(Siéntase libre de sugerir cambios)
Papeles
- Representaciones de fonema y char fomento: https://arxiv.org/pdf/1811.07240.pdf
- Tacotron Transfer Learning: https://arxiv.org/pdf/1904.06508.pdf
- Tiempo de fonema de la atención: https://ieeEexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Entrenamiento semi-supervisado para mejorar la eficiencia de los datos en la síntesis del habla de extremo al final-https://arxiv.org/pdf/1808.10128.pdf
- Escuchar mientras habla: Speech Chain por Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Pérdida de extremo a extremo generelizada para la verificación del orador: https://arxiv.org/pdf/1710.10467.pdf
- ES-Tacotron2: Tacotron 2 de tareas múltiples con una red estimada previamente entrenada para reducir el problema excesivo
- FastSpeech: https://arxiv.org/pdf/1905.09263.pdf
- Aprendizaje de canto del discurso: https://arxiv.org/pdf/1912.10128.pdf
- TTS-Gan: https://arxiv.org/pdf/1909.11646.pdf
- Utilizan funciones de duración y lingüística para EN2EN TTS.
- Cerca del rendimiento de Wavenet.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Tacotron consciente de la duración
- Melnet: https://arxiv.org/abs/1906.01083
- Aligntts: https://arxiv.org/pdf/2003.01950.pdf
- Descomposición del habla no supervisada a través del cuello de botella de Triple Information
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Flujo autorreegresivo inverso en tacotrón como arquitectura
- Glojo de onda como vocoder.
- Estilo de voz incrustación con mezcla de modelo gaussiano.
- El modelo es grande y más prestado que el tacotrón de vainilla
- Los valores de MOS son muy mejores que la implementación pública de tacotrón.
- Sistema de texto a voz de eficiencia eficiente basado en redes convolucionales profundas con atención guiada: https://arxiv.org/pdf/1710.08969.pdf
Resúmenes expansivos
Texto adversario de extremo a-end: http://arxiv.org/abs/2006.03575 (haga clic para expandir)
- End2END Feed-Forward TTS Learning.
- La alineación de los personajes se ha realizado con un módulo de alineador separado.
- El alineador predice la longitud de cada personaje. - La ubicación central de un char se encuentra en la longitud total de los caracteres anteriores. - Las posiciones de char se interpolan con una ventana gaussiana WRT la longitud de audio real.
- La salida de audio se calcula en el dominio MU-law. (No tengo un razonamiento para esto)
- Use solo 2 ventanas de audio de 2 segundos para Traning.
- El generador GAN-TTS se usa para producir una señal de audio.
- RWD se usa como discriminador de nivel de audio.
- MELD: Utilizan la arquitectura de Biggan-DeP como discriminador de nivel de espectrograma que registra el problema como reconstrucción de imágenes.
- Pérdida de espectrograma
- Usar solo el retroceso adversario no es suficiente para aprender las alineaciones de Char. Utilizan una pérdida de espectrograma b/w predicho espectrogramas y especificaciones de verdad en tierra.
- Tenga en cuenta que el modelo predice señales de audio. Los espectrogramas anteriores se calculan a partir del audio generado.
- El envoltura de tiempo dinámico se utiliza para calcular un alineación de costo mínimo B/W espectrogramas generados y verdad terrestre.
- Implica un enfoque de programación dinámica para encontrar una alineación de costo mínimo.
- La pérdida de longitud del alineador se usa para penalizar el alineador para predecir diferente a la longitud de audio real.
- Entrenan el modelo con un conjunto de datos de altavoces múltiples, pero informan los resultados en el altavoz de mejor rendimiento.
- Información del estudio de ablación de cada componente: (Longloss y Spectrogramloss)> Rwd> Meld> Phonemes> MultispeakerDataset.
- Mis 2 centavos: es un modelo de alimentación que proporciona síntesis de voz de extremo-2 sin necesidad de entrenar un modelo de vocoder separado. Sin embargo, es un modelo muy complicado con muchos hiperparámetros y detalles de implementación. Además, el resultado final no está cerca del estado del arte. Creo que necesitamos encontrar algoritmos específicos para aprender alineaciones de caracteres que reducirían la necesidad de sintonizar una combinación de diferentes algoritmos.
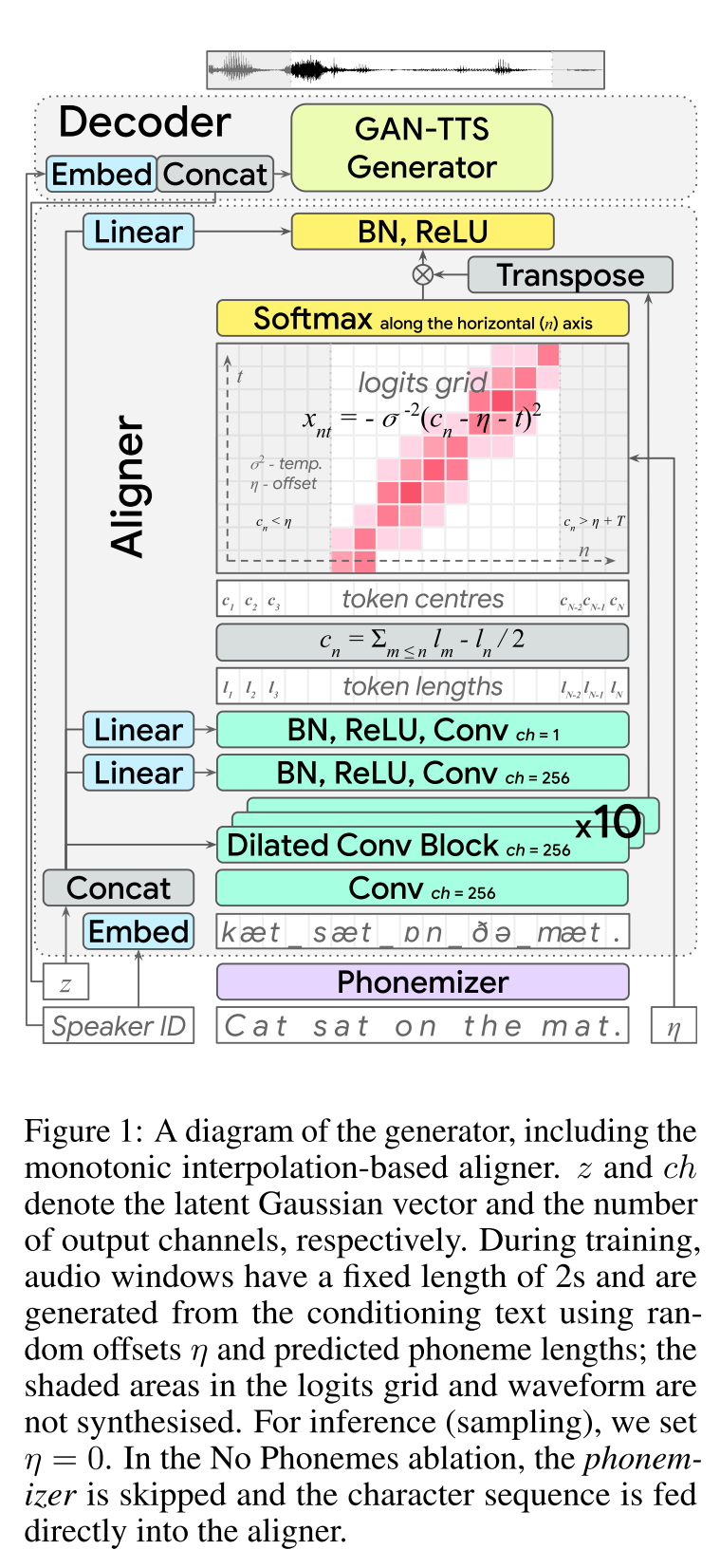
Discurso rápido2: http://arxiv.org/abs/2006.04558 (haga clic para expandir)
- Use duraciones de fonemas generados por MFA como etiquetas para entrenar un regulador de longitud.
- Utilice las normas del espectrograma de nivel de marco F0 y L2 (información de varianza) como características adicionales.
- El módulo predictor de varianza predice la información de varianza en el momento de la inferencia.
- Mejoras de resultados del estudio de ablación: modelo <modelo + l2_norm <modelo + l2_norm + f0
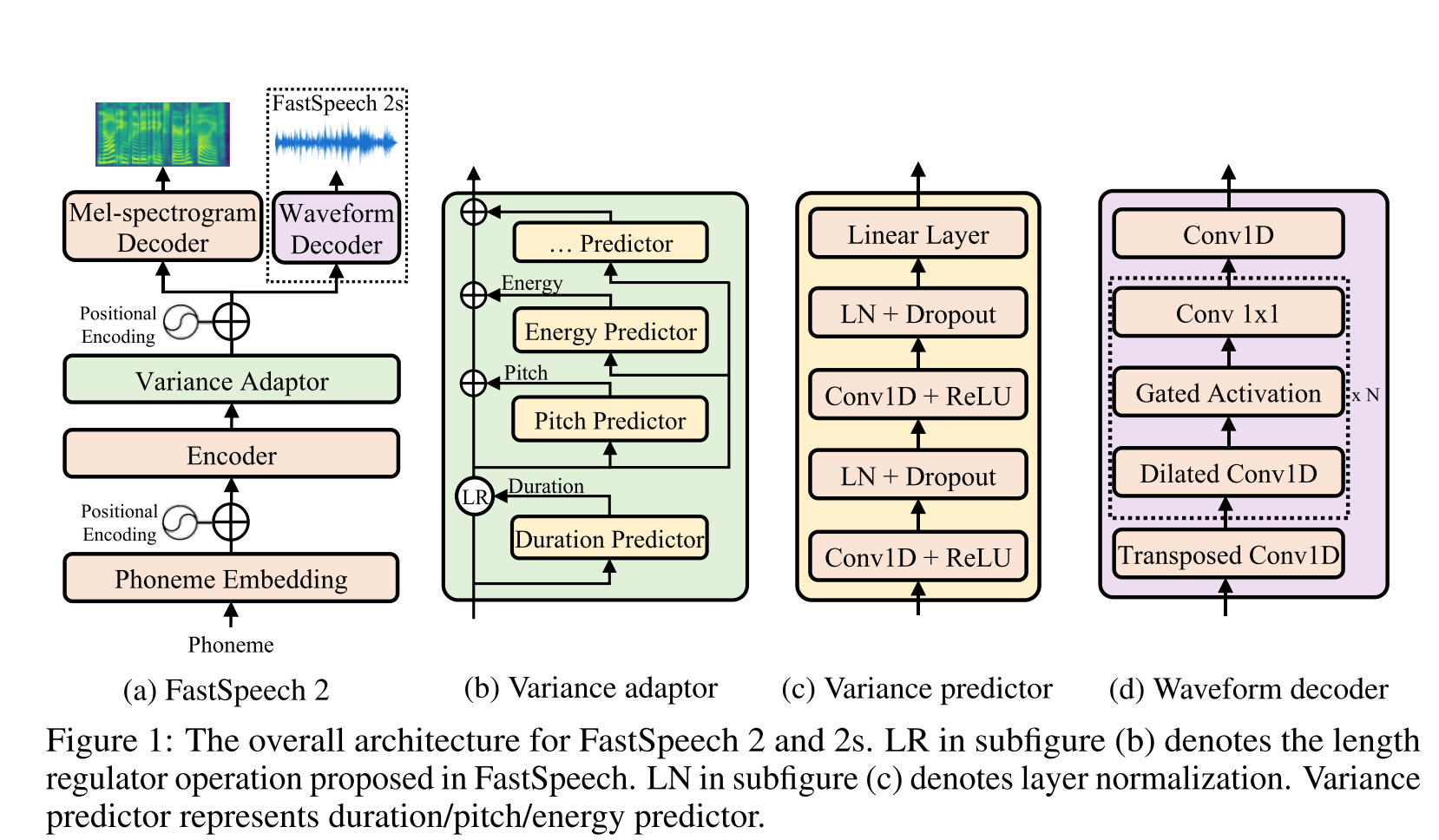
GLOW-TTS: https://arxiv.org/pdf/2005.11129.pdf (haga clic para expandir)
- Use la búsqueda de alineación monotónica para aprender la alineación b/w texto y espectrograma
- Esta alineación se utiliza para entrenar un predictor de duración para ser utilizado en inferencia.
- El codificador asigna a cada personaje a una distribución gaussiana.
- El decodificador mapea cada marco de espectrograma a un vector latente utilizando flujo de normalización (capas de brillo)
- Las salidas de codificadores y decodificadores están alineadas con MAS.
- Primero, en cada iteración, MAS encuentra la alineación más probable y esta alineación se utiliza para actualizar los parámetros del modo.
- Un predictor de duración está entrenado para predecir el número de marcos de espectrograma para cada personaje.
- A inferencia solo se usa el predictor de duración en lugar de MAS
- El codificador tiene la arquitectura del transformador TTS con 2 actualizaciones
- En lugar de una codificación posicional absoluta, usan la codificación posicional realista.
- También usan una conexión residual para el prenet codificador.
- El decodificador tiene la misma arquitectura que el modelo GLOW.
- Entrenan tanto el modelo único como de múltiples altavoces.
- Se muestra experimentalmente, Glow-TTS es más robusto contra oraciones largas en comparación con Tacotron2 original
- 15 veces más rápido que Tacotron2 en inferencia
- Mis 2 centavos: sus muestras suenan no tan naturales como Tacotron. Creo que los modelos de atención normal aún generan un discurso más natural, ya que la atención aprende a mapear los caracteres para modelar salidas directamente. Sin embargo, el uso de GLOW-TTS podría ser una buena alternativa para conjuntos de datos duros.
- Muestras: https://github.com/jaywalnut310/glow-tts
- Repositorio: https://github.com/jaywalnut310/glow-tts
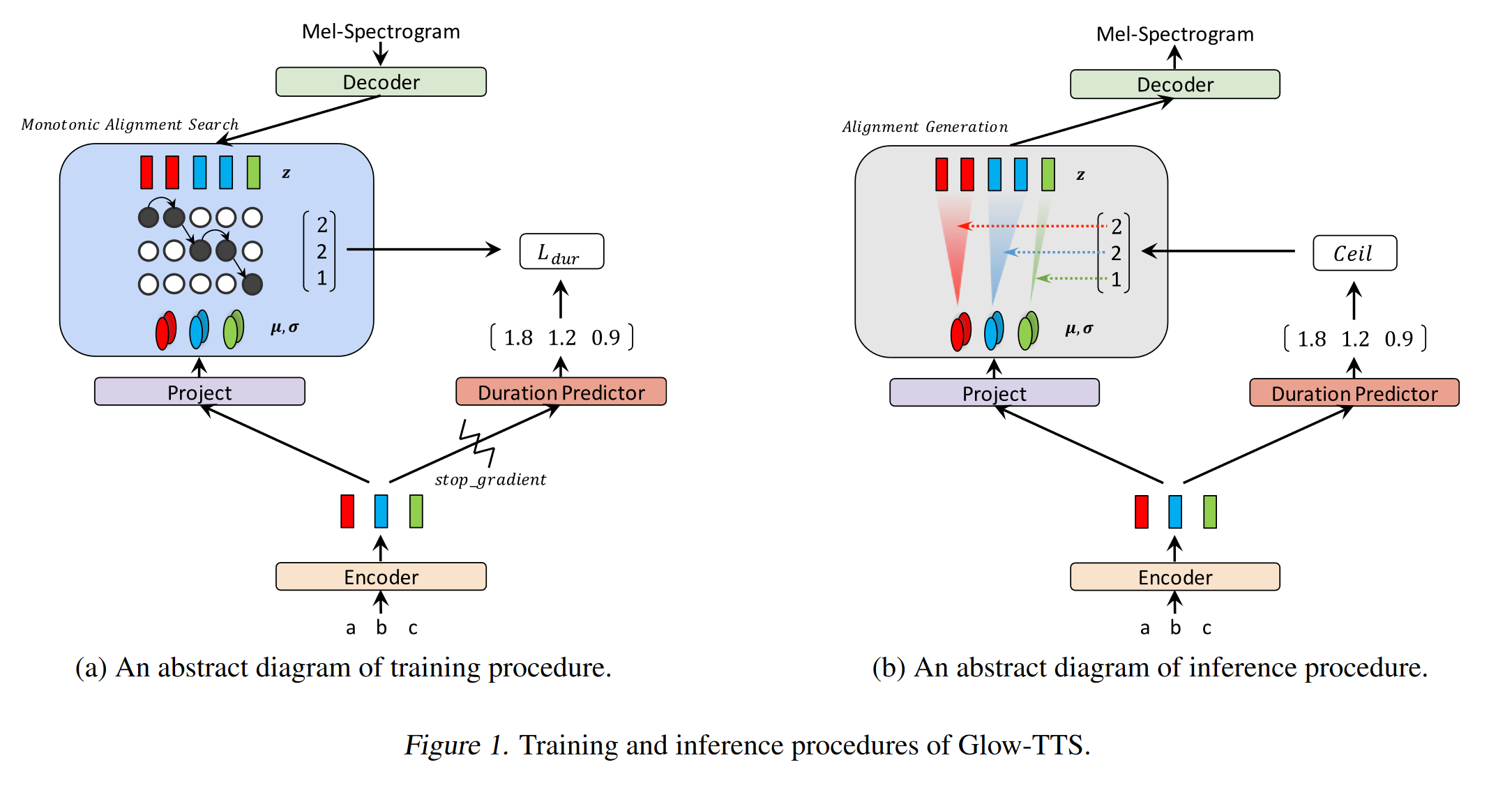
Texto neuronal no autorregresivo: http://arxiv.org/abs/1905.08459 (haga clic para expandir)
- Una derivación del modelo de voz profunda 3 utilizando capas convolucionales no causales.
- Paradigma de maestro-alumno para entrenar a un estudiante de Annon-Autoregressess con múltiples bloques de atención de un modelo de maestro autorregresivo.
- El maestro se utiliza para generar alineaciones de texto a espectrograma para ser utilizados por el modelo del alumno.
- El modelo está entrenado con dos funciones de pérdida para la alineación de atención y la generación de espectrogramas.
- Los bloques de atención múltiple refinan la capa de alineación de atención por capa.
- El estudiante utiliza la atención del producto DOT con la consulta, la clave y los vectores de valor. La consulta es solo vectores de codificación positinal. La clave y el valor son las salidas del codificador.
- El modelo propuesto está fuertemente ligado a la codificación posicional que también se basa en diferentes valores constantes.
Consistencia de dos decodificadores: https://erogol.com/solving-attention-problems-of-tts-models-with-double-decoder- consistencia (haga clic para expandir)
- El modelo utiliza una arquitectura de tacotrón como con 2 decodificadores y una Postnet.
- DDC utiliza dos decodificadores sincrónicos utilizando diferentes tasas de reducción.
- Los decodificadores utilizan diferentes tasas de reducción, por lo tanto, calculan salidas en diferentes granularidades y aprenden diferentes aspectos de los datos de entrada.
- El modelo utiliza la consistencia entre estos dos decodificadores para aumentar la robustez de la alineación de texto a espectrograma aprendido.
- El modelo también aplica un refinamiento a la salida del decodificador final aplicando la Postnet iterativamente varias veces.
- DDC utiliza la normalización por lotes en el módulo prenet y deja caer capas de abandono.
- DDC utiliza entrenamiento gradual para reducir el tiempo total de entrenamiento.
- Utilizamos un generador de Melgan de múltiples bandas como vocoder entrenado con múltiples discriminadores de ventanas aleatorias de manera diferente al trabajo original.
- Podemos entrenar un modelo DDC solo en 2 días con una sola GPU y el modelo final puede generar más rápido que el discurso en tiempo real en una CPU. Página de demostración: https://erogol.github.io/ddc-samples/ código: https://github.com/mozilla/tts
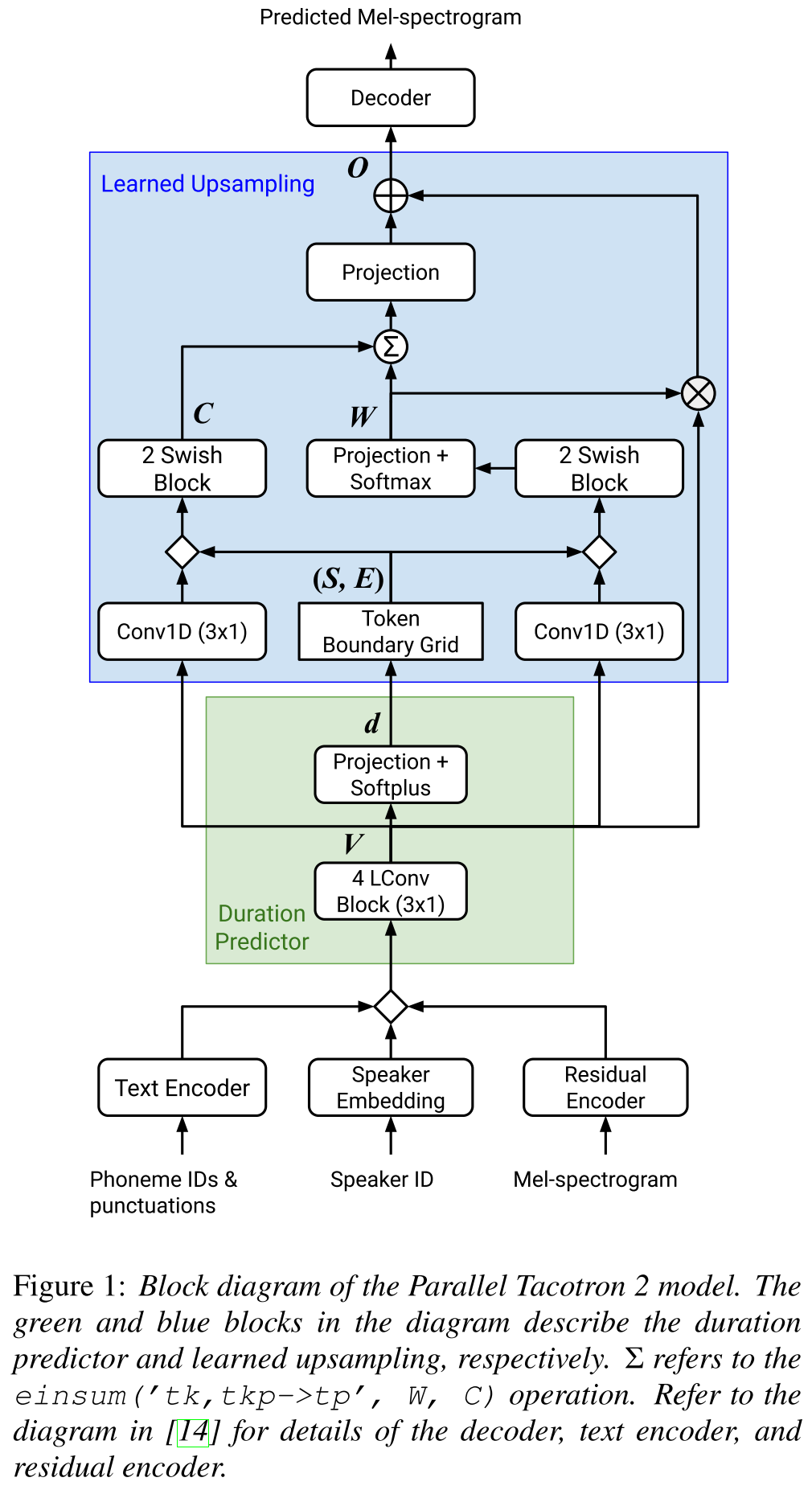
Tacotron2 paralelo: http://arxiv.org/abs/2103.14574 (haga clic para expandir)
- No requiere información de duración externa.
- Resuelve los problemas de alineación entre los espectrogramas reales y de verdad en tierra por pérdida de DTW Soft.
- Las duraciones previstas se convierten en alineación mediante una función de conversión aprendida, en lugar de un regulador de longitud, para resolver problemas de redondeo.
- Aprende un mapa de atención sobre las "redes límite de tokens" que se calculan a partir de las duraciones predichas.
- El decodificador se basa en 6 bloques de "convoluciones de peso ligero".
- Se utiliza un VAE para proyectar espectrogramas de entrada a características latentes y fusionarse con los incrustaciones de caracteres como una entrada a la red.
- Soft-DTW es computacionalmente intensivo ya que calcula la diferencia por pares para todos los marcos de espectrograma. Lo contraen con una cierta ventana diagonal para reducir la sobrecarga.
- El objetivo de duración final es la suma de pérdida de duración, pérdida de VAE y pérdida de espectrograma.
- ¿Solo usan conjuntos de datos patentados para los experimentos?
- Logra el mismo MOS con el modelo Tacotron2 y supera a Paralleltacotron.
- Página de demostración : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Código : no hay código hasta ahora
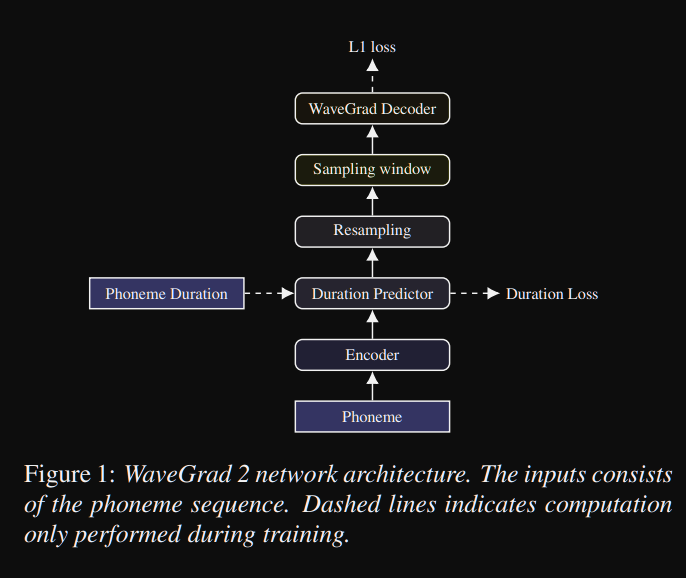
WaveGrad2: https://arxiv.org/pdf/2106.09660.pdf (haga clic para expandir)
- Calcula la forma de onda sin procesar directamente de una secuencia de fonema.
- Se utiliza un modelo de codificador de Tacotron2 como para calcular una representación oculta de los fonemas.
- Tacotrón no atento como predictor de duración suave para alinear la representación oculta con la salida.
- Expanden la representación oculta con las duraciones predichas y muestran una cierta ventana para convertir a una forma de onda.
- Exploraron diferentes tamaños de ventanas entre 64 y 256 cuadros correspondientes a 0.8 y 3.2 segundos de habla. Descubrieron que cuanto más grande es mejor.
- Página de demostración : nada hasta ahora
- Código : no hay código hasta ahora
Papeles múltiples
- Capacitación de sistemas de texto neuronal de texto a la especie de múltiples altavoces utilizando los corpuses del habla de los altavoces-https://arxiv.org/abs/1904.00771
- Voz profunda 2-https://papers.nips.cc/paper/6889-deep-voice-2-multi-speaker-neural-text-to-sepeech.pdf
- Muestra de TTS de adaptación eficiente - https://openreview.net/pdf?id=rkzjuoacfx
- Enfoque de incrustación de Wavenet + Speaker
- Voice Loop - https://arxiv.org/abs/1707.06588
- Modelado de espacio latente de múltiples expansiones para mejorar la inscripción rápida de TTS neural y mejorando la voz premium - https://arxiv.org/pdf/1812.05253.pdf
- Transferir el aprendizaje de la verificación del orador a la síntesis de texto a la especie de multiespeaker-https://arxiv.org/pdf/1806.04558.pdf
- Ajuste de nuevos altavoces basados en una muestra breve no traducida: https://arxiv.org/pdf/1802.06984.pdf
- Pérdida generalizada de finalización para la verificación del orador-https://arxiv.org/abs/1710.10467
Resúmenes expansivos
Aprendizaje semi-supervisado para la síntesis de texto a la especie de múltiples speaker utilizando una representación discreta del habla: http://arxiv.org/abs/2005.08024
- Entrena un modelo TTS de múltiples altavoces con solo una hora de datos emparejados (alineación de texto a voz) y datos más no apareados (solo voces).
- Aprende un libro de código con cada palabra de código corresponde a un solo fonema.
- El libro de código está alineado con los fonemas utilizando los datos pareados y el algoritmo CTC.
- Este libro de código funciona como un proxy para estimar implícitamente la secuencia fonema de los datos no apareados.
- Apilan el modelo Tacotron2 en la parte superior para realizar TTS utilizando los incrustaciones de palabras de código generadas por la parte inicial del modelo.
- Golpean los métodos de referencia en la configuración de datos emparejados de 1 hora de largo.
- No informan los resultados de datos emparejados completos.
- No tienen un buen estudio de ablación que pueda ser interesante para ver cómo las diferentes partes del modelo contribuyen al rendimiento.
- Usan Griffin-Lim como vocoder, por lo que hay espacio para mejorar.
Página de demostración: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
Código: https://github.com/ttaoretw/semi-tts 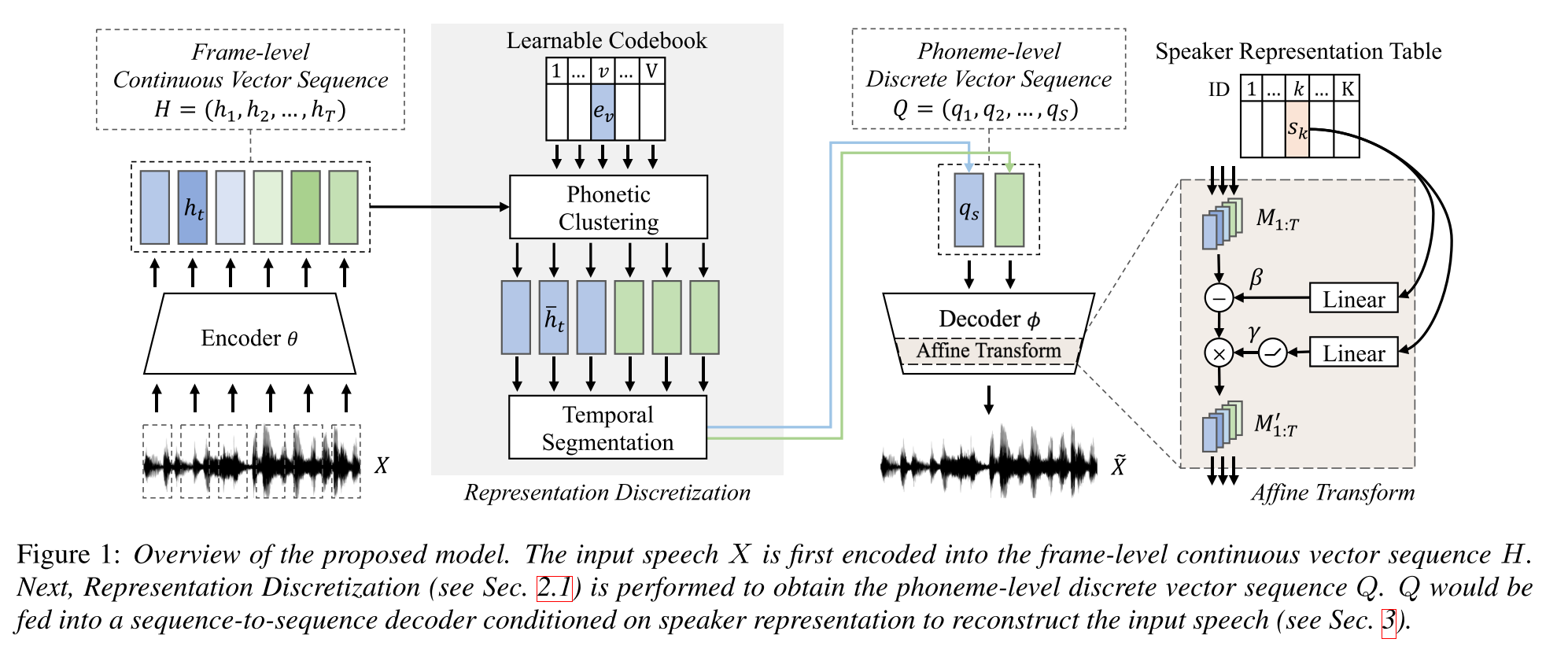
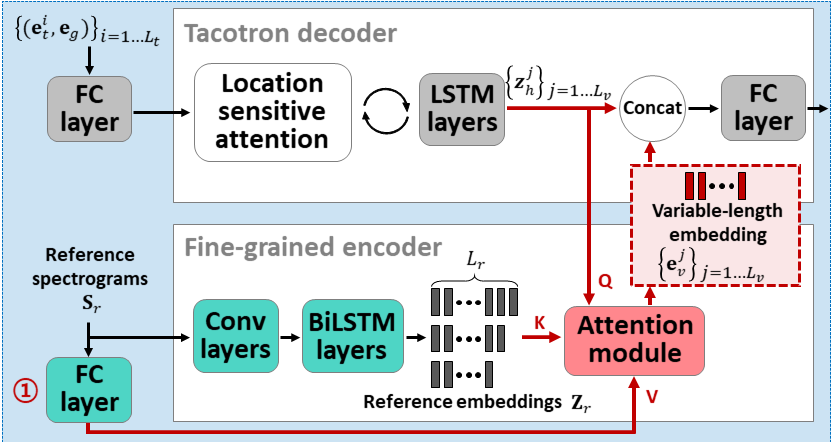
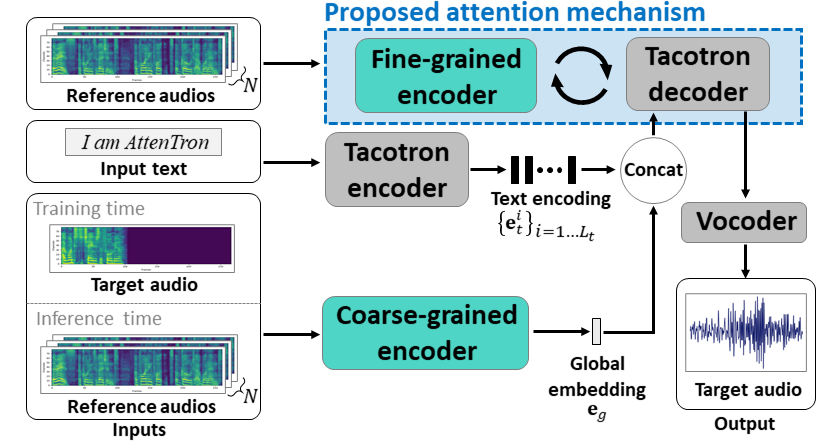
Atentrón: pocos disparos de texto a la especie explotando la atención basada en la atención Longitud de la variable Incrustación: https://arxiv.org/abs/2005.08484
- Use dos codificadores para aprender características dependientes del altavoz.
- El codificador grueso aprende un vector de incrustación de oradores globales basado en espectrogramas de referencia proporcionados.
- Fine Coder aprende una inclusión de longitud variable que mantiene la dimensión temporal en cooperación con un módulo de atención.
- La atención selecciona importantes marcos de espectrograma de referencia para sintetizar el discurso objetivo.
- Pre-entrenado el modelo con un solo conjunto de datos de altavoces primero (ljspeech para 30k iters).
- Atrae el modelo con un conjunto de datos de múltiples altavoces. (VCTK para 70k iterers).
- Logra métricas ligeramente mejores en comparación con el uso de vectores X del modelo de clasificación de altavoces y codificador de audio de referencia basado en VAE.
Página de demostración: https://hyperconnect.github.io/attentron/
Hacia el texto universal a la especie: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
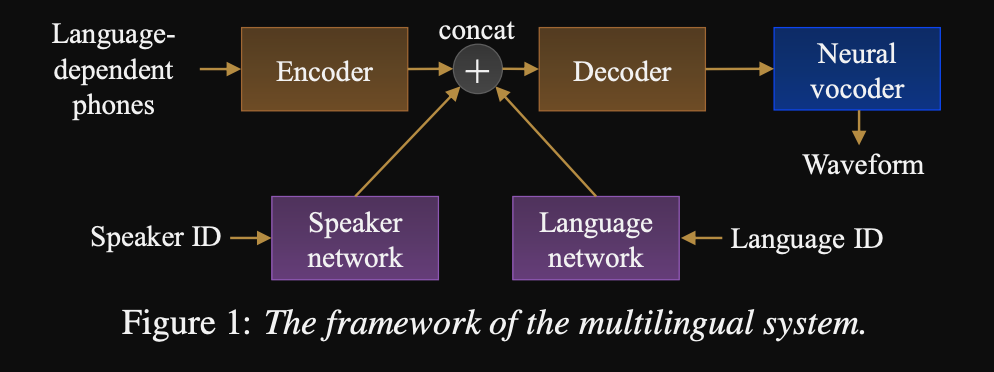
- Un marco para una secuencia a secuencia TTS multilingüe
- El modelo está entrenado con un conjunto de datos muy grande y altamente desequilibrado.
- El modelo puede aprender un nuevo idioma con 6 minutos y un nuevo hablante con 20 segundos de datos después de la capacitación inicial.
- La arquitectura del modelo es una red de codificador codificador basada en transformadores con una red de altavoces y una red de idiomas para el altavoz y la conditización del idioma. Las salidas de estas redes se concatenan a la salida del codificador.
- Las redes de acondicionamiento toman un vector único que representa el hablante o la identificación del idioma y lo proyecta a una representación de acondicionamiento.
- Utilizan un vocoder de Wavenet para convertir los espectrogramas MEL predichos en la salida de la forma de onda.
- Utilizan entradas de fonemas dependientes del lenguaje que no se compartan entre los idiomas.
- Muestra cada lote basado en la frecuencia inversa de cada idioma en el conjunto de datos. Por lo tanto, cada lote de capacitación tiene una distribución uniforme sobre los idiomas, aliviando el desequilibrio del lenguaje en el conjunto de datos de capacitación.
- Para aprender nuevos oradores/idiomas, ajustan el modelo de codificador del codificador con las redes de acondicionamiento. No entrenan el modelo Wavenet.
- Utilizan 1250 horas de grabaciones profesionales de 50 idiomas para la capacitación.
- Utilizan una velocidad de muestreo de 16 kHz para todas las muestras de audio y recortan silencios al principio y al final de cada clip.
- Usan 4 GPU V100 para entrenamiento, pero no mencionan cuánto tiempo entrenaron el modelo.
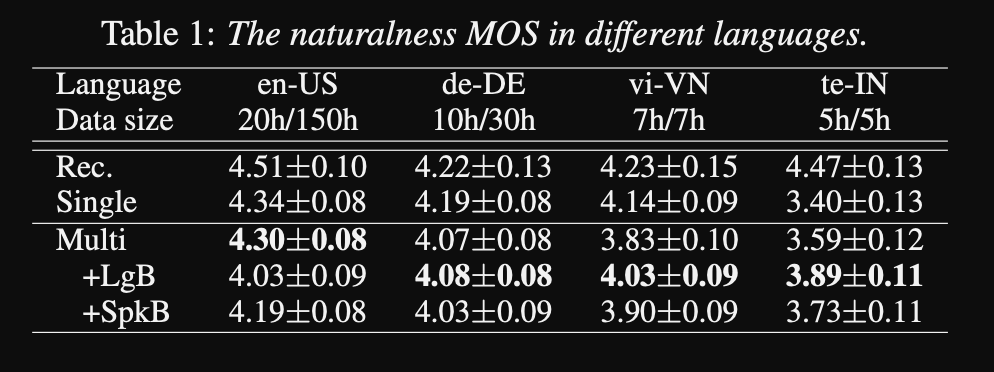
- Los resultados muestran que los modelos de altavoces únicos son mejores que el enfoque propuesto en la métrica MOS.
- También el uso de redes de acondicionamiento es importante para los lenguajes de cola larga en el conjunto de datos, ya que mejoran la métrica MOS para ellos, pero perjudican el rendimiento para los idiomas de alta recursos.
- Cuando agregan un nuevo altavoz, observan que el uso de más de 5 minutos de datos degrada el rendimiento del modelo. Afirman que, dado que estas grabaciones no están tan limpias como las grabaciones originales, usar más de ellas afecta el rendimiento general del modelo.
- El modelo multilingüe puede entrenar con solo 6 minutos de datos para nuevos altavoces e idiomas, mientras que un modelo de altavoz requiere 3 horas para entrenar y ni siquiera puede alcanzar valores de MOS similares como el modelo multilingüe de 6 minutos.
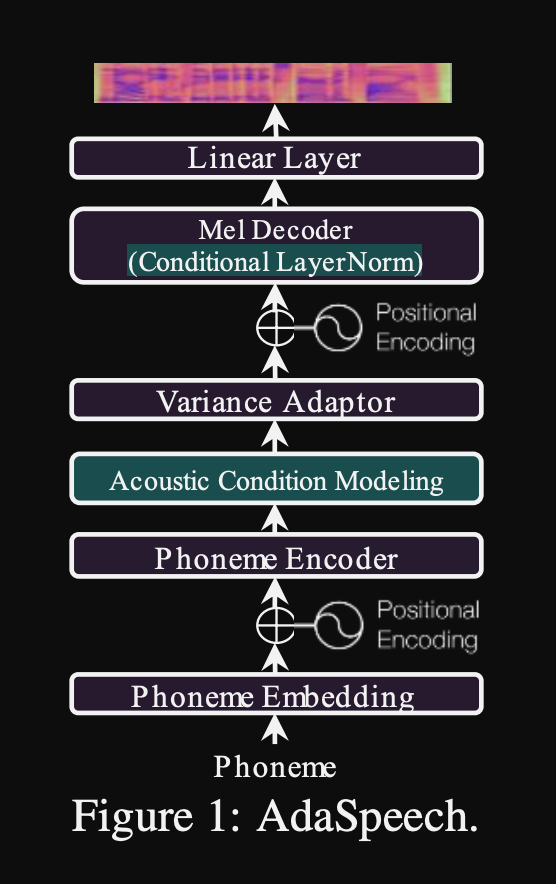
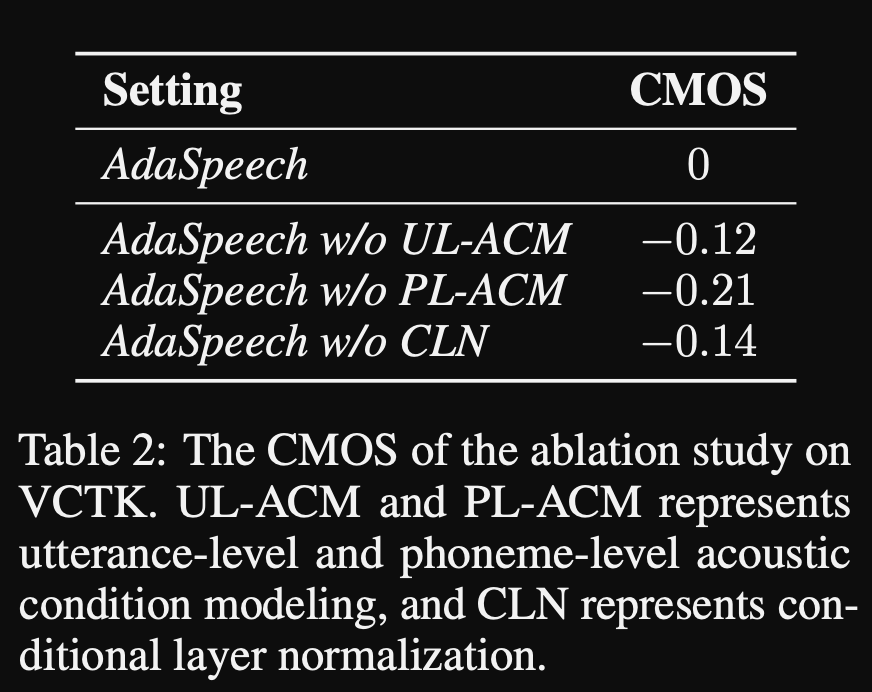
ADASPEECH: texto adaptativo al discurso para la voz personalizada: https://openreview.net/pdf?id=drynvt7gg4l
- Propusieron un sistema que pueda adaptarse a diferentes propiedades acústicas de entrada de los usuarios y utiliza un número mínimo de parámetros para lograr esto.
- La arquitectura principal se basa en el modelo FastSpeech2 que utiliza predictores de tono y varianza para aprender las granularidades más finas del discurso de entrada.
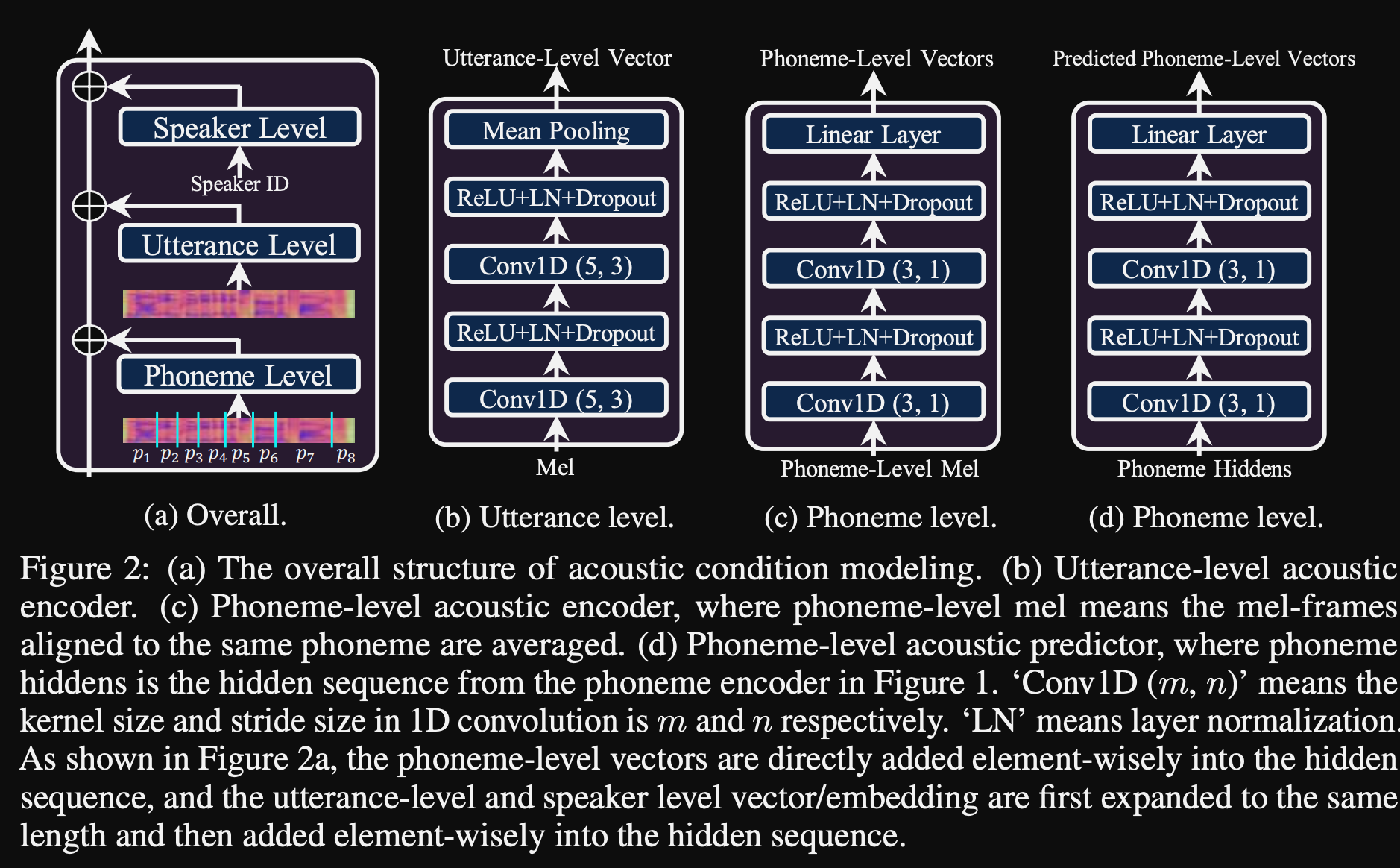
- Utilizan 3 redes de acondicionamiento adicionales.
- Nivel de enunciado. Se necesita un espectrograma MEL del discurso de referencia como entrada.
- Nivel de fonema. Se necesitan espectros MEL de nivel de fonema como entrada y calcula vectores de acondicionamiento a nivel de fonema. Los espectrogramas MEL a nivel de fonema se calculan tomando el marco de espectrograma promedio en la duración de cada fonema.
- Nivel de fonema 2. Se necesitan salidas del codificador fonema como entradas. Esto difiere de la red anterior simplemente utilizando la información del fonema sin ver los espectrogramas.
- Todas estas redes de acondicionamiento y el fastspeech2 de boonelas usan capas de normalización de capa.
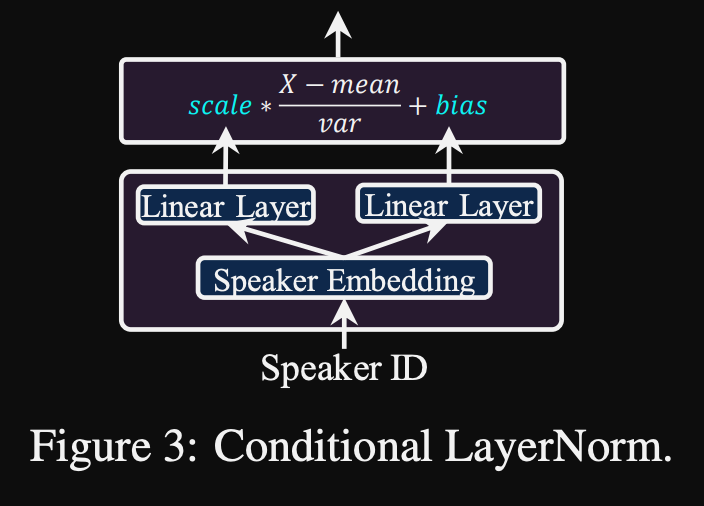
- Normalización de la capa condicional. Proponen el ajuste fino solo los parámetros de escala y sesgo de cada capa de normalización de la capa cuando el modelo está ajustado para un nuevo altavoz. Entrenan un módulo de acondicionamiento de altavoz para cada capa de norma de capa que genera una escala y valores de sesgo. (Usan un módulo de acondicionamiento de altavoz por bloque de transformador).
- Significa que solo almacena el módulo de acondicionamiento del altavoz para cada altavoz nuevo y predice los valores de escala y sesgo en inferencia, ya que mantiene el resto del modelo igual.
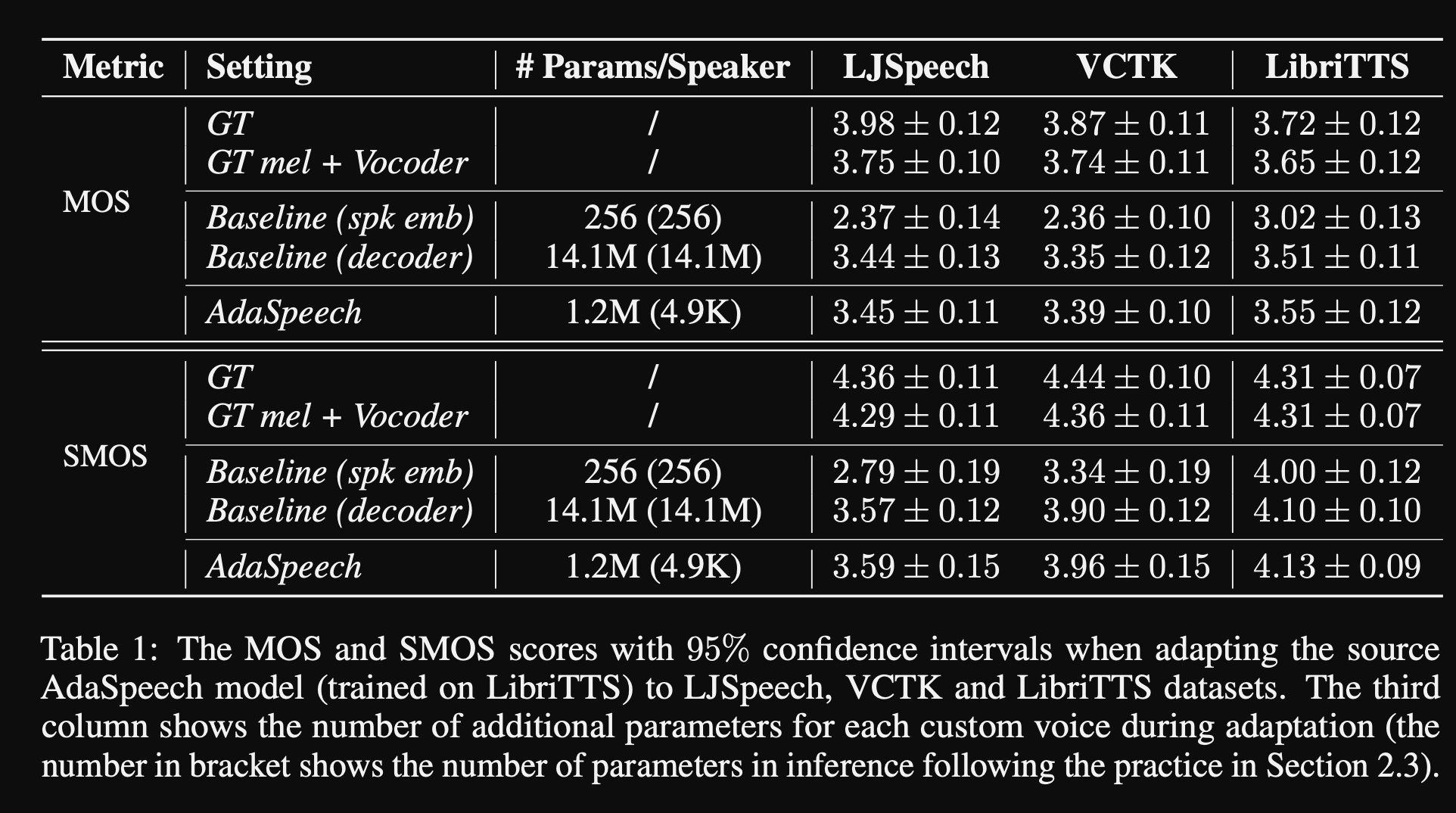
- En los experimentos, entrenan previamente el modelo en el conjunto de datos de Libritts y lo ajustan con VCTK y LJSPEECH
- Los resultados muestran que el uso de la normalización de la capa condicional logra mejor que sus 2 líneas de base que usan solo la incrustación de altavoces y la red de decodificadores.
- Su estudio de ablación muestra que la parte más significativa del modelo es la red de "nivel de fonema" seguida de la normalización de la capa condicional y la red de "nivel de expresión" en un orden.
- Un descenso importante del documento es que casi no hay comparación con la literatura y hace que los resultados sean más difíciles de evaluar de manera objetiva.
Página de demostración: https://speechresearch.github.io/adaspeech/

Atención
- Mecanismos de atención-relativa para ubicación para síntesis robusta de expresión larga de forma larga-https://arxiv.org/pdf/1910.10288.pdf
Voceros
Melgan: https://arxiv.org/pdf/1910.06711.pdf
Parallelwavegan: https://arxiv.org/pdf/1910.11480.pdf
- Pérdida STFT de multicala
- ~ Parámetros del modelo 1M (muy pequeño)
- Un poco peor que Wavernn
Mejora de FFTNet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
Ftetnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Reconstrucción de forma de onda del habla utilizando obras neuronales convolucionales con ruido e entradas periódicas
- 150.162.46.34:8080/icassp2019/icassp2019/pdfs/0007045.pdf
Hacia el alcance de vocoding universal robusto
- https://arxiv.org/pdf/1811.06292.pdf
LPCNET
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
Excitenet
- https://arxiv.org/pdf/1811.04769v3.pdf
Gelp: predicción lineal excitada por GaN para la síntesis del habla del espectrograma
- https://arxiv.org/pdf/1904.03976v3.pdf
Síntesis de discurso de alta fidelidad con redes adversas: https://arxiv.org/abs/1909.11646
- Gan-TTS, síntesis de discurso de extremo a extremo
- Utiliza duración y características lingüísticas
- La duración y las características acústicas se predicen mediante modelos adicionales.
- Discriminador de ventanas aleatorios: ingerir no toda la muestra de voz sino ventanas aleatorias.
- Múltiples RWD. Algunos condicionales y otros incondicionales. (condicionado en las características de entrada)
- Punchline: use ventanas muestreadas aleatoriamente con diferentes tamaños de ventana para D.
- Los resultados compartidos suenan mecánicos que muestran los límites de las características acústicas no neurales.
Melgan Multi-Band: https://arxiv.org/abs/2005.05106
- Use pérdidas de PWGAN en lugar de pérdida de características.
- El uso de un campo receptivo más grande aumenta significativamente el rendimiento del modelo.
- Generador previa para 200k iters.
- Predicción de señal de voz de múltiples bandas. La salida es suma de 4 predicciones de banda diferentes con filtros de síntesis PQMF.
- El modelo de banda múltiple tiene 1.9m parámetros (bastante pequeños).
- Afirmó ser 7 veces más rápido que Melgan
- En un conjunto de datos chino: MOS 4.22
WaveGlow: https://arxiv.org/abs/1811.00002
- Modelo muy grande (parámetros de 268 m)
- Difícil de entrenar ya que en GPU de 12 GB solo puede tomar el tamaño del lote 1.
- Inferencia en tiempo real debido al uso de convoluciones.
- Basado en el flujo de normalización invertible. (Gran tutorial https://blog.evjang.com/2018/01/nf1.html)
- El modelo aprende y el mapeo invetible de muestras de audio a los espectrogramas MEL con pérdida de probabilidad máxima.
- En inferencia, la red se ejecuta en dirección inversa y las especificaciones MEL se convierten en muestras de audio.
- El entrenamiento se ha realizado utilizando 8 NVIDIA V100 con 32 GB de RAM, tamaño por lotes 24. (Cososo)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, código: https://github.com/tianrengao/squeezewave
- ~ 5-13x más rápido que en tiempo real
- Redanduncias de resplandor de onda: muestras de audio largas, muestras ascendentes MEL-especs, grandes dimensiones de canales en la función WN.
- Correcciones: muestras de audio más pero más cortas como entrada, (l = 2000, c = 8 vs l = 64, c = 256)
- L = 64 coincide con la resolución MEL-Spec, por lo que no se necesita muestreo ascendente.
- Use convoluciones separables en forma de profundidad en módulos WN.
- Use una convolución regular en lugar de dilatado ya que las muestras de audio son más cortas.
- No divida las salidas del módulo a la salida residual y de red, suponiendo que estos vectores son casi idénticos.
- El entrenamiento se ha realizado utilizando Titan RTX 24GB Batch Size 96 para 600K iteraciones.
- MOS en LJSpeech: WaveGlow - 4.57, Squeezewave (L = 128 C = 256) - 4.07 y Squeezewave (L = 64 C = 256) - 3.77
- El modelo más pequeño tiene 21k muestras por segundo en Raspi3.
Wavegrad: https://arxiv.org/pdf/2009.00713.pdf
- Se basa en la difusión de probabilidad y la dinámica Lagenvin
- La idea base es aprender una función que mapea una distribución conocida para la distribución de datos de destino de forma iterativa.
- Informan 0.2 Factor en tiempo real en una GPU, pero el rendimiento de la CPU no se comparte.
- En el código de ejemplo a continuación, el autor informa que el modelo converge después de 2 días de capacitación en una sola GPU.
- Los puntajes MOS en el papel no son lo suficientemente compherentes, pero muestra un rendimiento comparable a modelos conocidos como Wavernn y Wavenet.
Código: https://github.com/ivanvovk/wavegrad 
De Internet (blogs, videos, etc.)
Videos
Discusión en papel
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Negociaciones
- Hable sobre presionar la frontera del texto neuronal a la voz, por Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- Hablar sobre la síntesis generativa de texto a voz basada en modelos, por Heiga Zen, 2017
- Video: https://youtu.be/nsrsrytkkt8
- Slide: https://research.google.com/pubs/pub45882.html
- Tutoriales sobre síntesis de texto a voz paramétrica neuronal en ISCA ODYESSY 2020, por Xin Wang, 2020
- Video: https://youtu.be/wce7sycdzai
- Diapositiva: http://tonywangx.github.io/slide.html#dec-2020
- Curso de procesamiento del habla ISCA en vocoders neurales, 2022
- Componentes básicos de los vocoders neurales: https://youtu.be/m833q5i-zys
- Modelos generativos profundos para la compresión del habla (LPCNET): https://youtu.be/7ksnfx3plgw
- NEURAL AUTO-REgresiva, Fuente-Filter y Vocoders glottales: https://youtu.be/gprmxdberx0
- Diapositiva: http://tonywangx.github.io/slide.html#jul-2020
- Síntesis del habla de la decodificación neural de oraciones habladas | Aisc: https://www.youtube.com/watch?v=mndtmdpmnmo
- Síntesis generativa de texto a la especie: https://www.youtube.com/watch?v=J4MVeAnking
- Síntesis del habla para la industria del juego: https://www.youtube.com/watch?v=aohaye4a-2q
General
- Revisión de sistemas de texto a la especie moderna: https://www.youtube.com/watch?v=8rxlsc-zcry
Cuadernos Jupyter
- Tutoriales en vocoders neurales seleccionados: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
Blogs
- Arquitecturas de aprendizaje profundo de texto a discurso: http://www.erogol.com/text-sepeech-deep-letarning-architectures/


