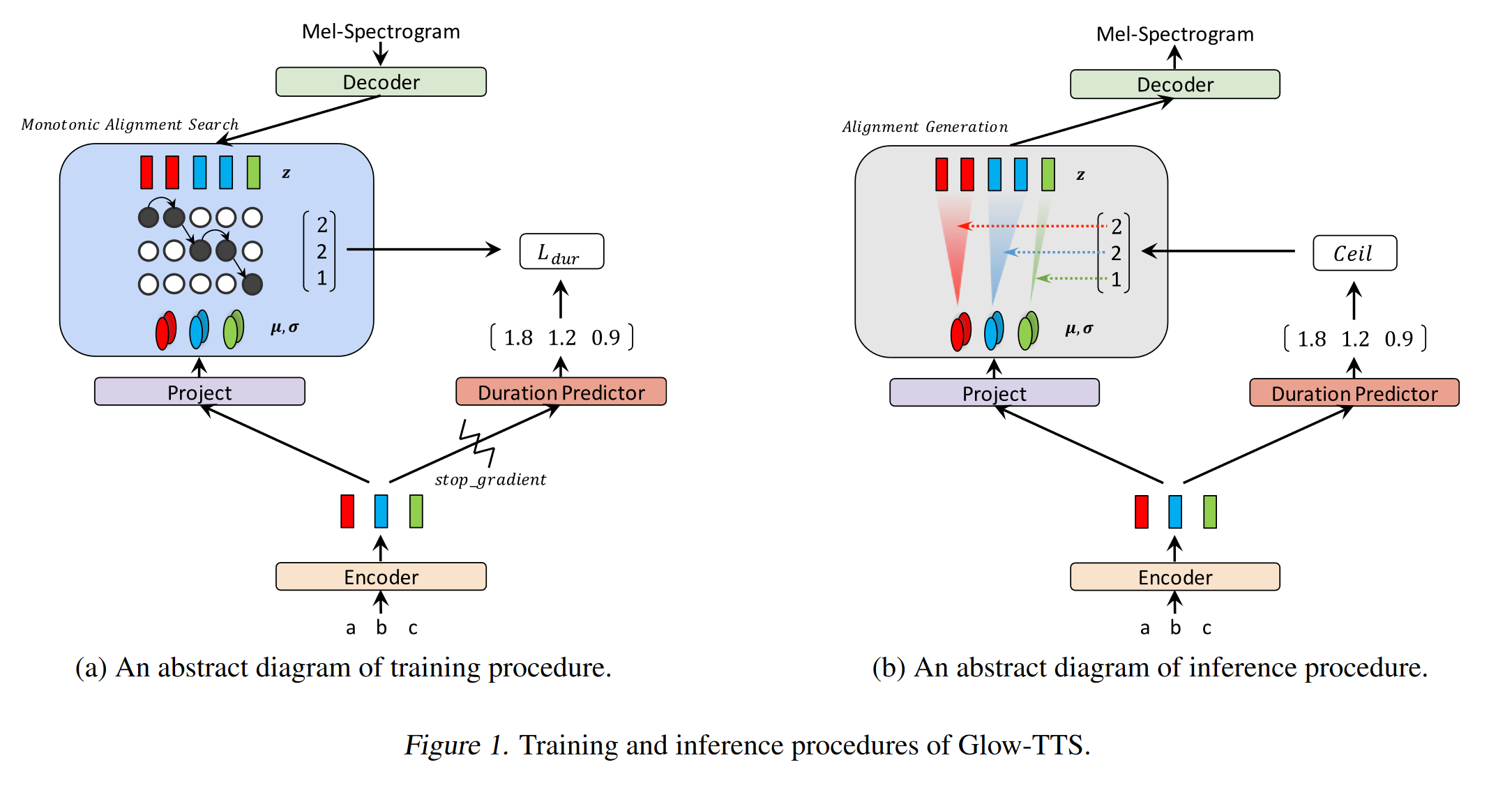
Неавторегрессивный нейронный текст в речь: http://arxiv.org/abs/1905.08459 (нажмите, чтобы развернуть)
- Вывод модели Deep Voice 3 с использованием незвуковых сверточных слоев.
- Парадигма учителя-ученика для обучения ученика Annon-Autoregressive с несколькими блоками внимания от модели ауторегрессии учителя.
- Учитель используется для генерации выравнивания текста в спектрограмму, которые будут использоваться моделью ученика.
- Модель обучена двумя функциями потерь для выравнивания внимания и генерации спектрограммы.
- Многолетние блоки внимания уточняют слой выравнивания внимания за слоем.
- Студент использует внимание точечного продукта с помощью векторов запросов, ключей и значения. Запрос - это только положительные векторы кодирования. Ключ и значение - выходы энкодера.
- Предлагаемая модель в значительной степени связана с позиционным кодированием, которое также зависит от различных постоянных значений.
Согласованность двойного декодера: https://erogol.com/solving-atration-problems-of-tts-models-with-double-decoder-consestency (нажмите, чтобы расширить)
- Модель использует такотронную архитектуру, но с 2 декодерами и постне.
- DDC использует два синхронных декодера с использованием различных скоростей сокращения.
- Декодеры используют разные скорости сокращения, поэтому они вычисляют выходы в различных гранулировании и изучают различные аспекты входных данных.
- Модель использует согласованность между этими двумя декодерами, чтобы повысить надежность выравнивания ученых до спектрограммы.
- Модель также применяет уточнение к окончательному выходу декодера, применяя пост -сети итеративно несколько раз.
- DDC использует нормализацию пакетов в модуле PRENET и выпадает на выбросы.
- DDC использует постепенное обучение, чтобы сократить общее время обучения.
- Мы используем многополосный генератор Мелгана в качестве вокадного, обученного несколькими случайными дискриминаторами оконных оконных оконных дискриминаторов, чем оригинальная работа.
- Мы можем обучить модель DDC только за 2 дня с одним графическим процессором, и окончательная модель способна генерировать речь в реальном времени на процессоре. Демо-страница: https://erogol.github.io/ddc-samples/ code: https://github.com/mozilla/tts
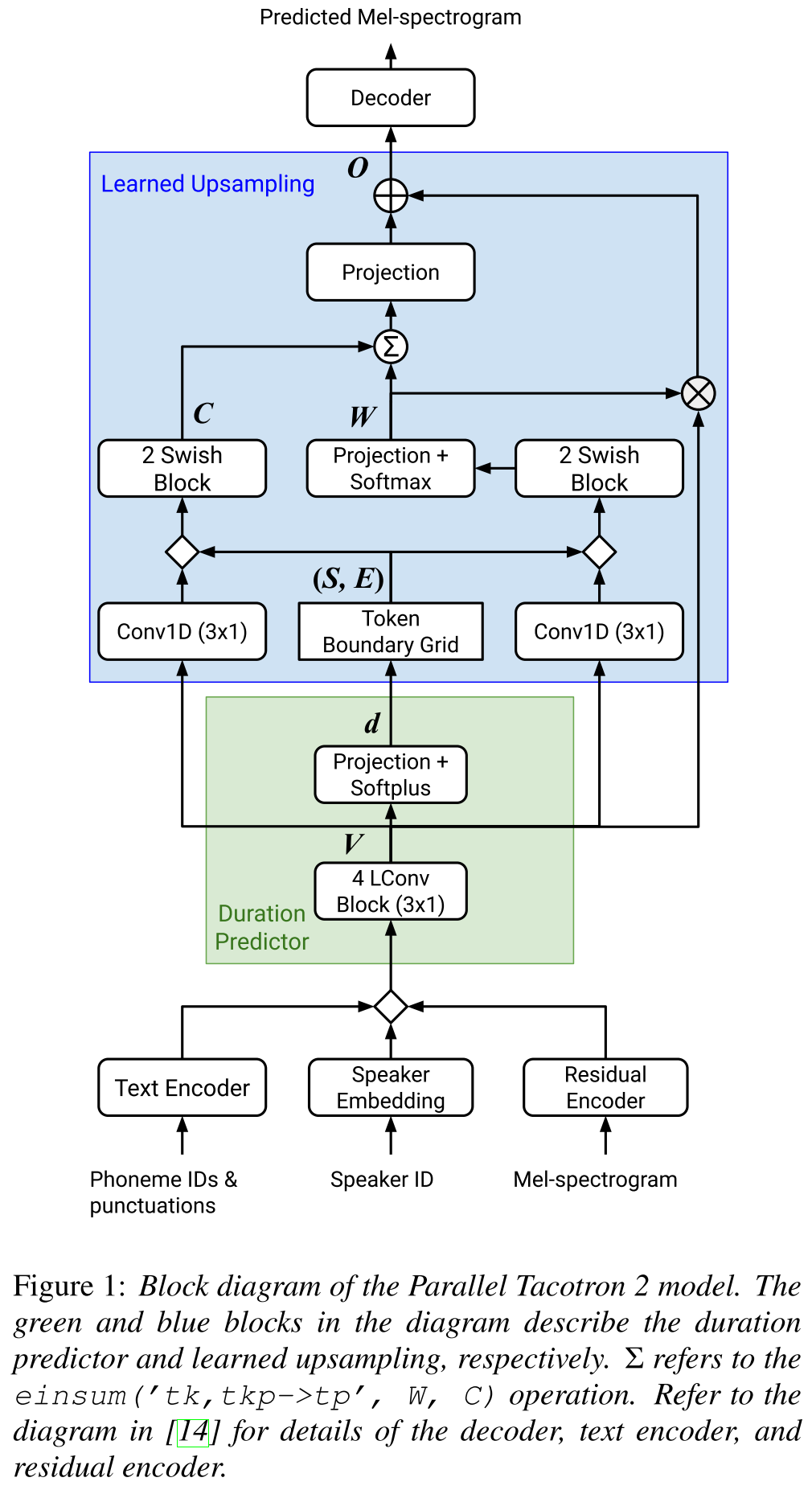
Parallel Tacotron2: http://arxiv.org/abs/2103.14574 (нажмите, чтобы развернуть)
- Не требует внешней информации.
- Решает проблемы выравнивания между реальными и территорией и не правдивой крючкой путем потери в мягком DTW.
- Прогнозируемые продолжительности преобразуются в соответствие с помощью учентной функции преобразования, а не регулятора длины, для решения вопросов округления.
- Узнает карту внимания над «граничными сетками токена», которая вычисляется из прогнозируемых продолжительности.
- Декодер построен на 6 «легких совет».
- VAE используется для проектирования входных спектрограмм с скрытыми функциями и объединяется с вставками символов в качестве входа в сеть.
- Soft-DTW является вычислительно интенсивным, поскольку он вычисляет парные различия для всех кадров спектрограммы. Они противопоставляют его определенным диагональным окном, чтобы уменьшить накладные расходы.
- Окончательной целью продолжительности является сумма потерь продолжительности, потери VAE и потери спектрограммы.
- Они используют только частные наборы данных для экспериментов?
- Достигает того же MOS с моделью Tacotron2 и превосходит ParalleltAcotron.
- Демо -страница : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Код : пока нет кода
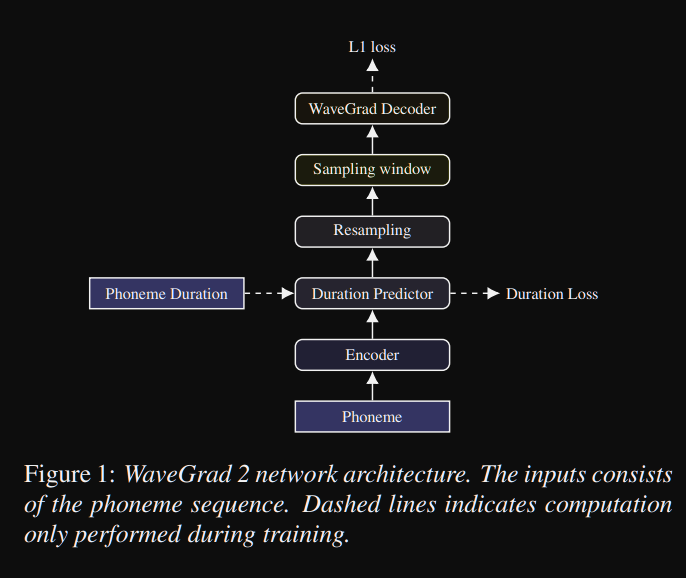
WaveGrad2: https://arxiv.org/pdf/2106.09660.pdf (нажмите, чтобы развернуть)
- Он вычисляет необработанную форму волны непосредственно из последовательности фонем.
- Модель такотрона2, подобная энкодеру, используется для вычисления скрытого представления из фонем.
- Невнимательный такотрон, подобный мягкому предиктору, чтобы выравнивать скрытое представление с выходом.
- Они расширяют скрытое представление с прогнозируемым продолжительностью и проберут определенное окно, чтобы преобразовать в форму волны.
- Они исследовали различные размеры окна между 64 и 256 кадрами, соответствующими 0,8 и 3,2 секунды речи. Они обнаружили, что чем больше, тем лучше.
- Демо -страница : ничего не так далеко
- Код : пока нет кода
Многогазной бумаги
- Обучение мультигадационных нейронных систем текста в речь с использованием динамики-имбалентных речевых корпораций-https://arxiv.org/abs/1904.007711
- Глубокий голос 2-https://papers.nips.cc/paper/6889-deep-voice-2-multi-peaker-neural-text-to-speech.pdf
- Образец эффективной адаптивной TTS - https://openreview.net/pdf?id=rkzjuoacfx
- Подход Wavenet + Discoersing
- Voice Loop - https://arxiv.org/abs/1707.06588
- Моделирование скрытого пространства с несколькими динамиками для улучшения нейронного TTS Quick Relluging New Dinger и улучшения премиального голоса - https://arxiv.org/pdf/1812.05253.pdf
- Трансферный обучение из проверки динамиков в синтез текста в речь Multipeaker-https://arxiv.org/pdf/1806.04558.pdf
- Установка новых динамиков на основе короткого невзванного образца - https://arxiv.org/pdf/1802.06984.pdf
- Обобщенная сквозная потеря для проверки динамика-https://arxiv.org/abs/1710.10467
Обширные резюме
Полуопервизированное обучение для синтеза текста в речь мульти-динамика с использованием дискретного речевого представления: http://arxiv.org/abs/2005.08024
- Обурите многопрофильную модель TTS с парными данными длиной всего часовой (выравнивание текста к Voice) и более непарные (только голоса).
- Он изучает кодовую книгу с каждым кодовым словом соответствует одной фонеме.
- Кодовая книга выровнена с фонемами, используя парные данные и алгоритм CTC.
- Эта книга кода функционирует как прокси, чтобы неявно оценить последовательность фонем непарных данных.
- Они складывают модель Tacotron2 сверху, чтобы выполнить TTS, используя кодовые вставки, сгенерированные начальной частью модели.
- Они превзошли методы контрольных данных в 1 часах парных настройки данных.
- Они не сообщают о полных парных результатах данных.
- У них нет хорошего исследования абляции, которое может быть интересно посмотреть, как разные части модели способствуют производительности.
- Они используют Гриффин-Лим в качестве вокадера, поэтому есть место для улучшения.
Демо-страница: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
Код: https://github.com/ttaoretw/semi-tts 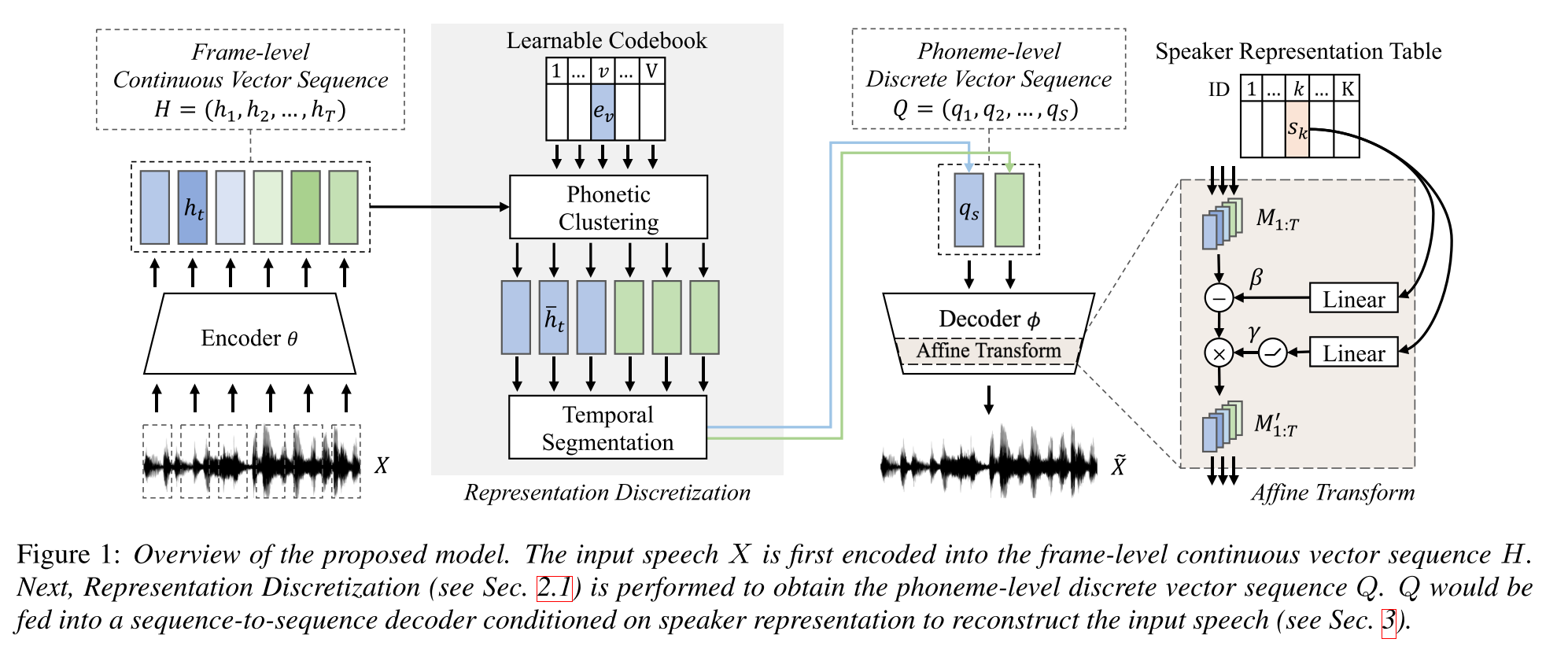
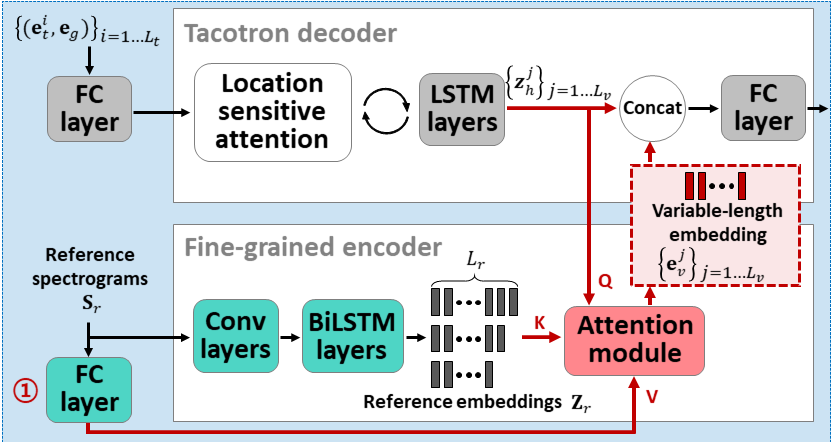
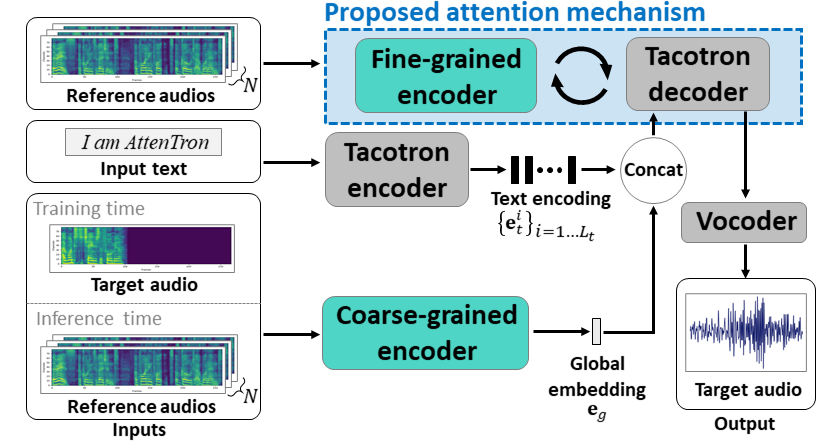
Attentron: несколько высказывания текста-речь Используя внимание на основе внимания. Внедрение длины: https://arxiv.org/abs/2005.08484
- Используйте два энкодера, чтобы выучить динамик, зависящие от функций.
- Крупный энкодер изучает глобальный вектор, включающий в себя вектор на основе предоставленных эталонных спектрограмм.
- Fine Encoder изучает переменную длину, сохраняя временное размещение в сотрудничестве с модулем внимания.
- Внимание выбирает важные кадры эталонных спектрограммов для синтеза целевой речи.
- Первопровернуть модель с одним набором данных динамика (LJSPEECH для 30K ITERS.)
- Настройте модель с помощью набора данных с несколькими динамиками. (VCTK для 70 тыс. Итера.)
- Он достигает немного лучших показателей по сравнению с использованием x-векторов из модели классификации динамиков и справочного звука на основе VAE.
Демо -страница: https://hyperconnect.github.io/attentron/
На пути к универсальному тексту к речи: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
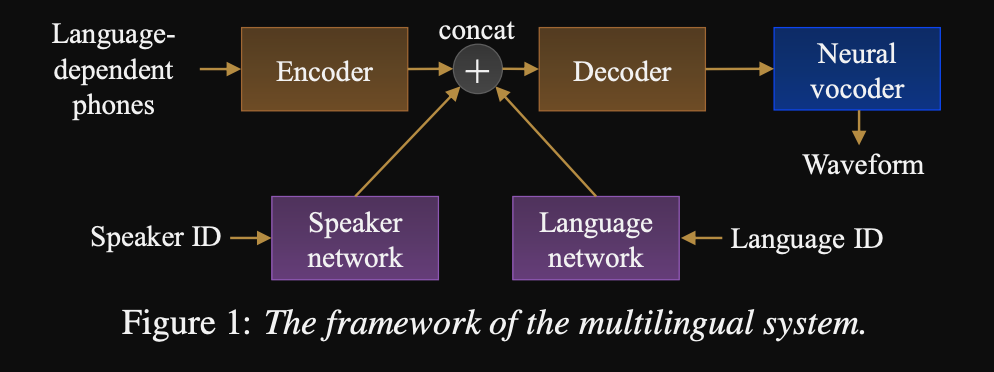
- Структура для последовательности для последовательности многоязычных TTS
- Модель обучена очень большим, очень несбалансированным набором данных.
- Модель может выучить новый язык с 6 минутами и новым динамиком с 20 секундами данных после первоначального обучения.
- Архитектура модели представляет собой сеть энкодеров-декодеров на основе трансформатора с сетью динамиков и языковой сетью для спикера и языковой кондиционирования. Выходы этих сетей объединяются с выходом энкодера.
- Сети по кондиционированию принимают одножелачный вектор, представляющий спикера или языкового идентификатора и проецируют его на кондиционирующее представление.
- Они используют вородовый Wavenet для преобразования прогнозируемых мель-спектрограмм в выходной сигнал.
- Они используют язык, зависящие от фонем, которые не разделяются между языками.
- Они пробуют каждую партию на основе обратной частоты каждого языка в наборе данных. Таким образом, каждая учебная партия имеет равномерное распределение по языкам, облегчая языковой дисбаланс в наборе учебных данных.
- Для изучения новых динамиков/языков они настраивают модель Encoder-Decoder с сети кондиционирования. Они не тренируют модель Wavenet.
- Они используют 1250 часов профессиональных записей из 50 языков для обучения.
- Они используют скорость отбора проб 16 кГц для всех образцов аудио и замолчать в начале и в конце каждого клипа.
- Они используют 4 V100 графических процессоров для обучения, но не упоминают, как долго они обучали модель.
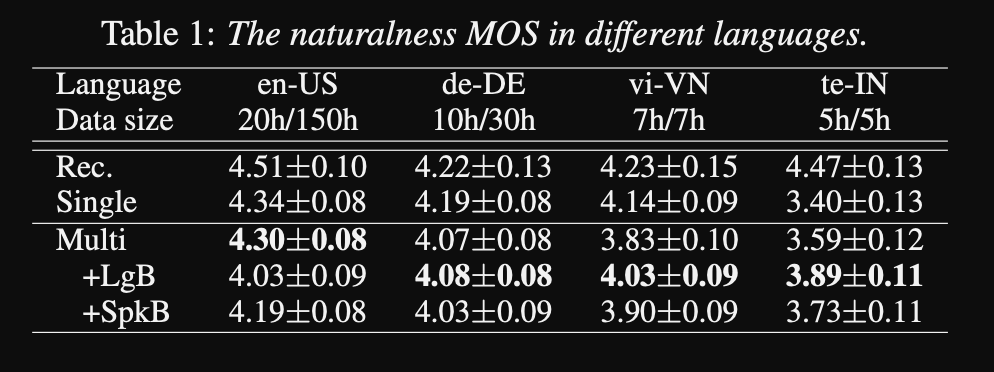
- Результаты показывают, что модели отдельных динамиков лучше, чем предлагаемый подход в метрике MOS.
- Также использование кондиционирующих сетей важно для языков с длинным хвостом в наборе данных, поскольку они улучшают метрику MOS для них, но ухудшают производительность для языков с высоким разрешением.
- Когда они добавляют новый динамик, они отмечают, что использование более 5 минут данных ухудшает производительность модели. Они утверждают, что, поскольку эти записи не такие чистые, как оригинальные записи, использование большего количества из них влияет на общую производительность модели.
- Многоязычная модель способна обучать только 6 минут данных для новых динамиков и языков, тогда как для тренировок для одного динамика требуется 3 часа, и она не может даже достигать аналогичных значений MOS, как и 6-минутная многоязычная модель.
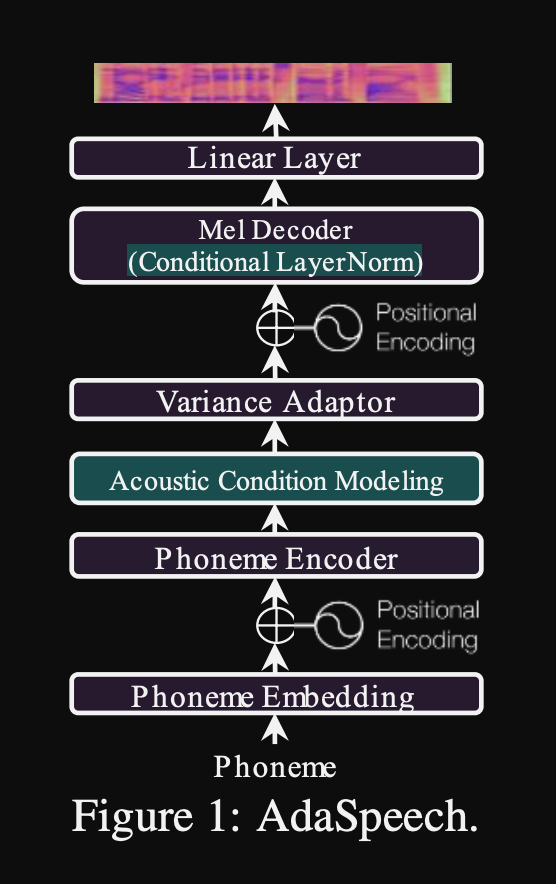
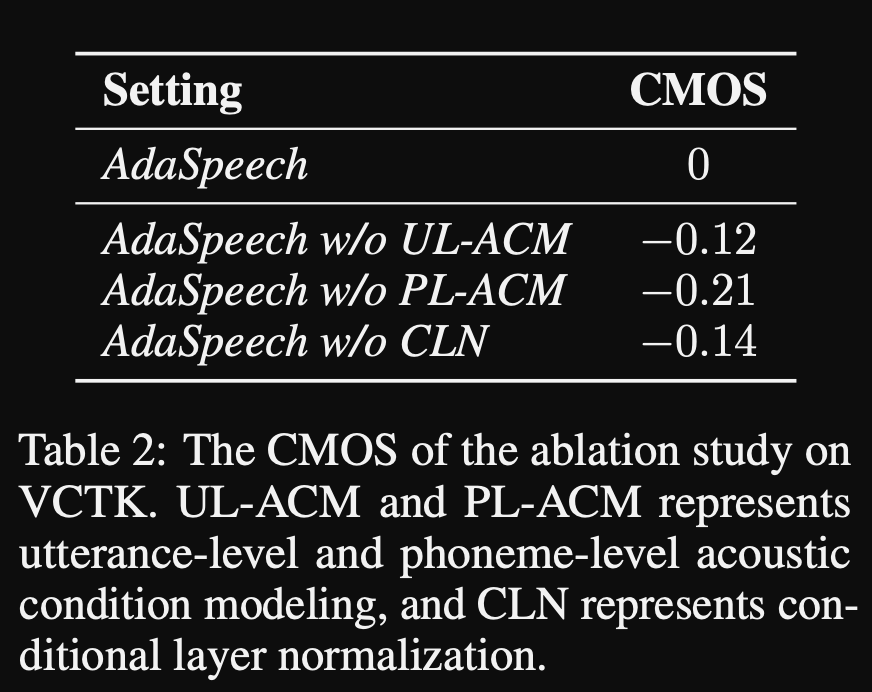
Adaspeech: адаптивный текст к речи для пользовательского голоса: https://openreview.net/pdf?id=drynvt7gg4l
- Они предложили систему, которая может адаптироваться к различным входным акустическим свойствам пользователей и использует минимальное количество параметров для достижения этого.
- Основная архитектура основана на модели Fastspeech2, которая использует предикторы высоты тона и дисперсии для изучения более тонких деталей входной речи.
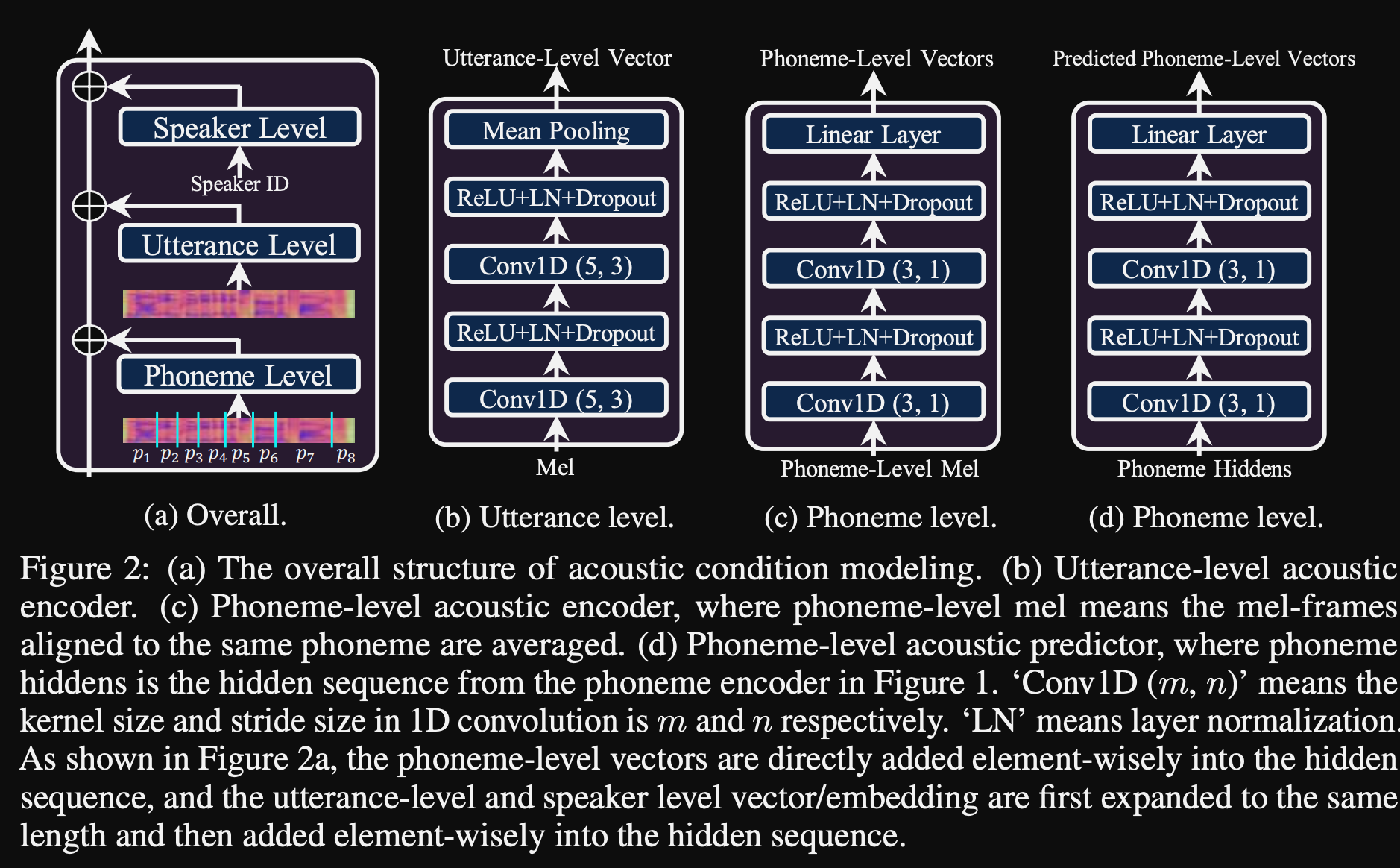
- Они используют 3 дополнительных сети кондиционирования.
- Уровень высказывания. Он принимает мель-спектрограмму эталонной речи в качестве входного.
- Уровень фонемы. Он принимает фонем на уровне Mel-Spectrograms в качестве входных и вычисляет векторы кондиционирования на уровне фонемы. Мель-спектрограммы на уровне фонемы рассчитываются путем принятия средней кадра спектрограммы в течение длительности каждой фонемы.
- Фонема уровня 2. Он принимает выходы фонем -энкодера в качестве входов. Это отличается от сети выше, просто используя информацию о фонеме, не видя спектрограммы.
- Все эти кондиционирующие сети и задний косточек Fastspeech2 используют слои нормализации слоев.
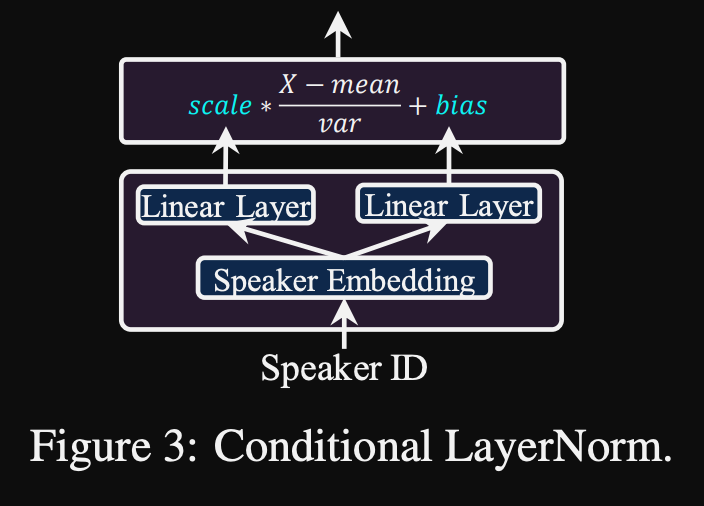
- Условная нормализация слоя. Они предлагают тонкую настройку только масштаб и параметры смещения каждого слоя нормализации слоя, когда модель точно настроена для нового динамика. Они обучают модуль кондиционера динамика для каждого слоя нормы слоя, который выводит шкалу и значения смещения. (Они используют один модуль кондиционера динамика на блок трансформатора.)
- Это означает, что вы храните только модуль кондиционера динамика для каждого нового динамика и предсказываете значения шкалы и смещения при выводе, поскольку вы держите остальную часть модели одинаковой.
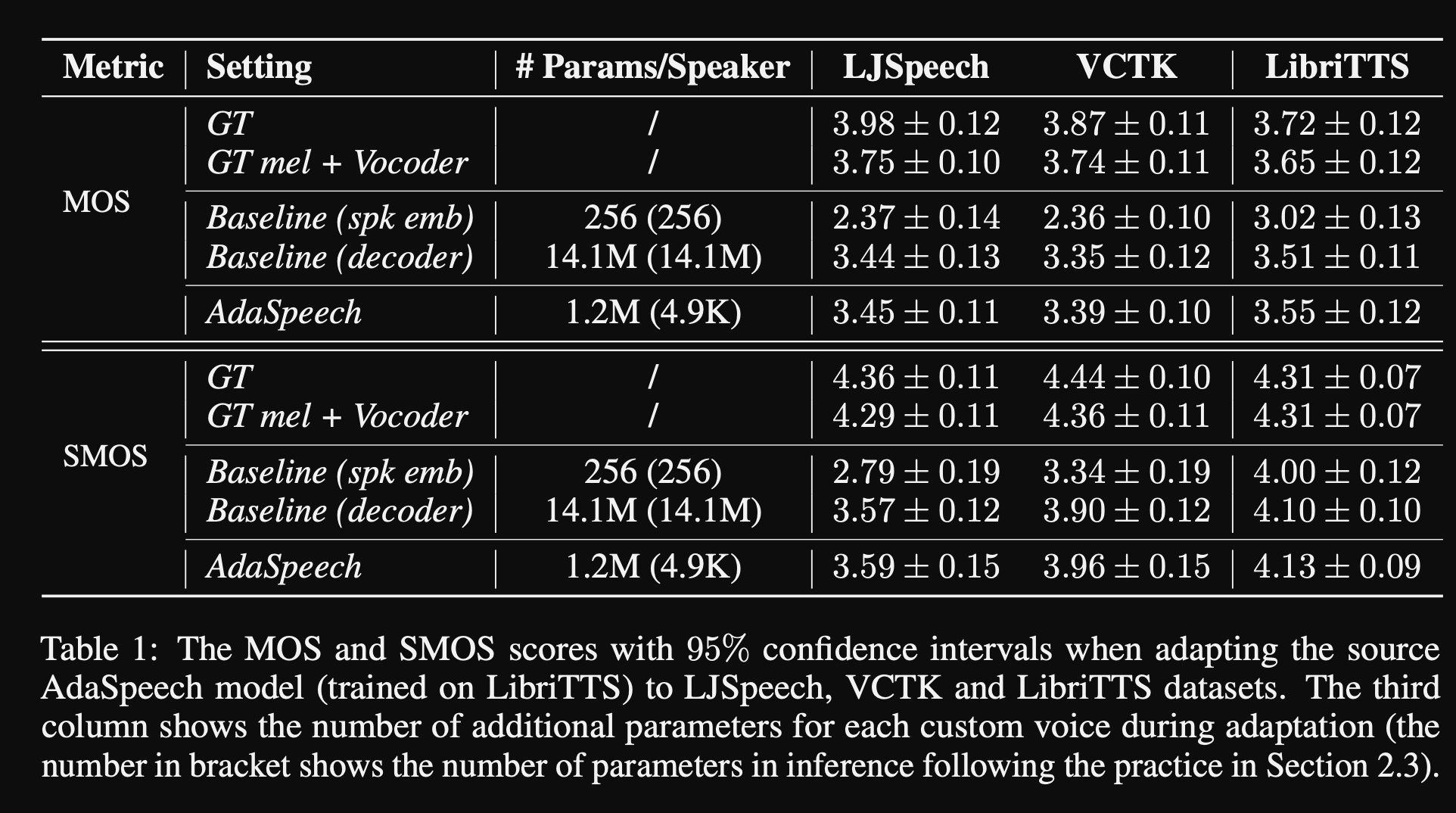
- В экспериментах они обучают предварительную подготовку модели на наборе данных Libritts и настраивайте ее с VCTK и LJSPEECH
- Результаты показывают, что использование условной нормализации слоя достигает лучшего, чем их 2 базовые показатели, которые используют только встроение динамиков и декодер.
- Их исследование абляции показывает, что наиболее значимой частью модели является сеть «Phoneme Level», за которой следует условная нормализация уровня и сеть «уровня высказывания» в порядке.
- Одним из важных нижних сторон статьи является то, что почти нет сравнения с литературой, и это затрудняет объективную оценку результатов.
Демо -страница: https://speechresearch.github.io/adaspeech/

Внимание
- Относительные механизмы внимания для надежного синтеза с длинной формой речи-https://arxiv.org/pdf/1910.10288.pdf
Вокадеры
Мелган: https://arxiv.org/pdf/1910.06711.pdf
PARALLELWAVEGAN: https://arxiv.org/pdf/1910.11480.pdf
- Потеря много масштаба STFT
- ~ 1M параметры модели (очень маленькие)
- Чуть хуже, чем Уэвернн
Улучшение FFTNet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
Fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Реконструкция формы речи с использованием сверточных Neuralnetworks с шумом и периодическими входами
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
К достижению надежного универсального вокана
- https://arxiv.org/pdf/1811.06292.pdf
LPCnet
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
ExteNet
- https://arxiv.org/pdf/1811.04769v3.pdf
Гельпа: GAN-задействованное линейное прогнозирование для синтеза речи Frommel-Spectram
- https://arxiv.org/pdf/1904.03976v3.pdf
Синтез речи высокой верности с состязательными сетями: https://arxiv.org/abs/1909.11646
- Gan-TTS, синтез речи сквозной речи
- Использует продолжительность и лингвистические особенности
- Продолжительность и акустические особенности прогнозируются дополнительными моделями.
- Случайный дискриминатор окон: проглатывает не весь образец голоса, а случайные окна.
- Несколько RWD. Некоторые условные и некоторые безусловные. (кондиционировано на входных функциях)
- Punchline: используйте случайные отобранные окна с разными размерами окна для D.
- Общие результаты звучат механические, что показывает пределы ненуранных акустических особенностей.
Multi-Band Melgan: https://arxiv.org/abs/2005.05106
- Используйте потери PWGAN вместо потерь сопоставления функций.
- Использование более крупного рецептивного поля значительно повышает производительность модели.
- Генератор предварительно подготовлен к итерам 200 тысяч.
- Предсказание многополосного голосового сигнала. Выход - это суммирование 4 различных полосовых прогнозов с фильтрами синтеза PQMF.
- Многополосная модель имеет параметры 1,9 м (довольно маленькие).
- Утверждается, что в 7 раз быстрее Мелгана
- На китайском наборе данных: MOS 4.22
Waveglow: https://arxiv.org/abs/1811.00002
- Очень большая модель (параметры 268 м)
- Трудно тренировать, так как на 12 ГБ графического процессора он может занять только размер партии 1.
- Вывод в режиме реального времени из-за использования свертков.
- На основе инвертируемого нормализующего потока. (Отличный учебник https://blog.evjang.com/2018/01/nf1.html)
- Модель изучает и приобретает отображение образцов аудио с мель-спектрограммами с максимальной потерей вероятности.
- В выводах сеть работает в обратном направлении и дает MEL-SPECs преобразованы в аудио-образцы.
- Обучение было проведено с использованием 8 NVIDIA V100 с 32 ГБ оперативной памяти, размером партии 24 (дорого)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, код: https://github.com/tianrengao/squeezewaveave
- ~ 5-13 раза быстрее, чем в режиме реального времени
- Волноводы Redanduncies: длинные аудио-образцы, воспроизведение Mel-Specs, большие размеры канала в функции WN.
- Исправления: больше, но более короткие образцы аудио в качестве входных данных (L = 2000, C = 8 против L = 64, C = 256)
- L = 64 соответствует разрешению MEL-SPEC, поэтому не требуется upsampling.
- Используйте глубину разделяемые совет, в модулях WN.
- Используйте регулярную свертку вместо расширения, поскольку образцы звука короче.
- Не разделите выходы модуля на остаточные и сетевые выходы, предполагая, что эти векторы практически идентичны.
- Обучение было проведено с использованием титана RTX 24 ГБ размером 96 для итераций 600 тыс.
- MOS на LJSPEECH: WAVENGLOW - 4,57, Squeezewave (L = 128 C = 256) - 4,07 и Squeezewave (L = 64 C = 256) - 3,77
- Наименьшая модель имеет 21 тыс. Образцов в секунду на Raspi3.
WAVERGRAD: https://arxiv.org/pdf/2009.00713.pdf
- Он основан на диффузии вероятности и динамике лагенвина
- Базовая идея состоит в том, чтобы изучить функцию, которая итеративно отображает известное распределение с целевым распределением данных.
- Они сообщают 0,2 фактора в реальном времени на графическом процессоре, но производительность процессора не является общей.
- В приведенном ниже примере автор сообщает, что модель сходится после 2 дней обучения на одном графическом процессоре.
- Оценки MOS на бумаге недостаточно составлены, но показывают сопоставимую производительность с известными моделями, такими как Wavernn и Wavenet.
Код: https://github.com/ivanvovk/wavegrade 
Из Интернета (блоги, видео и т. Д.)
Видео
Бумажное обсуждение
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Разговоры
- Поговорите о том, чтобы нажать границу нейронного текста в речь, Сюй Тан, 2021, https://youtu.be/ma8pcvmr8b0
- Разговор о синтезе текста в речь в сфере генеративной модели, от Heiga Zen, 2017
- Видео: https://youtu.be/nsrsrytkkt8
- Слайд: https://research.google.com/pubs/pub45882.html
- Учебные пособия по нейронному параметрическому синтезу текста в речь в ISCA Odyessy 2020, Синь Ван, 2020
- Видео: https://youtu.be/wce7sycdzai
- Слайд: http://tonywangx.github.io/slide.html#dec-2020
- Курс обработки речи ISCA по нейронным вокалу, 2022
- Основные компоненты нейронных вокадеров: https://youtu.be/m833q5-zys
- Глубокие генеративные модели для сжатия речи (LPCNET): https://youtu.be/7ksnfx3plgw
- Нейронные авто-регрессивные, исходные фильтра и глоттальные вокадеры: https://youtu.be/gprmxdberx0
- Слайд: http://tonywangx.github.io/slide.html#jul-2020
- Синтез речи от нервного декодирования разговорных предложений | AISC: https://www.youtube.com/watch?v=mndtmdpmnmo
- Генеративный синтез текста в речь: https://www.youtube.com/watch?v=J4mveanking
- Синтез речи для игровой индустрии: https://www.youtube.com/watch?v=aohaye4a-2q
Общий
- Современный текстовый речь Системы Обзор: https://www.youtube.com/watch?v=8rxlsc-zcry
Няневые ноутбуки
- Учебные пособия по выбранным нейронным вокалу: https://github.com/nii-yamagishilab/project-nn-pytorch-cripts/tree/master/tutoriors/b1_neural_vocoder
Блоги
- Текст к речи глубоко обучение


