Prototypical Networks for Few shot Learning PyTorch
1.0.0
Implementasi alternatif sederhana dari jaringan prototipikal untuk beberapa pembelajaran bidikan (kertas, kode) di Pytorch.
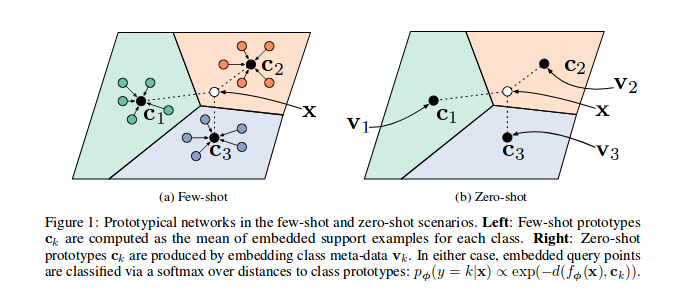
As shown in the reference paper Prototypical Networks are trained to embed samples features in a vectorial space, in particular, at each episode (iteration), a number of samples for a subset of classes are selected and sent through the model, for each subset of class c a number of samples' features ( n_support ) are used to guess the prototype (their barycentre coordinates in the vectorial space) for that class, so then the distances between the remaining Sampel n_query dan BaryCentre kelasnya dapat diminimalkan.
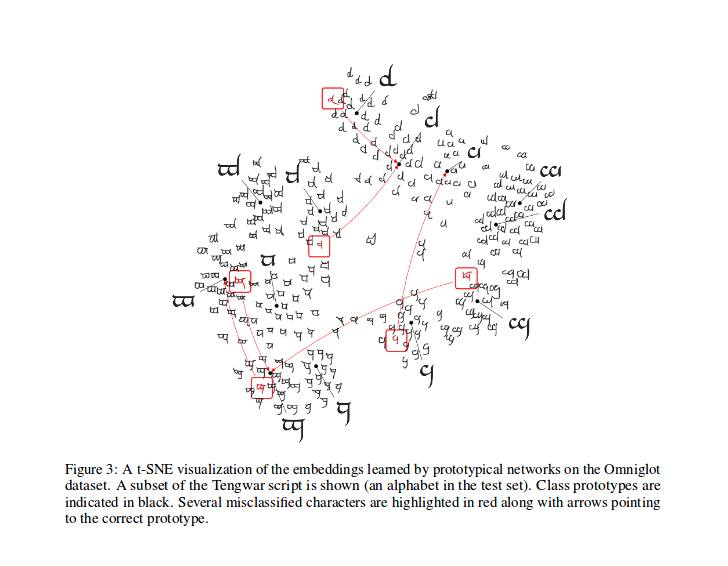
Setelah pelatihan, Anda dapat menghitung T-SNE untuk fitur yang dihasilkan oleh model (tidak dilakukan dalam repo ini, lebih banyak info tentang T-SNE di sini), ini adalah sampel seperti yang ditunjukkan dalam makalah.
Kudos to @ludc untuk kontribusinya: Pytorch/Visi#46. Kami akan menggunakan dataset resmi ketika akan ditambahkan ke TorchVision jika tidak menyiratkan perubahan besar pada kode.
Kami mengimplementasikan metode pemisahan vynials seperti pada [pencocokan jaringan untuk satu shot learning]. Itu bisa menjadi metode yang sama yang digunakan dalam makalah (sebenarnya saya mengunduh file split dari repo "offical"). Kami kemudian menerapkan rotasi yang sama di sana yang dijelaskan. Dengan cara ini kita harus dapat membandingkan hasil yang diperoleh dengan menjalankan kode ini dengan hasil yang dijelaskan dalam makalah referensi.
Seperti yang dijelaskan dalam PyDoc -nya, kelas ini digunakan untuk menghasilkan indeks setiap batch untuk algoritma pelatihan prototipikal.
Secara khusus, objek dipakai dengan melewati daftar label untuk dataset, sampler menyimpulkan kemudian jumlah total kelas dan membuat satu set indeks untuk setiap kelas Ni dataset. Pada setiap episode sampler memilih kelas acak n_classes dan mengembalikan angka ( n_support + n_query ) dari indeks sampel untuk masing -masing kelas yang dipilih.
Hitung kehilangan seperti dalam makalah yang dikutip, sebagian besar terinspirasi oleh kode ini oleh salah satu penulisnya.
Dalam prototypical_loss.py Kelas rugi dan kelas kerugian à la pytorch diimplementasikan.
Fungsi ini mengambil input input batch dari model, kebenaran tanah sampel dan angka n_suppport dari sampel yang akan digunakan sebagai sampel pendukung. Kelas episode disimpulkan dari daftar target, sampel n_support dapat diekstraksi secara acak untuk setiap kelas, kelas barycentres mereka dihitung, serta jarak masing -masing sampel yang tersisa 'yang menanamkan dari setiap kelas BaryCentre dan probabilitas setiap sampel milik setiap kelas episode dihitung secara finmal; Kemudian kerugian kemudian dihitung dari probabilitas prediksi yang salah (untuk sampel kueri) seperti biasa dalam masalah klasifikasi.
Harap dicatat bahwa kode pelatihan ada di sini hanya untuk tujuan demonstrasi.
Untuk melatih protonet pada tugas ini, CD ke dalam folder root src repo ini dan jalankan:
$ python train.py
Skrip mengambil opsi baris perintah berikut:
dataset_root : Direktori root di mana dataset disimpan, default ke '../dataset'
nepochs : Jumlah zaman yang akan dilatih, default ke 100
learning_rate : tingkat pembelajaran untuk model, default ke 0.001
lr_scheduler_step : langkah penjadwal tingkat pembelajaran, default ke 20
lr_scheduler_gamma : Penjadwal Tingkat Pembelajaran Steplr Gamma, default ke 0.5
iterations : Jumlah episode per zaman. default ke 100
classes_per_it_tr : Jumlah kelas acak per episode untuk pelatihan. default ke 60
num_support_tr : Jumlah sampel per kelas untuk digunakan sebagai dukungan untuk pelatihan. default ke 5
num_query_tr : nnumber sampel per kelas untuk digunakan sebagai permintaan untuk pelatihan. default ke 5
classes_per_it_val : Jumlah kelas acak per episode untuk validasi. default ke 5
num_support_val : Jumlah sampel per kelas untuk digunakan sebagai dukungan untuk validasi. default ke 5
num_query_val : Jumlah sampel per kelas untuk digunakan sebagai kueri untuk validasi. default ke 15
manual_seed : masukan untuk inisialisasi benih manual, default ke 7
cuda : Mengaktifkan Cuda (Store True )
Menjalankan perintah tanpa argumen akan melatih model dengan nilai hyperparamters default (menghasilkan hasil yang ditunjukkan di atas).
Kami mencoba mereproduksi kinerja kertas referensi, kami akan memperbarui hasil terbaik kami.
| Model | 1-shot (5-arah ACC.) | 5-shot (5-arah ACC.) | 1 -Shot (20 -arah ACC.) | 5-shot (20-arah ACC.) |
|---|---|---|---|---|
| Kertas referensi | 98,8% | 99,7% | 96,0% | 98,9% |
| Repo ini | 98,5%** | 99,6%* | 95,1%° | 98,6%°° |
* dicapai dengan menggunakan parameter default (menggunakan -opsi --cuda )
** Mencapai python train.py --cuda -nsTr 1 -nsVa 1
° Mencapai python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°° mencapai python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
mengutip kertas sebagai berikut (disalin-pasted dari arxiv untuk Anda):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Proyek ini dilisensikan di bawah lisensi MIT
Hak Cipta (C) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com).


