(변경 사항을 자유롭게 제안하십시오)
서류
- 음소 및 숯 표현 병합 : https://arxiv.org/pdf/1811.07240.pdf
- 타코트론 전송 학습 : https://arxiv.org/pdf/1904.06508.pdf
- 주의로부터의 음소 타이밍 : https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- 엔드 투 엔드 음성 합성에서 데이터 효율성을 향상시키기위한 반 감독 교육 -https://arxiv.org/pdf/1808.10128.pdf
- 말하기 중 : 딥 러닝의 언어 체인 -https://arxiv.org/pdf/1707.04879.pdf
- 스피커 검증을위한 Generelized 엔드 투 엔드 손실 : https://arxiv.org/pdf/1710.10467.pdf
- ES-TACOTRON2 : 지나치게 스무스 문제를 줄이기위한 미리 훈련 된 추정 네트워크가있는 멀티 태스킹 타코트론 2 : https://www.mdpi.com/2078-2489/10/4/131/pdf
- FastSpeech : https://arxiv.org/pdf/1905.09263.pdf
- 연설에서 노래를 배우기 : https://arxiv.org/pdf/1912.10128.pdf
- tts-gan : https://arxiv.org/pdf/1909.11646.pdf
- 그들은 En2en tts에 기간과 언어 기능을 사용합니다.
- Wavenet 성능에 가깝습니다.
- Durian : https://arxiv.org/pdf/1909.01700.pdf
- Melnet : https://arxiv.org/abs/1906.01083
- aligntts : https://arxiv.org/pdf/2003.01950.pdf
- 트리플 정보 병목 현상을 통한 감독되지 않은 음성 분해
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron : https://arxiv.org/pdf/2005.05957.pdf
- 아카트론에서 아키텍처와 같은 역자 가구류 흐름
- 보코더로서 Waveglow.
- 가우스 모델의 혼합과 함께 음성 스타일 임베딩.
- 모델은 바닐라 타코트론보다 크고 곤도입니다
- MOS 값은 공개 타코트론 구현보다 훨씬 낫습니다.
- 주의를 기울인 깊은 컨볼 루션 네트워크를 기반으로하는 효율적으로 훈련 가능한 텍스트 음성 시스템 : https://arxiv.org/pdf/1710.08969.pdf
광대 한 요약
엔드 투 엔드 부적 텍스트-스피치 : http://arxiv.org/abs/2006.03575 (확장하려면 클릭)
- End2end 피드 포워드 TTS 학습.
- 문자 정렬은 별도의 정렬 모듈로 수행되었습니다.
- Aligner는 각 문자의 길이를 예측합니다. - 숯의 중심 위치는 이전 문자의 총 길이를 발견합니다. - 숯 위치는 실제 오디오 길이를 가우스 윈도우로 보간됩니다.
- 오디오 출력은 MU-LAW 도메인에서 계산됩니다. (나는 이것에 대한 추론이 없다)
- 트래닝에는 오디오 창을 2 초만 사용하십시오.
- GAN-TTS 생성기는 오디오 신호를 생성하는 데 사용됩니다.
- RWD는 오디오 레벨 판별 자로 사용됩니다.
- MELD : Biggan-Deep 아키텍처를 이미지 재구성으로 문제를 회복하는 스펙트로 그램 레벨 식별기로 사용합니다.
- 스펙트로 그램 손실
- 적대적인 공급 백만 사용하는 것만으로는 충분하지 않습니다. 그들은 스펙트로 그램 손실 b/w 예측 된 스펙트로 그램 및지면 진실 사양을 사용합니다.
- 모델은 오디오 신호를 예측합니다. 위의 스펙트로 그램은 생성 된 오디오에서 계산됩니다.
- 동적 시간 랩핑은 최소 비용 정렬 B/W 생성 스펙트로 그램 및지면 진실을 계산하는 데 사용됩니다.
- 최소한의 비용 정렬을 찾기위한 동적 프로그래밍 접근법이 포함됩니다.
- Aligner 길이 손실은 실제 오디오 길이와 다르게 예측하기 위해 Aligner를 불이익시키는 데 사용됩니다.
- 그들은 멀티 스피커 데이터 세트로 모델을 훈련 시키지만 최고의 성능을 발휘하는 스피커에 대한 결과를보고합니다.
- 각 구성 요소의 절제 연구 중요성 : (Longthloss and SpectrogramLoss)> rwd> meld> phonemes> MultispeakerDataset.
- 내 2 센트 : 이는 별도의 보코더 모델을 훈련시킬 필요가없는 엔드 -2- 엔드 음성 합성을 제공하는 피드 포워드 모델입니다. 그러나 많은 초 파라미터와 구현 세부 사항이있는 매우 복잡한 모델입니다. 또한 최종 결과는 최신 기술에 가깝지 않습니다. 다른 알고리즘의 조합을 조정해야 할 필요성을 줄일 수있는 학습 문자 정렬에 대한 특정 알고리즘을 찾아야한다고 생각합니다.
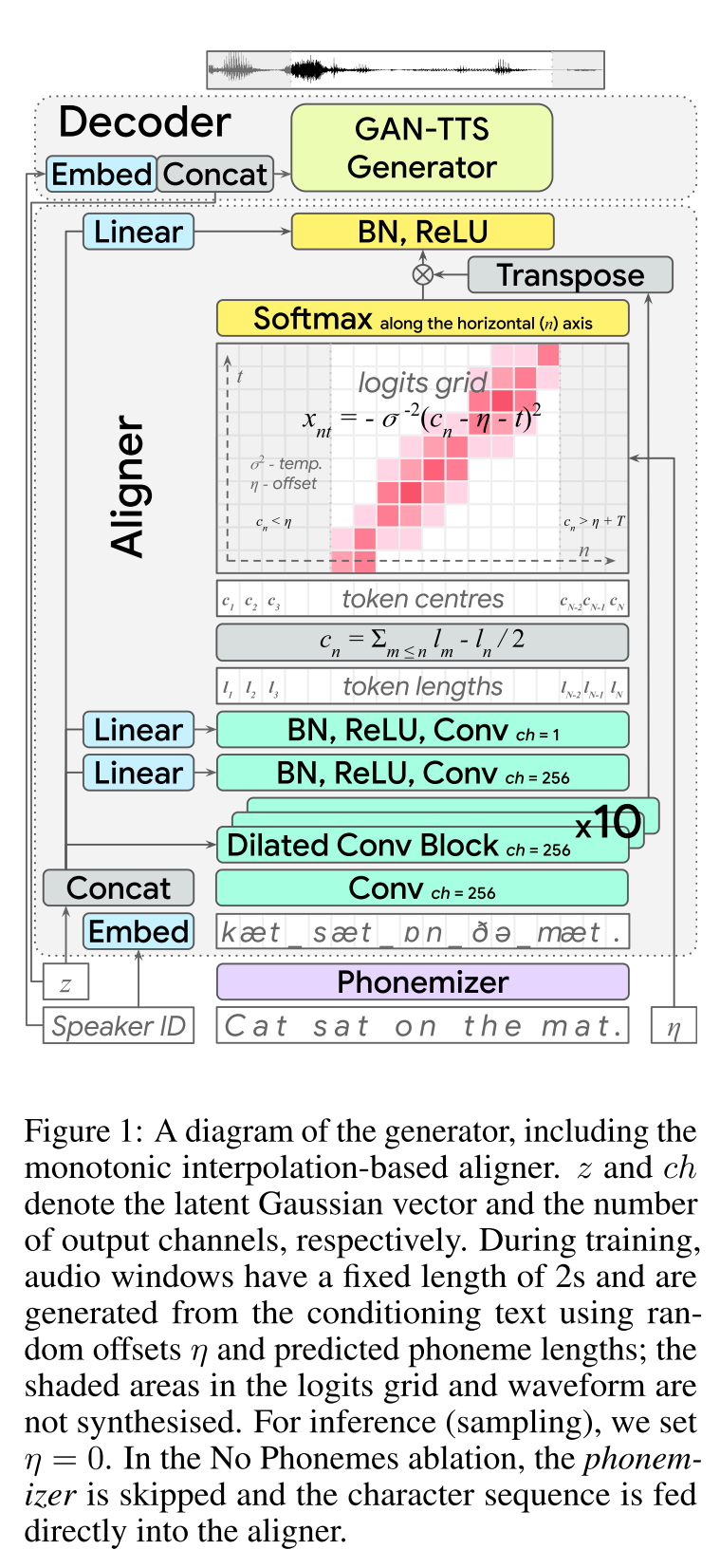
빠른 Speech2 : http://arxiv.org/abs/2006.04558 (확장 클릭)
- 길이 조절기를 훈련시키기위한 라벨로 MFA에 의해 생성 된 음소 기간을 사용하십시오.
- 프레임 레벨 F0 및 L2 스펙트로 그램 규범 (분산 정보)을 추가 기능으로 사용합니다.
- 분산 예측 변수 모듈은 추론 시간에 분산 정보를 예측합니다.
- 절제 연구 결과 개선 : 모델 <모델 + l2_norm <model + l2_norm + f0
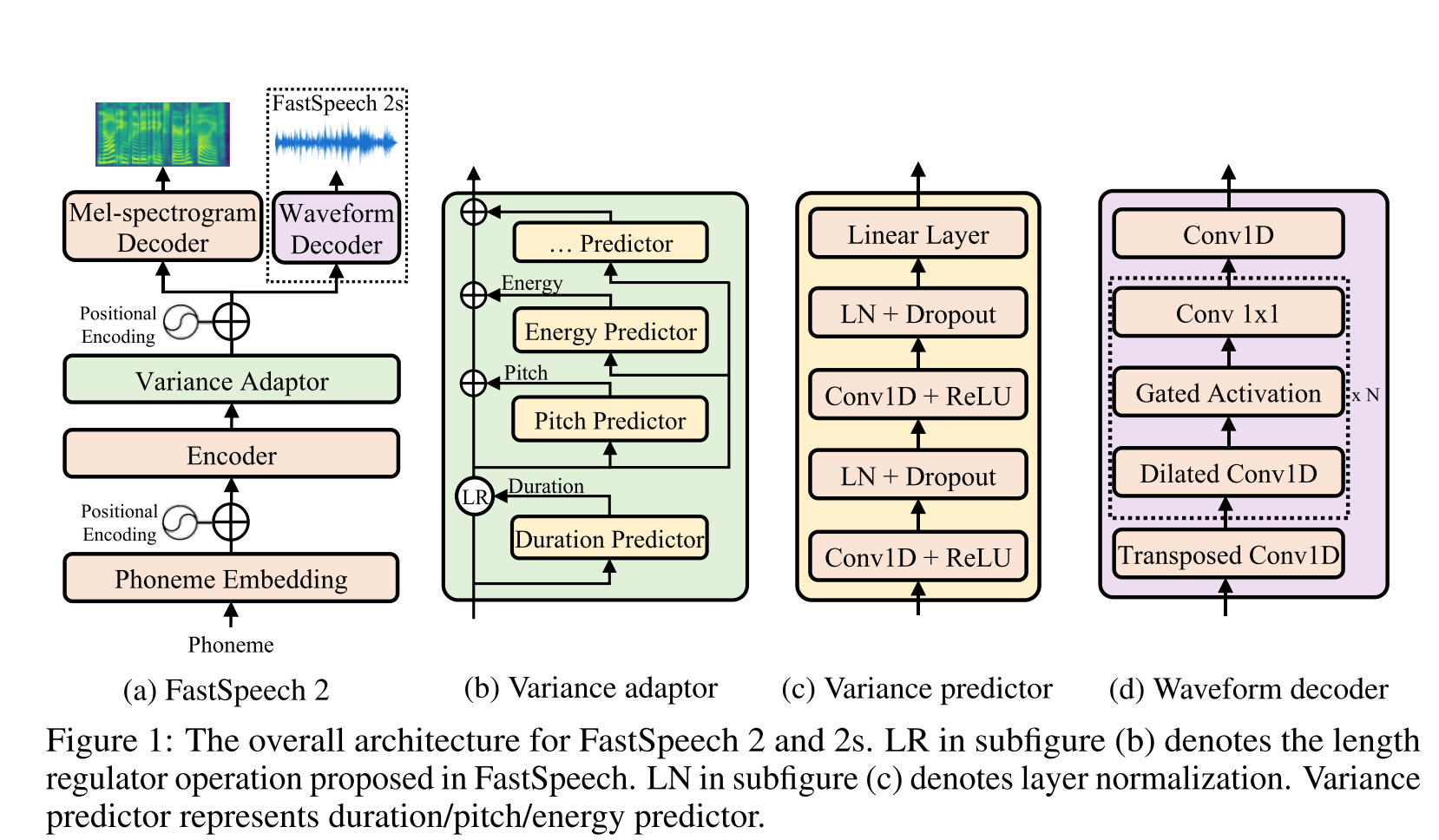
글로우 -TTS : https://arxiv.org/pdf/2005.11129.pdf (확장하려면 클릭)
- 단조 적 정렬 검색을 사용하여 정렬 B/W 텍스트 및 스펙트로 그램을 배우십시오.
- 이 정렬은 추론에 사용될 지속 시간 예측 변수를 훈련시키는 데 사용됩니다.
- 인코더는 각 캐릭터를 가우스 분포에 맵핑합니다.
- 디코더는 정규화 흐름 (글로우 층)을 사용하여 각 스펙트로 그램 프레임을 잠재 벡터에 맵핑합니다.
- 인코더 및 디코더 출력은 MAS와 정렬됩니다.
- 각각의 반복에서 먼저 MAS에서 가장 가능한 정렬을 발견 하고이 정렬은 모드 매개 변수를 업데이트하는 데 사용됩니다.
- 지속 시간 예측 변수는 각 문자에 대한 스펙트로 그램 프레임의 수를 예측하도록 훈련됩니다.
- 추론에 따라 기간 예측 변수 만 MAS 대신 사용됩니다.
- Encoder에는 2 개의 업데이트가있는 TTS 변압기의 아키텍처가 있습니다.
- 절대 위치 인코딩 대신 실제 위치 인코딩을 사용합니다.
- 또한 인코더 프레넷에 잔류 연결을 사용합니다.
- 디코더는 글로우 모델과 동일한 아키텍처를 가지고 있습니다.
- 그들은 단일 및 멀티 스피커 모델을 모두 훈련시킵니다.
- 실험적으로 보여지고, 글로우 테트는 원래 타코 트론 2에 비해 긴 문장에 대해 더 강력합니다.
- 추론에서 Tacotron2보다 15 배 빠릅니다
- 내 2 센트 : 그들의 샘플은 타코트론만큼 자연스럽지 않습니다. 주의는 캐릭터를 모델을 직접 모델로 매핑하는 법을 배우기 때문에 정상적인주의 모델이 여전히 더 자연스러운 음성을 생성한다고 생각합니다. 그러나 Glow-TTS를 사용하는 것은 하드 데이터 세트의 좋은 대안 일 수 있습니다.
- 샘플 : https://github.com/jaywalnut310/glow-tts
- 저장소 : https://github.com/jaywalnut310/glow-tts
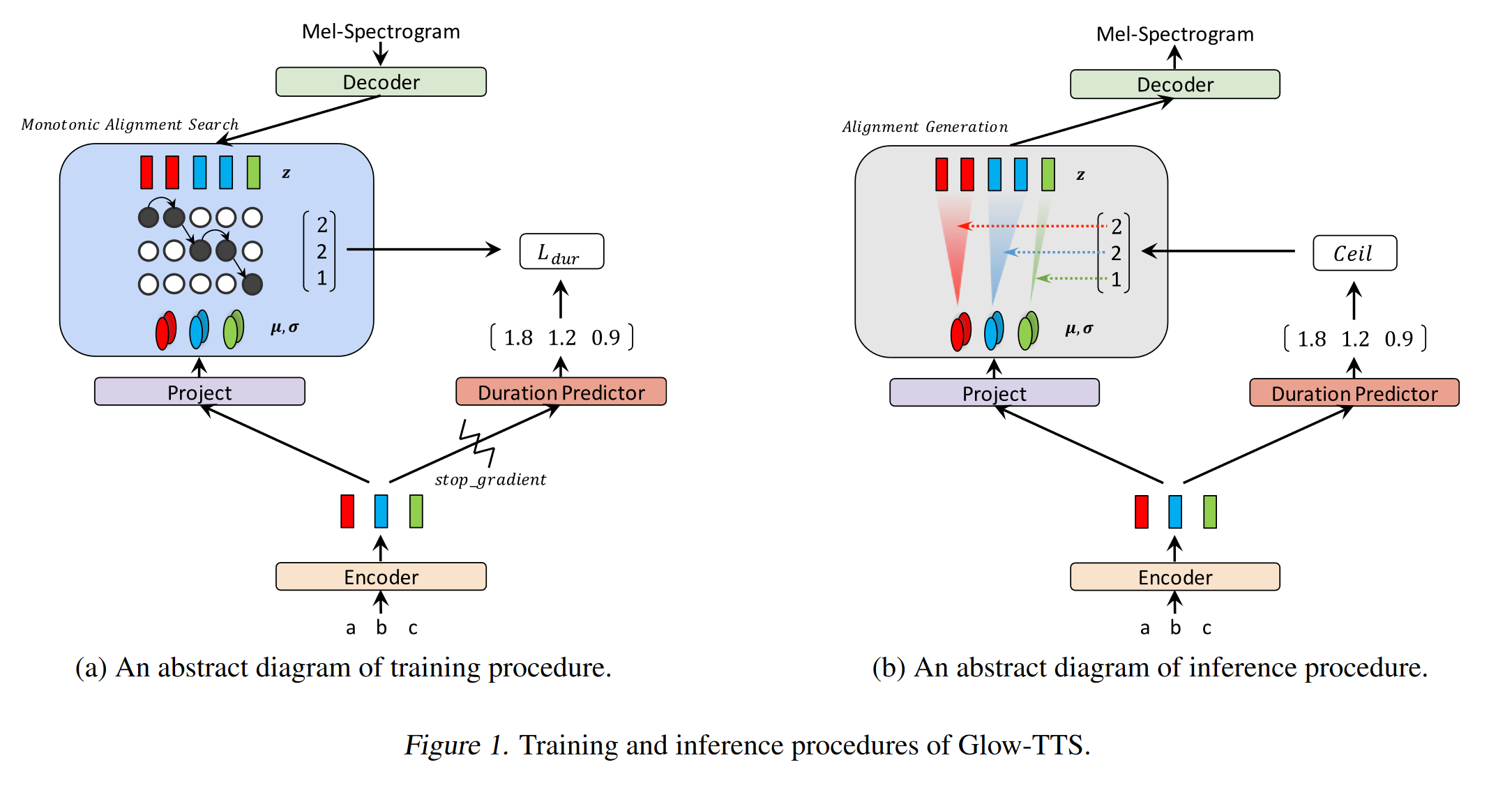
비-autoregreative 신경 텍스트---스피치 : http://arxiv.org/abs/1905.08459 (확장하려면 클릭)
- 비 콜라스 컨볼 루션 레이어를 사용한 딥 음성 3 모델의 파생.
- Autoregressive Teacher 모델의 여러주의 블록으로 Annon-Autoregressive 학생을 훈련시키는 교사-학생 패러다임.
- 교사는 학생 모델에서 사용할 텍스트-스펙트럼 정렬을 생성하는 데 사용됩니다.
- 이 모델은주의 정렬 및 스펙트로 그램 생성을 위해 두 가지 손실 함수로 훈련됩니다.
- 다중주의 블록은 층별주의 정렬 층을 개선합니다.
- 학생은 쿼리, 키 및 값 벡터와 함께 도트 제품주의를 사용합니다. 쿼리는 단지 양성 인코딩 벡터 일뿐입니다. 키와 값은 인코더 출력입니다.
- 제안 된 모델은 다른 상수 값에 의존하는 위치 인코딩에 크게 연결되어 있습니다.
이중 디코더 일관성 : https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder-consistency (클릭하여 확장)
- 이 모델은 타코트론과 같은 아키텍처를 사용하지만 2 개의 디코더와 우편 번호가 있습니다.
- DDC는 상이한 감소율을 사용하여 두 개의 동기 디코더를 사용합니다.
- 디코더는 다른 감소 속도를 사용하므로 상이한 세분성에서 출력을 계산하고 입력 데이터의 다른 측면을 학습합니다.
- 이 모델은이 두 디코더 간의 일관성을 사용하여 학습 된 텍스트-스펙트럼 정렬의 견고성을 높입니다.
- 이 모델은 또한 Postnet을 반복적으로 여러 번 적용하여 최종 디코더 출력에 개선을 적용합니다.
- DDC는 Prenet 모듈에서 배치 정규화를 사용하고 드롭 아웃 레이어를 떨어 뜨립니다.
- DDC는 점진적인 교육을 사용하여 총 교육 시간을 줄입니다.
- 우리는 원래 작업과 다르게 여러 랜덤 윈도우 판별자가 훈련 된 보코더로 멀티 밴드 멜간 생성기를 사용합니다.
- 우리는 단일 GPU로 2 일 만에 DDC 모델을 훈련시킬 수 있으며 최종 모델은 CPU에서 실시간 음성보다 빠르게 생성 할 수 있습니다. 데모 페이지 : https://erogol.github.io/ddc-samples/ 코드 : https://github.com/mozilla/tts
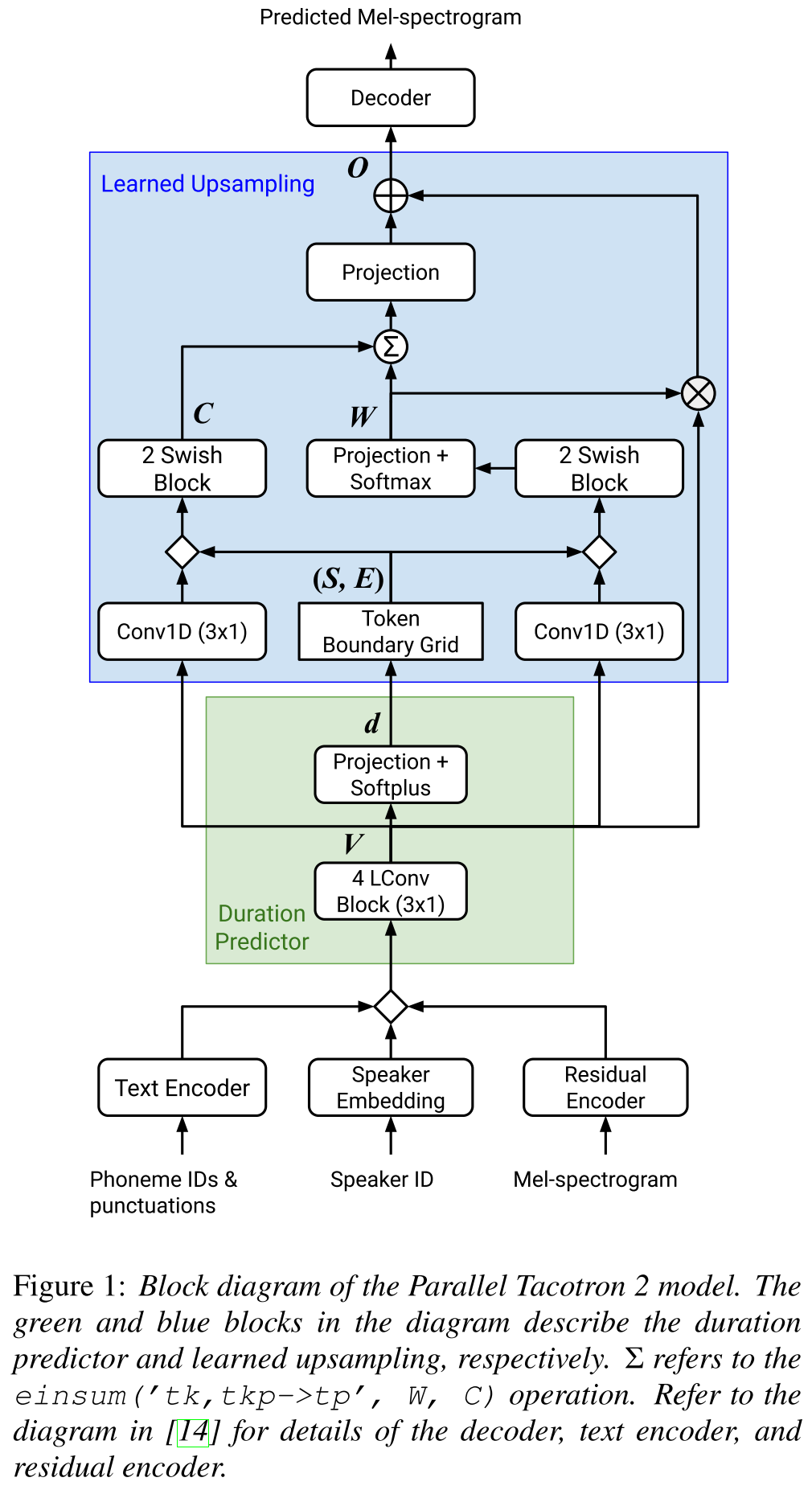
병렬 Tacotron2 : http://arxiv.org/abs/2103.14574 (확장하려면 클릭)
- 외부 지속 시간 정보가 필요하지 않습니다.
- 소프트 -DTW 손실에 의해 실제 및 지상 진실 스펙트로 그램 사이의 정렬 문제를 해결합니다.
- 예측 된 지속 시간은 반올림 문제를 해결하기 위해 길이 조절기가 아닌 학습 된 전환 함수에 의한 정렬로 변환됩니다.
- 예측 된 지속 시간에서 계산 된 "토큰 경계 그리드"에 대한주의 맵을 배웁니다.
- 디코더는 6 개의 "가벼운 컨벤션"블록에 제작되었습니다.
- VAE는 입력 스펙트로 그램을 잠재 기능으로 투사하는 데 사용되며 네트워크 입력으로 문자 임베딩과 병합됩니다.
- Soft-DTW는 모든 분광 프레임에 대한 쌍별 차이를 계산하기 때문에 계산 집약적입니다. 그들은 오버 헤드를 줄이기 위해 특정 대각선 창에 대항합니다.
- 최종 지속 시간 목표는 지속 시간 손실, VAE 손실 및 스펙트로 그램 손실의 합입니다.
- 그들은 실험에 독점 데이터 세트 만 사용합니까?
- Tacotron2 모델로 동일한 MOS를 달성하고 PeralelTacotron보다 성능이 우수합니다.
- 데모 페이지 : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- 코드 : 지금까지 코드가 없습니다
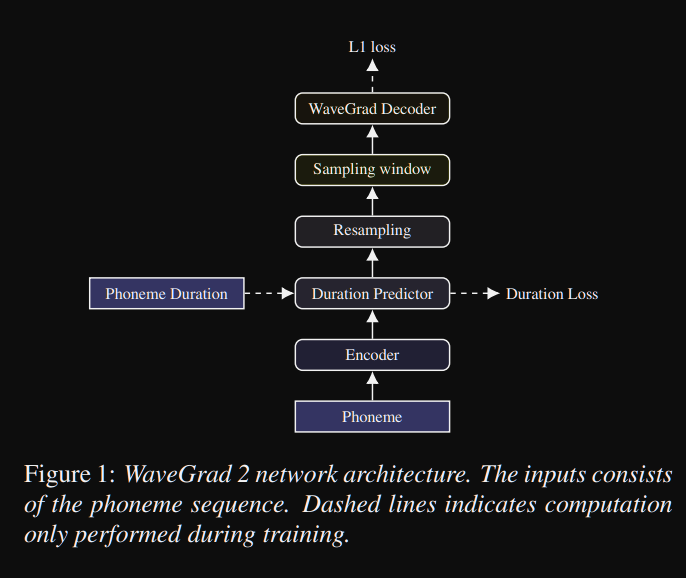
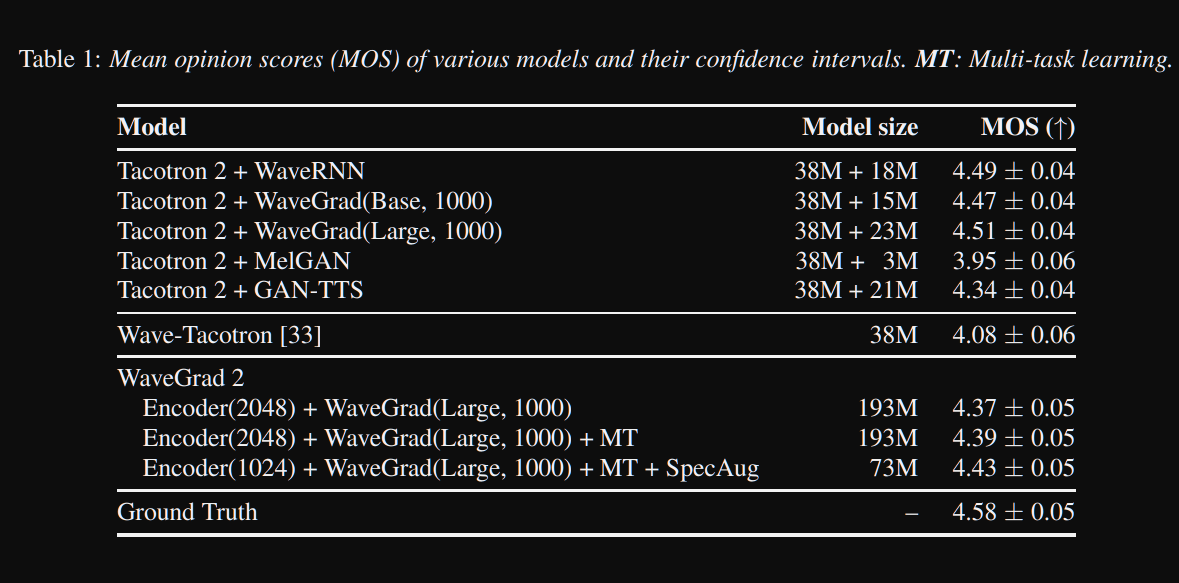
Wavegrad2 : https://arxiv.org/pdf/2106.09660.pdf (클릭하여 확장)
- 그것은 음소 시퀀스에서 직접 원시 파형을 계산합니다.
- 타코트론 2와 같은 인코더 모델은 음소로부터 숨겨진 표현을 계산하는 데 사용됩니다.
- 소프트 지속 시간 예측 변수와 같은 비 엔트리 성 타코 트론은 숨겨진 표현을 출력과 정렬합니다.
- 그들은 예측 된 지속 시간으로 숨겨진 표현을 확장하고 특정 창을 샘플링하여 파형으로 변환합니다.
- 그들은 0.8 및 3.2 초의 음성에 해당하는 64 및 256 프레임 사이의 다른 창 크기를 탐색했습니다. 그들은 클수록 더 좋습니다.
- 데모 페이지 : 지금까지 아무것도 없습니다
- 코드 : 지금까지 코드가 없습니다
멀티 스피커 종이
- 스피커-임을 사용하는 멀티 스피커 신경 텍스트-스피치 시스템 교육 corpora-https://arxiv.org/abs/1904.00771
- Deep Voice 2- https://papers.nips.cc/paper/6889-deep-voice-2-multi-seaker-neural-text-speech.pdf
- 샘플 효율적인 적응 형 TTS -https://openreview.net/pdf?id=rkzjuoacfx
- 음성 루프 -https://arxiv.org/abs/1707.06588
- 신경 TTS를 개선하기위한 멀티 스피커 잠재 공간 모델링 새로운 스피커를 빠르게 등록하고 프리미엄 음성 향상 -https://arxiv.org/pdf/1812.05253.pdf
- 스피커 검증에서 멀티 스피커 텍스트-음주 합성으로 전송 학습 -https://arxiv.org/pdf/1806.04558.pdf
- 짧은 번영되지 않은 샘플을 기반으로 새로운 스피커를 맞추고 -https://arxiv.org/pdf/1802.06984.pdf
- 스피커 검증을위한 일반화 된 엔드 투 엔드 손실 -https://arxiv.org/abs/1710.10467
광대 한 요약
불연속 음성 표현을 사용한 다중 스피커 텍스트-음주 합성에 대한 반 감독 학습 : http://arxiv.org/abs/2005.08024
- 1 시간 길이의 짝을 이루는 데이터 (텍스트-투표 정렬)와 더 짝을 이루지 않은 (Voide) 데이터로 멀티 스피커 TTS 모델을 교육하십시오.
- 각 코드 단어가있는 코드 북이 단일 음소에 해당합니다.
- 코드 북은 페어링 된 데이터와 CTC 알고리즘을 사용하여 음소에 정렬됩니다.
- 이 코드 북은 프록시와 같은 기능을 수행하여 짝을 이루지 않은 데이터의 음소 순서를 암시 적으로 추정합니다.
- 그들은 모델의 초기 부분에서 생성 된 코드 워드 임베딩을 사용하여 TTS를 수행하기 위해 Tacotron2 모델을 위에 쌓아 놓았습니다.
- 그들은 1 시간 길이의 짝을 이루는 데이터 설정에서 벤치 마크 방법을 이겼습니다.
- 그들은 전체 쌍을 이루는 데이터 결과를보고하지 않습니다.
- 그들은 모델의 다른 부분이 성능에 어떻게 기여하는지 보는 것이 흥미로울 수있는 좋은 절제 연구가 없습니다.
- 그들은 Griffin-lim을 보코더로 사용하므로 개선을위한 공간이 있습니다.
데모 페이지 : https://ttaoretw.github.io/multispkr-semi-tts/demo.html
코드 : https://github.com/ttaoretw/semi-tts 
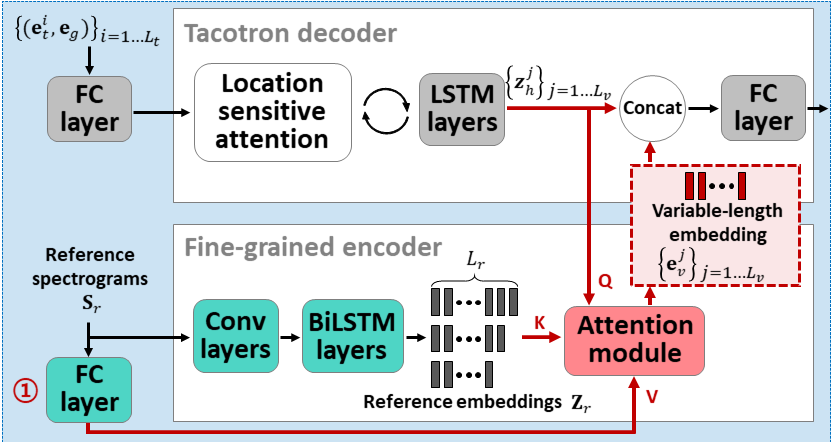
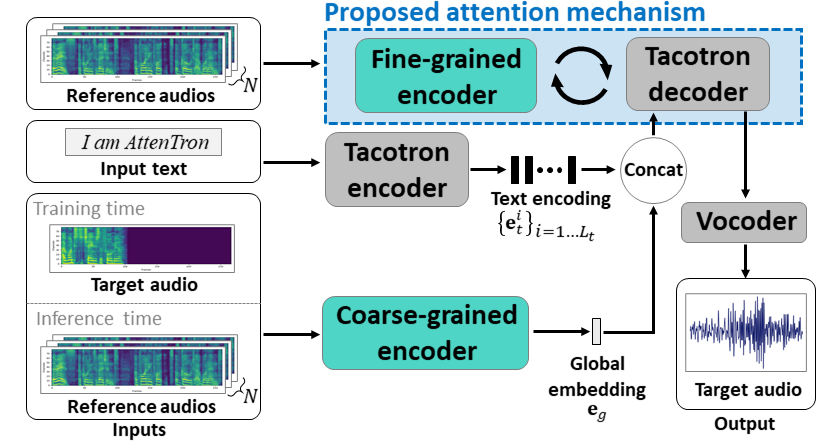
ATSENTRON :주의 기반 변수 길이 임베딩을 악용하는 소수의 텍스트-음성 : https://arxiv.org/abs/2005.08484
- 두 개의 인코더를 사용하여 스피커에 의존하는 기능을 배우십시오.
- 거친 인코더는 제공된 기준 스펙트로 그램을 기반으로 글로벌 스피커 임베딩 벡터를 학습합니다.
- 미세 엔코더는주의 모듈과 협력하여 시간적 치수를 유지하는 가변 길이 임베딩을 배웁니다.
- 주의는 목표 음성을 합성하기 위해 중요한 기준 스펙트로 그램 프레임을 선택합니다.
- 단일 스피커 데이터 세트를 사용하여 모델을 사전 트레인합니다 (30K ITERS 용 LJSPEECH).
- 멀티 스피커 데이터 세트로 모델을 미세 조정하십시오. (70k Iters 용 VCTK)
- 스피커 분류 모델 및 VAE 기반 참조 오디오 인코더의 X 벡터 사용과 비교하여 약간 더 나은 메트릭을 달성합니다.
데모 페이지 : https://hyperconnect.github.io/attentron/
Universal Text-To-Speech쪽으로 : http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
- 다국적 TTS 시퀀스 시퀀스에 대한 프레임 워크
- 이 모델은 매우 크고 균형 잡힌 데이터 세트로 훈련됩니다.
- 이 모델은 6 분 동안 새로운 언어를 배울 수 있으며 초기 교육 후 20 초의 데이터를 가진 새로운 스피커를 배울 수 있습니다.
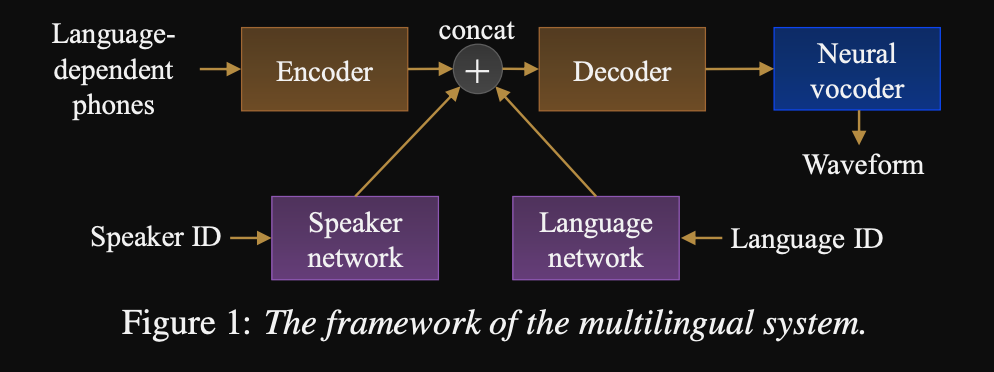
- 모델 아키텍처는 스피커 네트워크와 스피커 및 언어 조건을위한 언어 네트워크를 갖춘 변압기 기반 인코더 디코더 네트워크입니다. 이 네트워크의 출력은 인코더 출력에 연결됩니다.
- 컨디셔닝 네트워크는 스피커 또는 언어 ID를 나타내는 일대일 벡터를 사용하여 컨디셔닝 표현으로 투사합니다.
- 그들은 예측 된 멜 스피어 그램을 파형 출력으로 변환하기 위해 Wavenet 보코더를 사용합니다.
- 그들은 언어를 사용하여 언어들 사이에 공유되지 않은 음소 입력에 의존합니다.
- 데이터 세트에서 각 언어의 역 주파수에 따라 각 배치를 샘플링합니다. 따라서 각 훈련 배치는 언어에 대한 균일 한 분포를 가지며 교육 데이터 세트에서 언어 불균형을 완화시킵니다.
- 새로운 스피커/언어를 배우기 위해 컨디셔닝 네트워크로 인코더 디코더 모델을 미세 조정합니다. 그들은 Wavenet 모델을 훈련시키지 않습니다.
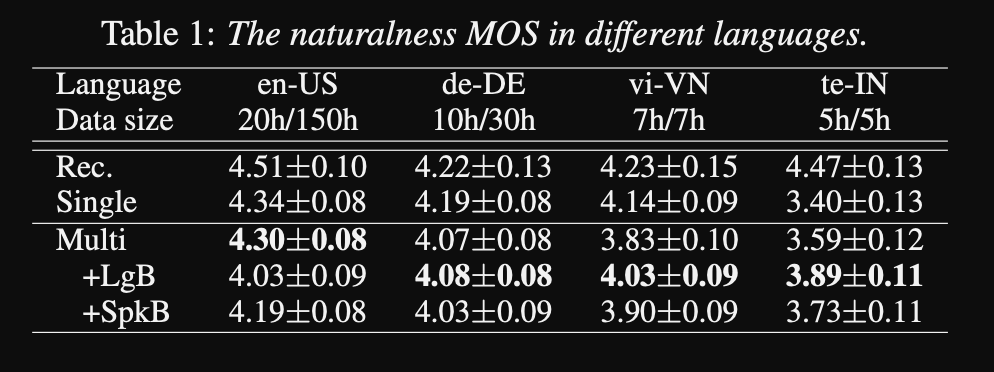
- 그들은 훈련을 위해 50 개 언어에서 1250 시간의 전문 녹음을 사용합니다.
- 그들은 모든 오디오 샘플에 16kHz 샘플링 속도를 사용하고 각 클립의 시작과 끝에서 침묵을 다듬습니다.
- 그들은 훈련을 위해 4 V100 GPU를 사용하지만 모델을 얼마나 오래 훈련 시켰는지는 언급하지 않습니다.
- 결과는 단일 스피커 모델이 MOS 메트릭에서 제안 된 접근법보다 낫다는 것을 보여줍니다.
- 또한 조절 네트워크를 사용하는 것은 데이터 세트의 장거리 언어에 대해 MOS 메트릭을 개선하지만 고급 자치소 언어의 성능을 손상시키기 때문에 중요합니다.
- 새로운 스피커를 추가하면 5 분 이상의 데이터를 사용하면 모델 성능이 저하된다는 것을 관찰합니다. 그들은 이러한 녹음이 원래 녹음만큼 깨끗하지 않기 때문에 더 많은 것을 사용하는 것이 모델의 일반적인 성능에 영향을 미칩니다.
- 다국어 모델은 새로운 스피커 및 언어에 대한 6 분의 데이터로 단일 스피커 모델을 훈련시킬 수있는 반면, 단일 스피커 모델은 훈련하는 데 3 시간이 필요하며 6 분 다국어 모델과 비슷한 MOS 값을 얻을 수 없습니다.
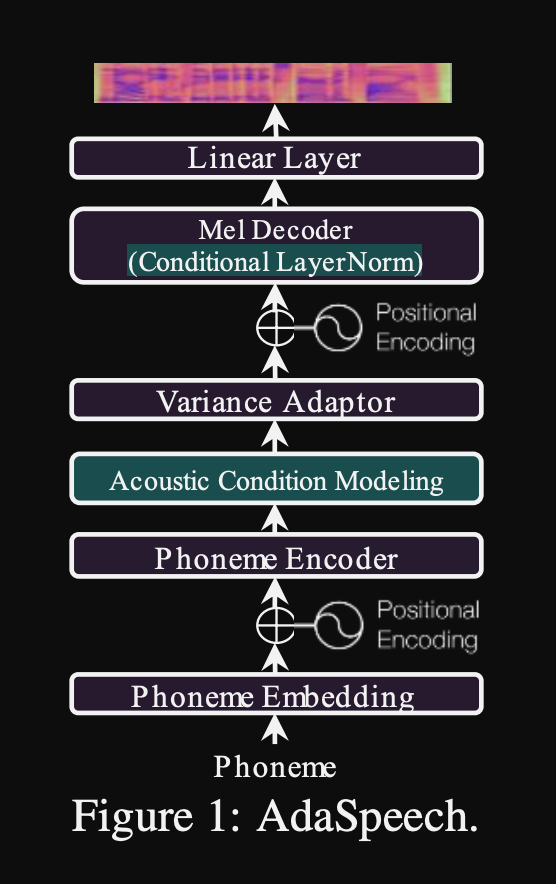
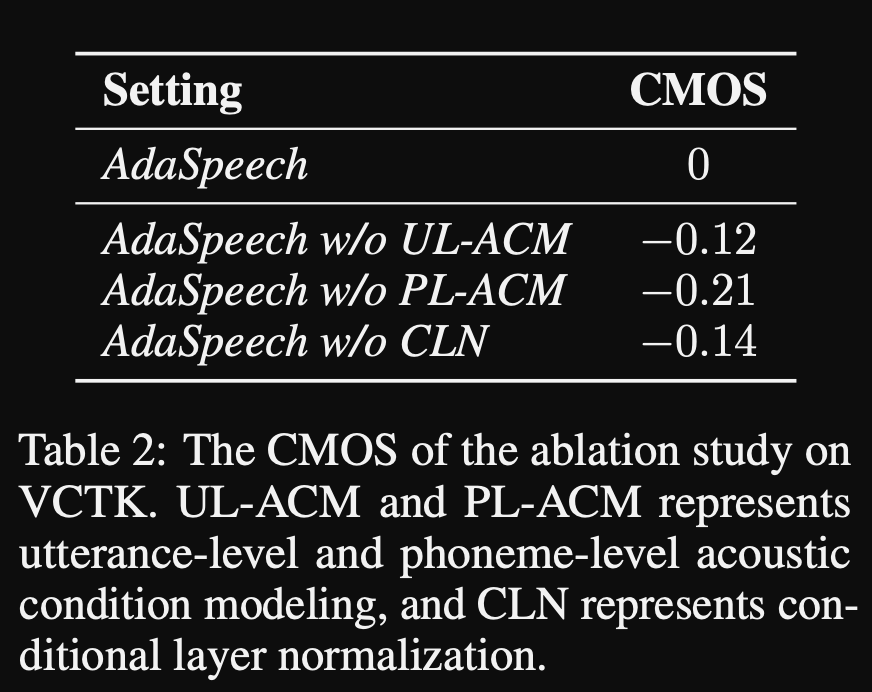
Adaspeech : 사용자 정의 음성에 대한 적응 텍스트 : https://openreview.net/pdf?id=drynvt7gg4l
- 그들은 사용자의 다른 입력 음향 속성에 적응할 수있는 시스템을 제안했으며 최소 수의 매개 변수를 사용하여이를 달성했습니다.
- 주요 아키텍처는 피치 및 분산 예측 변수를 사용하여 입력 음성의 더 미세한 세분성을 배우는 FastSpeech2 모델을 기반으로합니다.
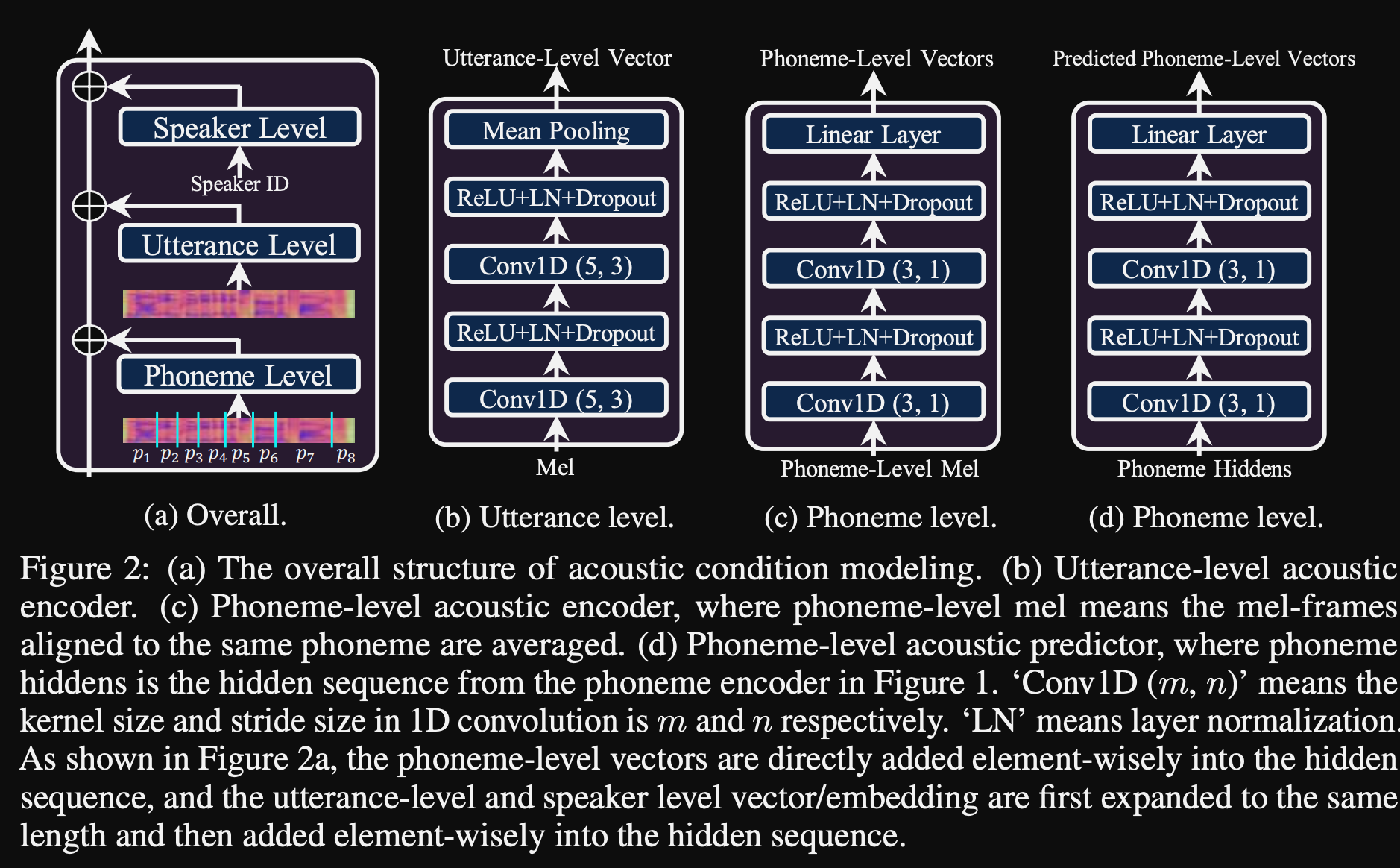
- 그들은 3 개의 추가 컨디셔닝 네트워크를 사용합니다.
- 발언 수준. 참조 음성의 Mel-spectrogram을 입력으로 사용합니다.
- 음소 수준. 입력으로 음소 레벨 멜 스펙트럼 그램이 필요하며 음소 수준 컨디셔닝 벡터를 계산합니다. 음소수 수준의 Mel-spectrogram은 각 음소의 지속 시간에 평균 스펙트로 그램 프레임을 복용하여 계산됩니다.
- 음소 레벨 2. Phoneme 인코더 출력을 입력으로 사용합니다. 이는 스펙트로 그램을 보지 않고 음소 정보 만 사용하여 위의 네트워크와 다릅니다.
- 이러한 모든 컨디셔닝 네트워크와 백 본 FastSpeech2는 층 정규화 층을 사용합니다.
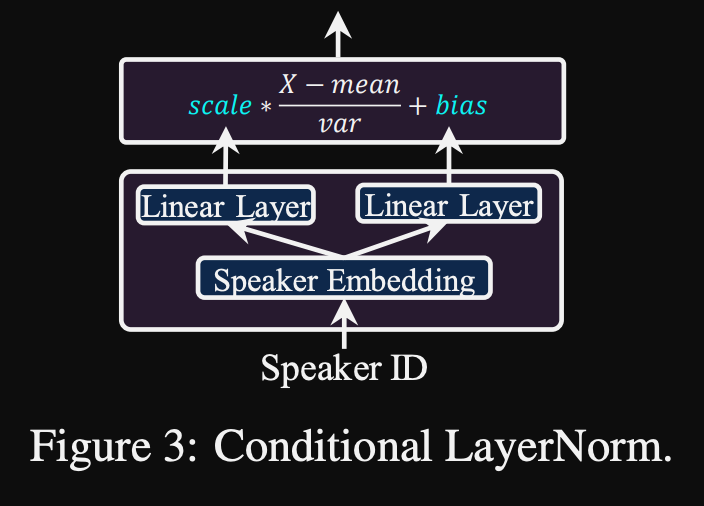
- 조건부 정규화. 모델이 새 스피커에 대해 미세 조정 될 때 각 계층 정규화 층의 스케일 및 바이어스 파라미터 만 미세 조정을 제안합니다. 스케일과 바이어스 값을 출력하는 각 계층 표준 계층에 대한 스피커 컨디셔닝 모듈을 훈련시킵니다. (변압기 블록 당 하나의 스피커 컨디셔닝 모듈을 사용합니다.)
- 이는 각 새로운 스피커에 대한 스피커 컨디셔닝 모듈 만 저장하고 나머지 모델을 동일하게 유지하면서 추론에 스케일 및 바이어스 값을 예측한다는 것을 의미합니다.
- 실험에서 그들은 Libritts 데이터 세트에서 모델을 사전 훈련하고 VCTK 및 LJSpeech로 미세 조정합니다.
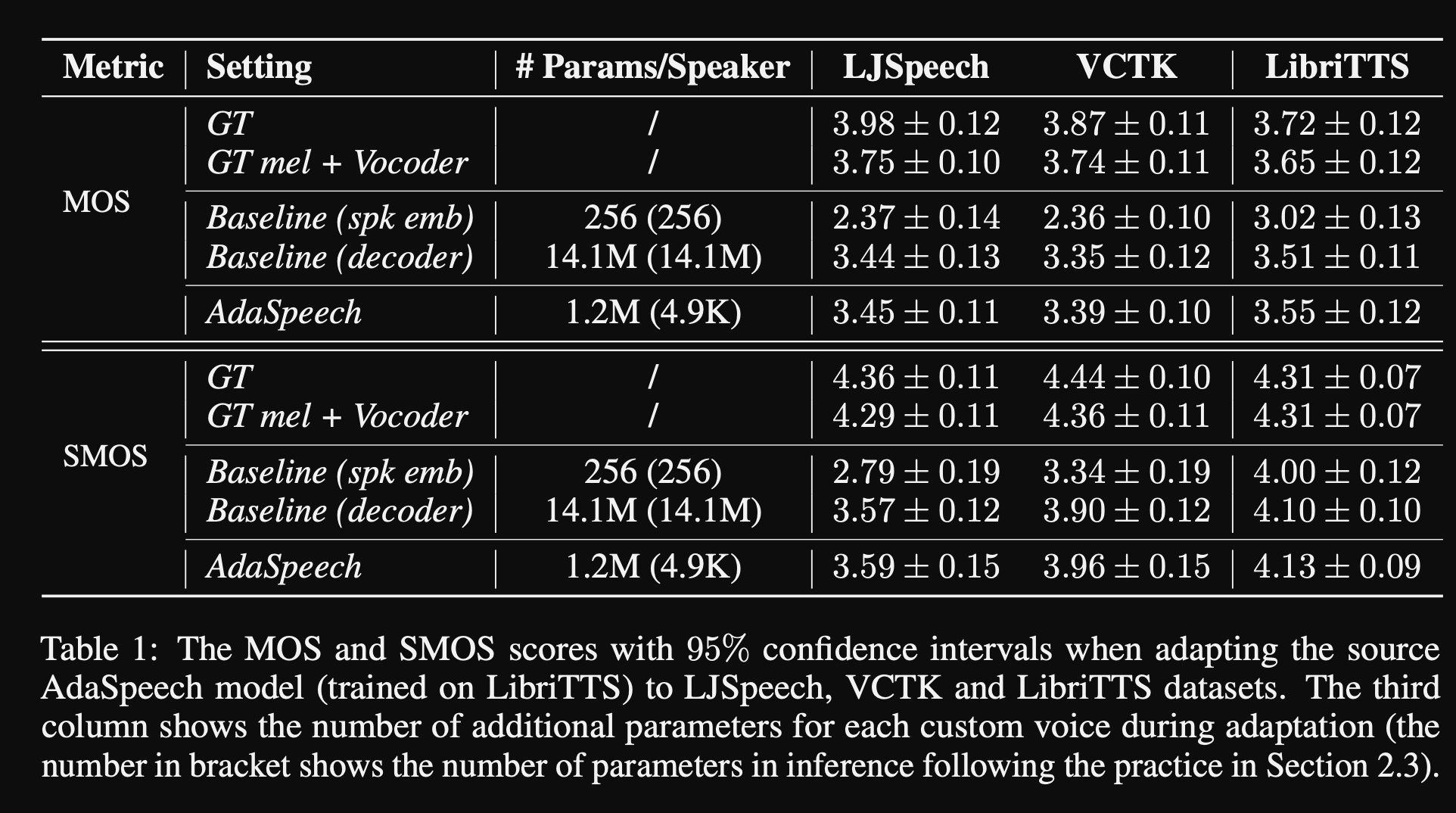
- 결과는 조건부 계층 정규화를 사용하는 것이 스피커 임베딩 및 디코더 네트워크 미세 조정 만 사용하는 2 개의 기준선보다 더 나은 것으로 나타났습니다.
- 그들의 절제 연구에 따르면 모델의 가장 중요한 부분은 "음소 수준"네트워크와 조건부 계층 정규화 및 "발화 레벨"네트워크가 순서대로 이어집니다.
- 논문의 중요한 중 하나는 문헌과 비교할 수 없으며 결과를 객관적으로 평가하기가 더 어렵다는 것입니다.
데모 페이지 : https://speechresearch.github.io/adaspeech/

주목
- 강력한 긴 형식 스피치 합성을위한 위치 관련주의 메커니즘 -https://arxiv.org/pdf/1910.10288.pdf
보코더
Melgan : https://arxiv.org/pdf/1910.06711.pdf
Parallel Wavegan : https://arxiv.org/pdf/1910.11480.pdf
- 다중 규모의 stft 손실
- ~ 1m 모델 매개 변수 (매우 작은)
- Wavernn보다 약간 더 나쁩니다
FFTNET 개선
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
노이즈 및 주기적 입력을 가진 Convolutional Neuralnetworks를 사용한 음성 파형 재구성
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
강력한 보편적 보코딩을 달성하기 위해
- https://arxiv.org/pdf/1811.06292.pdf
LPCNET
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
흥분
- https://arxiv.org/pdf/1811.04769v3.pdf
GELP : Mel-spectrogram의 음성 합성을위한 GAN- 발전된 선형 예측
- https://arxiv.org/pdf/1904.03976v3.pdf
적대적 네트워크를 사용한 고 충실도 음성 합성 : https://arxiv.org/abs/1909.11646
- GAN-TTS, 엔드 투 엔드 음성 합성
- 기간과 언어 기능을 사용합니다
- 지속 시간 및 음향 특징은 추가 모델로 예측됩니다.
- 랜덤 윈도우 판별 자 : 전체 음성 샘플이 아니라 임의의 창을 섭취합니다.
- 다수의 RWD. 조건부 및 무조건. (입력 기능 조건)
- 펀치 라인 : D에 대한 창 크기가 다른 무작위로 샘플링 된 창을 사용하십시오.
- 공유 결과는 비 신경 음향 특징의 한계를 보여주는 기계적으로 들립니다.
멀티 밴드 멜간 : https://arxiv.org/abs/2005.05106
- 피처 매칭 손실 대신 PWGAN 손실을 사용하십시오.
- 더 큰 수용 필드를 사용하면 모델 성능이 크게 향상됩니다.
- 200k ITERS의 발전기 사전 연상.
- 다중 대역 음성 신호 예측. 출력은 PQMF 합성 필터를 사용한 4 개의 다른 대역 예측의 요약입니다.
- 멀티 밴드 모델에는 1.9m 매개 변수가 있습니다 (아주 작은).
- Melgan보다 7 배 빠르다고 주장했습니다
- 중국 데이터 세트 : MOS 4.22
Waveglow : https://arxiv.org/abs/1811.00002
- 매우 큰 모델 (268m 매개 변수)
- 12GB GPU에서 훈련하기가 어렵습니다. 배치 크기 1 만 필요할 수 있습니다.
- 컨벤션 사용으로 인한 실시간 추론.
- 반전 할 수없는 정규화 흐름에 기초합니다. (훌륭한 튜토리얼 https://blog.evjang.com/2018/01/nf1.html)
- 모델은 최대 우도 손실로 멜 스피어 그램에 오디오 샘플을 학습하고 보이지 않는 맵핑을 배우고 있습니다.
- 추론에서 네트워크는 역 방향으로 실행되며 MEL-SPEC가 오디오 샘플로 변환됩니다.
- 훈련은 32GB RAM, 배치 크기 24를 갖춘 8 NVIDIA V100을 사용하여 수행되었습니다. (비싸다)
squeezewave : https://arxiv.org/pdf/2001.05685.pdf, 코드 : https://github.com/tianrengao/squeezewave
- ~ 5-13 배의 실시간보다 빠릅니다
- Waveglow redanduncies : 긴 오디오 샘플, 멜 스펙을 업 샘플링, WN 기능의 큰 채널 치수.
- 수정 사항 : 입력으로 오디오 샘플이 많지만 더 짧은 오디오 샘플 (L = 2000, C = 8 대 L = 64, C = 256)
- L = 64는 MEL-SPEC 해상도와 일치하므로 업 샘플링이 필요하지 않습니다.
- WN 모듈에서 깊이 현저한 분리 가능한 컨벤션을 사용하십시오.
- 오디오 샘플이 짧아서 확장 대신 정기적 인 컨볼 루션을 사용하십시오.
- 이러한 벡터가 거의 동일하다고 가정 할 때 모듈 출력을 잔차 및 네트워크 출력으로 분할하지 마십시오.
- 600K 반복에 대한 Titan RTX 24GB 배치 크기 96을 사용하여 교육을 수행했습니다.
- ljspeech의 MOS : Waveglow -4.57, squeezewave (l = 128 c = 256) -4.07 및 squeezewave (l = 64 c = 256) -3.77
- 가장 작은 모델은 RASPI3에서 초당 21K 샘플을 가지고 있습니다.
Wavegrad : https://arxiv.org/pdf/2009.00713.pdf
- 확산 및 Lagenvin 역학을 기반으로합니다
- 기본 아이디어는 알려진 분포를 반복적으로 타겟팅하기 위해 알려진 분포를지도하는 함수를 배우는 것입니다.
- 그들은 GPU에서 0.2 실시간 요소를보고하지만 CPU 성능은 공유되지 않습니다.
- 아래의 예제 코드에서 저자는 단일 GPU에 대한 2 일의 교육 후 모델이 수렴한다고보고합니다.
- 논문의 MOS 점수는 충분히 적합하지 않지만 Wavernn 및 Wavenet과 같은 알려진 모델과 비슷한 성능을 보여줍니다.
코드 : https://github.com/ivanvovk/wavegrad 
인터넷 (블로그, 비디오 등)에서
비디오
논문 토론
- Tacotron 2 : https://www.youtube.com/watch?v=2iarxxm-v9w
대화
- 2021 년 Xu Tan, https://youtu.be/ma8pcvmr8b0의 신경 텍스트-스페치의 국경을 추진하는 것에 대해 이야기하십시오.
- Heiga Zen, 2017의 생성 모델 기반 텍스트 음성 합성 합성에 대해 이야기하십시오.
- 비디오 : https://youtu.be/nsrsrytkkt8
- 슬라이드 : https://research.google.com/pubs/pub45882.html
- ISCA Odyessy 2020의 신경 파라 메트릭 텍스트 음성 음성 합성에 대한 튜토리얼, Xin Wang, 2020
- 비디오 : https://youtu.be/wce7sycdzai
- 슬라이드 : http://tonywangx.github.io/slide.html#dec-2020
- 신경 보구에 대한 ISCA 음성 처리 과정, 2022
- 신경 보코더의 기본 구성 요소 : https://youtu.be/m833q5i-zys
- 음성 압축 (LPCNET)에 대한 깊은 생성 모델 : https://youtu.be/7ksnfx3plgw
- 신경 자동 평균, 소스 필터 및 글로벌 보코더 : https://youtu.be/gprmxdberx0
- 슬라이드 : http://tonywangx.github.io/slide.html#jul-2020
- 음성 문장의 신경 디코딩으로 인한 음성 합성 | AISC : https://www.youtube.com/watch?v=mndtmdpmnmo
- 생성 텍스트-음성 합성 합성 : https://www.youtube.com/watch?v=j4MVeanking
- 게임 산업의 음성 합성 : https://www.youtube.com/watch?v=aoHaye4A-2Q
일반적인
- 최신 텍스트-음성 시스템 검토 : https://www.youtube.com/watch?v=8RXLSC-ZCry
Jupyter 노트북
- 선택된 신경 보코더에 대한 튜토리얼 : https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
블로그
- 텍스트 연설 딥 러닝 아키텍처 : http://www.erogol.com/text-speech-deep-learning-architectures/


