(Fühlen Sie sich frei, Änderungen vorzuschlagen)
Papiere
- Zusammenführen von Phonem- und Char -Darstellungen: https://arxiv.org/pdf/1811.07240.pdf
- Tacotron Transfer Learning: https://arxiv.org/pdf/1904.06508.pdf
- Phonem -Timing von Aufmerksamkeit: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- SEMI-SUPERVISCHE Schulung zur Verbesserung der Dateneffizienz in der End-to-End-Sprachsynthese-https://arxiv.org/pdf/1808.10128.pdf
- Hören beim Sprechen: Sprachkette von Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Generelle End-zu-End-Verlust für die Verifizierung der Sprecher: https://arxiv.org/pdf/1710.10467.pdf
- ES-Tacotron2: Multitask-Tacotron 2 mit vorgeborenem geschätztem Netzwerk zur Reduzierung des Problems der Übersbefestigkeit: https://www.mdpi.com/2078-2489/10/4/131/pdf
- Gegen Überschwemmlichkeit
- Fastspeech: https://arxiv.org/pdf/1905.09263.pdf
- Lernen singen aus der Sprache: https://arxiv.org/pdf/1912.10128.pdf
- Tts-gan: https://arxiv.org/pdf/1909.11646.pdf
- Sie verwenden Dauer und sprachliche Merkmale für EN2en TTs.
- Nahe Wavenet -Leistung.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Meldung: https://arxiv.org/abs/1906.01083
- Aligntts: https://arxiv.org/pdf/2003.01950.pdf
- Unbeaufsichtigtes Sprachabzug über den Triple Information Engpass
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Umgekehrter autoregerischer Fluss auf Tacotron wie Architektur
- Wellenlow als Vocoder.
- Sprachstil Einbettung mit Mischung aus Gaußschen Modell.
- Das Modell ist groß und verändert sich als Vanille -Tacotron
- Die MOS -Werte sind schwach besser als die öffentliche Tacotron -Implementierung.
- Effizient trainierbares Text-zu-Speech-System basierend auf tiefen Faltungsnetzen mit geführter Aufmerksamkeit: https://arxiv.org/pdf/1710.08969.pdf
Expansive Zusammenfassungen
End-to-End-Gegner text-to-Speech: http://arxiv.org/abs/2006.03575 (Klicken Sie hier, um zu erweitern)
- End2end Feed-Forward TTS-Lernen.
- Die Charakterausrichtung wurde mit einem separaten Aligner -Modul durchgeführt.
- Der Aligner sagt die Länge jedes Zeichens voraus. - Der mittlere Standort eines WHO wird die Gesamtlänge der vorherigen Zeichen gefunden. - Char -Positionen werden mit einem Gaußschen Fenster interpoliert, die die echte Audiolänge sind.
- Die Audioausgabe wird in der Mu-Law-Domäne berechnet. (Ich habe keine Argumentation dafür)
- Verwenden Sie nur 2 Sekunden Audiofenster für das Traning.
- Der GAN-TTS-Generator wird verwendet, um ein Audiosignal zu erzeugen.
- RWD wird als Diskriminator auf Audioebene verwendet.
- Meldung: Sie verwenden Biggan-Deep-Architektur als Diskriminatorebene auf Spektrogrammebene, die das Problem als Bildrekonstruktion regeln.
- Spektrogrammverlust
- Die Verwendung von nur widersprüchlichen Futtermittel reicht nicht aus, um die Char-Ausrichtungen zu erlernen. Sie verwenden einen Spektrogrammverlust von B/W prognostizierte Spektrogramme und Bodenwahrheitspezifikationen.
- Beachten Sie, dass das Modell Audiosignale vorhersagt. Die oben genannten Spektrogramme werden aus dem generierten Audio berechnet.
- Die dynamische Zeitverpackung wird verwendet, um eine minimale Preisausrichtung von b/w erzeugte Spektrogramme und Bodenwahrheit zu berechnen.
- Es beinhaltet einen dynamischen Programmieransatz, um eine minimale Kostenausrichtung zu finden.
- Der Verlust von Aligner Länge wird verwendet, um den Aligner für die Vorhersage von anderen Audiolänge zu bestrafen.
- Sie schulen das Modell mit Multi -Lautsprecher -Datensatz, melden jedoch die Ergebnisse des Lautsprechers am besten.
- Ablationsstudie Bedeutung jeder Komponente: (Länge und Spektrogramm)> RWD> Meldung> Phonemes> MultispeakerDataset.
- Meine 2 Cent: Es handelt sich um ein Vorwärtsmodell, das die Sprachsynthese der End-2-End-Sprache liefert, ohne ein separates Vocoder-Modell zu trainieren. Es ist jedoch ein sehr kompliziertes Modell mit vielen Hyperparametern und Implementierungsdetails. Auch das Endergebnis liegt nicht nahe am Stand der Technik. Ich denke, wir müssen spezifische Algorithmen für Lerncharakterausrichtungen finden, die die Notwendigkeit einer Kombination verschiedener Algorithmen verringern würden.
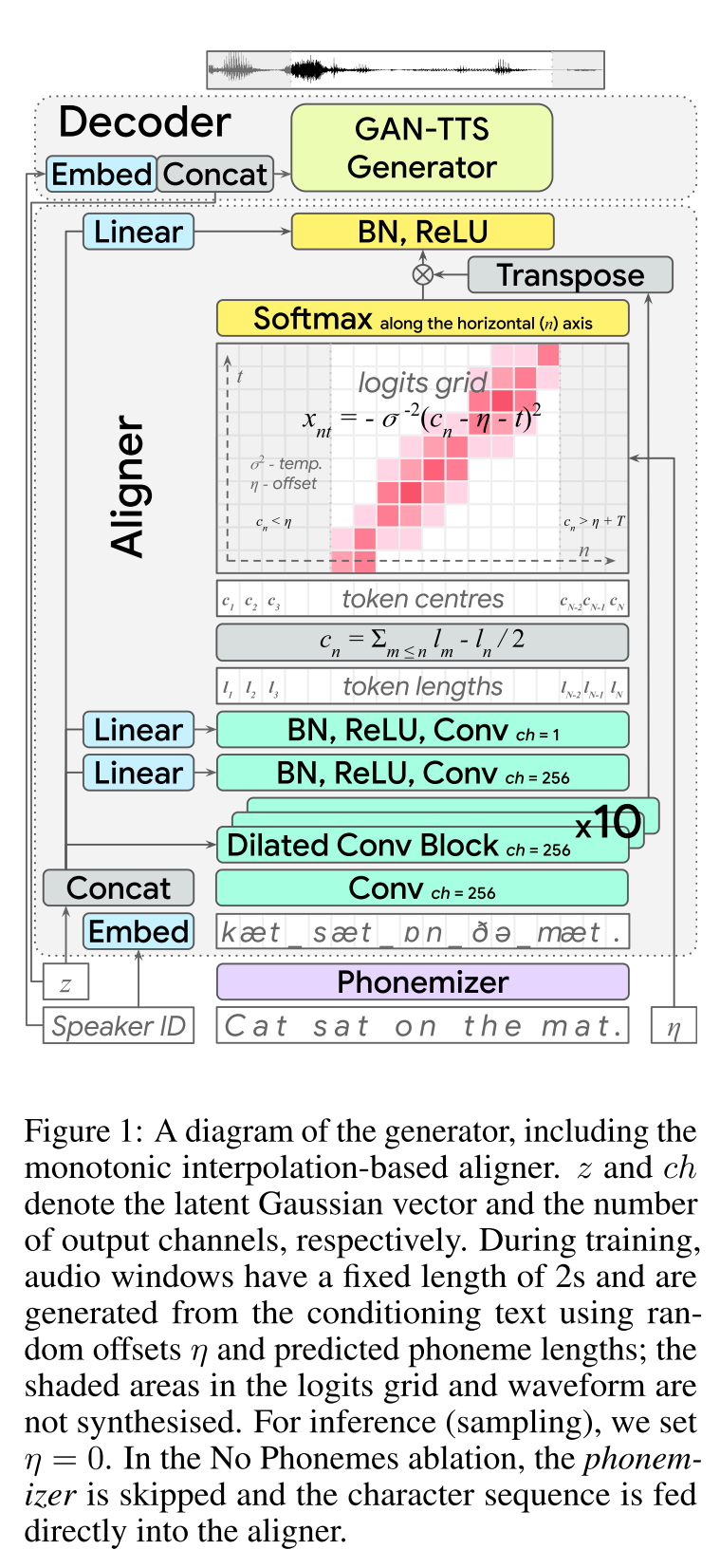
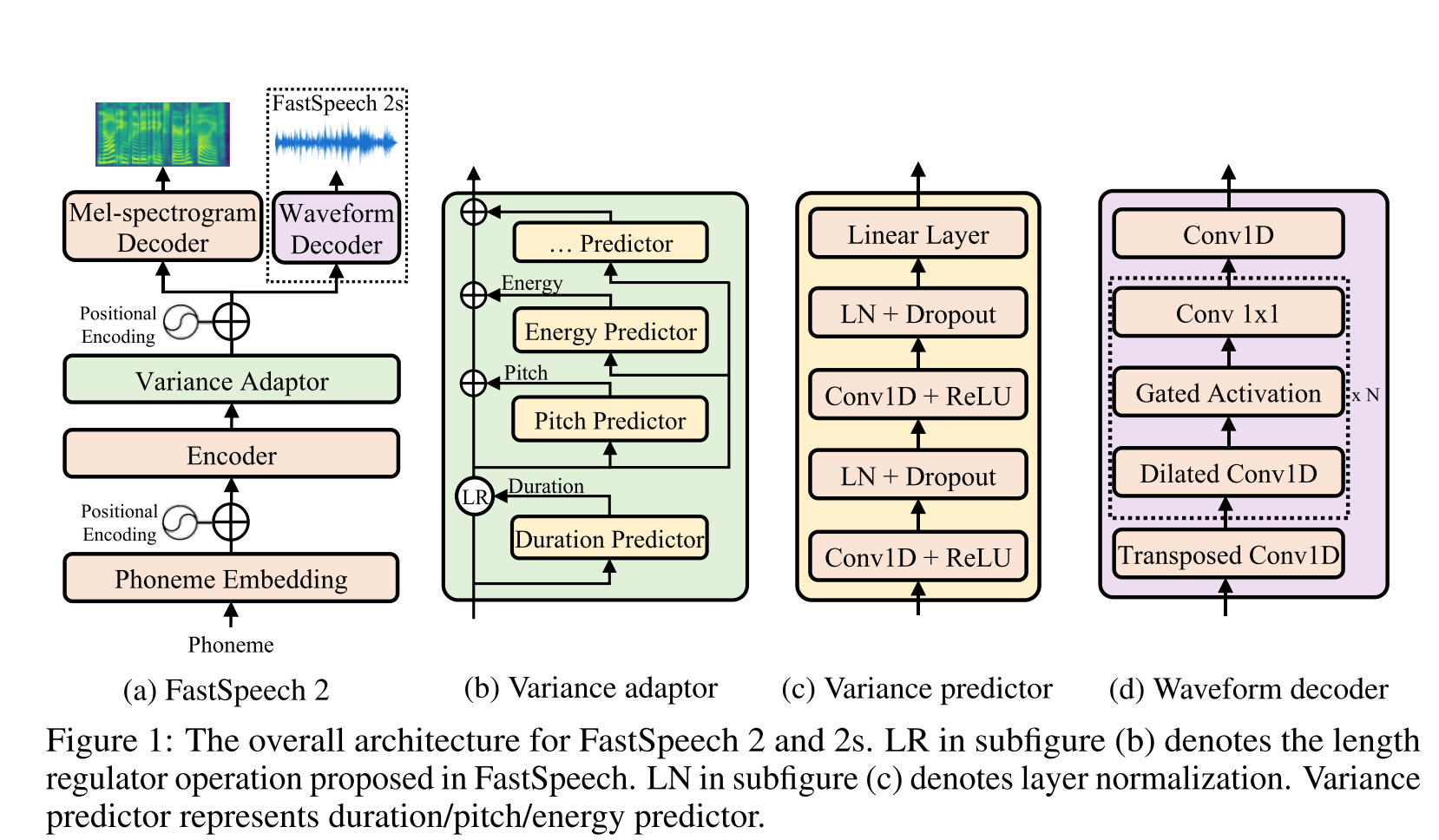
FAST Speech2: http://arxiv.org/abs/2006.04558 (Klicken Sie hier, um zu erweitern)
- Verwenden Sie Phonemdauer, die von MFA als Etiketten erzeugt werden, um einen Länge Regler zu trainieren.
- Die Nutzung von Frame -Level F0- und L2 -Spektrogrammnormen (Varianzinformationen) als zusätzliche Funktionen.
- Das Varianzprädiktormodul sagt die Varianzinformationen zum Inferenzzeiten voraus.
- Ablationsstudieergebnis Verbesserungen: Modell <Modell + L2_NORM <Modell + L2_NORM + F0
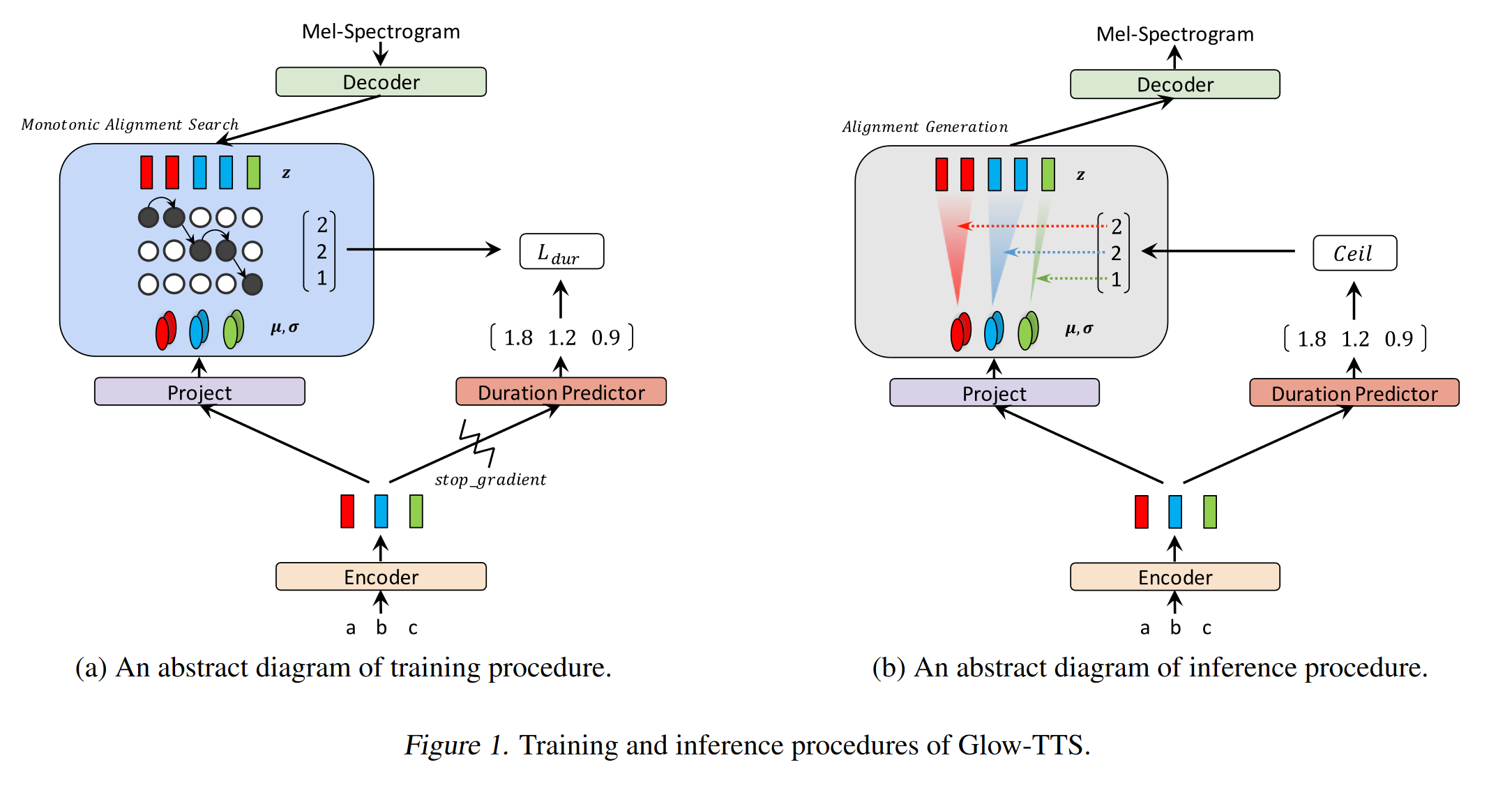
GLOW-TTS: https://arxiv.org/pdf/2005.11129.pdf (Klicken Sie hier, um zu erweitern)
- Verwenden Sie die monotonische Ausrichtungssuche, um die Ausrichtung zwischen Text und Spektrogramm zu erlernen
- Diese Ausrichtung wird verwendet, um einen Dauer -Prädiktor zu trainieren, der bei Inferenz verwendet werden soll.
- Encoder ordnet jeden Charakter einer Gaußschen Verteilung ab.
- Decoder bildet jeden Spektrogrammrahmen an einen latenten Vektor unter Verwendung des Normalisierungsflusss (Glühschichten)
- Encoder- und Decoderausgänge sind auf MAS ausgerichtet.
- Bei jeder Iteration wird zunächst die wahrscheinlichste Ausrichtung von MAS gefunden und diese Ausrichtung wird verwendet, um die Parameter der Modus zu aktualisieren.
- Ein Dauerprädiktor wird trainiert, um die Anzahl der Spektrogrammrahmen für jedes Zeichen vorherzusagen.
- Bei Inferenz wird nur der Dauer -Prädiktor anstelle von MAS verwendet
- Encoder hat die Architektur des TTS -Transformators mit 2 Updates
- Anstelle einer absoluten Positionscodierung verwenden sie eine Realt -Positionscodierung.
- Sie verwenden auch eine Restverbindung für das Encoder -Prenet.
- Decoder hat die gleiche Architektur wie das Glühmodell.
- Sie trainieren sowohl Single- als auch Multi-Sprecher-Modell.
- Es wird experimentell gezeigt, Glow-TTS ist gegenüber langen Sätzen im Vergleich zu Original Tacotron2 robuster
- 15x schneller als Tacotron2 bei Inferenz
- Meine 2 Cent: Ihre Samples klingen nicht so natürlich wie Tacotron. Ich glaube, normale Aufmerksamkeitsmodelle erzeugen immer noch mehr natürliche Sprache, da die Aufmerksamkeit lernt, Zeichen für direkte Ausgänge zu kartieren. Die Verwendung von Glow-TTs könnte jedoch eine gute Alternative für harte Datensätze sein.
- Beispiele: https://github.com/jaywalnut310/glow-tts
- Repository: https://github.com/jaywalnut310/glow-tts
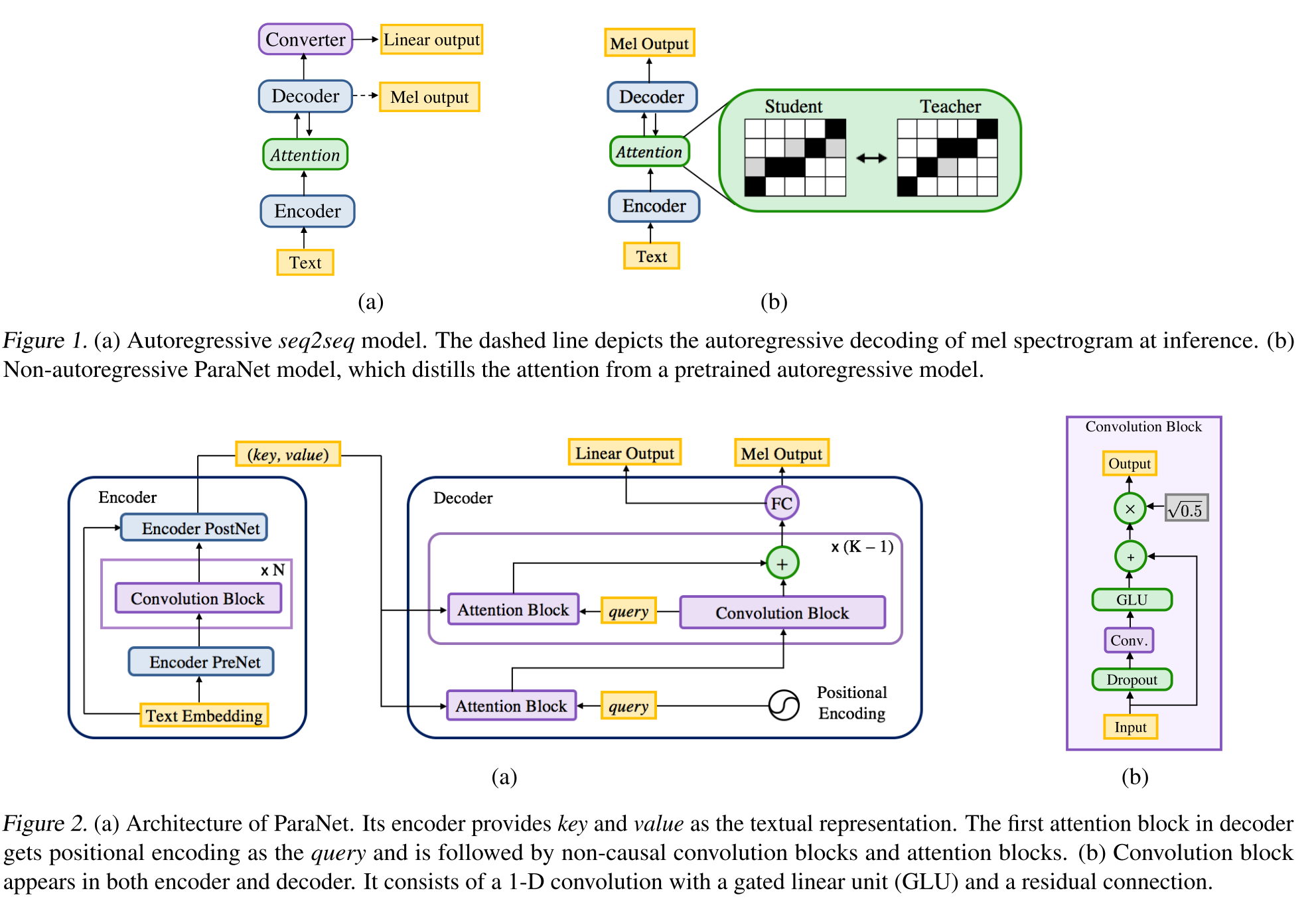
Nicht autoregressiv
- Eine Ableitung von Deep Voice 3-Modell mit nicht-kausalen Faltungsschichten.
- Lehrer-Student-Paradigma zum Ausbilden von Annon-Autoregressive Student mit mehreren Aufmerksamkeitsblöcken von einem autoregressiven Lehrermodell.
- Der Lehrer wird verwendet, um Text-to-Spektrogramm-Ausrichtungen zu generieren, die vom Schülermodell verwendet werden sollen.
- Das Modell wird mit zwei Verlustfunktionen für Aufmerksamkeitsausrichtung und Spektrogrammgenerierung geschult.
- Multi -Aufmerksamkeitsblöcke verfeinern die Aufmerksamkeitsausrichtungsschicht für Schicht.
- Der Schüler verwendet die Aufmerksamkeit der Dot-Produkte mit Abfrage-, Schlüssel- und Wertvektoren. Die Abfrage ist nur positive Codierungsvektoren. Der Schlüssel und der Wert sind die Encoderausgänge.
- Das vorgeschlagene Modell ist stark an die Positionscodierung gebunden, die auch auf unterschiedlichen konstanten Werten beruht.
Doppel-Decoder-Konsistenz: https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder-consistency (klicken, um zu erweitern)
- Das Modell verwendet eine Tacotron -ähnliche Architektur, jedoch mit 2 Decoder und einem Postnetz.
- DDC verwendet zwei synchrone Decoder unter Verwendung unterschiedlicher Reduktionsraten.
- Die Decoder verwenden unterschiedliche Reduktionsraten, weshalb sie Ausgaben in unterschiedlichen Granularitäten berechnen und unterschiedliche Aspekte der Eingabedaten lernen.
- Das Modell verwendet die Konsistenz zwischen diesen beiden Decodern, um die Robustheit der gelernten Text-zu-Spektrogramm-Ausrichtung zu erhöhen.
- Das Modell wendet außerdem eine Verfeinerung der endgültigen Decoderausgabe an, indem das Postnetz mehrmals iterativ angewendet wird.
- DDC verwendet die Batch -Normalisierung im Prenet -Modul und Drops Drops -Schichten.
- DDC nutzt ein allmähliches Training, um die Gesamtschulungszeit zu verkürzen.
- Wir verwenden einen Multi-Band-Melgan-Generator als Vocoder, der mit mehreren Zufallsfenster-Diskriminatoren trainiert ist als die ursprüngliche Arbeit.
- Wir sind in der Lage, ein DDC-Modell nur in 2 Tagen mit einer einzigen GPU zu trainieren, und das endgültige Modell kann in einer CPU schneller als Echtzeitreden generieren. Demo-Seite: https://erogol.github.io/ddc-samples/ Code: https://github.com/mozilla/ttss
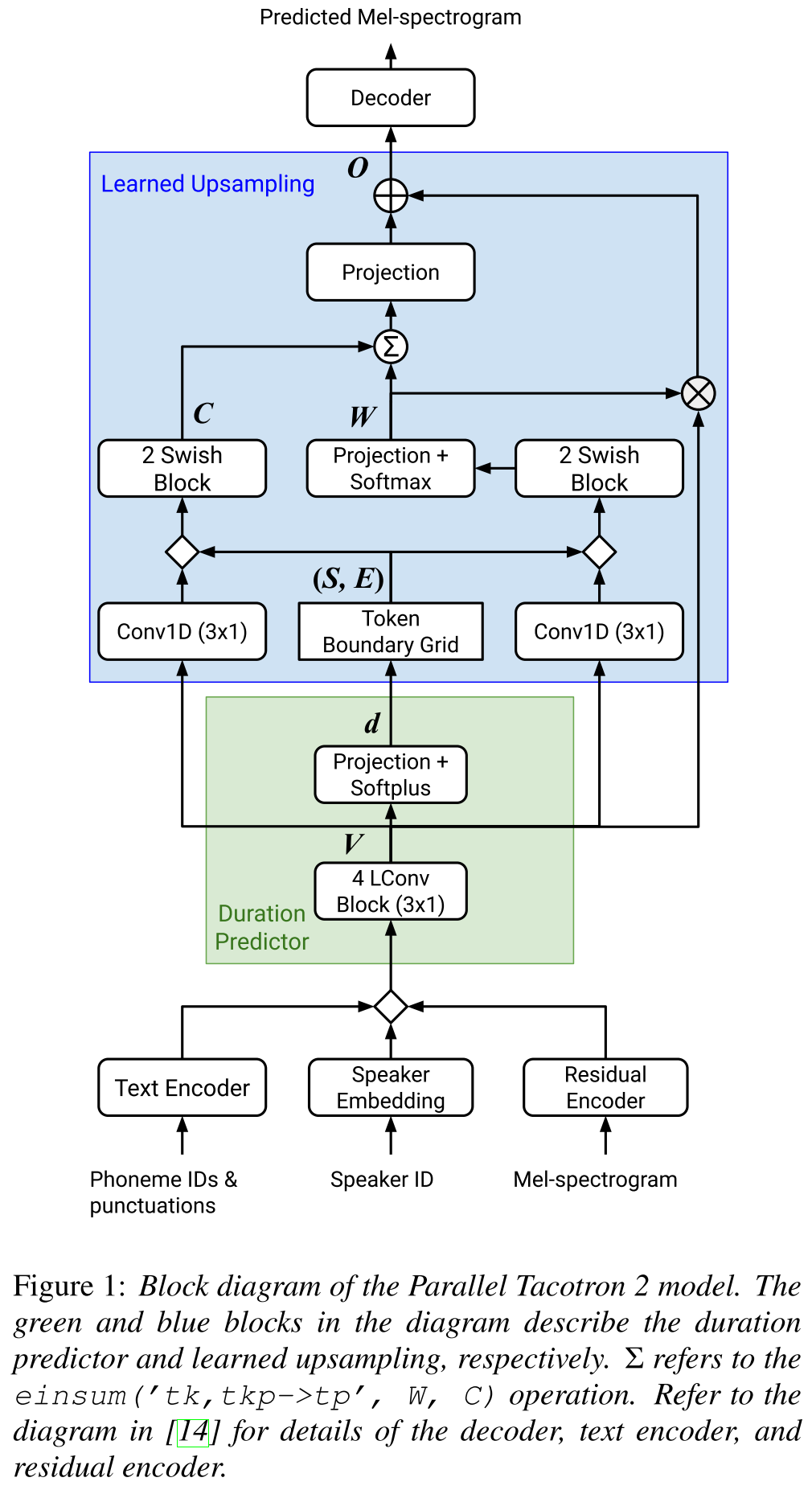
Parallel Tacotron2: http://arxiv.org/abs/2103.14574 (Klicken Sie hier, um zu erweitern)
- Erfordert keine externen Dauerinformationen.
- Löst die Ausrichtungsprobleme zwischen den realen und der Bodenwahrheitsspektrogramme durch Soft-DTW-Verlust.
- Die vorhergesagten Dauer werden durch eine gelernte Umwandlungsfunktion und nicht durch einen Längenregler in die Ausrichtung umgewandelt, um Rundungsprobleme zu lösen.
- Lernt eine Aufmerksamkeitskarte über "Token -Grenznetze", die aus vorhergesagten Dauern berechnet werden.
- Decoder basiert auf 6 "leichten Konvolutionen" Blöcke.
- Ein VAE wird verwendet, um Eingangsspektrogramme in latente Merkmale zu projizieren, und werden mit den CharacterR -Einbettungen als Eingabe für das Netzwerk zusammengeführt.
- Soft-DTW ist rechnerisch intensiv, da es einen paarweisen Differenz für alle Spektrogrammrahmen berechnet. Sie widersprechen es mit einem bestimmten diagonalen Fenster, um den Overhead zu reduzieren.
- Das Ziel der endgültigen Dauer ist die Summe des Dauerverlusts, des VAE -Verlustes und des Spektrogrammverlusts.
- Sie verwenden nur proprietäre Datensätze für die Experimente?
- Erreicht die gleichen MOs mit dem Tacotron2 -Modell und übertrifft Paralleltacotron.
- Demo -Seite : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Code : Bisher kein Code
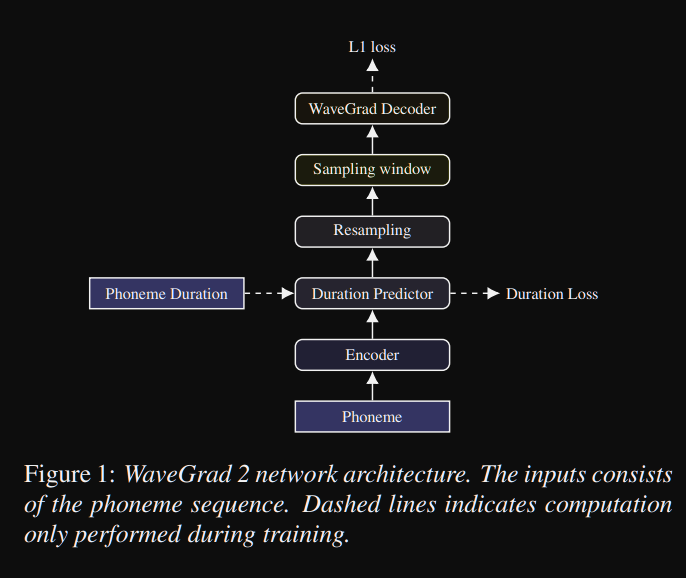
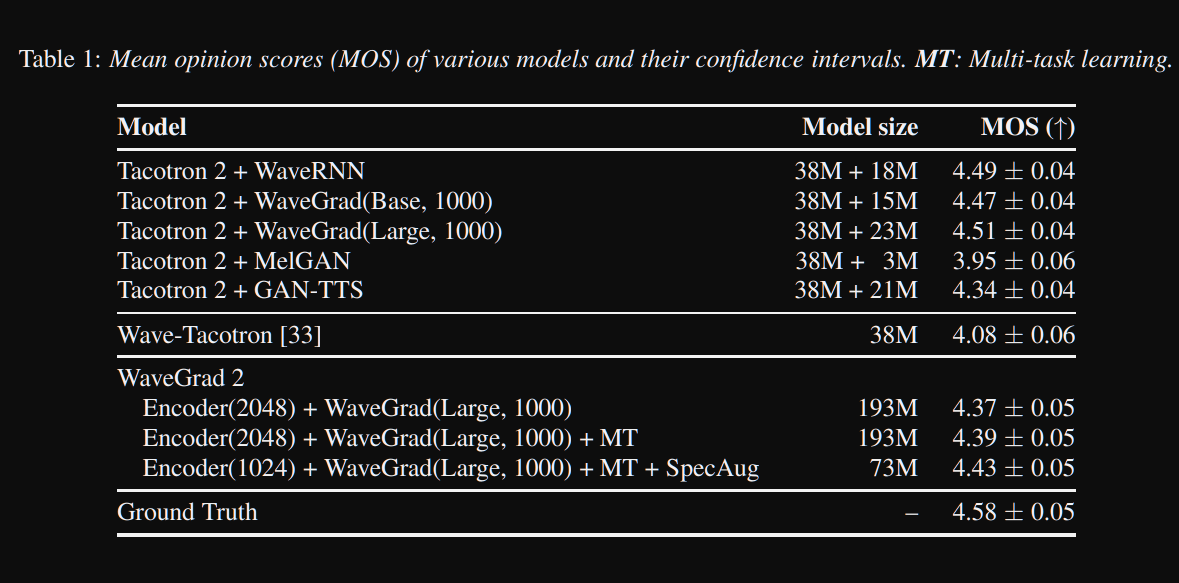
Wavegrad2: https://arxiv.org/pdf/2106.09660.pdf (Klicken Sie hier, um zu erweitern)
- Es berechnet die Rohwellenform direkt aus einer Phonemsequenz.
- Ein Tacotron2 -ähnliches Encodermodell wird verwendet, um eine versteckte Darstellung aus Phonemen zu berechnen.
- Nicht-attentiver Tacotron wie Weichdauer-Prädiktor zur Ausrichtung der versteckten Repräsentation mit der Ausgabe.
- Sie erweitern die verborgene Darstellung mit den vorhergesagten Dauern und probieren ein bestimmtes Fenster, um in eine Wellenform umzuwandeln.
- Sie untersuchten verschiedene Fenstergrößen zwischen 64 und 256 Bildern, die 0,8 und 3,2 Sekunden lang Sprache entsprechen. Sie fanden heraus, dass das größere ist, desto besser.
- Demo -Seite : Bisher nichts
- Code : Bisher kein Code
Multi-Sprecher-Papiere
- Training mit mehreren Sprechern neuronaler Text-zu-Speech-Systeme unter Verwendung von Sprecher-nach-nach-Speech-Korpora-https://arxiv.org/abs/1904.00771
- Deep Voice 2-https://papers.nips.cc/paper/6889-teep-voice-2-multi speaker-neural-text-t-speech.pdf
- Beispiel effiziente adaptive TTS - https://openreview.net/pdf?id=rkzjuoacfx
- Wellenet + Lautsprecher Einbettungsansatz
- Sprachschleife - https://arxiv.org/abs/1707.06588
- Modellierung von latenten Multi -Sprecher
- Übertragungslernen von der Überprüfung der Lautsprecher auf Multispeaker-Text-zu-Speech-Synthese-https://arxiv.org/pdf/1806.04558.pdf
- Anpassung neuer Lautsprecher basierend auf einer kurzen, nicht bezeichneten Stichprobe - https://arxiv.org/pdf/1802.06984.pdf
- Verallgemeinerter End-zu-End-Verlust für die Verifizierung der Sprecher-https://arxiv.org/abs/1710.10467
Expansive Zusammenfassungen
SEMI-superviertes Lernen für die Synthese „Multispeaker Text-to Speech“ unter Verwendung einer diskreten Sprachrepräsentation: http://arxiv.org/abs/2005.08024
- Trainieren Sie ein TTS-Modell mit mehreren Lautsprechern mit nur einer stunde lang gepaarten Daten (Text-to-Voice-Ausrichtung) und mehr ungepaarten (nur Voide).
- Es lernt ein Codebuch mit jedem Codewort entspricht einem einzelnen Phonem.
- Das Codebuch ist mit den gepaarten Daten und dem CTC-Algorithmus an Phoneme ausgerichtet.
- Dieses Codebuch funktioniert wie ein Proxy, um die Phonemsequenz der ungepaarten Daten implizit abzuschätzen.
- Sie stapeln das Tacotron2 -Modell oben, um TTs mithilfe der Codewort -Einbettungen durchzuführen, die vom ersten Teil des Modells generiert wurden.
- Sie besiegten die Benchmark -Methoden in 1 -stündigen, langen Dateneinstellung.
- Sie melden keine voll gepaarten Datenergebnisse.
- Sie haben keine gute Ablationsstudie, die interessant sein könnte, um zu sehen, wie unterschiedliche Teile des Modells zur Leistung beitragen.
- Sie verwenden Griffin-lim als Vocoder, daher gibt es Platz für Verbesserungen.
Demo-Seite: https://ttaoretw.github.io/multispkr-Semi-tts/demo.html
Code: https://github.com/ttaoretw/semi-tts 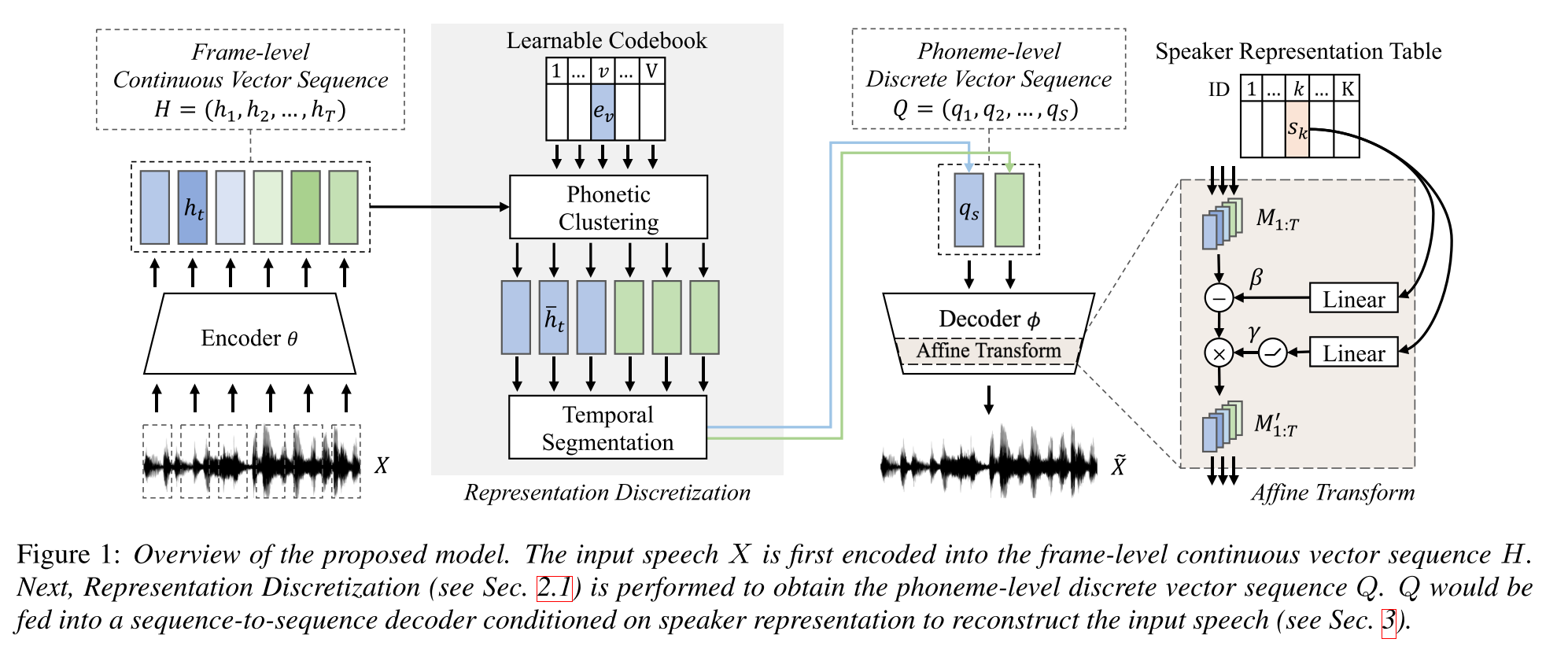
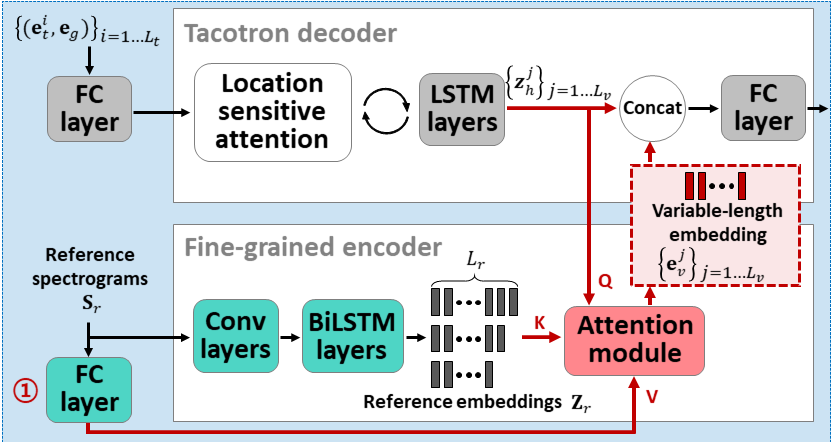
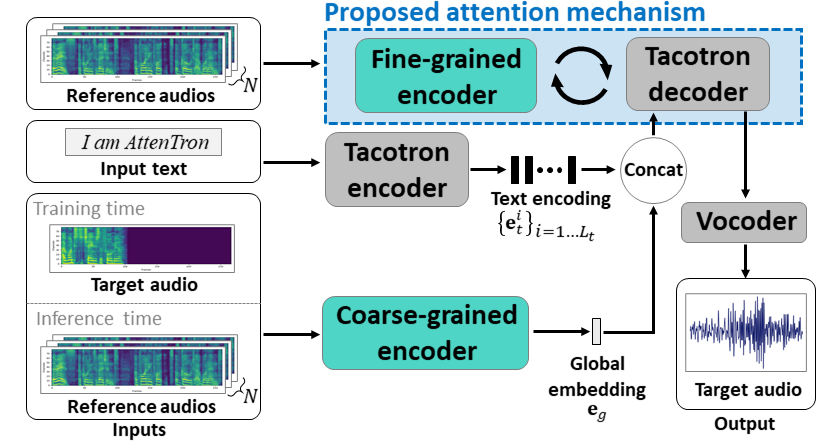
Aufmerksamkeit: Wenige Shot-Text-zu-Speech-Einbetten der aufmerksamkeitsbasierten variablen Länge: https://arxiv.org/abs/2005.08484
- Verwenden Sie zwei Encoder, um lautsprecher abhängige Funktionen zu lernen.
- Grobe Encoder lernt einen globalen Sprecher -Einbettungsvektor basierend auf den bereitgestellten Referenzspektrogrammen.
- Fine Encoder lernt eine variable Länge, die die zeitliche Abmvention in Zusammenarbeit mit einem Aufmerksamkeitsmodul behält.
- Die Aufmerksamkeit wählt wichtige Referenzspektrogrammrahmen für die Synthese der Zielsprache aus.
- Vorhanden Sie das Modell zuerst mit einem einzelnen Lautsprecherdatensatz (LJSpeech für 30.000 ITERS).
- Fein das Modell mit einem Datensatz mit mehreren Lautsprechern einstellen. (VCTK für 70k Iters.)
- Es erreicht im Vergleich zur Verwendung von X-Vektoren aus dem Lautsprecherklassifizierungsmodell und dem VAE-basierten Referenz-Audio-Encoder etwas bessere Metriken.
Demo -Seite: https://hyperconnect.github.io/attentron/
In Richtung Universal Text-to-Speech: http://www.interSpeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
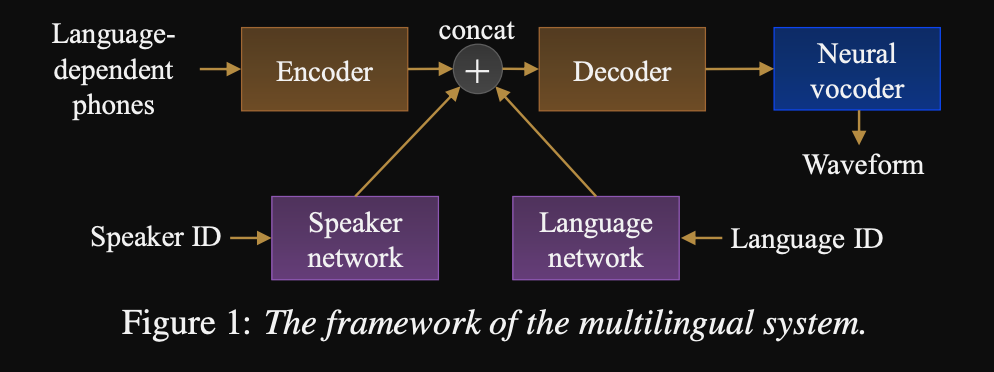
- Ein Framework für eine Sequenz zur Sequenz mehrsprachiger TTs
- Das Modell ist mit einem sehr großen, sehr unausgeglichenen Datensatz trainiert.
- Das Modell kann eine neue Sprache mit 6 Minuten und einen neuen Sprecher mit 20 Sekunden Daten nach dem ersten Training lernen.
- Die Modellarchitektur ist ein transformatorbasiertes Encoder-Decoder-Netzwerk mit einem Speaker-Netzwerk und einem Sprachnetzwerk für die Lautsprecher- und Sprachkonditinonierung. Die Ausgänge dieser Netzwerke werden mit der Encoder -Ausgabe verkettet.
- Die Konditionierungsnetzwerke nehmen einen One-Hot-Vektor, der den Sprecher oder die Sprach-ID darstellt, und projiziert ihn auf eine Konditionierungsdarstellung.
- Sie verwenden einen Wavenet-Vokoder zum Umwandeln der vorhergesagten Melspektrogramme in den Wellenformausgang.
- Sie verwenden Sprachabhängige Phonemes -Eingaben, die nicht zwischen Sprachen geteilt werden.
- Sie probieren jede Charge basierend auf der umgekehrten Häufigkeit jeder Sprache im Datensatz. Daher hat jede Trainingseinheit eine einheitliche Verteilung über Sprachen, die das Sprachungleichgewicht im Trainingsdatensatz lindert.
- Für das Erlernen neuer Sprecher/Sprachen stimmen sie das Encoder-Decoder-Modell mit den Konditionierungsnetzwerken gut ab. Sie trainieren das Wellenetmodell nicht.
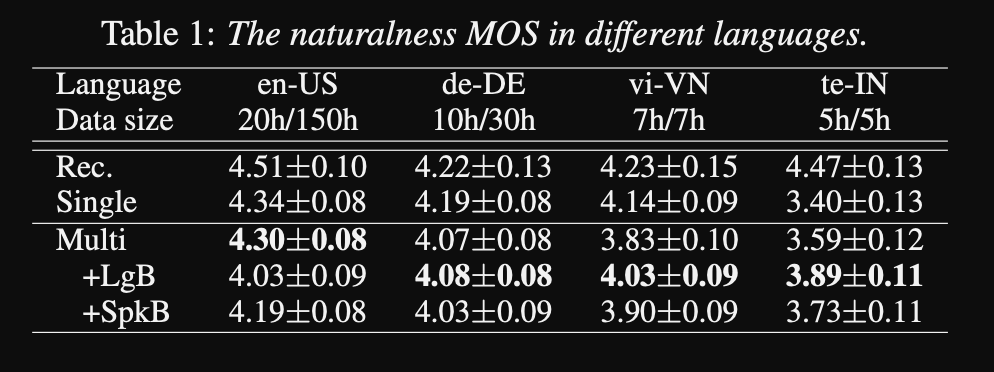
- Sie verwenden 1250 Stunden professionelle Aufnahmen aus 50 Sprachen für das Training.
- Sie verwenden eine 16 -kHz -Abtastrate für alle Audio -Proben und die Trimmschweigen am Anfang und am Ende jedes Clips.
- Sie verwenden 4 V100 -GPUs für das Training, erwähnen jedoch nicht, wie lange sie das Modell ausgebildet haben.
- Die Ergebnisse zeigen, dass Einzellautsprechermodelle besser sind als der vorgeschlagene Ansatz in der MOS -Metrik.
- Die Verwendung von Konditionierungsnetzwerken ist auch für die Langschwanzsprachen im Datensatz wichtig, da sie die MOS-Metrik für sie verbessern, aber die Leistung für die Hochresssprachen beeinträchtigen.
- Wenn sie einen neuen Lautsprecher hinzufügen, beobachten sie, dass die Verwendung von mehr als 5 Minuten Daten die Modellleistung abbaut. Sie behaupten, da diese Aufzeichnungen nicht so sauber sind wie die ursprünglichen Aufnahmen, beeinflusst mehr von ihnen die allgemeine Leistung des Modells.
- Das mehrsprachige Modell kann mit nur 6 Minuten Daten für neue Lautsprecher und Sprachen trainieren, während ein einzelnes Lautsprechermodell 3 Stunden für den Training benötigt und nicht einmal ähnliche MOS-Werte wie das 6-minütige Mehrlingsmodell erreichen kann.
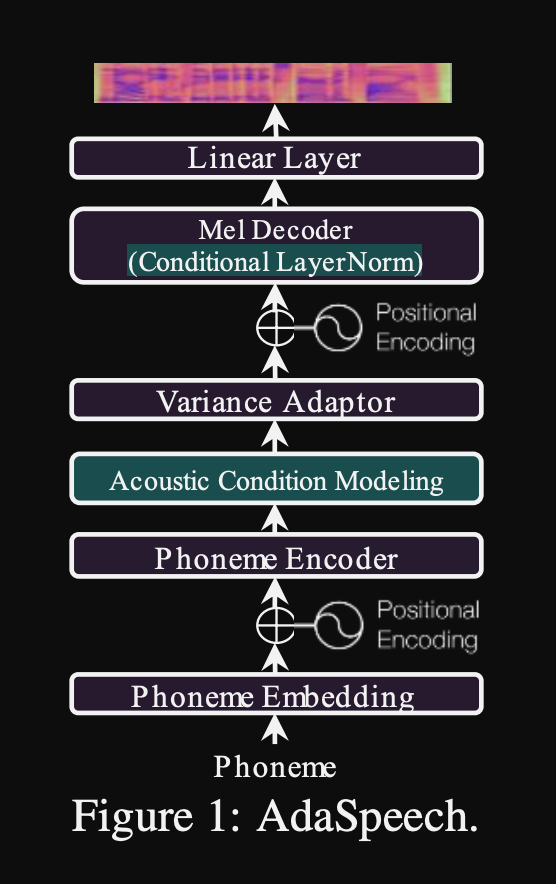
Adaspeech: adaptiver Text zur Sprache für benutzerdefinierte Stimme: https://openreview.net/pdf?id=drynvt7gg4l
- Sie schlugen ein System vor, das sich an verschiedene akustische Eingaben von Benutzern anpassen kann, und es verwendet die minimale Anzahl von Parametern, um dies zu erreichen.
- Die Hauptarchitektur basiert auf dem Fastspeech2 -Modell, das Pitch- und Varianz -Prädiktoren verwendet, um die feineren Granularitäten der Eingabessprache zu erlernen.
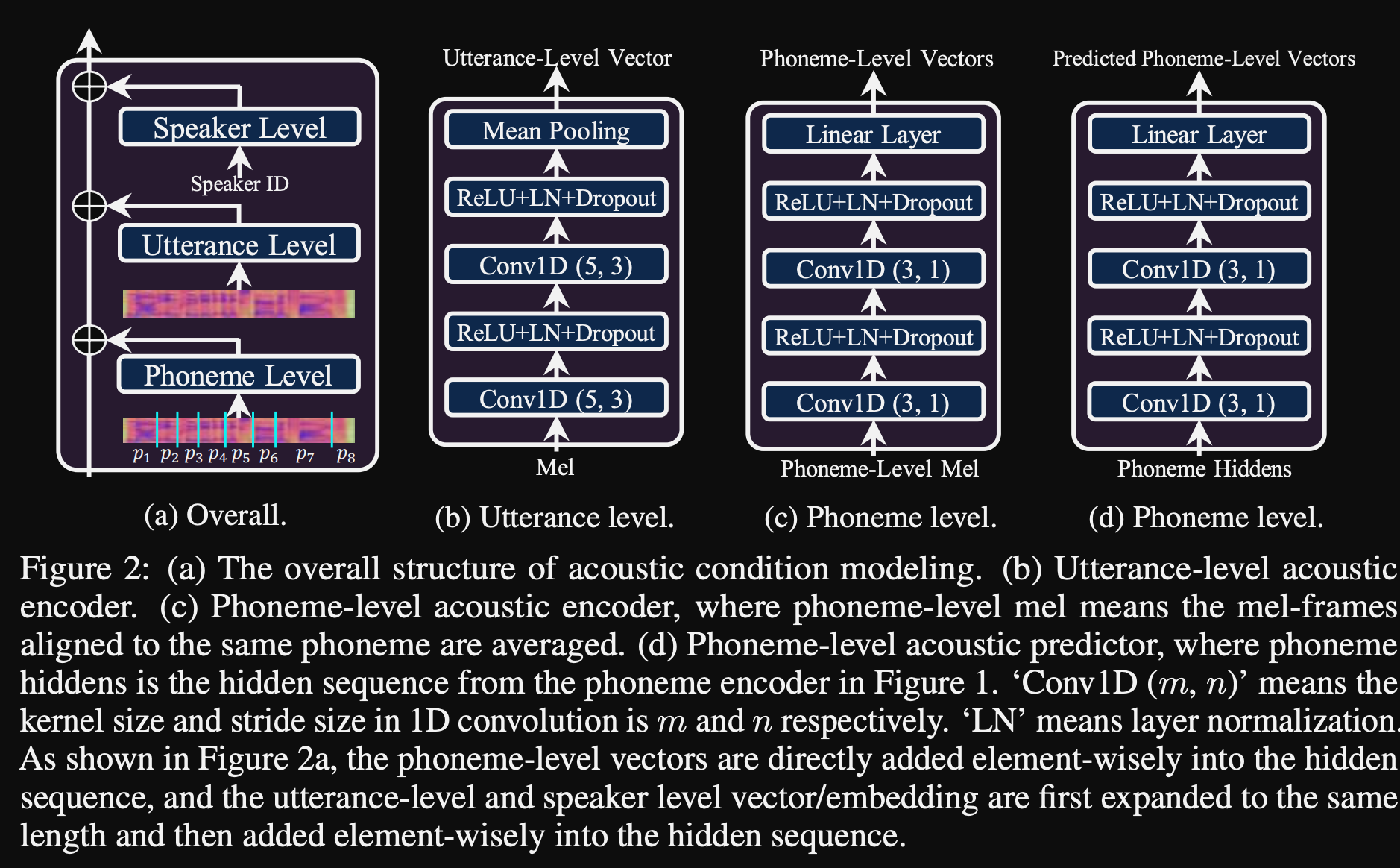
- Sie verwenden 3 zusätzliche Konditionierungsnetzwerke.
- Äußerungsstufe. Es nimmt Melspektrogramm der Referenzsprache als Eingabe an.
- Phonem -Ebene. Es dauert Melspektrogramme auf Phonemebene als Eingabe und berechnet Konditionierungsvektoren auf Phonemebene. Melspektrogramme auf Phonemebene werden durch Einnahme des durchschnittlichen Spektrogramms in der Dauer jedes Phonems berechnet.
- Phonem Level 2. Es dauert Phonem -Encoderausgänge als Eingänge. Dies unterscheidet sich vom oben genannten Netzwerk, indem nur die Phoneminformationen verwendet werden, ohne die Spektrogramme zu sehen.
- Alle diese Konditionierungsnetzwerke und der Back-Bone Fastspeech2 verwendet Ebenennormalisierungsschichten.
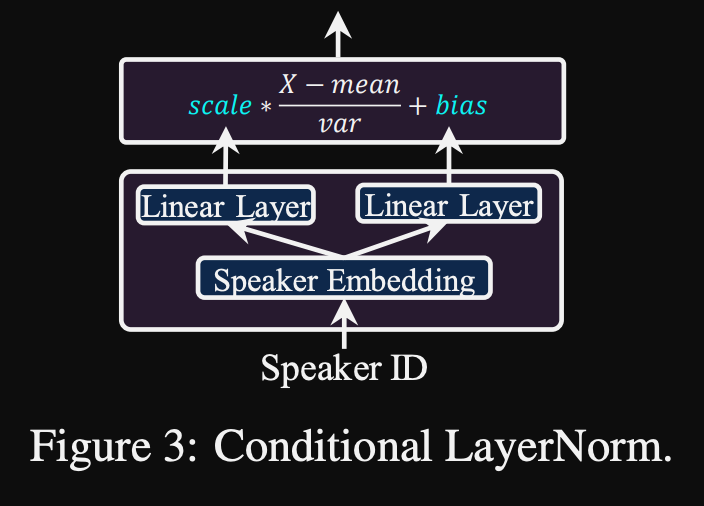
- Bedingte Schichtnormalisierung. Sie schlagen nur die Skala- und Vorspannungsparameter jeder Schichtnormalisierungsschicht vor, wenn das Modell für einen neuen Lautsprecher fein abgestimmt ist. Sie trainieren ein Lautsprecher -Konditionierungsmodul für jede Normschicht, die eine Skala und einen Verzerrungswerte ausgibt. (Sie verwenden ein Lautsprecher -Konditionierungsmodul pro Transformatorblock.)
- Dies bedeutet, dass Sie das Lautsprecher -Konditionierungsmodul für jeden neuen Lautsprecher nur speichern und die Skala- und Verzerrungswerte bei Folgerungen vorhersagen, wenn Sie den Rest des Modells gleich halten.
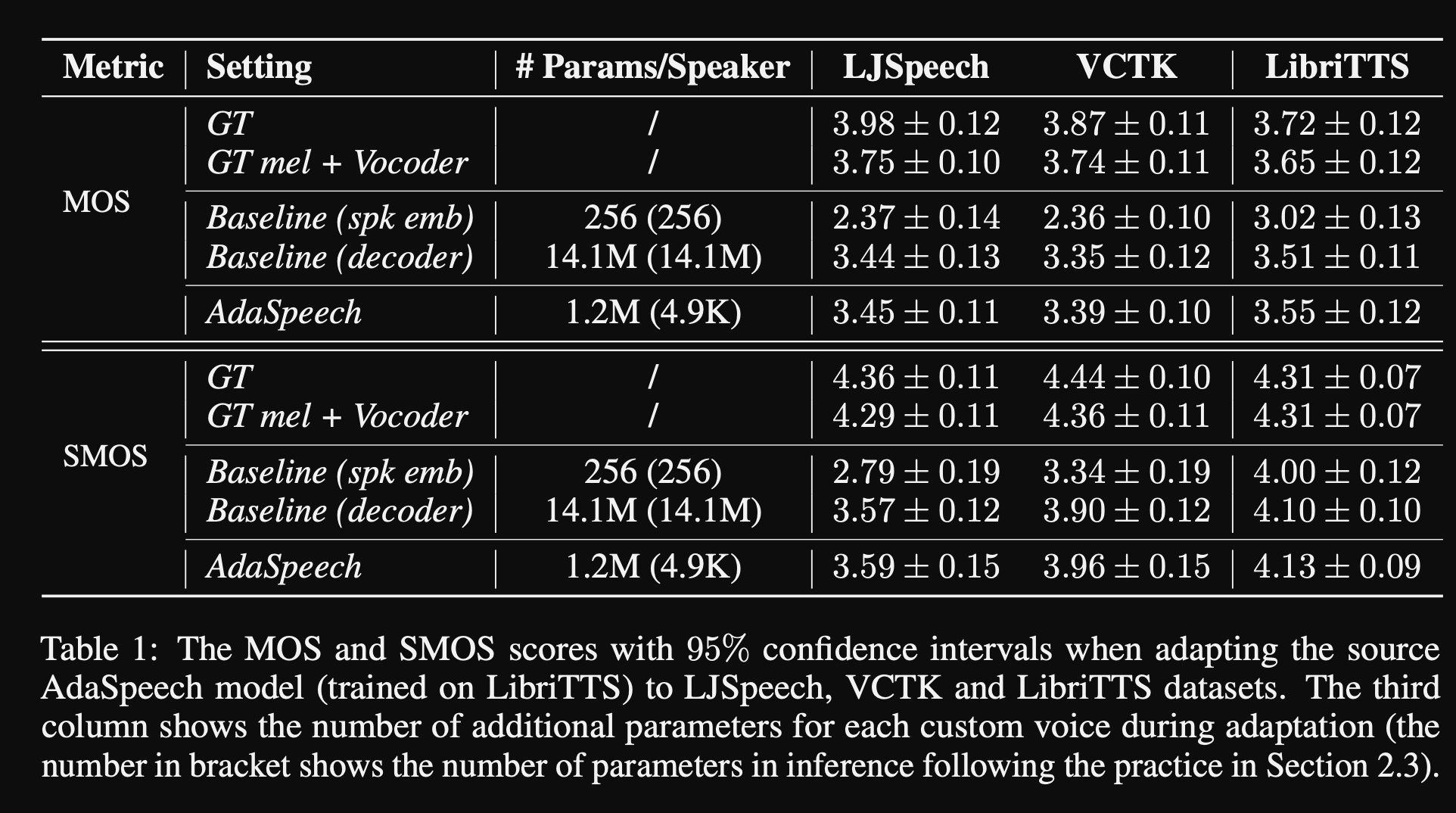
- In den Experimenten trainieren sie das Modell auf Libritts Dataset vor und optimieren Sie es mit VCTK und LJSpeech
- Die Ergebnisse zeigen, dass die Verwendung der Normalisierung der bedingten Schicht besser erreicht ist als ihre beiden Baselines, die nur Lautsprecher einbetten und decoders netzwerk fein abgemessen sind.
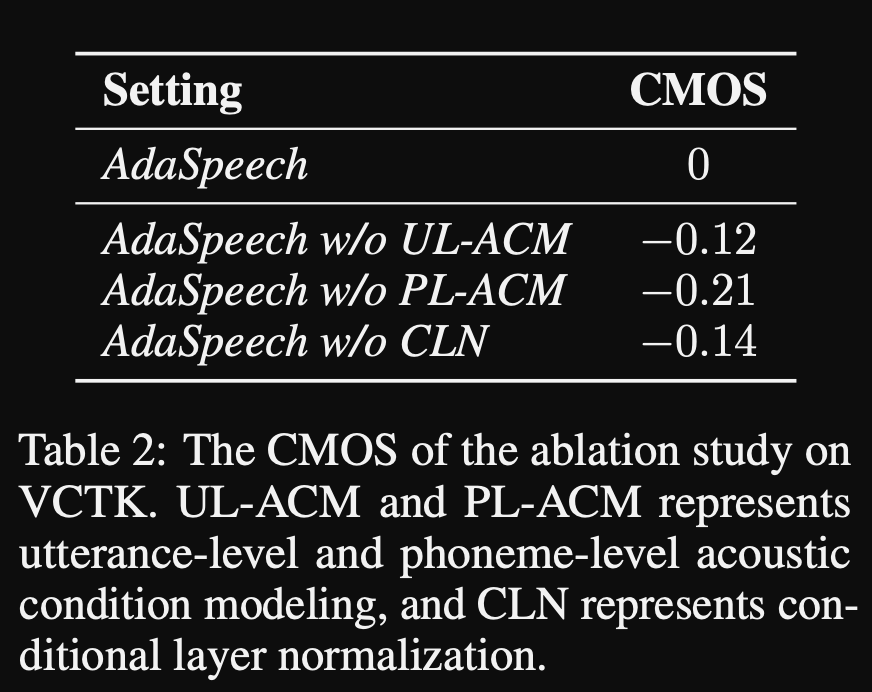
- Ihre Ablationsstudie zeigt, dass der bedeutendste Teil des Modells das Netzwerk „Phoneme Level“ ist, gefolgt von einer bedingten Normalisierung der Schicht und dem "Äußerungsebene" -Netzwerk in einer Reihenfolge.
- Eine wichtige Abwärtsseite des Papiers ist, dass es fast keinen Vergleich mit der Literatur gibt und es schwieriger ist, die Ergebnisse objektiv zu beurteilen.
Demo -Seite: https://speechresearch.github.io/adaspeech/

Aufmerksamkeit
- Standort-Relative Aufmerksamkeitsmechanismen für eine robuste Langformspeech-Synthese-https://arxiv.org/pdf/1910.10288.pdf
Vocoder
Melgan: https://arxiv.org/pdf/1910.06711.pdf
Parallelwavegan: https://arxiv.org/pdf/1910.11480.pdf
- Multi -Skala -STFT -Verlust
- ~ 1m Modellparameter (sehr klein)
- Etwas schlechter als Ravernn
Verbesserung der FFTNet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
Fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Rekonstruktion der Sprachwellenform unter Verwendung von Faltungsfisch -NeuralNetworks mit Rauschen und periodischen Eingängen
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
Um robuste universelle Vokodierung zu erreichen
- https://arxiv.org/pdf/1811.06292.pdf
LPCNET
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
Aufregung
- https://arxiv.org/pdf/1811.04769v3.pdf
Gelp: Lineare Vorhersage für die Sprachsynthese Frommel-Spektrogramm
- https://arxiv.org/pdf/1904.03976v3.pdf
High -Fidelity -Sprachsynthese mit gegnerischen Netzwerken: https://arxiv.org/abs/1909.11646
- GAN-TTS, End-to-End-Sprachsynthese
- Verwendet Dauer und sprachliche Merkmale
- Dauer und akustische Merkmale werden durch zusätzliche Modelle vorhergesagt.
- Zufälliger Fenster -Diskriminator: Nehmen Sie nicht die gesamte Sprachprobe, sondern die zufälligen Fenster ein.
- Mehrere RWDs. Einige bedingte und andere bedingungslose. (Konditioniert auf Eingangsfunktionen)
- Punchline: Verwenden Sie zufällig abgetastete Fenster mit unterschiedlichen Fenstergrößen für D.
- Shared-Ergebnisse klingen mechanisch klingen, die die Grenzen nicht-neuraler akustischer Merkmale anzeigen.
Multi-Band Melgan: https://arxiv.org/abs/2005.05106
- Verwenden Sie Pwgan-Verluste anstelle von Feature-Matching-Verlusten.
- Die Verwendung eines größeren Empfängnisfeldes steigert die Modellleistung signifikant.
- Generator Vorabbau für 200k ITERS.
- Multi-Band-Sprachsignalvorhersage. Die Ausgabe ist Summe von 4 verschiedenen Bandvorhersagen mit PQMF -Synthesefiltern.
- Das Multi-Band-Modell hat 1,9 m Parameter (ziemlich klein).
- Behauptet, 7x schneller zu sein als Melgan
- Auf einem chinesischen Datensatz: MOS 4.22
Wellenlow: https://arxiv.org/abs/1811.00002
- Sehr großes Modell (268 m Parameter)
- Es ist schwer zu trainieren, da es bei 12 GB GPU nur die Chargengröße 1 benötigt.
- Echtzeit-Inferenz aufgrund der Verwendung von Konvolutionen.
- Basierend auf invertierbarem Normalisierungsfluss. (Tolles Tutorial https://blog.evjang.com/2018/01/nf1.html)
- Das Modell lernt und unsichtbare Zuordnung von Audioproben zu Melspektrogrammen mit maximalem Wahrscheinlichkeitsverlust.
- Im Inferenznetz wird das Netzwerk in umgekehrter Richtung ausgeführt und Mel-Specs werden in Audio-Proben umgewandelt.
- Das Training wurde mit 8 NVIDIA V100 mit 32 GB RAM, Stapelgröße 24 (teuer) durchgeführt.
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, Code: https://github.com/tianrengao/squeeecewave
- ~ 5-13x schneller als Echtzeit
- Wellenlow Redanduncies: Lange Audio-Proben, Upsamples mel-Specs, große Kanalabmessungen in der WN-Funktion.
- Fixes: Mehr, aber kürzere Audioproben als Eingabe, (L = 2000, C = 8 gegenüber L = 64, C = 256)
- L = 64 entspricht der Mel-Spec-Auflösung, so dass kein Up-Sampling erforderlich ist.
- Verwenden Sie die tiefe trennbare Konvolutionen in WN-Modulen.
- Verwenden Sie regelmäßige Faltung anstelle von erweitert, da Audioproben kürzer sind.
- Teilen Sie die Ausgaben des Moduls nicht in die Rest- und Netzwerkausgabe, vorausgesetzt, diese Vektoren sind nahezu identisch.
- Das Training wurde mit Titan RTX 24 GB Stapelgröße 96 für 600.000 Iterationen durchgeführt.
- MOS auf LJSpeech: Waveglow - 4,57, Squeezewave (L = 128 C = 256) - 4,07 und Squeezewave (L = 64 C = 256) - 3,77
- Das kleinste Modell hat 21.000 Proben pro Sekunde auf Raspi3.
Wanderon: https://arxiv.org/pdf/2009.00713.pdf
- Es basiert auf Wahrscheinlichkeitsdiffusion und Lagenvin -Dynamik
- Die Grundidee besteht darin, eine Funktion zu erlernen, die eine bekannte Verteilung iterativ auf Datenverteilung abzubereiten.
- Sie melden einen Echtzeitfaktor von 0,2 für eine GPU, aber die CPU-Leistung wird nicht geteilt.
- Im folgenden Beispielcode berichtet der Autor, dass das Modell nach 2 Tagen Training auf einer einzelnen GPU konvergiert.
- Die MOS -Ergebnisse auf dem Papier sind nicht kompliziert genug, zeigen jedoch eine vergleichbare Leistung mit bekannten Modellen wie Rega und Wavenet.
Code: https://github.com/ivanvovk/wavegrad 
Aus dem Internet (Blogs, Videos usw.)
Videos
Papierdiskussion
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Gespräche
- Sprechen Sie über das Schieben der Grenze des neuronalen Textes-zu-Sprachs von Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- Sprechen Sie über generative modellbasierte Text-zu-Sprache-Synthese von Heiga Zen, 2017
- Video: https://youtu.be/nsrsrytkkt8
- Folie: https://research.google.com/pubs/pub45882.html
- Tutorials zur neuronalen parametrischen Text-zu-Sprache-Synthese bei Isca odyessy 2020, von Xin Wang, 2020
- Video: https://youtu.be/wce7Sycdzai
- Folie: http://tonywangx.github.io/slide.html#dec-2020
- ISCA Sprachverarbeitungskurs auf neuronalen Vocoder, 2022
- Grundkomponenten der neuronalen Vocoder: https://youtu.be/m833q5i-zys
- Deep Generative Models für die Sprachkomprimierung (LPCNET): https://youtu.be/7ksnfx3plgw
- Neuronale automatisch-tergressive, Source-Filter- und Glottal-Vocoder: https://youtu.be/gprmxdberx00
- Folie: http://tonywangx.github.io/slide.html#jul-2020
- Sprachsynthese aus neuronaler Dekodierung gesprochener Sätze | AISC: https://www.youtube.com/watch?v=mndtmdpmnmo
- Generative Text-to-Speech-Synthese: https://www.youtube.com/watch?v=j4MVeanging
- Sprachsynthese für die Gaming-Branche: https://www.youtube.com/watch?v=aohaye4a-2q
Allgemein
- Moderne Text-to-Speech-Systeme Review: https://www.youtube.com/watch?v=8rxlsc-zcry
Jupyter -Notizbücher
- Tutorials zu ausgewählten neuronalen Vokodern: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
Blogs
- Text zu Sprache Deep Learning Architekturen: http://www.erogol.com/text-speech-yep-learning-architektures/


