(Sinta -se à vontade para sugerir mudanças)
Papéis
- Mesclagem de representações de fonema e char: https://arxiv.org/pdf/1811.07240.pdf
- Learning de transferência de tacotron: https://arxiv.org/pdf/1904.06508.pdf
- Timing do fonema da atenção: https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8683827
- Treinamento semi-supervisionado para melhorar a eficiência dos dados na síntese de fala de ponta a ponta-https://arxiv.org/pdf/1808.10128.pdf
- Ouvindo enquanto fala: Cadeia de fala por Deep Learning - https://arxiv.org/pdf/1707.04879.pdf
- Perda generalizada de ponta a ponta para verificação do alto-falante: https://arxiv.org/pdf/1710.10467.pdf
- ES-TACOTRON2: TACOTRON MULTI-TASSAGEM COM REDE ESTIMATIVA PRÉ-TRADO PARA REDUZIR O PROBLEMA SUPERSO SOOTH: https://www.mdpi.com/2078-2489/10/4/131/pdf
- Contra suavidade excessiva
- FastSpeech: https://arxiv.org/pdf/1905.09263.pdf
- Aprendendo cantando da fala: https://arxiv.org/pdf/1912.10128.pdf
- TTS-GAN: https://arxiv.org/pdf/1909.11646.pdf
- Eles usam duração e recursos linguísticos para EN2EN TTS.
- Perto do desempenho do WaveNet.
- Durian: https://arxiv.org/pdf/1909.01700.pdf
- Tacotron ciente da duração
- Melnet: https://arxiv.org/abs/1906.01083
- ALIGNTTS: https://arxiv.org/pdf/2003.01950.pdf
- Decomposição da fala não supervisionada por gargalos de informações triplas
- https://arxiv.org/pdf/2004.11284.pdf
- https://anonymous0818.github.io/
- Flowtron: https://arxiv.org/pdf/2005.05957.pdf
- Fluxo inverso da AutoReGresive no tacotron como arquitetura
- Waveglow como vocoder.
- Estilo de fala incorporado com mistura de modelo gaussiano.
- O modelo é grande e mais tema que o baunilha tacotron
- Os valores do MOS são com agitação melhor que a implementação pública do tacotron.
- Sistema de texto em fala com eficientemente treinável com base em redes convolucionais profundas com atenção guiada: https://arxiv.org/pdf/1710.08969.pdf
Resumos expansivos
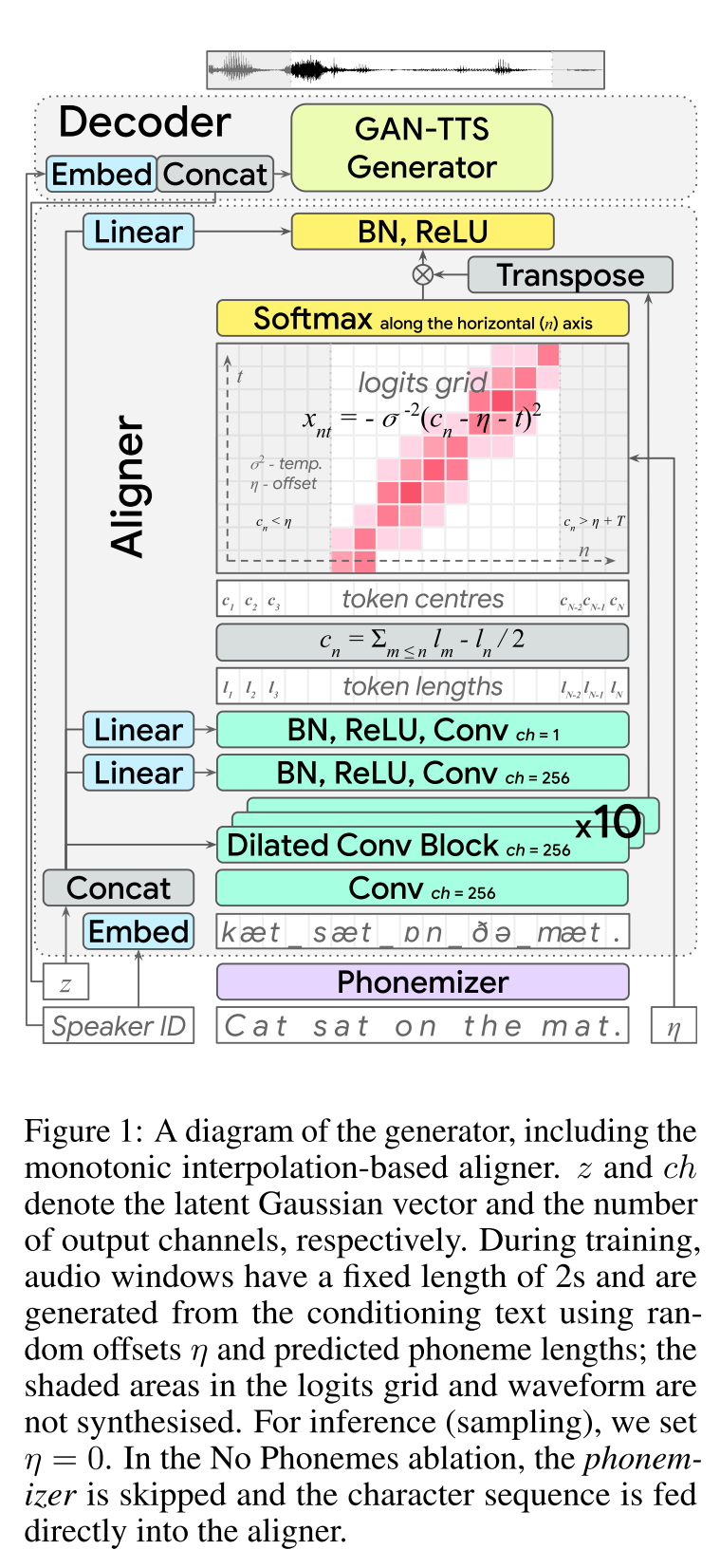
TEXTO ADVERSÁRIO DE ESTABRAÇÃO DE END-A-EM: http://arxiv.org/abs/2006.03575 (clique para expandir)
- END2END Aprendizagem de TTS para feed-forward.
- O alinhamento do caractere foi feito com um módulo alinhador separado.
- O alinhador prevê o comprimento de cada caractere. - A localização central de um char é encontrada no comprimento total dos caracteres anteriores. - As posições de char são interpoladas com uma janela gaussiana e o comprimento real do áudio.
- A saída de áudio é calculada no domínio MU-Law. (Eu não tenho um raciocínio para isso)
- Use apenas 2 secs em janelas de áudio para transar.
- O gerador Gan-TTS é usado para produzir sinal de áudio.
- O RWD é usado como discriminador de nível de áudio.
- MELD: Eles usam a arquitetura de profundidade do Biggan como discriminador de nível de espectrograma, recuperando o problema como reconstrução da imagem.
- Perda de espectrograma
- Usar apenas feedback adversário não é suficiente para aprender os alinhamentos de char. Eles usam uma perda de espectrograma B/W prevista espectrogramas e especificações de verdade no solo.
- Observe que o modelo prevê sinais de áudio. Os espectrogramas acima são calculados a partir do áudio gerado.
- O envolvimento do tempo dinâmico é usado para calcular um alinhamento de custo mínimo B/W gerado espectrogramas e a verdade no solo.
- Envolve uma abordagem de programação dinâmica para encontrar um alinhamento de custo mínimo.
- A perda de comprimento do alinhador é usada para penalizar o alinhador por prever diferente do comprimento real do áudio.
- Eles treinam o modelo com o conjunto de dados de vários alto -falantes, mas relatam os resultados do alto -falante com melhor desempenho.
- Estudo de ablação Importância de cada componente: (LengthLoss e Spectrogramloss)> RWD> MELD> PHONEMES> MULTISPEAKERDataset.
- Meus 2 centavos: é um modelo de alimentação que fornece síntese de fala de ponta-2 de ponta, sem necessidade de treinar um modelo de vocoder separado. No entanto, é um modelo muito complicado com muitos hiperparâmetros e detalhes de implementação. Além disso, o resultado final não está próximo do estado da arte. Acho que precisamos encontrar algoritmos específicos para aprender alinhamentos de caráter, o que reduziria a necessidade de ajustar uma combinação de algoritmos diferentes.
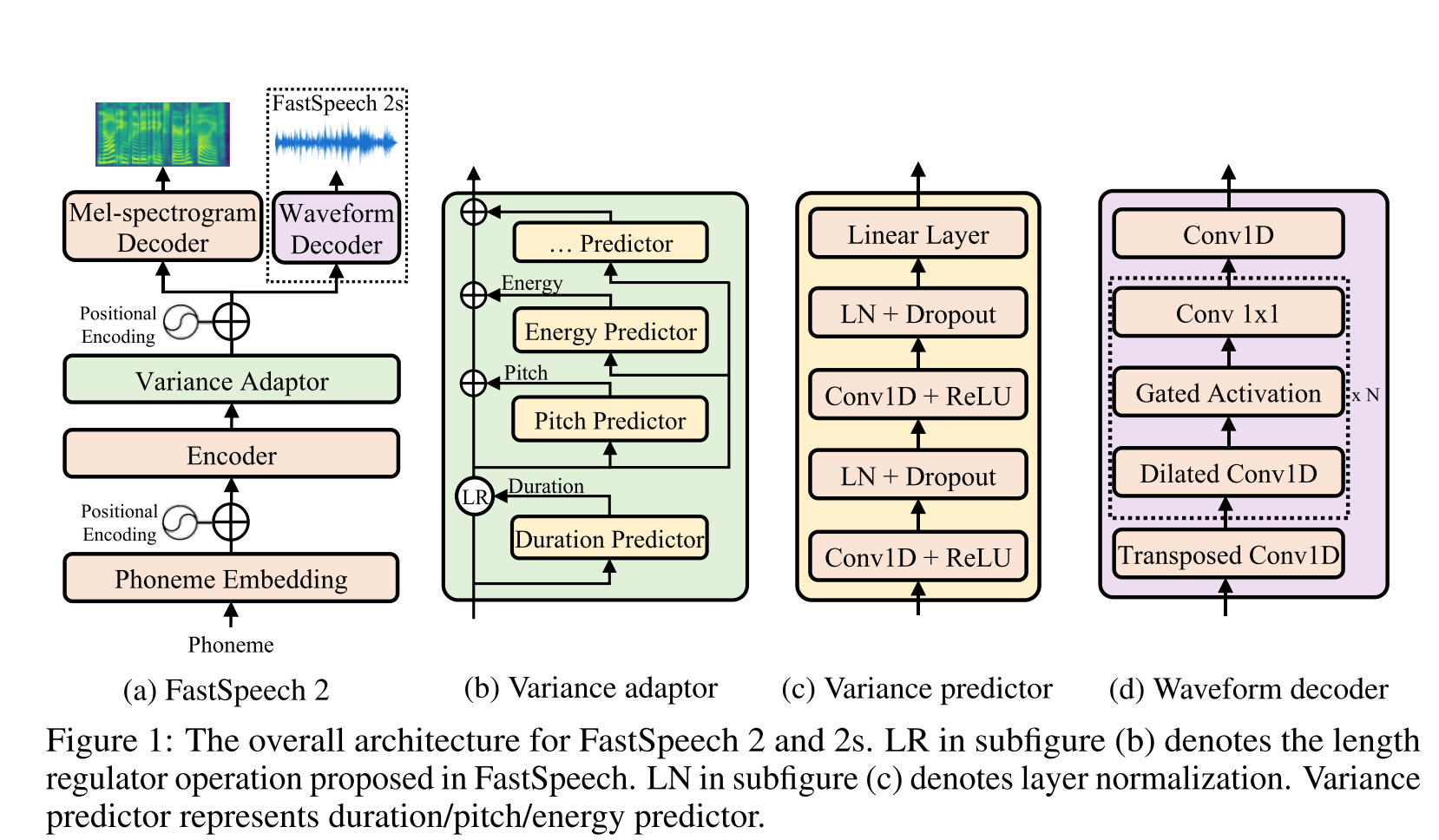
Fast Speech2: http://arxiv.org/abs/2006.04558 (clique para expandir)
- Use durações de fonemas geradas pelo MFA como rótulos para treinar um regulador de comprimento.
- Thay Use o nível do quadro F0 e L2 Normas de espectrograma (informações de variação) como recursos adicionais.
- O módulo Predictor de variação prevê as informações de variação em tempo de inferência.
- Melhorias do resultado do estudo de ablação: modelo <modelo + l2_norm <modelo + l2_norm + f0
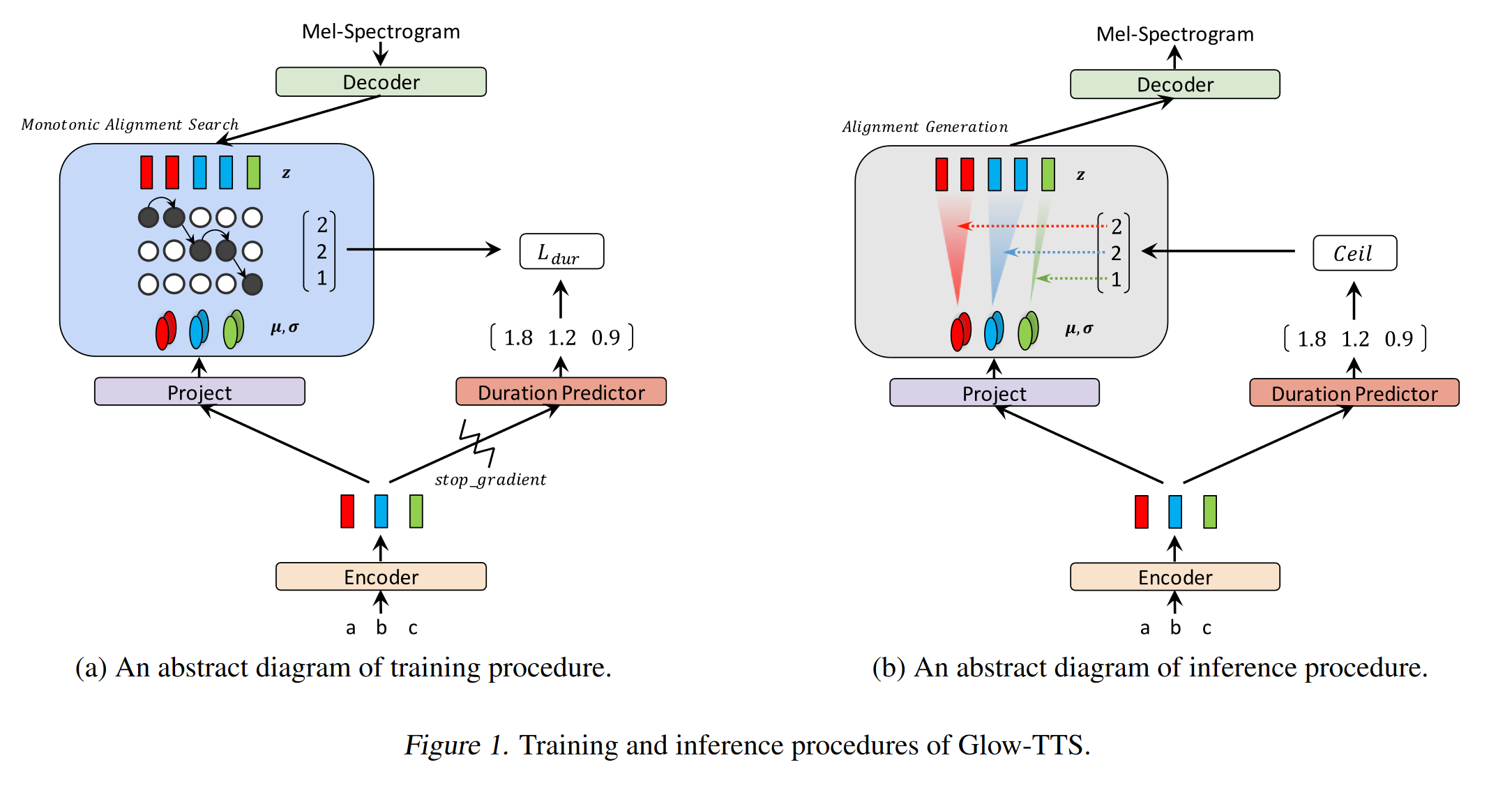
GLOW-TTS: https://arxiv.org/pdf/2005.11129.pdf (clique para expandir)
- Use pesquisa de alinhamento monotônico para aprender o alinhamento B/W Texto e o Spectrogram
- Esse alinhamento é usado para treinar um preditor de duração a ser usado na inferência.
- O codificador mapeia cada caractere para uma distribuição gaussiana.
- O decodificador mapeia cada quadro de espectrograma para um vetor latente usando o fluxo de normalização (camadas de brilho)
- As saídas do codificador e decodificador estão alinhadas com MAS.
- Em cada iteração, o alinhamento mais provável é encontrado pelo MAS e esse alinhamento é usado para atualizar os parâmetros do modo.
- Um preditor de duração é treinado para prever o número de quadros de espectrograma para cada caractere.
- Na inferência, apenas o preditor de duração é usado em vez de MAS
- O codificador tem a arquitetura do transformador TTS com 2 atualizações
- Em vez de codificação posicional absoluta, eles usam a codificação posicional realtiva.
- Eles também usam uma conexão residual para o codificador PreNET.
- O decodificador tem a mesma arquitetura que o modelo de brilho.
- Eles treinam modelo único e multi-falante.
- É mostrado experimentalmente, o Glow-TTS é mais robusto contra sentenças longas em comparação com o Tacotron2 original2
- 15x mais rápido que o tacotron2 na inferência
- Meus 2 centavos: suas amostras soam não tão naturais quanto o tacotron. Acredito que os modelos de atenção normais ainda geram mais discursos naturais, pois a atenção aprende a mapear os caracteres para modelar as saídas diretamente. No entanto, o uso do Glow-TTS pode ser uma boa alternativa para conjuntos de dados rígidos.
- Amostras: https://github.com/jaywalnut310/glow-tts
- Repositório: https://github.com/jaywalnut310/glow-tts
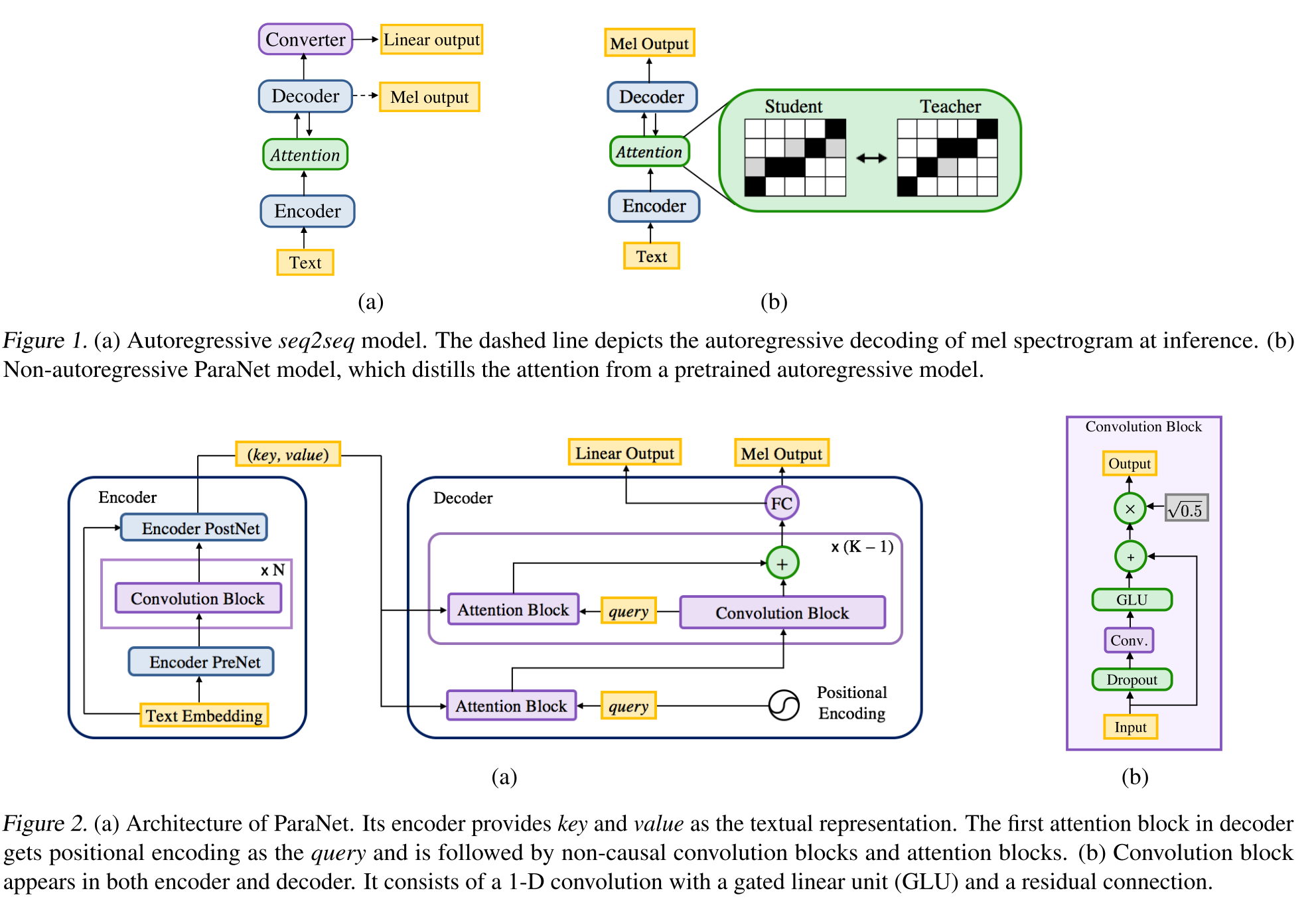
Texto neural não autorregressivo para falar: http://arxiv.org/abs/1905.08459 (clique para expandir)
- Uma derivação do modelo de voz profunda 3 usando camadas convolucionais não causais.
- Paradigma professor-aluno para treinar um aluno de Annon-Autoregressive com vários blocos de atenção de um modelo de professores autoregressivos.
- O professor é usado para gerar alinhamentos de texto a espectrograma a serem usados pelo modelo do aluno.
- O modelo é treinado com duas funções de perda para alinhamento de atenção e geração de espectrograma.
- Os blocos de atenção múltipla refinam a camada de alinhamento de atenção por camada.
- O aluno usa a atenção do produto DOT com vetores de consulta, chave e valor. A consulta é apenas vetores de codificação positina. A chave e o valor são as saídas do codificador.
- O modelo proposto está fortemente ligado à codificação posicional, que também se baseia em diferentes valores constantes.
Consistência do decodificador duplo: https://erogol.com/solving-attion-problems-of-tts-models-with-double-decoder-consistência (clique para expandir)
- O modelo usa um tacotron como arquitetura, mas com 2 decodificadores e uma rede postal.
- O DDC usa dois decodificadores síncronos usando diferentes taxas de redução.
- Os decodificadores usam taxas de redução diferentes, portanto, calculam saídas em diferentes granularidades e aprendem diferentes aspectos dos dados de entrada.
- O modelo usa a consistência entre esses dois decodificadores para aumentar a robustez do alinhamento instruído de texto a espectrograma.
- O modelo também aplica um refinamento à saída final do decodificador, aplicando o pós -rede iterativamente várias vezes.
- O DDC usa a normalização do lote no módulo PreNET e as camadas de abandono de gotas.
- O DDC usa treinamento gradual para reduzir o tempo total de treinamento.
- Utilizamos um gerador Melgan de várias bandas como um vocoder treinado com vários discriminadores de janelas aleatórias de maneira diferente do trabalho original.
- Somos capazes de treinar um modelo DDC apenas em 2 dias com uma única GPU e o modelo final é capaz de gerar mais rápido que o discurso em tempo real em uma CPU. Página de demonstração: https://erogol.github.io/ddc-samples/ Code: https://github.com/mozilla/tts
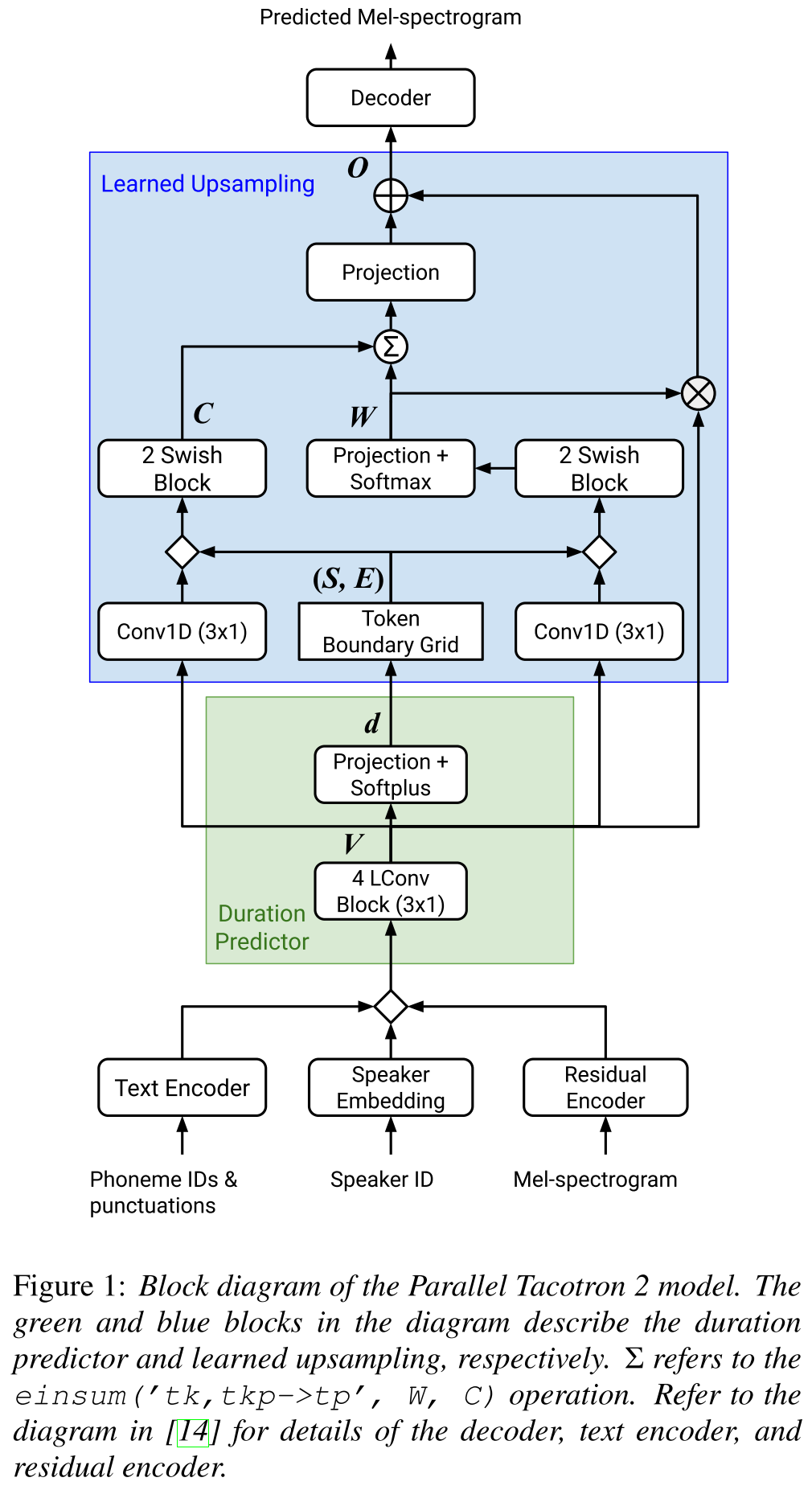
Parallel Tacotron2: http://arxiv.org/abs/2103.14574 (clique para expandir)
- Não requer informações de duração externa.
- Resolve os problemas de alinhamento entre os espectrogramas de verdadeira e a truta fundamental por perda de DTW suave.
- As durações previstas são convertidas em alinhamento por uma função de conversão aprendida, em vez de um regulador de comprimento, para resolver problemas de arredondamento.
- Aprende um mapa de atenção sobre "grades de limites de token" calculadas a partir de durações previstas.
- O decodificador é construído em blocos de 6 "convoluções leves".
- Um VAE é usado para projetar espectrogramas de entrada para recursos latentes e mesclado com as incorporações de caracteres como uma entrada para a rede.
- O Soft-DTW é computacionalmente intensivo, pois calcula a diferença pareada para todos os quadros do espectrograma. Eles contribuem para uma certa janela diagonal para reduzir a sobrecarga.
- O objetivo da duração final é a soma da perda de duração, perda de VAE e perda de espectrograma.
- Eles usam apenas conjuntos de dados proprietários para os experimentos?
- Alcança o mesmo MOS com o modelo Tacotron2 e supera o parallelltacotron.
- Página de demonstração : https://google.github.io/tacotron/publications/parallel_tacotron_2/index.html
- Código : nenhum código até agora
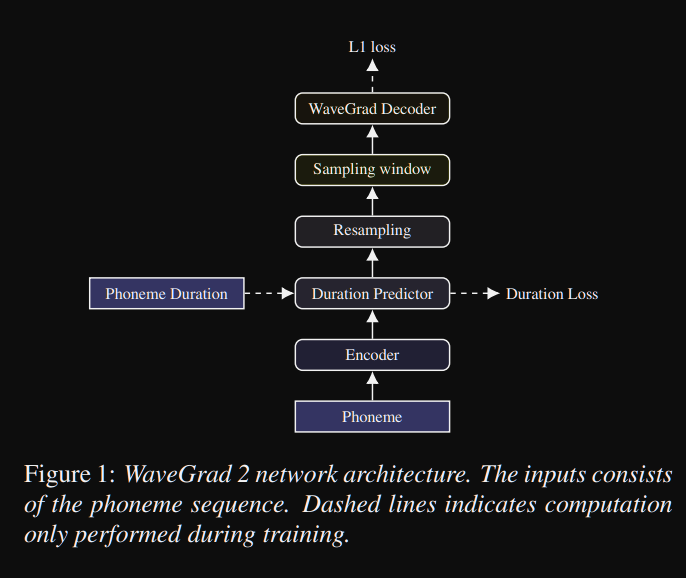
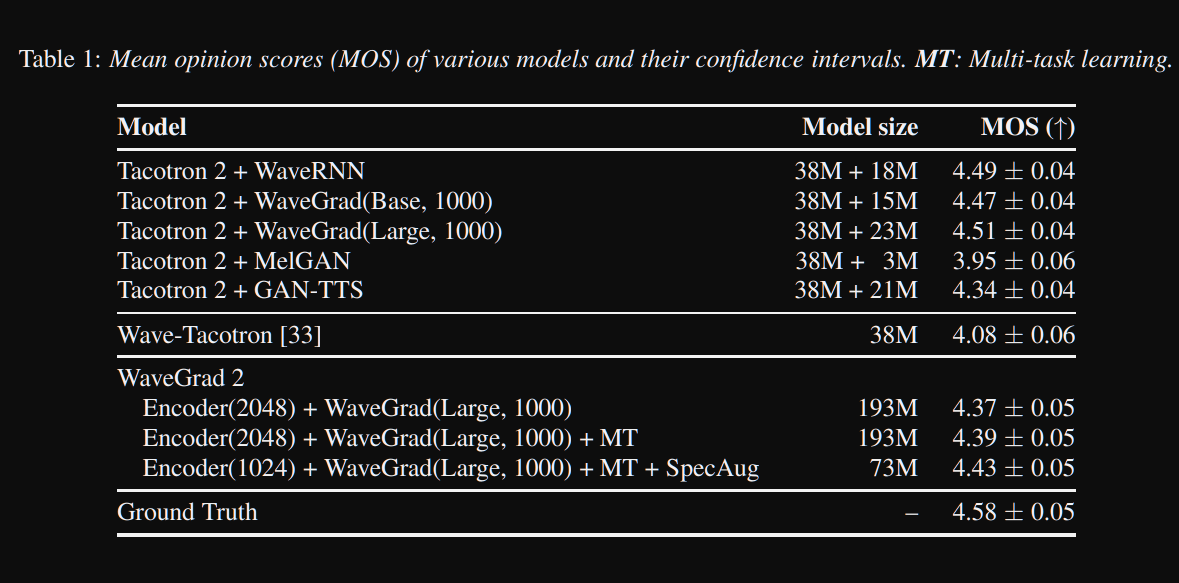
WaveGrad2: https://arxiv.org/pdf/2106.09660.pdf (clique para expandir)
- Ele calcula a forma de onda bruta diretamente de uma sequência de fonema.
- Um modelo de codificador como tacotron2 é usado para calcular uma representação oculta dos fonemas.
- Tacotron não atento, como preditor de duração suave, para alinhar a represenação oculta com a saída.
- Eles expandem a representação oculta com as durações previstas e amostraram uma certa janela para se converter em uma forma de onda.
- Eles exploraram tamanhos de janela diferentes, entre 64 e 256 quadros correspondentes a 0,8 e 3,2 segundos de fala. Eles descobriram que quanto maior é melhor.
- Página de demonstração : nada até agora
- Código : nenhum código até agora
Documentos de vários falantes
- Treinamento de sistemas de texto neural de múltiplos alto-falantes usando a Speech Corpora-https://arxiv.org/abs/1904.00771
- Voz Deep 2-https://papers.nips.cc/paper/6889-deep-voice-2-multi-speaker-neural-text-to-speech.pdf
- Amostra TTS adaptável eficiente e eficiente - https://openreview.net/pdf?id=rkzjuoacfx
- Abordagem de incorporação de alto -falante wavenet +
- Loop de voz - https://arxiv.org/abs/1707.06588
- Modelando o espaço latente de vários falantes para melhorar o TTS neural, inscrevendo -se no novo alto -falante e aprimorando a voz premium - https://arxiv.org/pdf/1812.05253.pdf
- Transfira o aprendizado da verificação do alto-falante para a síntese de texto para expressão de multispicais-https://arxiv.org/pdf/1806.04558.pdf
- Ajustar novos alto -falantes baseados em uma amostra curta não divulgada - https://arxiv.org/pdf/1802.06984.pdf
- Perda de ponta a ponta generalizada para verificação do alto-falante-https://arxiv.org/abs/1710.10467
Resumos expansivos
Aprendizagem semi-supervisionada para síntese de texto em fala de vários falantes usando representação discreta da fala: http://arxiv.org/abs/2005.08024
- Treine um modelo TTS de vários alto-falantes com apenas dados emparelhados de uma hora (alinhamento de texto a voz) e dados mais não pareados (apenas Voide).
- Aprende um livro de código com cada palavra de código corresponde a um único fonema.
- O livro de código está alinhado aos fonemas usando os dados emparelhados e o algoritmo CTC.
- Este livro de código funciona como um proxy para estimar implicitamente a sequência de fonemas dos dados não pareados.
- Eles empilham o modelo Tacotron2 na parte superior para executar o TTS usando as incorporações de palavras de código geradas pela parte inicial do modelo.
- Eles vencem os métodos de referência na configuração de dados emparelhados de 1 hora.
- Eles não relatam resultados completos de dados emparelhados.
- Eles não têm um bom estudo de ablação, que pode ser interessante ver como as diferentes partes do modelo contribuem para o desempenho.
- Eles usam Griffin-Lim como vocoder, portanto, há espaço para melhorias.
Página de demonstração: https://ttaoretw.github.io/multispkr-semi-tts/demo.html
Código: https://github.com/ttaoretw/semi-tts 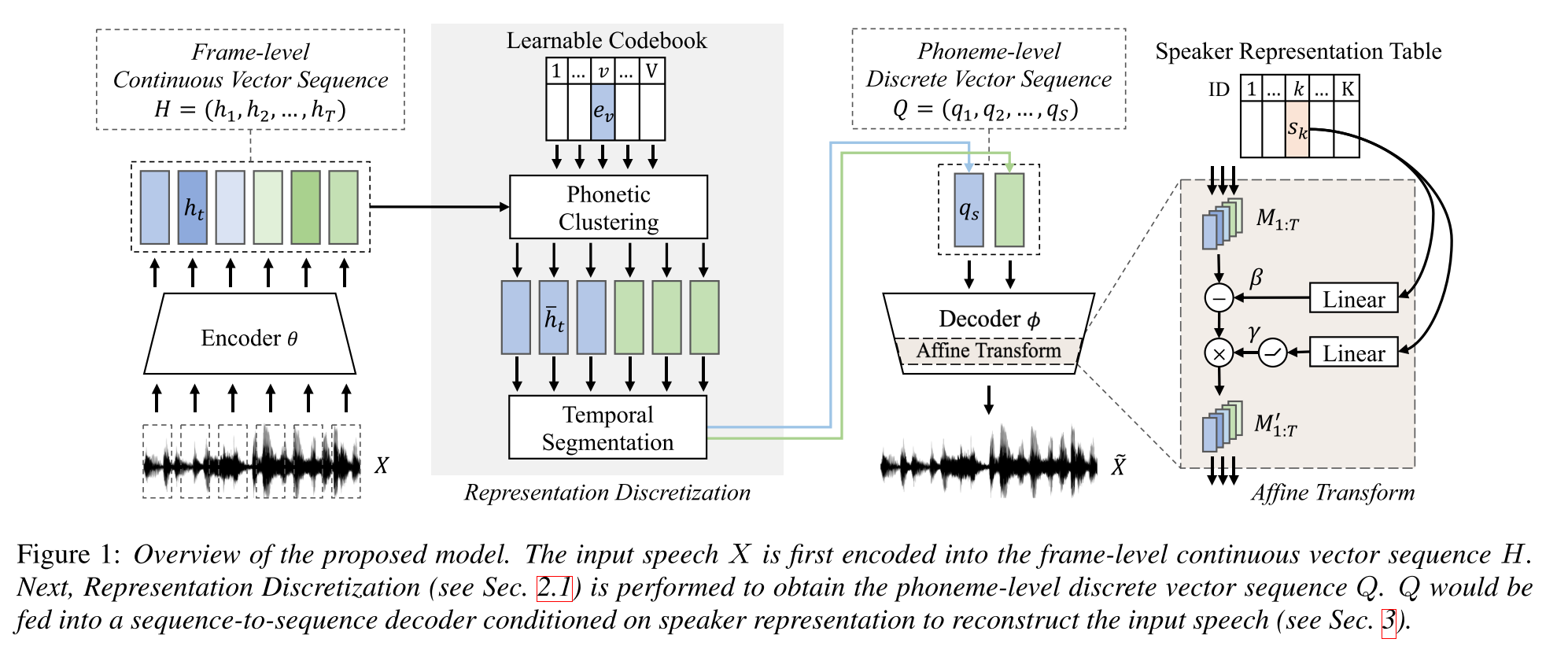
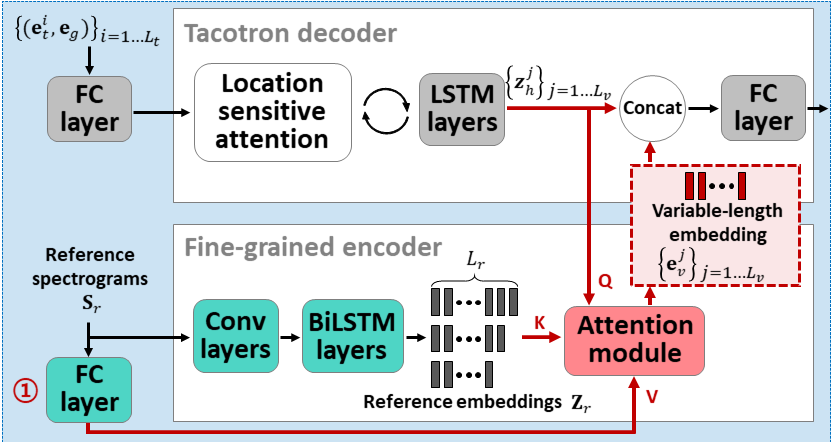
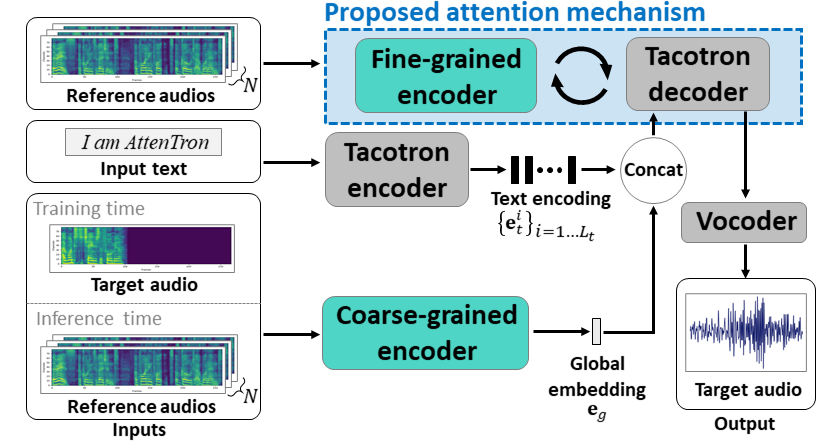
ATTENTRON: Few-shot Text-to-fala-fala, explorando o comprimento da variável baseada em atenção: https://arxiv.org/abs/2005.08484
- Use dois codificadores para saber que o alto -falante dependia de recursos.
- O codificador grosso aprende um vetor de incorporação de alto -falante global com base nos espectrogramas de referência fornecidos.
- O codificador fino aprende uma incorporação de comprimento variável, mantendo a dimensão temporal em cooperação com um módulo de atenção.
- A atenção seleciona os quadros de espectrograma de referência importantes para sintetizar a fala alvo.
- Pré-trep o modelo com um conjunto de dados de alto-falante primeiro (LJSpeech para 30k Iters.)
- Tune o modelo com um conjunto de dados de vários falantes. (VCTK para 70K iters.)
- Ele atinge métricas um pouco melhores em comparação com o uso de vetores X do modelo de classificação de alto-falantes e codificador de áudio de referência baseado em VAE.
Página de demonstração: https://hyperconnect.github.io/attentron/
Para a Universal Text-to-Speech: http://www.interspeech2020.org/uploadfile/pdf/wed-3-4-3.pdf
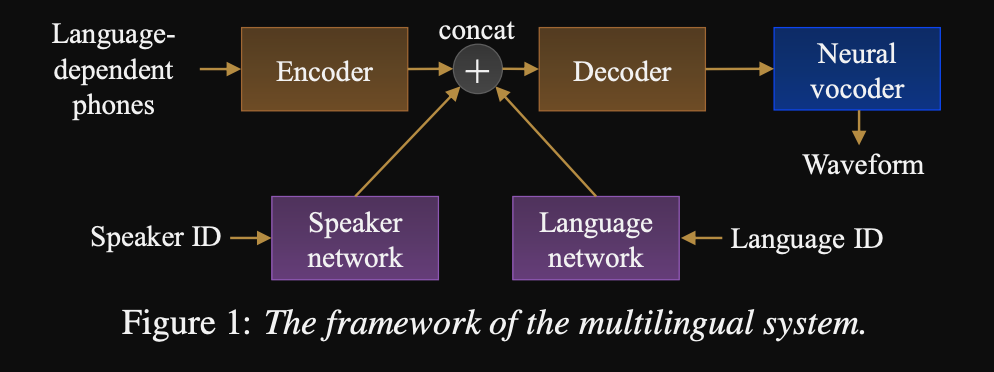
- Uma estrutura para uma sequência para sequenciar TTS multilíngues
- O modelo é treinado com um conjunto de dados muito grande e altamente desequilibrado.
- O modelo é capaz de aprender um novo idioma com 6 minutos e um novo alto -falante com 20 segundos de dados após o treinamento inicial.
- A arquitetura do modelo é uma rede de codificadores-decodificadores baseados em transformadores com uma rede de alto-falantes e uma rede de idiomas para o alto-falante e a condição de idioma. As saídas dessas redes são concatenadas com a saída do codificador.
- As redes de condicionamento levam um vetor de um hot que representa o alto-falante ou o ID do idioma e o projeta para uma representação de condicionamento.
- Eles usam um vocoder wavenet para converter espectrogramas MEL previstos na saída da forma de onda.
- Eles usam a linguagem dependia de entradas de fonemas que não são compartilhadas entre os idiomas.
- Eles amostraram cada lote com base na frequência inversa de cada idioma no conjunto de dados. Assim, cada lote de treinamento tem uma distribuição uniforme sobre os idiomas, aliviando o desequilíbrio da linguagem no conjunto de dados de treinamento.
- Para aprender novos alto-falantes/idiomas, eles ajustam o modelo de codificador-decodificador com as redes de condicionamento. Eles não treinam o modelo WaveNet.
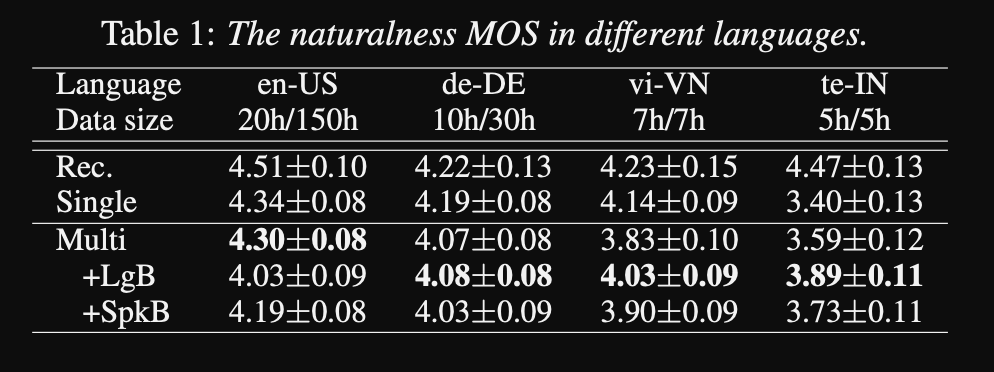
- Eles usam 1250 horas gravações profissionais de 50 idiomas para o treinamento.
- Eles usam a taxa de amostragem de 16kHz para todas as amostras de áudio e os silêncios do início e no final de cada clipe.
- Eles usam GPUs 4 V100 para treinamento, mas não mencionam quanto tempo treinaram o modelo.
- Os resultados mostram que os modelos de alto -falante único são melhores que a abordagem proposta na métrica do MOS.
- Também é importante usar redes de condicionamento para os idiomas de cauda longa no conjunto de dados, pois eles melhoram a métrica do MOS para eles, mas prejudicam o desempenho dos idiomas de alto recurso.
- Quando adicionam um novo alto -falante, eles observam que o uso de mais de 5 minutos de dados degrada o desempenho do modelo. Eles afirmam que, como essas gravações não são tão limpas quanto as gravações originais, o uso de mais delas afeta o desempenho geral do modelo.
- O modelo multilíngue é capaz de treinar com apenas 6 minutos de dados para novos alto-falantes e idiomas, enquanto um modelo de alto-falante requer 3 horas para treinar e não pode nem atingir valores de MOS semelhantes ao modelo multilíngue de 6 minutos.
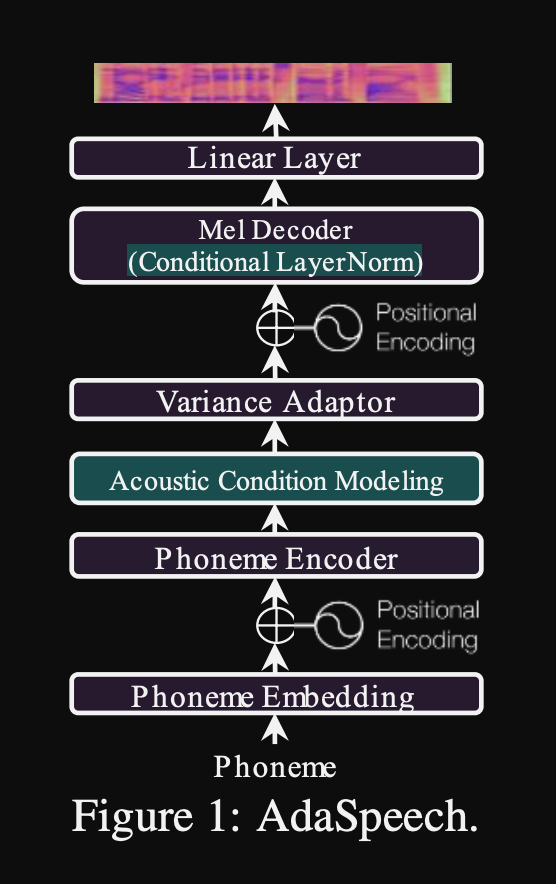
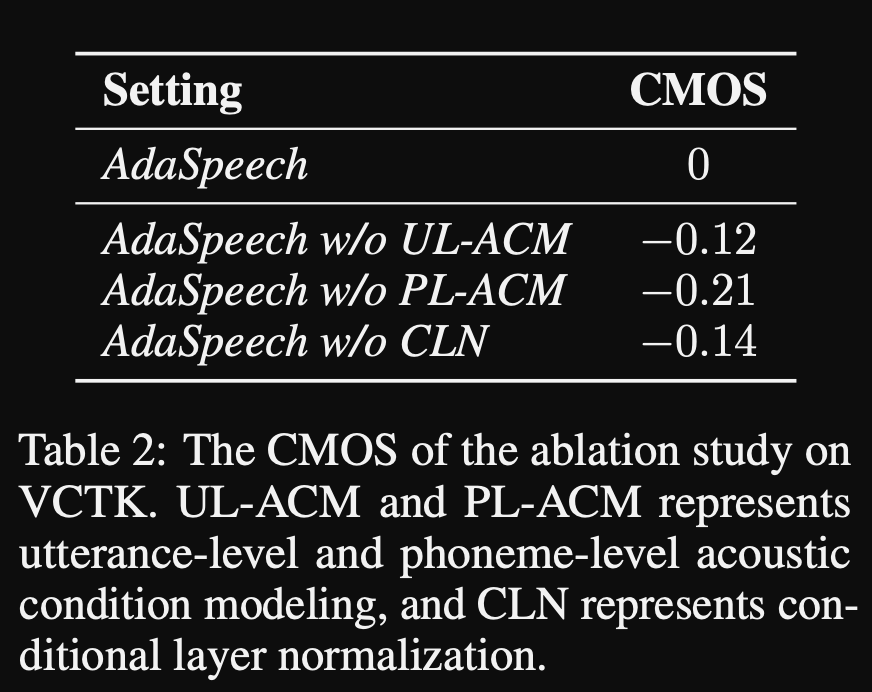
AdasPeech: texto adaptável à fala para voz personalizada: https://openreview.net/pdf?id=drynvt7gg4l
- Eles propuseram um sistema que pudesse se adaptar a diferentes propriedades acústicas de entrada dos usuários e usa o número mínimo de parâmetros para conseguir isso.
- A arquitetura principal é baseada no modelo FastSpeech2 que usa preditores de afinação e variação para aprender as granularidades mais refinadas do discurso de entrada.
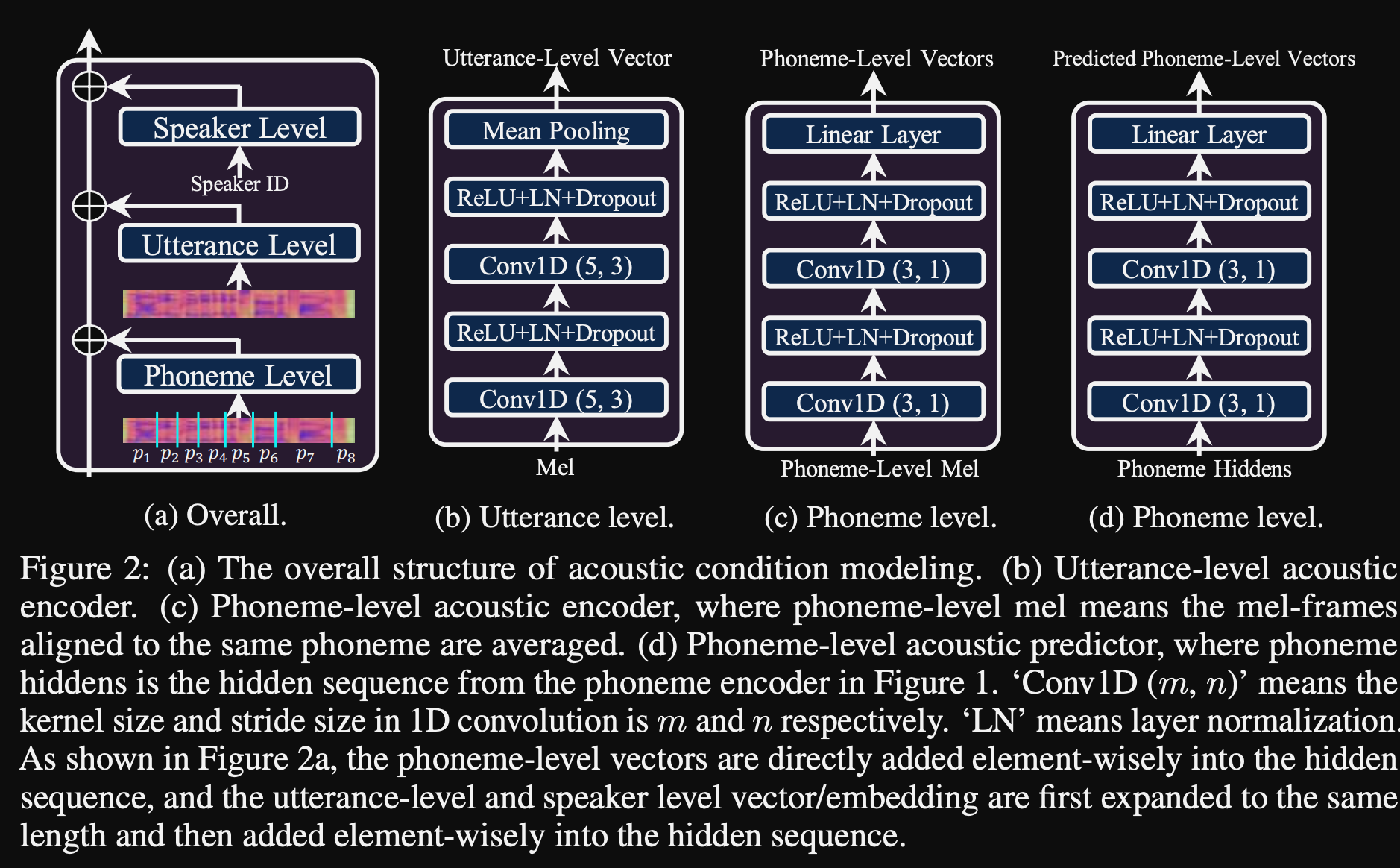
- Eles usam 3 redes de condicionamento adicionais.
- Nível de expressão. É preciso o espectrograma MEL do discurso de referência como entrada.
- Nível de fonema. São necessários espectrogramas MEL de nível de fonema como entrada e calcula vetores de condicionamento em nível de fonema. Os espectrogramas MEL em nível de fonema são calculados, tomando o quadro médio de espectrograma na duração de cada fonema.
- Nível 2 do fonema. São necessárias saídas do codificador de fonema como entrada. Isso difere da rede acima apenas usando as informações do fonema sem ver os espectrogramas.
- Todas essas redes de condicionamento e o fastspeech2 do osso traseiro usam camadas de normalização da camada.
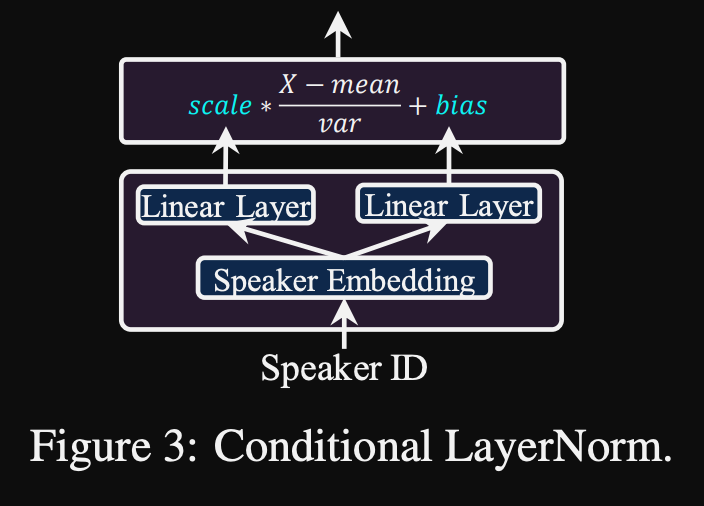
- Normalização da camada condicional. Eles propõem o ajuste fino apenas os parâmetros de escala e viés de cada camada de normalização da camada quando o modelo é ajustado para um novo alto-falante. Eles treinam um módulo de condicionamento do alto -falante para cada camada de norma de camada que gera uma escala e valores de polarização. (Eles usam um módulo de condicionamento do alto -falante por bloco de transformador.)
- Isso significa que você armazena apenas o módulo de condicionamento do alto -falante para cada novo alto -falante e prevê os valores de escala e polarização em inferência enquanto mantém o restante do modelo.
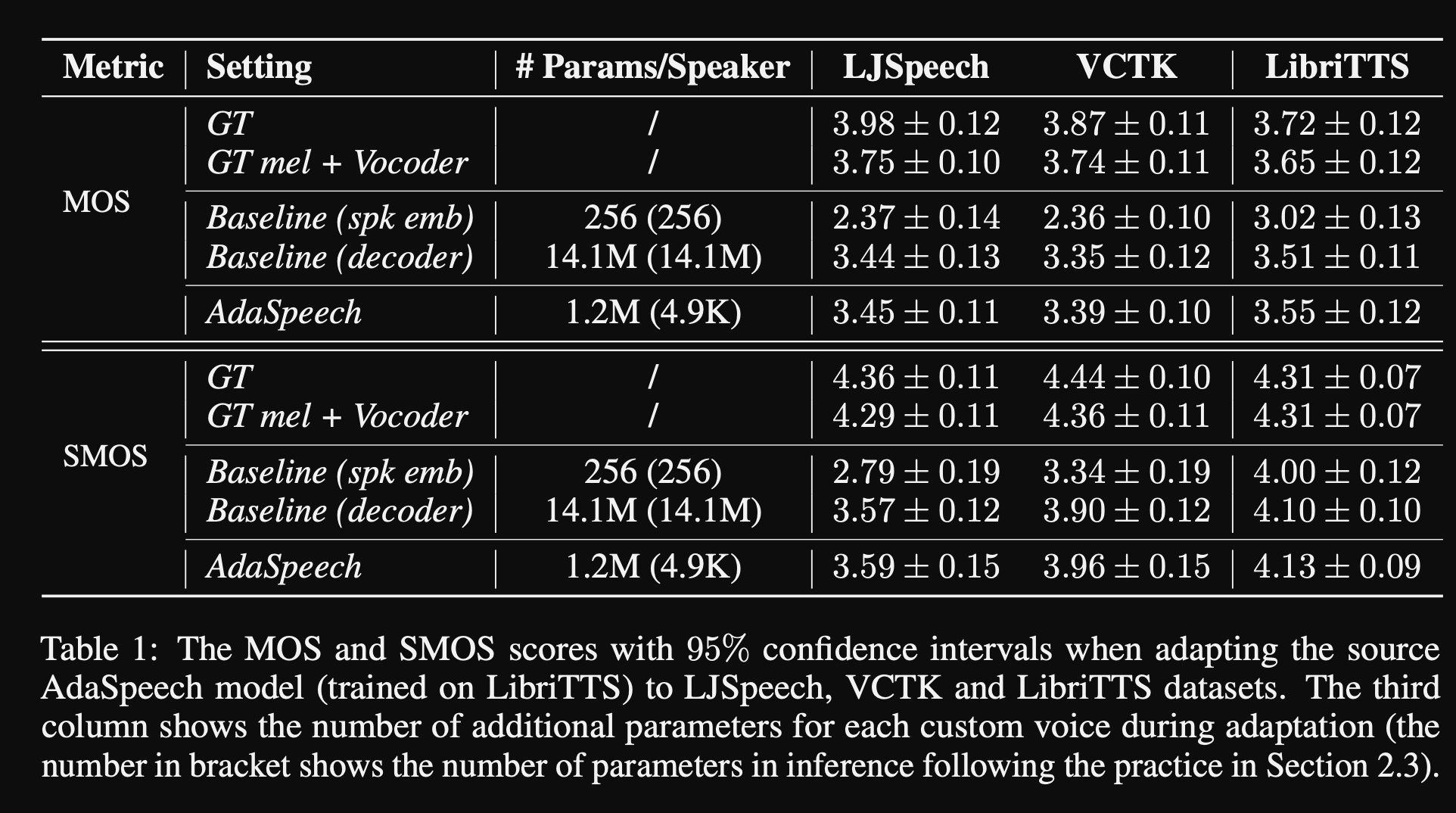
- Nos experimentos, eles treinam pré-trepndo o modelo no conjunto de dados Libritts e ajustam-o com VCTK e LJSPEECH
- Os resultados mostram que o uso de normalização da camada condicional alcança melhor do que suas duas linhas de base que usam apenas a ajuste fina de incorporação do alto-falante e decodificadores.
- Seu estudo de ablação mostra que a parte mais significativa do modelo é a rede de "nível de fonema", seguida pela normalização da camada condicional e rede de "nível de enunciado" em uma ordem.
- Uma parte inferior do artigo é que quase não há comparação com a literatura e torna os resultados mais difíceis de avaliar objetivamente.
Página de demonstração: https://speechresearch.github.io/adaspeech/

Atenção
- Mecanismos de atenção-relativa de localização para síntese robusta de forma longa-https://arxiv.org/pdf/1910.10288.pdf
Vocoders
Melgan: https://arxiv.org/pdf/1910.06711.pdf
Parallelwavegan: https://arxiv.org/pdf/1910.11480.pdf
- Perda de STFT em escala múltipla
- ~ 1M Parâmetros do modelo (muito pequeno)
- Um pouco pior do que wavernn
Melhorando a fftnet
- https://www.okamotocamera.com/slt_2018.pdff
- https://www.okamotocamera.com/slt_2018.pdf
Fftnet
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/clips/clips.php
- https://gfx.cs.princeton.edu/pubs/jin_2018_far/fftnet-jin2018.pdf
Reconstrução da forma de onda de fala usando neuralNetworks convolucionais com ruído e entradas periódicas
- 150.162.46.34:8080/icassp2019/iCassp2019/pdfs/0007045.pdf
Para obter vocoding universal robusto
- https://arxiv.org/pdf/1811.06292.pdf
LPCNET
- https://arxiv.org/pdf/1810.11846.pdf
- https://arxiv.org/pdf/2001.11686.pdf
Excitenet
- https://arxiv.org/pdf/1811.04769v3.pdf
GELP: Previsão linear excitada por Gan para síntese de fala a partir do spectrograma-espectrograma
- https://arxiv.org/pdf/1904.03976v3.pdf
Síntese da fala de alta fidelidade com redes adversárias: https://arxiv.org/abs/1909.11646
- Gan-tts, síntese de fala de ponta a ponta
- Usa duração e recursos linguísticos
- A duração e os recursos acústicos são previstos por modelos adicionais.
- Discriminador de janela aleatória: ingerir não toda a amostra de voz, mas janelas aleatórias.
- Múltiplos RWDs. Alguns condicionais e outros incondicionais. (Condicionado nos recursos de entrada)
- Punchline: Use janelas amostradas aleatoriamente com diferentes tamanhos de janela para D.
- Os resultados compartilhados parecem mecânicos que mostram os limites das características acústicas não neurais.
Melgan multi-banda: https://arxiv.org/abs/2005.05106
- Use as perdas do PWGan em vez de perda de correspondência.
- O uso de um campo receptivo maior aumenta significativamente o desempenho do modelo.
- Gerador pré -treinamento para 200k iters.
- Previsão de sinal de voz de várias bandas. A saída é a soma de 4 previsões de banda diferentes com filtros de síntese de PQMF.
- O modelo de múltiplas bandas possui parâmetros de 1,9M (bastante pequeno).
- Afirmou ser 7x mais rápido que Melgan
- Em um conjunto de dados chinês: MOS 4.22
Waveglow: https://arxiv.org/abs/1811.00002
- Modelo muito grande (268m parâmetros)
- Difícil de treinar, pois na GPU de 12 GB, só pode levar o tamanho 1 do lote.
- Inferência em tempo real devido ao uso de convoluções.
- Com base no fluxo de normalização invertível. (Ótimo tutorial https://blog.evjang.com/2018/01/nf1.html)
- O modelo aprende e o mapeamento invetível de amostras de áudio para espectrogramas MEL com perda máxima de verossimilhança.
- Na rede de inferência, as execuções na direção inversa e fornecem as especificações MEL são convertidas em amostras de áudio.
- O treinamento foi feito usando 8 nvidia v100 com 32 GB de RAM, tamanho do lote 24. (Caro)
Squeezewave: https://arxiv.org/pdf/2001.05685.pdf, código: https://github.com/tianrengao/squeezewave
- ~ 5-13x mais rápido que em tempo real
- Redandúnculos de Glow Wave: amostras de áudio longas, amostras de amostras MEL-Specs, grandes dimensões de canal na função WN.
- Correções: mais, mas amostras de áudio mais curtas como entrada, (L = 2000, C = 8 vs L = 64, C = 256)
- L = 64 corresponde à resolução MEL-Spec, portanto, não é necessária uma amostragem.
- Use convoluções separáveis em profundidade nos módulos WN.
- Use a convolução regular em vez de dilatada, pois as amostras de áudio são mais curtas.
- Não divida as saídas do módulo na saída residual e de rede, assumindo que esses vetores sejam quase idênticos.
- O treinamento foi realizado usando o tamanho 96 do Titan RTX 24 GB para iterações de 600 mil.
- Mos em LJSpeech: Waveglow - 4,57, Squeezewave (L = 128 C = 256) - 4,07 e Squeezewave (L = 64 C = 256) - 3,77
- O menor modelo possui 21k amostras por segundo no RASPI3.
WaveGrad: https://arxiv.org/pdf/2009.00713.pdf
- É baseado em difusão de probabilidade e dinâmica de Lagenvin
- A idéia base é aprender uma função que mapeia uma distribuição conhecida para direcionar a distribuição de dados iterativamente.
- Eles relatam 0,2 fator em tempo real em uma GPU, mas o desempenho da CPU não é compartilhado.
- No código de exemplo abaixo, o autor relata que o modelo converge após 2 dias de treinamento em uma única GPU.
- As pontuações do MOS no papel não são o suficiente, mas mostram desempenho comparável a modelos conhecidos como Wavernn e WaveNet.
Código: https://github.com/ivanvovk/wavegr 
Da internet (blogs, vídeos etc.)
Vídeos
Discussão em papel
- Tacotron 2: https://www.youtube.com/watch?v=2iarxxm-v9w
Conversas
- Converse sobre empurrar a fronteira do texto neural em fala, por Xu Tan, 2021, https://youtu.be/ma8pcvmr8b0
- Converse sobre a síntese generativa de texto em fala, por Heiga Zen, 2017
- Vídeo: https://youtu.be/nsrsrytkkt8
- Slide: https://research.google.com/pubs/pub45882.html
- Tutoriais sobre a síntese de texto em fala paramétrica neural na ISCA ODYESSY 2020, por Xin Wang, 2020
- Vídeo: https://youtu.be/wce7sycdzai
- Slide: http://tonywangx.github.io/slide.html#dec-2020
- Curso de processamento de fala da ISCA sobre vocoders neurais, 2022
- Componentes básicos dos vocoders neurais: https://youtu.be/m833q5i-zys
- Modelos generativos profundos para compactação de fala (LPCNET): https://youtu.be/7ksnfx3plgw
- Vocoders auto-regressivos, filtro de origem e glotais neurais: https://youtu.be/gprmxdberx0
- Slide: http://tonywangx.github.io/slide.html#jul-2020
- Síntese de fala da decodificação neural de sentenças faladas | AISC: https://www.youtube.com/watch?v=mndtmdpmnmo
- Síntese generativa de texto em fala: https://www.youtube.com/watch?v=j4mVeanking
- Síntese de fala para a indústria de jogos: https://www.youtube.com/watch?v=aoHaye4a-2q
Em geral
- Revisão de sistemas de texto em fala moderna: https://www.youtube.com/watch?v=8rxlsc-zcry
Notebooks Jupyter
- Tutoriais sobre vocoders neurais selecionados: https://github.com/nii-yamagishilab/project-nn-pytorch-scripts/tree/master/tutorials/b1_neural_vocoder
Blogs
- Arquiteturas de texto para aprendizado profundo da fala: http://www.erogol.com/text-speech-deep-learning-architectures/


