Prototypical Networks for Few shot Learning PyTorch
1.0.0
Pytorchの少数のショット学習(紙、コード)のためのプロトタイプネットワークの簡単な代替実装。
リファレンスペーパーに示されているように、プロトタイプネットワークは、特に各エピソード(反復)でベクトル空間にサンプルの特徴を埋め込むようにトレーニングされています(反復)、クラスのサブセットのサブセットのサンプルの多くが選択され、クラスcの各サブセットのサブセットの各サブセットのn_supportが送信されます。 n_queryサンプルとそのクラスのバリセントルを最小限に抑えることができます。
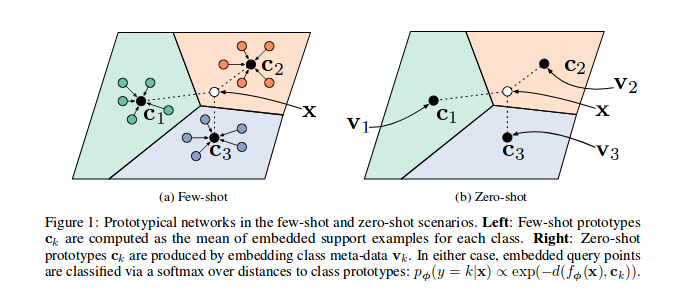
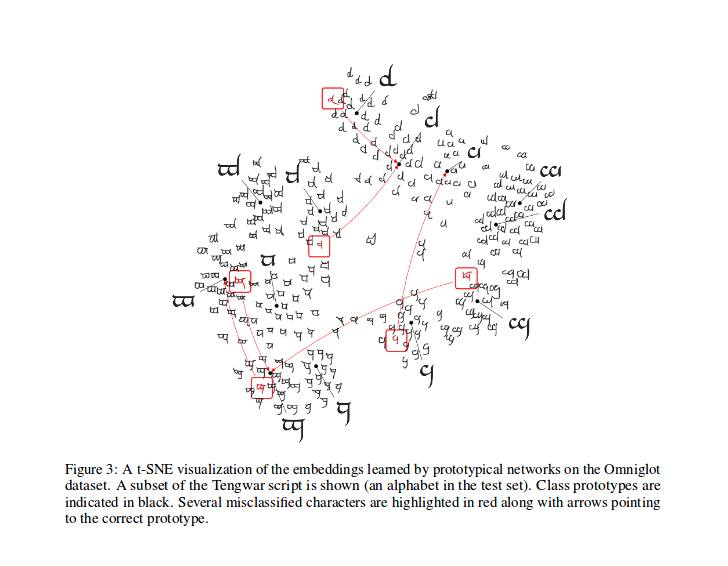
トレーニング後、モデルによって生成された機能のT-SNEを計算できます(このレポでは行われていませんが、ここではT-SNEに関する情報が増えます)。これは、論文に示すようにサンプルです。
彼の貢献に対する@ludcへの称賛:pytorch/vision#46。コードの大きな変更を暗示していない場合、Torchvisionに追加される公式データセットを使用します。
[ワンショット学習のネットワークを一致させる]と同様に、Vynials分割方法を実装しました。これは、論文で使用されている同じ方法である可能性があります(実際、「オフカル」リポジトリから分割ファイルをダウンロードします)。次に、説明した同じ回転を適用します。このようにして、このコードを実行することで得られた結果を参照論文で説明した結果と比較できるはずです。
Pydocで説明されているように、このクラスは、プロトタイプのトレーニングアルゴリズムの各バッチのインデックスを生成するために使用されます。
特に、オブジェクトは、データセットのラベルのリストを渡すことによりインスタンス化され、サンプラーはクラスの総数をインスタードし、各クラスNIのインデックスセットをデータセットに作成します。各エピソードで、サンプラーはn_classesランダムクラスを選択し、選択したクラスのそれぞれのサンプルインデックスの数字( n_support + n_query )を返します。
引用された論文のように損失を計算します。その著者の一人からこのコードに触発されたものです。
prototypical_loss.pyでは、損失関数と損失クラスの両方がPytorchの両方が実装されています。
この関数は、モデルからのバッチ入力、サンプルのグラウンドトゥルース、およびサポートサンプルとして使用されるサンプルの数n_suppportを入力します。エピソードクラスはターゲットリストから推測され、 n_supportサンプルは各クラスに対してランダムに抽出され、クラスのバリセントレが計算され、各クラスからの埋め込みの各サンプルの距離と各エピソードクラスの各サンプルの確率がfinmallyに計算されます。次に、分類の問題で通常どおり(クエリサンプルの場合)間違った予測確率から損失が計算されます。
トレーニングコードは、デモンストレーションのためだけにここにあることに注意してください。
このタスクでプロトネットをトレーニングするには、このリポジトリのsrcルートフォルダーにCDを実行して実行します。
$ python train.py
スクリプトは、次のコマンドラインオプションを取得します。
dataset_root :データセットが保存されているルートディレクトリ、デフォルト'../dataset'
nepochs :トレーニングするエポックの数、デフォルト100に
learning_rate :モデルの学習率、デフォルトは0.001になります
lr_scheduler_step :steplr学習レートスケジューラステップ、デフォルト20に
lr_scheduler_gamma :steplr学習率スケジューラガンマ、デフォルトは0.5になります
iterations :エポックあたりのエピソード数。デフォルトは100になります
classes_per_it_tr :トレーニング用のエピソードごとのランダムクラスの数。デフォルトは60になります
num_support_tr :トレーニングのサポートとして使用するクラスごとのサンプルの数。デフォルトは5になります
num_query_tr :トレーニングのクエリとして使用するクラスごとのサンプルの数。デフォルトは5になります
classes_per_it_val :検証のためのエピソードごとのランダムクラスの数。デフォルトは5になります
num_support_val :検証のサポートとして使用するクラスごとのサンプルの数。デフォルトは5になります
num_query_val :検証のクエリとして使用するクラスごとのサンプルの数。デフォルトは15になります
manual_seed :マニュアルシードの初期化の入力、デフォルト7
cuda :cuda(store True )を有効にする
引数なしでコマンドを実行すると、デフォルトのHyperParamters値を使用してモデルをトレーニングします(上記の結果が生成されます)。
参照用紙のパフォーマンスを再現しようとしています。ここでは、最良の結果を更新します。
| モデル | 1ショット(5ウェイACC。) | 5ショット(5ウェイACC。) | 1-ショット(20ウェイACC。) | 5ショット(20-way acc。) |
|---|---|---|---|---|
| 参照ペーパー | 98.8% | 99.7% | 96.0% | 98.9% |
| このレポ | 98.5%** | 99.6%* | 95.1%° | 98.6%°° |
*デフォルトパラメーターを使用して達成されました( --cudaオプションを使用)
**ランニングpython train.py --cuda -nsTr 1 -nsVa 1
°ランニングpython train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°°running python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
次のように論文を引用します(あなたのためにarxivからコピーしてそれを受け取りました):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
このプロジェクトは、MITライセンスの下でライセンスされています
Copyright(c)2018 Daniele E. Ciriello、Orobix SRL(www.orobix.com)。


