(Jangan ragu untuk menyarankan perubahan)
Dokumen
- Gabungan representasi fonem dan char: https://arxiv.org/pdf/1811.07240.pdf
- Pembelajaran Transfer Tacotron: https://arxiv.org/pdf/1904.06508.pdf
- Waktu fonem dari perhatian: https://ieexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Pelatihan Semi-Dijelas untuk Meningkatkan Efisiensi Data dalam Sintesis Pidato End-to-End-https://arxiv.org/pdf/1808.10128.pdf
- Mendengarkan Saat Berbicara: Rantai Pidato oleh Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Kehilangan end-to-end yang dihasilkan untuk verifikasi speaker: https://arxiv.org/pdf/1710.10467.pdf
- ES-TACOTRON2: multi-tugas Tacotron 2 dengan perkiraan jaringan pra-terlatih untuk mengurangi masalah kelebihan kelebihan: https://www.mdpi.com/2078-2489/10/4/131/pdf
- Melawan kelembaban berlebihan
- FastSpeech: https://arxiv.org/pdf/1905.09263.pdf
- Belajar Bernyanyi Dari Pidato: https://arxiv.org/pdf/1912.10128.pdf
- TTS-GAN: https://arxiv.org/pdf/1909.11646.pdf
- Mereka menggunakan durasi dan fitur linguistik untuk tts en2en.
- Dekat dengan kinerja Wavenet.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Durasi Tacotron yang sadar
- Melnet: https://arxiv.org/abs/1906.01083
- Aligntts: https://arxiv.org/pdf/2003.01950.pdf
- Dekomposisi ucapan tanpa pengawasan melalui kemacetan informasi triple
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Aliran Autoregressive terbalik pada arsitektur seperti tacotron
- Waveglow sebagai Vocoder.
- Gaya ucapan menanamkan dengan campuran model Gaussian.
- Modelnya besar dan lebih tinggi dari vanilla tacotron
- Nilai MOS sangat baik daripada implementasi tacotron publik.
- Sistem teks-ke-speech yang dapat dilatih secara efisien berdasarkan jaringan konvolusional yang dalam dengan perhatian terpandu: https://arxiv.org/pdf/1710.08969.pdf
Ringkasan yang luas
END-to-END TEXT-to-speech: http://arxiv.org/abs/2006.03575 (klik untuk memperluas)
- end2end feed-forward tts learning.
- Penyelarasan karakter telah dilakukan dengan modul Aligner yang terpisah.
- Aligner memprediksi panjang masing -masing karakter. - Lokasi tengah char ditemukan Wrt total panjang karakter sebelumnya. - Posisi char diinterpolasi dengan jendela Gaussian WRT panjang audio yang sebenarnya.
- Output audio dihitung dalam domain mu-hukum. (Saya tidak punya alasan untuk ini)
- Gunakan hanya 2 Secs Audio Windows untuk Traning.
- Generator Gan-TTS digunakan untuk menghasilkan sinyal audio.
- RWD digunakan sebagai diskriminator tingkat audio.
- MELD: Mereka menggunakan arsitektur Biggan-Deep sebagai diskriminator tingkat spektrogram yang mengatur masalah sebagai rekonstruksi gambar.
- Kehilangan spektrogram
- Menggunakan hanya umpan balik permusuhan tidak cukup untuk mempelajari keberpihakan char. Mereka menggunakan kerugian spektrogram b/w yang diprediksi spektrogram dan spesifikasi kebenaran tanah.
- Perhatikan bahwa model memprediksi sinyal audio. Spektrogram di atas dihitung dari audio yang dihasilkan.
- Pembungkus waktu dinamis digunakan untuk menghitung penyelarasan biaya minimal b/w yang dihasilkan spektrogram dan kebenaran tanah.
- Ini melibatkan pendekatan pemrograman yang dinamis untuk menemukan penyelarasan biaya minimal.
- Kehilangan panjang aligner digunakan untuk menghukum pelurus karena memprediksi berbeda dari panjang audio nyata.
- Mereka melatih model dengan dataset multi speaker tetapi melaporkan hasil pada speaker berkinerja terbaik.
- Studi Ablasi Pentingnya masing -masing komponen: (panjang dan spektrogramloss)> rwd> meld> fonem> multiseakerDataSet.
- 2 sen saya: Ini adalah model umpan ke depan yang menyediakan sintesis ucapan akhir-2 tanpa perlu melatih model vocoder yang terpisah. Namun, ini adalah model yang sangat rumit dengan banyak hiperparameter dan detail implementasi. Juga hasil akhirnya tidak dekat dengan keadaan seni. Saya pikir kita perlu menemukan algoritma spesifik untuk mempelajari keberpihakan karakter yang akan mengurangi kebutuhan tunning kombinasi algoritma yang berbeda.
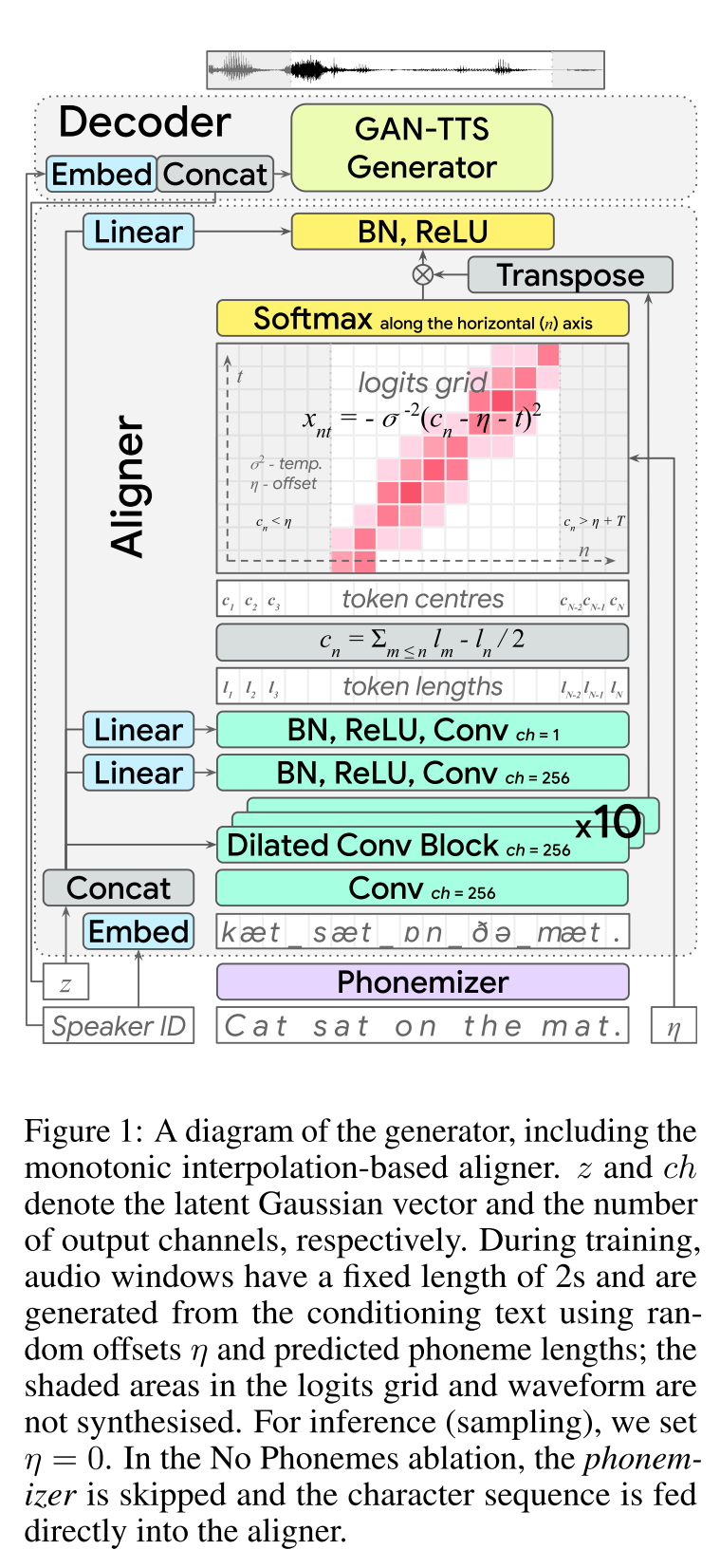
Pidato cepat2: http://arxiv.org/abs/2006.04558 (klik untuk memperluas)
- Gunakan durasi fonem yang dihasilkan oleh MFA sebagai label untuk melatih regulator panjang.
- Mereka menggunakan frame level f0 dan l2 spektrogram norma (informasi varians) sebagai fitur tambahan.
- Modul Prediktor Varians memprediksi informasi varians pada waktu inferensi.
- Peningkatan hasil studi ablasi: model <model + l2_norm <model + l2_norm + f0
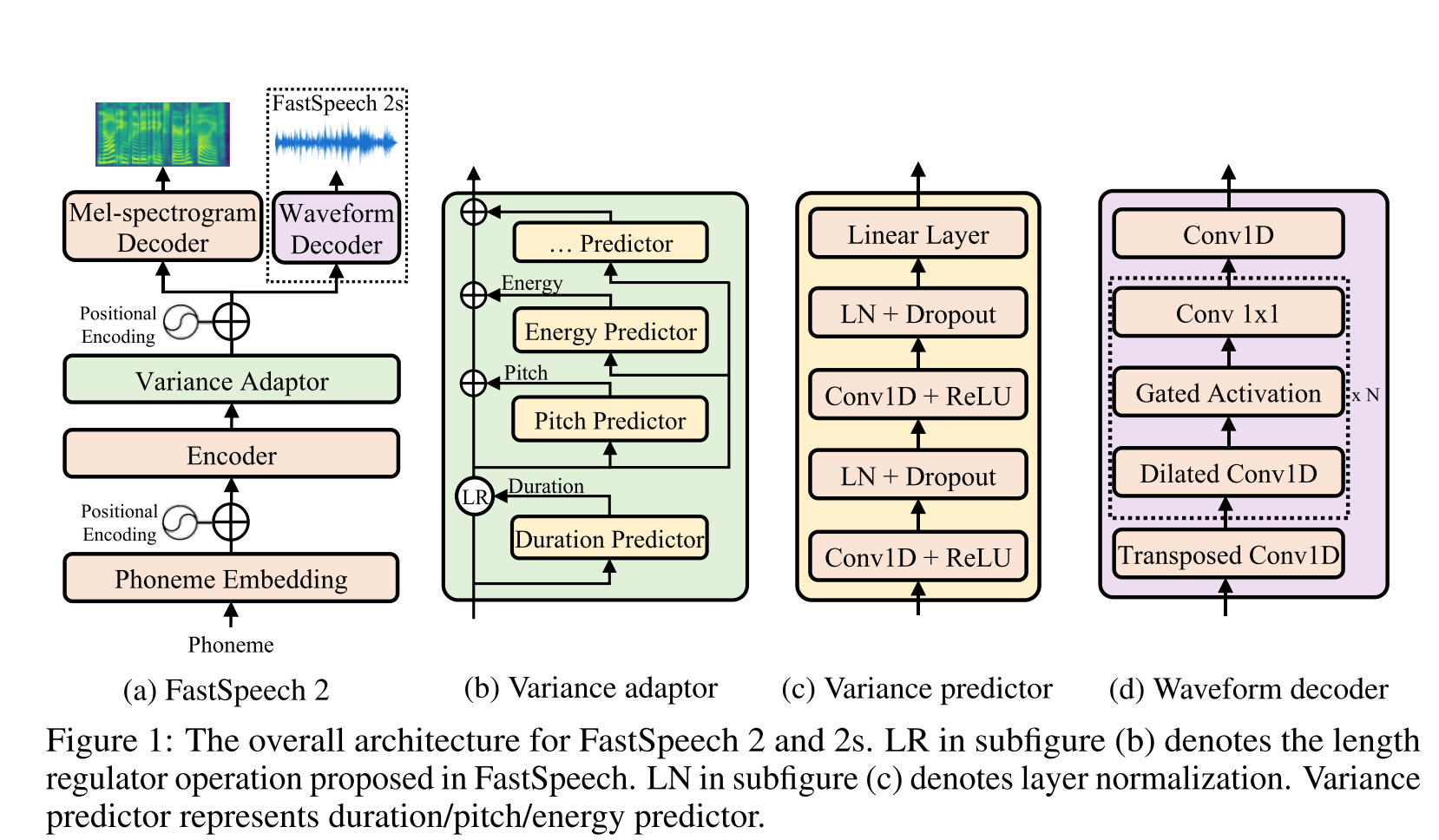
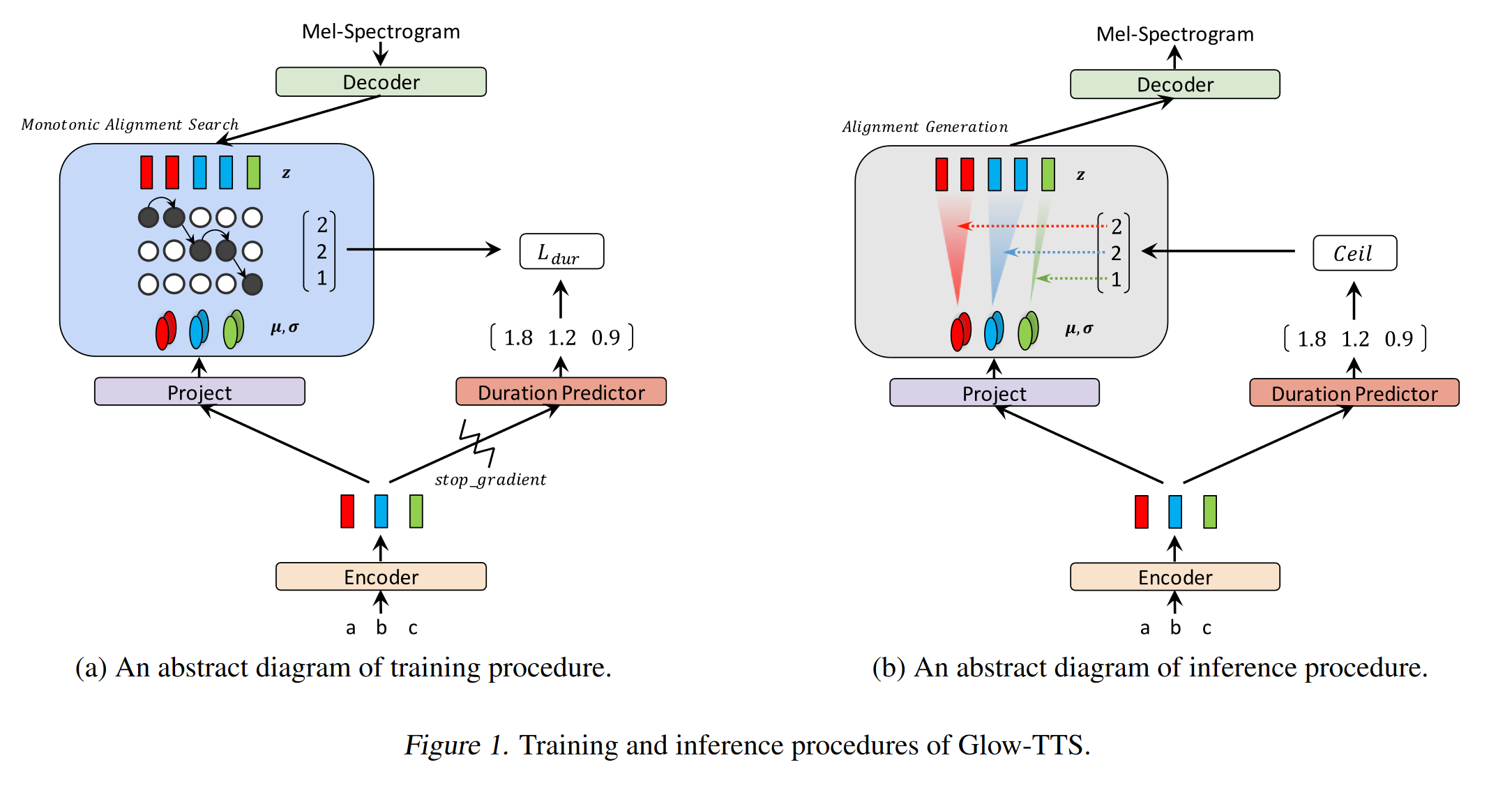
Glow-tts: https://arxiv.org/pdf/2005.11129.pdf (klik untuk memperluas)
- Gunakan pencarian penyelarasan monotonik untuk mempelajari teks dan spektrogram B/W Alignment
- Penyelarasan ini digunakan untuk melatih prediktor durasi untuk digunakan pada inferensi.
- Encoder memetakan setiap karakter ke distribusi Gaussian.
- Decoder Maps Setiap bingkai spektrogram ke vektor laten menggunakan aliran normalisasi (lapisan cahaya)
- Output encoder dan dekoder disejajarkan dengan MAS.
- Pada setiap iterasi terlebih dahulu penyelarasan yang paling mungkin ditemukan oleh MAS dan penyelarasan ini digunakan untuk memperbarui parameter mode.
- Prediktor durasi dilatih untuk memprediksi jumlah bingkai spektrogram untuk setiap karakter.
- Pada inferensi hanya prediktor durasi yang digunakan sebagai ganti mas
- Encoder memiliki arsitektur transformator TTS dengan 2 pembaruan
- Alih -alih pengkodean posisi absolut, mereka menggunakan pengkodean posisi yang realtif.
- Mereka juga menggunakan koneksi residu untuk prenet enkoder.
- Decoder memiliki arsitektur yang sama dengan model cahaya.
- Mereka melatih model tunggal dan multi-speaker.
- Ini ditunjukkan secara eksperimental, GLOW-TTS lebih kuat terhadap kalimat panjang dibandingkan dengan Tacotron2 asli
- 15x lebih cepat dari tacotron2 saat inferensi
- 2 sen saya: Sampel mereka terdengar tidak sealami Tacotron. Saya percaya model perhatian normal masih menghasilkan lebih banyak ucapan alami karena perhatian belajar memetakan karakter untuk memodelkan output secara langsung. Namun, menggunakan GLOW-TTS mungkin merupakan alternatif yang baik untuk dataset keras.
- Sampel: https://github.com/jaywalnut310/glow-tts
- Repositori: https://github.com/jaywalnut310/glow-tts
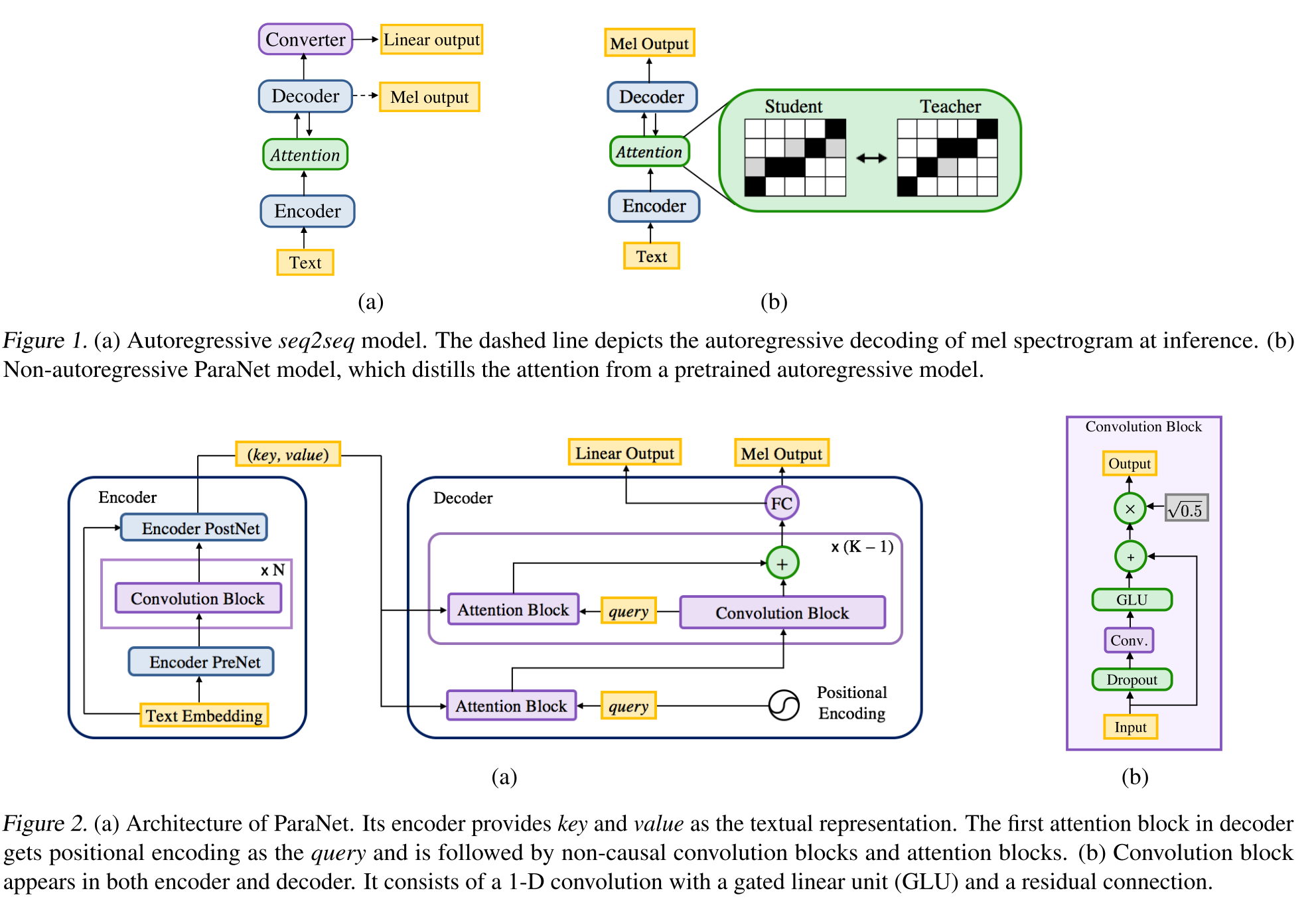
Non-autoregressive Neural Text-to-speech: http://arxiv.org/abs/1905.08459 (klik untuk memperluas)
- Derivasi model suara dalam 3 menggunakan lapisan konvolusional non-kausal.
- Paradigma guru-siswa untuk melatih siswa Annon-Autoregressive dengan ganda perhatian dari model guru autoregresif.
- Guru digunakan untuk menghasilkan keberpihakan teks-ke-spektrogram untuk digunakan oleh model siswa.
- Model ini dilatih dengan dua fungsi kerugian untuk penyelarasan perhatian dan pembuatan spektrogram.
- Blok Multi Attention memperbaiki lapisan perataan demi perhatian.
- Siswa menggunakan perhatian produk DOT dengan kueri, kunci dan vektor nilai. Kueri hanyalah vektor pengkodean positinal. Kunci dan nilainya adalah output encoder.
- Model yang diusulkan sangat terkait dengan pengkodean posisi yang juga bergantung pada nilai konstan yang berbeda.
Konsistensi Decoder Ganda: https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder-consistency (klik untuk memperluas)
- Model ini menggunakan arsitektur seperti tacotron tetapi dengan 2 decoder dan postnet.
- DDC menggunakan dua decoder sinkron menggunakan laju reduksi yang berbeda.
- Decoder menggunakan tingkat reduksi yang berbeda sehingga mereka menghitung output dalam granularitas yang berbeda dan mempelajari berbagai aspek data input.
- Model ini menggunakan konsistensi antara kedua decoder ini untuk meningkatkan ketahanan penyelarasan teks-ke-spektrogram yang dipelajari.
- Model ini juga menerapkan penyempurnaan pada output dekoder akhir dengan menerapkan postnet secara iteratif beberapa kali.
- DDC menggunakan normalisasi batch dalam modul Prenet dan menjatuhkan lapisan putus sekolah.
- DDC menggunakan pelatihan bertahap untuk mengurangi total waktu pelatihan.
- Kami menggunakan generator Melgan multi-band sebagai vokoder yang dilatih dengan beberapa diskriminator jendela acak secara berbeda dari karya aslinya.
- Kami dapat melatih model DDC hanya dalam 2 hari dengan GPU tunggal dan model terakhir dapat menghasilkan lebih cepat daripada pidato real-time pada CPU. Halaman demo: https://erogol.github.io/ddc-samples/ kode: https://github.com/mozilla/tts
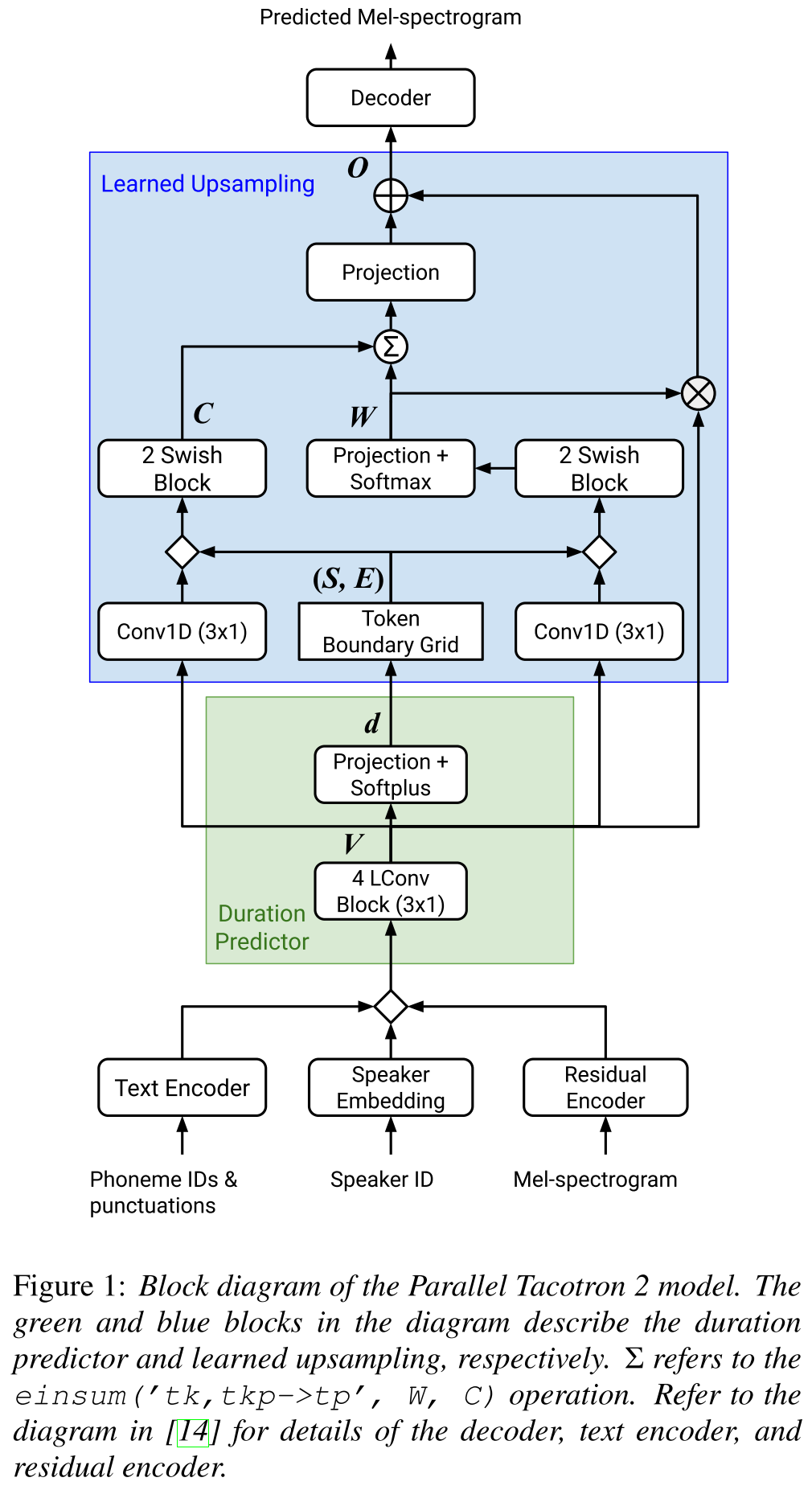
Parallel Tacotron2: http://arxiv.org/abs/2103.14574 (klik untuk memperluas)
- Tidak memerlukan informasi durasi eksternal.
- Memecahkan masalah penyelarasan antara spektrogram nyata dan kebenaran-kebenaran oleh kehilangan-DTW soft-DTW.
- Durasi yang diprediksi dikonversi menjadi penyelarasan dengan fungsi konversi yang dipelajari, bukan regulator panjang, untuk menyelesaikan masalah pembulatan.
- Mempelajari peta perhatian atas "kisi batas token" yang dihitung dari durasi yang diprediksi.
- Decoder dibangun di atas blok "konvolusi ringan" 6.
- VAE digunakan untuk memproyeksikan spektrogram input ke fitur laten dan digabungkan dengan embeddings karakterr sebagai input ke jaringan.
- Soft-DTW intensif secara komputasi karena menghitung perbedaan berpasangan untuk semua bingkai spektrogram. Mereka mengontraknya dengan jendela diagonal tertentu untuk mengurangi overhead.
- Tujuan durasi akhir adalah jumlah kehilangan durasi, kehilangan VAE dan kehilangan spektrogram.
- Mereka hanya menggunakan set data hak milik untuk eksperimen?
- Mencapai MOS yang sama dengan model Tacotron2 dan mengungguli paraleltacotron.
- Halaman demo : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Kode : sejauh ini tidak ada kode
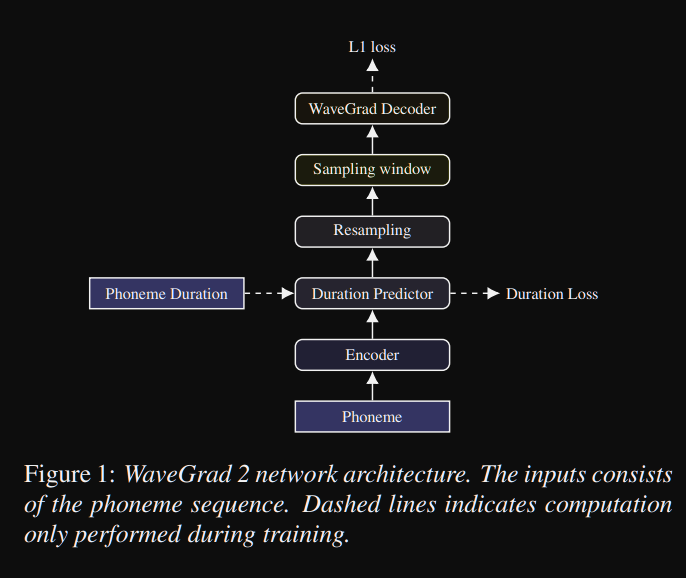
Wavegrad2: https://arxiv.org/pdf/2106.09660.pdf (klik untuk memperluas)
- Ini menghitung bentuk gelombang mentah langsung dari urutan fonem.
- Model Encoder seperti Tacotron2 digunakan untuk menghitung representasi tersembunyi dari fonem.
- Tacotron non-perhatian seperti prediktor durasi lunak untuk menyelaraskan representasi tersembunyi dengan output.
- Mereka memperluas representasi tersembunyi dengan durasi yang diprediksi dan mencicipi jendela tertentu untuk dikonversi ke bentuk gelombang.
- Mereka menjelajahi berbagai ukuran jendela di antara 64 dan 256 frame yang sesuai dengan 0,8 dan 3,2 detik pidato. Mereka menemukan bahwa yang lebih besar adalah yang lebih baik.
- Halaman demo : Tidak ada sejauh ini
- Kode : sejauh ini tidak ada kode
Kertas multi-speaker
- Pelatihan Multi-Speaker Sistem Teks-Untuk-Berpekatan Menggunakan Speaker-Imbalanced Speech Corpora-https://arxiv.org/abs/1904.00771
- Deep Voice 2-https://papers.nips.cc/paper/6889-deep-voice-2-multi-speaker-neural-text-tpeech.pdf
- Contoh TTS adaptif yang efisien - https://openreview.net/pdf?id=rkzjuoacfx
- Pendekatan embedding wavenet + speaker
- Loop Suara - https://arxiv.org/abs/1707.06588
- Pemodelan Ruang Laten Multi -Speaker untuk Meningkatkan TTS Neural TTS mendaftarkan speaker baru dan meningkatkan suara premium - https://arxiv.org/pdf/1812.05253.pdf
- Transfer pembelajaran dari verifikasi speaker ke sintesis teks-ke-speech multispeaker-https://arxiv.org/pdf/1806.04558.pdf
- Memasang speaker baru berdasarkan sampel pendek yang belum ditranskripsikan - https://arxiv.org/pdf/1802.06984.pdf
- Kehilangan end-to-end umum untuk verifikasi speaker-https://arxiv.org/abs/1710.10467
Ringkasan yang luas
Pembelajaran Semi-Dijelas untuk Sintesis Teks-Untuk-Pidato Multi-Speaker Menggunakan Representasi Bicara Diskrit: http://arxiv.org/abs/2005.08024
- Latih model TTS multi-speaker dengan data berpasangan hanya satu jam (penyelarasan teks-ke-suara) dan lebih banyak data yang tidak berpasangan (hanya voide).
- Ini mempelajari buku kode dengan setiap kata kode sesuai dengan satu fonem.
- Buku kode diselaraskan dengan fonem menggunakan data berpasangan dan algoritma CTC.
- Buku kode ini berfungsi seperti proxy untuk secara implisit memperkirakan urutan fonem dari data yang tidak berpasangan.
- Mereka menumpuk model Tacotron2 di atas untuk melakukan TTS menggunakan embeddings kata kode yang dihasilkan oleh bagian awal model.
- Mereka mengalahkan metode benchmark dalam pengaturan data berpasangan selama 1 jam.
- Mereka tidak melaporkan hasil data berpasangan penuh.
- Mereka tidak memiliki studi ablasi yang baik yang bisa menarik untuk melihat bagaimana berbagai bagian model berkontribusi pada kinerja.
- Mereka menggunakan Griffin-Lim sebagai vokoder sehingga ada ruang untuk perbaikan.
Halaman demo: https://ttaoretw.github.io/mulpkr-semi-tts/demo.html
Kode: https://github.com/ttaoretw/semi-tts 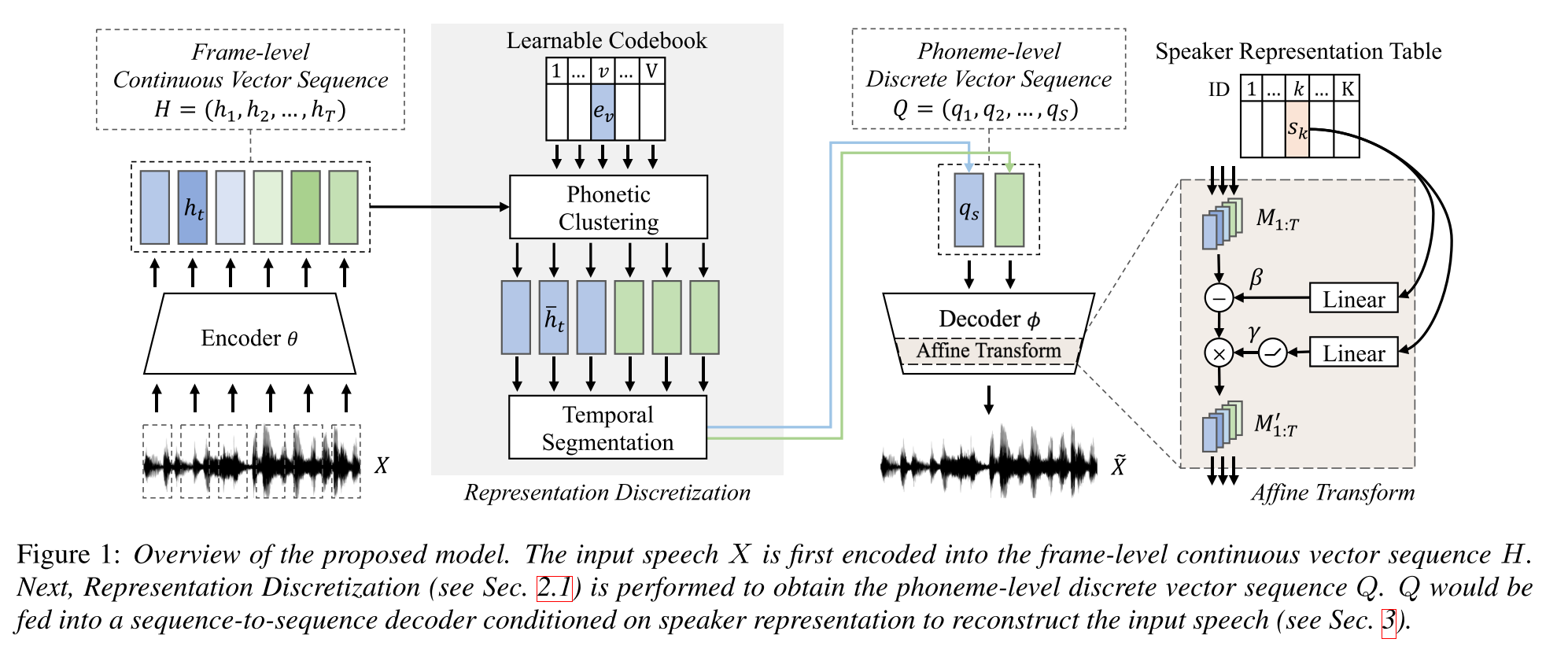
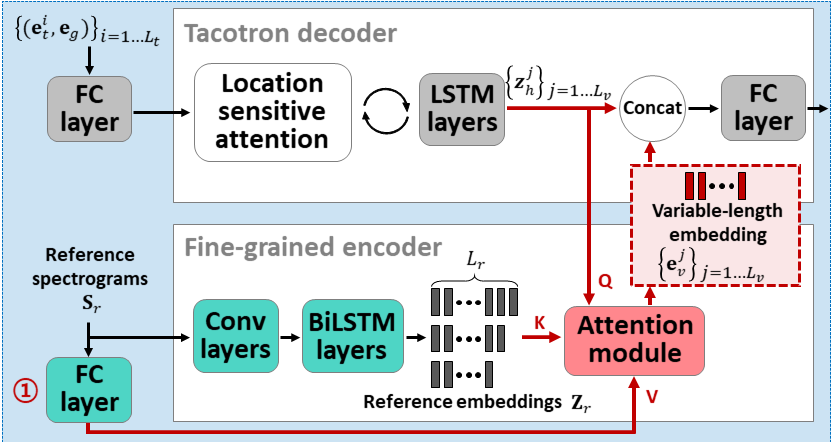
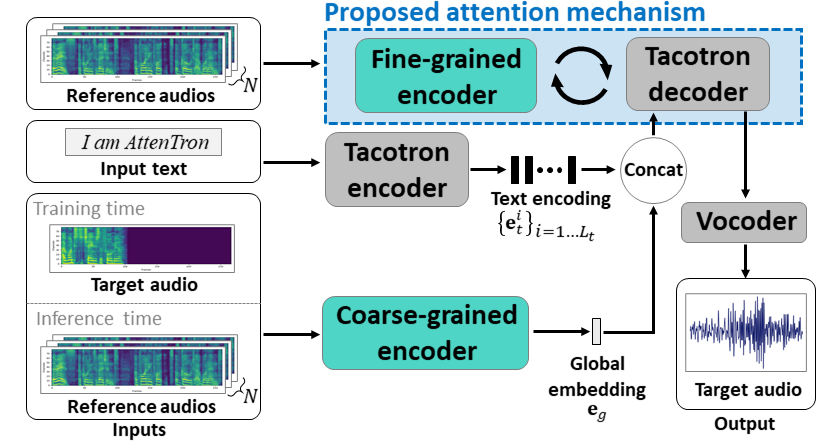
Attentron: beberapa shot teks-ke-speech mengeksploitasi panjang variabel berbasis perhatian embedding: https://arxiv.org/abs/2005.08484
- Gunakan dua encoder untuk mempelajari fitur tergantung speaker.
- Encoder kasar mempelajari vektor embedding speaker global berdasarkan spektrogram referensi yang disediakan.
- Encoder halus mempelajari embedding panjang variabel menjaga dimensi temporal bekerja sama dengan modul perhatian.
- Perhatian memilih bingkai spektrogram referensi penting untuk mensintesis ucapan target.
- Pra-Pelatihan Model dengan satu dataset speaker pertama (ljspeech untuk 30K iters.)
- Fine-tune model dengan dataset multi-speaker. (VCTK untuk 70K iters.)
- Ini mencapai metrik yang sedikit lebih baik dibandingkan dengan menggunakan x-vektor dari model klasifikasi speaker dan encoder audio referensi berbasis VAE.
Halaman demo: https://hyperconnect.github.io/attentron/
Menuju Universal Text-to-speech: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
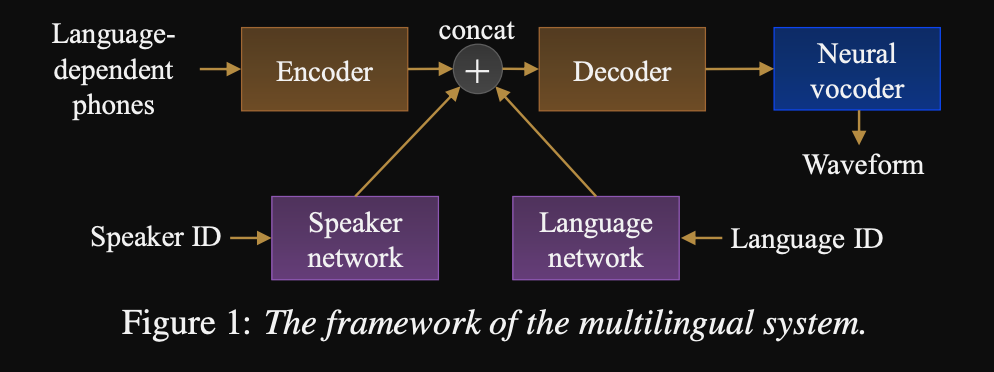
- Kerangka kerja untuk urutan untuk urutan multi-bahasa TTS
- Model ini dilatih dengan dataset yang sangat besar dan sangat tidak seimbang.
- Model ini dapat mempelajari bahasa baru dengan 6 menit dan pembicara baru dengan 20 detik data setelah pelatihan awal.
- Model Architecture adalah jaringan encoder-decoder berbasis transformator dengan jaringan speaker dan jaringan bahasa untuk pembicara dan konditinoning bahasa. Output dari jaringan ini digabungkan dengan output enkoder.
- Jaringan pengkondisian mengambil vektor satu-panas yang mewakili pembicara atau ID bahasa dan memproyeksikannya ke representasi pengkondisian.
- Mereka menggunakan vocoder Wavenet untuk mengonversi prediksi Mel-spectrograms ke output bentuk gelombang.
- Mereka menggunakan input fonem yang tergantung pada bahasa yang tidak dibagikan di antara bahasa.
- Mereka mencicipi setiap batch berdasarkan frekuensi terbalik dari setiap bahasa dalam dataset. Dengan demikian setiap batch pelatihan memiliki distribusi seragam melalui bahasa, mengurangi ketidakseimbangan bahasa dalam dataset pelatihan.
- Untuk mempelajari penutur/bahasa baru, mereka menyempurnakan model encoder-decoder dengan jaringan pengkondisian. Mereka tidak melatih model Wavenet.
- Mereka menggunakan rekaman profesional 1250 jam dari 50 bahasa untuk pelatihan.
- Mereka menggunakan laju pengambilan sampel 16kHz untuk semua sampel audio dan memotong keheningan di awal dan akhir setiap klip.
- Mereka menggunakan 4 V100 GPU untuk pelatihan tetapi mereka tidak menyebutkan berapa lama mereka melatih model.
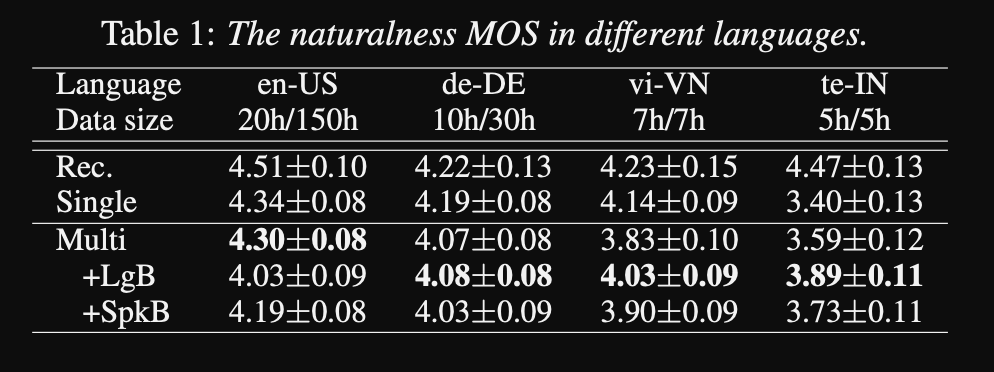
- Hasilnya menunjukkan bahwa model pembicara tunggal lebih baik daripada pendekatan yang diusulkan dalam metrik MOS.
- Juga menggunakan jaringan pengkondisian adalah penting untuk bahasa-bahasa ekor panjang dalam dataset karena mereka meningkatkan metrik MOS untuk mereka tetapi merusak kinerja untuk bahasa sumber daya tinggi.
- Ketika mereka menambahkan speaker baru, mereka mengamati bahwa menggunakan lebih dari 5 menit data menurunkan kinerja model. Mereka mengklaim bahwa karena rekaman ini tidak sebersih rekaman asli, menggunakan lebih banyak dari mereka mempengaruhi kinerja umum model.
- Model multi-bahasa mampu berlatih hanya dengan 6 menit data untuk speaker dan bahasa baru sedangkan model pembicara tunggal membutuhkan 3 jam untuk berlatih dan bahkan tidak dapat mencapai nilai MOS yang serupa dengan model multi-bahasa 6 menit.
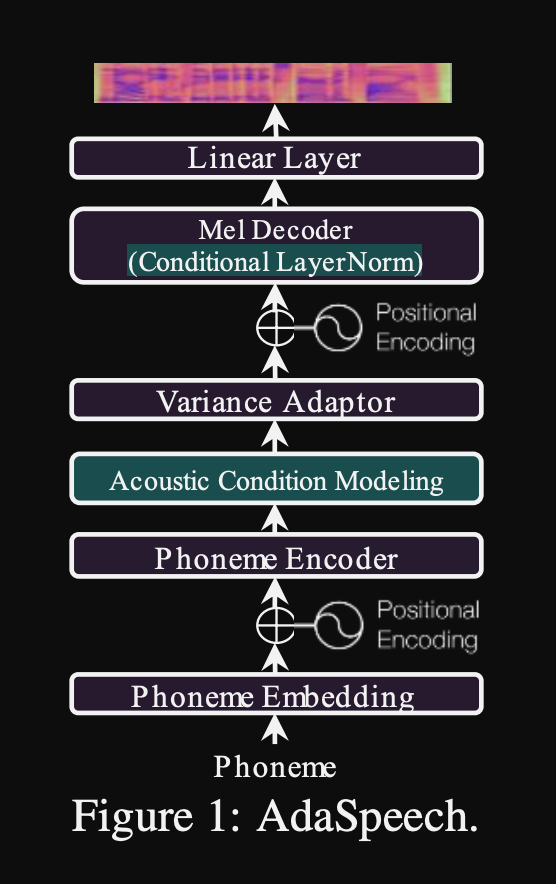
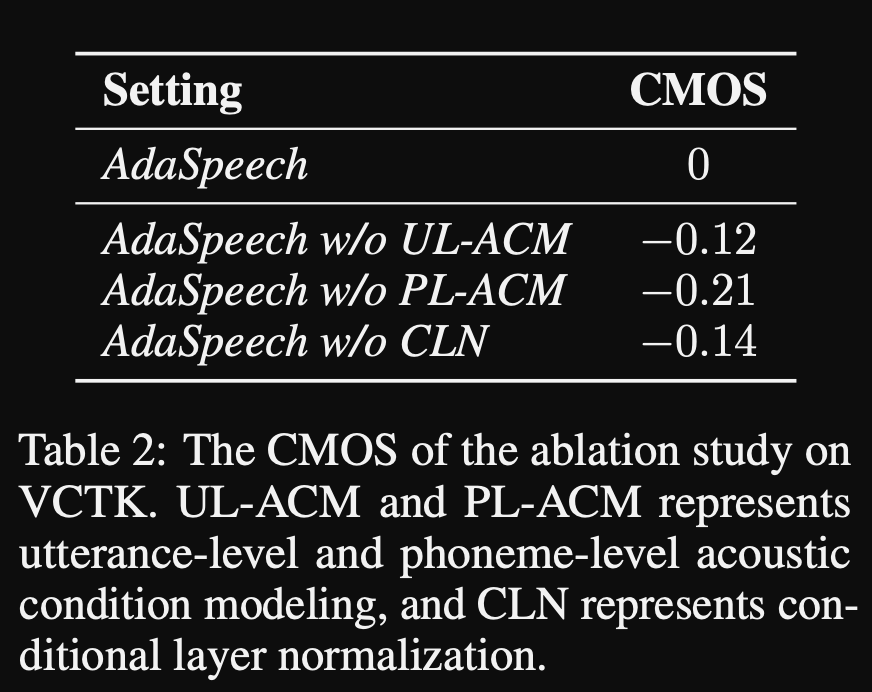
Adaspeech: Teks Adaptif ke Pidato untuk Suara Kustom: https://openreview.net/pdf?id=drynvt7gg4l
- Mereka mengusulkan sistem yang dapat beradaptasi dengan sifat akustik input yang berbeda dari pengguna dan menggunakan jumlah minimum parameter untuk mencapai ini.
- Arsitektur utama didasarkan pada model FastSpeech2 yang menggunakan prediktor pitch dan varians untuk mempelajari granularitas yang lebih baik dari pidato input.
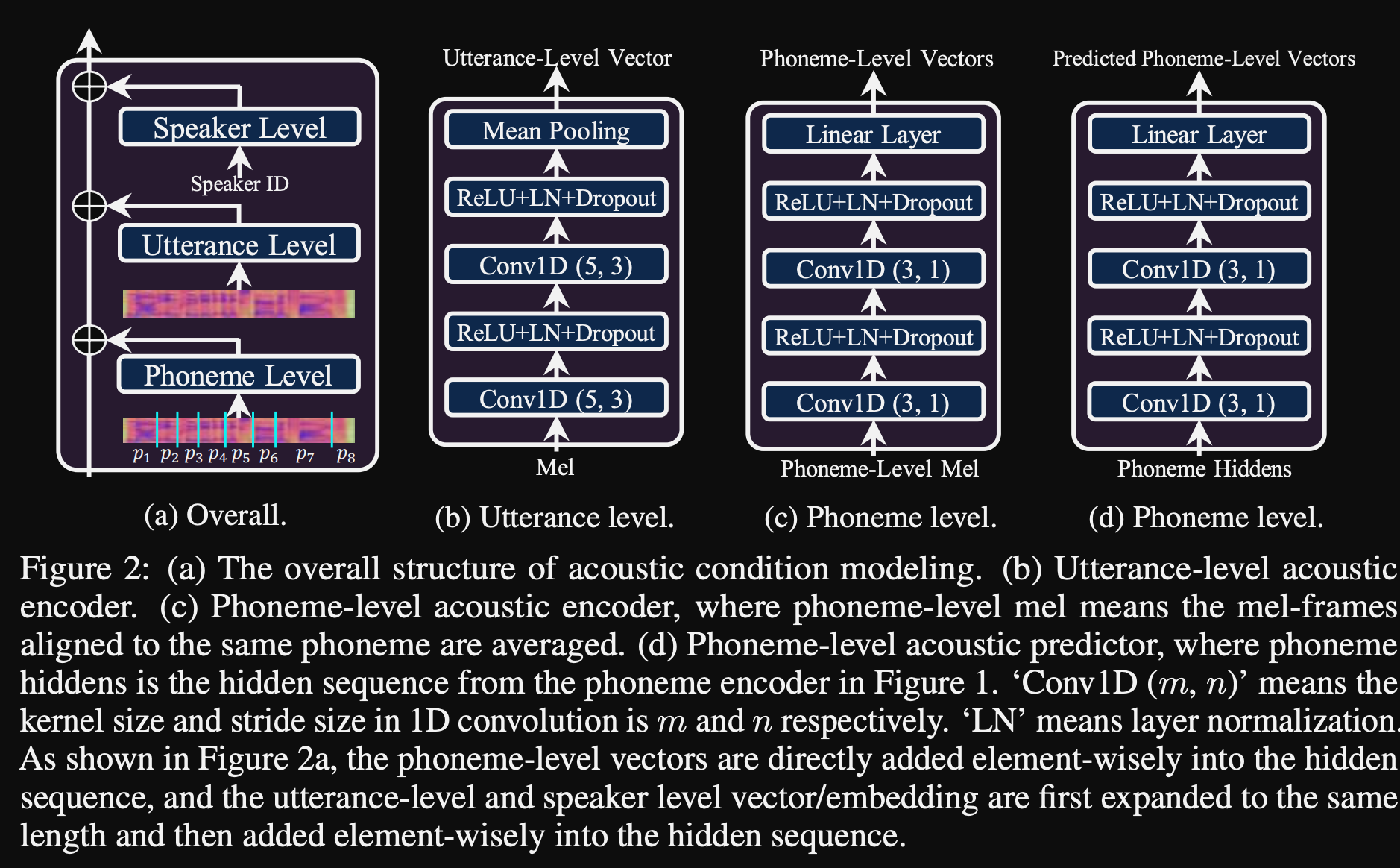
- Mereka menggunakan 3 jaringan pengkondisian tambahan.
- Tingkat ucapan. Dibutuhkan Mel-Spectrogram dari pidato referensi sebagai input.
- Tingkat fonem. Dibutuhkan level fonem Mel-spectrograms sebagai input dan menghitung vektor pengkondisian level fonem. Mel-spectrogram tingkat fonem dihitung dengan mengambil bingkai spektrogram rata-rata dalam durasi setiap fonem.
- Level fonem 2. Dibutuhkan output enkoder fonem sebagai input. Ini berbeda dari jaringan di atas dengan hanya menggunakan informasi fonem tanpa melihat spektrogram.
- Semua jaringan pengkondisian ini dan FastSpeech2 tulang belakang menggunakan lapisan normalisasi lapisan.
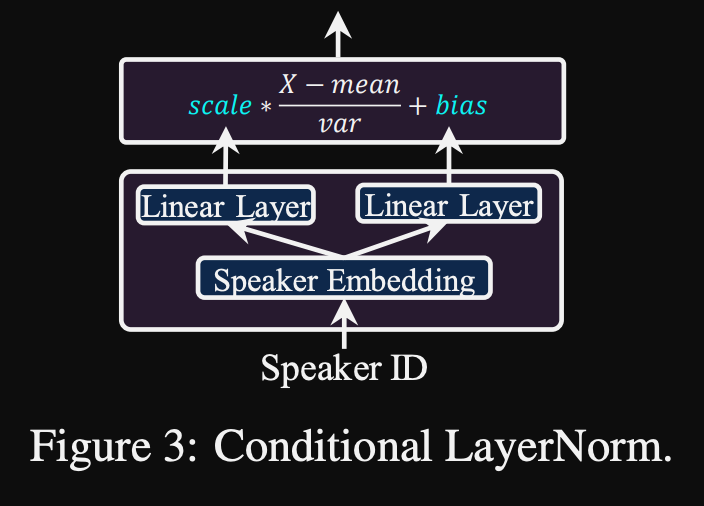
- Normalisasi lapisan bersyarat. Mereka mengusulkan penyempurnaan hanya skala dan parameter bias dari setiap lapisan lapisan normalisasi ketika model disesuaikan untuk speaker baru. Mereka melatih modul pengkondisian speaker untuk setiap lapisan lapisan norma yang menghasilkan skala dan nilai bias. (Mereka menggunakan satu modul pengkondisian speaker per blok transformator.)
- Ini berarti bahwa Anda hanya menyimpan modul pengkondisian speaker untuk setiap pembicara baru dan memprediksi skala dan nilai bias pada inferensi saat Anda menjaga sisa model yang sama.
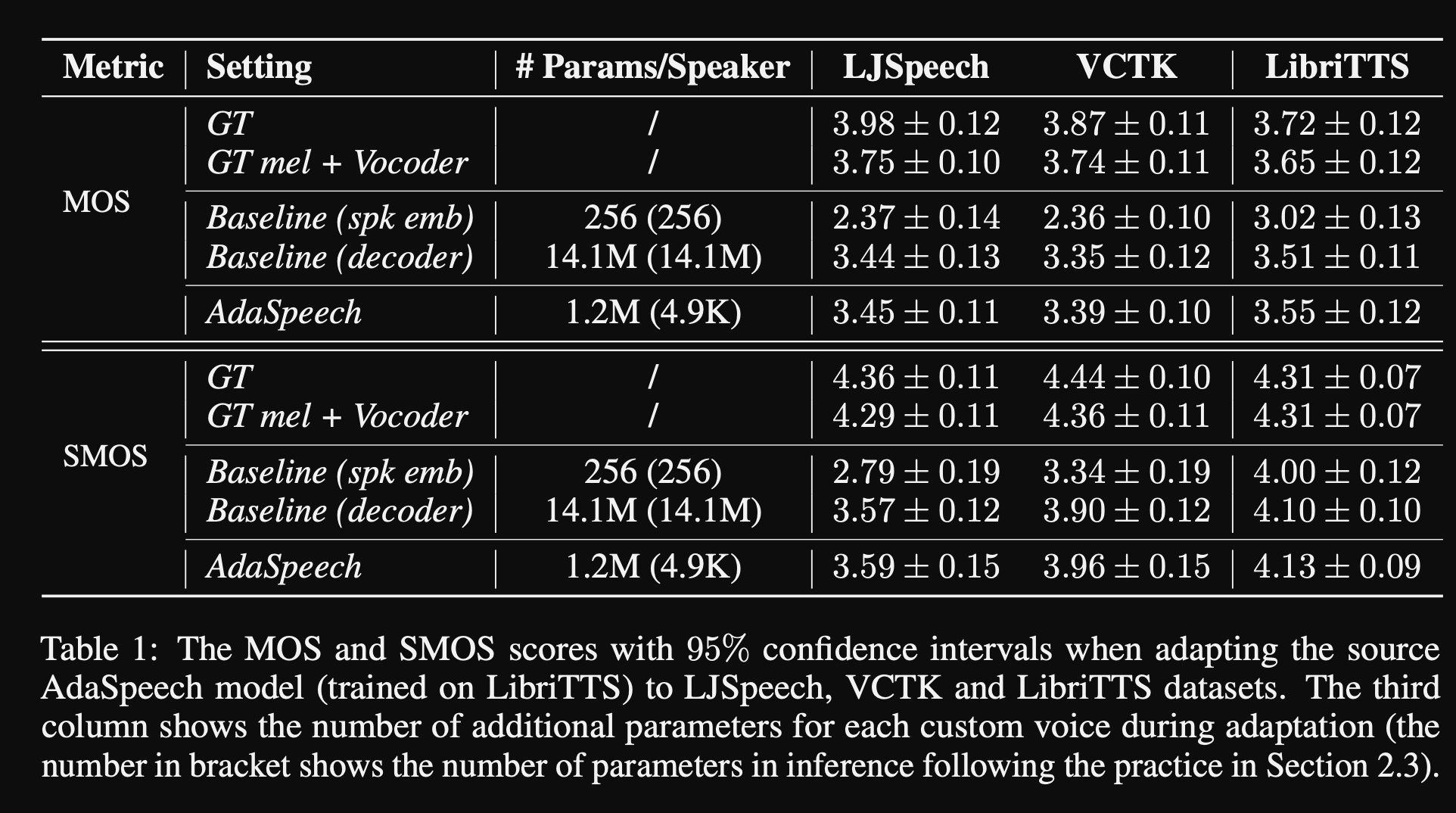
- Dalam percobaan, mereka melatih pra-kereta model pada dataset Libitts dan menyempurnakannya dengan VCTK dan LJSPEECH
- Hasilnya menunjukkan bahwa menggunakan normalisasi lapisan bersyarat mencapai lebih baik daripada 2 baseline mereka yang hanya menggunakan embedding speaker dan decoder network fine-tunning.
- Studi ablasi mereka menunjukkan bahwa bagian paling signifikan dari model ini adalah jaringan "level fonem" diikuti oleh normalisasi lapisan bersyarat dan jaringan "tingkat ucapan" dalam suatu urutan.
- Salah satu sisi penting dari makalah ini adalah bahwa hampir tidak ada perbandingan dengan literatur dan membuat hasil lebih sulit untuk dinilai secara objektif.
Halaman demo: https://speechresearch.github.io/adaspeech/

Perhatian
- Lokasi-Relatif Mekanisme Perhatian untuk Sintesis Long-Formspeech yang kuat-https://arxiv.org/pdf/1910.10288.pdf
Vocoders
Melgan: https://arxiv.org/pdf/1910.06711.pdf
Parallelwavegan: https://arxiv.org/pdf/1910.11480.pdf
- Kehilangan STFT multi skala
- ~ Parameter model 1M (sangat kecil)
- Sedikit lebih buruk dari Wavernn
Meningkatkan fftnet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
Fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Rekonstruksi Bentuk Gelombang Bicara Menggunakan Convolutional NeuralNetworks dengan Noise dan Input Berkala
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
Menuju mencapai vokoding universal yang kuat
- https://arxiv.org/pdf/1811.06292.pdf
Lpcnet
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
Excitenet
- https://arxiv.org/pdf/1811.04769v3.pdf
Gelp: Prediksi linier yang tereksitasi gan untuk sintesis bicara dari spektrogram-spektrogram
- https://arxiv.org/pdf/1904.03976v3.pdf
Sintesis Pidato Fidelity Tinggi dengan Jaringan Periasan: https://arxiv.org/abs/1909.11646
- Gan-tts, sintesis ucapan ujung ke ujung
- Menggunakan fitur durasi dan linguistik
- Durasi dan fitur akustik diprediksi oleh model tambahan.
- Diskriminator Jendela Acak: Menyeret bukan seluruh sampel suara tetapi jendela acak.
- Beberapa RWD. Beberapa bersyarat dan beberapa tidak bersyarat. (dikondisikan pada fitur input)
- Punchline: Gunakan jendela sampel secara acak dengan ukuran jendela yang berbeda untuk D.
- Hasil yang dibagikan terdengar mekanis yang menunjukkan batas fitur akustik non-neural.
Multi-band Melgan: https://arxiv.org/abs/2005.05106
- Gunakan kerugian PWGAN alih-alih kerugian pencocokan fitur.
- Menggunakan kinerja model bidang reseptif yang lebih besar secara signifikan.
- Pretraining generator untuk 200k iters.
- Prediksi sinyal suara multi-band. Outputnya adalah penjumlahan dari 4 prediksi pita yang berbeda dengan filter sintesis PQMF.
- Model multi-band memiliki parameter 1,9m (cukup kecil).
- Diklaim 7x lebih cepat dari Melgan
- Pada dataset Cina: MOS 4.22
Waveglow: https://arxiv.org/abs/1811.00002
- Model yang sangat besar (parameter 268m)
- Sulit dilatih karena pada GPU 12GB hanya dapat mengambil ukuran batch 1.
- Kesimpulan real-time karena penggunaan konvolusi.
- Berdasarkan aliran normalisasi yang terbalik. (Tutorial hebat https://blog.evjang.com/2018/01/nf1.html)
- Model belajar dan pemetaan sampel audio yang tidak biasa menjadi Mel-spectrograms dengan kehilangan kemungkinan maks.
- Dalam Inference Network berjalan dalam arah terbalik dan memberikan MEL-SPEC dikonversi ke sampel audio.
- Pelatihan telah dilakukan dengan menggunakan 8 NVIDIA V100 dengan RAM 32GB, ukuran batch 24. (Mahal)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, kode: https://github.com/tianrengao/squeezewave
- ~ 5-13x lebih cepat dari waktu nyata
- Waveglow Redanduncies: Sampel audio panjang, upsamples Mel-specs, dimensi saluran besar dalam fungsi WN.
- Perbaikan: sampel audio lebih tetapi lebih pendek sebagai input, (l = 2000, c = 8 vs l = 64, c = 256)
- L = 64 cocok dengan resolusi Mel-spec sehingga tidak ada peningkatan yang diperlukan.
- Gunakan konvolusi terpisah yang dapat dipisahkan dalam modul WN.
- Gunakan konvolusi reguler alih -alih melebar karena sampel audio lebih pendek.
- Jangan membagi output modul ke output residual dan jaringan, dengan asumsi vektor ini hampir identik.
- Pelatihan telah dilakukan dengan menggunakan Titan RTX 24GB Batch Ukuran 96 untuk iterasi 600k.
- Mos pada ljspeech: waveglow - 4.57, squeezewave (l = 128 c = 256) - 4.07 dan squeezewave (l = 64 C = 256) - 3.77
- Model terkecil memiliki 21k sampel per detik pada RASPI3.
Wavegrad: https://arxiv.org/pdf/2009.00713.pdf
- Ini didasarkan pada difusi probabilitas dan dinamika lagenvin
- Gagasan dasarnya adalah mempelajari fungsi yang memetakan distribusi yang diketahui untuk menargetkan distribusi data secara iteratif.
- Mereka melaporkan 0,2 faktor waktu nyata pada GPU tetapi kinerja CPU tidak dibagikan.
- Dalam kode contoh di bawah ini, penulis melaporkan bahwa model konvergen setelah 2 hari pelatihan pada satu GPU.
- Skor MOS di atas kertas tidak cukup ganas tetapi menunjukkan kinerja yang sebanding dengan model yang dikenal seperti Wavernn dan Wavenet.
Kode: https://github.com/ivanvovk/wavegrad 
Dari internet (blog, video dll)
Video
Diskusi kertas
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Pembicaraan
- Bicaralah tentang mendorong perbatasan teks-ke-speech, oleh Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- Bicara tentang sintesis teks-ke-speech berbasis model generatif, oleh Heiga Zen, 2017
- Video: https://youtu.be/nsrsrytkkt8
- Slide: https://research.google.com/pubs/pub45882.html
- Tutorial tentang Sintesis Teks-ke-Teks Parametrik Saraf di Isca Odyessy 2020, oleh Xin Wang, 2020
- Video: https://youtu.be/wce7sycdzai
- Slide: http://tonywangx.github.io/slide.html#dec-2020
- Kursus Pemrosesan Pidato ISCA tentang Neural Vocoders, 2022
- Komponen Dasar Vocoders Neural: https://youtu.be/m833q5i-zys
- Model generatif yang dalam untuk kompresi ucapan (lpcnet): https://youtu.be/7ksnfx3plgw
- Neural Auto-Regregressive, Source-Filter dan Vocoders Glottal: https://youtu.be/gprmxdberx0
- Slide: http://tonywangx.github.io/slide.html#jul-2020
- Sintesis Bicara dari Decoding Saraf Kalimat Lisan | AISC: https://www.youtube.com/watch?v=mndtmdpmnmo
- Sintesis Teks-Untuk-Pidato Generatif: https://www.youtube.com/watch?v=j4mveanKing
- Sintesis pidato untuk industri game: https://www.youtube.com/watch?v=aohaye4a-2q
Umum
- Ulasan Sistem Teks-Teks Modern: https://www.youtube.com/watch?v=8rxlsc-zcry
Jupyter Notebooks
- Tutorial tentang Vocoders Saraf Pilihan: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
Blog
- Teks untuk berbicara arsitektur pembelajaran mendalam: http://www.erogol.com/text-feech-deep-learning-architectures/


