Prototypical Networks for Few shot Learning PyTorch
1.0.0
Implémentation alternative simple de réseaux prototypiques pour quelques tirs d'apprentissage (papier, code) dans Pytorch.
Comme le montre le papier de référence, les réseaux prototypiques sont formés pour intégrer les caractéristiques des échantillons dans un espace vectoriel, en particulier, à chaque épisode (itération), un certain nombre d'échantillons pour un sous-ensemble de classes sont sélectionnés et envoyés via le modèle, pour chaque sous-ensemble de classe c , un certain nombre de caractéristiques des échantillons ( n_support ) sont utilisées pour deviner le prototype (leurs coordonnées BaryCre Les échantillons n_query restants et leur classe Barycentre peuvent être minimisés.
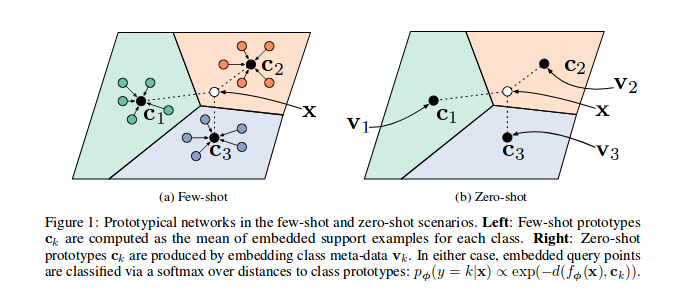
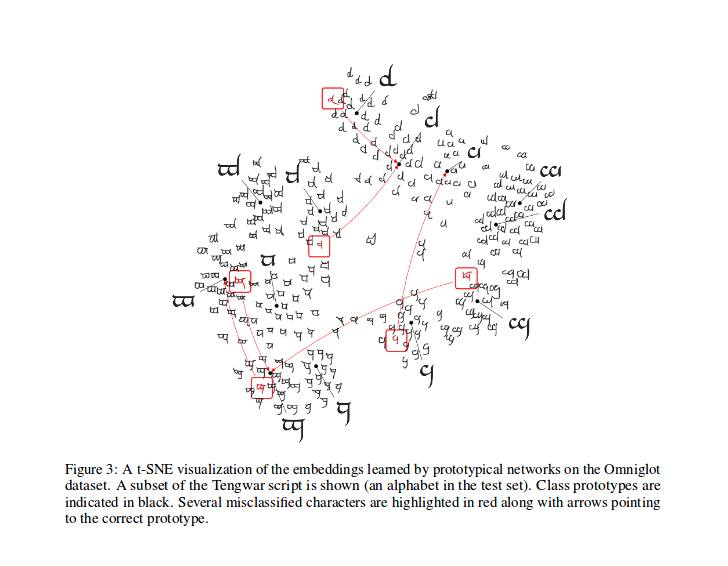
Après l'entraînement, vous pouvez calculer le T-SNE pour les fonctionnalités générées par le modèle (non réalisée dans ce dépôt, plus d'infos sur T-SNE ici), il s'agit d'un échantillon comme indiqué dans l'article.
Félicitations à @ludc pour son contribution: Pytorch / Vision # 46. Nous utiliserons l'ensemble de données officiel lorsqu'il sera ajouté à TorchVision s'il n'implique pas de grandes modifications du code.
Nous avons implémenté la méthode de division Vynials comme dans [Networks de correspondance pour un apprentissage par photo]. Cela devrait être la même méthode utilisée dans l'article (en fait, je télécharge les fichiers fendus du repo "officiel"). Nous appliquons ensuite les mêmes rotations décrites. De cette façon, nous devons être en mesure de comparer les résultats obtenus en exécutant ce code avec les résultats décrits dans le document de référence.
Comme décrit dans son PYDOC, cette classe est utilisée pour générer les index de chaque lot pour un algorithme de formation prototypique.
En particulier, l'objet est instancié en passant la liste des étiquettes pour l'ensemble de données, l'échantillonneur s'infiltre alors le nombre total de classes et crée un ensemble d'index pour chaque classe dans l'ensemble de données. À chaque épisode, l'échantillonneur sélectionne les classes aléatoires n_classes et renvoie un nombre ( n_support + n_query ) d'index d'échantillons pour chacune des classes sélectionnées.
Calculez la perte comme dans l'article cité, principalement inspiré par ce code par l'un de ses auteurs.
Dans prototypical_loss.py , la fonction de perte et la classe de perte à la pytorch sont implémentées.
La fonction prend l'entrée de l'entrée par lots du modèle, les vérités de sol des échantillons et le nombre n_suppport d'échantillons à utiliser comme échantillons de support. Les classes d'épisode sont déduites de la liste cible, les échantillons n_support sont extraits au hasard pour chaque classe, leurs barycentres de classe sont calculés, ainsi que les distances de chaque échantillon restant dans chaque classe Barycentre et la probabilité de chaque échantillon d'appartenance à chaque classe d'épisode sont finalement calculées; Ensuite, la perte est ensuite calculée à partir des mauvaises probabilités de prédictions (pour les échantillons de requête) comme d'habitude dans les problèmes de classification.
Veuillez noter que le code de formation est là juste à des fins de démonstration.
Pour former le protonet sur cette tâche, CD dans le dossier racine src de ce repo et exécutez:
$ python train.py
Le script prend les options de ligne de commande suivantes:
dataset_root : Le répertoire racine où cet ensemble de données est stocké, par défaut à '../dataset'
nepochs : nombre d'époches pour s'entraîner, par défaut à 100
learning_rate : taux d'apprentissage pour le modèle, par défaut à 0.001
lr_scheduler_step : étape de planificateur de taux d'apprentissage Steplr, par défaut à 20
lr_scheduler_gamma : STEPLR PRINCIPAL DU TAX DU TAUX GAMMA, par défaut à 0.5
iterations : nombre d'épisodes par époque. par défaut à 100
classes_per_it_tr : Nombre de classes aléatoires par épisode pour la formation. par défaut à 60
num_support_tr : nombre d'échantillons par classe à utiliser comme support pour la formation. par défaut à 5
num_query_tr : Nnumber d'échantillons par classe à utiliser comme requête pour la formation. par défaut à 5
classes_per_it_val : nombre de classes aléatoires par épisode pour validation. par défaut à 5
num_support_val : nombre d'échantillons par classe à utiliser comme support pour la validation. par défaut à 5
num_query_val : Nombre d'échantillons par classe à utiliser comme requête pour la validation. par défaut à 15
manual_seed : entrée pour les initialisations manuelles des graines, par défaut à 7
cuda : Active Cuda (Store True )
L'exécution de la commande sans arguments entraînera les modèles avec les valeurs d'hyperparamters par défaut (produisant des résultats indiqués ci-dessus).
Nous essayons de reproduire les performances du papier de référence, nous mettons à jour ici nos meilleurs résultats.
| Modèle | 1-Shot (ACC à 5 voies) | 5 tirs (ACC à 5 voies) | 1 -shot (20 voies acc.) | 5 tirs (20 voies acc.) |
|---|---|---|---|---|
| Document de référence | 98,8% | 99,7% | 96,0% | 98,9% |
| Ce repo | 98,5% ** | 99,6% * | 95,1% ° | 98,6% °° |
* réalisé en utilisant les paramètres par défaut (en utilisant l'option --cuda )
** A réalisé en cours d'exécution python train.py --cuda -nsTr 1 -nsVa 1
° A réalisé en cours d'exécution python train.py --cuda -nsTr 1 -nsVa 1 -cVa 20
°° réalisé en cours d'exécution python train.py --cuda -nsTr 5 -nsVa 5 -cVa 20
Citez le papier comme suit (copié le poutulé à partir d'Arxiv pour vous):
@article{DBLP:journals/corr/SnellSZ17,
author = {Jake Snell and
Kevin Swersky and
Richard S. Zemel},
title = {Prototypical Networks for Few-shot Learning},
journal = {CoRR},
volume = {abs/1703.05175},
year = {2017},
url = {http://arxiv.org/abs/1703.05175},
archivePrefix = {arXiv},
eprint = {1703.05175},
timestamp = {Wed, 07 Jun 2017 14:41:38 +0200},
biburl = {http://dblp.org/rec/bib/journals/corr/SnellSZ17},
bibsource = {dblp computer science bibliography, http://dblp.org}
}
Ce projet est concédé sous licence MIT
Copyright (C) 2018 Daniele E. Ciriello, Orobix SRL (www.orobix.com).


