Prototypical Networks for Few shot Learning PyTorch
1.0.0
การใช้งานทางเลือกอย่างง่ายของเครือข่ายต้นแบบสำหรับการเรียนรู้ช็อตไม่กี่ (กระดาษ, รหัส) ใน Pytorch
ดังที่แสดงในเครือข่ายต้นแบบกระดาษอ้างอิงได้รับการฝึกฝนให้ฝังคุณสมบัติตัวอย่างในพื้นที่เวกเตอร์โดยเฉพาะอย่างยิ่งในแต่ละตอน (การวน n_support ) จำนวนตัวอย่างสำหรับชุดย่อยของชั้นเรียนจะถูกเลือกและส่งผ่านแบบจำลองแต่ละส่วนของคลาส c ระหว่างตัวอย่าง n_query ที่เหลือและคลาส Barycentre ของพวกเขาสามารถลดลงได้
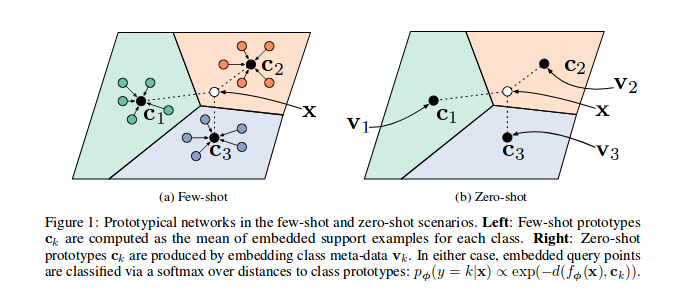
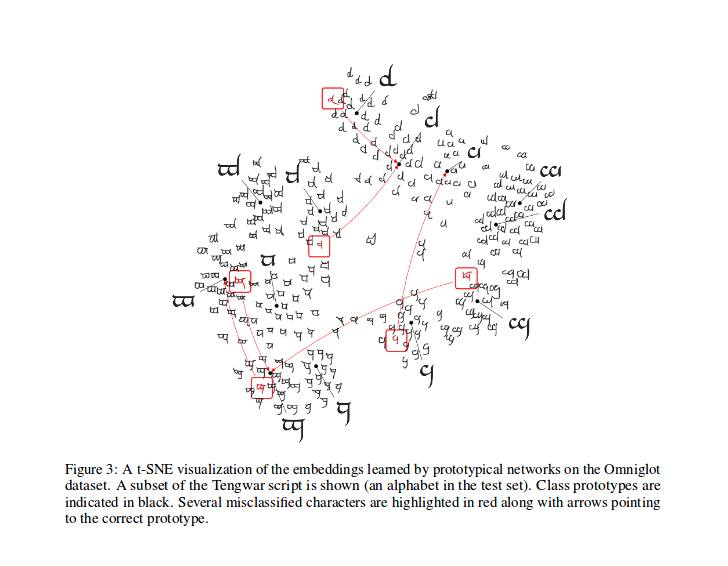
หลังจากการฝึกอบรมคุณสามารถคำนวณ T-SNE สำหรับคุณสมบัติที่สร้างขึ้นโดยโมเดล (ไม่ได้ทำใน repo นี้ infos เพิ่มเติมเกี่ยวกับ T-SNE ที่นี่) นี่เป็นตัวอย่างดังที่แสดงในกระดาษ
ความรุ่งโรจน์ถึง @ludc สำหรับการมีส่วนร่วมของเขา: Pytorch/Vision#46 เราจะใช้ชุดข้อมูลอย่างเป็นทางการเมื่อมันจะถูกเพิ่มเข้าไปใน Torchvision หากไม่ได้หมายความถึงการเปลี่ยนแปลงครั้งใหญ่ในรหัส
เราใช้วิธีการแยก Vynials เช่นเดียวกับใน [การจับคู่เครือข่ายสำหรับการเรียนรู้หนึ่งนัด] นั่นเป็นวิธีเดียวกับที่ใช้ในกระดาษ (อันที่จริงฉันดาวน์โหลดไฟล์แยกจาก repo "Offical") จากนั้นเราใช้การหมุนแบบเดียวกันกับที่อธิบายไว้ ด้วยวิธีนี้เราควรจะสามารถเปรียบเทียบผลลัพธ์ที่ได้จากการเรียกใช้รหัสนี้กับผลลัพธ์ที่อธิบายไว้ในเอกสารอ้างอิง
ตามที่อธิบายไว้ใน PYDOC คลาสนี้ใช้เพื่อสร้างดัชนีของแต่ละชุดสำหรับอัลกอริทึมการฝึกอบรมต้นแบบ
โดยเฉพาะอย่างยิ่งวัตถุจะถูกสร้างอินสแตนซ์โดยผ่านรายการของป้ายกำกับสำหรับชุดข้อมูลตัวตัวอย่างของตัวอย่างจากนั้นจำนวนคลาสทั้งหมดและสร้างชุดของดัชนีสำหรับแต่ละคลาส Ni ชุดข้อมูล ในแต่ละตอนตัวอย่างจะเลือกคลาสสุ่ม n_classes และส่งคืนตัวเลข ( n_support + n_query ) ของดัชนีตัวอย่างสำหรับแต่ละคลาสที่เลือก
คำนวณการสูญเสียเช่นเดียวกับในกระดาษที่อ้างถึงส่วนใหญ่ได้รับแรงบันดาลใจจากรหัสนี้โดยหนึ่งในผู้เขียน
ใน prototypical_loss.py ทั้งฟังก์ชั่นการสูญเสียและระดับการสูญเสียà la pytorch ถูกนำมาใช้
ฟังก์ชั่นใช้ในอินพุตอินพุตแบทช์จากโมเดลความจริงภาคพื้นดินของตัวอย่างและจำนวน n_suppport ของตัวอย่างที่จะใช้เป็นตัวอย่างการสนับสนุน คลาสตอนได้รับการอนุมานจากรายการเป้าหมายตัวอย่าง n_support จะถูกสกัดแบบสุ่มสำหรับแต่ละชั้นเรียน Barycentres ของพวกเขาจะถูกคำนวณเช่นเดียวกับระยะทางของแต่ละตัวอย่างที่เหลือจากแต่ละคลาส Barycentre และความน่าจะเป็นของแต่ละตัวอย่าง จากนั้นการสูญเสียจะถูกคำนวณจากความน่าจะเป็นที่ผิดพลาด (สำหรับตัวอย่างการสืบค้น) ตามปกติในปัญหาการจำแนกประเภท
โปรดทราบว่ารหัสการฝึกอบรมอยู่ที่นี่เพื่อวัตถุประสงค์ในการสาธิต
ในการฝึกอบรมโปรโตเน็ตในงานนี้ซีดีลงในโฟลเดอร์รูท src ของ repo นี้และดำเนินการ:
$ python train.py
สคริปต์ใช้ตัวเลือกบรรทัดคำสั่งต่อไปนี้:
dataset_root : ไดเรกทอรีรูทที่เก็บชุดข้อมูล tha, ค่าเริ่มต้นเป็น '../dataset'
nepochs : จำนวนยุคที่จะฝึกอบรมค่าเริ่มต้นถึง 100
learning_rate : อัตราการเรียนรู้สำหรับแบบจำลองเริ่มต้นที่ 0.001
lr_scheduler_step : ขั้นตอนการกำหนดค่าอัตราการเรียนรู้ Steplr, เริ่มต้นเป็น 20
lr_scheduler_gamma : GAMMA อัตราการเรียนรู้ของ Steplr, Gamma, เริ่มต้นเป็น 0.5
iterations : จำนวนตอนต่อยุค ค่าเริ่มต้นเป็น 100
classes_per_it_tr : จำนวนคลาสสุ่มต่อตอนสำหรับการฝึกอบรม ค่าเริ่มต้นเป็น 60
num_support_tr : จำนวนตัวอย่างต่อคลาสที่จะใช้เป็นการสนับสนุนสำหรับการฝึกอบรม ค่าเริ่มต้นเป็น 5
num_query_tr : nnumber ของตัวอย่างต่อคลาสเพื่อใช้เป็นแบบสอบถามสำหรับการฝึกอบรม ค่าเริ่มต้นเป็น 5
classes_per_it_val : จำนวนคลาสสุ่มต่อตอนสำหรับการตรวจสอบความถูกต้อง ค่าเริ่มต้นเป็น 5
num_support_val : จำนวนตัวอย่างต่อคลาสที่จะใช้เป็นการสนับสนุนสำหรับการตรวจสอบความถูกต้อง ค่าเริ่มต้นเป็น 5
num_query_val : จำนวนตัวอย่างต่อคลาสที่จะใช้เป็นแบบสอบถามสำหรับการตรวจสอบความถูกต้อง ค่าเริ่มต้นเป็น 15
manual_seed : อินพุตสำหรับการกำหนดค่าเริ่มต้นของเมล็ดด้วยตนเอง, ค่าเริ่มต้นเป็น 7
cuda : เปิดใช้งาน cuda (เก็บ True )
การเรียกใช้คำสั่งโดยไม่มีอาร์กิวเมนต์จะฝึกอบรมโมเดลด้วยค่า hyperparamters เริ่มต้น (การผลิตผลลัพธ์ที่แสดงด้านบน)
เรากำลังพยายามทำซ้ำกระดาษอ้างอิงเราจะอัปเดตผลลัพธ์ที่ดีที่สุดของเราที่นี่
| แบบอย่าง | 1-shot (5 ทาง ACC.) | 5-shot (5 ทาง ACC.) | 1 -shot (20 -way Acc.) | 5-shot (20-WAY ACC.) |
|---|---|---|---|---|
| กระดาษอ้างอิง | 98.8% | 99.7% | 96.0% | 98.9% |
| repo นี้ | 98.5%** | 99.6%* | 95.1%° | 98.6%°° |
* ทำได้โดยใช้พารามิเตอร์เริ่มต้น (ใช้ -ตัวเลือก --cuda )
** ประสบความสำเร็จในการวิ่ง python train.py --cuda -nsTr 1 -nsVa 1
°ประสบความสำเร็จในการวิ่ง python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°°ประสบความสำเร็จในการวิ่ง python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
อ้างอิงกระดาษดังนี้ (คัดลอกมาจาก arxiv สำหรับคุณ):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
โครงการนี้ได้รับใบอนุญาตภายใต้ใบอนุญาต MIT
ลิขสิทธิ์ (c) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com)


