Prototypical Networks for Few shot Learning PyTorch
1.0.0
Implementación alternativa simple de redes prototípicas para pocos aprendizaje de disparos (papel, código) en Pytorch.
Como se muestra en el documento de referencia, las redes prototípicas están capacitadas para insertar las características de las muestras en un espacio vectorial, en particular, en cada episodio (iteración), varias muestras para un subconjunto de clases se seleccionan y se envían a través del modelo, para cada subconjunto de la Clase c de una serie de características de muestras ( n_support ) se usan para adivinar el prototipo (sus barycentre en el espacio de las vías de vías de las vías de las muestras). Se pueden minimizar las muestras n_query restantes y su clase Barycentre.
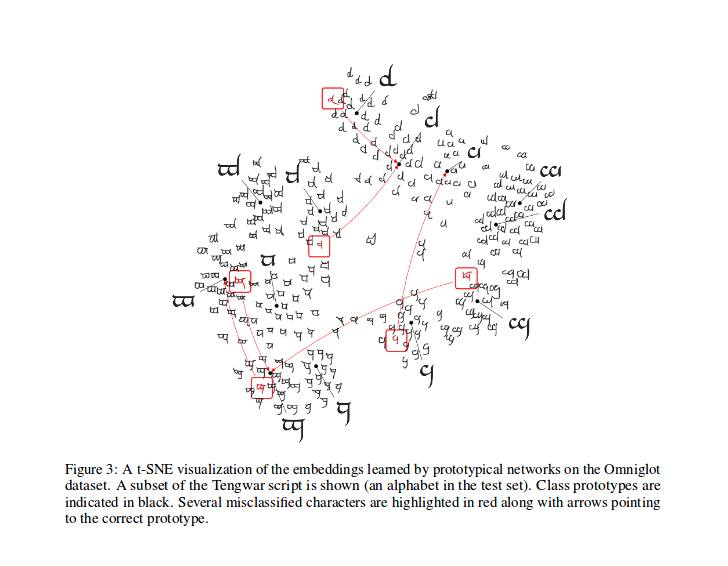
Después del entrenamiento, puede calcular el T-SNE para las características generadas por el modelo (no realizado en este repositorio, más infos sobre T-SNE aquí), esta es una muestra como se muestra en el documento.
Felicitaciones a @Ludc por su contribución: Pytorch/Vision#46. Usaremos el conjunto de datos oficial cuando se agregará a TorchVision si no implica grandes cambios en el código.
Implementamos el método de división Vynials como en [Redes coincidentes para un aprendizaje de un disparo]. Ese debería ser el mismo método utilizado en el documento (de hecho, descarto los archivos divididos del repositorio "oficial"). Luego aplicamos las mismas rotaciones allí descritas. De esta manera, deberíamos poder comparar los resultados obtenidos ejecutando este código con los resultados descritos en el documento de referencia.
Como se describe en su PYDOC, esta clase se utiliza para generar los índices de cada lote para un algoritmo de entrenamiento prototípico.
En particular, el objeto se instancia al pasar la lista de las etiquetas para el conjunto de datos, la muestra infiere el número total de clases y crea un conjunto de índices para cada clase ni el conjunto de datos. En cada episodio, la muestra selecciona clases aleatorias n_classes y devuelve un número ( n_support + n_query ) de los índices de muestras para cada una de las clases seleccionadas.
Calcule la pérdida como en el artículo citado, inspirado principalmente en este código por uno de sus autores.
En prototypical_loss.py se implementan la función de pérdida y la clase de pérdida à la pytorch.
La función toma la entrada de la entrada por lotes del modelo, las verdades terrestres de las muestras y el número n_suppport de las muestras que se utilizarán como muestras de soporte. Las clases de episodios se infieren de la lista de objetivos, las muestras n_support se extraen al azar para cada clase, se calculan sus clases de la clase, así como las distancias de cada muestra restantes que incrusta de cada clase Barycentre y la probabilidad de cada muestra de pertenencia a cada clase de episodio se calcula finalmente; Luego, la pérdida se calcula a partir de las probabilidades de predicciones incorrectas (para las muestras de consulta) como de costumbre en los problemas de clasificación.
Tenga en cuenta que el código de capacitación está aquí solo para fines de demostración.
Para entrenar el protonet en esta tarea, CD en la carpeta de raíz src de este repositorio y ejecute:
$ python train.py
El script toma las siguientes opciones de línea de comando:
dataset_root : el directorio raíz donde se almacena el conjunto de datos, predeterminado a '../dataset'
nepochs : número de épocas para entrenar, por defecto a 100
learning_rate : tasa de aprendizaje para el modelo, predeterminado a 0.001
lr_scheduler_step : Paso de programador de tasa de aprendizaje Steplr, predeterminado a 20
lr_scheduler_gamma : steplr tasa de aprendizaje gamma, predeterminado a 0.5
iterations : número de episodios por época. predeterminado a 100
classes_per_it_tr : número de clases aleatorias por episodio para entrenamiento. predeterminado a 60
num_support_tr : número de muestras por clase para usar como soporte para el entrenamiento. predeterminado a 5
num_query_tr : Number de muestras por clase para usar como consulta para el entrenamiento. predeterminado a 5
classes_per_it_val : número de clases aleatorias por episodio para la validación. predeterminado a 5
num_support_val : número de muestras por clase para usar como soporte para la validación. predeterminado a 5
num_query_val : número de muestras por clase para usar como consulta para validación. predeterminado a 15
manual_seed : entrada para las inicializaciones de semillas manuales, predeterminada a 7
cuda : Habilita CUDA (tienda True )
Ejecutar el comando sin argumentos capacitará a los modelos con los valores predeterminados de HyperParamters (produciendo resultados mostrados anteriormente).
Estamos tratando de reproducir el documento de referencia, actualizaremos aquí nuestros mejores resultados.
| Modelo | 1-shot (Acc. De 5 vías) | 5-SHOT (ACC. 5 vías) | 1 -shot (Acc. De 20 vías) | 5-SHOT (20 vías Acc.) |
|---|---|---|---|---|
| Papel de referencia | 98.8% | 99.7% | 96.0% | 98.9% |
| Este repositorio | 98.5%** | 99.6%* | 95.1%° | 98.6%°° |
* logrado con los parámetros predeterminados (usando la opción --cuda )
** logró correr python train.py --cuda -nsTr 1 -nsVa 1
° logró correr python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°° logrado corriendo python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
cita el documento de la siguiente manera (Copied-Paste de Arxiv para ti):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Este proyecto tiene licencia bajo la licencia MIT
Copyright (c) 2018 Daniele E. Ciriello, Oobix SRL (www.orobix.com).


