Prototypical Networks for Few shot Learning PyTorch
1.0.0
Einfache alternative Implementierung prototypischer Netzwerke für wenige Schusslernen (Papier, Code) in Pytorch.
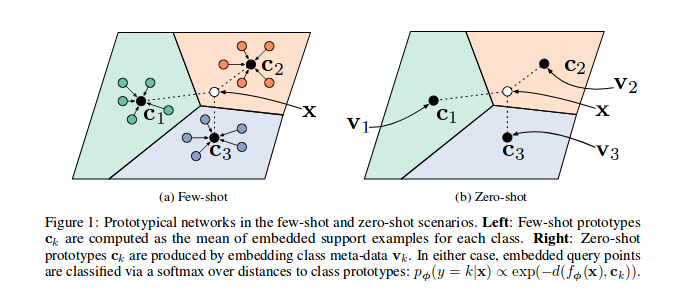
Wie in den Referenzpapier gezeigt werden, werden prototypische Netzwerke in einem vektoriellen Raum, insbesondere in jeder Episode (Iteration), trainiert, eine Reihe von Proben für eine Untergruppe von Klassen ausgewählt und durch das Modell gesendet werden. Für jede Untergruppe der Klassen c -Merkmale ( n_support ) wird der Prototyp der Klassenstruktur -CORTODINATE -Merkmale verwendet. Die verbleibenden n_query -Proben und ihr Klassen -Barycentre können minimiert werden.
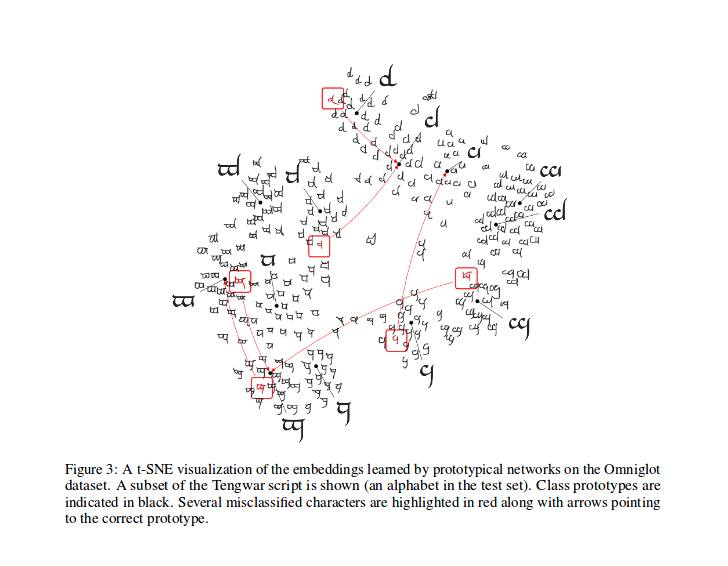
Nach dem Training können Sie die T-Sne für die vom Modell erzeugten Funktionen berechnen (nicht in diesem Repo, mehr Infos über T-Sne hier). Dies ist eine Stichprobe, wie in der Arbeit gezeigt.
Ein großes Lob an @ludc für seinen Beitrag: Pytorch/Vision#46. Wir werden den offiziellen Datensatz verwenden, wenn es zu Torchvision hinzugefügt wird, wenn es keine großen Änderungen am Code impliziert.
Wir haben die Vynials -Spaltungsmethode wie in [passenden Netzwerken für One Shot Learning] implementiert. Das wäre die gleiche Methode, die im Papier verwendet wird (tatsächlich lade ich die geteilten Dateien aus dem "Offical" -Repo herunter). Wir wenden dann die gleichen Rotationen dort beschrieben an. Auf diese Weise sollten wir in der Lage sein, Ergebnisse zu vergleichen, die durch Ausführen dieses Code mit den im Referenzpapier beschriebenen Ergebnissen erzielt werden.
Wie in seinem Pydoc beschrieben, wird diese Klasse verwendet, um die Indizes jeder Charge für einen prototypischen Trainingsalgorithmus zu generieren.
Insbesondere wird das Objekt instanziiert, indem die Liste der Etiketten für den Datensatz übergeben wird. Der Sampler ist fern, dann die Gesamtzahl der Klassen und erstellt eine Reihe von Indizes für jede Klasse NI des Datensatzes. In jeder Episode wählt der Sampler n_classes zufällige Klassen aus und gibt für jedes der ausgewählten Klassen eine Nummer ( n_support + n_query ) von Samples -Indizes zurück.
Berechnen Sie den Verlust wie in dem zitierten Papier, der hauptsächlich von diesem Code von einem seiner Autoren inspiriert wurde.
In prototypical_loss.py werden sowohl Verlustfunktion als auch Verlustklasse à la pytorch implementiert.
Die Funktion nimmt die Stapeleingabe aus dem Modell, die Grundwahrheiten der Proben und die Nummer n_suppport von Proben, die als Stützproben verwendet werden sollen. Episodenklassen werden aus der Zielliste abgeleitet, n_support -Stichproben werden für jede Klasse zufällig extrahiert. Ihre Klassen -Baryzentre werden berechnet, sowie die Entfernungen der verbleibenden Proben, die aus jeder Klassen -Baryzentre einbettet, und die Wahrscheinlichkeit jeder Zugehörigkeit zu jeder Episodenklasse wird feinmallisch berechnet. Anschließend wird der Verlust aus den falschen Vorhersagenwahrscheinlichkeiten (für die Abfragemutproben) wie in Klassifizierungsproblemen gewohnt berechnet.
Bitte beachten Sie, dass der Trainingscode nur für Demonstrationszwecke vorhanden ist.
Um das Protonet für diese Aufgabe zu trainieren, können Sie CD in den src -Root -Ordner dieses Repos und ausführen:
$ python train.py
Das Skript nimmt die folgenden Befehlszeilenoptionen an:
dataset_root : Das Stammverzeichnis, in dem der Datensatz gespeichert ist, standardmäßig '../dataset'
nepochs : Anzahl der Epochen, für die sie trainieren sollten, standardmäßig 100
learning_rate : Lernrate für das Modell, Standard auf 0.001
lr_scheduler_step : StepLR Lernrate Scheduler Schritt, Standard bis 20
lr_scheduler_gamma : StepLR -Lernrate Scheduler Gamma, Standard auf 0.5
iterations : Anzahl der Episoden pro Epoche. Standard auf 100
classes_per_it_tr : Anzahl der zufälligen Klassen pro Episode für das Training. Standard auf 60
num_support_tr : Anzahl der Stichproben pro Klasse, die als Unterstützung für das Training verwendet werden sollen. Standard auf 5
num_query_tr : number der Proben pro Klasse als Abfrage für das Training verwendet. Standard auf 5
classes_per_it_val : Anzahl der zufälligen Klassen pro Episode zur Validierung. Standard auf 5
num_support_val : Anzahl der Stichproben pro Klasse, die als Unterstützung für die Validierung verwendet werden sollen. Standard auf 5
num_query_val : Anzahl der Stichproben pro Klasse, die als Abfrage zur Validierung verwendet werden sollen. Standard auf 15
manual_seed : Eingabe für die manuellen Seeds -Initialisierungen, Standard auf 7
cuda : Ermöglicht Cuda (speichern True )
Durch das Ausführen des Befehls ohne Argumente trainieren die Modelle mit den Standard -Hyperparamterwerten (die oben gezeigten Ergebnisse erzeugen).
Wir versuchen, die Referenzpapierdauer zu reproduzieren. Wir werden hier unsere besten Ergebnisse aktualisieren.
| Modell | 1-shot (5-Wege Acc.) | 5-Shot (5-Wege Acc.) | 1 -Shot (20 -Wege Acc.) | 5-Shot (20-Wege ACC.) |
|---|---|---|---|---|
| Referenzpapier | 98,8% | 99,7% | 96,0% | 98,9% |
| Dieses Repo | 98,5%** | 99,6%* | 95,1%° | 98,6%°° |
* Mit Standardparametern erreicht (mit der Option --cuda )
** erreichte laufende python train.py --cuda -nsTr 1 -nsVa 1
° erreicht laufende python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°° erreicht laufende python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
Zitieren Sie das Papier wie folgt (kopiert es von Arxiv für Sie):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Dieses Projekt ist unter der MIT -Lizenz lizenziert
Copyright (C) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com).


